MiniMax M3とは?
MiniMax M3は汎用の大規模言語モデルで、MiniMaxは「MSAという新しいアテンションアーキテクチャに基づき、1Mコンテキストを持つフロンティアコーディング・エージェントモデル」と説明しています。以前のM2ライン(M2、M2.1、M2.5、M2.7)の後継であり(M2ラインも引き続き利用可能)、最初のステップからマルチモーダルとしてトレーニングされた最初のMiniMaxモデルです。画像・動画入力に対応し、デスクトップコンピューターを操作することさえ可能です。
MiniMax自体は「Intelligence with everyone」をキャッチフレーズとする中国のAI研究所で、テキストをはるかに超えてビデオ(Hailuo)、音声、音楽まで手がけています。M3はそのラインナップにおけるテキストとエージェントの旗艦モデルです。中国から登場する強力なモデルの波を追っている方なら、M3がQwenやKimi K2.5と同じ文脈に位置することがわかるでしょう。今年最も注目すべきオープンウェイトのリリースの一つです。
公式リリースはMiniMaxのXアカウントでその主張を明確に示しました:
"Introducing MiniMax M3: The First Open-Weights Model to Combine Three Frontier Capabilities... Coding & Agentic Frontier: 59.0% SWE-Bench Pro, 66.0% Terminal Bench 2.1... MiniMax Sparse Attention scales context to 1M... Natively Multimodal from Step Zero"
進める前に名前について一点:「MiniMax 3」という名前のモデルは存在しません。正式名称はMiniMax M3であり、このガイドではそれを取り上げます。
MiniMax M3の仕組み:スパースアテンションと1Mトークンウィンドウ
M3について最も興味深いのはベンチマークではなく、コストを爆発させずに100万トークンを読めるアーキテクチャです。これは本当に巧妙だと感じる部分なので、どのように機能するか説明します。
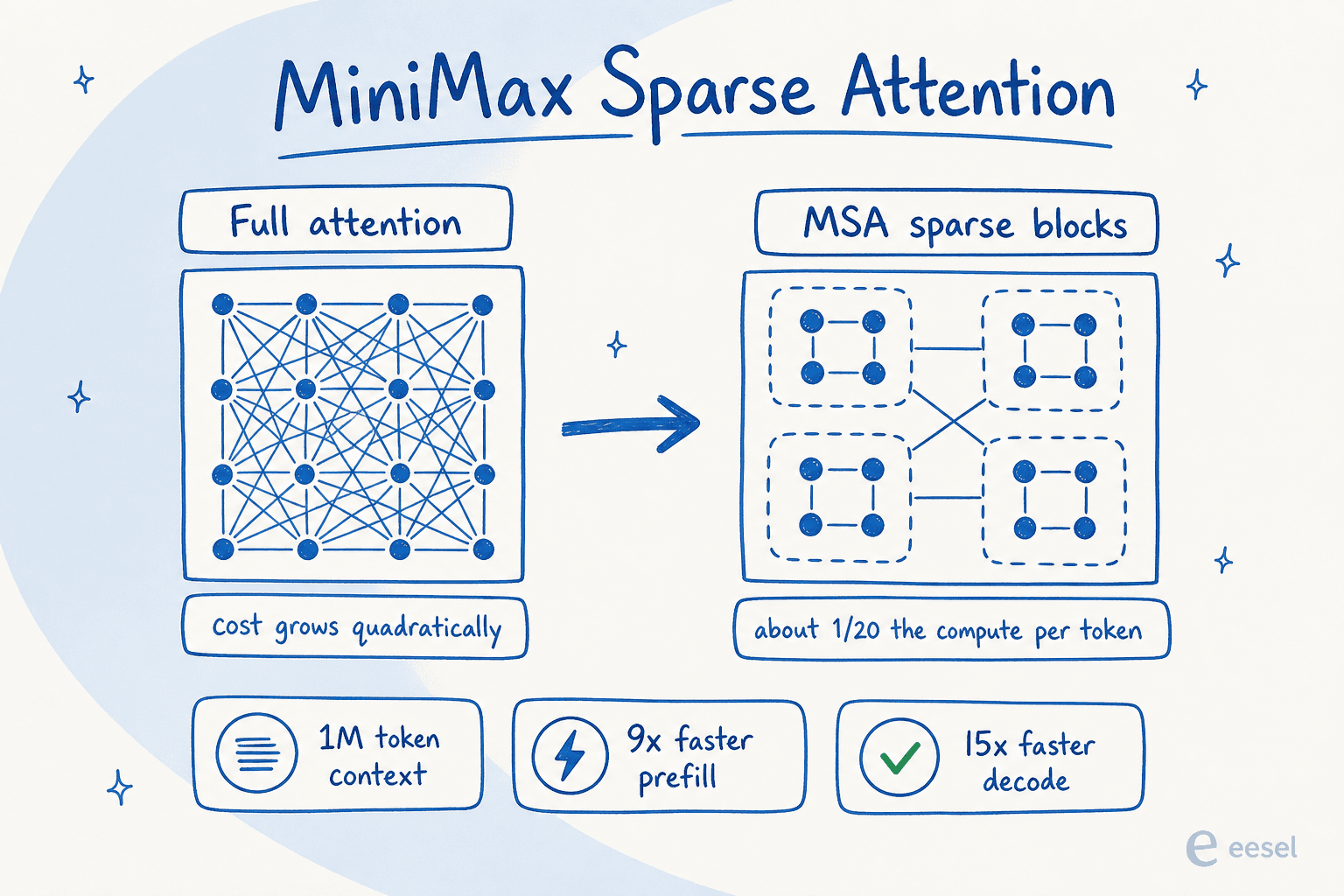
内部的にM3はMixture-of-Expertsモデルで、総パラメータ数は約428B、トークンごとに活性化されるのは約23Bです。つまり、各リクエストでは自身のごく一部のみを実行します。その上にある真の目玉がMiniMax Sparse Attention(MSA)です。コンテキストをブロックに分割し、すべてのトークンを相互比較するのではなく、関連するブロックにのみアテンションを向ける新しいアテンション設計です。
これが重要なのは、通常のアテンションはコンテキストが増えるにつれて二次的にコストが上昇するためで、長いコンテキストウィンドウが通常低速で高コストな理由がここにあります。MiniMaxによると、MSAはトークンあたりの計算量を約1/20に削減し、M2と比較して1Mコンテキストで9倍以上高速なプリフィルと15倍高速なデコードを実現しながら、アブレーション実験では大多数の能力でフルアテンションと同等のパフォーマンスを維持しています。結果として1,000,000トークンのコンテキストウィンドウ(最低512Kを保証)を実現しており、M2ラインの204,800から大幅に向上しています。
M3の動作について知っておくべきその他の点:
- 思考モード。
thinkingパラメーターで推論をenabled、adaptive(モデルが判断)、または低レイテンシ向けのdisabledに設定でき、両モードは同一の料金を共有します。 - ネイティブマルチモーダル。 「ステップ0から」テキスト・画像・動画のインターリーブでトレーニングされているため、後からビジョンが追加されたモデルよりもモダリティを深く融合しています。
- 長期的な作業向けに構築。 MiniMax自身のデモでは、M3が研究論文を再現するためにほぼ12時間自律的に動作し、147のベンチマーク提出と1,959のツール呼び出しにわたって約24時間かけてCUDAカーネルを最適化しました。
詳細な手法はM3技術レポートに記載されています。
MiniMax M3はどれくらい優れているか?ベンチマーク
MiniMaxはM3をソフトウェアエンジニアリングとターミナル実行のフロンティアと位置付け、GPT-5.5、Gemini 3.1 Pro、Claude Opusなどのクローズドモデルと比較しています。以下はアナウンスで公開されたスコアです:
| ベンチマーク | 測定内容 | MiniMax M3 |
|---|---|---|
| SWE-Bench Pro | 実際のソフトウェア修正 | 59.0% |
| Terminal-Bench 2.1 | コマンドラインエージェントタスク | 66.0% |
| MCP Atlas | エージェントプロトコルでのツール使用 | 74.2% |
| SWE-fficiency | 効率的なコード変更 | 34.8% |
| KernelBench Hard | GPUカーネル最適化 | 28.8% |
| PostTrainBench | 自律的なモデルトレーニング | 37.1 (#3) |
| Video-MME(512フレーム) | 動画理解 | 84.6 |
これらの数値が意味することについて正直に言うと、自律的なモデルトレーニングベンチマークPostTrainBenchでは、M3は全体で3位となり、Claude Opus 4.7(42.4)とGPT-5.5(39.3)にわずかに及びませんでしたが、それ以外のすべてを上回りました。これが全体的なパターンです:M3はオープンウェイトモデルとして優れており、コーディングで競争力がありますが、クローズドなフロンティアのトップではありません。以前のM2ファミリーはすでに独立したインデックスでオープンウェイトのスコアを押し上げており、M3はそこからの明確な一歩前進です。
これらのモデルの比較について広いコンテキストを知りたい方は、Claude代替とGemini代替のガイドで比較のクローズドモデル側を網羅しています。
MiniMax M3の料金は?
ここがM3の評判の源泉です。開発者が繰り返し言及する理由は料金にあります。
MiniMaxはM3を2つの方法で販売しています。1つ目は、リリース時に3段階に更新されたサブスクリプションToken Planで、テキスト・画像・音声・音楽がすべて共通の使用プールを使います:
| Token Plan | 価格 / 月 | 月あたりM3トークン目安 |
|---|---|---|
| Plus | $20 | 約17億トークン |
| Max | $50 | 約51億トークン |
| Ultra | $120 | 約98億トークン |
MiniMaxはエントリー層を"$20 = Claude Proの10倍"のスループットと表現していますが、これはマーケティングであり、方針を示しています:1ドルあたり最大トークン数。Qwnの料金やオープンウェイトパックの他のモデルと同様の低コスト戦略です。
2つ目は従量制APIで、入力長による課金です。512K入力トークン未満の呼び出しは標準料金、それ以上はフルリポジトリや超長文書作業向けの高い長文コンテキスト料金が適用されます。思考のオン・オフは料金が同じで、レイテンシに敏感なワークロード向けにpriorityサービス層も利用できます。r/LLMDevsの開発者によると、リリース時のトークン単価は512K以下で100万トークンあたり$0.60/$2.40と報告されており、彼らの言葉では「DeepSeek領域」に入る価格です。
コスト面の残り半分はライセンスです。M3はMiniMax Community Licenseの下でオープンウェイトです:非商用利用は無料ですが、商用利用には「Built with MiniMax M3」という目に見えるクレジット表記が必要で、年間収益2,000万ドル超の場合は事前の書面による承認が必要です。つまりオープンウェイトであり、オープンソースではありません。コミュニティがすぐに指摘する区別です。他の有料オプションとの純粋なコスト比較には、安価なAIツールリストとKimi K2.5料金ガイドが役立つ参考資料です。
開発者がMiniMax M3について実際に言っていること
公開ベンチマークだけではわからないことがあります。より有益なシグナルは、実際の業務でM3を使用している開発者から来ており、評価は一致しています:コストパフォーマンスの高い選択肢であり、フロンティアの代替ではありません。
価値についての最も明確な議論は、実はM2.7の前モデルに切り替えた人物から来ており、r/openclawに投稿されています:
"claude is a slightly better model. better reasoning, better depth on hard problems. that's just how it is. but minimax m2.7 delivers exceptionally well for what i actually use it for, at a fraction of the cost... sometimes good enough is actually great when it's reliable and affordable."
M3について具体的には、r/opencodeの開発者が他の中国モデルを試した後にこう述べています:
"I started using Kimi 2.6, then GLM 51, then DeepSeek4. But now after trying minimax m3 I am really impressed. It seems to think very deeply and really do a good job following directions... It seems to have flown a lot under the radar."
これはM3が市場でどのような位置にあるかをおおよそ表しています:オープンウェイト、Sonnetクラス程度の能力、バリュー層の価格設定。
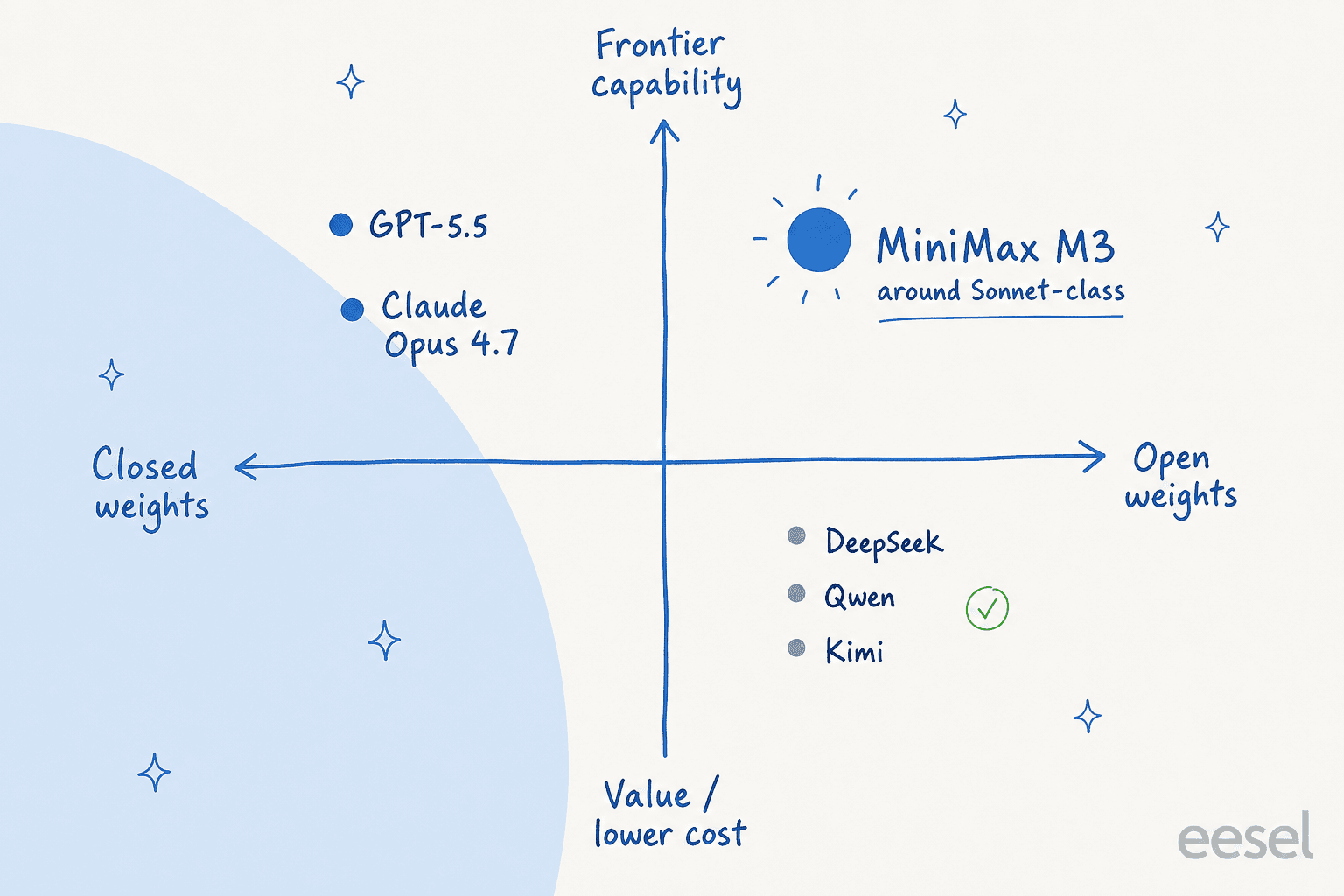
ただし、賞賛ばかりではなく、本番環境を考えている場合は批判も真剣に受け止める必要があります。最も多い不満はプレッシャー下での信頼性です。r/hermesagentのテスターはM3の予測不能さを指摘しています:
"I feel like it is much more chaotic and verbose, as well as hallucinations being more common. Now it just suddenly keeps stopping mid action... Right now I wouldn't use it in production."
また、ホストされたAPIについてデータ保持の懸念が繰り返し指摘されており、ユーザーはプロンプトデータのトレーニング利用からのオプトアウト方法が明確に見つからないと述べています。これはホビープロジェクト以上に顧客データにとって重要な問題であり、セルフホスティングコミュニティがHugging Faceでウェイトが公開されていることを評価している大きな理由の一つです。
落とし穴:優れたモデルはまだサポートエージェントではない
新しい輝かしいモデルがリリースされるときに見落とされがちなことをお伝えします。M3のようなモデルは素晴らしいエンジンです。しかしエンジンは車ではなく、生のモデルはカスタマーサポートエージェントではありません。
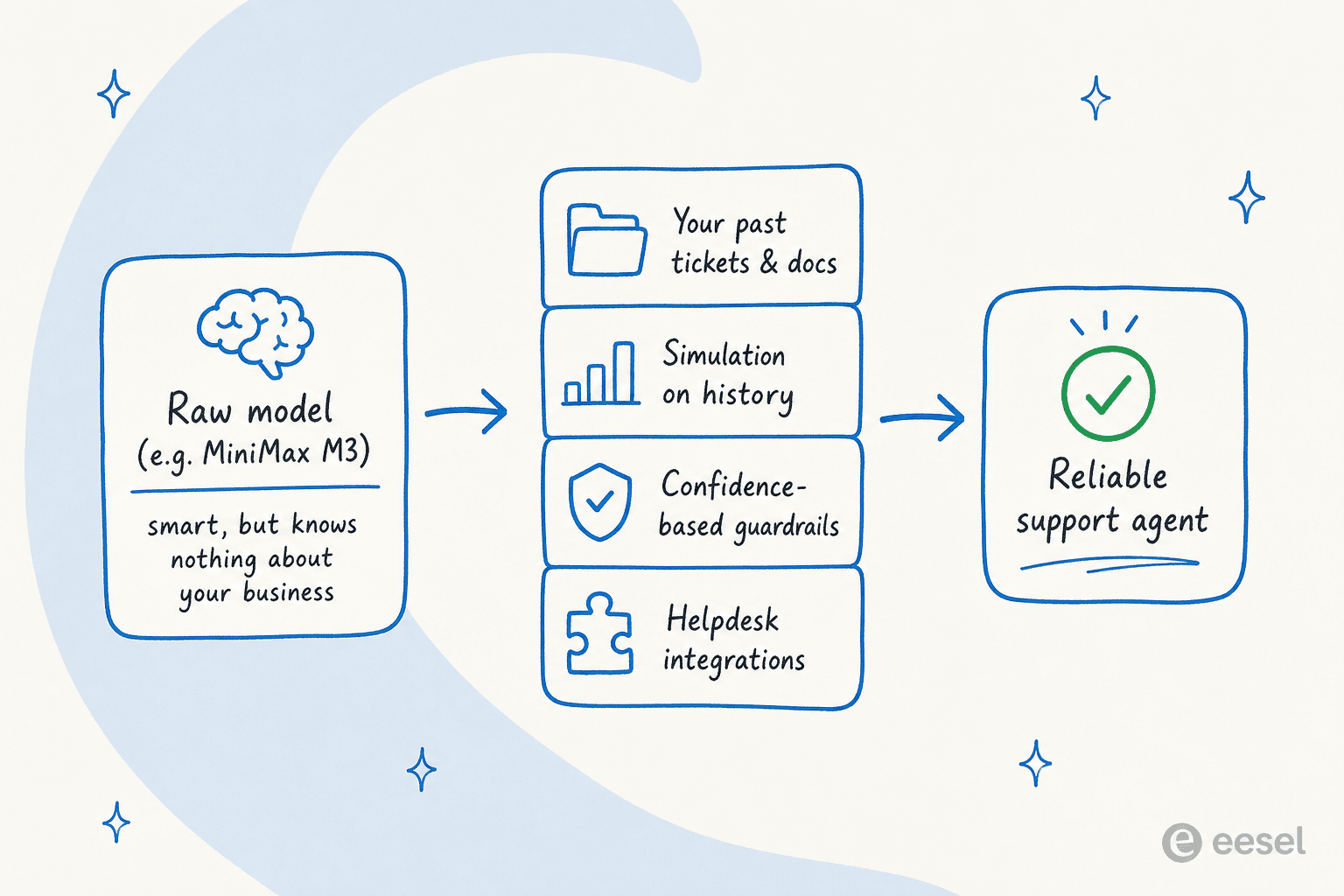
私はeeselでここ数年、言語モデルをライブサポートキューに向けたときに何が起きるかを観察してきました。失敗パターンは常に同じです:モデルは自信ありげに聞こえるが、具体的な内容で間違える。なぜなら返金ポリシー、過去5万件の解決済みチケット、あるいは人間がレビューせずに送っても安全な回答を知らないからです。リーダーボードで最も賢いモデルでも、誰も教えなければ出荷期限を幻覚します。だからすべてのeeselの展開は、顧客に回答する前に過去チケットに対してシミュレーションを実行します。
サポートに関する重要な質問は「M3はSWE-Benchで何点を取ったか」ではありません。それは:実際のチケットとドキュメントから学習できるか、本番前に安全にテストできるか、誤った回答を自信を持って送ることを何が防ぐのか、です。これらはモデルの問題ではなく製品の問題であり、カスタマーサービス向けの最良のAIのまとめが中心に置いている問いです。
同じ点は、チャットボットが誤って回答するたびに浮かび上がり、AIエージェントのコストが人間と比べてどうかが、モデルのトークン単価よりもチケットをどれだけ確実に解決するかに大きく依存する理由でもあります。
eesel:モデルをサポートのチームメイトに変えるレイヤー
これがまさにeeselが埋めるために構築されたギャップです。モデルを選んで祈るよう求める代わりに、eesselはヘルプデスクの上にAIチームメイトとして座り、初日から過去チケット・ヘルプドキュメント・ツールから学習し、その後Tier-1の作業を下書き・トリアージ・解決する際に、安全に稼働させ続けるためのガードレールを維持します。

具体的な差別化要因はシミュレーションモードです:過去の実際のチケット数千件に対してエージェントを実行し、何を回答したか、どこにギャップがあるかを正確に確認し、それを埋めてからようやく本番稼働させます。信頼度ベースのルーティングにより、信頼度の低い回答は送信ではなく下書きとして扱われます。これが、SmabaのようなチームがZendeskエージェントを月間10万件以上のドイツ語チケットで完全自動化している方法であり、Gridwiseが初月に73%のTier-1解決率を達成した方法です。100以上のインテグレーションに接続し、80以上の言語で回答し、1チケットあたり$0.40の従量制料金でシート料金なしで動作します。
サポート向けのモデルを選ぶためにここに来たなら、より良い出発点はレイヤーであり、リーダーボードではありません。eesselを無料でお試しいただけます。クレジットカード不要で、1人の顧客にも触れる前に、シミュレーションで自分のチケットを解決する様子を見ることができます。私が機能を見てきたすべてのカスタマーサービスAI展開の背後にある同じ教訓です:モデルは交換可能、信頼性は交換不可能です。
よくある質問
MiniMax M3をわかりやすく説明すると?
MiniMax M3は本当にオープンソースですか?
MiniMax M3の料金は?
MiniMax M3はコーディングに向いていますか?
MiniMax M3をカスタマーサポートに使えますか?
MiniMax M3は100万トークンのコンテキストをどう処理しますか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.