
まとめ
Hugging Faceの料金には5つの独立した課金体系があります:ベースアカウントプラン(無料〜Enterprise)、オンデマンドで起動するSpacesのハードウェア、Inference Providersを通じたサーバーレス推論、Inference Endpointsによる専用モデルデプロイ、そしてストレージです。多くの混乱は、プランの価格がHubのシート分のみをカバーしており、モデルを実行するたびに別途コンピュート料金が発生するという事実から来ています。
簡単にまとめると:無料プランは探索目的には十分な機能を備えています。月額$9のPROは個人開発者に最もコストパフォーマンスが高く、主にZeroGPUクォータの増加とSpaces Dev Modeが理由です。月額$20/ユーザーのTeamは、チームでの共同作業が始まってから意味を持ちます。月額$50+/ユーザーのEnterpriseでSSOと監査ログが利用可能になり、組織がこれらを必要とするなら価値があります。専用のInference Endpointsを運用する場合は予算を慎重に組んでください:常時起動のT4 GPU 1台が$0.50/時、1リクエストも処理する前から年間約$365かかります。
実際に何に課金されるのか
Hugging Faceの料金でよくある誤解は、アカウントプランの価格が総コストだと思い込むことです。そうではありません。Metactoの2026年コストガイドには次のように書かれています:「これらのプランはモデルの実行コストをカバーしていません。遊園地への入場料のようなもので、アトラクションには別途料金がかかります。」
アカウントプラン(無料・PRO・Team・Enterprise)はHubのサブスクリプションです。リポジトリのホスティング、ストレージ、コラボレーション機能、ガバナンス管理が含まれます。モデルの実行は別の請求書になり、3つの異なるシステムに分かれています:Spaces(オプションのGPUを持つデモ・アプリホスティング)、Inference Providers(サードパーティのモデルAPIへのサーバーレス転送)、Inference Endpoints(自分で管理する専用の常時起動インフラ)。
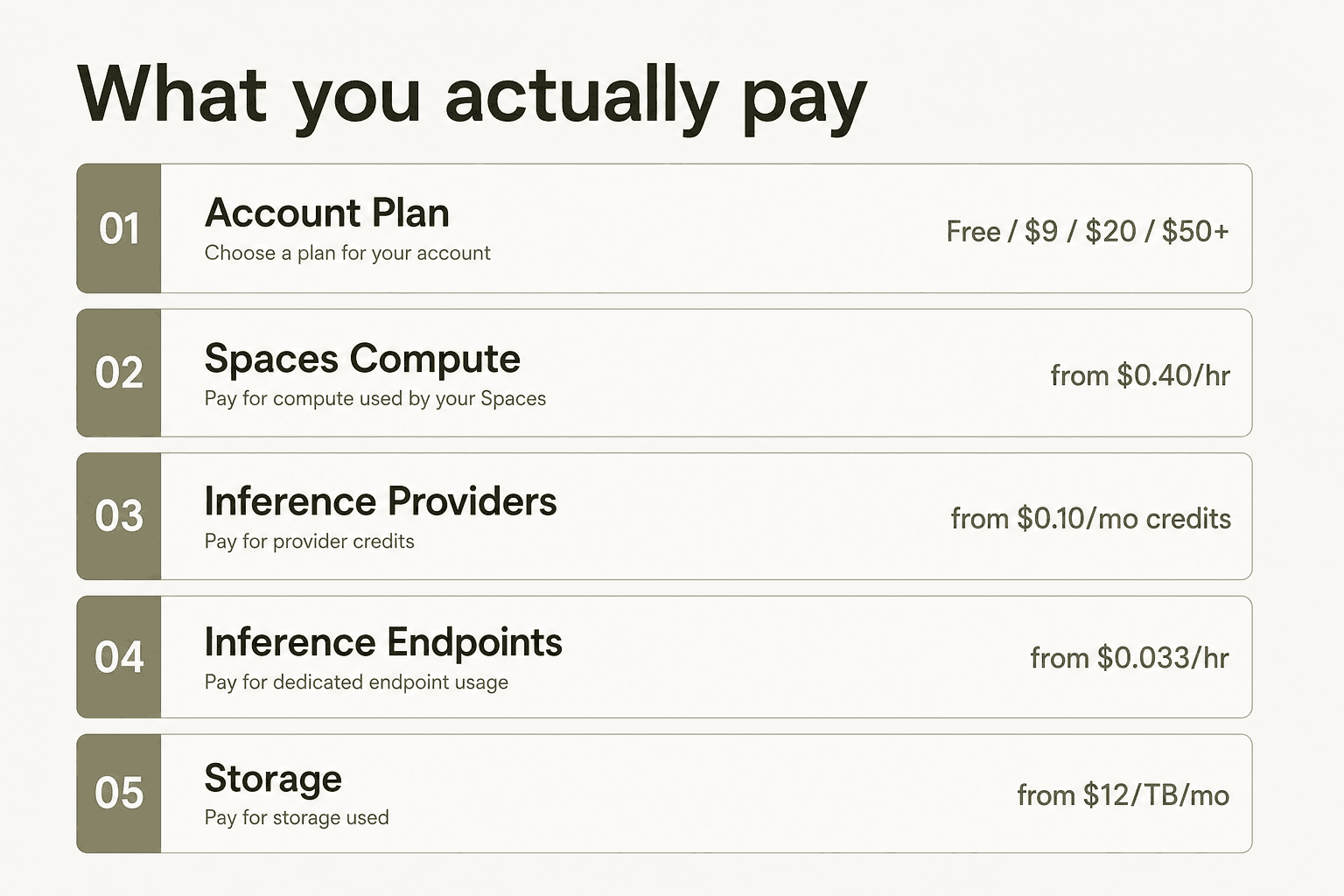
この分離を理解することが、Hugging Faceの価格表を正確に読むための前提条件です。
アカウントプラン
無料
無料プランは多くの人が期待する以上に充実しています。Hubで200万以上のモデル、50万以上のデータセット、100万以上のSpacesにアクセスでき、100 GBのプライベートリポジトリストレージ、コミュニティZeroGPUアクセス、月$0.10のInference Providerクレジットが含まれています。このクレジットは本番環境では長くは持ちませんが、小規模な実験には十分です。
含まれないもの:SSO、監査ログ、リソースグループ、優先キューなし。Inference APIのレート制限は有料プランよりも明らかに厳しいです。無料プランは、エコシステムを学んでいる方や時折実験を行う方に最適です。チームで本番サービスを提供する場合には向いていません。
PRO - 月額$9
これが料金ページで最も明確な価値の飛躍です。月額$9で、PROには次が含まれます:
- ZeroGPUクォータが8倍、最優先キュー(1日40分 vs 無料の5分)
- 1 TBのプライベートストレージ(100 GBから増加)
- 月$2のInference Providerクレジット(無料の20倍)
- Spaces Dev Mode - SpaceへのSSHとVS Codeアクセスで、再デプロイなしに素早くイテレーション可能
- 非公開トレーニングデータを扱うためのプライベートDataset Viewer
- 新しいHub機能への早期アクセスとPROバッジ
ZeroGPUクォータの増加が主な魅力です。ZeroGPUは全ユーザーに共有プールのNvidia RTX Pro 6000 Blackwell GPUへのアクセスを時間課金なしで提供しています。ただし、無料プランのユーザーは1日約5分のGPU時間でクォータに達します。PROは優先スケジューリング付きで40分に拡張されます。
SaaSLensは2026年3月のレビューでHugging Faceを4.7/5と評価し、「個人創業者向けの最高評価ツールの一つ」と呼び、PROプランについては「コーヒー数杯分のコストでエンタープライズグレードのGPUアクセスが得られる」と評しました。妥当な評価です。専用インフラなしでGPUバックのデモを実行したい場合は、常にPROを選択する価値があります。
Team - ユーザーあたり月額$20
Teamは最初の組織レベルのプランです。課金はシートごとに切り替わり、Hugging Face組織の全メンバーが月$20を支払います。組織内の全員がPROの特典を受けられるほか、次の機能が追加されます:
- 12 TBのベースパブリックストレージ + シートあたり1 TBパブリック + シートあたり1 TBプライベート
- シートあたり月$2のInference Providerクレジット(組織全体でプール)
- Inference Providersの組織レベルの課金管理 - 支出上限の設定と特定プロバイダーの無効化
- Hugging Faceチームからの優先サポート
- 全メンバーがZeroGPUクォータ8倍の恩恵を受けられる
Inference Providersの課金管理は、個人メンバーが高価なフロンティアモデルで誤ってコストを積み上げてしまう可能性がある研究チームにとって特に役立ちます。管理者は組織の月間支出を上限設定し、特定のプロバイダーをオフにできます。
重要な注意点:TeamにはSSO、監査ログ、リソースグループが含まれていません。これらはEnterpriseのみです。チームが社内のIDプロバイダーと連携したり、コンプライアンスレポートを生成する必要がある場合、人数にかかわらずTeamでは不十分です。
Enterprise - ユーザーあたり月額$50〜
Enterpriseでガバナンス機能一式が利用可能になります。$50/ユーザー/月は最低価格で、大規模契約ではボリュームコミットメント、年次課金、カスタムSLAについてHugging Faceのセールスチームと交渉します。主なEnterpriseの顧客にはNVIDIA、Google、OpenAI、Meta、Salesforce、IBM Research、Shopify、Robloxが含まれます。
このプランにチームを移行させる機能:
SSOはIDプロバイダー(Okta、Azure AD、Google Workspace、またはSAML/OpenID Connect準拠のIdP)と連携します。Enterprise Plusでは自動ユーザープロビジョニング用のSCIMが追加されます。
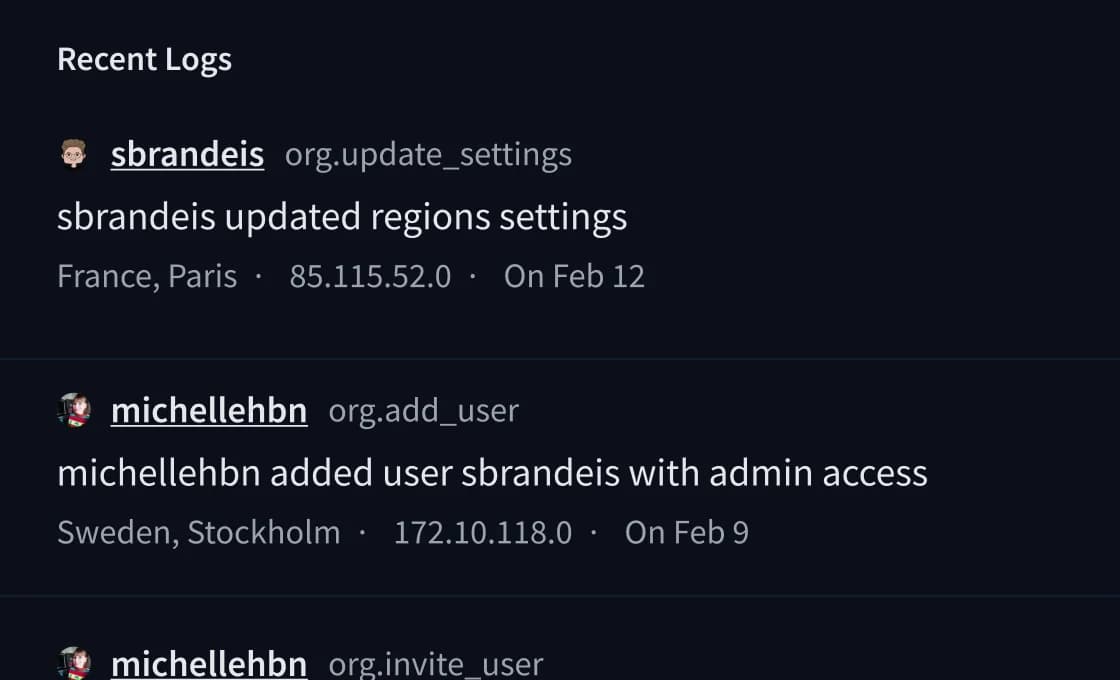
監査ログはすべての組織アクション(誰が何を、どこから、いつ変更したか)をユーザー属性、IPアドレス、場所とともに記録します。SOC 2 Type IIレビューやGDPRコンプライアンス文書に役立ちます。
リソースグループを使うと、管理者がリポジトリを名前付きグループに割り当て、ユーザーごとにREAD、WRITE、CONTRIBUTORアクセスを付与できます。単一の組織内で研究・本番・実験ワークスペースを分離するのに便利です。
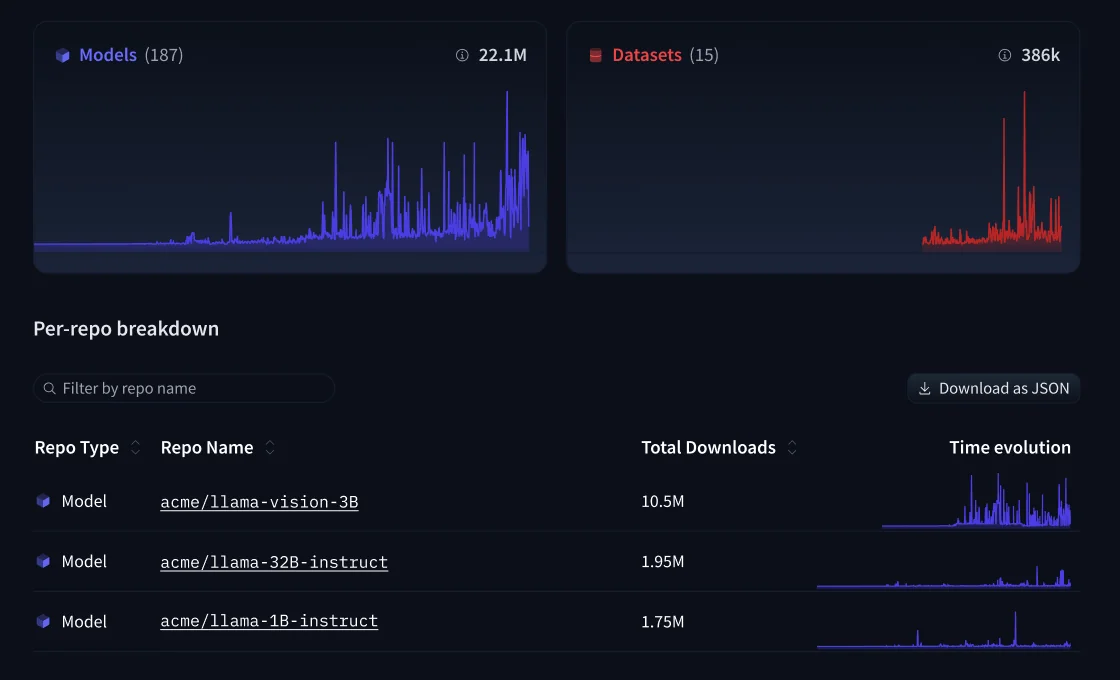
リポジトリ分析は組織全体のダウンロードトレンド、モデル使用状況、データセットアクセスを一つのダッシュボードに表示します。実際に使用されている内部モデルを把握するのに役立ちます。
データレジデンシーでは、リポジトリが保存される地理的地域を選択・監査できます。GDPRやデータ主権の要件に関係します。Enterprise Plusではネットワークセキュリティ制御とIPホワイトリストが追加されます。
Enterpriseのストレージは充実しています:200 TBのベースパブリックストレージ + シートあたり1 TB、大規模契約では1 PBまでスケール可能。
プランの比較一覧
| 無料 | PRO | Team | Enterprise | |
|---|---|---|---|---|
| 価格 | $0 | $9/月 | $20/ユーザー/月 | $50+/ユーザー/月 |
| プライベートストレージ | 100 GB | 1 TB | 1 TB/シート | 1 TB/シート |
| パブリックストレージ | ベストエフォート | 最大10 TB | 12 TB + 1 TB/シート | 200 TB + 1 TB/シート |
| 推論クレジット | $0.10/月 | $2/月 | $2/シート/月 | $2/シート/月 |
| ZeroGPUクォータ | 標準 | 8倍 + 優先 | 8倍(全メンバー) | 8倍(全メンバー) |
| Spaces Dev Mode | なし | あり | あり | あり |
| プライベートDataset Viewer | なし | あり | あり | あり |
| 組織課金管理 | なし | なし | あり | あり |
| SSO | なし | なし | なし | あり |
| 監査ログ | なし | なし | なし | あり |
| リソースグループ | なし | なし | なし | あり |
| リポジトリ分析 | なし | なし | なし | あり |
| データレジデンシー | なし | なし | なし | あり |
| 優先サポート | なし | なし | あり | あり(専任) |
| 年次契約 | なし | なし | なし | あり |
Spacesハードウェア料金
SpacesはHubにホストされるインタラクティブなMLアプリとデモです。CPU Basicプランは無料で、GPUプランはSpaceが動作している間、時間単位の従量課金です。
| ハードウェア | vCPU | RAM | アクセラレーター | VRAM | 時間単価 |
|---|---|---|---|---|---|
| CPU Basic | 2 | 16 GB | - | - | 無料 |
| CPU Upgrade | 8 | 32 GB | - | - | $0.03 |
| ZeroGPU | 動的 | 動的 | RTX Pro 6000 Blackwell | 最大96 GB | 無料* |
| T4 - small | 4 | 15 GB | T4 | 16 GB | $0.40 |
| T4 - medium | 8 | 30 GB | T4 | 16 GB | $0.60 |
| L4 (1×) | 8 | 30 GB | L4 | 24 GB | $0.80 |
| L4 (4×) | 48 | 186 GB | L4 | 96 GB | $3.80 |
| L40S (1×) | 8 | 62 GB | L40S | 48 GB | $1.80 |
| L40S (4×) | 48 | 382 GB | L40S | 192 GB | $8.30 |
| L40S (8×) | 192 | 1,534 GB | L40S | 384 GB | $23.50 |
| A10G - small | 4 | 15 GB | A10G | 24 GB | $1.00 |
| A10G - large | 12 | 46 GB | A10G | 24 GB | $1.50 |
| A100 - large | 12 | 142 GB | A100 | 80 GB | $2.50 |
| 4× A100 | 48 | 568 GB | A100 | 320 GB | $10.00 |
| 8× A100 | 96 | 1,136 GB | A100 | 640 GB | $20.00 |
*ZeroGPUはクォータ内では無料です。PROおよびTeam/Enterprise組織のメンバーは標準クォータの8倍を利用できます。超過分は10分あたり$1で課金されます。
無料CPUプランのSpacesは48時間の非アクティブ後にスリープします。有料GPUのSpacesは一時停止するまで動作し続けます。T4-smallを30日間起動したままにすると$288かかります。自動シャットオフはありません。
知っておくべき点:コミュニティGPUグラントは対象となるサイドプロジェクトに利用可能です。オープンリサーチを公開していて継続的なGPUアクセスが必要な場合は、有料プランにコミットする前に申請する価値があります。
Inference Providers(サーバーレス)
Inference Providersを使うと、router.huggingface.co/v1の単一のエンドポイントを通じて、18以上の推論パートナー(Groq、Fireworks、Mistral、Cohere、Nebius、SambaNova、その他)にまたがる45,000以上のモデルにAPIコールをルーティングできます。Hugging Faceはプロバイダーの価格をマークアップなしで転送します。
Hugging Face経由でルーティングする際に適用される、プランごとの月次クレジット:
| プラン | 月次クレジット |
|---|---|
| 無料 | $0.10 |
| PRO | $2.00 |
| Team / Enterprise(シートあたり) | $2.00 |
クレジットがなくなると、使用量は従量課金に移行します。HFにアカウントへの請求を任せる(シンプルで月次クレジットが適用される)か、自分のプロバイダーAPIキーを持ち込んでプロバイダーに直接支払う(HFクレジットは適用されないが、課金関係を直接管理できる)かを選択できます。
TeamおよびEnterprise組織は、組織設定から支出上限を設定したり特定のプロバイダーを無効化したりできます。個人メンバーが高価なフロンティアモデルを実行している場合のコスト管理に役立ちます。
Hugging Faceは独自のhf-inferenceバックエンドも維持しています。これはかつての「Inference API(サーバーレス)」で、現在はエンベディング、テキスト分類、小型モデル(BERT、GPT-2)などのCPUバウンドタスクに特化しています。Llama 3.1 70Bや現行世代のLLMの実行はサードパーティのプロバイダーを経由します。
Inference Endpoints(専用デプロイ)
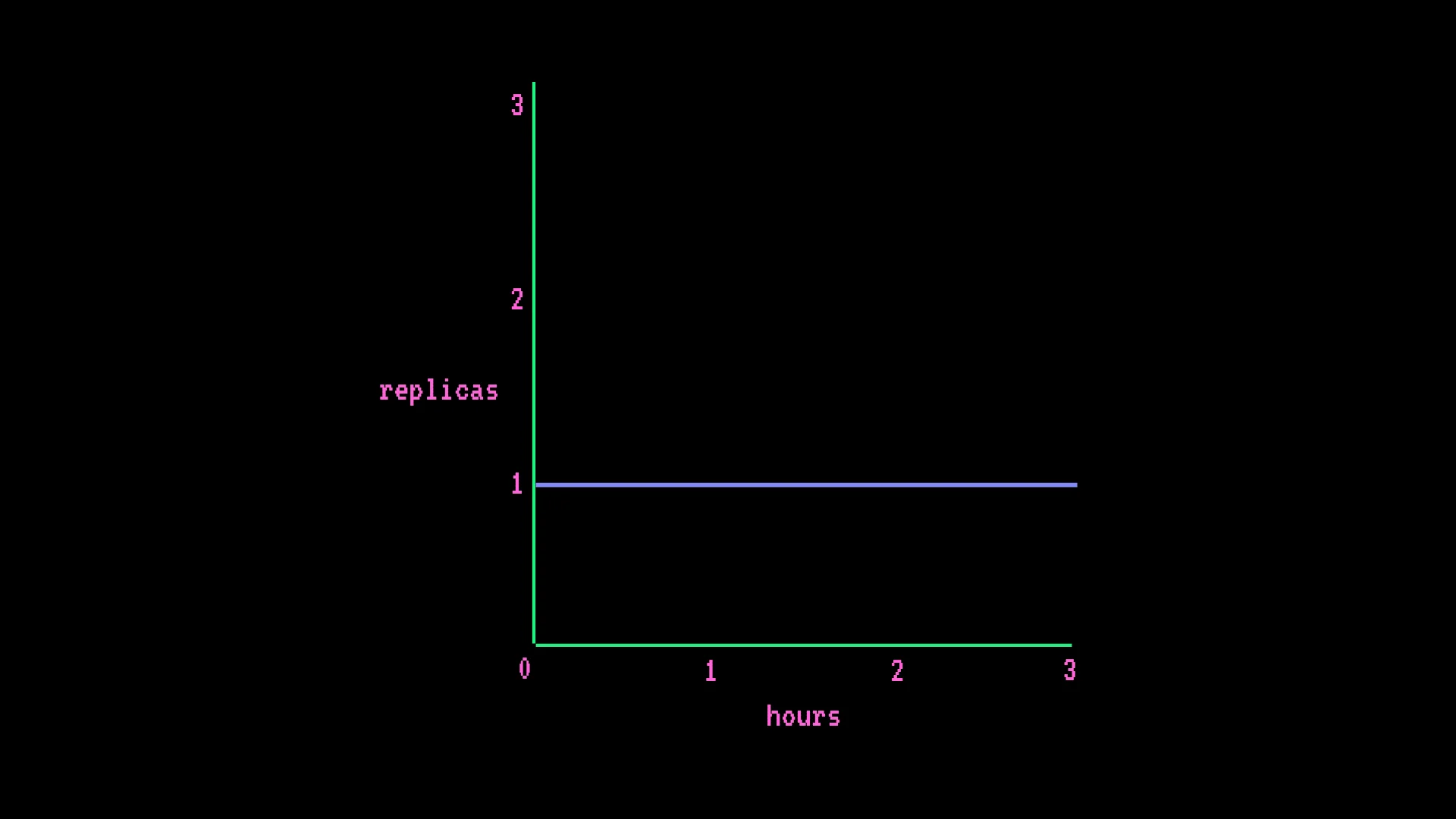
Inference Endpointsは、予測可能なレイテンシと専用インフラが必要なチーム向けです。コールドスタートなし、共有キューなし、AWS・Azure・GCPでの自動スケーリングデプロイが可能です。ハードウェアを選択すれば、コンテナとスケーリングはHugging Faceが管理します。
最も驚きを招きやすい課金モデルです。エンドポイントはリクエスト量に関係なく、アクティブなレプリカ数にインスタンスレートを掛けた分単位で課金されます。 リクエストごとまたはトークンごとの課金ではありません。
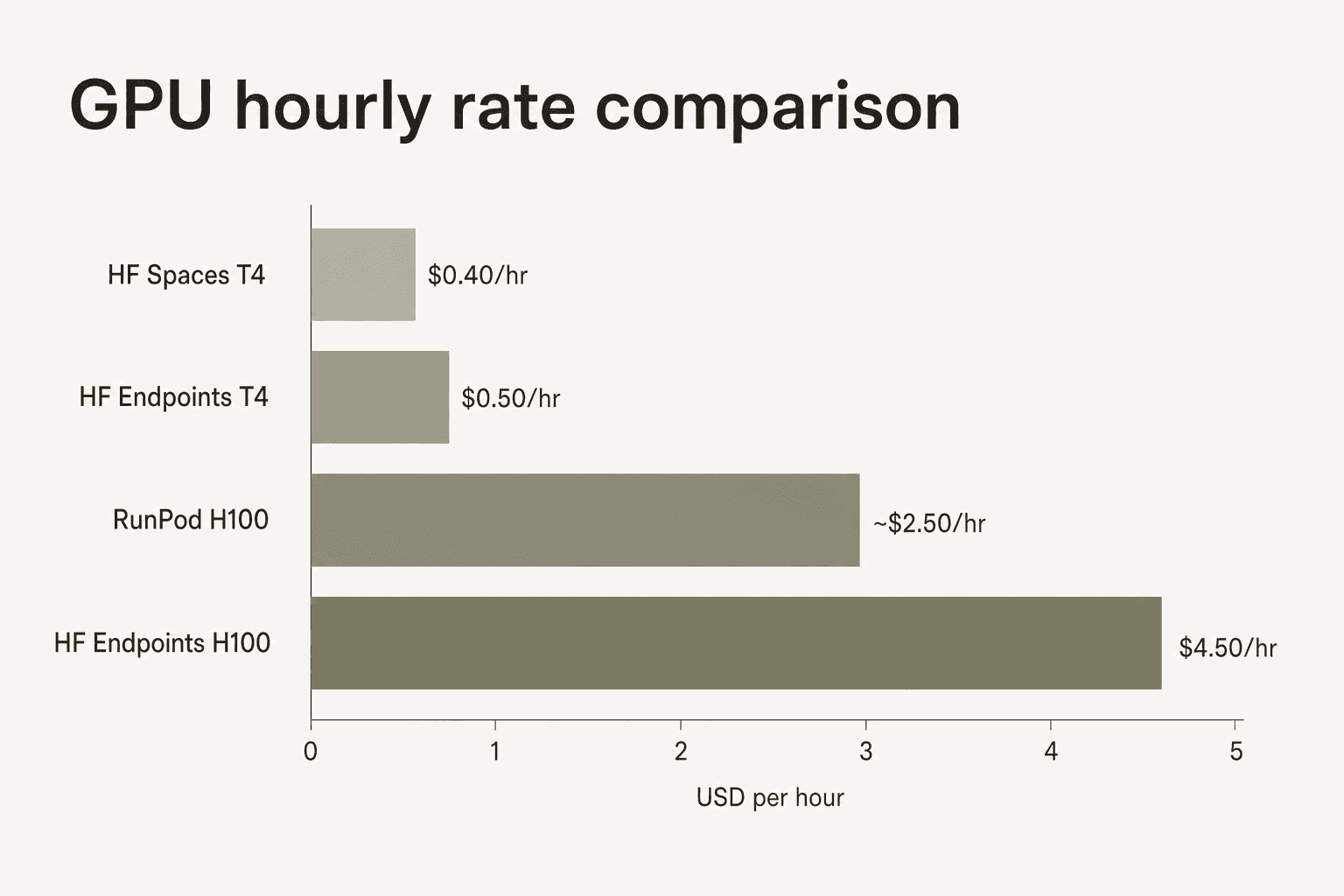
GPUインスタンス料金(AWS)
| GPU | 台数 | VRAM | 時間単価 |
|---|---|---|---|
| T4 | 1 | 14 GB | $0.50 |
| T4 | 4 | 56 GB | $3.00 |
| L4 | 1 | 24 GB | $0.80 |
| L40S | 1 | 48 GB | $1.80 |
| A100 | 1 | 80 GB | $2.50 |
| A100 | 4 | 320 GB | $10.00 |
| A100 | 8 | 640 GB | $20.00 |
| H100 | 1 | 80 GB | $4.50 |
| H100 | 4 | 320 GB | $18.00 |
| H100 | 8 | 640 GB | $36.00 |
| H200 | 1 | 141 GB | $5.00 |
| B200 | 1 | 179 GB | $9.25 |
| B200 | 8 | 1,432 GB | $74.00 |
| RTX PRO 6000 | 1 | 96 GB | $2.75 |
GCPとAzureのオプションも利用可能で、ハードウェアプランによって若干異なる価格設定です。CPU、アクセラレーター(Inferentia2、TPU v5e)インスタンスを含む完全な表はInference Endpointsの料金ページにあります。
具体的なコスト例
常時起動のCPUエンドポイント - AWS 2vCPU、1レプリカ:
- $0.067/時 × 730時間 = 約$49/月
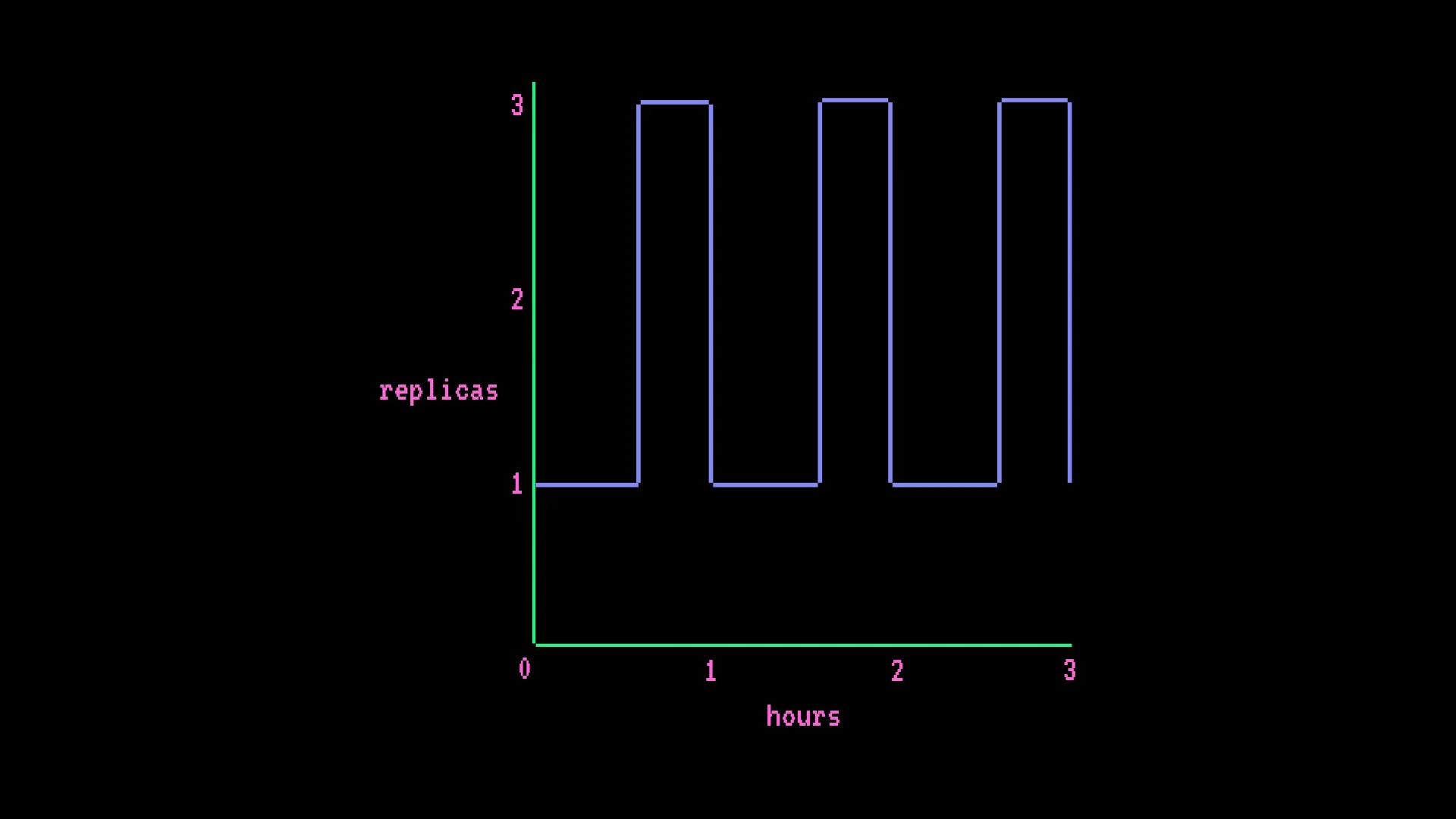
オートスケーリングのGPUエンドポイント - AWS T4 x1、最小1レプリカ、最大3、毎時15分のスパイク:
- $0.50 × (730時間 × 1 + 182.5時間 × 追加2レプリカ) = $547.50/月
課金計算式:時間単価 × ((時間数 × 最小レプリカ数) + (スケールアップ時間数 × 追加レプリカ数))
この常時起動モデルは最も多くの予想外請求の原因です。Hugging Faceフォーラムでの3,700以上のビューを集めた質問がこの混乱を端的に表しています:
「料金モデルが少し分かりません。CPU Basicマシン($0.06/時)にモデルをデプロイするとします。モデルがデプロイされている間ずっと課金されるのか、それともコンピュート時間だけ(例えば2つのリクエストを送り、それぞれ10秒かかるなら20秒分だけ)課金されるのでしょうか?」
答えは:リクエストごとではなく、モデルがデプロイされている間ずっと課金されます。この違いに多くの人が驚かされています。
ストレージ料金
Hub上のストレージは独立した課金レイヤーで、月あたりTB単位で課金されます。レートはボリュームと、リポジトリがパブリックかプライベートかによって異なります:
| ボリューム | パブリックレート | プライベートレート |
|---|---|---|
| ベース | $12/TB/月 | $18/TB/月 |
| 50 TB以上 | $10/TB/月 | $16/TB/月 |
| 200 TB以上 | $9/TB/月 | $14/TB/月 |
| 500 TB以上 | $8/TB/月 | $12/TB/月 |
エグレスとCDN配信は追加料金なしで含まれており、別途エグレス料金がかかるAWS S3の約$23/TB/月と比べて有利です。
各有料プランにはTB課金が始まる前の意味のあるベースストレージが含まれています:
- PRO: 最大10 TBパブリック + 1 TBプライベート
- Team: 12 TBパブリックベース + シートあたり1 TBパブリック + シートあたり1 TBプライベート
- Enterprise: 200 TBパブリックベース + シートあたり1 TB、大規模契約では1 PBまでスケール可能
有料プランのパブリックストレージアドオン:1 TBが$12/月、5 TBが$60/月、10 TBが$120/月、50 TBが$500/月。含まれる上限を超えるプライベートストレージは$18/TB/月から従量課金されます。
知っておくべき課金上の落とし穴
SpacesやInference Endpointsにはデフォルトの支出上限がありません。 Inference Providerの支出はTeamとEnterpriseの組織レベルで上限設定できますが、GPU Spacesと専用エンドポイントには自動のキルスイッチがありません。2025年4月のフォーラムスレッドでは、一晩で$78.22から$519.24に急増した請求が報告されています:
「24時間以内に約1,100時間の突然の増加があり、技術的に不可能です。継続的なGPU使用でも、1インスタンスあたり最大24時間/日です。このスパイクは何十もの並列インスタンスを意味しますが、そんなことはありません。」
課金バグかプロセスの暴走かにかかわらず、ユーザーには事前にリスクを上限設定する方法がありませんでした。教訓:GPU Spacesには手動一時停止ポリシーを設定し、Inference Endpointの最小レプリカ数はできるだけ低く保ってください。
時間レートと月次レートが常に一致するとは限りません。 2024年10月のスレッドでは実際の不整合が発見されています:Mediumの永続ストレージプランは$0.03/時と記載されており、これは月約$21.60を意味しますが、実際の月次請求は$25でした。時間単価から外挿するのではなく、月次合計を直接確認する価値があります。
Inference Endpointsは常時課金されます。 エンドポイントの最小レプリカ数が1の場合、トラフィック量に関係なく24時間365日ハードウェアレートで課金されます。アイドル時間が無料のサーバーレス価格モデルに慣れているチームはここで驚くことになります。
コンピュートコストの比較
Hugging Face Inference Endpointsは、コモディティGPUプロバイダーと比べてコンビニエンスプレミアムが乗っています。HF Dedicated EndpointsのH100はクラウドリージョンによって$4.50〜$10/時で、同じハードウェアがRunPodでは$2〜3/時です。コミュニティのレビューデータでもこのギャップが繰り返し指摘されており、「GPUコンピュートコストがすぐに積み上がる」という声がある一方、Hubとの統合、モデルの可用性、インフラ管理の不要さがHFエコシステム内に留まりたいチームにはプレミアムを正当化すると評価されています。
CPUバウンドのワークロード(エンベディング、分類、小型モデル)では計算が変わります。HFのレートは競争力があり、マネージドインフラはエンジニアリング時間を節約します。プレミアムが最も際立つのは高GPUエンドで、Together AIなどのプロバイダーが、Hubのモデルレジストリとデプロイツールなしでもいいチームにより良い純粋なコンピュートコストを提供しています。
Inference Playgroundは、コンピュートプランにコミットする前にモデルを試す最も簡単な方法です。課金設定なしにブラウザUIからプロバイダーに対してテストできます。
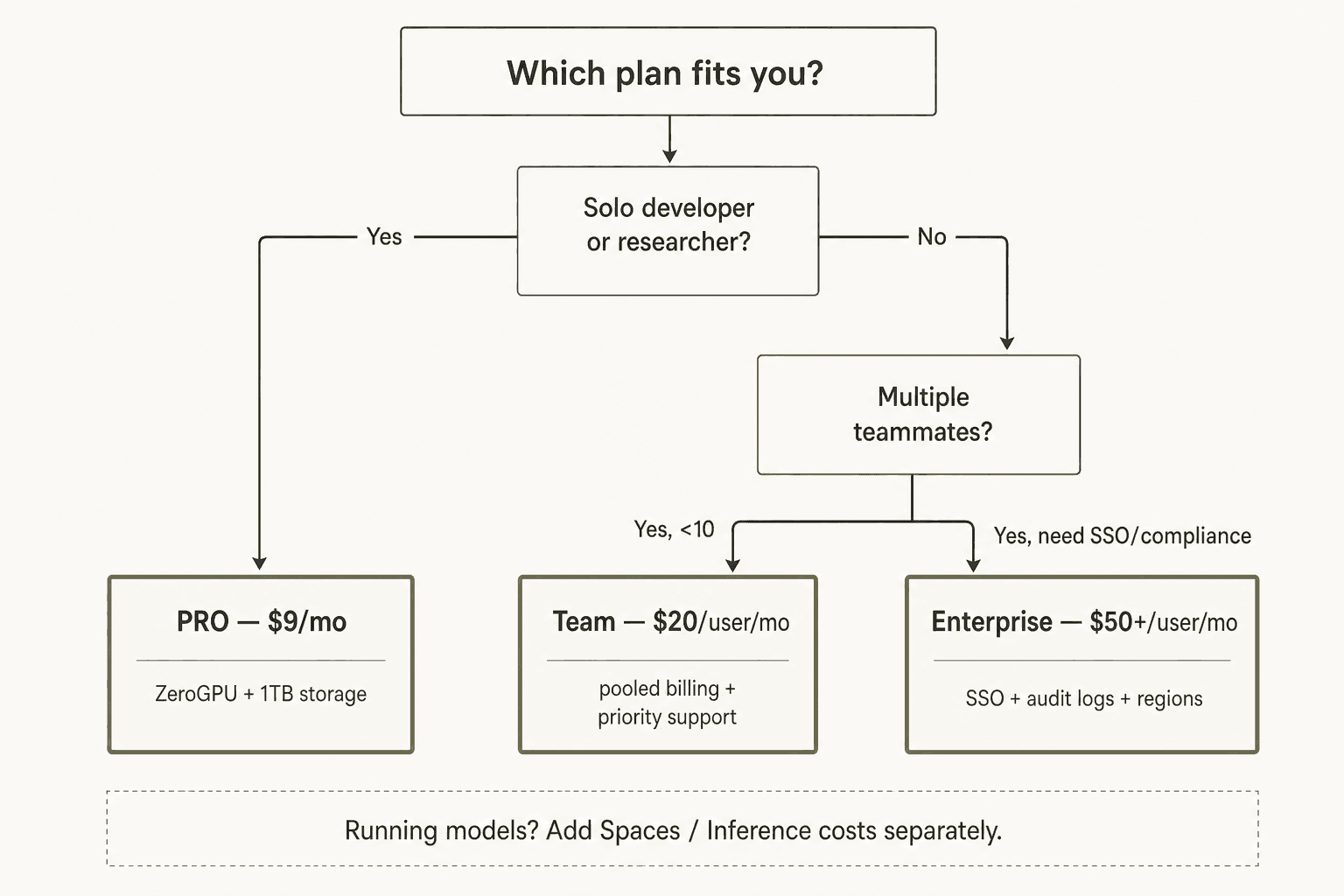
状況に合ったプランとプロダクトの選び方
無料 - モデルの探索、時折の実験、エコシステムの学習。モデルレジストリとZeroGPUアクセスで、何も費用をかけずに役立てることができます。
PRO(月額$9) - ZeroGPUクォータの増加、より多くのプライベートストレージ、またはSpaces Dev Modeが必要な積極的な個人開発者向け。MLを定期的に行う人には反論しにくい価格です。
Team(ユーザーあたり月額$20) - モデルやデータセットで共同作業をする実際のチーム向け。Inference Providersの組織レベルの課金管理とプールされたストレージが、このスケールで意味を持ち始めます。
Enterprise(ユーザーあたり月額$50+) - SSO、監査ログ、またはコンプライアンス要件がある場合。チームが大きいからではなく、実際にガバナンス機能が必要になったときに選択してください。
Inference Providers - インフラなしで管理できる、プロバイダーレートでのサードパーティモデルへの便利なサーバーレスアクセス。月$2のクレジットは本番環境ではすぐ底をつきますが、統一APIは評価やプロトタイピングに最適です。
Inference Endpoints - 予測可能なレイテンシとオートスケーリングを持つ専用ハードウェア。常時課金の予算を立て、最小レプリカ数を保守的に設定し、手動一時停止ポリシーを実装してください。低トラフィックや実験的なデプロイにはデフォルトの選択肢ではありません。
より広いエコシステムを比較したい場合は、Hugging Faceの代替サービスでモデルデプロイの他の7つのプラットフォームを評価できます。
eeselを試す
Hugging FaceをカスタマーサポートのAI向けに検討している場合(チケット返信の自動化、ヘルプデスクエージェントの構築、繰り返しのクエリの自動対応)、eeselはより直接的な方法を提供します。5つの課金体系にまたがるモデルホスティングインフラを管理する代わりに、eeselはZendesk、Slack、Freshdesk、その他100以上のツールに完全自律型のAIエージェントを直接デプロイします。エージェントを平文で説明すると、チケットをエンドツーエンドで解決し、コンピュート時間ではなくタスクあたり$0.40の使用量に応じた価格設定です。GPU管理なし、課金スパイクなし、設定が必要なInference Endpointsなし。
よくある質問
Hugging Faceの費用はいくらですか?
Hugging Faceは無料で使えますか?
Hugging Face PROには何が含まれますか?
Hugging Face Enterpriseはいくらですか?
Hugging Face Inference Endpointsの課金はどのように機能しますか?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.








