AIでチケットを偏向させる方法:実践ガイド
Riellvriany Indriawan
Katelin Teen
最終更新 June 20, 2026
「偏向」が実際に意味することと、どこで間違えるか
偏向とは単純にこういうことです:顧客が質問を持っていて、人間のエージェントがチケットに触れることなく答えを得られた。うまくやれば全員の勝利です。顧客は深夜2時に即座に回答を得て、エージェントは同じ配送ポリシーの返答を百回も入力するのをやめ、ヘルプセンターがすでに回答している質問に人間のコストを支払わなくて済みます。これはカスタマーサポート自動化において最もレバレッジの高い動きの一つです。
問題は、「偏向」が静かに「キューから責任を偏向させる」の同義語になったことです。多くのボットは単純に人に到達しにくくすることで高い偏向数を達成しています:3つの無関係な記事をループするチャットボット、メールアドレスを隠す連絡フォーム、「それについては確かではありません」と答えてから何もしないウィジェット。チケットは解決されませんでした。顧客は諦めて、苛立ち、しばしば一日後にさらに怒って戻ってきました。
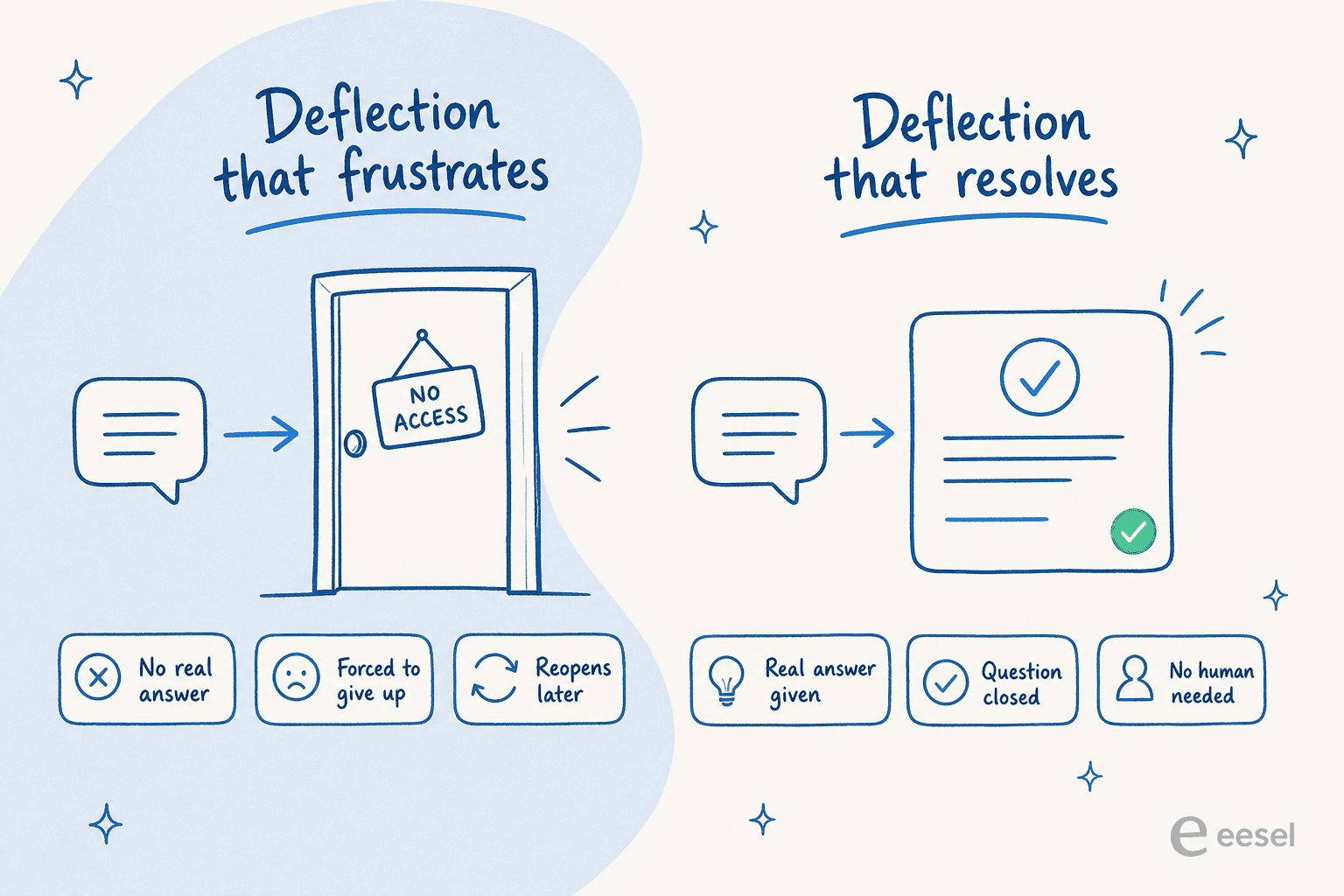
このガイドの残りのために一つの区別を覚えておいてください:目標は解決であり、偏向ではありません。偏向されたチケットは、顧客が求めていたものを実際に得た場合にのみカウントされます。以下のすべては、最初の種類を得てもらい、2番目の種類を得させないために構築されています。
ライブキューでAI偏向を運用して学んだこと
私はeeselのサポート側で働いているので、これは理論ではありません。私たちは何年もかけて、何千もの実際のチケットにわたってライブサポートキューにAIエージェントを置いてきました。そこで定着した教訓は、AIが何かを回答する能力があるということは、自律的に回答することが安全であることと同じではないということです。
具体的な例を挙げましょう。Zendesk と Shopify で月約1,000チケットを処理するドイツのオンラインジュエリー小売業者の実際のトライアルで、私たちの分析ではAIが93%のトリアージ精度と100%のスパム検出を達成していることが示されました。すべてを自動解決する準備ができているように聞こえますよね?しかし、その下書きの12%だけがそのまま送信するのに十分な質であり、7%の事実誤り率がまだありました。初日にフル自動にスイッチを入れていたら、7%の顧客が自信あふれた間違った回答を受け取っていたでしょう。それが罠です。不注意な偏向は単に助けに失敗するだけでなく、積極的に人々に誤情報を与え、苦情が来るまで気づかないのです。
その経験が、以下のすべてのステップが信頼と制御を後付けではなく、ポイントとして扱う理由です。
ステップ1:実際に偏向可能なものを見つける
何かを自動化する前に、チケットが何で構成されているかを把握しましょう。ほとんどのチームが驚かされます:ボリュームの大部分は少数の繰り返し質問です。注文状況(WISMO、「私の注文はどこですか」)、パスワードリセット、返金適格性、「プランはどう変更するか」、基本的な製品の質問。その繰り返しのティア1層があなたの偏向金鉱であり、答えが安定して文書化されているためAIに渡すのが最も安全です。
これを見る最速の方法は、過去数ヶ月のチケットにテーマ分析を実行することです。良いAIヘルプデスクエージェントは過去のチケットをトピック別にクラスタリングし、各テーマが占めるボリュームの割合を教えてくれるので、推測しなくて済みます。チケットの35%がWISMOで、毎回同じ方法で回答しているなら、最初にターゲットにできる35%です。
最も難しく感情的なチケットから始める衝動に抵抗してください。請求に関する紛争、アカウントセキュリティ、苛立った顧客が付いているもの、これらは今のところ人間に任せてください。偏向とは予測可能なボリュームをクリアして、実際にそれを必要とするケースのためにチームにスペースを作ることです。
ステップ2:ナレッジを1カ所にまとめる
AIはどこかに答えが存在しないとチケットを偏向させることができません。これはチームが飛ばして、なぜ偏向率が10%で止まっているのかと不思議に思うステップです。
あなたのナレッジは通常、思っているよりも多くの場所にあります:公開ヘルプセンター、内部マクロ、解決済みの過去チケット、NotionやConfluenceウィキ(https://www.eesel.ai/blog/confluence-ai-knowledge-base)、Google Docs、LoomビデオやSlackスレッドさえも。最も価値のあるソースはしばしばあなた自身の過去のチケットです。なぜなら、サニタイズされたヘルプセンター版ではなく、チームが実際に回答をどう表現するかを捉えているからです。あるイギリスのチームはわずか9つの同期されたマクロから56の解決済みタスクを生み出しました。これは既に持っているナレッジにどれほどのレバレッジがあるかを示しています。
ここで2つの実践的な動き:
- すべてを接続し、その後重複排除する。 AIにヘルプセンター、マクロ、過去のチケットをポイントして、実際の解決から回答させましょう。公開記事だけでなく、解決済みチケットから学ぶツールは明らかに多く偏向させます。
- 明らかなギャップを埋める。 ステップ1のテーマ分析で、高ボリュームで良いドキュメントがないトピックが浮かび上がります。本番公開前にそれらの記事を書きましょう。一部のAIツールは見つけたギャップから不足しているナレッジベース記事の下書きさえ作成します。
ステップ3:信頼度ベースのルーティングを設定する
これは機能する偏向と裏目に出る偏向を分けるステップであり、購買者が最も頻繁に必要だと私に言う単一のことです。
原則はシンプルです:AIは確信のあるチケットだけに回答し、残りはすべて静かに人間に残すべきです。月約7,000のGorgias チケットを処理するDTCサプリメントブランドのCXリードが、誰もが言ったのと同じくらい明確に私に言ってくれました。彼女は7,000チケットをチェックしてAIがうまく推測したかどうかを確認できないと言いました。だから自信を持って対応できる質問だけを扱い、それ以外はすべて放っておくAIが必要だったのです。それがゲームの全てです。70%の信頼度で全てに答えるAIは、99%の信頼度でチケットの半分に答えるAIより悪いのです。
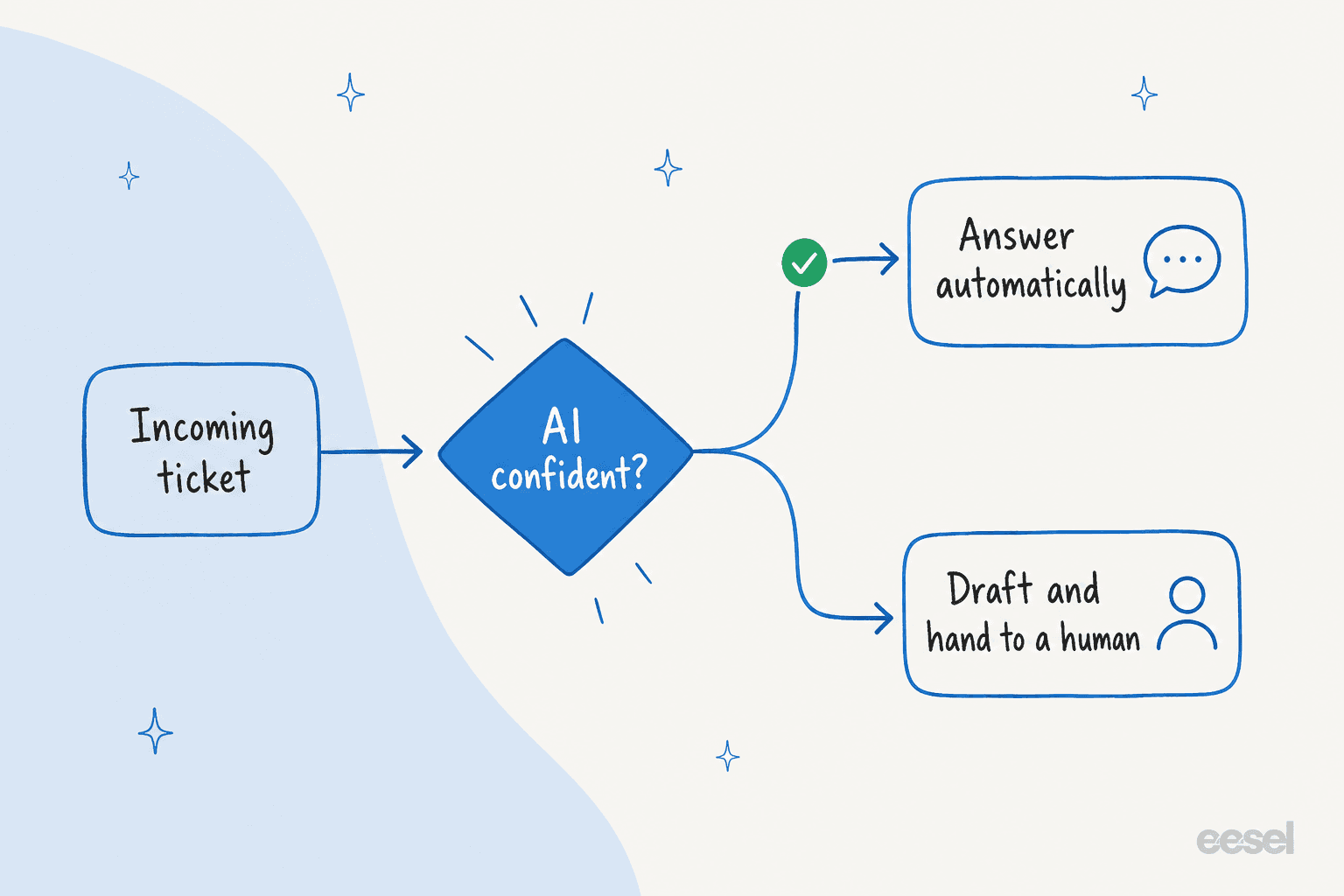
実際には、信頼度ベースのルーティングとはしきい値を設定することを意味します:それ以上であればAIは返信を送信するかチケットを解決し、それ以下であればエージェントへの内部メモとして提案された回答の下書きを作成するか、返信せずに適切なチームにチケットをルーティングします。また、一部のカテゴリ(法的なもの、解約リスクのあるアカウントなど)はどれだけ自信があってもAIに触れさせてはならないため、チケットタイプ全体を自動化から除外する機能も必要です。
最善な点は、ルールエンジンは不要で、今ではすべてをわかりやすい言葉で設定できることです。エージェントがいつ介入すべきか、使用するトーン、いつ静かにすべきかを説明すれば、それに従います。
ステップ4:人間へのクリーンな引き継ぎを構築する
偏向とエスカレーションは同じシステムの2つの半分です。AIが助けられない瞬間、引き継ぎは顧客に見えないようにしなければなりません。「最初からやり直してください」なし、会話履歴の消失なし、行き止まりなし。
SEOツールのウェブサイトウィジェットからの実際のチャットが完璧な例です。顧客はプロジェクトからキーワードを削除する方法を尋ね、AIはドキュメントから回答しました。検索エンジンを削除する方法を尋ね、再び回答。そして「人間と話せますか?」と入力すると、エージェントはリズムを崩さずにサポートチームに直接引き渡しました。2つの質問が偏向され、1つのクリーンなエスカレーション、摩擦ゼロ。それが良い見た目です。
引き継ぎを設定するとき、顧客が自分を繰り返さなくて済むように、AIが完全な会話コンテキストを人間のエージェントに渡すことを確認してください。そして、人への道を本当に見つけやすくしてください。逆説的に、明確な「人間と話す」パスはボットへの信頼を高めます。人々は出口が存在すると知ってリラックスし、最初にセルフサービスの回答を試すことに喜んで乗り気になるからです。
ステップ5:本番公開前にシミュレーションする
これはほぼすべてのガイドが飛ばすステップであり、公開での失敗から救ってくれるステップです。
AIが一つの本番チケットにも触れる前に、シミュレーションで過去のチケットに対して実行してください。適切なヘルプデスクAIは何千もの過去チケットを再生し、正確にどう回答したかを示し、テーマ別の予測偏向率を提供します。ギャップ(推測するトピック、ずれたトーン、不足しているドキュメント)を見つけて、顧客が露出する前に修正します。
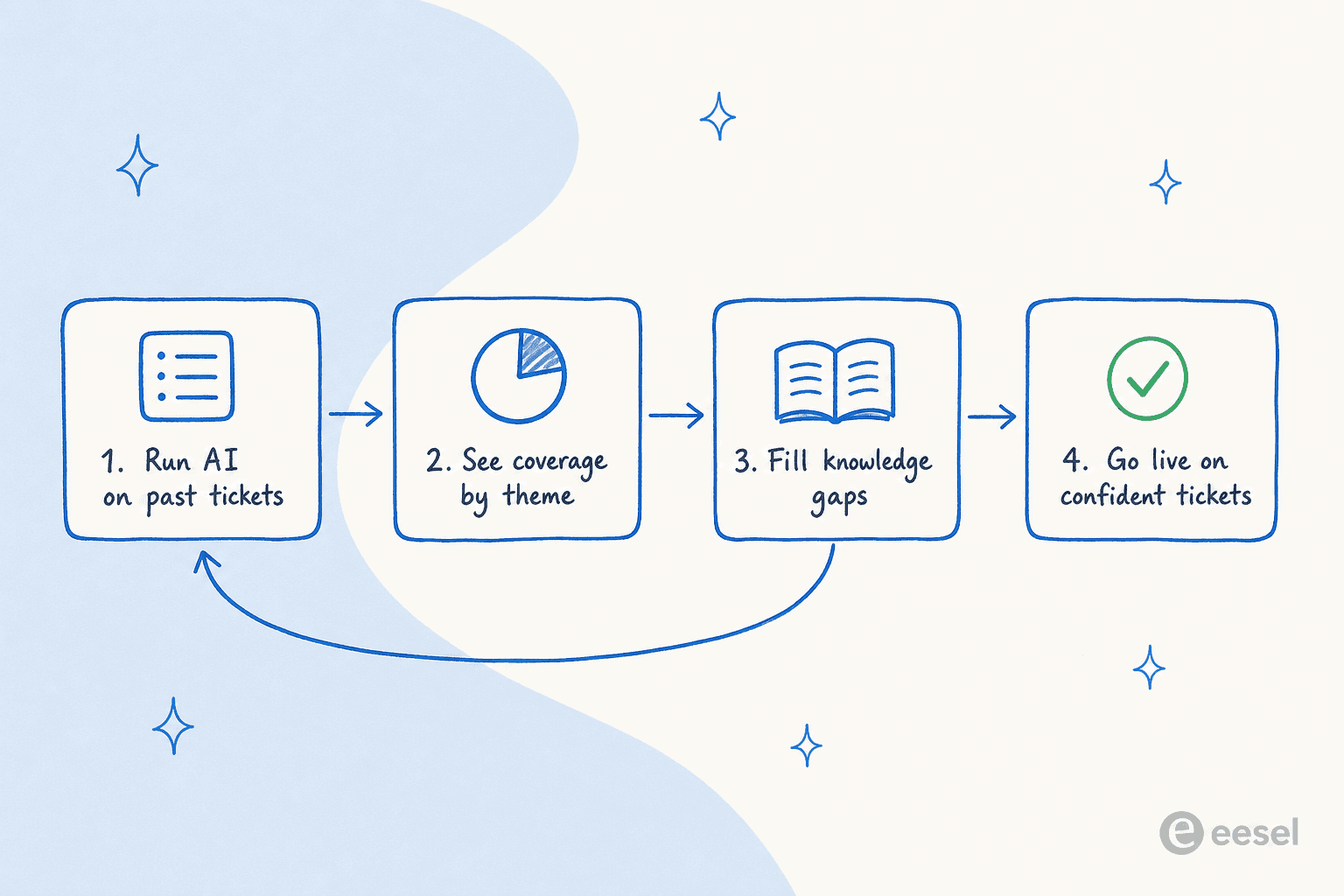
これは上司と現実的な期待を設定する方法でもあります。「AIはチケットの80%を処理します」と約束する代わりに、「シミュレーションでは、1ヶ月目に42%を安全に解決できることが示されており、具体的なテーマはこちらです」と言えます。そして、その自信のあるスライスだけで本番公開し、監視し、拡大します。狭く始めて自律性を獲得することは、すべてを有効にして祈るよりも常に優れています。
ステップ6:重要な数値を測定する
生の偏向率を測定すると、顧客が諦めるように最適化してしまいます。だから代わりに正しいことを測定してください。
実際に重要な数値は解決率です:AIが処理したチケットのうち、顧客が戻ってきたりエスカレーションしたりすることなく本当に解決されたのはどれだけか?AI処理チケットの再開率とCSATとペアリングして、「偏向されたが怒っている」ケースを発見してください。私が知っているある内部ITチームは15%の偏向から始まり、初日に空虚な数値で勝利を宣言するのではなく、AIにより多くのナレッジを与えながら上昇を追跡して、55%の目標を設定しました。

良い測定が何を明らかにするかの許可された例:
「最初の月に、eeselはティア1リクエストの73%を解決しています。私たちのチームは7日間のトライアル中に迅速に実装して結果を出しました。」
Kim Simpson, Gridwise(eesel AIヘルプデスクエージェント)
フレーミングに注目してください:「73%を偏向させた」ではなく、「ティア1リクエストの73%を解決」。それがこのガイド全体がかかっている区別です。
偏向を台無しにする一般的な間違い
私が繰り返し見るいくつかのパターン:
- シミュレーション前に完全自律性をオンにする。 これが7%の事実誤り率が実際の顧客に届く方法です。シミュレーションして、狭く本番公開し、拡大する。
- 偏向率を目標として扱う。 人間に到達しにくくすることに報酬を与えます。代わりに解決率と再開率を追跡する。
- AIをナレッジから遠ざける。 薄いヘルプセンターだけを指すボットはほとんど何も偏向させません。過去チケットとマクロも接続する。
- 人間を隠す。 エスカレーションパスを埋め込むと信頼とCSATが下がります。「人と話す」を簡単にすると、ボットの使用率は増え、減りません。
- 設定して忘れる。 製品とポリシーが変化するにつれて偏向が衰退します。AIが間違えたことを毎週確認し、修正をフィードバックする。
これらを正しく行えば、偏向は虚栄心の高い指標ではなく、本来あるべきものになります:チームがより少ない繰り返し作業をし、顧客がより速い回答を得ること。それはまたチームがサービスを削減せずにチケットボリュームを減らす方法のほとんどでもあります。
eeselを試す
このガイドが説明する方法でチケットを偏向させたい場合、eeselはまさにこのワークフローを中心に構築されています。既存のヘルプデスクにプラグインし、初日から過去チケットとヘルプドキュメントから学習し、何千もの過去チケットに対してシミュレーションして、本番公開前に予測偏向率を確認できます。信頼度ベースのルーティングにより、自信があることだけに回答し、それ以外はすべてクリーンにチームに渡します。
Zendesk、Freshdesk、Gorgias、Front、Help Scoutおよび100以上の他のツールで動作し、従量課金制でボリュームが増えても追加料金なし。クレジットカードなしで無料トライアルを開始し、午後中に独自の偏向予測を確認できます。
よくある質問
顧客を苛立たせずにAIでチケットを偏向させるにはどうすればいいですか?
良いチケット偏向率とはどのくらいですか?
顧客に公開する前にAI偏向をテストするにはどうすればいいですか?
最初にAIで偏向させても安全なチケットの種類は何ですか?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.







