Cursor Originとは正確に何か
OriginはCursor独自のGitフォージです。コードのホスティング、レビュー、コラボレーションを行うゼロから構築されたプラットフォームで、GitHubと正面から競合します。ローンチ投稿のCursorの一言説明は非常に明快です。
コードストレージとGitホスティングをローンチします。Originはチームとエージェントにコードをホスト、レビュー、コラボレーションする場所を提供します。今秋利用可能。ウェイトリストに登録してください。
製品ページのタグラインは「エージェント時代のためのGitフォージ」で、サポートコピーが1行あります。「コードはどのインフラも対処できるスピードより速く動いています。Originはこの瞬間のために設計されました。」今日の公開サイトはこれがほぼすべてで、タグラインとウェイトリストのボタンだけです。
Cursorが買収したコードレビュースタートアップGraphiteの共同創業者Tomas Reimersがステージでデモを行いました。この詳細は見かけより重要で、後で戻ってきます。Cursor自体をご存知でない方へ、VS Codeのフォーク上に構築されたAIネイティブコードエディターで、Originは「コードを書く場所」から「コードが生きる場所」へのCursorの移行を意味します。
なぜまったく新しいGitホストを構築するのか
これは考える価値のある問いです。「CursorはGitHubをコピーした」というのは怠惰な読み方で、要点を見失っています。
Gitとその上のGitHubは、人間のペースを中心に設計されました。開発者がブランチを開き、数時間コードを書き、プルリクエストを開き、チームメートがレビューするのを待ち、そしてマージします。リズム全体が時間と日数で測られ、それで問題ありませんでした。人間はそれほどの速さでしか入力できないからです。
AIエージェントはその前提を壊します。AlphaSignalの記事が述べたように、「何十何百ものエージェントが同じコードベースに対して同時にクローン、ブランチ、コミット、リベースを数秒で行える」ことは「GitHubがアーキテクチャ上対処するよう設計されたものとは根本的に異なる負荷プロファイルです」。エージェントコーディングツールのフリートを実行すると、ボトルネックはコードを書く速さではなく、機械が生成するものをホスト、レビュー、安全にマージする速さになります。
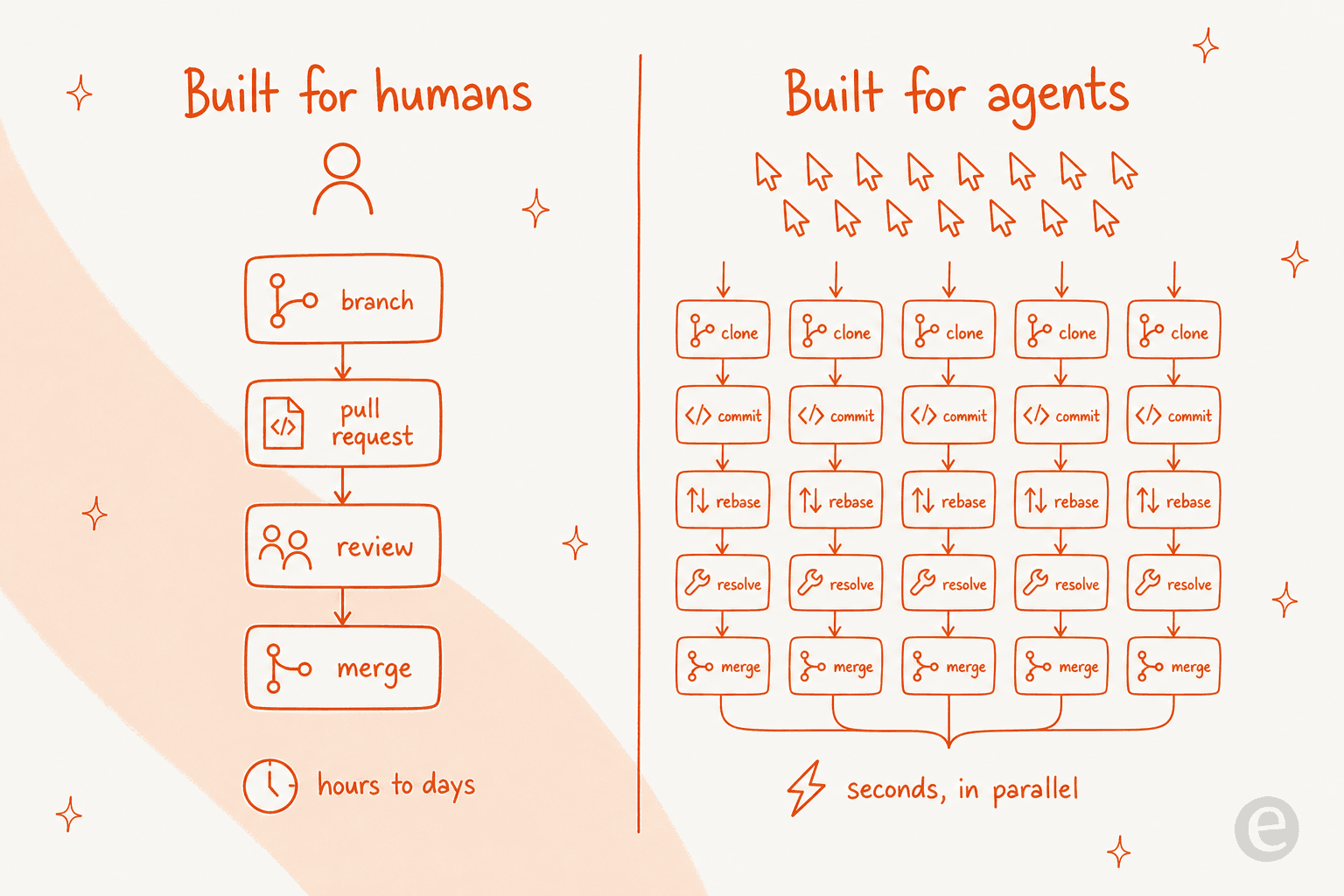
つまりOriginの賭けは、次に再構築すべきインフラはフォージ自体だということです。アナリストのMark Kはこれを「大規模なエージェント生成コードの調整、レビュー、安全なマージ」を中心に構築された「エージェントネイティブのGitHub競合を目指すCursorの試み」と表現しました。これは今のAIエージェントインフラの多くの背後にある同じ論理です。人間のために構築したツールは、ソフトウェアが主要ユーザーになった瞬間に軋みはじめます。
実際のフードの下には何があるか
CursorはまだリアルなDocsを公開していないため、機能の全体像はローンチデモと会場にいた人々から得られます。表示または言及されたことは以下の通りです。
- Git互換性:新しいワークフローを強制するのではなく、標準のgitツールで機能します。
- APIとMCPの拡張性:swyxが「apiとmcpで拡張可能」と説明し、エージェントがフォージをプログラム的に操作できます。
- エージェントによるマージ競合の組み込み解決、さらにCI/ビルド失敗のエージェント解決(「組み込みのマージ競合とco失敗のエージェント解決」)。
- ハイブリッドNVMe + S3ストレージアーキテクチャ:Diggの報道によると「無限のレプリカをサポート」します。
- スタックされたプルリクエストのGrahiteからの継承。多くの依存する変更を並行して管理します。
ステージデモの数字が見出しを飾ります。Nick Dobosがスライドから引用したのは「cursor originは毎秒22.6コミットをサポート(単一リポジトリで)」で、デモでは1時間あたり数十万のクローンを処理したと報告されており、AlphaSignalが「既存のGitホスティングインフラをすべてストレスにさらすであろう」と述べた種類の負荷です。

簡単な正直な注意点:「296,000+クローン」という広く共有された数字が報道に出回りましたが、元の見出しで単位と時間枠が切り捨てられたため、Cursorが独自の数字を公開するまで、正確なベンチマークではなくスケールの主張として扱います。
Originが本当にはまるのは、Cursorが静かに組み立ててきたスタックの最後のピースとしてです。Mark Kは全体像を「AIソフトウェアファクトリー」と表現しました。Cursorでコードを書き、エージェントを並行で実行し、Graphiteスタイルのスタックされたワークフローでレビューし、Originでホストしてマージする。Graphiteの買収がそのレビューとマージのレイヤーを信頼できるものにしており、だからこそOriginはGitHubのクローンというより、Cursor自身のエージェントコーディングワークフローのループを閉じるものとして読みます。
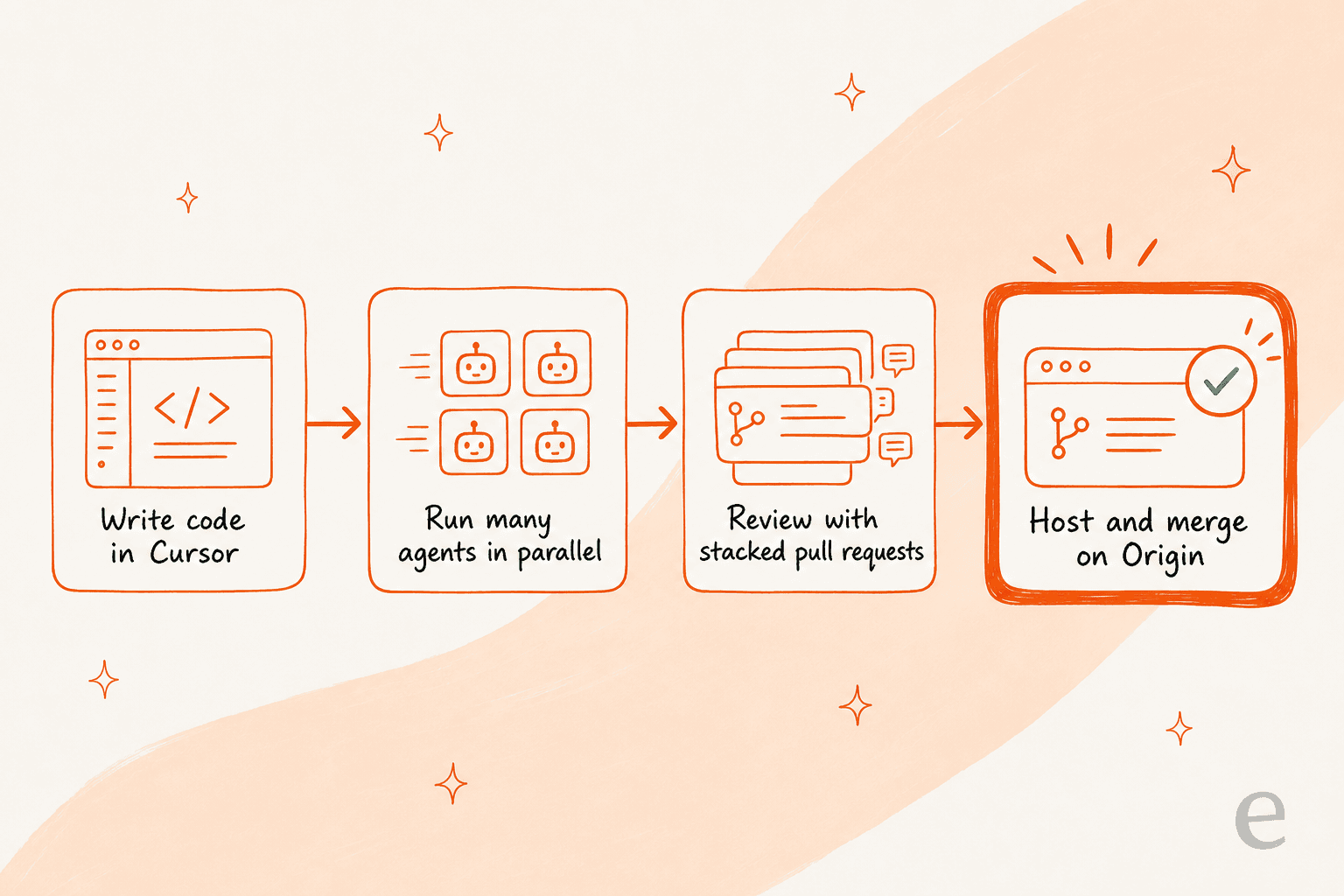
欠点:薄いローンチと本物の信頼問題
ここでブレーキをかけます。ローンチは派手で、公式投稿は300万ビュー以上を集めましたが、実際の製品の表面はタグラインと登録フォームだけです。Hacker Newsはこれを見逃しませんでした。「これほど情報が少ないウェイトリストは見たことがない」とあるコメンターが書きました。ウェイトリスト自体もローンチ時に負荷で落ちたと報告されており、これはスループットを謳う製品にとって悪いシグナルか適切なシグナルかのどちらかです。
より深い反論は最も興味深いもので、サポートで常に耳にするものと同じです。エージェントが毎秒22.6回コミットしているなら、実際に誰がそれをすべてレビューしているのか?HNスレッドより:
これはGithubとどう違うのか...これはAIのコード生成をマシンスピードでどう扱うのか?人間はAIのゴミコードのレビューループに今でもいるのか?
それがすべてのゲームです。機械がコードを書いてマージできる速度を上げることは、コードが正しいかどうかを誰も保証できなければ何の意味もありません。「エージェントがマージ競合を自動的に解決する」はエージェントがそれを間違えてマシンスピードでデプロイするまでは素晴らしく聞こえます。
そしてCursor自体への信頼もあります。r/cursorの反応の声高な一部はフィーチャーよりもコードベースの引き渡しについてでした:
Xがホストするリポジトリに自分のコードを渡す前に、CursorでGitサーバーを自分で構築してAWSでホストする
そのコメント(「X」という参照はCursorの背後に誰がいるかについてのコメンターの解釈であり、スレッドによると、Cursorが確認したことではありません)は繰り返し浮上した広範な懸念と共鳴しています。本当の製品はトレーニングデータとしてのコードではないかという懸念です。CursorがOriginのデータ取り扱い規約を公表するまで、プライバシー問題は「まだ未解決」として分類し、「問題なし」とはしません。
Originがエージェント時代について本当に教えてくれること
Gitの配管から距離を置いてOriginを見ると、それはシグナルです。人間のために構築されたインフラは、エージェントが主要ユーザーになった瞬間に再構築される。これはCursor固有の洞察ではなく、パターンです。私がeesel AIを構築してきた過去数年でサポート側のバージョンを生きてきたからこそそう言えます。
ヘルプデスクはGitより先に全く同じ問題を抱えていました。ZendeskやFreshdeskのようなツールは、人間のエージェントが1度に1チケットを拾い上げることを中心に設計されていました。AIエージェントをその世界に導入すると、Hacker NewsがOriginについて問いかけているのと同じ質問がそのまま出てきます。誰がアウトプットをレビューするのか、自信を持って間違っているときはどうなるのか、自分のデータは誰かのモデルのトレーニングに使われているのか。確信を持った口調のボットが静かに間違った答えを出すのを見てきたからこそ、今では1回のライブ返信が出る前に各チームが自分たちの実際のチケット履歴に対してロールアウトをシミュレートするようにしており、低信頼の回答は送信されるのではなく人間向けに下書きにされます。スループットは難しい部分ではありませんでした。信頼がそうでした。
Originが引き起こすbuild-versus-buyの本能(「AWSで自分のGitサーバーをホストする」)も二度見の価値があります。サポート側でテクニカルチームから何度も聞く話で、実際に試したチームは大抵、私たちの顧客の一人が至ったのと同じ場所に着きます。
自分たちのLLMアプリケーションを書こうとすることもできましたが、そこに時間を投資したくなかったのです。メンテナンスしなくて済むものが欲しかった。
それはBitcoin ATMの会社のエンジニアリングリードがビルドではなくバイを選んだ話で、ケーススタディから引用しました。OriginはCursorがインフラ層で逆の賭けをしているもので、エージェントスケールのコードをホストすることがチームが誰かに運用を支払うほど難しい問題だと賭けています。それが本当かどうかは、コミット毎秒の問題ではなく、レビューと信頼の問題を解決するかどうかにまったく依存します。
では、Cursor Originを気にすべきですか?Cursorのエージェントに力を入れている真剣なエンジニアリング組織を運営しているなら、ウェイトリストに登録して特にデータ規約を注意深く見てください。サポート、IT、またはオペレーションチームで自分たちに何か変わるかを疑問に思っているなら、少なくとも直接的には変わりません。AIエージェントを活用するために新しいGitホストは必要ありません。持っているツールにすでに統合できるエージェントと、それを信頼するためのガードレールが必要です。
eesel AIを試してみる
Cursor Originはエージェント時代のコードインフラを再構築しています。サポート側では、eesel AIがしばらく同等のことをしてきました。すでに使っているヘルプデスク、Slack、Docsの中に住み、初日から過去チケットから学習し、何も移行せずにTier-1作業を処理するAIエージェントです。
ウェイトリストとの違いは、実際に実行できることです。GridwiseはeeselでTier-1リクエストの73%を初月に解決し、7日間のトライアル中に結果が届きました。各ロールアウトは実際のチケット履歴に対するシミュレーションから始まり、ライブ返信が出る前にカバレッジと精度を確認できます。エージェント時代が本当に依存しているのはその部分であり、コミット毎秒ではありません。

秋を待つのではなく今日AIエージェントを活用したいなら、eeselを試す。
よくある質問
Cursor Originはいつ利用可能になりますか?
Cursor OriginはGitHubの競合ですか?
Cursor Originで自分のコードは安全ですか?
仕事でAIエージェントを使うためにCursor Originは必要ですか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.