Ce qu'est réellement GLM-5.2
GLM-5.2 est le dernier modèle phare de Z.ai, la société anciennement connue sous le nom de Zhipu AI, issue de l'Université de Tsinghua en 2019 et entrée en bourse à Hong Kong en janvier 2026. La fiche technique synthétique :
- Poids ouverts, licence MIT. Les poids sont publics sur Hugging Face et ModelScope, sans restrictions régionales. Vous pouvez les télécharger et les exécuter vous-même.
- 753 milliards de paramètres, ~40 milliards actifs. C'est un modèle Mixture-of-Experts, donc seule une partie de ces paramètres s'active par token.
- Contexte d'un million de tokens. Un saut 5x par rapport aux 200K de GLM-5.1 ; Z.ai souligne qu'il est entraîné pour rester fiable sur de longues exécutions d'agents de coding désordonnées, pas seulement pour accepter nominalement les tokens.
- Conçu pour le travail à long horizon. L'ensemble de la version 5.2 est axé sur les tâches de coding et d'ingénierie autonomes qui durent des heures, avec un nouveau contrôle de niveau d'effort (
Maxpour la qualité maximale,Highpour réduire environ de moitié les tokens de sortie).
En termes simples : c'est un modèle de coding de classe frontier que vous pouvez légalement exécuter sur votre propre matériel. Cette combinaison est ce qui attire l'attention, car elle n'avait pas vraiment existé avant à cette qualité, et elle remodèle la façon dont les équipes pensent leurs budgets en IA générative.
Les benchmarks et ce qu'ils apprennent à une entreprise
La revendication phare de Z.ai est que GLM-5.2 est le modèle open-source le plus puissant sur les benchmarks de coding standard, et le premier modèle open-weights à dépasser les 80% sur Terminal-Bench. Les chiffres confirment ce positionnement.
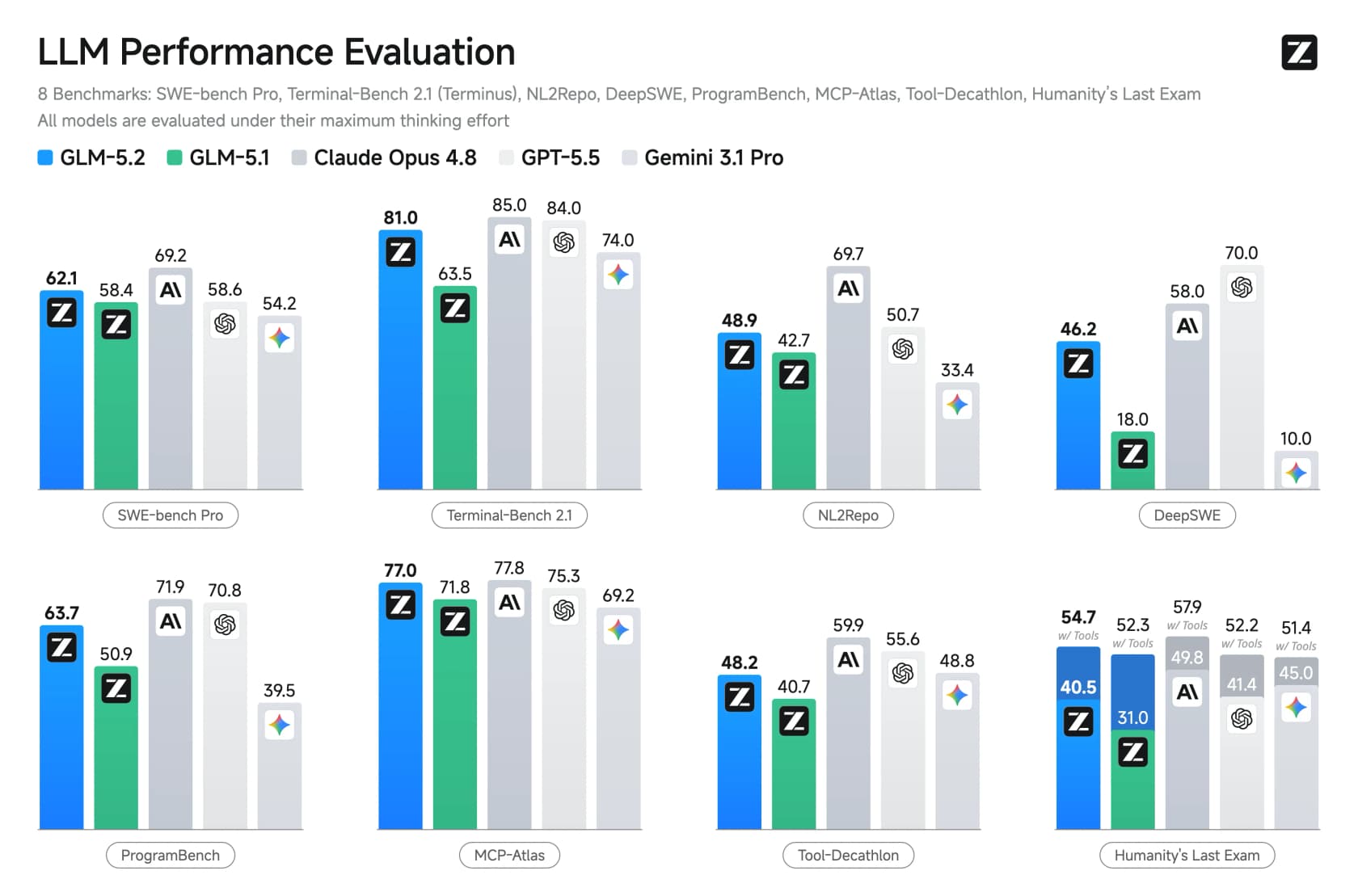
Sur la suite de coding standard, GLM-5.2 affiche 62,1 sur SWE-bench Pro et 81,0 sur Terminal-Bench 2.1, juste derrière Opus 4.8 (85,0) et devant GPT-5.5 sur plusieurs métriques. Le saut depuis GLM-5.1 est ce qui devrait vous faire réagir : Terminal-Bench est passé de 63,5 à 81,0 en une seule version.
Le tableau à long horizon est encore plus déséquilibré, ce sur quoi Z.ai a concentré ses efforts.
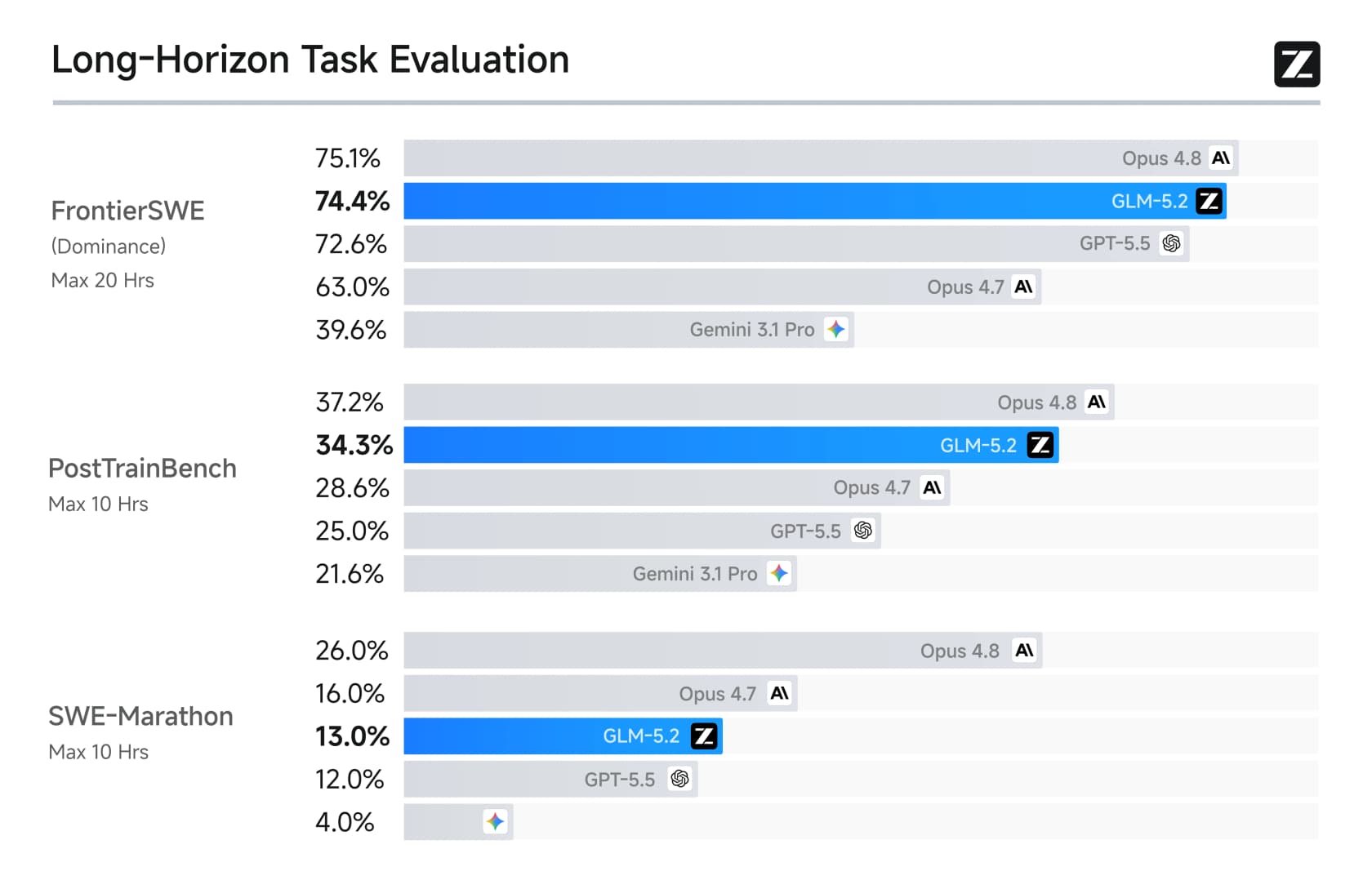
Sur FrontierSWE, il atteint 74,4%, presque au coude à coude avec les 75,1% d'Opus 4.8 et bien au-dessus de GPT-5.5. Des praticiens reconnus l'ont remarqué. Jeremy Howard de fast.ai l'a qualifié de merveille :
« @Zai_org GLM 5.2 est une merveille ! Il est au moins aussi bon qu'Opus 4.8 et GPT... Il est super rapide, peu coûteux et pas trop verbeux. Il répond avec nuance et jugement, et gère très bien le contexte long. »
Graham Neubig, qui travaille sur les agents de coding à CMU, est allé plus loin en publiant qu'il est « probablement le premier modèle suffisamment bon pour se passer entièrement des modèles fermés dans son workflow ». C'est une affirmation forte de la part de quelqu'un qui n'a aucune raison de le flatter.
Voici cependant le bémol que je souhaiterais mettre sur la table. Les benchmarks sont des benchmarks de coding. Ils vous disent que GLM-5.2 est excellent pour écrire et corriger du code sur de longues sessions ; ils ne vous disent pas grand-chose sur la façon dont il se comporte en répondant à un client confus à 2h du matin, où le mode d'échec n'est pas un test raté, mais une mauvaise réponse exprimée avec confiance que personne ne détecte. Plus à ce sujet ci-dessous.
Le vrai titre, c'est le prix
Les benchmarks attirent l'attention, mais le prix est ce qui fait vraiment bouger les entreprises. GLM-5.2 fonctionne à 1,40 $ par million de tokens en entrée et 4,40 $ par million en sortie, contre 5 $/30 $ pour GPT-5.5 et 5 $/25 $ pour Opus 4.8.
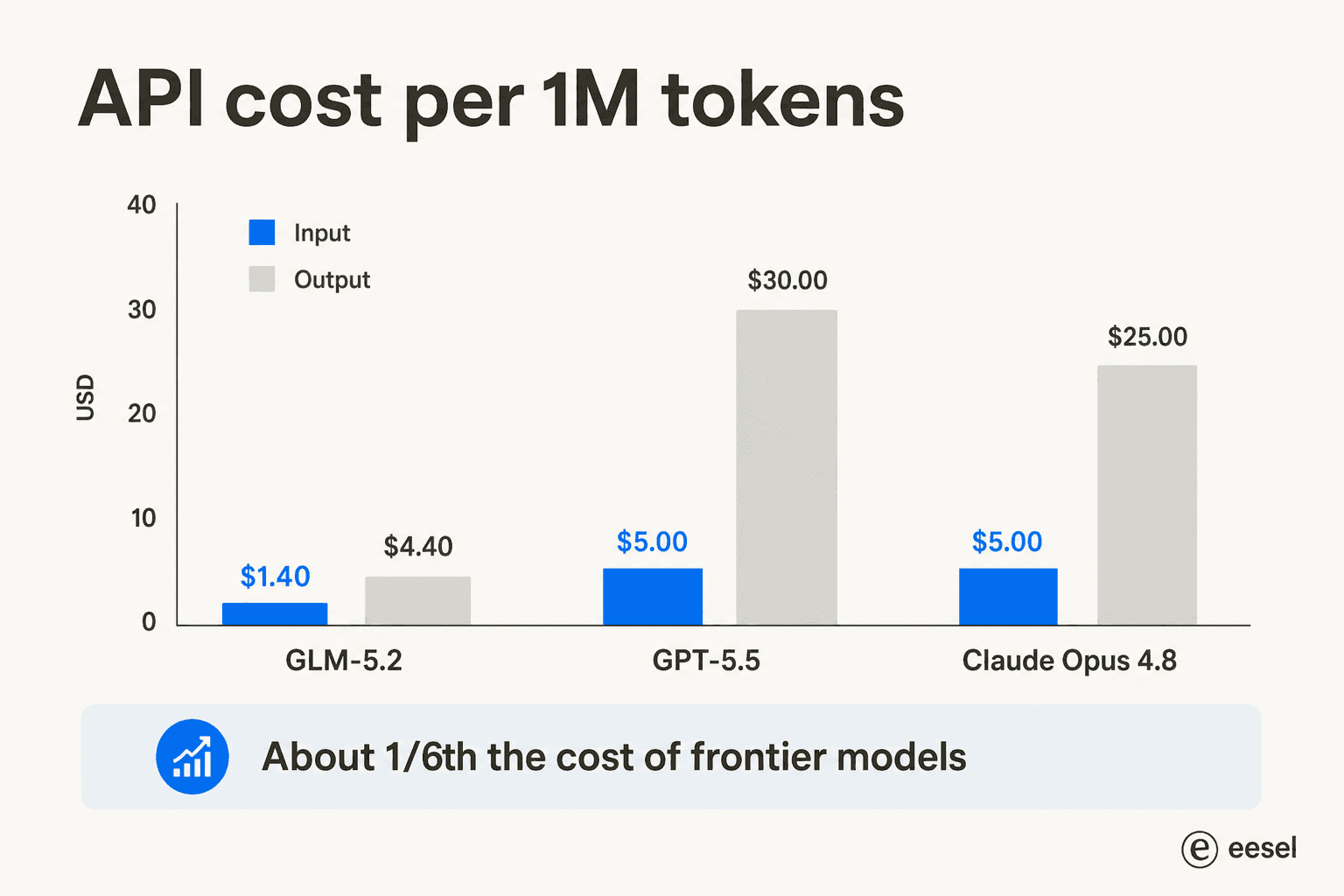
Cet écart est toute l'histoire pour beaucoup d'équipes. Le cadrage sur Reddit et LinkedIn est cohérent : un « tueur de frontier bon marché » qu'on peut utiliser pour le coding quotidien. Nate Herkelman a résumé l'ambiance dans un post LinkedIn : « GLM 5.2 dans Claude Code me souffle l'esprit (5x moins cher). »
Mais « bon marché » mérite un astérisque, et c'est un point important pour la budgétisation. GLM-5.2 est un raisonneur lourd : il brûle beaucoup de tokens de sortie pour réfléchir, surtout en mode effort Max. Ainsi, sur une API facturée au token, la facture peut grimper plus vite que le tarif affiché ne le suggère si vous ne surveillez pas le niveau d'effort. Le forfait à prix fixe existe précisément pour rendre ce coût prévisible, ce qui nous amène à la question d'accès.
Trois façons d'exécuter GLM-5.2 pour votre entreprise
Il n'y a pas un seul chemin « GLM-5.2 pour les entreprises », il y en a trois, et ils conviennent à des équipes très différentes.

| Voie d'accès | Prix | Idéal pour |
|---|---|---|
| API Z.ai (paiement au token) | 1,40 $ entrée / 4,40 $ sortie par million | L'intégrer dans sa propre appli ou son agent ; usage mesuré |
| OpenRouter / agrégateurs | à partir de 1,20 $ entrée / 4,10 $ sortie par million | Même modèle via des fournisseurs routés, souvent légèrement moins cher |
| GLM Coding Plan, Lite | 18 $/mois (12,60 $/mois annuel) | Coding léger dans Claude Code et plus de 20 outils |
| GLM Coding Plan, Pro | 72 $/mois (50,40 $/mois annuel) | Développement quotidien sur des repos de taille moyenne, 5x usage Lite |
| GLM Coding Plan, Max | 160 $/mois (112 $/mois annuel) | Grands repos, utilisation intensive, 20x usage Lite |
| Auto-hébergement (poids ouverts) | Gratuit (MIT), plus le matériel | Contrôle total des données, environnements réglementés ou isolés |
L'API paiement au token est le moyen le plus rapide d'intégrer GLM-5.2 dans votre propre produit, et elle est livrée avec des endpoints compatibles OpenAI et Anthropic, de sorte que vous pouvez pointer Claude Code ou un harnais similaire directement dessus. Le GLM Coding Plan est la voie à prix fixe pour les développeurs qui vivent dans un outil de coding et souhaitent une facture mensuelle prévisible plutôt que mesurée.
L'auto-hébergement est le plus surestimé. Oui, les poids sont gratuits et sous licence MIT, ce qui est vraiment important pour les secteurs réglementés. Mais un modèle à 753 milliards de paramètres n'est pas quelque chose qu'on fait tourner sur un GPU libre. Comme l'a formulé un développeur sur r/LocalLLaMA, l'« empreinte massive de 753B signifie qu'aucun d'entre nous ne peut le faire tourner chez soi sans un cluster d'entreprise ». De façon réaliste, vous regardez un serveur multi-GPU, de l'ordre de 150 000 $ de matériel, avant les compromis de quantification qui le font ramper. Pour la plupart des entreprises, « auto-héberger » signifie vraiment « l'héberger chez un fournisseur cloud de confiance », pas « le faire tourner au bureau ».
Où GLM-5.2 s'intègre, et où je serais prudent
Assemblez les pièces et le tableau est assez clair. Pour les travaux d'ingénierie internes, GLM-5.2 est un oui facile pour au moins un essai : coding agentique, refactorisations, longues sessions de débogage, recherche automatisée sur une grande base de code. La qualité est là, le prix est une fraction des alternatives, et si vous êtes sensible aux coûts, c'est difficile à contester. Si votre mix de tâches est plus simple, il vaut la peine de comparer les prix avec DeepSeek, qui est encore moins cher pour le travail de routine.
Là où je freinerais, c'est tout ce qui est en contact avec les clients, et c'est la partie que les benchmarks ne couvrent pas.

Trois choses me rendent prudent quant à pointer un modèle brut, n'importe quel modèle brut, vers des clients réels :
- Résidence des données. GLM-5.2 est un modèle open-weights d'un laboratoire basé en Chine, et Z.ai a été ajouté à la Liste des entités du Département du Commerce américain en 2025. Les poids ouverts sont en réalité la solution ici, pas le problème : vous pouvez auto-héberger ou passer par un fournisseur audité pour que les données des clients ne touchent jamais l'API officielle. Mais c'est une décision à prendre délibérément. Certaines équipes soulèvent le point de la vie privée avec insistance, et elles n'ont pas tort.
- Fiabilité. L'« odeur de grand modèle » est réelle, et des scores de coding impressionnants ne signifient pas qu'un modèle n'inventera pas avec confiance une politique de remboursement. Le chercheur en sécurité Zack Korman a signalé que GLM-5.2 « semble être très bon dans les évasions et contournements de sandbox d'agents IA », ce qui est exactement le genre de chose qu'on veut savoir avant qu'il ait accès aux outils de vos systèmes. L'hallucination sur un vrai ticket est un problème de confiance, et c'est pourquoi nous simulons chaque déploiement sur des tickets historiques avant de passer en production.
- Latence et contrôle des coûts. Cette caractéristique de raisonnement lourd qui rend GLM-5.2 excellent en coding le rend plus lent et plus coûteux par réponse en effort
Max, ce qui compte quand un client attend.
Aucun de ces éléments n'est rédhibitoire. Ce sont simplement les différences entre « le modèle a obtenu de bons résultats » et « je le mettrais devant mes clients demain ». La solution n'est pas un meilleur modèle, c'est la couche qui l'entoure.
Utiliser GLM-5.2 (ou n'importe quel modèle) pour le support : la méthode eesel
Voici ce à quoi je reviens sans cesse après des années à faire tourner de l'IA sur des files d'attente de support : le harnais importe plus que le modèle. Le même point ressort de la communauté : les gens constatent régulièrement qu'un modèle moins capable dans un meilleur environnement surpasse un plus puissant dans un moins bon. Ce qui décide des résultats sur de vrais tickets, c'est si l'IA est ancrée dans vos connaissances, si vous contrôlez quand elle répond, et si vous l'avez testée avant qu'elle aille en production. C'est la même leçon qui distingue un vrai agent de support IA d'un chatbot basé sur des règles.
C'est ce qu'est eesel. C'est une couche auditée qui se pose au-dessus de n'importe quel modèle qui est le meilleur, apprend de vos tickets passés et de vos documents d'aide, et répond uniquement quand elle est sûre — le reste étant transmis à un humain. Avant que quoi que ce soit ne parte en production, vous le faites tourner en simulation sur des milliers de vos vrais tickets historiques pour voir exactement comment il aurait répondu, de sorte que vous ne le découvrez pas en production. C'est la partie qu'une clé d'API GLM-5.2 brute ne vous donne pas, et c'est là que réside la majeure partie du vrai risque — le même écart qui tranche la question du build versus achat pour l'IA de support.

Mon avis honnête : soyez enthousiasmé par GLM-5.2 pour vos ingénieurs et testez-le pour le coding cette semaine. Pour les aspects en contact avec les clients, faites du modèle une pièce interchangeable et concentrez votre énergie sur la couche qui le rend sûr à déployer. Vous pouvez essayer eesel gratuitement et le simuler sur vos propres tickets avant de dépenser un centime — c'est la seule façon dont j'évaluerais si un modèle est prêt pour votre entreprise. Si vous évaluez le coût global du support IA, c'est le chiffre qui compte vraiment.
Questions fréquemment posées
GLM-5.2 est-il suffisamment bon pour un usage professionnel ?
Combien coûte GLM-5.2 pour les entreprises ?
Est-il sécurisé d'utiliser GLM-5.2 avec des données d'entreprise ?
Puis-je utiliser GLM-5.2 pour le support client ?
GLM-5.2 est-il meilleur que DeepSeek ou GPT-5.5 pour les entreprises ?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.