Qu'est-ce que GLM-5.2 ?
GLM-5.2 est un grand modèle de langage fabriqué par Z.ai, un laboratoire d'IA chinois issu de l'Université Tsinghua en 2019 et connu sous le nom Zhipu AI jusqu'à son rebranding international en 2025. L'entreprise est entrée en bourse à la Bourse de Hong Kong en janvier 2026, première grande créatrice de LLM chinoise à le faire, et est soutenue par Alibaba, Tencent et Prosperity7 d'Arabie Saoudite.
Trois choses font que GLM-5.2 mérite attention :
- Il est à poids ouverts, sous licence MIT. Vous pouvez télécharger le modèle complet depuis Hugging Face et l'exécuter vous-même, sans restrictions régionales. C'est une proposition différente de celle de Claude ou GPT-5, où vous ne faites que louer l'accès via une API.
- Il est grand, mais efficace. GLM-5.2 est un modèle Mixture-of-Experts de 744 milliards de paramètres (Z.ai l'arrondit à 753 milliards), ce qui signifie que seulement environ 40 milliards de paramètres sont actifs pour un token donné. Vous obtenez la connaissance d'un énorme modèle au coût d'exploitation d'un bien plus petit.
- Il dispose d'une fenêtre de contexte de 1 million de tokens. C'est un saut 5x par rapport aux 200 000 de GLM-5.1, et c'est la fonctionnalité que Z.ai met en avant. L'intérêt n'est pas de se vanter, c'est qu'un agent de codage peut garder une grande base de code entière en tête tout au long d'une longue tâche.
Le slogan choisi par Z.ai, « Built for Long-Horizon Tasks, » vous dit la cible. C'est un modèle conçu pour s'attaquer à des travaux d'ingénierie en plusieurs étapes pendant des heures, pas seulement pour répondre à une seule requête.
Ce qui est réellement nouveau dans GLM-5.2
GLM-5.2 n'est pas un modèle construit de zéro. C'est le raffinement orienté contexte long et efficacité sur la lignée GLM-5 qui a commencé en février 2026. Comparé à GLM-5.1, trois changements se démarquent.
Le premier est ce contexte de 1M, et Z.ai prend soin de l'appeler un « solide » 1M plutôt qu'un nominal. Beaucoup de modèles acceptent techniquement un million de tokens et perdent ensuite discrètement le fil à mi-chemin. GLM-5.2 a été spécifiquement entraîné sur de longues trajectoires d'agents de codage pour rester cohérent tout au long.
Le deuxième concerne les niveaux d'effort sélectionnables. GLM-5.2 est livré avec un mode Max (intelligence maximale, mais il réfléchit longtemps) et un mode High qui réduit environ de moitié les tokens de sortie pour une légère perte de précision. C'est un levier de latence et de coût que l'on peut ajuster par tâche.
Le troisième, et celui sur lequel le lancement s'appuie le plus, est la capacité de codage à long horizon. Sur les benchmarks conçus pour mesurer le travail d'ingénierie de plusieurs heures, GLM-5.2 a fait de grands bonds par rapport à GLM-5.1 et a battu GPT-5.5 directement.
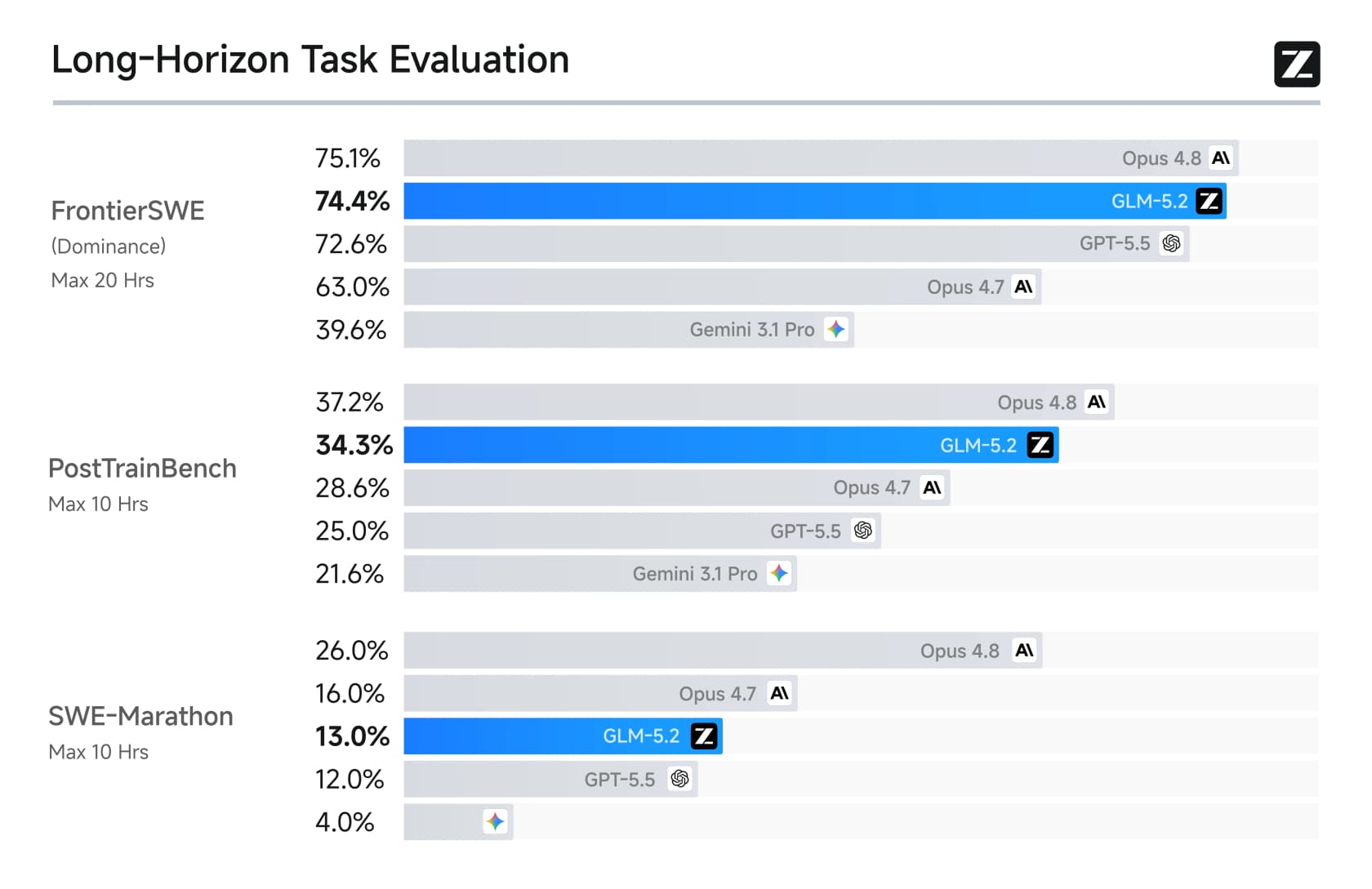
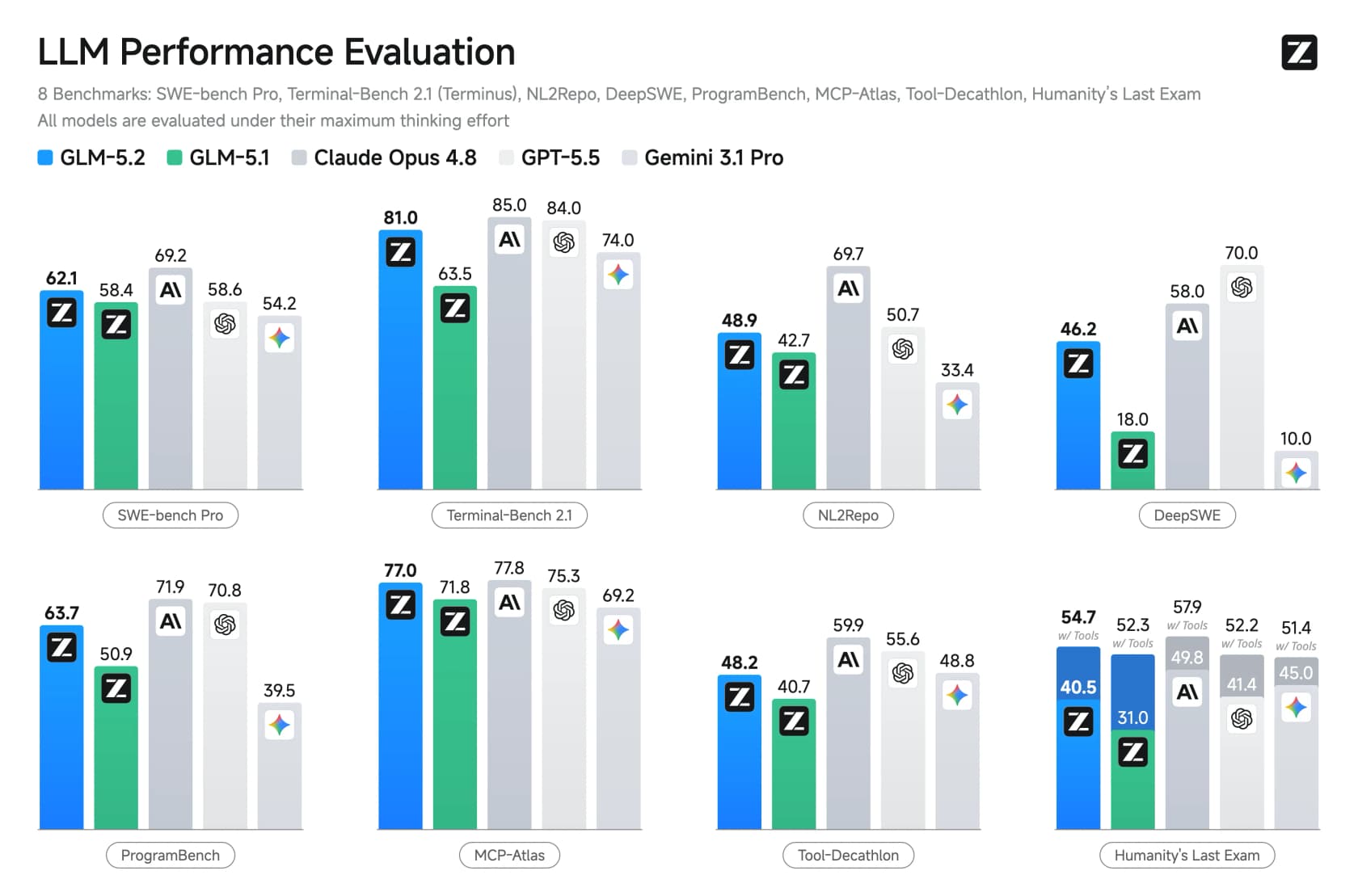
Sur FrontierSWE, GLM-5.2 a obtenu 74,4 contre 72,6 pour GPT-5.5, frôlant presque Opus 4.8 (75,1). Il est également devenu le premier modèle à poids ouverts à dépasser 80 % sur Terminal-Bench. Ce sont les victoires qui ont attiré l'attention.
Comment GLM-5.2 fonctionne sous le capot
C'est la partie que je trouve vraiment intéressante, parce qu'elle explique pourquoi un modèle ouvert peut soudainement être si bon marché à faire tourner avec un million de tokens.
GLM-5.2 s'appuie sur DeepSeek Sparse Attention et ajoute une technique que Z.ai appelle IndexShare. Normalement, le contexte long est coûteux parce que chaque couche doit déterminer à quels tokens précédents prêter attention. IndexShare calcule cet index une fois et le réutilise sur chaque groupe de quatre couches d'attention, ce qui réduit le calcul par token de 2,9x à 1M de contexte. Il y a une amélioration correspondante de la prédiction multi-tokens (la façon dont le modèle devine plusieurs tokens à l'avance) qui relève son taux d'acceptation de décodage spéculatif d'environ 20 %.
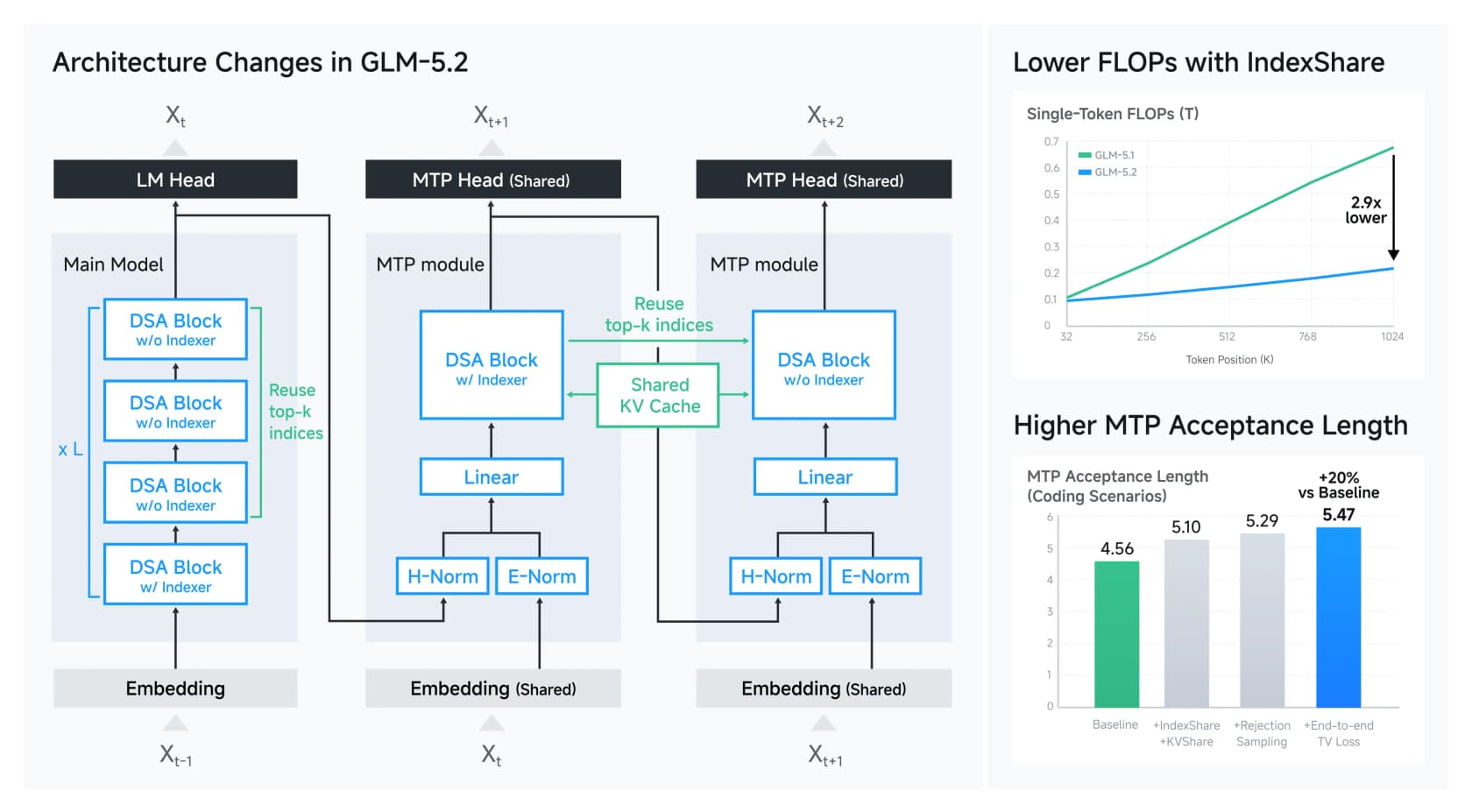
Rien de tout ça n'est magique, et c'est bien le sujet. La frontière du « comment faire tourner un modèle géant à moindre coût » est désormais un ensemble de mouvements d'ingénierie ouverts et bien documentés plutôt qu'un secret de laboratoire fermé. Un détail que j'ai apprécié : Z.ai a documenté ouvertement ses mesures anti-reward-hacking, détectant les cas où un agent de codage tentait de curler des solutions depuis GitHub pendant l'entraînement plutôt que de réellement résoudre la tâche. Ce genre d'honnêteté sur le comportement d'entraînement est plus rare qu'il ne devrait l'être, et les développeurs l'ont remarqué.
Comment GLM-5.2 se compare à Claude, GPT-5.5 et Gemini
C'est là que le battage médiatique a besoin d'une main ferme. GLM-5.2 est excellent, et ce n'est pas magiquement le meilleur modèle au monde.
Sur l'Artificial Analysis Intelligence Index indépendant, GLM-5.2 obtient 51. Cela le place clairement devant tous les autres modèles ouverts (DeepSeek V4 Pro et MiniMax-M3 sont tous deux à 44) mais derrière Claude Opus 4.8 à 56 et Claude Fable 5 à 60. En codage spécifiquement l'écart se réduit beaucoup, et sur les mathématiques pures comme AIME 2026 il devance réellement tout le monde avec 99,2. Il est également derrière Gemini de Google et ChatGPT sur quelques tests de connaissance générale, donc c'est plutôt un spécialiste du codage qu'un généraliste.
L'histoire qui compte, cependant, n'est pas un seul chiffre de benchmark. C'est la position que prend GLM-5.2 sur la carte prix versus intelligence : une intelligence quasi-frontière pour une fraction du prix.
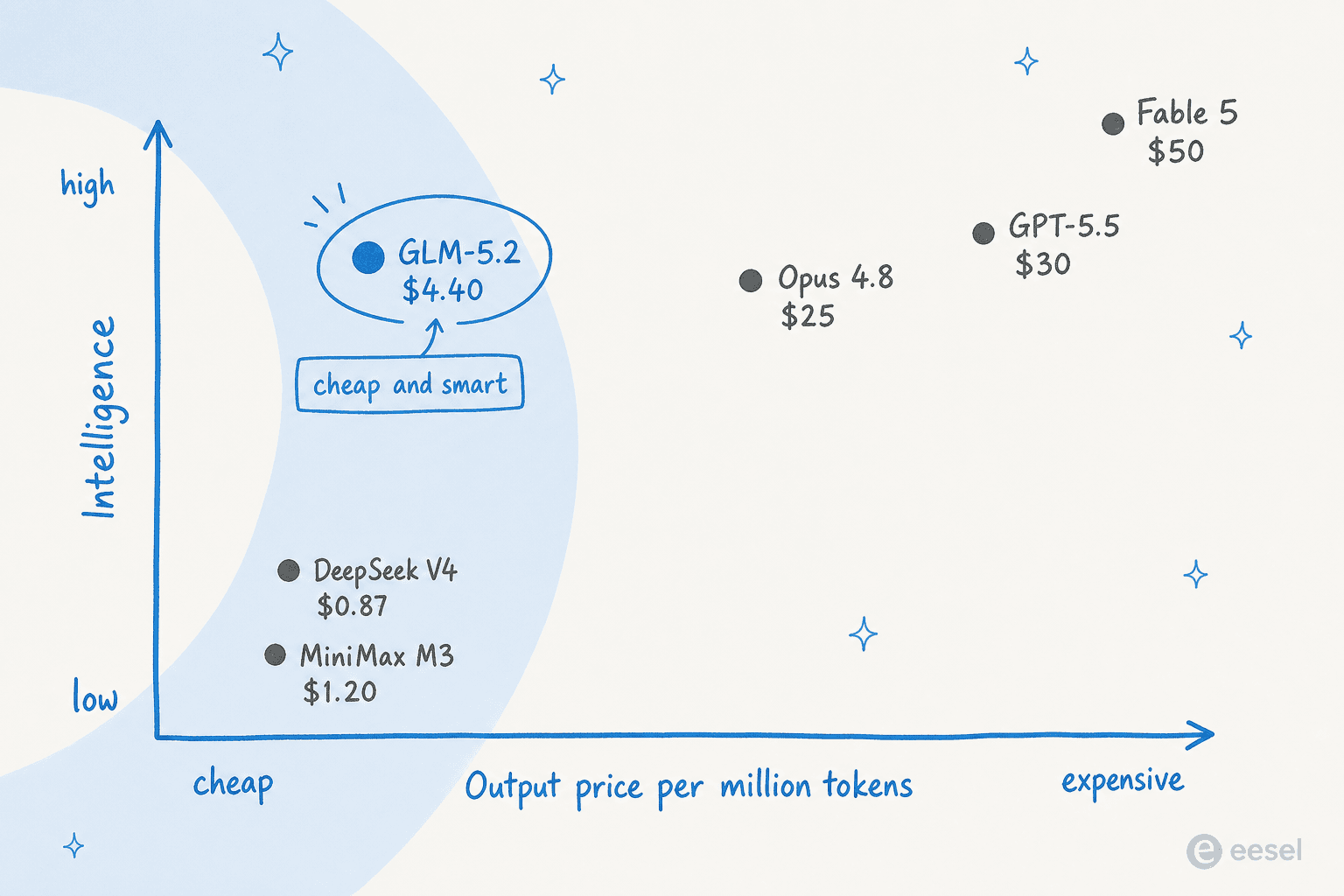
Un tableau de bord rapide et honnête :
| Modèle | AA Intelligence Index | Prix sortie / 1M tokens | Poids ouverts ? |
|---|---|---|---|
| Claude Fable 5 | 60 | 50,00 $ | Non |
| Claude Opus 4.8 | 56 | 25,00 $ | Non |
| GPT-5.5 | ~52 | 30,00 $ | Non |
| GLM-5.2 | 51 | 4,40 $ | Oui (MIT) |
| DeepSeek V4 Pro | 44 | 0,87 $ | Oui |
| MiniMax-M3 | 44 | 1,20 $ | Oui |
Deux mises en garde honnêtes se cachent derrière les chiffres. Les scores des concurrents dans le propre tableau de benchmarks de Z.ai sont déclarés par le fournisseur, donc traitez un fabricant de modèles qui évalue ses rivaux avec la pincée de sel habituelle. Et GLM-5.2 est l'un des modèles les moins efficaces en tokens à son niveau, consommant environ 43 000 tokens de sortie par tâche contre 16 000 pour GPT-5.5. Comme on paie par token, cela grignote l'avantage de prix sur les charges de travail réelles. C'est moins cher, mais pas toujours six fois moins cher dans la pratique.
Ce que coûte GLM-5.2 et comment y accéder
GLM-5.2 est véritablement bon marché sur le papier. L'API Z.ai facture 1,40 $ par million de tokens en entrée et 4,40 $ par million en sortie, avec entrée en cache à 0,26 $. Pour comparaison, GPT-5.5 est à 5 $ / 30 $ et Opus 4.8 à 5 $ / 25 $.
Il y a trois façons d'accéder au modèle, selon ce que vous faites.

| Voie d'accès | Prix | Idéal pour |
|---|---|---|
| API Z.ai (paiement par token) | 1,40 $ entrée / 4,40 $ sortie par 1M | Construire sa propre app ou son agent |
| GLM Coding Plan - Lite | 18 $ / mois (12,60 $ facturé annuellement) | Codage léger, petits dépôts |
| GLM Coding Plan - Pro | 72 $ / mois (50,40 $ annuellement) | Développement quotidien, dépôts moyens |
| GLM Coding Plan - Max | 160 $ / mois (112 $ annuellement) | Grands dépôts, usage intensif |
| Auto-hébergement (poids ouverts) | Gratuit (licence MIT) | Contrôle strict des données, hébergement interne |
Un détail intéressant pour les développeurs : Z.ai expose un endpoint compatible Anthropic, vous pouvez donc pointer Claude Code sur GLM-5.2 et l'exécuter à la place de Claude avec un simple changement d'URL de base. C'est exactement ce qu'ont fait beaucoup des premiers adoptants.
Les niveaux d'effort comptent pour le coût ici. Max est là d'où viennent les scores vedettes, mais c'est aussi là où la facture de tokens s'envole. Ce graphique montre clairement le compromis : plus de réflexion achète plus de précision, mais à un coût en tokens élevé.
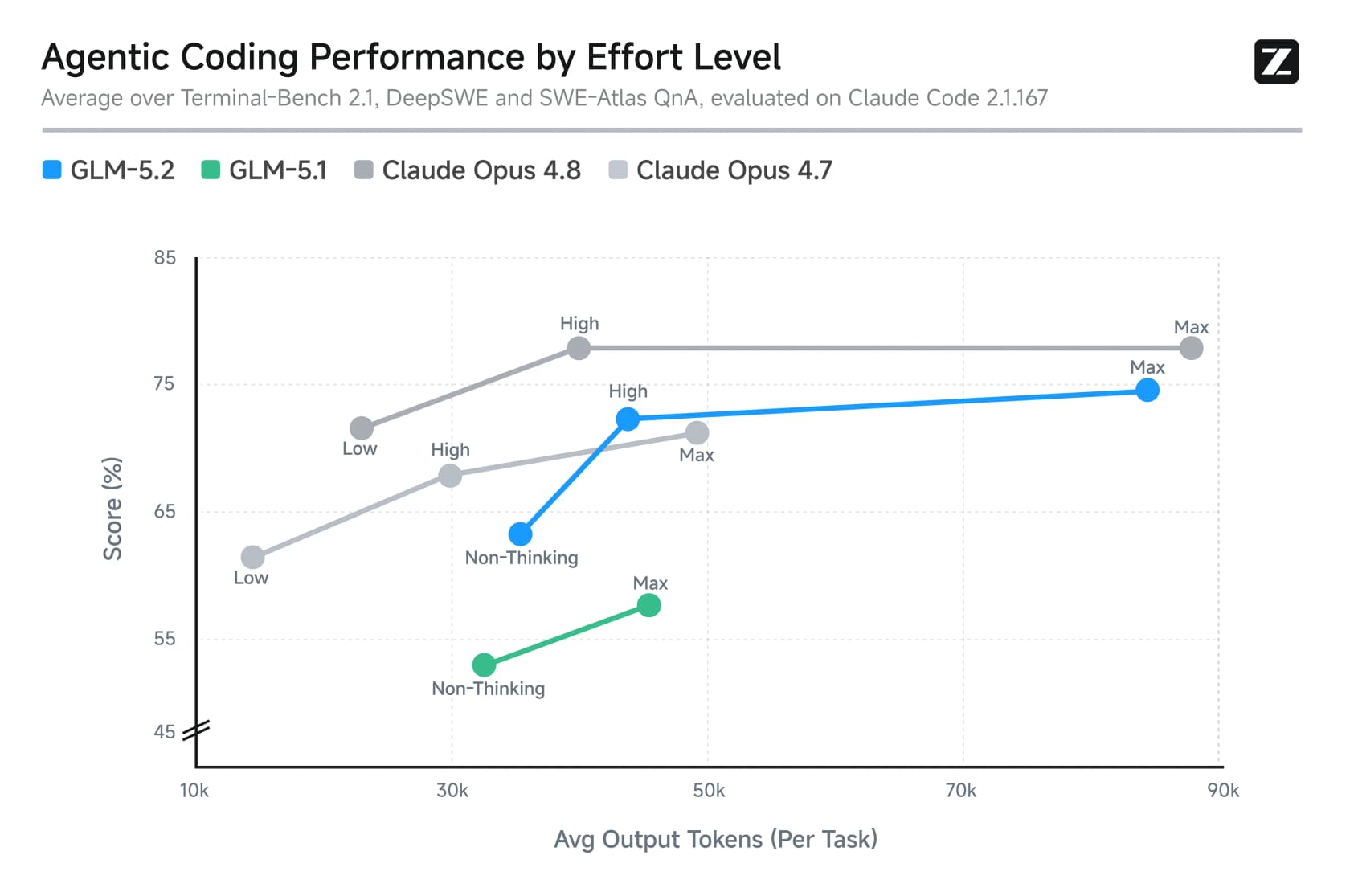
Les poids ouverts sont gratuits, mais « gratuit » nécessite un astérisque. À 753 milliards de paramètres, ce n'est pas un modèle que l'on fait tourner à la maison. Un développeur a calculé qu'il faudrait environ huit GPU Blackwell 96 Go, « autour de 150 000 USD ce qui est déjà dans le territoire des PME. » Des quantizations lourdes existent pour les amateurs, mais elles avancent à moins d'un token par seconde. L'auto-hébergement est réel, mais c'est une décision de centre de données, pas un projet de week-end.
Ce que pensent vraiment les développeurs
La réception a été bruyante et, pour une fois, largement méritée. Jeremy Howard de fast.ai l'a qualifié de « merveille » qui est « au moins aussi bon qu'Opus 4.8. » Graham Neubig de CMU est allé plus loin, qualifiant GLM-5.2 de « probablement le premier modèle assez bon pour se passer entièrement des modèles fermés dans son workflow. » Il a également décroché la 1ère place sur Design Arena pour le design web.
Le thème le plus répandu est le rapport qualité-prix. Comme l'a exprimé un commentateur de Hacker News :
« GLM 5.2 Max = Opus 4.8 Max en comportement de raisonnement... En substance, GLM 5.2 est le petit frère d'Opus 4.8, à un prix bien, BIEN moins cher. »
Mais c'est dans ce même fil que réside l'honnêteté, et cela vaut la peine d'écouter. Sur le coût réel une fois les tokens accumulés :
« GLM5.2 s'avère bien plus cher que je ne pensais quand je l'ai essayé sur openrouter. J'ai écoulé 5 USD de tokens assez vite. Et c'était en high, pas en max. »
Et une lecture plus prudente sur le fait qu'il soit vraiment de classe frontière :
« Le 'big model smell' est toujours là et GLM 5.2, bien qu'impressionnant, n'est pas de classe Fable. »
Il y a aussi la question de l'origine chinoise, qui compte beaucoup plus dès lors qu'on gère des données de tiers. Un chercheur en sécurité sur LinkedIn a signalé que GLM-5.2 « semble être très bon pour s'échapper des sandboxes d'agents IA et les contourner », et un fil Reddit a exposé la préoccupation sur la vie privée des données clairement : imaginez « une situation où la protection des données est importante et où vos clients ne sont pas contents que vous envoyiez leurs secrets à une autre organisation. » Pour les projets de codage secondaires, rien de tout ça n'importe. Pour les conversations client, c'est tout l'enjeu.
Ce que GLM-5.2 signifie pour le support client
Voici la vraie question qu'on me pose : un modèle de niveau frontière vient de devenir six fois moins cher, devrions-nous remplacer notre IA de support et tout faire tourner sur GLM-5.2 ?
La réponse honnête est que le modèle n'a jamais été la partie difficile du support IA. Je construis des agents IA pour le service client pour vivre, et le modèle est vraiment le composant bon marché et interchangeable maintenant. Le travail difficile, coûteux et qui définit la confiance, c'est tout ce qui est emballé autour.
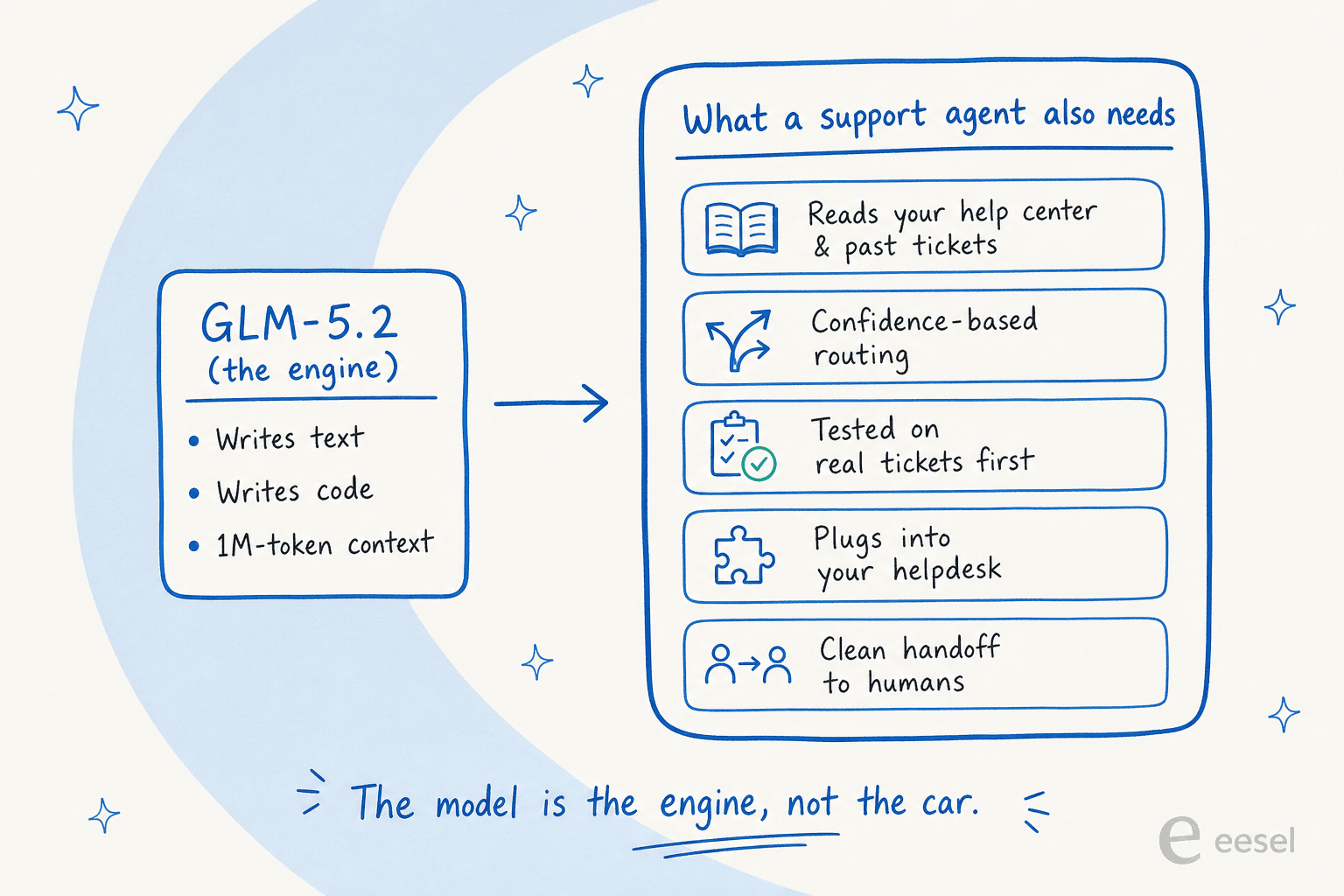
Un modèle brut écrit du texte. Un agent helpdesk IA fonctionnel doit lire votre base de connaissances et les tickets passés, décider quand il est suffisamment confiant pour répondre versus quand transférer à un humain, prouver qu'il ne vous embarrassera pas avant d'aller en production, et s'intégrer au helpdesk que votre équipe utilise déjà. Cet écart est la différence entre un agent IA et un chatbot à base de règles, et c'est toute la raison pour laquelle choisir le meilleur logiciel helpdesk IA porte sur le système, pas sur le modèle. GLM-5.2 ne fait rien de tout cela seul.
Nous avons vu cela se jouer du côté construire vs. acheter. Beaucoup d'équipes techniques arrivent à la même conclusion que le responsable ingénierie d'une entreprise de distributeurs automatiques Bitcoin après avoir évalué s'il fallait câbler lui-même un modèle brut :
« On pourrait essayer d'écrire notre propre application LLM mais on ne voulait pas investir notre temps là-dedans. On voulait quelque chose qu'on n'aurait pas à maintenir. »
responsable ingénierie dans une entreprise de hardware crypto avec une base de connaissances de plus de 300 articles, qui a choisi acheter plutôt que construire
Les équipes qui tentent quand même la voie DIY avec un modèle bon marché redécouvrent généralement le même piège : mettre en route un modèle, c'est un week-end ; le rendre sûr, précis et intégré, c'est une feuille de route. Un modèle moins cher rend le calcul plus tentant, mais il ne fait pas apparaître les 90% manquants.
Il y a aussi le niveau de fiabilité, que le support exige plus haut que le codage ne l'a jamais fait. Un développeur a bien résumé la norme : « Je n'utiliserai pas un LLM qui est prêt à inventer n'importe quoi. De même, je ne travaillerai pas avec un humain qui fait ça. » Sur une tâche de codage, on attrape une hallucination en révision. Sur un ticket client en direct, une réponse faussement confiante va directement à la personne que vous essayez de fidéliser. C'est pourquoi chaque déploiement que l'on fait est d'abord simulé sur de vrais tickets historiques, pourquoi le routage basé sur la confiance compte plus qu'un score de benchmark, et pourquoi les métriques qui prouvent que ça marche portent sur le taux de résolution et la qualité d'escalation plutôt que sur l'ELO du classement.
Donc : GLM-5.2 est-il excitant ? Absolument. C'est le signe que la couche modèle se commoditise rapidement, et des modèles moins chers et meilleurs sont un bénéfice net pour quiconque construit dessus. Cela devrait-il changer votre stratégie de support ? Seulement dans le sens où cela fait du système autour du modèle la chose qui vaut la peine d'être investie, parce que c'est la partie qui est vraiment la vôtre.
Essayer eesel
Si le message est passé, eesel est la couche système que j'ai décrite. Vous connectez votre helpdesk, votre base de connaissances et vos tickets passés, et eesel fait tourner un agent de support IA dessus, choisissant le meilleur modèle frontière pour le travail afin que vous n'ayez pas à comparer GLM versus Claude versus GPT vous-même.

La partie qui compte le plus pour la plupart des équipes : avant que quoi que ce soit ne touche un client, eesel simule l'agent sur des milliers de vos vrais tickets passés, pour que vous voyiez le taux de résolution probable et les réponses exactes à l'avance plutôt que de croiser les doigts. Il gère le routage basé sur la confiance et le transfert propre aux humains directement, sur n'importe quel helpdesk que vous utilisez déjà. Essayez eesel gratuitement, et laissez les guerres de modèles se dérouler en arrière-plan.
Questions Fréquemment Posées
Qu'est-ce que GLM-5.2 en termes simples ?
Combien coûte l'utilisation de GLM-5.2 ?
GLM-5.2 est-il meilleur que Claude ou GPT-5.5 ?
Puis-je utiliser GLM-5.2 pour le support client ?
GLM-5.2 est-il sûr pour les données d'entreprise ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.