
拡散ベースのAIモデルとは何か?
拡散モデルは、段階的なノイズ付加プロセスを逆転させることでデータを構築する方法を学ぶ生成モデルです。この発想は物理学に由来します。実データにランダムなノイズを少しずつ加えていく一連のステップを定義し、そのプロセスを逆転させてノイズからサンプルを再構成するようネットワークを訓練します。基礎となる研究はSohl-Dickstein et al. (2015)と、2020年のノイズ除去拡散確率モデル(denoising diffusion probabilistic models)に関する論文です。
これには二つの半分があります。**順方向プロセス(forward process)**では、実際の画像を取り、それが完全な砂嵐(ノイズ)になるまで、少しずつガウスノイズを何度も加えていきます。この部分には学習は必要ありません。その唯一の役割は訓練ペアを作り出すことです。**逆方向プロセス(reverse process)**では、ニューラルネットワークが一度に1ステップ分のノイズを取り消す方法を学習します。生成時にはランダムなノイズから出発し、ネットワークを繰り返し実行し、各パスでもう少しずつ取り除いていき、一貫した結果が現れるまで続けます。
これをすんなり腑に落とす直感はこうです。氷の彫刻が溶けて水たまりになる様子を撮影し、そのフィルムを逆再生することを想像してください。形のない水たまりから出発し、フレームごとに彫刻へと再び凍らせていくのです。モデルは各ステップでキャンバス全体を扱うため、進めながら前の間違いを修正し続けることができます。
これは、現代のほとんどの画像・動画・音声生成を支える技術です。拡散はSora、Midjourney、Riffusionの背後にあり、DALL-E 2、Imagen、Stable Diffusionも同様です。共通の筋道は、いずれもノイズから出発し、あなたのプロンプトに導かれながら結果へと反復的にノイズ除去していくという点です。
自己回帰型LLMはどのようにテキストを生成するのか
拡散がテキストにとってなぜ大きな意味を持つのかを理解するには、対比が必要です。あなたが使ったことのあるほぼすべての大規模言語モデル(LLM)は、ChatGPT、Claude、Gemini、Llamaを含め、**自己回帰型(autoregressive)**モデルです。それはテキストを左から右へ、一度に1トークンずつ生成し、トークンはそれより前のすべてが存在するまで生成できません。
その設計からは二つの帰結が生まれ、どちらも比較において重要です。
- レイテンシは逐次的である。 各トークンの生成には、数十億のパラメータを通過する完全な順方向パスが必要なため、長い出力(長い推論トレースを思い浮かべてください)は、待ち時間とコストの両方を直接的に膨らませます。
- 後戻りできない。 トークンが一度出てしまうと、それは固定されます。モデルは後の単語を踏まえて前の単語を修正できません。この一方向の習性は、反転の呪い(reversal curse、モデルが「AはBである」を知っていても「BはAである」でつまずく現象)のような癖の原因とされています。
利点は、可変長の出力が簡単なことです。モデルは完了したらシーケンス終了トークンを出すだけです。その柔軟性は、自己回帰がテキストで支配的であり続けてきた理由の一つです。
拡散言語モデルはどのように違った形でテキストを生成するのか
拡散言語モデル(dLLM)は、画像のレシピをテキストに移植します。ノイズからピクセルを作る代わりに、マスクからトークンを作るのです。Google DeepMindはこれを率直に説明しています。テキストを直接予測するのではなく、モデルはノイズを段階的に洗練して出力を生成する方法を学ぶため、解に素早く反復し、生成中に誤りを訂正できる、と。
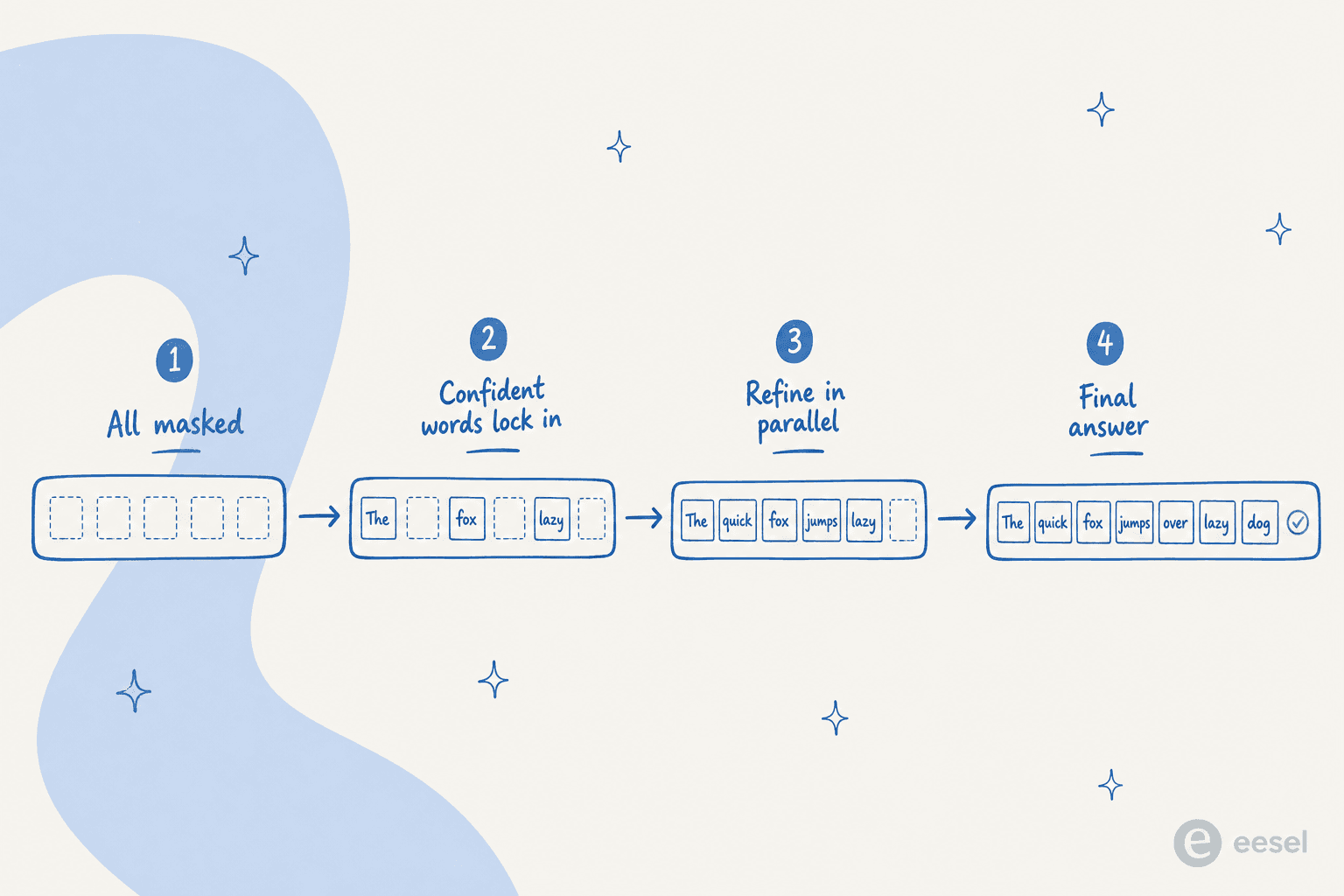
テキストにおける主流の手法は**マスク拡散(masked diffusion)**です。8Bのオープン拡散モデルであるLLaDAでは、順方向プロセスがトークンをマスクし、逆方向プロセスがトランスフォーマーの「マスク予測器」を使ってマスクされたトークンを一度にすべて埋め、完全にマスクされた状態から完全に書かれた状態への拡散をシミュレートします。それ以前の系統であるDiffusion-LMは、代わりに単語ベクトル上の連続拡散を使いました。
目玉となる違いは**並列デコーディング(parallel decoding)**です。dLLMはトークンを一度に1つずつではなく並列で生成し、基盤となるトランスフォーマーは複数のトークンを同時に変更して回答を全体的に改善できます。定式化が非自己回帰的であるため、**任意順序生成(any-order generation)**も可能になります。モデルはシーケンス内のどこであれ確信のある単語を先に確定させ、それから残りを埋めることができます。
最も明快な説明の一つは、実はHacker Newsの開発者から出てきたもので、「拡散がトランスフォーマーを置き換える」という混乱を断ち切るものでした。
「名前に反して、拡散LMは画像拡散とはほとんど関係がなく、BERTや古き良きマスク言語モデリングにずっと近い……ゼロから何かを生成するには、まずモデルにすべての[MASK]を与えることから始める……10ステップでシーケンス全体を生成し終えているだろう。」nvtop、Hacker NewsでのGemini Diffusionの議論より
その並列・双方向の見方は、拡散モデルがなぜギャップの両側のコンテキストを見られるのかの理由でもあります。例えばLLaDAは、左から右へのモデルをつまずかせる反転の呪いを克服し、反転詩の補完タスクでGPT-4oを上回ります。
自己回帰型 vs 拡散型:核心的な違い
この記事から一つの絵だけ覚えるなら、これにしてください。自己回帰型モデルはリレー競走のように文を組み立て、各単語が次へとバトンを渡します。拡散型モデルはポラロイド写真を現像するように文を組み立て、画像全体が一度に浮かび上がり、パスごとに鮮明になっていきます。
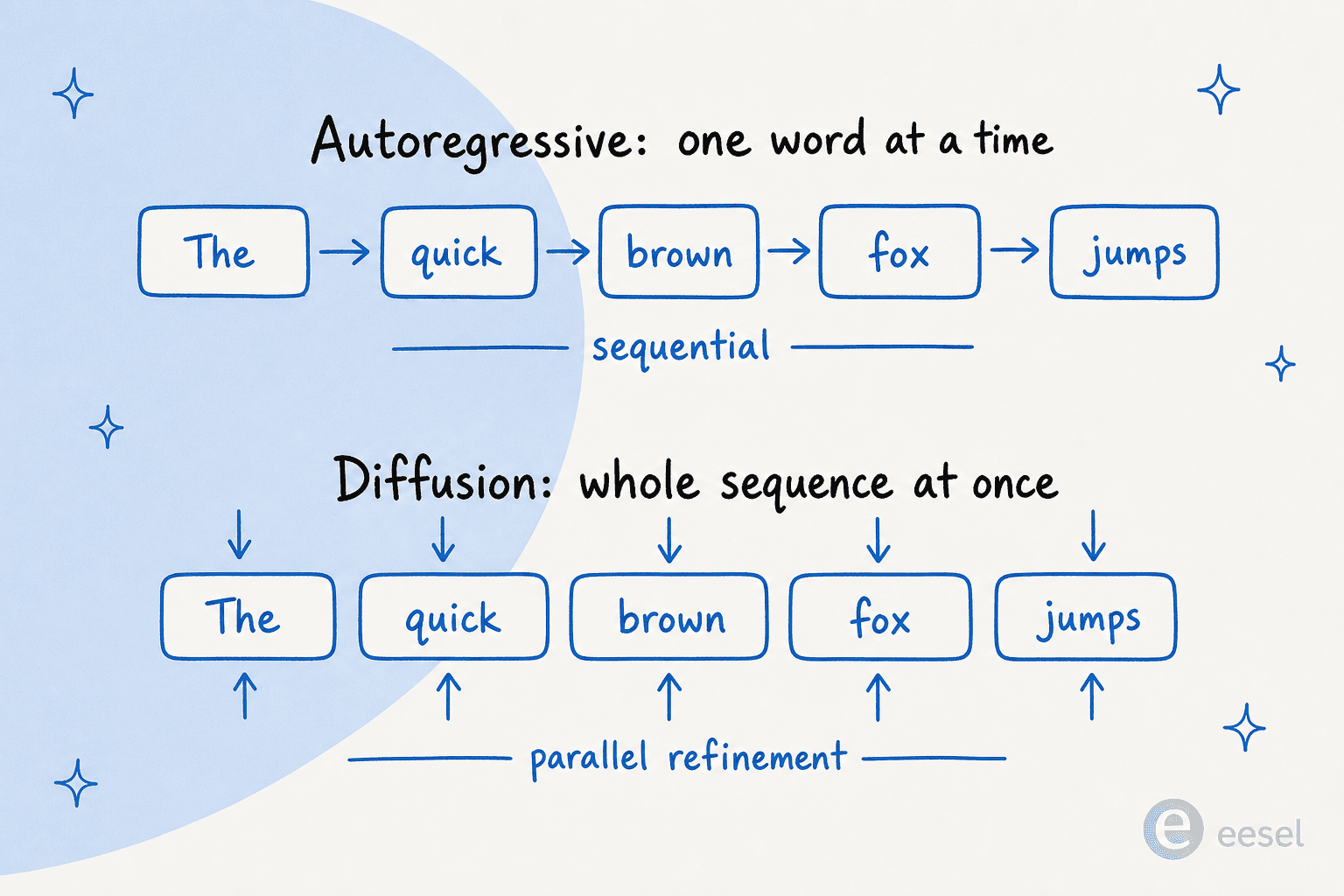
買い手が実際に気にする観点で、この二つがどう比較されるかは次のとおりです。
| 観点 | 自己回帰型(GPT、Claude、Gemini) | 拡散型(Mercury、Gemini Diffusion) |
|---|---|---|
| 生成順序 | 左から右へ、一度に1トークン | シーケンス全体を並列で、任意順序 |
| 速度 | 数十〜約200トークン/秒 | 約1,000〜1,500トークン/秒 |
| 前のトークンを修正できるか? | いいえ、一度出たら固定 | はい、ノイズ除去パスをまたいで可能 |
| 編集とインフィリング | ぎこちない(追記のみ) | 自然(両側を条件にできる) |
| 難しい推論 | 現状では強い | 後れを取る、特にフロンティア規模で |
| 長いコンテキスト | より効率的(KVキャッシュを再利用) | より弱い(パスごとにアテンションを再計算) |
| 出力長 | 可変、柔軟 | しばしば固定長ブロック |
| エコシステムの成熟度 | 5年分のツール群 | 初期段階、急速に進展中 |
対称性に注目してください。拡散の勝ち点(速度、修正、インフィリング)も負け点(推論の深さ、長いコンテキスト、成熟度)も、いずれも同じ根本原因に遡れます。シーケンス全体を並列で扱うことが、それを高速かつ編集可能にする一方で、長いコンテキストと段階的な推論をより難しくしているのです。
速度の見返りと、その落とし穴
速度の数字は本当に目を見張るもので、すべてがマーケティングというわけではありません。開発者でありLLMブロガーのSimon Willisonは、Gemini Diffusionのウェイトリストを通過して試しました。
「では鍵となる特徴は速度だ。ウェイトリストを通過して、たった今試してみたが、いやはや、彼らが速いと言っているのは冗談ではない。」Simon Willison、Gemini Diffusionの第一印象
いくつかのモデル間でスループットがどう比較されるかを、文脈として自己回帰型のベースラインとともに示します。
| モデル | 種類 | スループット(トークン/秒) | 出典 |
|---|---|---|---|
| Gemini Diffusion | 拡散型 | 約1,479(オーバーヘッド除く) | ベンダー |
| Mercury 2 (Inception) | 拡散型 | 約1,196ピーク | Artificial Analysis |
| Mercury Coder Mini | 拡散型 | 1,109 | ベンダー、AAが裏付け |
| Gemini 2.0 Flash-Lite | 自己回帰型 | 約201 | Inceptionによる |
| Claude 4.5 Haiku | 自己回帰型 | 約89 | Inceptionによる |
| GPT-5 Mini | 自己回帰型 | 約71 | Inceptionによる |
ここで正直に押さえておくべきことが二つあります。第一に、ほとんどのスループットの数字はNVIDIA H100上で測定され、その多くはベンダーの主張です。Artificial Analysisが主要な独立した出典であり、Mercuryの速度は裏付けたものの、品質はまだ裏付けていません。第二に、速度の優位性は本物ですが条件付きです。高品質な生成には通常、多くのノイズ除去ステップが必要で、安易にステップを削ると品質が急激に低下しますので、速度は慎重に使う必要があります。
そして品質のギャップは依然として目に見えており、特に難しいタスクでそうです。Gemini Diffusionは、いくつかのコードと数学のベンチマークでは先行しているにもかかわらず、Flash-Liteに対してGPQA Diamondで40.4%対56.5%、Global MMLUで69.1%対79.0%というスコアです。本番のエージェントスタックに携わるエンジニアの率直な見解は引用する価値があります。歴史的な問題を直接名指ししているからです。
「[初期の拡散LMは]壊れた時計が速いのと同じ意味で速かった——間違った答えにどれだけ速くたどり着けても意味がない。」vainkop、「Mercury 2 and the End of Autoregressive Monopoly」
今日のチームへの彼の評価は慎重です。これは「自分のエージェントスタックを今すぐ書き直せ」という瞬間ではなく、「注意深く追い、素早く動く準備をしておけ」という瞬間だ、というものです。
先頭を走るモデルたち
この分野は、研究上の物珍しさから出荷可能な製品へと急速に移行しました。資金調達のシグナルは大きく鳴り響いています。StanfordのStefano Ermonによって設立されたInception Labsは、2025年11月に5,000万ドルを調達しました。その戦略的な顔ぶれにはNvidia、MicrosoftのM12、Databricks、Snowflakeが含まれ、さらにエンジェルのAndrew NgとAndrej Karpathyも名を連ねています。インフラのプレイヤーが賭けるとき、彼らはその速度が提供可能だと考えているのです。
| モデル | 提供元 | ステータス | 際立つ点 |
|---|---|---|---|
| Mercury / Mercury 2 | Inception Labs | API稼働中、100万トークンあたり$0.25 / $0.75 | 初の商用拡散LLM;約1,196トークン/秒 |
| Gemini Diffusion | Google DeepMind | 実験的、ウェイトリスト | 約Gemini 2.0 Flash-Liteの品質を数倍の速度で |
| DiffusionGemma | Google DeepMind | オープンウェイト(Apache 2.0)、2026年6月 | 26Bのmixture-of-experts;1,000トークン/秒超、品質はGemma 4以下 |
| LLaDA 8B | ML-GSAI(研究) | オープンウェイト | MMLU 65.9、ほぼLlama3 8Bに匹敵 |
| Dream 7B | HKU NLP + Huawei | オープンウェイト | 計画タスクで圧倒(数独 81.0 対 Qwenの21.0) |
名前が紛らわしいほど似ているので、手短に明確化しておきます。「Gemini Diffusion」(クローズド、ウェイトリスト)と「DiffusionGemma」(オープンウェイト)は、Googleの二つの異なるリリースです。前者はGoogle I/O 2025で披露された実験的なホスト型モデルで、後者は2026年6月10日にApache 2.0でリリースされたダウンロード可能な26Bモデルで、256トークンのブロックを並列でノイズ除去して生成し、公開されたすべてのベンチマークで標準的なGemma 4を下回っています。品質と引き換えの速度を、オープンに取引しているわけです。
これらすべてに共通するパターンは、小規模・中規模では品質ギャップを縮める10倍超のスループット優位性(LLaDAはほぼLlama3 8Bに匹敵、Mercuryはコードで競争力あり)ですが、フロンティアでは依然として現れます。今日の主要なユースケースはコード生成と、並列デコーディングの速度が積み重なる低レイテンシのエージェント的ループです。
なぜ拡散ベースのAIモデルはビジネスにとって重要なのか
モデルを製品の中に組み込むと、速度はもはや見栄えだけの指標ではなくなります。最も明快な捉え方は本番運用の経験から来ています。自己回帰型システムでは、レイテンシはチェーンの中で積み重なります。
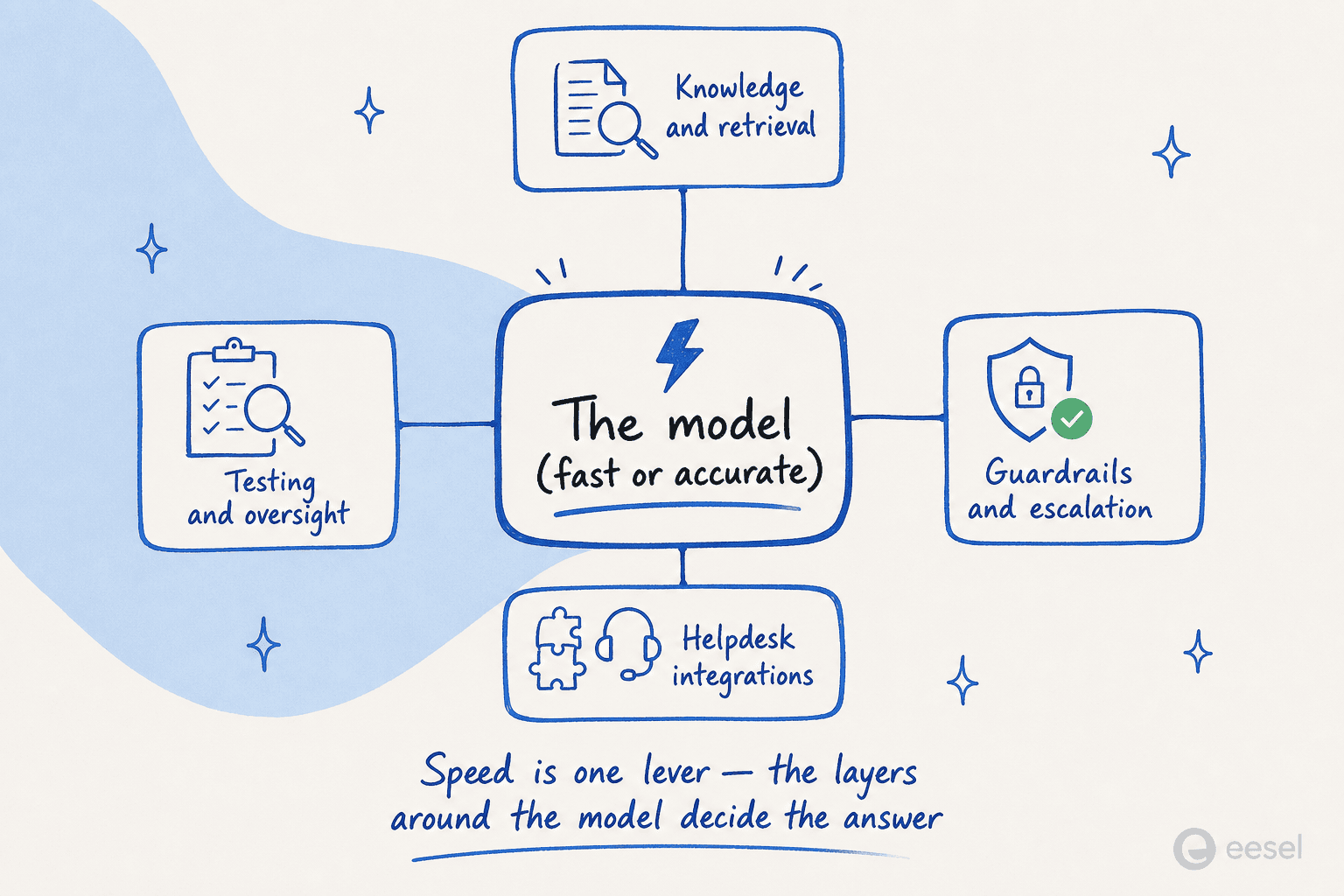
あるエンジニアが説明したように、モデルを3回呼び出す(推論、計画、実行)単一のエージェントステップは、3回の逐次パスです。それをいくつか連鎖させると7〜8秒に達し、それは「リアルタイムのエージェントではなく、遅いバッチジョブだ」ということになります。ステップごとの生成が速くなれば、より深いAIエージェントのチェーンが手の届くものになります。同じ記事は、チームが現在SLAを守るためにチェーンの深さを3〜5ステップに抑えていると指摘しています。拡散速度の推論があれば、10ステップのチェーンが実現可能に見え始めます。
速度が報われる具体的な場面をいくつか挙げます。
- リアルタイムチャットとコパイロット。 そのエンジニアの言葉を借りれば、サブ秒の応答は、SaaS製品のアシスタント層にとって「採用されるか見放されるかの違い」です。
- 大量バッチテキスト。 要約、分類、再フォーマット、翻訳はスループット律速で並列化可能であり、まさに拡散が輝く領域です。
- コーディングアシスタント。 拡散のインフィリングの性質はコード編集に適しており、ブロックの先頭と末尾を同じパスで生成し、途中を編集できます。
そしてコストの問題があります。同じハードウェア上でより速く生成できるということは、トークンあたりの推論コストが下がることを意味します。そしてInceptionの共同創業者は、このアプローチは「転送されたメモリ単位あたりより多くの計算を行う」と主張しており、これが古いハードウェアでAI推論コストを削減する新たな方法を開くとしています。1日に数十万件のエージェント呼び出しを実行するチームにとって、これは積み重なります。Mercury 2の公開価格である入力100万トークンあたり$0.25、出力100万トークンあたり$0.75は本当に安価です。
しかし、ここがほとんどの報道が飛ばしている部分です。ほとんどの本番アプリにとって、自己回帰型モデルは依然としてデフォルトであり、それには正当な理由があります。それらは長いコンテキストをより効率的に扱い、より深く推論し(拡散はトークンあたりの仕事が少ないため、「考える」余地が少ない)、5年分のツールを背後に持っています。現実的な一手は置き換えではなくルーティングです。単純で高頻度のステップ(検索、整形、分類)は高速な拡散モデルに送り、深い推論にはフロンティアの自己回帰型モデルを取っておくのです。それをAIエージェント対人間エージェントのコストの経済性と比べれば、その魅力は明らかです。安価な仕事を、より多く安価にこなすのです。
AIカスタマーサポートにとって何を意味するのか
カスタマーサポートは、一見すると完璧な拡散のユースケースに見えます。ライブチャットとAIサポートエージェントは、まさに1秒対数秒の差が、体験を反応が良いと感じさせるか、もたついていると感じさせるかを決める、低レイテンシでユーザー向けのシナリオです。より速いモデルは、AIチャットボットでのよりキビキビした応答を意味するはずです。
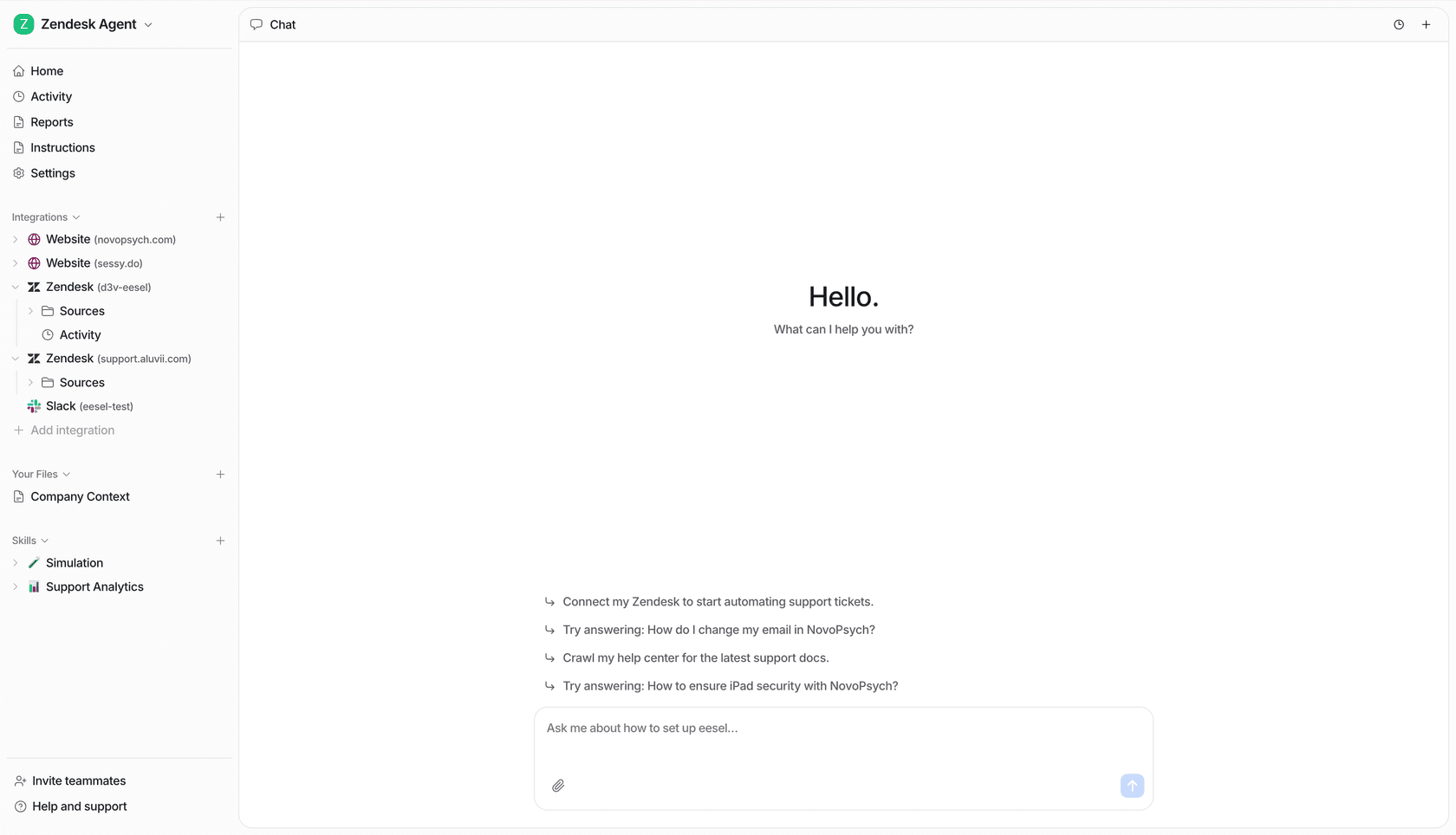
じっくり考える価値のある捉え直しはこうです。サポートチームにとって、モデルのアーキテクチャは、それを取り巻くオーケストレーションよりはるかに重要度が低いのです。実際のサポートの回答は、ゼロから生成されることはほとんどありません。それはあなたのナレッジベース、チケット履歴、ポリシー文書に基づいて根拠づけられた回答です。これは、拡散の弱点である長いコンテキストの扱いを、サポートのユースケースのまさに進路上に置きます。そしてそれは、検索の品質、知識の新しさ、ガードレールが、最終トークンが左から右に出されたか並列で出されたかよりも、はるかに回答を左右することを意味します。
ありていに言えば、古い知識や弱いエスカレーションルールにつながった高速なモデルは、間違った回答をより速く生み出すだけです。壊れた時計の問題を、サポートに当てはめたものです。これはまた、AIチャットボットの問題が、なぜそれほど基盤モデルに起因することが少なく、根拠づけ、テスト、そして実際に追跡すべき指標に起因することがそれほど多いのかの理由でもあります。
そこで本当に役立つアドバイスは、モデルに依存しない姿勢を保つことです。それが来年のより速い拡散モデルであれ、より賢い自己回帰型モデルであれ、基盤となるモデルがあなたの足元で改善していけるような層を選びましょう。拡散から最も恩恵を受けるチームは、まず堅固なオーケストレーションの上に構築し、モデルを差し替え可能な部品として扱ったチームです。
eeselを試す
これこそ、eesel AIが構築されている方法そのものです。一つのモデルアーキテクチャに賭けるのではなく、eeselはオーケストレーション層です。初日からあなたの過去のチケット、ヘルプドキュメント、ツールから学習し、その後、あなたがすでに使っているヘルプデスク全体で返信を下書きし、トリアージし、エスカレーションします。確信度ベースのルーティングにより、確信度の低い回答は本番公開されず下書きのままに留まります。

このトピックにとって重要な差別化要因は、シミュレーションモードです。これはあなたの過去のチケットに対してエージェントを実行するので、本番公開前にカバレッジを確認し、ギャップを修正できます。これこそ、高速なモデルが自信満々に間違った回答を出荷するのを止める方法です。100以上の連携と80以上の言語にわたって動作するので、来年どのモデルが最速・最賢になろうと、あなたのサポート環境は機能し続けます。クレジットカード不要でeeselを無料で試すことができます。
よくある質問
拡散ベースのAIモデルとは、簡単に言うと何ですか?
拡散ベースのAIモデルは、通常のLLMより実際に速いのですか?
自社のビジネスは拡散言語モデルに切り替えるべきですか?
AIカスタマーサポートにとって、モデルのアーキテクチャは重要ですか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








