「AIが不確かなとき」という問いかけが間違っている理由
多くのセットアップガイドはエスカレーションをチューニング問題として扱います:信頼度しきい値を選び、0.7に設定して完了。これが逆側でr/lifehacksの「人間に繋いでもらうために汚い言葉を言う」ハックを生み出すフレームです。コミュニティは脆弱なキーワードトリガーを回避する方法を学んでいます。なぜなら、ボットの信頼度数値は顧客が本当に困っていることではなかったからです。
顧客が困っているのは閉じ込められている感覚です。
本当の怒りがどこにあるか見てみましょう。r/Anthropicより:
「ボットと話したら人間にエスカレーションされ、その人間は要求が殺到しているためメールで折り返すと言われた。」
エスカレーションは技術的に成功しました。しかし顧客はまだ怒っていました。なぜならAIがコンテキストなしで非同期のブラックホールに放り込んだからです。サポートから締め出されたr/shopifyのマーチャントより:
「問題で助けが必要なのに、AIチャットボットが実際の人間と話すあらゆる方法を塞いでいるようだ。」
そしてOjas PatilがLinkedInでZomatoの配達遅延チャットについて語っています:
「理論上、自動化はサポートを速くするはずだ。現実では、顧客はボットに人間と話させてもらうよう説得する時間を費やしている。」
つまりエスカレーションの設定は「どのしきい値を選ぶべきか?」ではありません。並行して走る3つの別々のデザイン作業です:
- トリガー - AIが退くべきこと。1つのルールではなく5つ。
- ペイロード - 会話がAIを離れるときに一緒に渡されるもの。
- 遷移時の顧客体験 - AIと人間の間でユーザーが何を見て、聞いて、待つか。
1つを正しくして他をスキップすると、Navdeep Singh GillがLinkedIn Pulseで呼ぶ**「余計な手順を踏んだ放棄」**を作ってしまいます。この記事の残りは3つすべてを正しくする方法です。
エスカレーションを発動させるべき5つのトリガー
単一のしきい値は最もよくある本番バグです。信頼度は1つの入力であり、シグナル全体ではありません。BlueTweakのフレーム:「多くのチームは1つのタイプしか実装しないが、最良のシステムは3つすべてを使う」 - 明示的、信頼度ベース、コンテキスト的なトリガーが一緒に配線されています。

1. ユーザーからの明示的な要求 - 譲れない一つ
顧客が「人間と話したい」「エージェントに繋いで」またはそれに類することを入力したら、即座にエスカレーションします。確認ステップなし。「本当にいいですか?」なし。再試行なし。BlueTweakより:
「顧客が直接人間を要求したとき、システムはループなし、摩擦なし、再試行なしで即座にエスカレーションすべきだ。これを無視することは信頼を損なう最も速い方法の一つだ。」
Salesforce Agentforceはこれをトピック分類器レイヤーで実装しており、内部ロジックに飲み込まれないようにしています:「ユーザーが明示的に人間と話すよう要求したとき、システムは内部ロジックをバイパスして即座に引き渡しを発動させる。」
これは意図的に壊されることが最も多いトリガーでもあります。通常、誰かがデフレクション率を最適化しているからです。やめましょう。Social Intentsのチャットボットエンゲージメント80%という数値には条件があります:「80%の人々は人間のオプションが存在することを知っている場合にのみチャットボットを使う。」 非常口を隠すとデフレクション率は上がりますが、エンゲージメントは崩壊します。(関連するメトリクスの罠についてはライブチャットデフレクション向けAIについての見解をご覧ください。)
2. 低信頼度 + 第2モデルのQAゲート
これは全ガイドが最初に取り上げるトリガーであり、最も調整が難しいものです。3つのことが重要です:
信頼度数値はあなたが考えるものではありません。 Digital Applied の2026年エスカレーション設計ガイドより:
「RLHFで訓練されたモデルは系統的に誤キャリブレーションされており、最高の言語的信頼度が間違った出力と相関することが多い。本番の過信頼度分析が文書化しているように、宣言された90%の信頼度は実際の精度75%程度に相当することが多い。」
したがって生の0.7しきい値は30%のミス率ではなく、多段階エージェントにわたって蓄積された実際のミス率は40〜45%に近くなります。自然に感じるよりも高いしきい値を設定し、間違えると高コストな意図に対してはさらに厳しくします。Social Intentsは「連続2回40%未満」から始めることを推奨し、返金・請求・キャンセルには高いしきい値(約0.4)を設定することを勧めています。
信頼度と知識カバレッジを組み合わせます。 引用できる関連ドキュメントがないボットは、自信があっても本来エスカレーションすべきです。そのためナレッジベースに接続するAIチャットボットは返信前にすべての回答を根拠付けします。Gorgias AIエージェントの文書化された動作:
「AIエージェントの回答は接続したソースに完全に基づいています。それを超えた推測はせず、関連する回答が見つからなければ推測する代わりに引き渡します。」
すべての返信の前に別のQAモデルを配置します。 これは本番設定で最も省略されるパターンです。再びGorgias:
「すべての返信は内部QAステップも通過します。第2のAIモデルが信頼度を測定し、返信がしきい値を満たさない場合は送信されません。」
第2モデルゲートは、プライマリモデルが自信を持って間違っているケースを捕捉します。これは最も損害の大きい障害モードです。しきい値を過剰エスカレーションなしに調整する方法の詳細については、Zendesk AIエージェントの意図信頼度しきい値ガイドがメトリクスのトレードオフを解説しています。
3. 感情と機密トピック - 信頼度に関わらずエスカレーション
このトリガーはAIが自信を持っているときでも発動します。Gorgiasのガードレールより、ほとんどのストアに推奨されるハードコードされた引き渡しリスト:
「法的紛争または法的措置に関するあらゆる言及;医療上の質問または健康状態への言及;詐欺関連の言語またはチャージバックへの言及;書面による方針の範囲外の判断を必要とするあらゆる苦情。」
その上に感情状態レイヤーを追加します。Social Intentsは*「これは役に立たない」、「イライラしてきた」*、繰り返し質問パターン、またはメッセージ長の増加などのフレーズを監視し、顧客が怒りで離脱する前に謝罪と引き渡しをトリガーすることを推奨しています。
CX Todayはこのレイヤーを「リスクスコアリング」と呼んでいます:
「ボットが自信を持っていても、この状況は自動化するには敏感すぎませんか?詐欺シグナル、請求紛争、脆弱な顧客、規制された開示、または不正に扱われると評判被害を生む可能性のあるものを考えてください。」
4. VIP / 顧客セグメント
すべての顧客が同じではありません。Social Intentsより:
「優先ユーザー(プラチナクライアント、大口顧客、主要アカウント)を特定できる場合、チャットボットの初期トリアージ後に人間にエスカレーションすることを検討してください…VIP顧客には営業時間中に優先エスカレーションを与え、最良の顧客を特別に満足させましょう。」
このトリガーはAIエージェントがすでに持っている顧客データに基づいています:注文金額、アカウント層、NPSスコア、アカウント年齢。ヘルプデスクで既に追跡しているセグメントフィールドに接続します。実践的な例:LTV > $10kの顧客は営業時間中に自動化を完全にバイパスし、時間外のみAIエージェントに対応させます。これが価値があるかどうかの計算は自動化に有利な傾向があります。AIエージェント対人間エージェントのコストの比較をご覧ください。
5. アクションに人間の承認が必要
不可逆的な操作にのみ使用します:資金移動、アカウント削除、返金承認、割引発行、身元変更、データエクスポート。Digital Appliedの4段階アクションリスクモデルは明確です:
「Tier 4 - 高リスク / 不可逆。本番デプロイ、資金移動、データ削除、権限変更、外部通信。エージェントがどれだけ自信を持っていると主張しても、人間の承認は非交渉です。」
Gorgiasの平易な言い方:「人間のエージェントが最初に承認せずに割引を提供しないでください。」
重要な詳細:承認ゲートはAIのプロンプトの中に置くことができません。 Digital Appliedより:
「承認ロジックはワークフロー実行レイヤーで強制されるべきであり、AIが実行時にネゴシエートするものではありません。」
モデル自身の次のアクションが承認を必要とするかどうかをモデルに決めさせると、十分に説得力のある顧客メッセージが聞くのをやめさせることができます。アクションを発動するワークフローにルールを組み込んでください。プロンプトではなく統合レイヤーで。
引き渡しペイロード:人間が実際に必要とするもの
これはほとんどのエスカレーション設定を飲み込む障害モードです。トリガーは正しく発動します。会話は移動します。人間はコールドスタートします。顧客は「自動化は私の時間を無駄にした」と感じます。
この数値は認識されているより鋭いです。BlueTweakが引用するPwCの調査より:
「73%の消費者が、情報を繰り返さなければならないことをサポートインタラクションの最も不満な部分の一つとして挙げており、特に転送後に顕著だ。」
「顧客の約70%が会話がエスカレーションされたときにエージェントが自分の履歴を知っていることを期待しているが、サポートチームの約34%しかツールが実際にそのデータをきれいに渡すと言っていない。」
70/34の期待対提供のギャップは構造的な問題であり、チューニングの問題ではありません。それがどこでも見られる理由:ほとんどのプラットフォームは人間に生のトランスクリプトを渡すことで「コンテキストを渡している」と主張します。それはコンテキストではなく、非構造化データです。
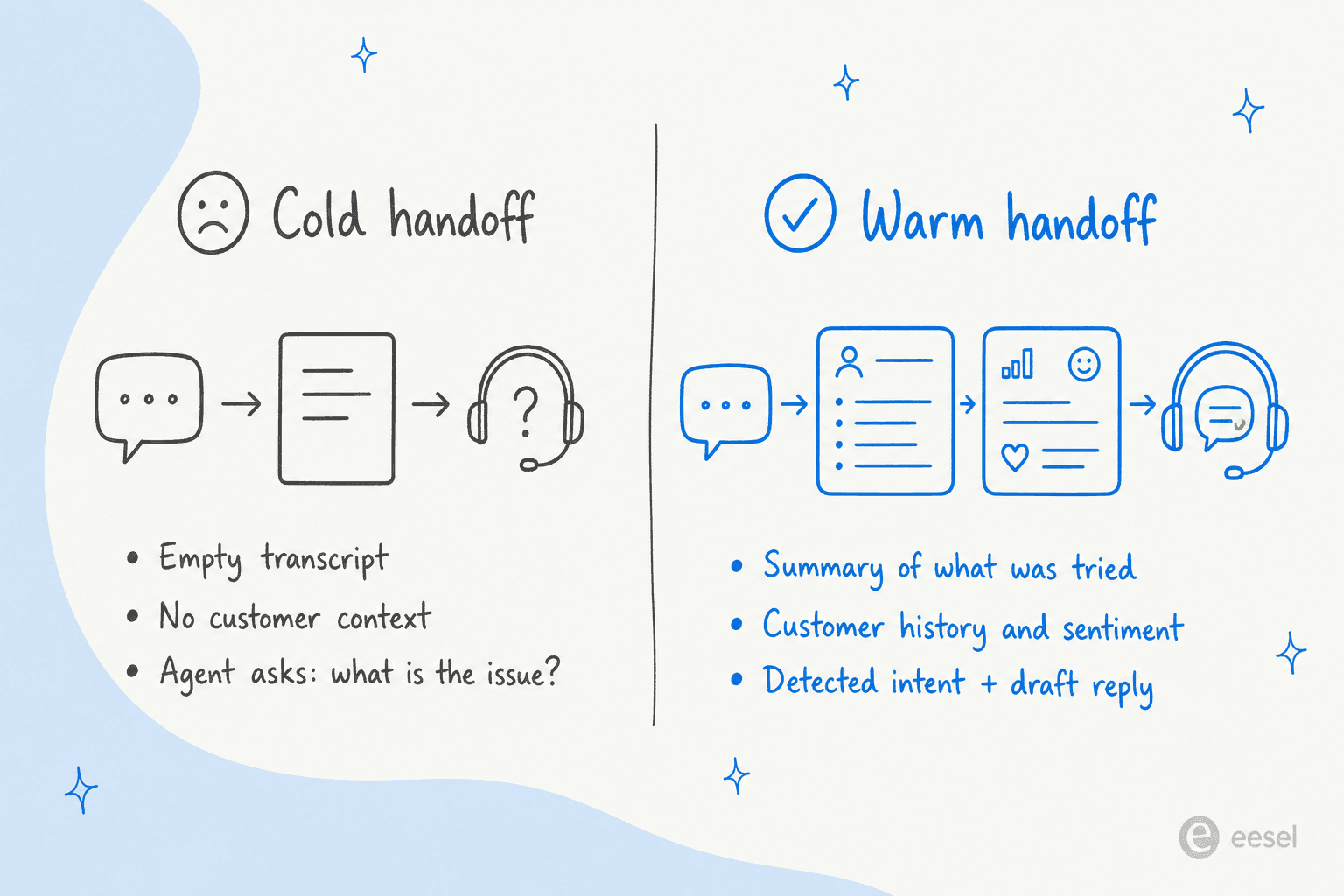
最小コンテキストパッケージ
BlueTweak のフレームから、動作するペイロードには6つのフィールドがあります:
| フィールド | 内容 | 重要な理由 |
|---|---|---|
| 問題サマリー | 顧客の言葉ではなくエージェントの言葉での1文 | エージェントはこれを最初に読む;他のものはオンデマンドで読み込む |
| 検出された意図 | 分類されたカテゴリー(例:refund_request、wismo、billing_dispute) | エージェントはボットがどのバケットだと思ったか、そして何を間違えた可能性があるかを知ることができる |
| 顧客とアカウントデータ | 名前、プラン、注文金額、LTV、最近の注文、サポート履歴 | エージェントを会話だけでなく関係性に位置づける |
| 感情インジケーター | 引き渡し時の検出された感情状態(不満 / 中立 / ポジティブ) | エージェントが読む前にトーンに備える |
| AIが試みたこと | 送信された返信、引用されたソース、実行または試みたアクション | エージェントがAIが試みたことを提案するのを避ける |
| 返信の下書き | 人間が編集して送信できるスタート返信 | 最も速いCSATの向上;エージェントはゼロから始めない |
アクション承認エスカレーションに特有のものとして、Digital Appliedは*「推定財務影響、可逆性フラグ、エージェントが評価した代替アプローチ、監査相関のためのセッションID、承認期限タイムスタンプ」*の追加を推奨しています。承認者が何を承認しているかを見ずにYesをクリックするよう求められないように。
オープニングも重要です
引き渡し後のエージェントの最初のメッセージは、顧客が遷移がウォームかコールドかを判断する場所です。Social Intentsより:
「こんにちは田中様、パスワードのリセットについてボットとチャットされていたようですね。それについてお手伝いします。」
vs 障害モード:
「こんにちは、どのようなお手伝いができますか?」
前者はAIの作業を認識します。後者は顧客をゼロに戻します。前者は5秒の勝利です;後者は54%の離脱シーケンスの始まりです。
実際の設定方法:5ステップのウォークスルー
構築すべき順番でのメカニクス。
ステップ1 - AIが触れるべきでないものを決める
トリガーを調整する前に、禁止リストを定義します。これは思ったより速く、正しくする必要がある表面積を劇的に減らします。
最近1ヶ月分のチケットを開きます。間違えると高コストなカテゴリーにタグを付けます:返金、請求紛争、アカウント変更、法律に隣接するもの全て、個人情報やPIIを含むもの全て、規制業種(医療、金融、法律アドバイス)のもの。これらのカテゴリーには信頼度しきい値は不要です。「常にエスカレーション」と言うハードルールが必要です。
Gorgias + Shopify(月約7,000チケット)のDTCサプリメントブランドのCXリードとして匿名化した実際の顧客より:
「AIを通したくないチケットがある。」
これは回避すべき制約ではなく、機能要件です。「このカテゴリー全体は人間に行く、AIなし」と言える能力を自分に与えてください。
eeselでは、エージェントのエスカレーションルールの1行の平文で行います:
「
refund_request、legal、またはbilling_disputeのタグが付いたチケットには返信しない。1行サマリーと共にチームに直接引き渡す。」
Zendeskでは、関連するフローの先頭にエスカレーションブロックを配置することでこれを行います。Zendeskフロービルダーガイドでどこに配置するかを解説しています。GorgiasではAIエージェントアクションの設定に従って設定する引き渡しトピックリストです。結果は同じ:特定のものはAIに触れない。
ステップ2 - マルチシグナルトリガーロジックを設定する
AIが触れることを許されているものすべてに対して、他の4つのトリガーを重ねます。
これについてのより詳細なウォークスルーについては、Zendesk AIエージェントの人間への転送ガイドとZendesk AIエージェント引き渡しのハウツーがメッセージングチャンネルのメカニクスをさらに詳しく解説しており、Zendesk AIエージェントフォールバックメッセージガイドは何も一致しないときに何を言うかをカバーしています。
合理的な開始設定:
- 信頼度しきい値:ベースライン0.6、ハイリスクな意図(返金、請求、キャンセル)では0.8。
- 繰り返し失敗キャップ:顧客が異なる方法で同じことを聞く2ターン → 3回目にエスカレーション。
- 感情トリガー:不満の検出 → 謝罪 + 人間を提供。
- VIPルール:
vipタグが付いた顧客またはLTV > $Xの顧客 → 営業時間中は直接人間へ。 - アクション承認:$Xを超える返金、アカウント削除、割引発行 → AIがどれだけ確信していてもエスカレーション。
ツールが1つのノブしか公開していない場合は、他をシミュレートする必要があります。通常は引き渡しトピックをリストに入れてキーワードを監視します。Tidio LyroのナチュラルランゲージGuidanceはこのように動作します。実用的ですが、不満な顧客が実際に使う言葉のルールを書かない限り感情ケースは検出できません。

ステップ3 - 遷移メッセージを書く
トリガーが何であれ、引き渡しの瞬間に顧客は何かを聞きます。沈黙しないでください。Social Intentsより:
「サイレントに切り替えないでください。ボットは次のようなことを言うべきです:『もちろんです、さらにお手伝いできる人間のエージェントに繋ぎます。』 待ち時間がある場合は期待値を設定します:例えば 『エージェントがすぐに参加します』 または 『現在2番目にお待ちです、約1〜2分でエージェントが対応します。』」
含めるべき3つのこと:
- 彼らが何をしようとしていたかの認識。
- 推定待機時間(範囲でも可)。
- 人間が完全なコンテキストを持つという注記。ゼロから始まる感じがしないように。
時間外の場合はメールを取得し、返信の期待時間を伝えます。Gorgiasのオフラインチャットパターン - 「チャットがオフラインのときに引き渡しが発生した場合、AIエージェントはショッパーのメールアドレスを求め、後でチームがメールでフォローアップできるようにする」 - が正しいデフォルトです。オプションの*「引き渡しメッセージに営業時間を共有する」*トグルは期待値を設定するための小さなタッチです。
ステップ4 - 構造化されたペイロードを渡す
ほとんどのプラットフォームは次の人間にトランスクリプトを渡して完了と呼びます。これがコールド引き渡しの障害モードです。上記の6つのフィールドからペイロードを構築し、エージェントがトランスクリプトの前にそれらを見るようにします。20件のメッセージの下に埋まっているのではなく。
Zendeskでは、エスカレーションブロックの一部としてチケットフィールドとタグを入力し、サマリーを上部に表示する会話トランスクリプトビューを使用します。Zendesk AIエージェント会話ログビューでペイロードのギャップを発見します。Gorgiasでは、自動タグ付けパターン(エスカレーション用のai_handover、除外チケット用のai_ignore)でダウンストリームのルーティングルールを構築できます。Gorgias引き渡しガイドでは、これらのタグをエージェント割り当てに接続する方法を解説しています。
eeselのパターンは、エージェントがスレッドを読む前に構造化された内部ノートとしてサマリーを置くことです。エージェントが最初に見るのは*「サマリー:顧客は注文#4521の配送を更新したい、AIがセルフサービスリンクを送るよう試みたが、顧客はアカウントで見つけられないと返信した。」*これがエージェントのアンカーです。必要なら完全なトランスクリプトもそこにありますが、めったに必要としません。
ステップ5 - 引き渡し率ではなく引き渡し結果を測定する
これは誰もがスキップするステップです。BlueTweakより:
「低い率は強力な自動化を示す可能性も、顧客がAIループに閉じ込められているシグナルの可能性もある。高い率は低いAIパフォーマンスを反映する可能性も、真に人間の介入を必要とするユースケースに過ぎない可能性もある。メトリクスは結果と組み合わせたときだけ意味を持つ。」
実際に重要なメトリクス:
- 引き渡し後の初回解決率(FCR) - 全体のFCRとは別に追跡。エスカレーションされたチケットが戻ってき続けるなら、間違ったチケットがエスカレーションされているかペイロードが失敗しています。
- エスカレーション後の24〜48時間ウィンドウ内の再コンタクト率。BlueTweakによると*「隠れた失敗の最も信頼できる指標の一つ。」*
- CSATデルタ - エスカレーションされた会話vs自動解決された会話のCSAT。エスカレーションが一貫して低いスコアなら、問題はエージェントではなく引き渡し体験です。
- コンテキスト完全性スコア - エージェントが各引き渡しを評価:十分 / 部分的 / 不足。収集コストが低く、ペイロードのバグを素早く露出。
- 顧客がAIからオプトアウトした後の人間までの時間。長い待機 + 少ないコンテキスト = 最悪のCSATの組み合わせ。
- オーバーライド頻度 - スーパーバイザーがボットをオーバーライドし続けている場合、しきい値が緩すぎます。
下位四分位の引き渡しの月次レビューを実施します。Gorgiasが推奨するサイクル:「フラグが立ったチケットを読み、理由付きで良い/まあまあ/悪いと評価し、引き渡しクラスターについてIntentsページを確認し、Guidance Opportunitiesをレビューして承認し、ポリシーが変わったらGuidanceを更新する」 (Gorgias)。設定した場所全てで同じループを適用します。
より深いメトリクス設計については、Zendesk AIエージェントのメトリクスと解決率および広範なAI対人間カスタマーサポート比較のウォークスルーをご覧ください。
主要なヘルプデスクAIエージェントのエスカレーション処理
ベンダーを選んでいる場合(または既存のベンダーがなぜ誤ってルーティングし続けるか理解しようとしている場合)、プラットフォーム間の違いは主にトリガーロジックがどのように公開されているかにあります。作者が構築したブロック、ネイティブの信頼度ダイヤル、またはナチュラルランゲージルール。エスカレーションサーフェスの形状があなたが実際に購入しているものです。
| ベンダー | エスカレーショントリガーモデル | 知っておくべきこと |
|---|---|---|
| Zendesk AIエージェント | 作者定義のエスカレーションブロック + 会話引き渡しイベント。ユーザーリクエスト・意図不一致・ブロック配置からのトリガー | 「エージェントは会話に関連するチケットが閉じられるまで最初のレスポンダーのまま」 - デフォルトの4日間の解決から閉鎖ウィンドウにより引き渡し状態が宙に浮く可能性あり。Zendesk エスカレーションガイドをご覧ください |
| Freshdesk Freddy | 「エージェント引き渡しの自動化」トグル + AIエージェントスタジオの引き渡し設定。主にリクエスト駆動;公開NLP信頼度ノブなし | プレビューモードは*「未回答のクエリや人間エージェントサポートが要求された場合のエージェント転送を実行しない」* - 本番なしでエスカレーションを完全にテストできない。Freshdesk ベストプラクティスをご覧ください |
| Gorgias Automate | 4つの明示的なトリガー:低信頼度、リストされた引き渡しトピック、知識ギャップ、明示的な要求または怒り/不満の検出 | Chat AIエージェントはShopifyのみ。非ShopifyマーチャントはチャットにこれをWebサイト以外で使用できない。Gorgias引き渡しガイドをご覧ください |
| Ada | 名前+説明を持つファーストクラスのHandoffオブジェクト;ライブ/非同期/時間外バリアント;組み込みフォールバック | 最大5つのアクティブな引き渡し;引き渡しブロックの変数はActions収集データとは別 - 最もよくある落とし穴 |
| Salesforce Einstein/Agentforce | 作者が配置したステップのエージェントシステムダイアログへの転送;フォールバックとしてConfused Dialog | 競合する転送ステップはNext Stepをサイレントにオーバーライドします - 2つの設定が警告なしに競い合う可能性あり |
| Help Scout | 自律エージェントなし - AIドラフトとAIアシストはデフォルトでhuman-in-the-loop | 人間がループの外に出たことがないので「エスカレーション」は意味をなさない。Plus/Proプランのみ;AIドラフトが何かを生成するには過去の返信が約100件必要 |
| Tidio Lyro | プロンプトスタイルのGuidance - 高価値顧客、機密トピック、エージェント可用性のためのナチュラルランゲージルール | 基盤となるClaudeモデルが更新されるとエスカレーションロジックがドリフトする;無料ティアは50 Lyroレスポンスに制限。Tidio AIエージェントガイドをご覧ください |
より広いコンテキストについては、カスタマーサポート自動化のための最良のAI、最良のAIカスタマーサポートチャットボット、サポート向けAIライブチャットツールのまとめをご覧ください。エスカレーション動作はスコアリングの次元の1つです。
テーブルから2つのパターンが際立っています。第一に、これらのツールのほとんどはエスカレーションをフローロジックとして表現させます - エスカレーションブロック、転送ダイアログ、システムボット。専任のボットビルダーなら問題ありません;サポートリードにルールを書かせたい場合は摩擦です。第二に、ほぼすべてが公開ドキュメントでペイロードコントラクトを明確にしていません。APIを通じて構造化されたpassControlメタデータ形式を公開しているのはZendeskだけです;Adaは変数を公開しています(上記のActionsの落とし穴あり)。他の全員については、引き渡しと一緒に渡されるのは会話にたまたまあったもので、それは「トランスクリプト」の丁寧な言い方です。
それがeeselが埋めるギャップですが、原則は一般化できます:何を使っていても、プラットフォームが正しいものを渡してくれることを期待するのではなく、ペイロードを明示的にします。
よくある障害モードとそれぞれの修正
ベンダーのドキュメント、実務家の投稿、収集したコミュニティの感情に繰り返し現れるパターン:
- ボットはエスカレーションする代わりに幻覚を見る。 低信頼度の回答が送信され、CSATがサイレントに崩壊する。修正: 送信前の第2 AIのQAゲート。それなしでは、「誤った返金ポリシーを自信を持って幻覚するボットは、『よくわかりません、人間を呼ばせてください』と言うボットより悪い結果だ」 (r/AI_CustomerService)。
- 顧客が諦めるまで「わかりません」のループ。 Freshdeskはこれを直接指摘:「これらの瞬間を、人間エージェントへの会話のシームレスな転送に設定し、イライラする無限ループを防いでください。」 修正: 2ターンルール。
- 「非常口」が隠れている。 「30%の消費者は1回の悪いチャットボット体験の後に競合他社に乗り換える」;「80%の人々は人間のオプションが存在することを知っている場合にのみチャットボットを使う」 (Social Intents)。修正: 最初のメッセージから「エージェントに話す」オプションを見えるようにする。
- コンテキストのリセット。 エスカレーションが発生し、エージェントはコールドスタートし、顧客は*「自動化は私の時間を無駄にした」*と感じる (CX Today)。修正: 先ほどのペイロード。
- ループバック - 顧客を失敗したばかりの同じフローに戻す。「信頼はすぐに崩壊する」 (CX Today)。修正: 意図別に失敗したフローを追跡して無効化する。
- 行き止まり - ボットは解決できず信頼できる次のステップも提供しない。「顧客は閉じ込められていると感じる」 (CX Today)。修正: どんなフォールバックパスも何もないよりはマシ - 「24時間以内にメールします」でも。
- 検証不可能なアクション - 「ボットは『直した』と主張するが何も変わらない。これはCXの問題だけでなく、敏感な環境での詐欺とコンプライアンスのリスクだ」 (CX Today)。修正: トリガー5のワークフローレベルの承認ゲート。
- 過剰エスカレーションがデフレクションポイントを殺す。 逆の障害。Digital Appliedより:「承認リクエストが頻繁に来すぎると、人々は読むのをやめる。反射を発達させる - 承認、承認、承認 - そしてその反射は攻撃面だ。」 修正: 承認を階層化する;フラグが立ったものすべてがTier 4ではない。
- デフレクション率のみをKPIとする。 r/sysadminの社内ITヘルプデスクより:「今月5000件の問題を処理した!高価な人間のキューに達しなかった5000件のチケット。ただし、その半数がボットの『回答』が実際には何も修正しなかったため2日後に再チケットを作成し、今はバックログと怒ったユーザーがいる」 (r/sysadmin)。修正: 再コンタクト率。
- 隠れた再コンタクト失敗。 顧客がエスカレーション後24〜48時間以内に戻る;最も信頼できる失敗シグナルの1つ (BlueTweak)。修正: メトリクスは存在する;測定する。
- AIが説得されて外れる可能性のある承認ロジック。 AIが自身の次のアクションが承認を必要とするかどうかを決める場合、十分に説得力のあるプロンプトがそれを聞くのをやめさせることができる (Digital Applied)。修正: 承認ルールはワークフローレイヤーに存在し、プロンプトには絶対に置かない。
ウォーム引き渡しの実際の例
これがエンドツーエンドで機能するときの様子。SE Rankingのウェブサイトチャットバブルのエンドユーザーより(共有許可をいただいた匿名の顧客ストーリー):
「プロジェクトからキーワードを削除するにはどうすればよいですか?」
(AIエージェントがヘルプドキュメントから回答。)
「検索エンジンを削除するにはどうすればよいですか?」
(AIエージェントがヘルプドキュメントから回答。)
「人間と話せますか?」
(AIが即座に
handover_to_helpdeskを発動し、2つの質問+回答、顧客のメール、1行のサマリーを添付:「ユーザーはキーワード/検索エンジン削除ドキュメントを閲覧していた;今は人間の助けが必要 - ドキュメントがないフォローアップの質問の可能性が高い。」)
2つのドキュメント質問がデフレクションされました。顧客が人間を求めた瞬間、即座に引き渡し、完全なコンテキスト。これが全体のパターンです:AIが簡単な作業をやり、適切なツールでなくなった瞬間に退き、人間はメッセージ4から1〜3の完全な可視性で始まります。
2番目のパターン、Confluenceバックアップ + Jiraエスカレーションのウェブサイトチャットウィジェットを立ち上げているメドテックチームより:
「スニペットをコピーしたがNetlifyで動作しない...」(AIがデバッグを支援) ... 「動いた。プレビュー/テストチャットを同僚と共有して試してもらえますか?」(AIがチャットの途中で統合設定をライブに切り替え、その後フォローアップのためにJiraチケットをエスカレーション。)
繰り返す形:AIが得意なことを処理する。そして何かが人間の判断や承認を必要とする瞬間に、エスカレーションが発動します。コンテキストと共に、正しいチャンネルで、正しいチームに。
AIチャットエスカレーションにeeselを試す
このパターン全体 - 5つのトリガー、平文ルール、完全なコンテキストでのウォーム引き渡し - をプリミティブから構築せずに手に入れたい場合、それがeeselの提案です。
eeselはすでに使っているヘルプデスク内でAIチームメイトとして動作します - Zendesk、Freshdesk、Gorgias、Freshservice、Slack、メール - プラットフォームを変えずに複数のヘルプデスクで実際に機能するエスカレーションルールを取得できます。ルール自体は平文で記述されます:「返金リクエストには絶対に返信しない;サマリーと共にチームに引き渡す」、「顧客が法的措置やチャージバックに言及したら、感情フラグと共に即座にエスカレーション」、「priorityタグが付いたVIPは営業時間中は常に人間に行く。」 フロービルダーなし、ダイアログツリーなし。
引き渡しペイロードはデフォルトで構造化されています:すべてのエスカレーションされたチケットは、人間が読む前に内部ノートとして添付されたサマリー、検出された意図、顧客の最近の履歴、返信の下書きを受け取ります。設定は既存のヘルプ記事と過去のチケットから数分で完了します。手動トレーニングなし、データラベリングなし。自信が付いたら簡単なカテゴリーで自律に切り替える前に、本番稼働前に過去のチケットでテストでき、ドラフトモード(AIが提案、人間が送信)で始められます。価格はシートではなくタスク単位なので、エスカレーションに保守的であるコストは低く保たれます。
eeselを無料で試す - $50クレジット付き、カード不要。
よくある質問
不確かなときに人間へエスカレーションするAIエージェントをどう設定しますか?
エスカレーションを1つではなく5つのトリガーに同時に紐付けます:ユーザーからの明示的な要求、低信頼度の回答(返信前に第2モデルのQAゲートと組み合わせる)、感情または機密トピックの検出、VIP顧客セグメント、そして人間の承認が必要なアクション(返金、キャンセル、不可逆なもの全て)。これをベンダーのボットビルダーで設定するか、eeselを使って英語の平文でエージェントのエスカレーションルールに記述します。その後、本番稼働前に過去のチケットでテストしましょう。
AIチャットエスカレーションとは何ですか?
AIチャットエスカレーションとは、AIサポートエージェントが会話の解決を止めて人間に引き渡す瞬間です。ユーザーが要求したとき、モデルの信頼度が下がったとき、感情が変化したとき、あるいは次のアクションに人間の承認が必要なときに発生します。うまく行えば自動化とチームをつなぐ信頼の橋になります。うまく行かなければ、顧客には「余計な手順を踏んだ放棄」に映ります。最良のAIカスタマーサポートエージェントの比較では、各ベンダーの対応方法を比較しています。
AIチャットエスカレーションの信頼度しきい値はどのくらいが適切ですか?
一律の数値はありません。信頼度は複数の入力の1つとして扱ってください。RLHFで訓練されたモデルは系統的に誤キャリブレーションされており、宣言された90%の信頼度は実際の精度75%程度に相当することが多いです。多くのチームは約40%から始め、返金などハイリスクな意図に対してしきい値を引き上げます。Zendeskのしきい値ガイドでは、過剰エスカレーションを避けながら調整する方法を解説しています。
引き渡し時にAIエージェントは人間にどのようなコンテキストを渡すべきですか?
生のトランスクリプトではなく、構造化されたサマリーです。最低限必要なもの:顧客の問題の1行説明、AIが試みたこと、検出された意図、感情、関連する顧客・注文データ、そしてエージェントが編集して送れる返信の下書き。PwCの調査によると、73%の顧客が情報を繰り返さなければならないことをサポートの最も不満な点として挙げています。エージェントが二度と「問題は何ですか?」と聞かないことが目標です。1つのプラットフォームでの例はZendesk会話トランスクリプトガイドをご覧ください。
AIチャットエスカレーションのルールはZendesk・Freshdesk・Gorgiasで同時に機能しますか?
ネイティブには機能しません。各ベンダーは独自のボットを独自の方法で構築しています。Zendeskのエスカレーションは作者が配置するブロックを使用し、Freshdesk Freddyはリクエスト駆動の引き渡しトグルを使用し、Gorgiasは信頼度+トピックルールを使用します。複数のヘルプデスクで1つのルールセットを使いたい場合は、eeselのようなプラットフォームが役立ちます。同じ平文ルールがZendesk・Freshdesk・Gorgiasのいずれのチケットにも適用されます。

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.