Comment savoir si mon support IA fonctionne ?
Alicia Kirana Utomo
Katelin Teen
Dernière modification June 17, 2026

En bref
« Mon support IA fonctionne-t-il ? » se résume à cinq chiffres lus ensemble, pas un seul : taux de résolution, taux de déviation, qualité des réponses, précision d'escalade et taux d'erreurs factuelles. Si la résolution et la déviation augmentent tandis que la qualité et le CSAT restent stables, ça fonctionne. Si le volume augmente mais que la satisfaction baisse, ou que le bot répond avec assurance sans rien citer, ce n'est pas le cas, peu importe à quel point il semble occupé.
Le piège est de juger un agent IA sur l'activité (« il a répondu à 4 000 tickets ! ») plutôt que sur les résultats. Un bot peut être énormément occupé et silencieusement dans l'erreur. La solution est d'observer le petit ensemble de métriques décrites ci-dessous, d'apprendre à repérer les signaux positifs et d'alerte, et idéalement de simuler avec vos vrais tickets passés avant de lui faire confiance en production.
J'ai passé les trois dernières années et plus à déployer des agents IA sur des files d'attente de support en direct chez eesel, c'est donc le tableau de bord que j'utiliserais vraiment.
Pourquoi « est-ce que ça fonctionne ? » est plus difficile qu'il n'y paraît
Voici ce que la plupart des tableaux de bord ne vous diront pas. Le mode d'échec effrayant pour le support IA n'est pas que le bot se taise, c'est que le bot ait l'air excellent tout en étant dans l'erreur.
J'ai observé un agent au ton assuré dire à un client « oui, nous prenons en charge le modèle de votre voiture » pour des marques qui n'étaient pas du tout dans la base de connaissances, simplement parce que quelqu'un avait écrit « nous prenons en charge tous les modèles » dans un document d'aide. Le bot n'était pas cassé. Il faisait exactement ce qu'on lui avait dit, et il le faisait avec une aisance parfaite. C'est la raison pour laquelle nous simulons maintenant chaque déploiement contre des tickets historiques avant de l'activer, plutôt que d'appuyer sur un interrupteur en espérant le meilleur.
Avant d'arriver aux chiffres : « fonctionner » signifie que l'IA résout les bons tickets correctement, transfère le reste proprement et n'invente rien entre les deux. Les comptages d'activité sont de la vanité. Les résultats sont la vérité. Si vous ne retenez qu'une idée de cet article, que ce soit celle-là.
Les cinq chiffres qui vous informent vraiment
Quand les équipes me demandent comment interpréter leur agent IA, je les oriente vers les mêmes cinq métriques de support client. Lues ensemble, elles capturent presque tous les modes d'échec.
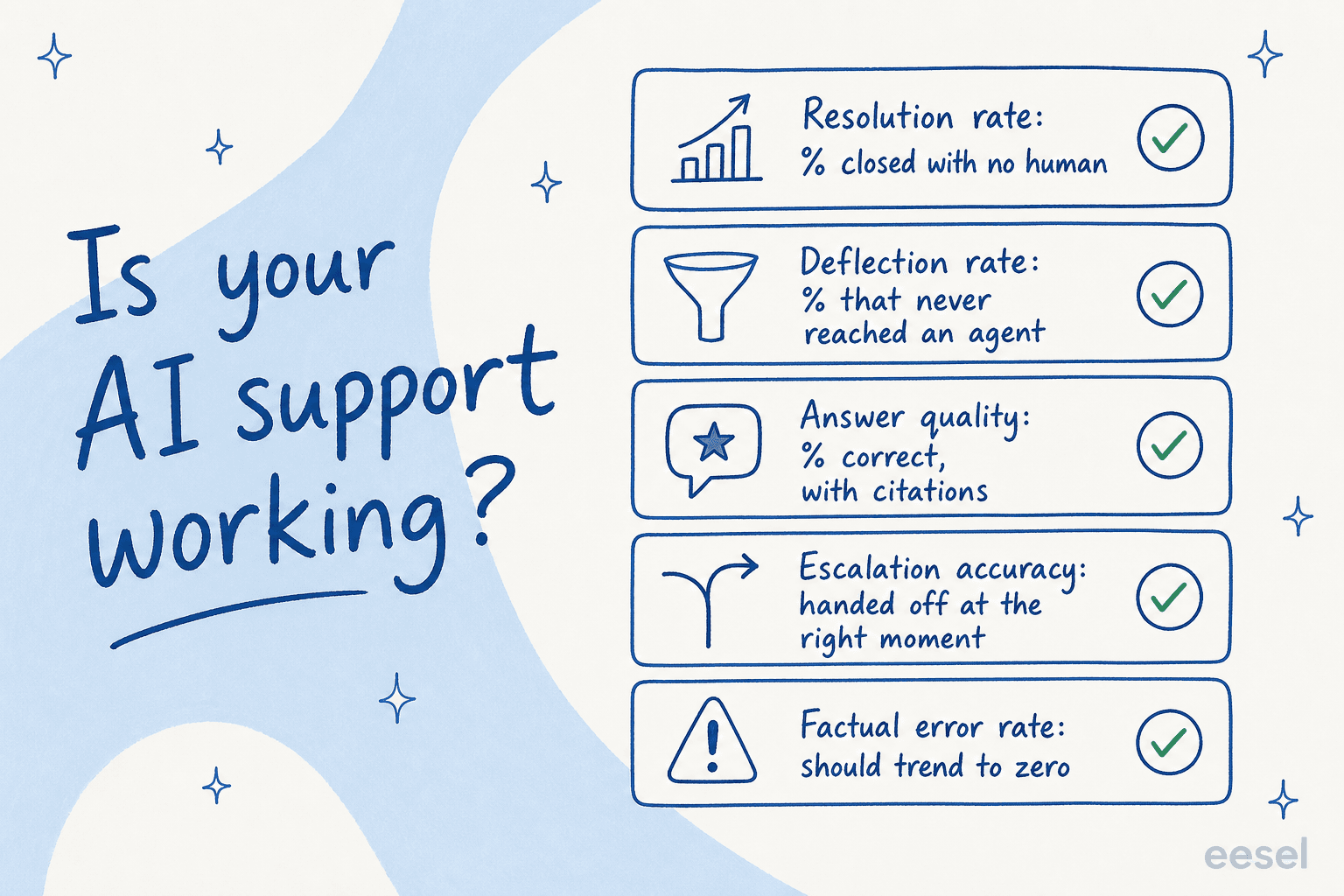
1. Taux de résolution
Le chiffre phare : quel pourcentage de tickets l'IA a-t-elle clôturés de bout en bout sans qu'un humain les touche. C'est celui qui est directement lié au coût, car chaque ticket résolu est un ticket qu'un agent n'a pas eu à ouvrir.
Qu'est-ce qui est « bon » ? Cela dépend entièrement de votre mix de tickets, mais le niveau 1 est là où l'IA prouve sa valeur en premier. Une application d'analyse de chauffeurs de l'économie à la demande sur Zendesk nous a indiqué, dans une évaluation publique sur G2, que eesel résolvait 73 % de leurs demandes de niveau 1 dès le premier mois, avec des résultats visibles dans un essai de 7 jours. À l'autre extrémité, un helpdesk IT interne fonctionnant sur Jira a commencé à 15 % de déviation et s'est fixé un objectif de 55 %. Les deux « fonctionnent ». L'essentiel n'est pas un benchmark universel, c'est la tendance : le taux de résolution augmente-t-il à mesure que vous alimentez l'agent en connaissances ?
2. Taux de déviation
Déviation et résolution sont utilisées de façon interchangeable, et elles ne devraient pas l'être. La résolution est un ticket clôturé sans humain. La déviation est un client qui a obtenu sa réponse et n'a jamais ouvert de ticket, généralement via un widget de chat ou en libre-service avant que la conversation ne devienne un cas de support.
Cela vaut la peine d'être suivi séparément, car un taux de déviation élevé est ce qui réduit silencieusement votre file d'attente. Si vous souhaitez la définition précise et la formule, nous avons rédigé ce qu'est le taux de déviation et comment l'améliorer, et un article séparé sur la mesure de la déviation IA par rapport à la déviation humaine pour éviter les doubles comptages.
3. Qualité des réponses
Le volume sans qualité est le piège. La vraie question derrière la résolution est donc : quand l'IA a répondu, avait-elle raison, et a-t-elle montré son travail ?
Cela est mesurable. Dans un échantillon d'une semaine sur 581 chats, nous avons évalué la qualité des chats à 96 %. Dans un autre échantillon de 434 chats, la répartition était 86 % bonne, 7 % partielle, 6 % déviée et 1 % totalement échouée, et sur les vrais tickets déclenchés par webhook (le test le plus difficile), c'était 79 % de bonne qualité. La méthode exacte compte moins que d'en avoir une : évaluez un échantillon de réponses pour leur exactitude et pour savoir si elles comportaient une citation. Une réponse sans source attachée est une réponse à laquelle vous ne pouvez pas faire confiance. Un fondateur de legal-tech avec lequel nous travaillons l'a bien résumé : avec eesel, ils pouvaient « définir des limites précises sur les sources et cela fournit toujours des citations transparentes », ce qui dans leur domaine fait la différence entre utile et un procès.
4. Précision d'escalade
Un bon agent IA sait ce qu'il ne sait pas. La précision d'escalade est donc vraiment une mesure du jugement : quand l'IA n'était pas sûre, a-t-elle transmis à un humain plutôt que de deviner ?
C'est le chiffre le plus sous-estimé de la liste. Vous voulez un agent qui résout avec confiance et escalade honnêtement, pas un qui répond à tout. Un responsable support d'une plateforme SMS a capturé l'idéal dans une évaluation G2 : l'IA « répond avec confiance, mais pas trop de confiance ». Cette deuxième partie est tout l'enjeu. Suivez votre taux d'escalade et, plus important encore, si les escalades se produisent au bon moment.
5. Taux d'erreurs factuelles
Enfin, le chiffre qui devrait tendre vers zéro : à quelle fréquence l'IA dit-elle quelque chose de faux. C'est différent des réponses « partielles ». Une erreur factuelle, c'est le bot qui affirme un fait erroné comme s'il était certain.
Lors d'un essai sur le vrai trafic Zendesk d'un bijoutier allemand (environ 1 000 tickets par mois), nous avons mesuré 93 % de précision de triage et 100 % de détection de spam sans faux positifs, mais aussi un taux d'erreurs factuelles de 7 % qui nous a indiqué exactement où la base de connaissances avait des lacunes. Ces 7 % n'étaient pas une raison d'abandonner le déploiement. C'était une carte. Chaque erreur factuelle pointe vers un document manquant ou contradictoire, qui est généralement corrigeable, et c'est l'essentiel de ce que couvre notre guide sur la prévention des hallucinations IA dans le support.
Les signaux positifs (et les signaux d'alerte)
Les chiffres vous montrent la tendance. Mais il existe des signaux qualitatifs que vous pouvez lire en un seul après-midi en parcourant les transcriptions, et ils sont souvent plus rapides qu'attendre un mois de données.
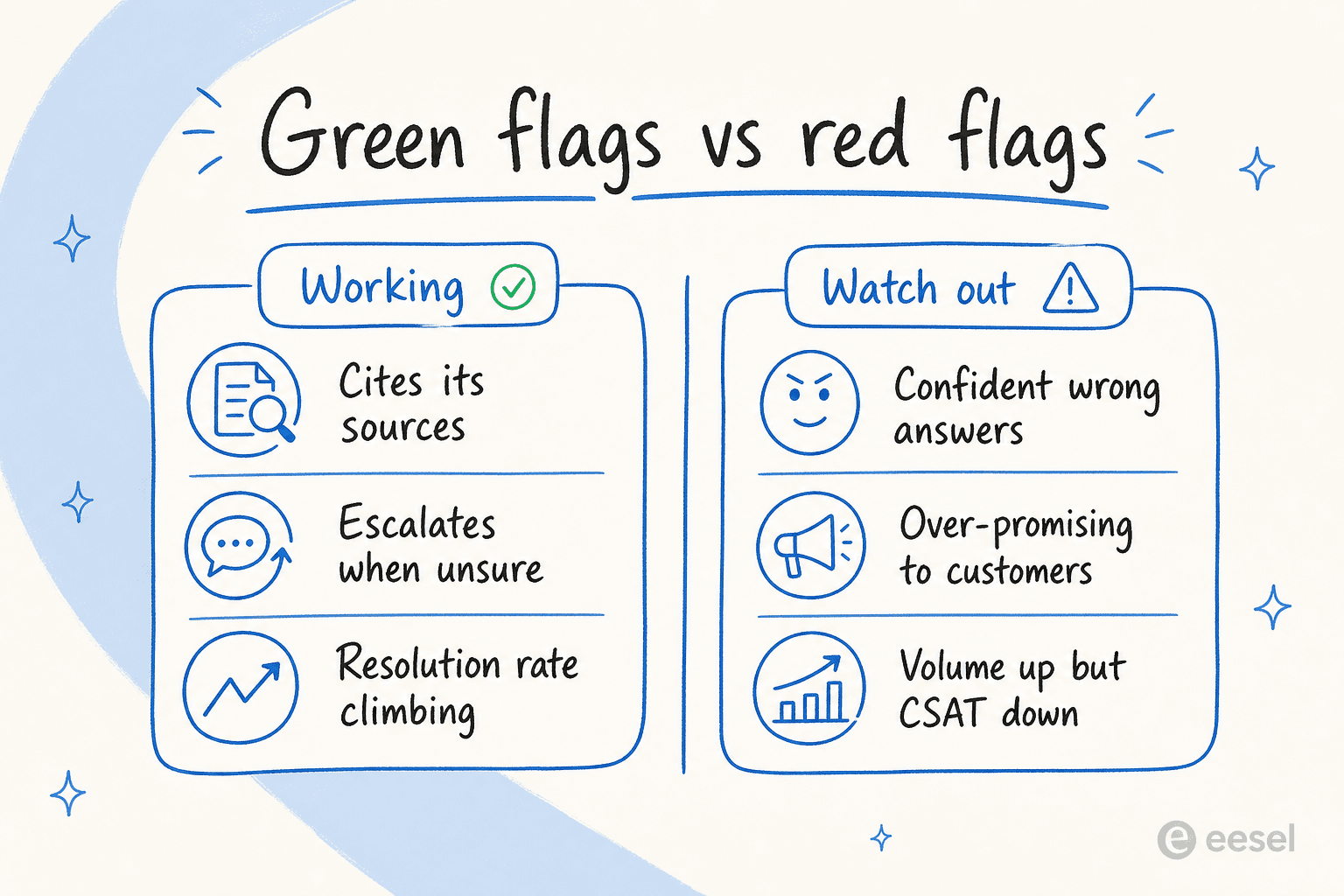
Les signaux positifs sont les plus simples. L'IA cite ses sources à chaque réponse. Elle escalade quand elle est vraiment incertaine plutôt que de bluffer. Votre taux de résolution augmente semaine après semaine, pas stationnaire. Et, le signe le plus simple de tous, vos agents arrêtent de se plaindre des tickets répétitifs.
Les signaux d'alerte sont ceux sur lesquels je concentrerais votre attention, car ils se cachent derrière des tableaux de bord qui semblent bons :
- Réponses incorrectes données avec confiance. L'exemple du modèle de voiture mentionné plus tôt. Le bot est fluide, certain et incorrect. C'est le schéma le plus dommageable de tous, car les clients le croient.
- Promesses excessives. J'ai vu des agents rassurer des clients d'une façon que l'entreprise ne peut pas soutenir. Un responsable support nous l'a signalé directement, en disant à l'IA « arrête de dire aux clients que nous allons les aider. Tu ne sais pas ça, » et « arrête de promettre des choses à des clients que nous ne pouvons pas faire ». Si votre bot prend des engagements sur des délais de livraison ou des résultats, c'est un problème de contrôle, pas un problème de connaissances.
- Volume en hausse, CSAT en baisse. L'agent traite plus, et les clients sont moins satisfaits. Cette divergence est le signe le plus clair que « occupé » et « fonctionnel » se sont dissociés.
- Pas de citations. Si vous ne pouvez pas voir d'où vient une réponse, le client non plus, et vous non plus quand vous l'auditerez plus tard.
La plupart de ces problèmes proviennent de lacunes dans la base de connaissances ou de garde-fous manquants, ce qui est une bonne nouvelle, car les deux sont corrigeables sans tout démonter. L'article sur les problèmes courants des chatbots IA approfondit les coupables habituels.
Où chercher vraiment
Tout cela suppose que vous pouvez voir ce que fait votre agent IA. Si votre outil ne vous montre qu'un total, c'est la première chose à corriger, car vous ne pouvez pas gérer ce que vous ne pouvez pas lire.
Les deux vues que je consulte le plus sont le tableau de bord des rapports et le journal d'activité brut. La vue des rapports est là où vit la tendance : volume de tâches dans le temps, comment les tâches ont été déclenchées (chat, e-mail, note interne) et combien d'actions IA ont été approuvées, rejetées ou attendent encore une décision humaine. Ce ratio approbation/rejet est un indicateur rapide de confiance.

Le journal d'activité est là où vous lisez le vrai travail. Chaque conversation, son canal, le ticket associé et si elle s'est terminée résolue ou en attente. C'est ici que vous allez pour vérifier par échantillonnage la qualité des réponses et repérer les cas confiants-incorrects que les chiffres agrégés lissent. Je parcourrais dix d'entre eux par semaine, au minimum.

Si votre helpdesk exécute déjà des enquêtes CSAT sur les conversations clôturées, associez ces scores spécifiquement aux tickets traités par IA. Cette seule coupe, CSAT sur les tickets résolus par IA versus ceux résolus par des humains, règle la plupart des débats « est-ce vraiment bon ? » plus rapidement que n'importe quoi d'autre.
N'attendez pas d'être en production pour le découvrir
Voici la partie que la plupart des équipes ignorent, et celle sur laquelle j'insisterais le plus : vous n'avez pas besoin de découvrir si votre IA fonctionne en la testant sur de vrais clients.
L'erreur est de traiter la mise en production comme un interrupteur marche/arrêt. Le meilleur modèle est une montée progressive. Vous faites progresser l'IA à travers des étapes d'autonomie à mesure que les chiffres le justifient, pas avant.
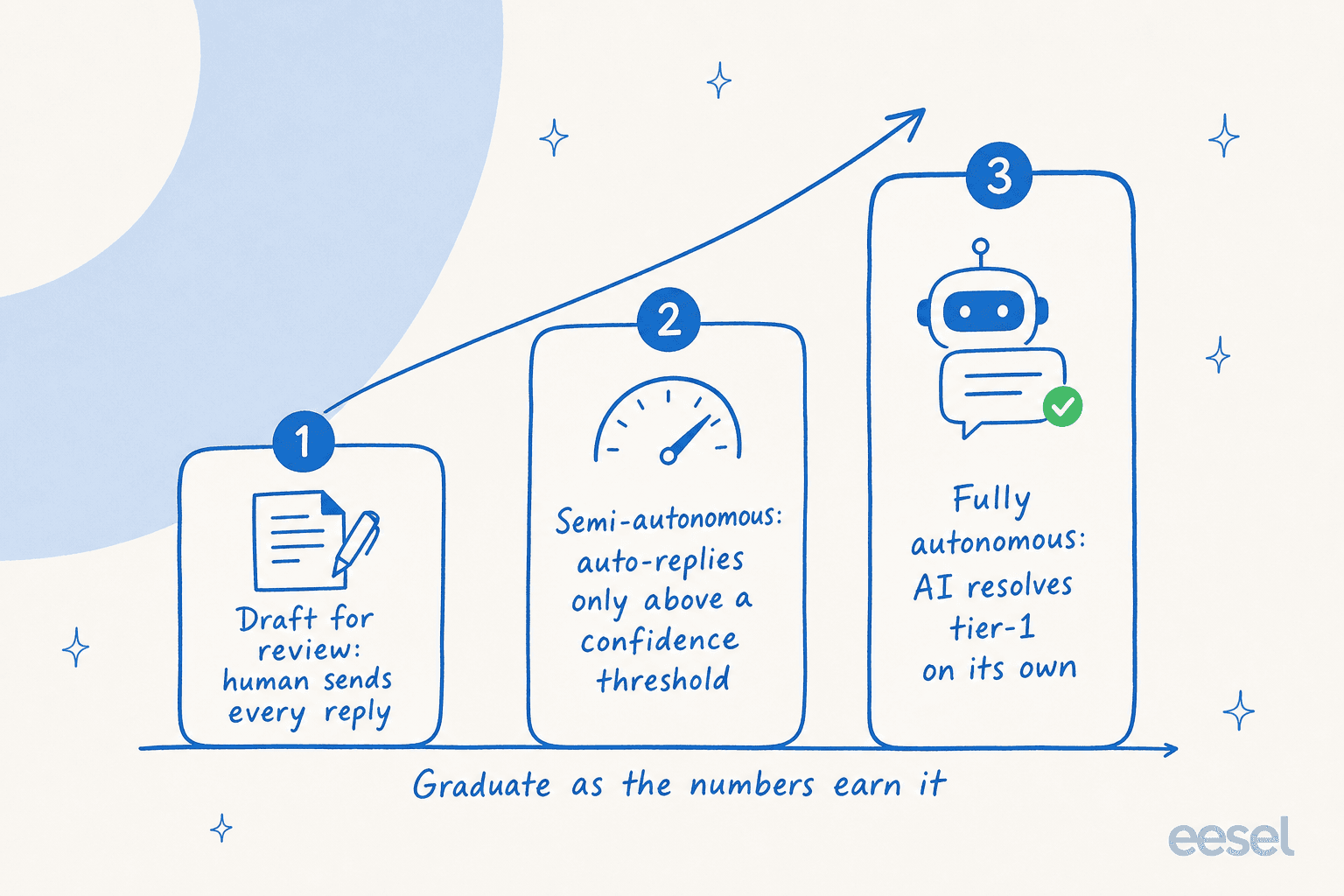
Vous commencez en mode brouillon, où l'IA rédige des réponses mais un humain envoie chacune d'elles, ce qui vous permet d'évaluer la qualité sans aucun risque pour le client. À mesure que les réponses se confirment, vous passez en semi-autonome, laissant l'IA répondre automatiquement uniquement au-dessus d'un seuil de confiance et acheminant le reste vers une personne. Une fois les chiffres stables, vous la laissez fonctionner entièrement de façon autonome sur les cas de niveau 1 qu'elle a mérités.
Même avant le mode brouillon, vous pouvez exécuter une simulation sur des milliers de vos vrais tickets passés pour voir exactement comment l'IA aurait répondu à chacun, avec un taux de résolution prédit, avant qu'une seule réponse en direct ne parte. Cet essai du bijoutier allemand que j'ai mentionné a effectué une validation croisée sur 100 tickets précisément de cette façon. Simuler d'abord est la façon de répondre à « est-ce que ça fonctionne ? » avant d'avoir risqué un seul client. C'est aussi, honnêtement, la partie que j'aimerais que plus d'équipes fassent, car elle transforme un acte de foi en une mesure.
Un avertissement juste, puisque je travaille sur ceci : eesel s'intègre profondément avec des helpdesks comme Zendesk, Freshdesk et Help Scout, donc je ne suis pas un observateur neutre de la catégorie. Mais l'approche rampe et simulation s'applique quel que soit l'outil que vous utilisez. Si votre fournisseur IA ne peut pas vous montrer un test à blanc sur vos propres tickets, c'est en soi un signal jaune qui mérite d'être questionné.
Essayez eesel
Si vous voulez répondre à « mon support IA fonctionne-t-il ? » avec des chiffres plutôt que des intuitions, c'est le problème que eesel est conçu pour résoudre. Vous connectez votre helpdesk et vos sources de connaissances, vous briefez l'agent en langage clair et vous exécutez une simulation sur vos tickets passés pour obtenir un taux de résolution prédit avant de passer en production, puis vous montez du mode brouillon à l'autonomie avec les rapports pour soutenir chaque étape.

Il fonctionne avec une tarification basée sur l'usage sans frais par siège, et il y a un niveau gratuit pour le tester sur votre propre file d'attente. Vous pouvez voir comment d'autres équipes ont mesuré leurs déploiements sur la page des témoignages clients, ou lire notre guide pratique de l'IA dans le support client pour le manuel complet. Essayez eesel et découvrez quel serait votre vrai taux de résolution.
Questions fréquentes
Quel est un bon taux de résolution pour un agent de support IA ?
En quoi la déviation IA diffère-t-elle de la résolution IA ?
Quels sont les signaux d'alerte que mon agent de support IA échoue ?
Puis-je tester mon support IA avant de le laisser répondre aux clients ?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








Comment savoir si mon support IA fonctionne ?