Pourquoi déflectar les tickets sur WhatsApp est un problème à part
Le mail vous donne une marge. Un client qui envoie un mail s'attend à attendre. WhatsApp n'en donne aucune, parce que le canal ressemble à envoyer un SMS à une personne, et la fenêtre de patience se mesure en minutes. Un « où est ma commande ? » à 23h veut une réponse à 23h, pas un message automatique le lundi matin. Cette attente de rapidité est exactement la raison pour laquelle la déflexion a plus de sens ici que presque partout ailleurs : les questions sont répétitives, à fort volume et urgentes, ce qui est le point optimal pour un agent de support IA.
WhatsApp vient aussi avec des règles que le mail n'a pas. Pour automatiser les réponses à une vraie échelle, vous avez besoin de l'API officielle WhatsApp Business (l'application Business gratuite ne suffit pas pour une équipe), Meta vous facture par fenêtre de conversation de 24 heures, et les modèles de message ont besoin d'une approbation. Donc « déflectar les tickets sur WhatsApp » représente vraiment deux décisions empilées : quelle plateforme vous connecte à WhatsApp, et quelle IA répond réellement aux questions. L'essentiel de l'argent et de la douleur se trouve dans la seconde.
J'ai passé suffisamment de temps sur des files en direct pour avoir vu un bot à l'air confiant donner à un client la mauvaise politique de retours sur un canal où tout se prend en capture d'écran. Donc quand j'évalue une configuration de déflexion maintenant, je me soucie moins de la démo et plus de deux choses ennuyeuses : comment l'IA est ancrée dans votre vraie connaissance et ce qu'elle fait quand elle n'est pas sûre. Gardez ces deux questions en tête pour le reste de cet article.
Ce que « déflexion » signifie vraiment sur WhatsApp (et l'écart que personne ne mentionne)
Voici la définition sur laquelle il vaut la peine d'être strict. Un ticket est déflecté quand le problème du client est réellement résolu sans qu'un humain ne le touche. Il n'est pas déflecté quand le bot a simplement fermé le chat, caché le bouton « parler à un humain » ou répondu à quelque chose d'adjacent et que le client a abandonné et envoyé un mail à la place.
Cette distinction est la chose la plus coûteuse que les équipes se trompent. Un bot WhatsApp rapportera volontiers un grand nombre de déflexions pendant qu'une partie de ces chats « déflectés » sont des clients qui reviennent plus en colère par une autre porte. Nous suivons la métrique qui compte vraiment : le taux de recontact dans les 48 heures. Si ça monte pendant que votre taux de déflexion a l'air bien, le bot ferme des chats, pas les résout.
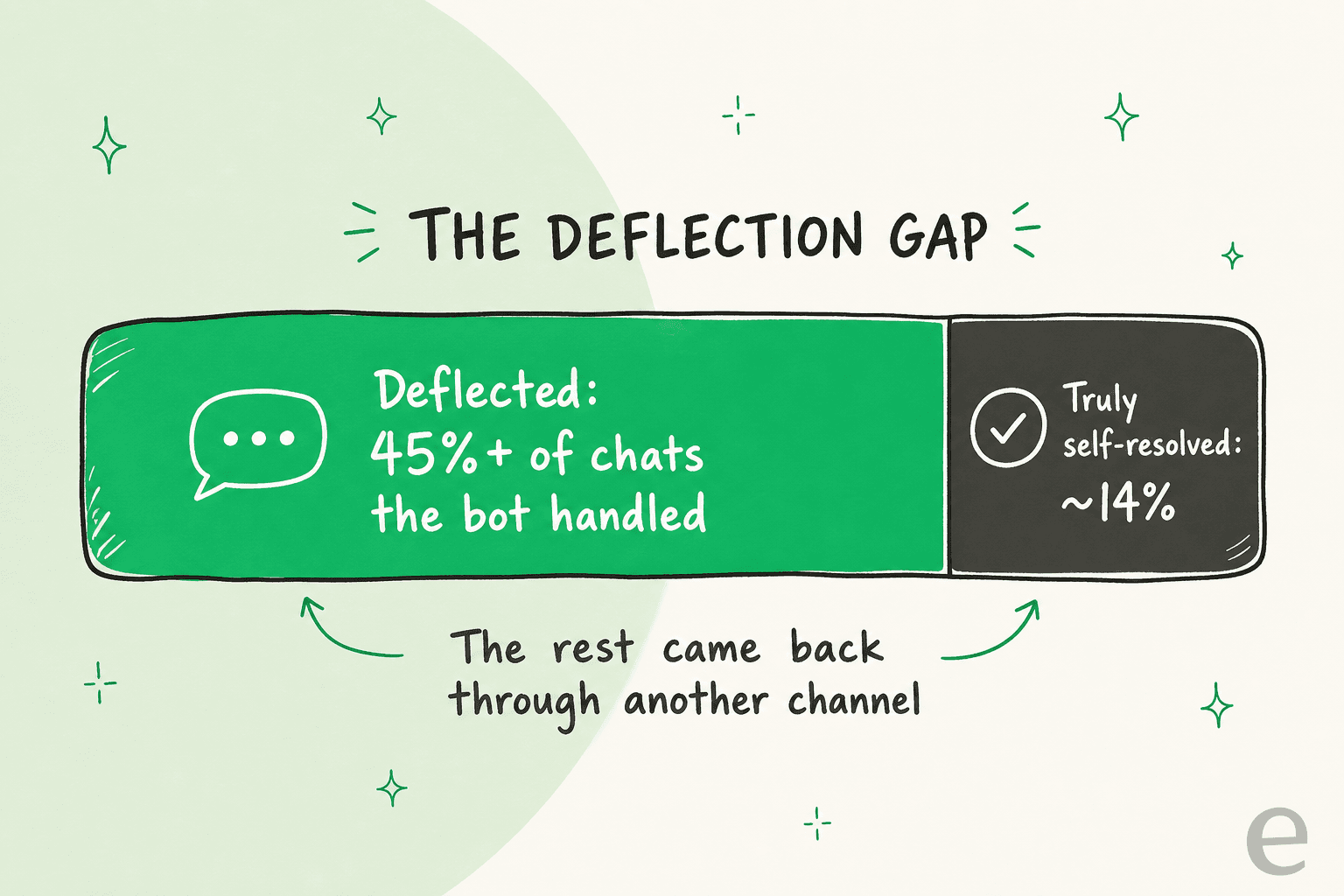
La leçon qu'on réapprend sans cesse : chasser le pourcentage de déflexion principal crée des incitations perverses, où la façon la plus facile de « déflectar » plus est de rendre un humain plus difficile à atteindre. Le meilleur cadrage que j'ai entendu pour tout le piège vient d'un responsable CX à qui nous avons parlé, et il s'applique parfaitement à WhatsApp :
« L'IA ne pourra jamais répondre à 100 % des questions… J'ai besoin d'une IA qui ne gère que les tickets qu'elle est confiante pour gérer, et tous les autres, qu'elle les laisse tranquilles. »
un responsable CX de suppléments DTC, de nos propres appels clients
Laissez les difficiles tranquilles. Ce n'est pas une limitation dont s'excuser, c'est l'objectif de conception. Un bot qui connaît ses limites et route proprement surpasse celui qui tente tout, à chaque fois.
Comment l'IA déflecte un ticket WhatsApp, étape par étape
Sous le capot, la déflexion moderne ne ressemble en rien au bot à mots-clés de 2018. Un vrai agent IA raisonne sur votre vraie connaissance au lieu de faire correspondre des flux fixes. Dans une file WhatsApp, le flux fonctionne comme ça :
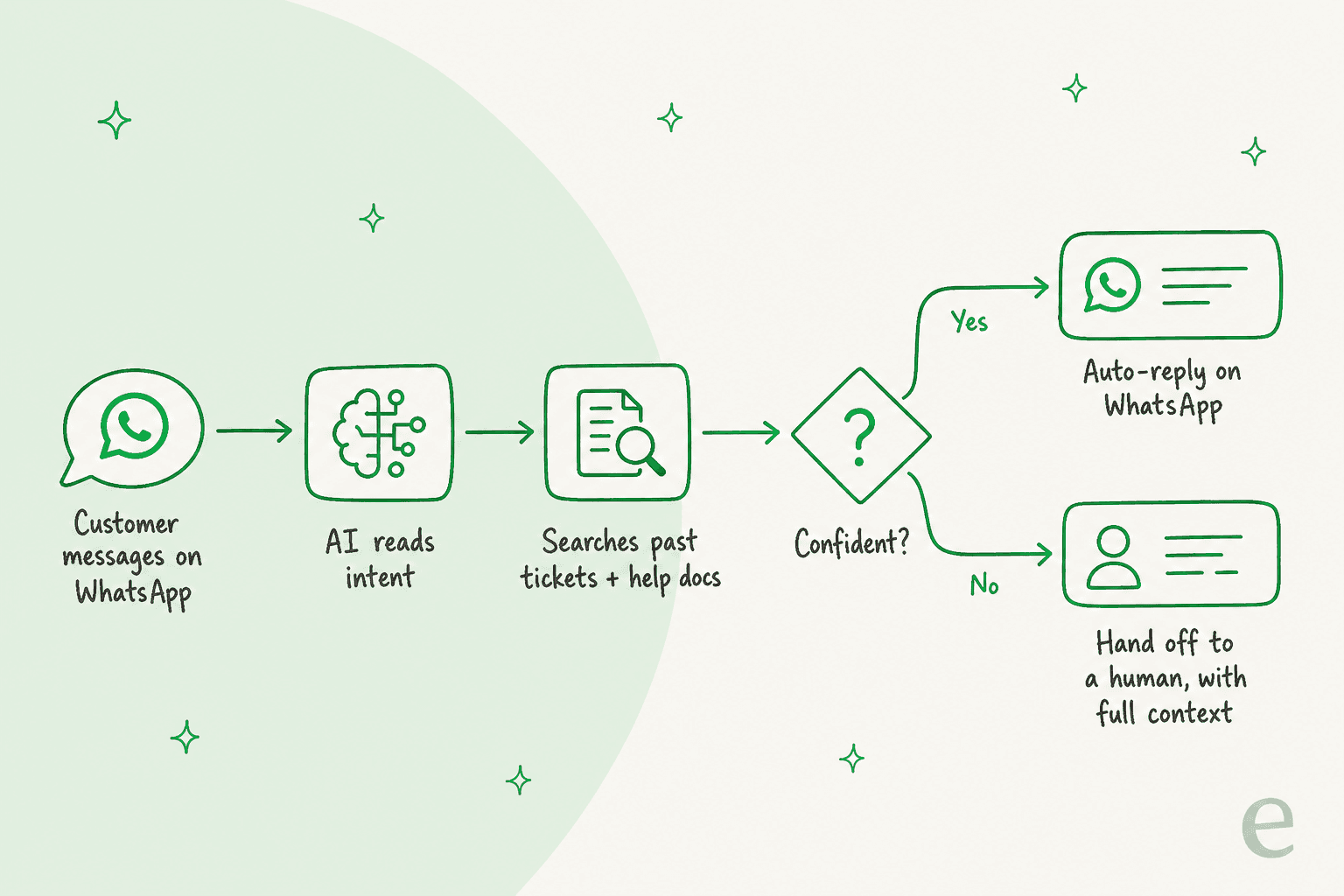
- Le client envoie un message sur WhatsApp. Comme un SMS, sans portail, sans formulaire.
- L'IA lit l'intention. Elle détermine ce que le client veut vraiment (statut de commande, remboursement, aide à la connexion) et lit le ton, car un message en colère est un signal d'escalade, pas de continuer à répondre.
- Elle recherche dans votre connaissance. Il s'agit de récupération ancrée dans vos documents d'aide, votre base de connaissances et, crucialement, vos tickets passés résolus, pour que la réponse sonne comme votre équipe plutôt que comme un manuel générique.
- Elle vérifie sa propre confiance. Haute confiance : répondre et résoudre. Basse : ne pas deviner.
- Elle répond automatiquement ou passe la main. Une réponse confiante revient directement dans le chat. Tout ce qui est incertain devient une passation propre à un humain, avec la transcription complète pour que le client n'ait jamais à se répéter.
Deux de ces étapes font l'essentiel du travail, et ce sont les mêmes deux que je vous ai dit de garder en tête : l'ancrage (étape 3) et la porte de confiance (étape 4). Faites-les bien et la déflexion se gère d'elle-même. Faites-les mal et vous avez automatisé un moyen d'agacer les gens plus vite.
Ce qui déflecte vraiment sur WhatsApp (et ce qui ne devrait pas)
Chaque question ne déflecte pas au même taux, et la façon la plus rapide de gâcher un lancement est de pointer l'IA sur tout à la fois. Le tableau honnête ressemble à une échelle :
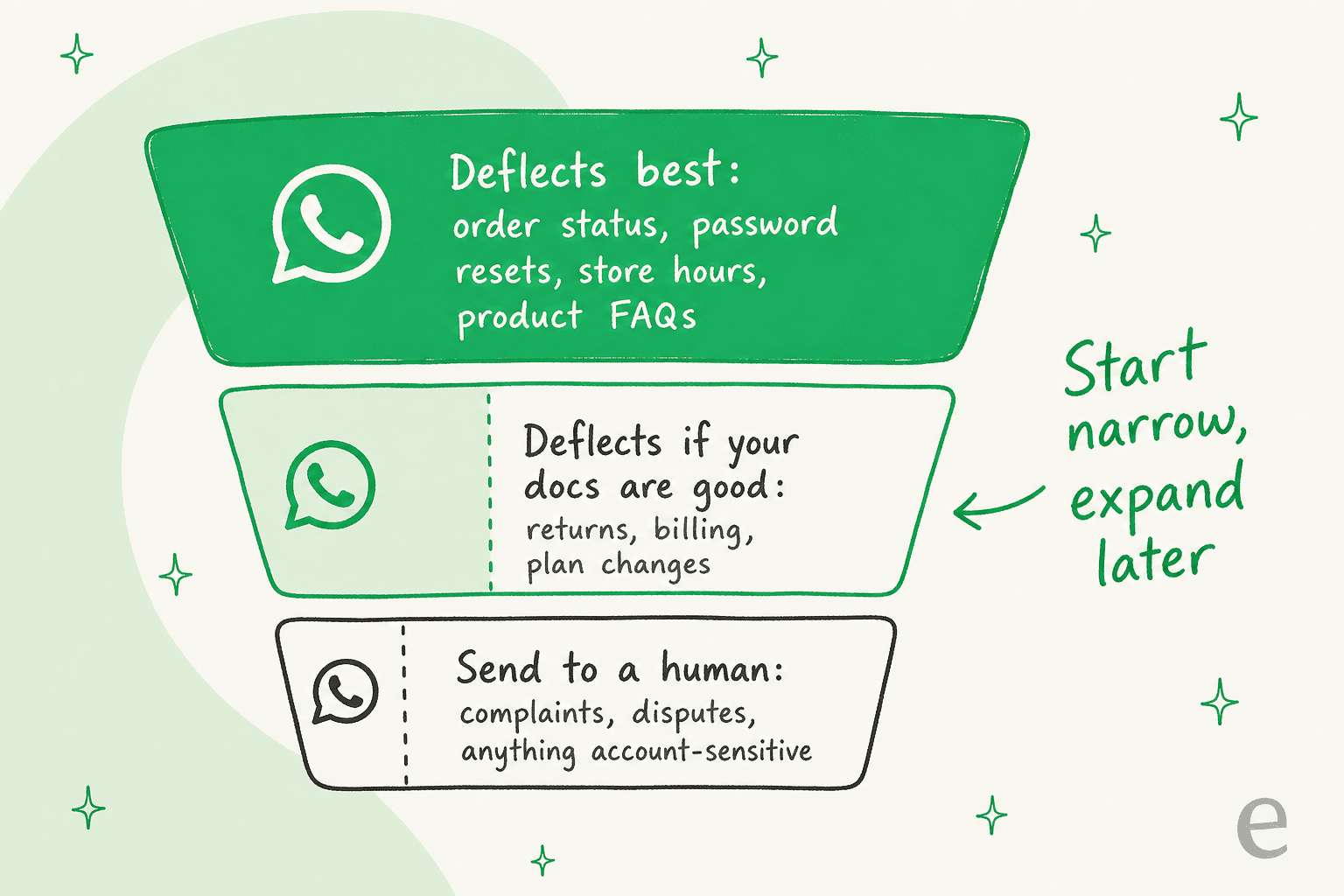
- Haut de l'échelle (déflecte le mieux) : statut de commande, « où est ma commande », réinitialisations de mot de passe et de compte, horaires d'ouverture, délais de livraison, questions standard sur les produits. Ce sont des questions répétitives, factuelles avec une seule bonne réponse. C'est par là qu'on commence.
- Milieu (déflecte si votre documentation est suffisamment bonne) : retours, questions de facturation, changements de plan. L'IA peut les gérer bien, mais seulement si votre centre d'aide les couvre clairement et que l'IA peut consulter le contexte spécifique au compte.
- Bas (envoyer à un humain) : réclamations, litiges de facturation, menaces de résiliation, tout ce qui est légal ou sensible au compte. Tenter de déflectar cela, c'est transformer un petit problème en client perdu.
Commencez avec deux ou trois types de questions à fort volume pour lesquels vous avez une bonne documentation, prouvez le taux de déflexion, puis élargissez. Un périmètre défendable l'emporte sur un périmètre qui impressionne dans un deck. C'est aussi pourquoi l'ancrage compte autant : le plafond de l'IA est fixé par votre base de connaissances, pas par le modèle. Si la réponse n'est pas écrite quelque part que l'IA peut lire, aucun prompting habile ne peut y remédier.
Les deux choses qui décident si ça fonctionne
Chaque outil de déflexion WhatsApp fait bien la démo. Ceux qui survivent au contact d'une vraie file partagent deux caractéristiques.
Il apprend de votre vrai historique. Une IA entraînée sur vos tickets passés et documents d'aide répond avec votre voix dès le premier jour, y compris les cas limites que votre équipe a appris à la dure. Le contraste qui compte : un outil à qui vous donnez vingt FAQ répondra comme une boîte de recherche, tandis qu'un ancré dans des milliers de conversations résolues répond comme l'agent qui est là depuis trois ans. Quand les équipes nous disent qu'elles ont failli construire ça en interne avec un modèle brut, c'est généralement ça qui les a stoppées. Comme l'a dit un client : « Nous aurions pu essayer d'écrire notre propre application LLM mais nous ne voulions pas investir notre temps dans ça. Nous voulions quelque chose que nous n'aurions pas à maintenir » (GENERAL BYTES).
Il refuse de deviner. Le routage basé sur la confiance est la fonctionnalité de sécurité qui rend la réponse automatique viable sur un canal où tout se prend en capture d'écran. L'IA répond quand elle est sûre et transforme une réponse incertaine en brouillon ou passation plutôt qu'en mauvaise réponse envoyée en direct. Combinez ça avec la capacité de tester sur votre vrai historique de chat avant le lancement, et vous arrêtez de voler à l'aveugle.

Cette étape de simulation est quelque chose que je ne lâcherais plus après avoir vu un bot passer en production à l'aveugle. Faire tourner l'IA sur vos derniers milliers de chats WhatsApp vous donne le vrai taux de déflexion, par sujet, avant qu'un client ne le voie jamais, donc le jour du lancement est une confirmation et non une expérience. C'est aussi là que l'écart de fausse déflexion apparaît tôt, pendant qu'il est encore peu coûteux à corriger.
Comment le configurer sans faire exploser votre CSAT
Si vous avez déjà un helpdesk, vous n'avez rien à migrer pour mettre de l'IA sur WhatsApp. Une couche IA se connecte à WhatsApp et à la configuration Zendesk, Freshdesk, Gorgias ou Front que vous avez déjà, donc la connexion WhatsApp et votre historique de tickets restent là où ils sont.
Un déploiement qui ne se retourne pas contre vous va généralement comme suit :
- Auditez d'abord votre documentation. Listez vos 20 à 30 questions WhatsApp les plus fréquentes et vérifiez qu'une réponse claire et à jour existe pour chacune. Celles sans bonnes réponses sont hors périmètre jusqu'à ce que vous les écriviez. Cette seule étape fait plus pour votre taux de déflexion que n'importe quel choix de modèle.
- Connectez WhatsApp et votre connaissance. Pointez l'IA sur votre centre d'aide, vos tickets passés et tous les systèmes de commande ou de compte dont elle a besoin pour faire des recherches, pour qu'elle réponde avec un vrai contexte plutôt que des articles génériques.
- Simulez avant de lancer. Faites tourner l'agent sur des chats historiques pour voir le taux de déflexion projeté et attraper les mauvaises réponses pendant qu'elles ne coûtent rien.
- Commencez en mode brouillon ou réponse automatique étroite. Laissez-le gérer automatiquement les questions du haut de l'échelle, rédiger le reste pour un humain, et élargir l'autonomie au fur et à mesure que les chiffres le justifient.
- Traitez chaque escalade comme une tâche à faire. Chaque passation est un manque dans votre documentation ou votre périmètre. Réintégrez-la et le taux de déflexion monte tout seul.
Les erreurs que je vois le plus : chasser le chiffre de déflexion plutôt que le taux de recontact, lancer avec une documentation périmée, et rendre le passage à un humain si difficile que la « déflexion » n'est que frustration. Évitez ces trois-là et le reste c'est du réglage. Si vous comparez ça à des embauches, notre analyse du coût de l'agent IA versus humain et des économies plus larges est un bon contrôle, puisque les chats gérés par l'IA coûtent une fraction de ceux gérés par un humain.
Déflectez les tickets WhatsApp avec eesel
Si l'objectif est un agent IA qui déflecte vraiment les chats WhatsApp (pas seulement les ferme), le chemin le plus rapide n'est généralement pas de changer de plateforme, c'est d'ajouter un meilleur cerveau au stack que vous utilisez déjà. eesel AI se connecte à WhatsApp et à votre helpdesk actuel, apprend de vos tickets passés et documents d'aide, et commence à rédiger ou résoudre automatiquement avec votre voix en quelques minutes.
Les deux choses que je vous ai dit de ne jamais lancer sans elles sont les valeurs par défaut ici : il simule sur votre vrai historique de chat pour que vous voyiez le taux de déflexion avant de passer en production, et il ne répond automatiquement que quand il est confiant, routant le reste vers un humain avec le contexte complet. Il répond dans la langue du client dans plus de 80 langues, ce qui compte beaucoup sur un canal mondial comme WhatsApp, et sur de vraies files les chiffres tiennent : eesel a résolu 73 % des demandes de niveau 1 pour Gridwise dès le premier mois, et Smava fait tourner un agent entièrement automatisé sur plus de 100 000 tickets par mois.
Avec une tarification transparente par ticket et 50 $ d'utilisation gratuite, vous pouvez prouver le taux de déflexion sur vos propres chats WhatsApp avant de payer quoi que ce soit. Essayez eesel et voyez vos chiffres sur de vraies conversations en premier.
Questions fréquentes
Qu'est-ce que la déflexion de tickets IA pour WhatsApp ?
Combien l'IA peut-elle réalistement déflectar sur WhatsApp ?
Ai-je besoin de l'API WhatsApp Business pour la déflexion IA ?
Est-il sûr de laisser l'IA répondre automatiquement aux clients WhatsApp ?
L'IA peut-elle déflectar les tickets WhatsApp sans remplacer mon helpdesk ?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.