Wie messe ich den ROI von KI-Support?
Kurnia Kharisma Agung Samiadjie
Katelin Teen
Zuletzt bearbeitet June 21, 2026

Zusammenfassung
Um den ROI von KI-Support zu messen, setzen Sie einen Dollarbetrag für das an, was die KI jeden Monat zurückgewinnt, und ziehen dann die Kosten ab. Zurückgewonnener Wert = vollständig gelöste Tickets + zurückgegebene Agentenstunden + After-Hours-Abdeckung, die Sie nicht mehr besetzen müssen. Ziehen Sie die KI- und Einrichtungskosten ab, und was übrig bleibt, ist Ihr Ertrag.
Die Falle besteht darin, die falschen Dinge zu messen. Die Deflection Rate allein sieht in einer Demo großartig aus und beweist fast nichts über Geld. Die Metriken, die wirklich Budget bewegen, sind vollständige Lösungsrate, Kosten pro gelöstem Ticket und erste Reaktionszeit – mit CSAT als Leitplanke, die die Deflection-Zahl ehrlich hält.
Und der mit Abstand häufigste Grund, warum ROI-Zahlen falsch sind: keine Baseline. Wenn Sie Ihre Vorher-Zahlen nicht erfasst haben, haben Ihre Nachher-Zahlen keinen Vergleich. Die Lösung: Zuerst die Baseline erfassen, dann die KI gegen Ihre eigenen historischen Tickets simulieren, damit die Prognose auf Ihrem tatsächlichen Volumen basiert – nicht auf der Folie eines Anbieters.
Beginnen Sie damit, was ROI hier wirklich bedeutet
Ich habe mehr als drei Jahre damit verbracht, Support-Teams dabei zuzuschauen, wie sie versuchen, KI in Zahlen zu fassen, und das Gespräch beginnt fast immer an der falschen Stelle. Die Menschen greifen nach „Wie viele Tickets hat sie deflektiert?", weil es die Zahl ist, die das Dashboard zuerst anzeigt. Aber Deflection ist eine Aktivitäts-Metrik, keine Wert-Metrik. Finance genehmigt keine Verlängerungen auf Basis von Aktivitäten.
Die ehrliche Version der Frage lautet: Für jeden Euro, den ich für diese KI ausgebe, wie viele Euro kommen zurück? Das ändert alles. Sie messen nicht, wie beschäftigt die KI ist. Sie messen die Lücke zwischen dem Wert, den sie zurückgewinnt, und den Betriebskosten.
So sieht das aus.
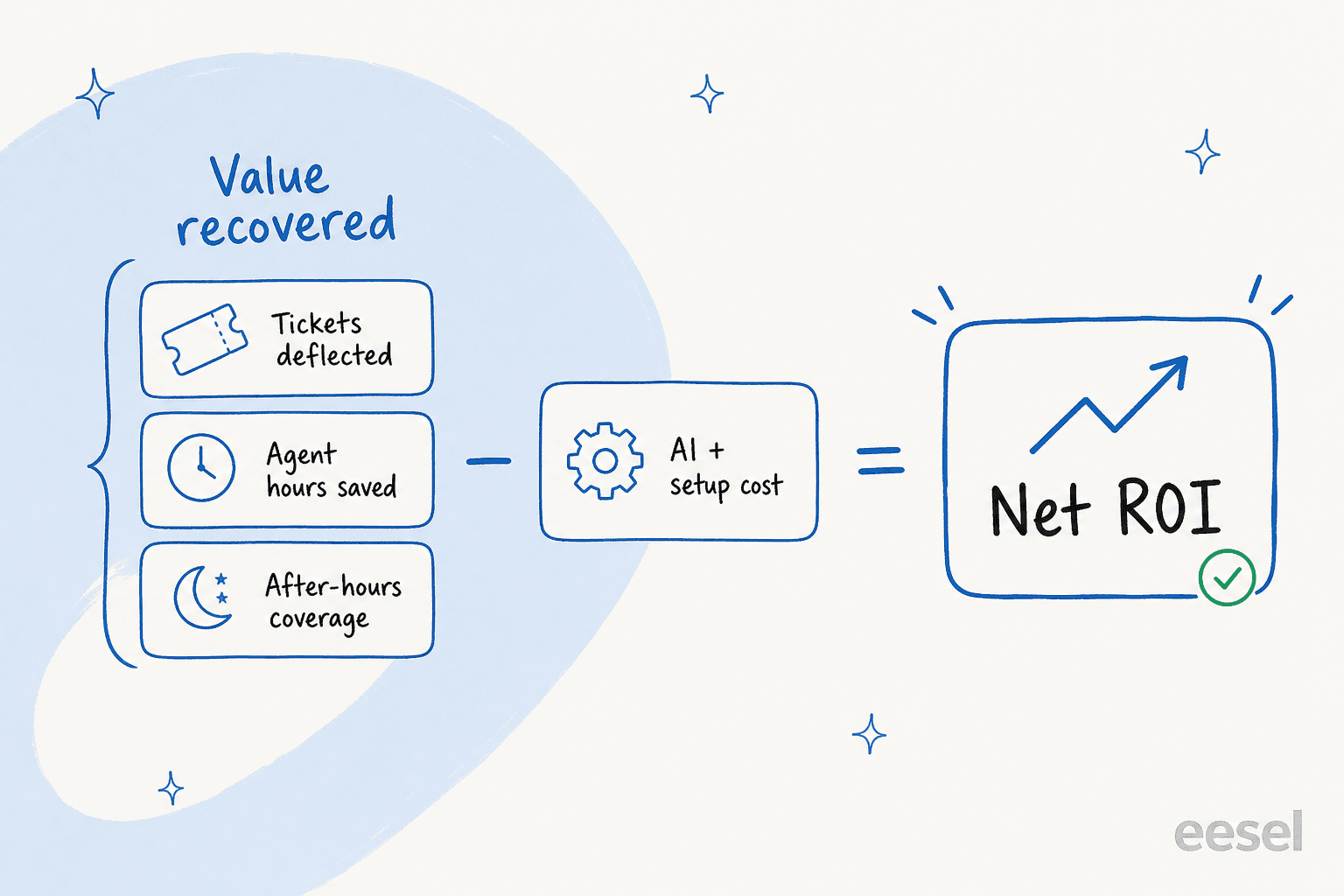
„Zurückgewonnener Wert" hat drei Teile, und die meisten Teams zählen nur den ersten:
- Vollständig gelöste Tickets. Die KI hat das gesamte Gespräch übernommen, kein Mensch hat es berührt. Multiplizieren Sie diese mit Ihren vollständig belasteten Kosten pro Ticket.
- Zurückgegebene Agentenstunden. Selbst bei Tickets, die ein Mensch schließt, spart ein KI-Copilot, der die Antwort entwirft oder die Warteschlange priorisiert, Minuten pro Ticket. Diese Minuten sind echtes Geld über Tausende von Tickets.
- After-Hours- und Spitzenabdeckung. Die Arbeit, die die KI um 2 Uhr nachts oder während eines Black-Friday-Ansturms übernimmt, für die Sie sonst Überstunden oder Zeitarbeitspersonal bezahlen würden oder die einfach liegen bleibt.
Wenn Sie den zweiten und dritten Punkt verpassen, werden Sie Ihren eigenen ROI erheblich unterschätzen. Die Kehrseite, auf die ich zurückkommen werde, ist, dass es genauso einfach ist, ihn zu überschätzen, indem man automatisch geschlossene Spam-Mails und „Ich weiß es nicht"-Antworten als Erfolge wertet.
Die Metriken, die es wirklich beweisen
Wenn die Formel das Ziel ist, sind Metriken der Weg dorthin. Sie brauchen ein kleines, ehrliches Set, kein 40-Zeilen-Dashboard, das niemand liest. Nach genug Rollouts ist dies die Kurzliste, zu der ich immer wieder zurückkomme.
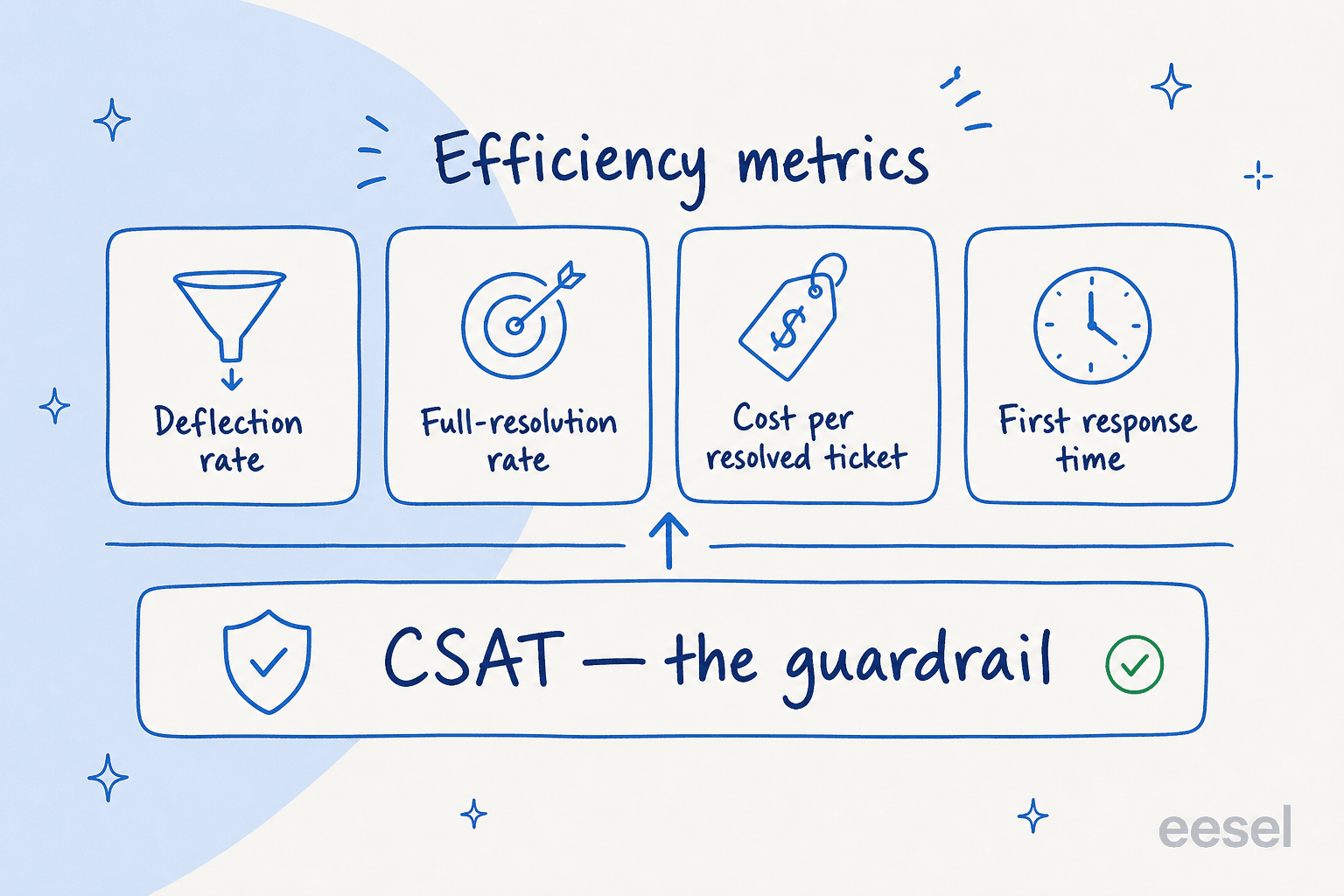
Deflection Rate. Der Anteil des eingehenden Volumens, den die KI ohne menschliche Beteiligung bearbeitet. Nützlich, aber die am meisten missbrauchte Zahl in der Kategorie, da sie trivial aufgebläht werden kann (mehr dazu unten). Verfolgen Sie sie, aber lassen Sie sie nie allein reisen.
Vollständige Lösungsrate. Der Anteil der Tickets, die die KI tatsächlich abgeschlossen hat, sodass der Kunde zufrieden ist – nicht nur beantwortet. Dies ist die Zahl, die sauber zu eingesparten Kosten abbildet. Die Lücke zwischen Deflection und vollständiger Lösung ist meist der Ort, an dem die Wahrheit liegt.
Kosten pro gelöstem Ticket. Ihre gesamten KI-Ausgaben dividiert durch vollständig gelöste Tickets, neben Ihren menschlichen Kosten pro Ticket. Dies ist die Zeile, die ein CFO zuerst liest. Unser eigener KI- vs. menschlicher Agent-Kostenvergleich geht auf die menschliche Seite dieses Verhältnisses ein, und der Offshore-Vergleich deckt die günstigere Arbeitsalternative ab, gegen die die meisten Teams sie abwägen.
Erste Reaktionszeit. KI antwortet in Sekunden, sodass diese Zahl meist steil abfällt. Dies ist der einfachste Erfolg, den man Stakeholdern zeigen kann, und er hängt direkt mit der SLA-Performance zusammen.
Dann die Leitplanke: CSAT. Dies ist die eine Metrik, die alle anderen überstimmen kann. Eine Deflection Rate von 70 % bei sinkendem CSAT ist keine 70 % Deflection – es ist ein Maß dafür, wie viele Kunden aufgegeben haben. Ein Betreiber hat die Messlatte während eines Anrufs perfekt formuliert:
„Die KI wird nie 100 % der Fragen beantworten können, aber wenn sie versucht und einfach antwortet ‚Entschuldigung, ich weiß das nicht', kann ich nicht alle meine 7.000 Tickets überprüfen, um zu sehen, ob die KI tatsächlich eine gute Antwort gegeben hat – dann ist der Sinn ein bisschen weg. Ich brauche eine KI, die nur die Tickets bearbeitet, bei denen sie sicher ist, und alle anderen in Ruhe lässt."
Das ist ein CX-Leiter eines Direct-to-Consumer-Unternehmens mit etwa 7.000 Tickets pro Monat, und er beschreibt genau, warum CSAT und vollständige Lösungsrate über der reinen Deflection stehen. Eine KI, die alles selbstsicher beantwortet – auch die Dinge, bei denen sie eskalieren sollte – wird beides ruinieren. Wenn Sie das vollständige Menü der zu beobachtenden Dinge möchten, gehen unsere Leitfäden zu KI-Kundensupport-Metriken und KI-Performance-Metriken tiefer als diese Kurzliste.
Ein Rechenbeispiel, das Sie kopieren können
Abstrakte Verhältnisse bringen kein Budget ein. Eine konkrete Zahl schon. Also nehmen wir ein Team, das 1.000 Tickets pro Monat bearbeitet – ein übliches Mittelmarktvolumen.
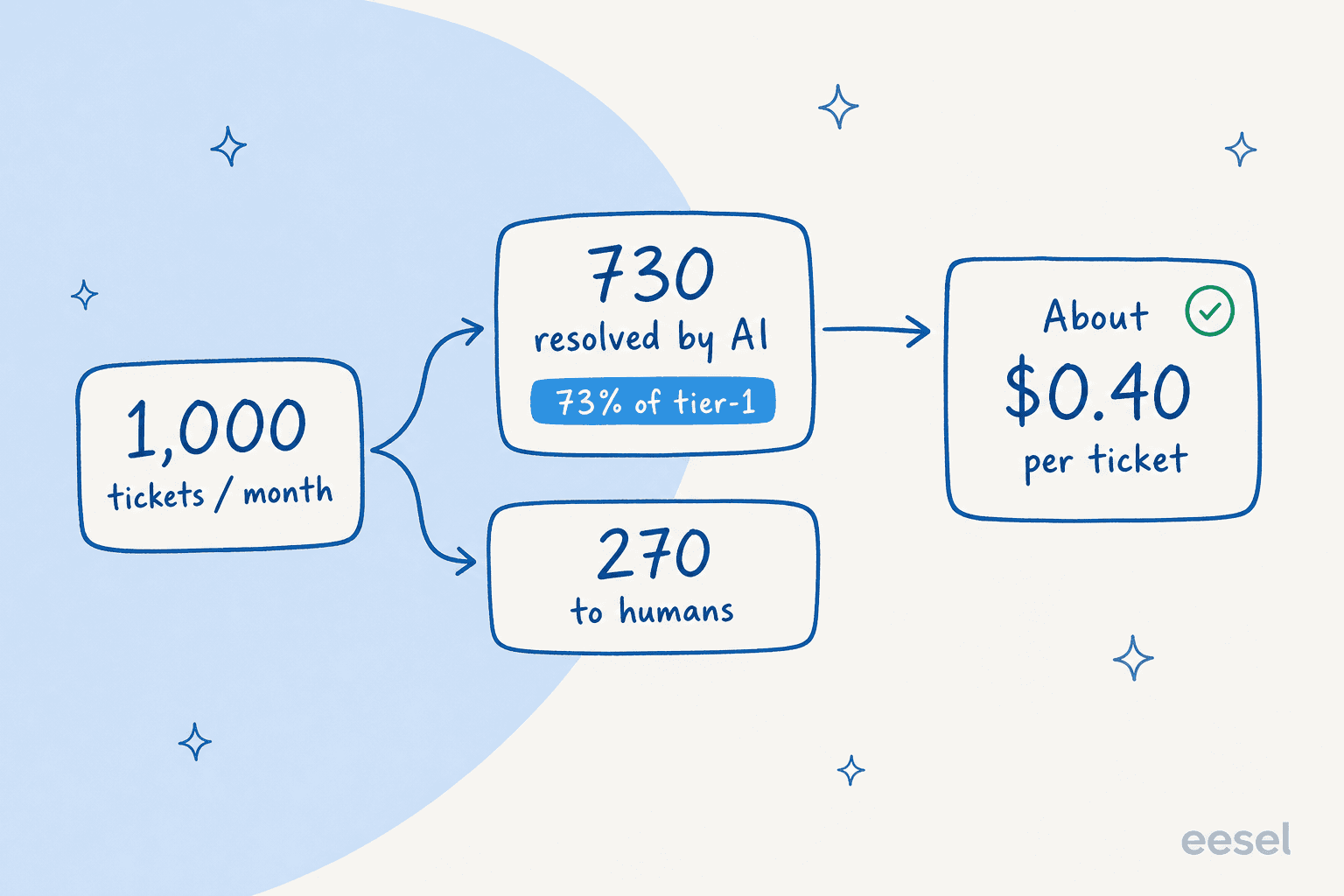
Angenommen, die KI löst im ersten Monat 73 % des Tier-1-Volumens vollständig. Das ist keine hypothetische Obergrenze: Eine Gig-Economy-Fahreranalyse-App auf Zendesk erzielte genau das innerhalb eines 7-tägigen Tests und hielt es aufrecht. Also 730 Tickets von Anfang bis Ende bearbeitet, 270 an Menschen weitergeleitet.
Jetzt die beiden Seiten der Bilanz:
| Position | Nur Menschen | Mit KI |
|---|---|---|
| Tickets / Monat | 1.000 | 1.000 |
| Von KI gelöst | 0 | 730 |
| Von Menschen bearbeitet | 1.000 | 270 |
| Ca. Humankosten / Ticket | 5,00 $ | 5,00 $ |
| KI-Kosten / gelöstes Ticket | - | ~0,40 $ |
| Monatliche Humanbearbeitungskosten | 5.000 $ | 1.350 $ |
| Monatliche KI-Kosten | - | ~292 $ |
| Monatliche Gesamtkosten | 5.000 $ | ~1.642 $ |
Das ist nur die Deflection-Seite, und sie zeigt bereits eine bedeutende monatliche Ersparnis. Die Kosten pro Ticket sind hier entscheidend: Pay-as-you-go- und Pro-Ticket-Modelle halten diese Zahl niedrig und vorhersehbar, während Pro-Resolution-Preise Sie genau in den Monaten mehr kosten, in denen die KI am besten arbeitet, und während saisonaler Spitzen, die Sie nicht kontrollieren können. (eesels Preisgestaltung ist Pay-as-you-go pro Aufgabe ohne Plattformgebühr, was dafür sorgt, dass die November-Rechnung wie die März-Rechnung aussieht.)
Jetzt kommen die Teile hinzu, die die meisten Teams vergessen: Die 270 menschlichen Tickets werden schneller bearbeitet, weil die KI sie entwirft und priorisiert, sodass Ihre Agenten weniger Zeit dafür benötigen. Und das After-Hours-Volumen, das die KI jetzt abdeckt, ist Volumen, für das Sie keine Überstunden bezahlen. Diese beiden Zeilen sind in der Regel genauso viel wert wie die reine Deflection-Ersparnis. Das ist der Unterschied zwischen einem soliden ROI-Fall und einem schwachen.
Die Baseline-Falle und andere Arten, wie die Zahl lügt
Hier ist das Versagensmuster, das ich am häufigsten sehe, und es hat nichts mit der Qualität der KI zu tun. Teams starten, beobachten, wie die Deflection-Zahl steigt, fühlen sich gut und können dann die eine Frage, die Finance stellt, nicht beantworten: „Im Vergleich zu was?" Niemand hat die Vorher-Zahlen aufgeschrieben.
Sie können keine Rendite berechnen ohne eine Baseline. Bevor Sie irgendetwas einschalten, erfassen Sie Ihre aktuellen Kosten pro Ticket, durchschnittliche erste Reaktionszeit, Lösungsrate und CSAT für mindestens einen repräsentativen Monat. Das ist Ihr „Vorher". Alles, was Sie danach messen, ist nur im Vergleich dazu bedeutungsvoll. Eine Support-Ticket-Analyse Ihrer letzten Monate ist die günstigste Stunde, die Sie für das gesamte Projekt aufwenden werden.
Ein paar weitere Arten, wie die Zahl still lügt:
- Spam als Deflection zählen. Wenn 20 % Ihres Posteingangs Spam sind und die KI ihn durch automatisches Schließen „deflektiert", ist das Hygiene, kein Wert. In einem echten Test waren 22 % des Posteingangs Spam. Rechnen Sie ihn heraus, bevor Sie den Prozentsatz feiern.
- „Ich weiß es nicht" als Lösung zählen. Eine Antwort ist keine Lösung. Wenn die KI antwortet, der Kunde aber trotzdem eskaliert, hat dieses Ticket Sie mehr gekostet, nicht weniger. Deshalb schlägt die vollständige Lösungsrate die Antwortrate.
- Den Eskalationspfad ignorieren. Tickets, die die KI weiterleitet, sollten schnell zum richtigen Menschen gelangen. Wenn die Eskalation unübersichtlich ist, verlieren Sie die Zeiteinsparungen, die Sie auf der Lösungsseite verbucht haben.
- Wissens-Pflege vergessen. Der ROI sinkt, wenn die Wissensbasis veraltet. Planen Sie ein wenig laufende Zeit für die Aktualisierung der Antworten ein und zählen Sie diese auf der Kostenseite.
Das sind keine Gründe, KI-Support zu misstrauen. Es sind Gründe, ihn wie ein Betreiber und nicht wie ein Marketingfachmann zu messen.
So machen Sie ROI von Tag eins an messbar
Der sauberste Weg, die Baseline-Falle zu vermeiden, ist, vor dem Launch eine Prognose zu erstellen und dann mit echtem Reporting gegen diese Prognose zu tracken. Dies ist der Teil, in dem ich das nennen werde, was wir gebaut haben, weil es genau um dieses Problem herum aufgebaut ist.
eesel führt eine Simulation über Ihre echten vergangenen Tickets durch, bevor irgendetwas live geht. Anstatt eine Deflection-Rate von einer Anbieterfolie zu raten, erhalten Sie eine Prognose, die auf Ihrem eigenen historischen Volumen basiert: wie viele Tickets sie gelöst hätte, wo sie eskaliert wäre und was das in Kosten übersetzt. Wir tun dies, weil wir zugesehen haben, wie selbstsicher klingende Bots still falsche Antworten gaben, und der einzig ehrliche Weg zu wissen, wie eine KI auf Ihrer Warteschlange verhalten wird, ist, sie gegen Ihre Warteschlange laufen zu lassen.

Sobald es live ist, verfolgt das Reporting-Dashboard die gleichen Metriken, für die dieser Beitrag argumentiert: Lösungsrate, Deflection und wo Kunden noch eskalieren, sodass Sie den ROI aufbauen sehen können, anstatt ihn bei der Verlängerung zu schlussfolgern. Es lässt sich in wenigen Minuten in Helpdesks wie Zendesk und den Rest Ihres Stacks integrieren, trainiert auf Ihrer Wissensbasis und vergangenen Tickets und ermöglicht es Ihnen, im Copilot-Modus zu beginnen (Entwürfe für Agenten), bevor Sie ihm die vollständige Lösung überlassen. Dieser schrittweise Anstieg ist selbst eine ROI-Taktik: Sie sichern sich die Einsparungen durch Agentenproduktivität, während Sie Vertrauen in die vollständige Automatisierung aufbauen.
eesel ausprobieren
Wenn Sie versuchen, den ROI von KI-Support zu messen, ist der schwierigste Teil, eine ehrliche Zahl zu erhalten, bevor Sie echtes Geld ausgeben. eesels Simulation liefert genau das: Sie lässt einen KI-Agenten gegen Ihre eigenen vergangenen Tickets laufen und zeigt die Deflection- und Kostenprognose vorab, sodass der Business-Case auf Ihren Daten basiert, nicht auf einem generischen Benchmark. Sie können es in Minuten auf Ihrer Wissensbasis trainieren, die Lösungsmetriken im Reporting-Dashboard beobachten und die Rechnung mit Pay-as-you-go-Preisgestaltung vorhersehbar halten. Es ist kostenlos zu testen, und die Simulation allein beantwortet die ROI-Frage meist schneller als eine Tabellenkalkulation.