So, can AI actually do support QA?
Short answer: yes, and better than the manual version on the one dimension that matters most, coverage.
I build the AI agents that do this, so let me be precise about what "yes" means. Traditional support QA is an analyst pulling a handful of tickets per agent per week, scoring them in a spreadsheet, and moving on. If your team handles a few thousand conversations a month, that's a review of maybe 2% of them, and a biased 2% at that, because reviewers gravitate toward the tickets that are easy to score. The weird edge case that quietly churned a customer almost never makes the sample.
AI flips that. Once a model reads every conversation against your rubric, scoring 100% of conversations costs roughly the same effort as scoring 2%. Coverage stops being the thing you ration. The catch is that "reads everything" and "judges everything correctly" are two different claims. AI nails the first. The second is where you keep a human in the loop.
What AI does well (and the proof)
Here's where AI QA is genuinely strong, and I'd rather show you real numbers than adjectives.
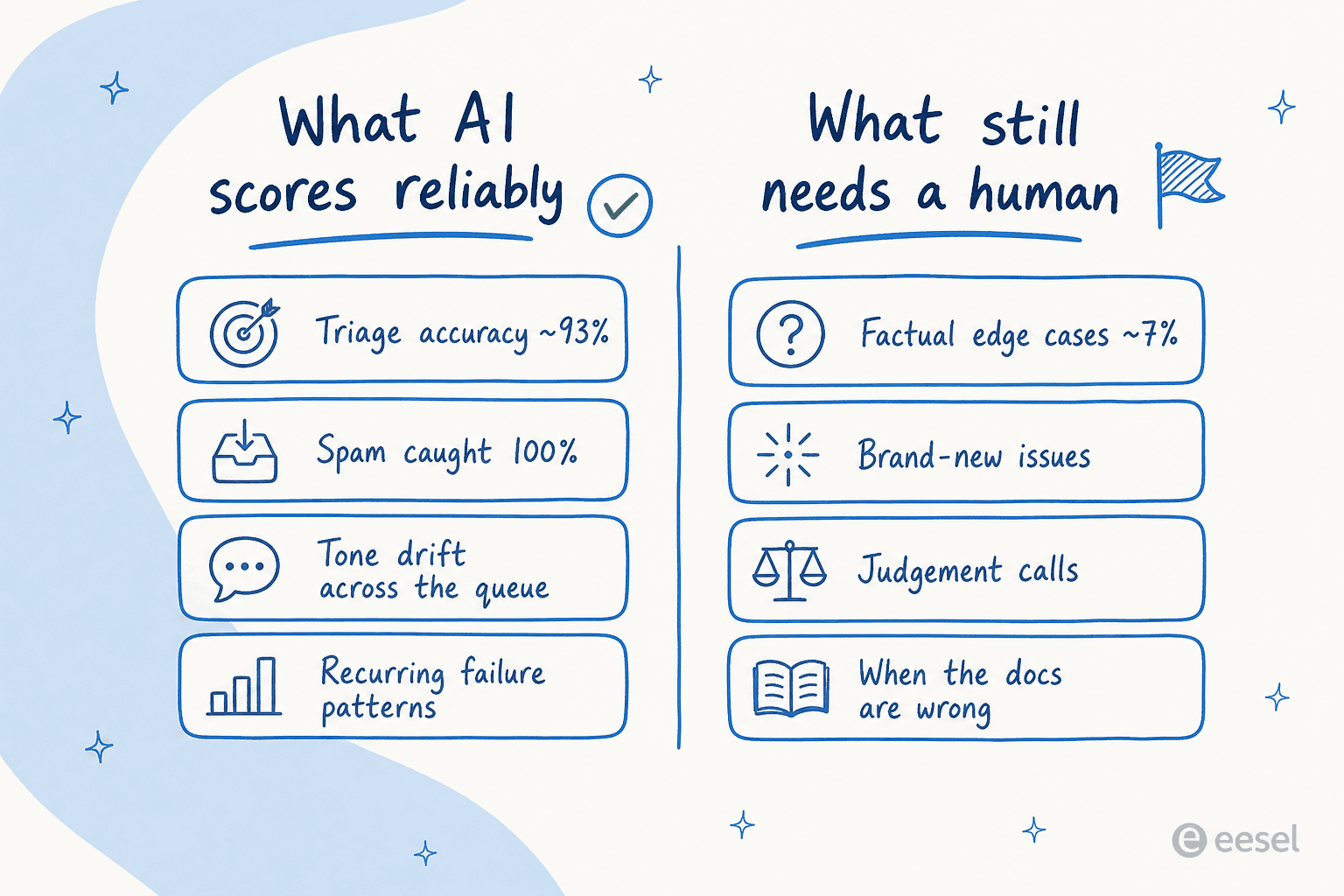
When we ran an agent against one customer's actual Zendesk traffic, it scored about 93% on triage accuracy and caught 100% of spam with zero false positives, on an inbox that was 22% spam. Category by category it was sharper still: useful drafts on returns and refunds 93.8% of the time, warranty claims 96.4%, product inquiries and refund-status lookups 100%. Those are the repetitive, pattern-heavy tickets that QA exists to keep consistent, and a model that has read your history is excellent at spotting where an answer drifts off the pattern.
The same strength applies to your humans. AI is very good at the things a tired reviewer misses: tone that slips on refunds, a policy that one agent keeps getting subtly wrong, a topic where every answer scores low because the underlying help doc is stale. Those are patterns, and patterns are what a model reading the whole queue finds that a 2% sample structurally can't. It also never gets bored on ticket 4,000, which is more than I can say for any human QA shift.
How AI actually scores a conversation
This is the part people imagine is some black box, and it really isn't. The mechanism is the same rubric a human reviewer would use, just applied to everything.
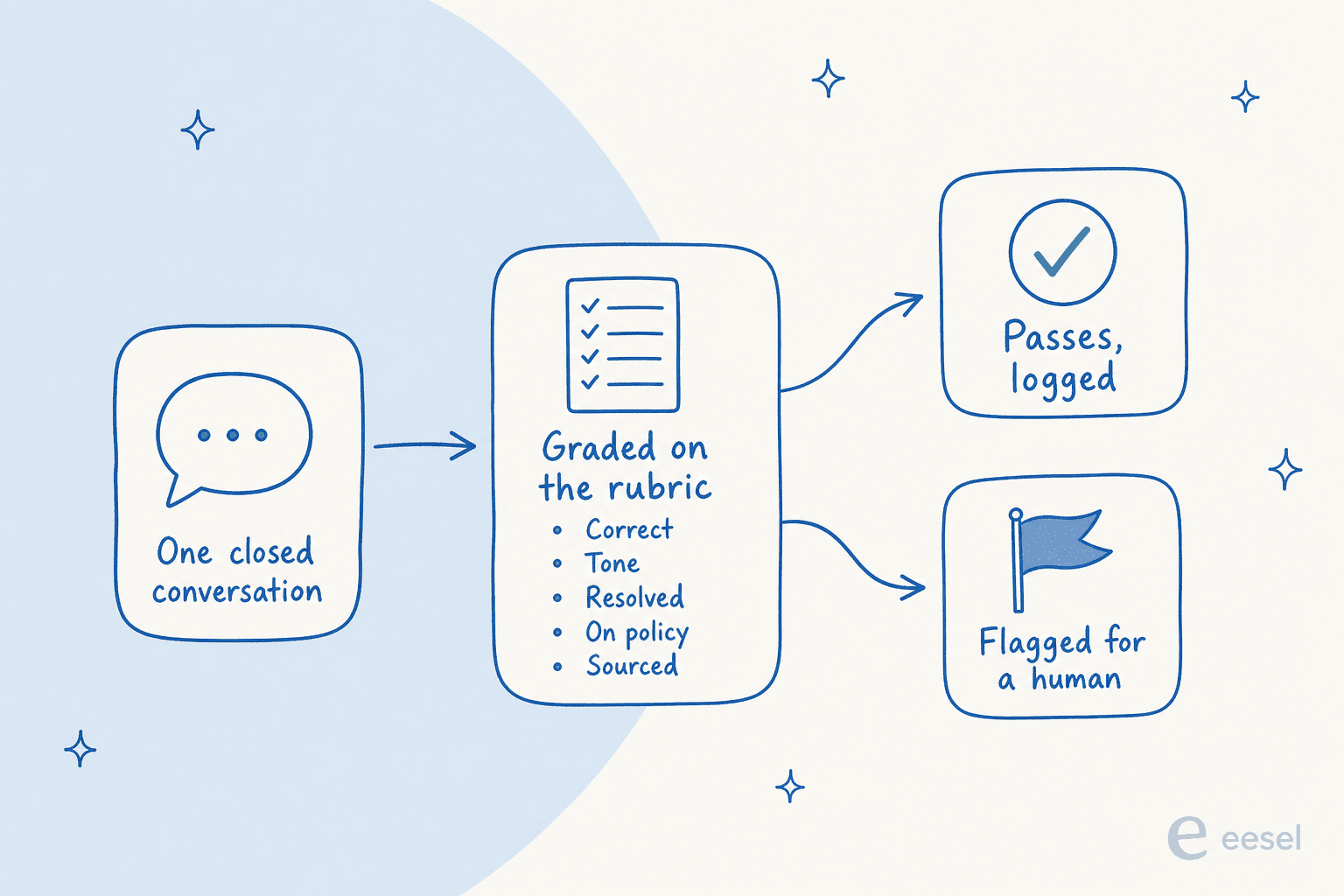
A closed conversation goes in. The AI grades it on a handful of explicit dimensions: was it factually correct, was the tone right, did it actually resolve the issue, did it follow policy, and did it cite a real source instead of making something up. Conversations that pass get logged; the ones that score low get flagged for a person to look at. The output you want isn't one number, it's a breakdown you can trend, so you can see that this batch all failed on the same policy or that one topic is dragging your scores down.
Two things make or break this. First, the rubric has to be explicit, no "you'll know it when you see it." Five sharp dimensions beat thirty fuzzy ones, for the AI and for the human. Second, you have to feed it both the conversations and the knowledge base the answer should have come from. A score of "wrong" is only useful if you know whether the agent was wrong or the docs were, and that distinction is the difference between coaching a person and rewriting an article. If you want the full build, we wrote a step-by-step on doing support QA with AI.
Where AI QA still needs a human
Now the honest other half, because a QA post that only lists strengths is exactly the kind of thing AI QA is supposed to catch.
Go back to that audit. The agent's drafts were directionally right 88% of the time, but only 12% were good enough for an agent to send as-is, and there was a 7% factual error rate. Dig into the gap and it's revealing: about 65% of the rewrites were just length and tone (the AI wrote eight sentences where the team sends three), around 20% needed data the AI couldn't see (an ERP or logistics lookup), and only about 5% were the AI being flat-out wrong. So most of what "needs a human" is fixable with better training, but that last sliver of factual error is the part you never automate away entirely.
The sharpest example I've watched: a team's AI confidently told customers "yes, we support your model" for products that weren't actually in their database, because the help center said "we support all models." The AI wasn't hallucinating, it was faithfully repeating a doc that was wrong. No amount of model quality catches that on its own. A human reading the flagged pattern catches it in five minutes. That's the real division of labour in AI vs human support: the AI reads everything and surfaces the suspicious pattern, a person decides what it means and fixes the root cause.
So the things to keep a human on: novel issues with no precedent in your history, judgement calls like a goodwill exception, anything that depends on business context that lives in someone's head rather than your docs, and the periodic calibration of the AI's own scores. Treat the AI's grade as a second analyst's opinion, not a final ruling, and you get the coverage without the blind spots.
The test most teams skip: can AI QA itself?
Here's the bit most "AI for QA" pieces breeze past, and it's the one I care about most. If you're going to let AI handle tickets, that AI has to pass QA before it touches a customer, and most teams never run that check.
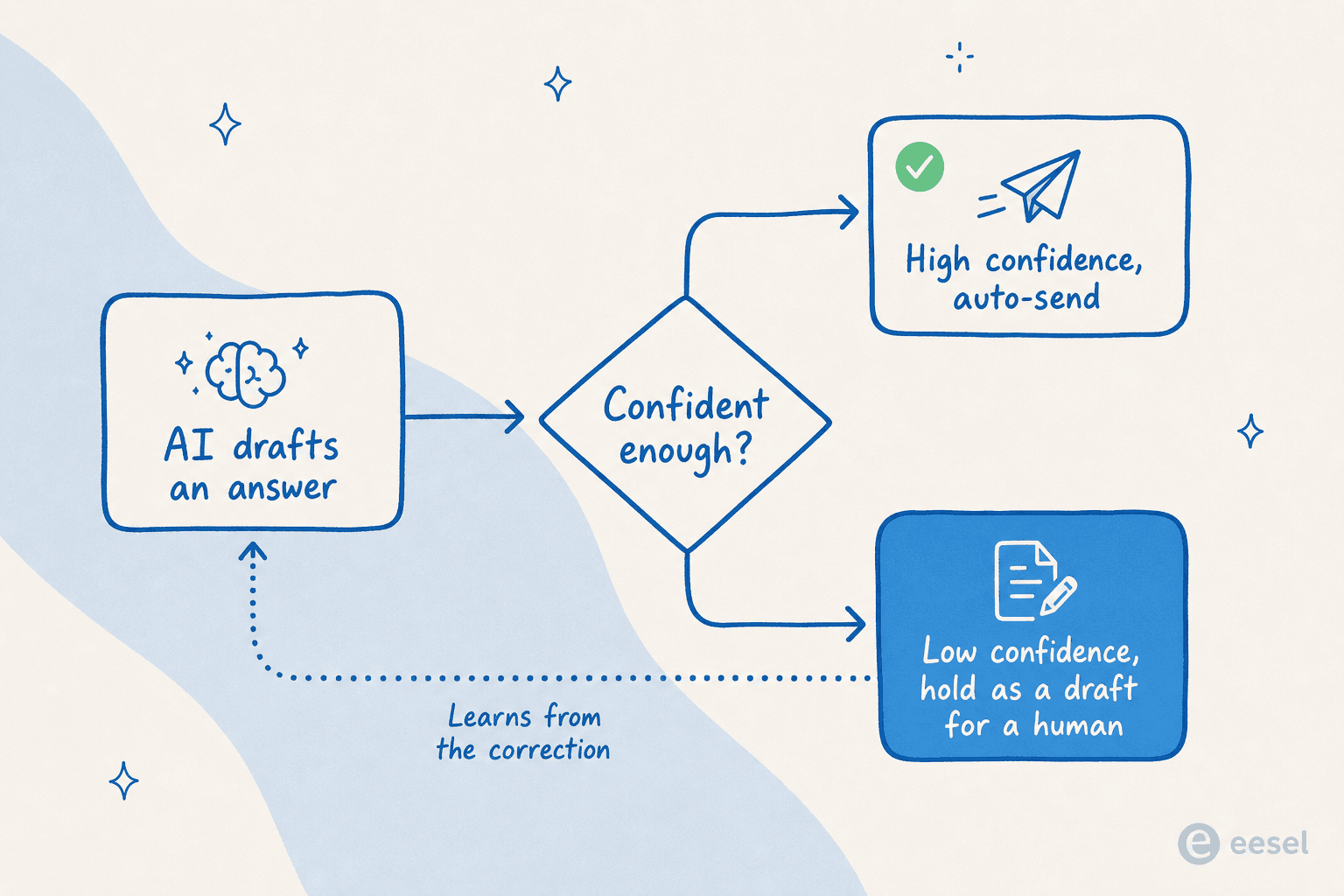
The mechanism is confidence-based routing. The agent only auto-sends answers it's confident about; anything below the threshold it holds as a draft for a human, and it learns from the correction so the same miss stops repeating. One DTC supplements lead put the stakes to us perfectly: an AI that answers "sorry, I don't know" to everything is useless, but an AI that guesses is worse, "because nobody can re-read 7,000 tickets to catch the guesses." QA is the answer to both.
So we built the check into the rollout. Before an eesel agent goes live, you run it in a simulation against your real past tickets and see its quality and coverage by topic, with no customers involved. That's how we got the 93% and 7% numbers in the first place, on the safe side of the glass. Once it's live, the same scores show up in your agent analytics, so QA on the automation never really stops.

This is also the most honest answer to "can I trust it?" You don't trust it on faith. You QA it, set it to draft rather than auto-send where its confidence is low, and widen its autonomy as the scores earn it. That's the line between a demo and a deployment.
How teams actually use AI QA day to day
In practice it settles into a loop, and the loop matters more than any single score. The AI scores every conversation as it closes. It surfaces the coaching moments a human should look at, grouped by what they have in common, instead of five random tickets. A team lead acts on the patterns: coaching the agents who got flagged, fixing the docs behind the repeat misses, updating the ticket tagging and escalation rules a low-scoring topic exposes. Fix the doc behind a recurring miss and you often reduce ticket volume at the same time.
Tool-wise, you've got two camps. Dedicated QA platforms like Zendesk QA (the product formerly known as Klaus) and MaestroQA auto-score conversations and feed coaching workflows, and they're a solid fit if QA is a standalone function for you. The other camp is AI customer service software that bundles QA in alongside the agent doing the work, so the same engine that scores your team's conversations is the one that QAs the AI's drafts. One last guardrail worth saying out loud: QA is not CSAT. A customer can rate a confidently wrong answer five stars, so you want both your QA scores and your CSAT report, not one standing in for the other.
Try eesel for support QA
If you want AI support QA without bolting three tools together, that's exactly what eesel's AI helpdesk agent is built around. It connects to your existing helpdesk, reads your past conversations and knowledge base, and lets you run a simulation over real historical tickets so you can see quality and coverage before anything goes live.

The useful part for QA is that the same engine scoring an AI agent's drafts is what reads your team's conversations, so QA on humans and QA on automation live in one place instead of two spreadsheets. It plugs in over an afternoon, already knows your help center, and the usage-based pricing doesn't charge you per seat for the privilege of reviewing your own tickets. Free to try.
Frequently Asked Questions
Can AI do support quality assurance accurately?
How does AI support QA actually score a conversation?
What can't AI do in support quality assurance?
How much of my support volume can AI QA cover?
Can AI QA an AI support agent too?
Does AI support QA replace my QA analysts?
What tools can do AI support quality assurance?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.