
Gemma 4とは正確には何か?
私はeeselでAIエージェントを構築しており、ここ数年でオープンモデルが「試してみると楽しい」から「有料顧客の前に出せるほど優秀」になっていく過程を観察してきました。毎日ライブのサポートキューでエージェントを稼働させており、あるお客様であるSmavaは自動エージェントで月間10万件以上のドイツ語チケットを処理しています。Googleが新しいオープンモデルをリリースするたびに、一つの視点から読みます:人間の監視なしに顧客に回答させて本当に信頼できるか?
Gemma 4はオープンモデルとしてこの問いに対する最も興味深い答えです。
簡単に言えば、GemmaはGoogle DeepMindのオープンモデルラインで、クローズドなGeminiモデルの小さくてダウンロード可能な親戚です。Gemma 4はGoogleのローンチポストによると「パラメータあたりの知能を最大化するためにGemini 3と同じ世界クラスの研究と技術から構築されています」。キーワードはオープンウェイトです:Googleは実際のモデルファイルを公開しているため、ネットワークからAPIコールを一切出さずに自分のラップトップ、サーバー、スマートフォンで実行できます。
また、マルチモーダルでもあります。すべてのモデルがテキストと画像入力を処理し、小さいモデルはネイティブオーディオを追加し、モデルカードでは2025年1月のトレーニングカットオフと140以上の言語サポートが示されています。RAG対LLMの解説記事を読んだ方には:Gemma 4はその絵の「LLM」部分、自分の知識に向けるリーズニングエンジンです。
5つのサイズとどれが自分に合うか
Gemma 4は1つのモデルではなく5つあり、実行される場所ごとに分類されています。これは他の何より先に理解する価値のある部分です。なぜなら間違ったサイズを選ぶのが私が見てきた最もよくある失敗だからです。
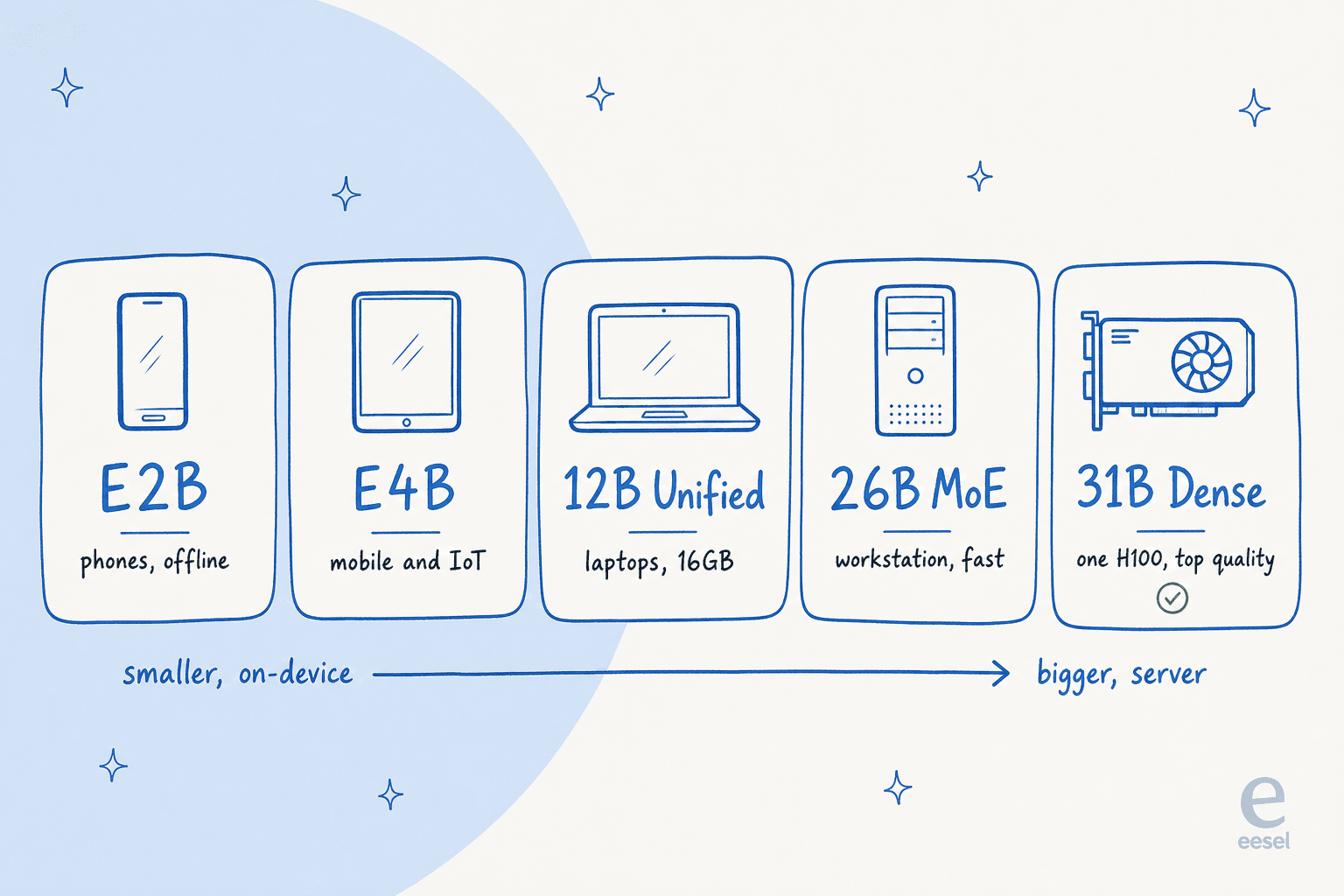
モデルカードから直接抜粋したスペック付きのラインアップです:
| モデル | 有効パラメータ | コンテキスト | モダリティ | 動作環境 |
|---|---|---|---|---|
| E2B | 2.3B(埋め込みで5.1B) | 128K | テキスト、画像、音声 | スマートフォン、Raspberry Pi、エッジ |
| E4B | 4.5B(埋め込みで8B) | 128K | テキスト、画像、音声 | ハイエンドスマートフォン、IoT |
| 12B Unified | 11.95B | 256K | テキスト、画像、音声 | ラップトップ(~16GB) |
| 26B A4B (MoE) | 25.2B合計、3.8Bアクティブ | 256K | テキスト、画像 | ワークステーション、低レイテンシ重視 |
| 31B Dense | 30.7B | 256K | テキスト、画像 | 80GB H100×1、最高品質 |
E2BとE4Bの「E」は有効パラメータを意味します。これらのモデルはPer-Layer Embeddingsと呼ばれるトリックを使ってメモリフットプリントを小さく保つことで、スマートフォンがほぼゼロレイテンシでオフライン動作できます。GoogleはPixelチームとQualcomm、MediaTekと共同開発したため、デモではなく実際のモバイルシリコン向けに最適化されています。
12B Unifiedは新参者で、2026年6月3日に追加されました。「ラップトップ対応」の選択肢であり、Googleが初めてネイティブ音声入力を備えた中型モデルです。31B Denseは純粋な品質の旗艦で、すべてのファインチューニングのベースとなっています。
中間の26Bがグループの中で最も巧みな設計です。独自のセクションに値します。
26Bモデルが20倍大きいモデルに匹敵できる理由
26BはMixture-of-Experts(MoE)モデルで、これを理解することがGemma 4の重要性を把握する最善の方法です。
通常の「密な」モデルは処理するすべてのトークンですべてのパラメータを起動します。MoEモデルはパラメータを多くの小さな「エキスパート」に分割し、各トークンに対して実際に必要な少数のみをオンにします。その仕組みは次の通りです:
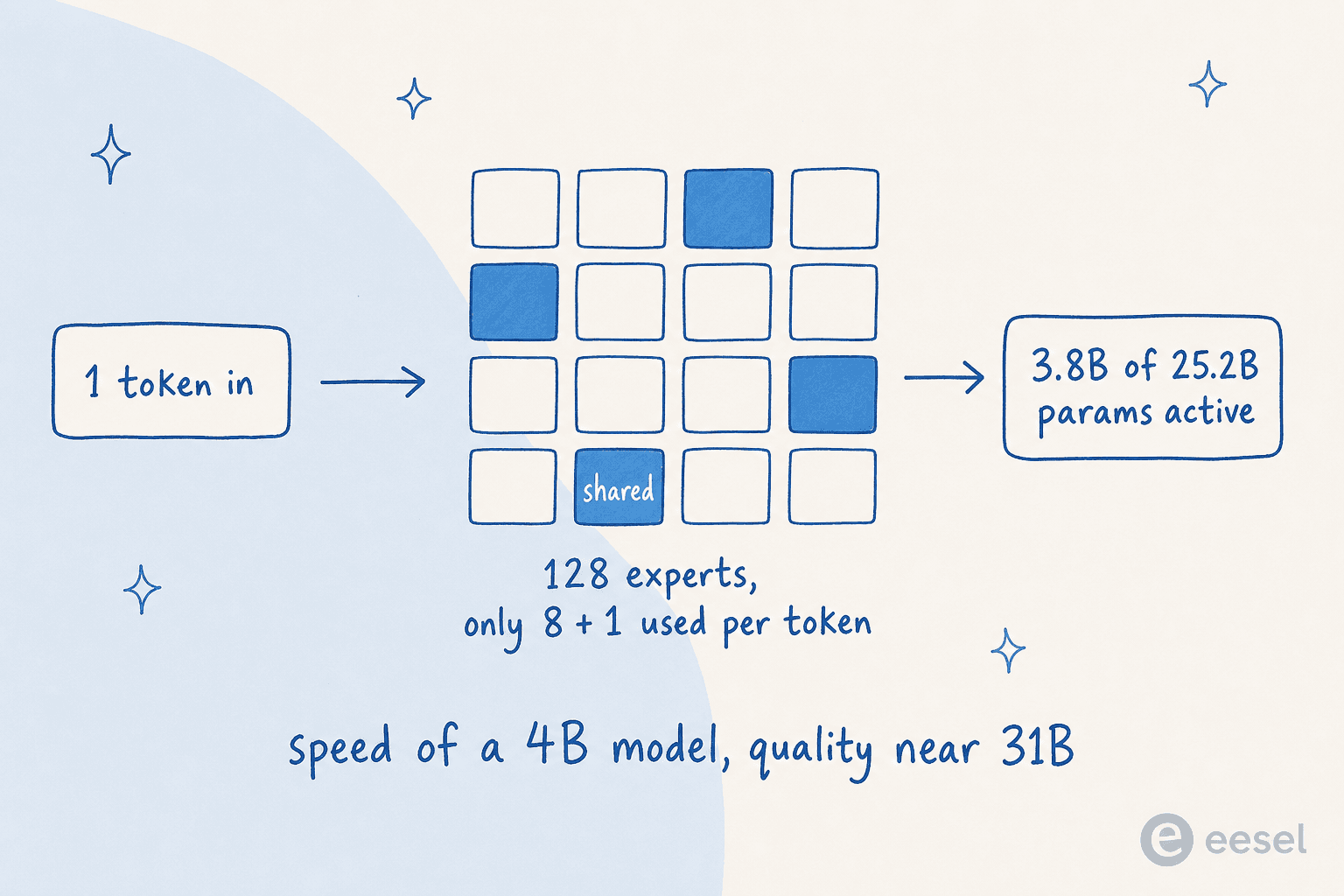
Gemma 4の26Bは25.2Bの総パラメータを持ちますが、128のエキスパートのうち8つと1つの共有エキスパートを経由してトークンあたり3.8Bのみがアクティブです。実際の結果:4Bの密なモデルとほぼ同じ速度で動作しながら、31Bに近い品質で回答します。(注意点:ルーティングのために25.2B全パラメータをメモリにロードする必要があるため、MoEは計算量を節約しますがRAMは節約しません。)
なぜ重要か?「より賢い」が「より大きく遅い」を意味するという古い前提を打ち破るからです。GoogleのパフォーマンスとサイズのグラフでGemma 4の中型モデルがどこに位置するかを見てください:
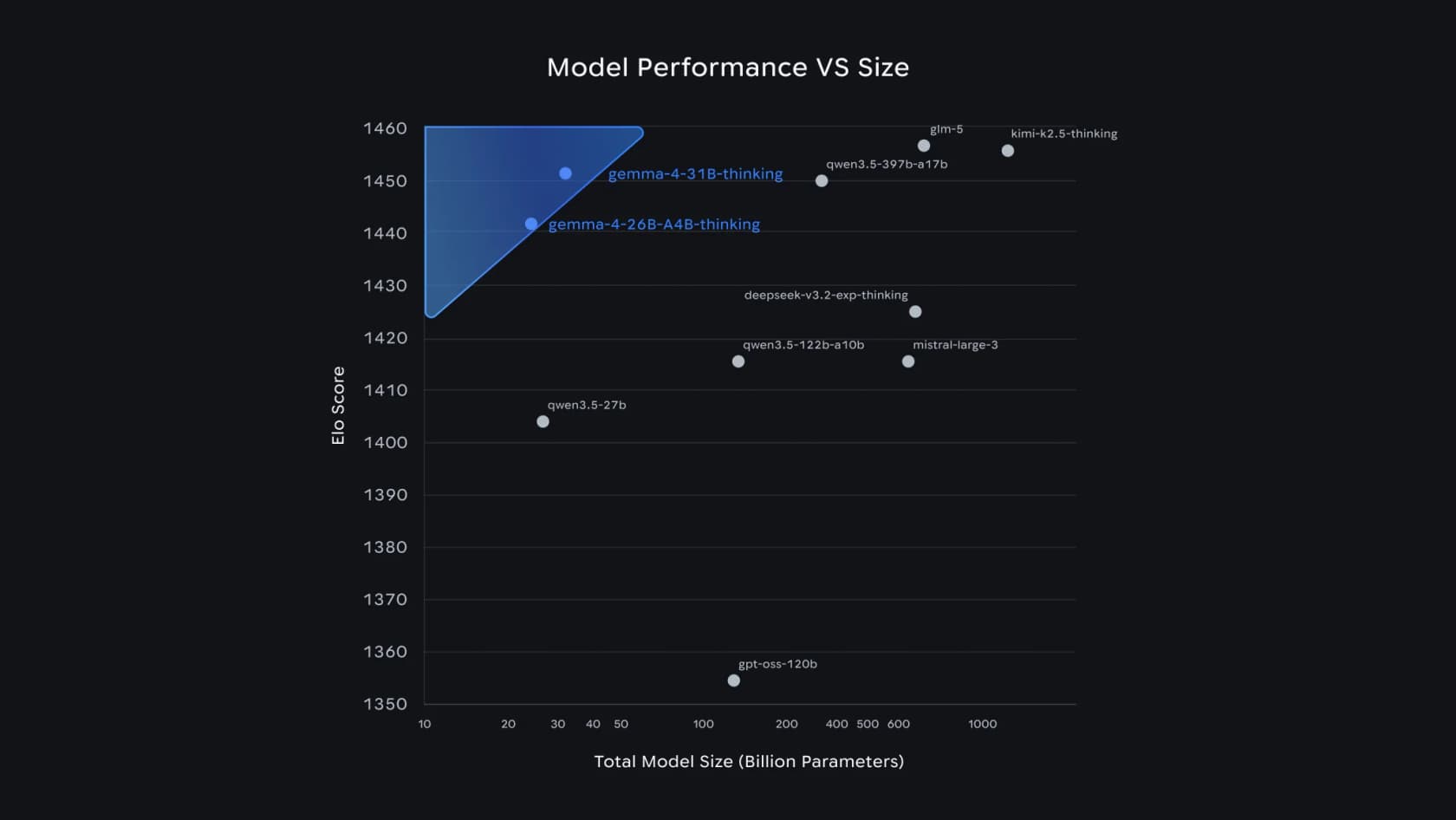
31BはArena AIのテキストリーダーボードでオープンモデル3位、26B MoEは6位で、だからこそGoogleは「Gemma 4は20倍のサイズのモデルを凌駕する」と主張できます。サポートチームにとってのポイントはリーダーボードの順位ではなく、その品質が自分たちが所有するハードウェアに収まるということです。
「オープンウェイト」の本当の意味(そしてライセンスが変わった理由)
「オープン」は曖昧に使われることが多いため、正確にします。なぜならここがGemma 4の最大の転換点だからです。
以前のGemmaモデルはカスタムの「Gemma利用規約」の下でリリースされていました。Gemma 4は標準のApache 2.0ライセンスに切り替えました。Googleの言葉によれば「商業的に許容的」であり、「データ、インフラ、モデルへの完全なコントロール」を付与します。Hugging FaceのCEOであるClément Delangueはこの動きを「大きなマイルストーン」と呼びました。
このライセンスが実践的に意味する違いは次の通りです:
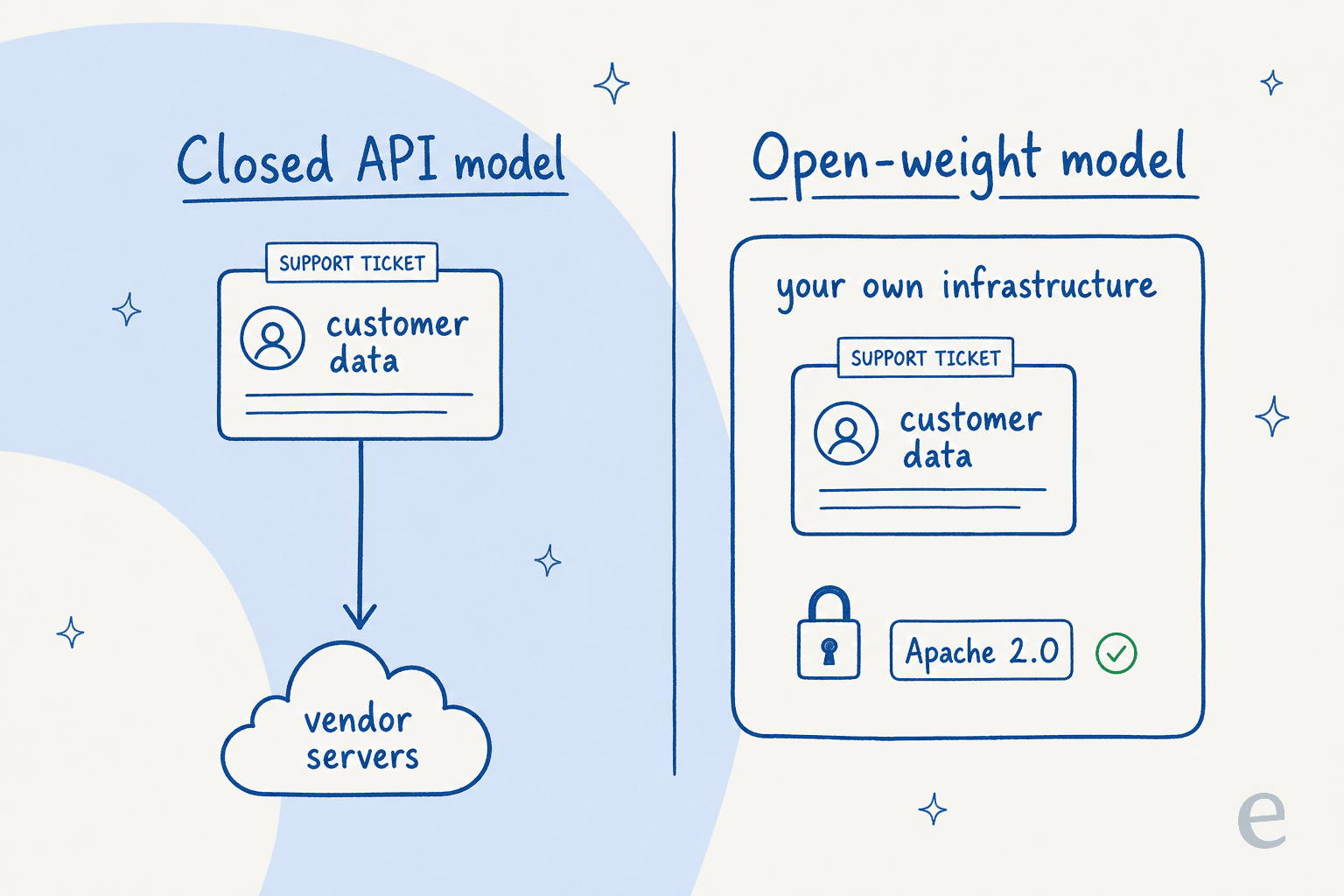
クローズドAPIモデルでは、処理するすべての顧客メッセージがベンダーのサーバーに送信されます。Apache 2.0のオープンウェイトモデルでは、自社インフラ内(オンプレミスまたは自社クラウド)ですべてを実行でき、データが外に出ることはありません。規制産業にいる人にとって、このデータ保管のコントロールがオープンモデルを気にする唯一の理由です。オープンソースのチケットシステムやオープンソースのチャットボットプラットフォームを選ぶ理由と同じです。
スケールアップのために、GoogleはGemma 4をVertex AI、Cloud Run、GKEで提供しており、Ollama、llama.cpp、vLLM、LM Studioなどセルフホスターがすでに使っているツールと初日から動作します。
ベンチマークとGemma 4が本当に輝く場所
次に数字です。Googleは命令調整済みのGemma 4モデルを前世代のGemma 3 27Bと比較した完全なベンチマーク表を公開しています:
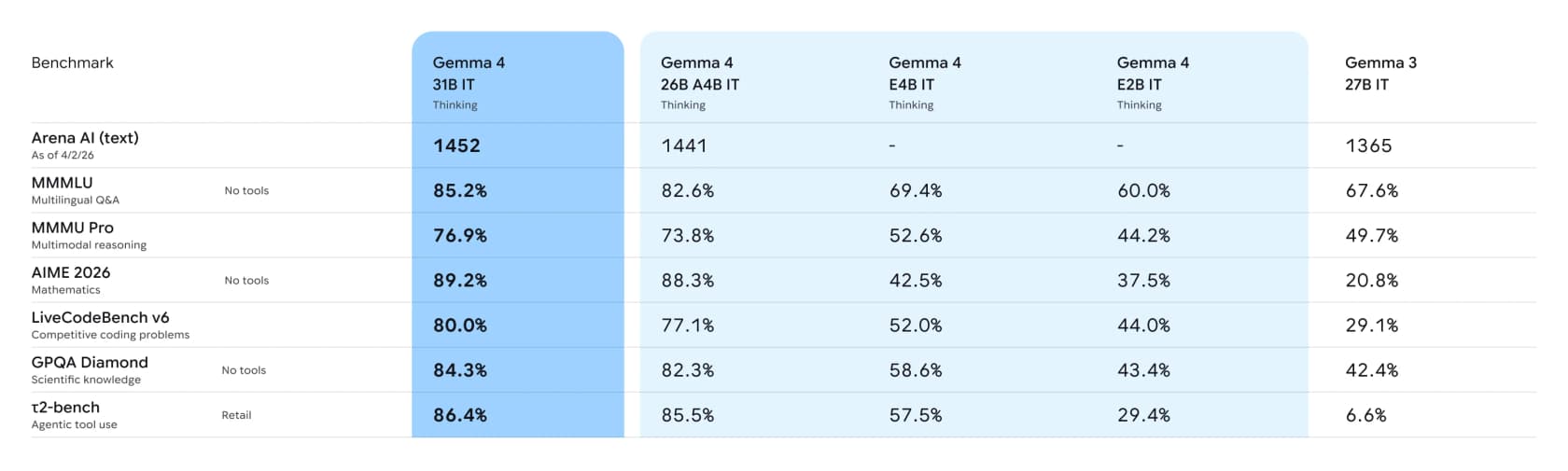
私が注目する行はエージェント型ツール使用です。タスクを完了するためにモデルが実際にツールを呼び出せるかテストするτ2-benchリテールベンチマークで、31BモデルはGemma 3の6.6%に対して86.4%を達成しています。これは段階的な改善ではなく、世代を超えた飛躍です。そしてこれがチャットボットを実際に仕事ができる何かに変える能力です。
クローズドな巨人に対しても健闘しています。Arena Eloでは、31Bの1452は15〜35倍のパラメータを持つモデルのすぐ後ろに位置します:
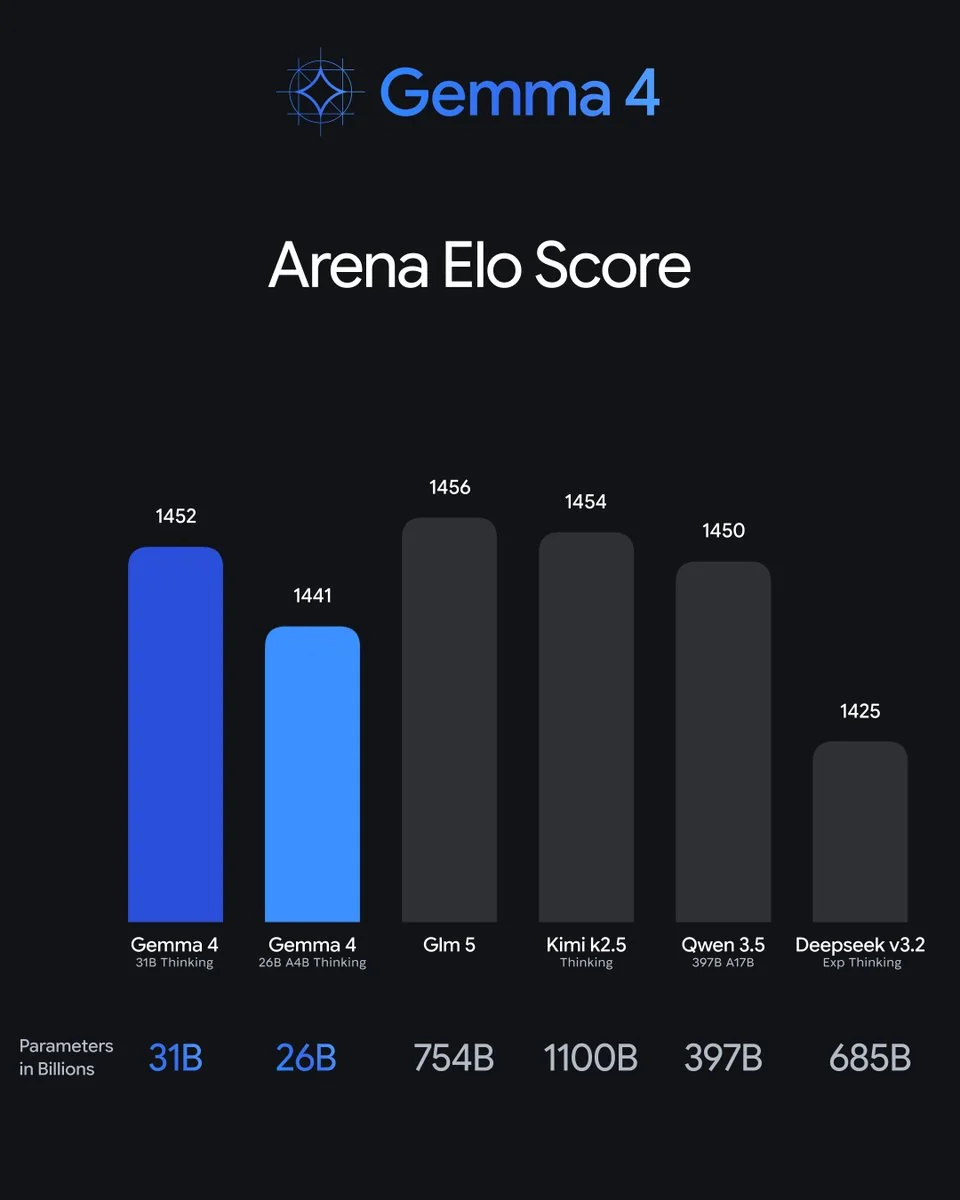
アーキテクチャ的に興味深い注記はSebastian Raschkaの分析にあり、Gemma 4はGemma 3から内部的に「ほぼ変わっていない」ため、飛躍は「おそらくトレーニングセットとレシピによるもの」とのことです。つまりGoogleはより良いデータで、新しいアーキテクチャではなくこの飛躍を達成したということで、静かに印象的な成果です。
実際に動かすとどうか
ベンチマークは一つのことです。実際にGemma 4を毎日動かしている人たちは何と言っているか?ローカルモデルコミュニティで調べました。そこに率直な意見があるからです。
称賛は一貫しています:高速で、メモリを食わず、冗長ではありません。
「M4Maxで超高速、そのスピードの割に驚くほど賢い。メモリをボロボロにしない。Qwenみたいに何時間も推論して(トークン予算を全部使い切って)なんてしない...openclaw、hermes、claude codeなどに最適。ローカルでこのモデルが大好き。今の定番モデル。」— u/styles01、r/LocalLLaMA
「何時間も推論しない」というポイントが繰り返し出てきます。マルチモーダルのユースケースで26Bと31Bを動かしているセルフホスターは実際の数字を示し、31Bで約149トークン/秒、26Bで88トークン/秒を報告し、「ベンチマークは大きなモデルと比べてどれほど冗長でないかを本当に捉えていない」と付け加えています。
しかしここに正直な限界があります。これが生のGemma 4をライブキューに無監督で置かない理由です:
「コーディング以外のすべてにおいてはるかに優れていることは同意する。[...] しかし、ウェイトやkvキャッシュがネイティブ以外の量子化だと大きく劣化する。」— u/fragment_me、r/LocalLLM
コミュニティの評価をまとめると:Gemma 4はウェイト以上の性能を発揮する優れたチャット・指示追従モデルで、2つの注意点があります。コーディングとエージェント型ワークフローは弱点で、ネイティブ量子化以外で実行すると顕著に劣化します。仕事に選ぶ前に知っておくべきことです。
カスタマーサポートへの意味
ここからサポートチームを運営する誰にとっても実践的になります。Gemma 4のようなオープンモデルは素晴らしい材料です。単独ではサポートエージェントではありません。
生のモデルは返金ポリシーを知らず、過去のチケットを参照できず、ヘルプデスクに接続されていません。監督なしに顧客の前に置くと、何年もかけて対策してきた失敗パターンが正確に起こります:自信に満ちた口調で静かに間違った回答をするボットです。モデルはエンジンで、実際の製品はその周りのすべて、知識、安全なルーティング、ツールへの接続、そして本番稼働前にテストする能力です。
この差こそが私たちのようなプラットフォームが存在する理由です。オープンウェイトの動きはモデル層のコントロールを与えますが、ほとんどのサポートチームはML Opsチームにもなりたくはありません。ほとんどの人にとって最善の答えは、インフラを自分で構築せずにデータコントロールと学習の利点を得ることです。それがモデルとAIカスタマーサービスプラットフォームの間に私が引く線です。
AIサポートのためにeeselを試す
Gemma 4について読んで「条件は自分次第でAIにチケットに答えてほしい」と考えたなら、それはeeselが解決するために作られた問題です。
eeselのAIヘルプデスクエージェントはすでに使っているツール(Zendesk、Freshdesk、Gorgias、Slack、その他100以上)に接続し、初日から過去のチケットとヘルプドキュメントから学習するので、長年の履歴が即座に知識になります。冒頭の「信頼できるか?」という問いに直接対応する部分:顧客が一人も見る前に、何千件もの過去のチケットに対してエージェントをシミュレートして、どのように回答したかを正確に確認できます。Gridwiseが最初の月にティア1リクエストの73%を解決できたのはそのためです。

使用量ベースで1チケットあたり$0.40から、席料なしで、クレジットカード不要で$50の無料使用量から始められます。エンジンとなるモデルがGemma 4であろうと何であろうと、本当に欲しいのはキューで信頼できるエージェントです。eeselを試してどう対応するか確認してください。
よくある質問
Gemma 4とは何ですか?
Gemma 4は無料で使えますか?
Gemma 4のモデルサイズは?
Gemma 4はラップトップやスマートフォンで動きますか?
Gemma 4はカスタマーサポートに適していますか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








