DiffusionGemmaとは?
DiffusionGemmaはGoogleのオープンなGemmaファミリーに属するモデルで、あなたが使ってきたほぼすべてのチャットボットの背後にある自己回帰的なアプローチではなく、拡散プロセスでテキストを生成します。これは2026年6月10日にGoogle DeepMindによってApache 2.0の下で実験的なオープンウェイトモデルとして公開され、公式のモデルカードはDeepMindのサイトに置かれています。
主な仕様シートは以下のとおりです。
| 属性 | DiffusionGemma |
|---|---|
| 公開日 | 2026年6月10日 |
| ライセンス | Apache 2.0(オープンウェイト) |
| アーキテクチャ | Gemma 4をベースに構築、Mixture-of-Experts |
| サイズ | 総パラメータ252億、ステップあたり有効約38億(「26B A4B」) |
| 生成 | 256トークンのブロックを並列にノイズ除去 |
| 入力 / 出力 | マルチモーダル入力(テキスト/画像/動画)、テキスト出力 |
| 速度 | H100一基で毎秒1,000トークン超、同等のARモデルより最大4倍高速 |
| ハードウェア | BF16で約52GB VRAM、INT8で約28GB、量子化で約18GBから実行可能 |
これらの数値の大半はMarkTechPostのローンチ報道とSpheronのデプロイガイドに由来し、並列ブロックの詳細はDiggの記事からのものです。「26B A4B」というラベルはGoogleの略記で、26BクラスのMixture-of-Expertsモデルでありながら、任意のステップで約38億パラメータしか発火しないことを意味します。これが高速かつ安価に動作する理由の一つです。
これが大ごとである理由はベンチマークのスコアではありません。フロンティアラボが、実際にダウンロードできる拡散言語モデルを出荷したことです。長年、拡散は画像や動画で支配的な手法でした(MidjourneyやSoraを思い浮かべてください)が、テキストは頑なに自己回帰的なまま、つまりChatGPTやClaudeのような日常的なアシスタントを動かすのと同じファミリーでした。DiffusionGemmaは、テキスト側が追いついてきていることを示すこれまでで最も明確なシグナルの一つです。
DiffusionGemmaの実際の仕組み
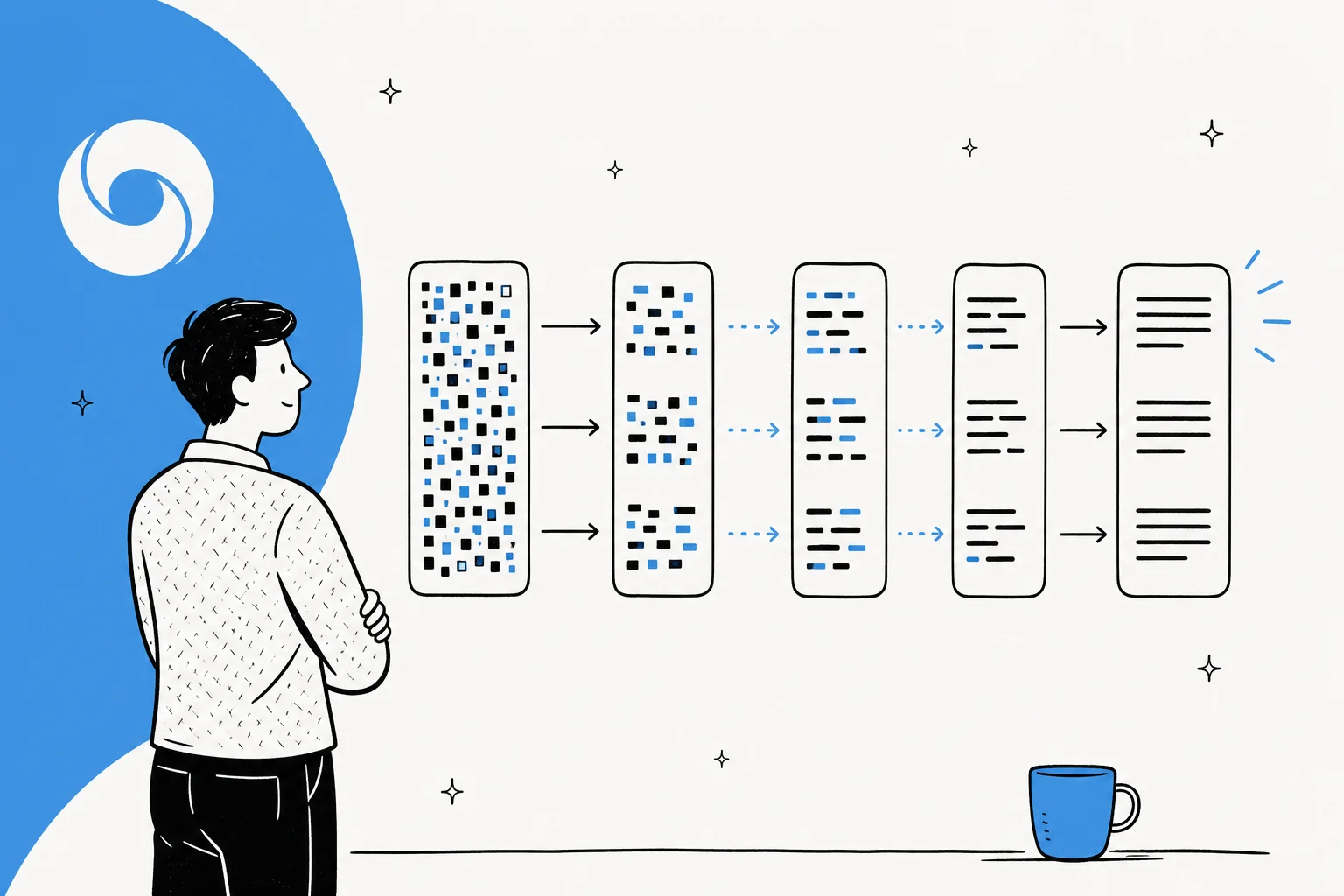
標準的な大規模言語モデルは自己回帰的です。Inception Labsが述べるように、それらは「テキストを左から右へ一度に1トークンずつ生成し、あるトークンはその前のすべてのテキストが生成されるまで生成できない」のです。各単語は前の単語を待つため、長い回答は数十億のパラメータを通る長い順方向パスの連続を意味します。レイテンシーはここから生じます。
拡散はこれをひっくり返します。テキストにおける支配的なアプローチはマスク拡散です。すべてがマスクされたトークンのブロックから始め、トランスフォーマーがマスク解除されたバージョンを予測し、数回のパスにわたってその推測を洗練していきます。Googleはこれを、テキストを「画像拡散が機能するのと同じやり方で生成する。テキストを直接予測するのではなく、モデルはノイズを段階的に洗練することで出力を生成することを学習し、解に素早く反復し、生成中にエラーを修正できる」ものだと説明しています。
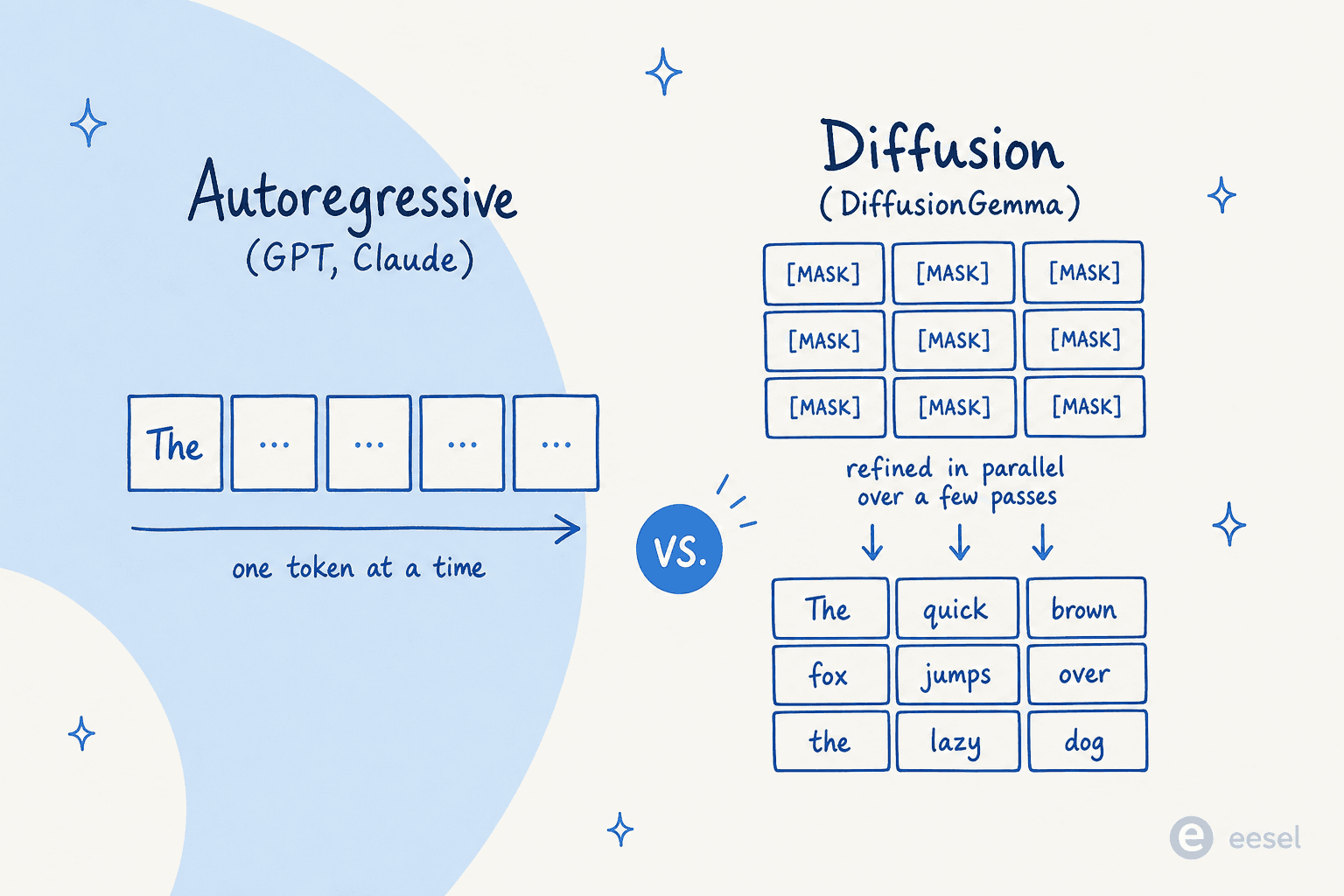
一つ明確にしておきます。名前で人々がつまずくからです。ここでの拡散はトランスフォーマーを置き換えるものではなく、自己回帰を置き換えるものです。よく引用されるユーザーsynapsomorphyによるHacker Newsのコメントが説明しているように。
「拡散はトランスフォーマーの代わりではなく、自己回帰の代わりだ。Mercuryのような従来の拡散LLMも依然としてトランスフォーマーを使うが、因果マスキングがないため、入力全体が一度に処理され、出力の生成は明らかに異なる。」
並列に生成することの実用的な利点は三つあります。生の速度、生成の途中でエラーを修正できること、そして自然なインフィリングです(モデルはギャップの両側の文脈を見られるため、末尾に追加するだけでなく、シーケンスの中間を編集するのが得意です)。Andrej Karpathyは早い段階でその新規性を指摘し、拡散は「左から右へ進むのではなく、すべてを一度に行う。ノイズから始めて、徐々にトークンのストリームへとノイズ除去していく」と述べました。
DiffusionGemma対Gemini Diffusion:混同しないこと
これはほぼ全員が引っかかります。Googleが約1年の間に2つのテキスト拡散の代物を出荷し、ほぼ同一の名前を付けたからです。
Gemini Diffusionは2025年5月のGoogle I/Oで、Googleのインフラ上で動作する実験的でウェイトリスト限定のモデルとして披露されました。ダウンロードはできません。対照的にDiffusionGemmaは、自分でダウンロードして実行できるオープンウェイトのものです。
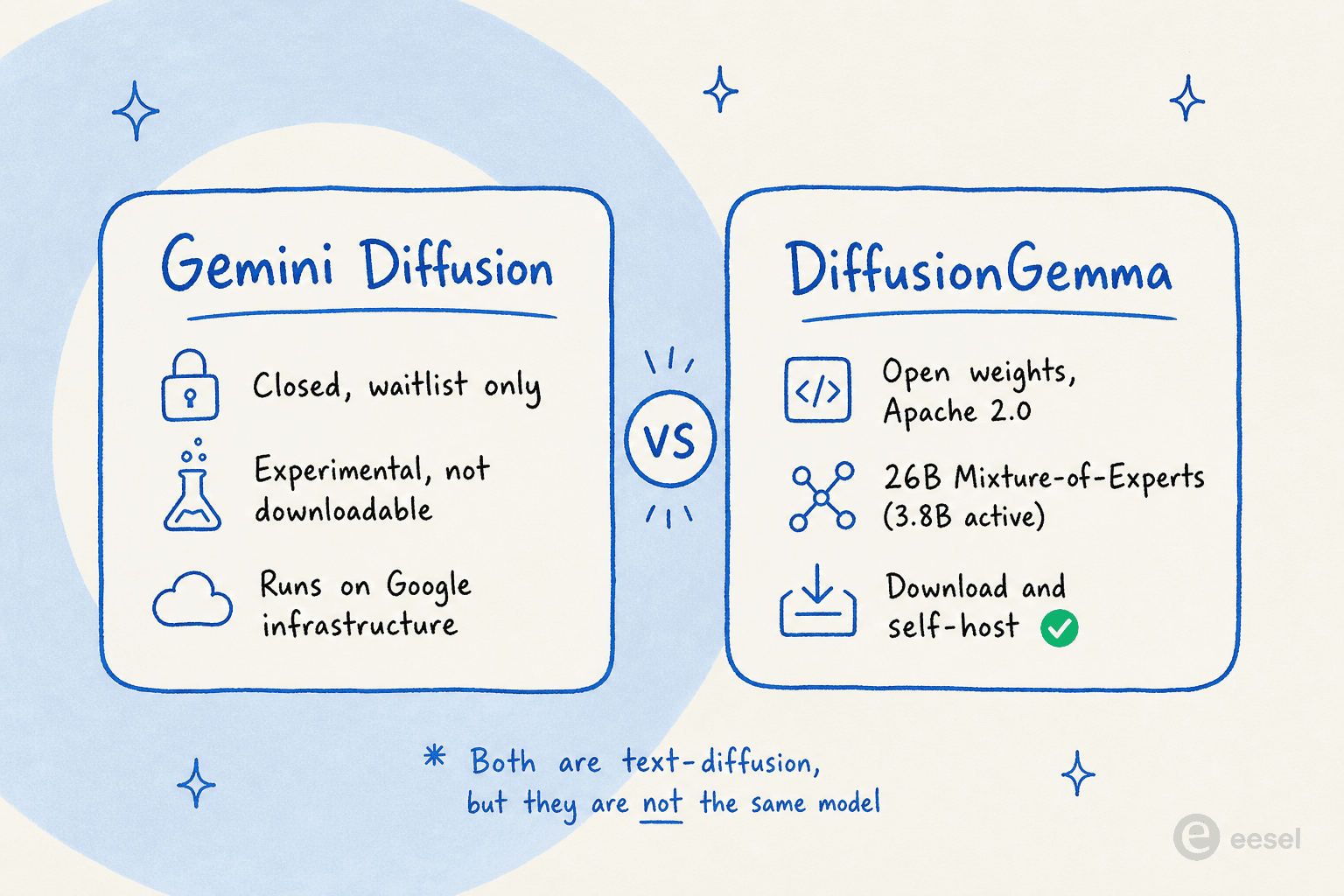
Googleが実験的なクローズドモデルとオープンウェイトのリリースの両方を出荷したという事実そのものが、この話の核心です。それは拡散言語モデルが研究上の好奇心の段階を脱したという最も強いシグナルです。フロンティアラボがアーキテクチャをオープンソース化するとき、それは他の人々がその上に構築するだろうと賭けているのです。
速度の数値(そしてそれがそこそこ本物である理由)
速度こそがすべての売り文句なので、数値を正直に見てみましょう。DiffusionGemmaの毎秒1,000トークン超は拡散の親戚たちと並び、自己回帰モデルとの差は大きいものです。
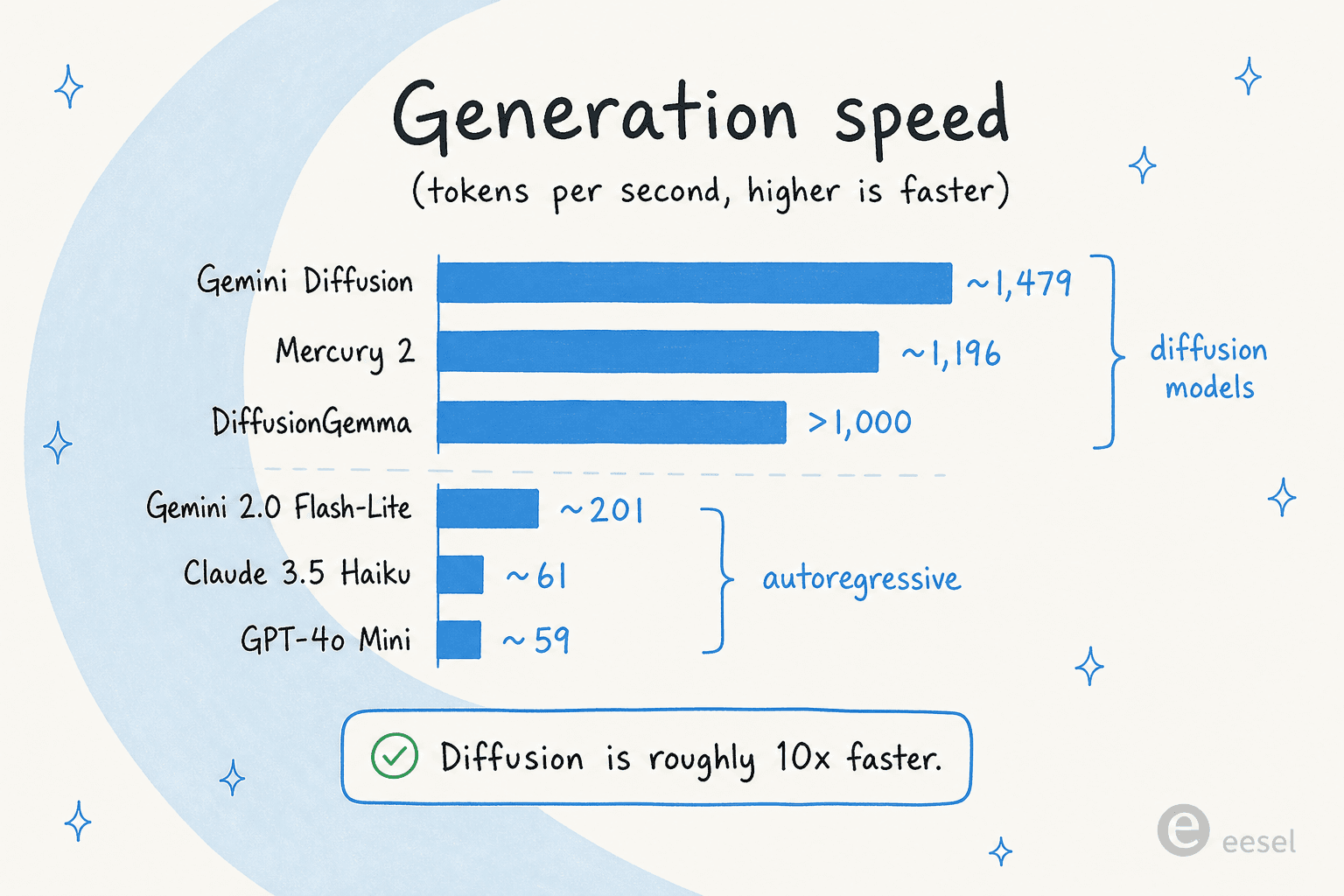
いくつかの留保がこれを地に足のついたものに保ちます。ほぼすべての数値はNVIDIA H100で計測されており、その大半はベンダーの主張です。この分野で唯一の独立した尺度であるArtificial Analysisは、InceptionのMercuryモデルの速度は裏付けましたが、品質はまだです。DiffusionGemmaに関して言えば、毎秒1,000トークン超と最大4倍という数値はGoogleやYellow.comのようなパートナーの記事に由来し、まだ第三者のベンチマークではありません。
比較として、人々が実際に本番で使う自己回帰モデルはスループットでははるかに低い位置にあります。Inception自身のベンチマークによれば、GPT-4o Miniは毎秒約59トークン、Claude 3.5 Haikuは約61で、速度最適化されたGemini 2.0 Flash-Liteで約201です。つまり拡散に対する「およそ10倍高速」という枠組みは、少なくとも紙の上では成り立ちます。
どこで輝き、どこで輝かないか
正直な見立ては、拡散はスループット律速で並列化可能な作業では確かに高速だが、本番アプリが実際に必要とする多くのことでは自己回帰が依然として勝る、というものです。ここで最良の単一の情報源は、エンジニアのSean Goedeckeによる拡散の限界の分析であり、それは一つの判断にきれいに対応します。
拡散を選ぶべきときは、作業が大量かつ並列化可能な場合です。一括要約、分類、フォーマット変換、翻訳、あるいはステップごとの高速な応答が積み重なる低レイテンシーのエージェントループなどです。コード生成は特に好相性で、拡散のインフィリング的な性質が、ブロックの先頭と末尾を同じパスで生成するというコードの編集の仕方に合致します。
自己回帰を維持すべきときは、短い出力が必要な場合(拡散は出力に関係なくすべてのノイズ除去パスを実行するため、6トークンの回答を出すのに余分な作業をします)、長いコンテキストウィンドウ(拡散はキー・バリューキャッシュをそう簡単に再利用できないため、毎パスでコンテキスト全体にわたるアテンションを再計算します)、あるいは難しい思考連鎖の推論の場合です。最後の点について、Goedeckeが最も鋭い主張をしています。
「拡散モデルの推論の可能性に広く懐疑的であるべき理由の一つは、まさにそれらがトークンあたり自己回帰モデルよりもはるかに少ない作業しか行わないことだ。それは単に、モデルが『考える』ことに費やす余地が少ないということだ。」
Sean Goedecke、"Strengths and limitations of diffusion language models"
DiffusionGemma自体がこのトレードオフを裏付けています。それは公開されたあらゆるベンチマークで標準のGemma 4を下回ったままです。本番のエージェントスタックについて書いたあるエンジニアは、拡散への歴史的な批判を印象的に言い表しました。初期のモデルは「壊れた時計が速いのと同じ意味で速かった。間違った答えにどれだけ速くたどり着いても意味がない」(dev.to)。品質のギャップは小・中規模では縮まっていますが、フロンティアでは依然として目に見えます。
ほとんどのチームが行き着く現実的な動きは置き換えではなく、ルーティングです。単純で高頻度のステップ(検索、フォーマット、分類)は高速な拡散モデルに送り、深い推論にはフロンティアの自己回帰モデルを取っておくのです。これは、一つのAIヘルプデスクにすべてをやらせるのではなく、仕事に合った適切なツールを選ぶのと同じ論理です。
DiffusionGemmaがカスタマーサポートチームにとって意味すること
拡散はサポートにうってつけに聞こえます。ライブチャットとAIサポートエージェントは、まさに1秒の応答と数秒の応答との差が、ツールがリアルタイムに感じられるか「待たされるサービス」に感じられるかを決める、低レイテンシーでユーザー向けのケースです。顧客向けのコパイロットでは、サブ秒の応答が採用と離脱の差を本当に分けることがあります。
しかしここに、私たちが反論したい点があります。サポートチームにとって、モデルのアーキテクチャはその周りのオーケストレーションよりもはるかに重要度が低いのです。2つの留保がこのユースケースに直接当てはまります。
第一に、実際のサポート回答は長いコンテキストと検索に依存しますが、長いコンテキストはまさに拡散の弱点です。良い回答はゼロからの生成ではなく、あなたのナレッジベース、チケット履歴、ポリシードキュメントに対する根拠に基づいた回答です。検索と根拠付けは、最終的なトークンが左から右に出てきたか並列に出てきたかよりも回答品質にとって重要であり、これがRAG対LLMという問いの核心です。
第二に、顧客向けの何ごとにおいても、品質と信頼性は生の速度に勝ります。古びた知識や弱いエスカレーションルールにつながれた高速なモデルは、間違った回答をより速く生み出すだけです。それがサポートに当てはめた、壊れた時計の問題です。

ですから、DiffusionGemmaについて読んでいて、それが必要かどうか悩んでいるサポートリーダーなら、おそらく直接は必要ありません。あなたが欲しいのは、根拠付け、ガードレール、ヘルプデスク連携を正しく行い、そのうえで内部で最も速く最良のモデルから静かに恩恵を受けるプラットフォームです。レイテンシーは数ある操作レバーの一つにすぎず、あなたの解決率を押し下げているものであることはまれです。より大きな問いは通常、それを処理する人間に対するチケットあたりのコストです。
eeselを試す
eesel AIは、既存のヘルプデスク(Zendesk、Freshdesk、HubSpot、Gorgias、Front)の中で動き、初日から過去のチケットとヘルプドキュメントを学習してティア1サポートを処理するAIの同僚を販売しています。ここで関連する理由は、eeselが意図的にモデルに依存しないことです。だから上記のアーキテクチャ論争は、あなたが勝つ必要のないものなのです。eeselが正しく行うのは、実際に数字を動かすオーケストレーションです。たとえば、確信がないときは送信ではなく下書きを行う確信度ベースのルーティングや、過去のチケットに対して実行して本番稼働前にカバレッジを確認できるシミュレーションモードなどです。Gridwiseは初月でティア1リクエストの73%が解決されたのを確認しており、料金は解決済みチケットあたり0.40ドルからの従量制でシートあたりの料金はないため、GPU時間ではなく成果に対して支払います。
よくある質問
DiffusionGemmaを簡単に言うと何ですか?
DiffusionGemmaはGemini Diffusionと同じものですか?
DiffusionGemmaは通常のLLMと比べてどれくらい速いですか?
DiffusionGemmaをカスタマーサポートに使えますか?
DiffusionGemmaの運用コストはどれくらいですか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








