Wie verhindere ich, dass mein KI-Support-Agent halluziniert?
Alicia Kirana Utomo
Katelin Teen
Zuletzt bearbeitet June 19, 2026

Was „Halluzination" für einen Support-Agenten wirklich bedeutet
Eine Halluzination liegt vor, wenn das Modell mit derselben Überzeugung etwas Falsches behauptet wie etwas Wahres. Große Sprachmodelle sagen die wahrscheinlichsten nächsten Wörter voraus. Wenn ihnen keine echte Antwort vorliegt, hören sie nicht auf. Sie produzieren eine flüssige, plausible, völlig erfundene Antwort. Das ist kein Fehler, den man beheben kann – so funktioniert die zugrunde liegende Technologie.
In einem allgemeinen Chatbot ist eine Halluzination ärgerlich. Im Support ist sie teuer. Deine KI-Kundensupport-Software spricht für dein Unternehmen, gegenüber einem Kunden, oft über Geld, Konten oder Zusagen, die du jetzt einhalten musst. Ich habe erlebt, wie ein selbstsicher klingender Bot einem Kunden stillschweigend etwas mitgeteilt hat, das schlicht nicht unsere Richtlinie war – und die Kosten lagen nicht im falschen Satz, sondern im Folgeticket, dem Vertrauensverlust und dem Menschen, der das wieder geradebiegen musste.
Eines unserer Kunden, ein dänisches Fahrzeug-Telematik-Team, das den Support über Zendesk abwickelt, erlebte die klarste Variante davon. Ihre Wissensbasis besagte „wir unterstützen alle Modelle", also bestätigte der Agent fröhlich, als ein Kunde nach einer Automarke fragte, die gar nicht in ihrer Datenbank war. Das Modell war nicht kaputt. Es las, was ihm gegeben wurde, und antwortete selbstsicher. Das Problem lag darin, was es lesen durfte und ob es gezwungen war, ehrlich über seine Quellen zu sein.
Das ist das ganze Spiel, und deshalb geht es im Rest dieses Beitrags um die Konfiguration, nicht um das Modell.
Die ehrliche Antwort: Verhindere, dass die falsche Antwort versendet wird – nicht, dass das Modell denkt
Hier ist die Umdeutung, die die meisten „Wie stoppt man KI-Halluzinationen"-Ratschläge verpassen. Man wird kein Modell bekommen, das nie ein falsches Token erzeugt. Das zu verfolgen ist ein aussichtsloser Kampf. Was man absolut tun kann, ist eine Reihe von Schleusen zu bauen, damit eine falsche Antwort abgefangen wird, bevor sie gesendet wird.
Denk daran als Tiefenverteidigung. Das Modell entwirft etwas. Bevor dieser Entwurf zu einer Antwort wird, die ein Kunde liest, durchläuft er Verankerung, eine Quellenprüfung, eine Konfidenzprüfung und bei Bedarf einen Menschen. Jede Schleuse, die das Problem erkennt, reicht aus.
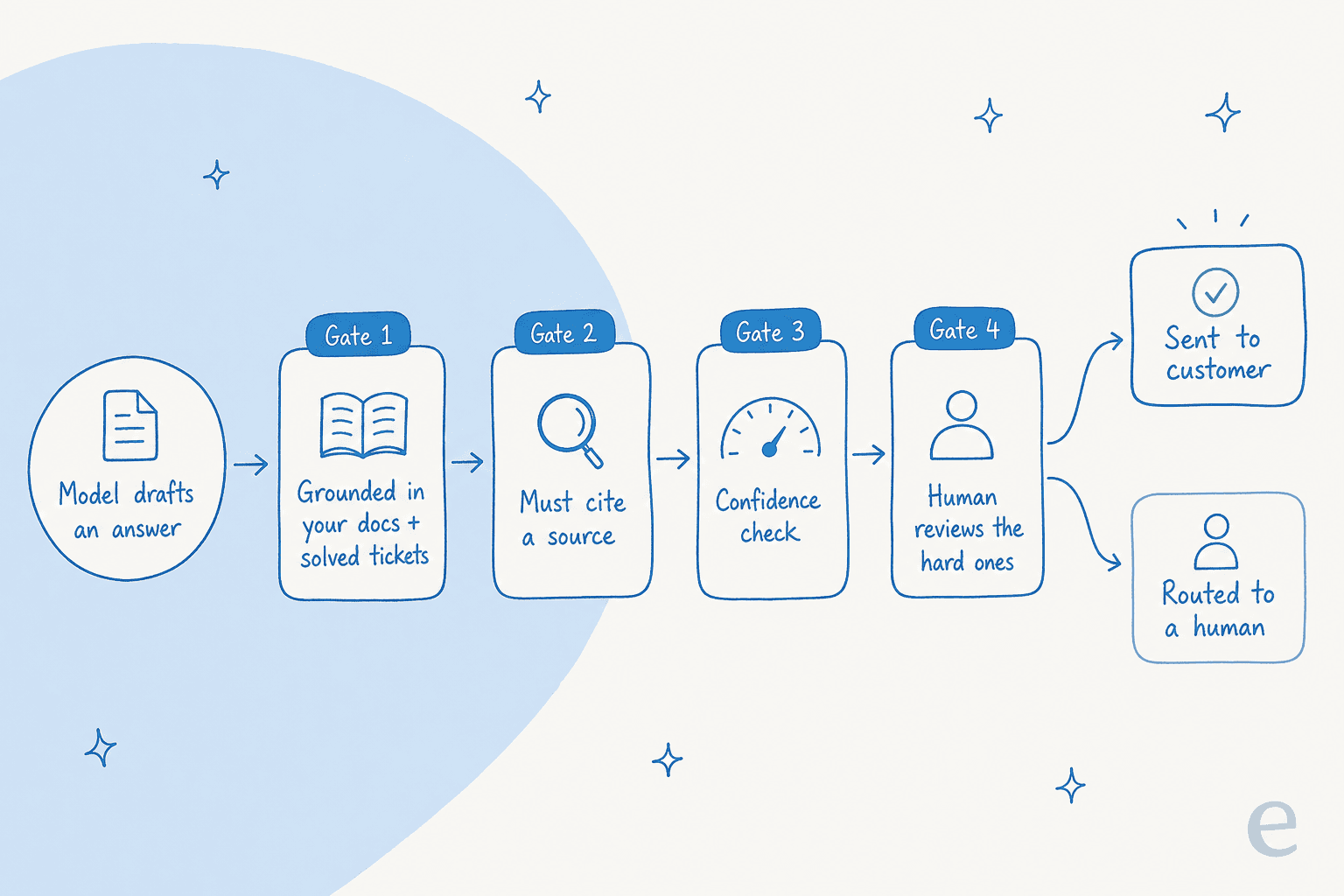
Warum das wichtig ist: Eine einzige nachweislich falsche Antwort zerstört das Vertrauen eines Kunden in alle anderen Antworten des Agenten, egal wie gut die übrigen sind. Das Ziel ist also kein perfektes Modell, sondern ein System, in dem der schlechteste Fall „die KI sagt nichts" ist und nicht „die KI sagt etwas Falsches". Lass uns das aufbauen.
Die Konfiguration, die einen Support-KI wirklich vor Halluzinationen schützt
Füttere ihn mit deinen eigenen Antworten, nicht mit dem offenen Internet
Der erste und größte Hebel ist die Verankerung: Der Agent sollte nur aus deinem eigenen Wissen antworten, nicht aus dem, was er beim Pre-Training absorbiert hat. Das bedeutet, ihn mit deinem Hilfecenter, deinen internen Dokumenten, deinen Makros und idealerweise deiner Sammlung gelöster Tickets zu verbinden und ihn dann auf dieses Material zu beschränken.
Gelöste Tickets sind die unterschätzte Quelle hier. Ein Hilfecenter sagt dem Agenten, was dein Produkt sollte tun; deine gelösten Tickets zeigen, wie dein Team tatsächlich auf echte Kunden in deinem Kundenservice-Workflow antwortet, einschließlich aller Sonderfälle. Ein KI-Wissensbasis-Chatbot, der aus beidem lernt, ist weit schwerer aus der Bahn zu werfen als einer, der nur auf Marketingseiten trainiert wurde.
Man kann sehen, wie ein unverankerter Agent in der Praxis aussieht. Ein Salesforce-Berater, der Agentforce bewertet hat, brachte es auf den Punkt:
„Außerdem sind die Halluzinationen wirklich schlimm, da wir nicht trainieren und es mit einem allgemeinen Modell arbeitet – manchmal gibt es einfach Informationen, die nicht unsere sind."
– Arjun G., Rezension von Salesforce Agentforce auf G2
„Informationen, die nicht unsere sind" – das ist das Indiz. Die Lösung besteht darin sicherzustellen, dass die einzigen verfügbaren Informationen deine sind. Die Kehrseite der Verankerung ist allerdings Veralterung, also halte die Quelle aktuell. Wie ein anderer Rezensent derselben Tool-Familie warnte:
„Wenn deine Content-Version-Dateien (Wissensartikel) seit 2021 nicht mehr aktualisiert wurden, gibt der KI-Agent Kunden selbstsicher veraltete Informationen."
– Muhammad O., Rezension von Agentforce Service auf G2
Verankert aber veraltet ist eine eigene Art falscher Antwort. Genau deshalb ist das Training von KI auf deiner Wissensbasis ein fortlaufender Job, kein einmaliger Import, und warum eine gut gepflegte Wissensbasis sich auszahlt – weit über die KI hinaus.
Jede Antwort muss ihre Quelle zitieren
Verankerung begrenzt, was der Agent lesen kann. Quellenangaben zwingen ihn zu beweisen, dass er tatsächlich etwas gelesen hat. Wenn der Agent das konkrete Dokument oder Ticket angeben muss, auf das sich seine Antwort stützt, passieren zwei gute Dinge: Ein Prüfer kann die Antwort mit einem Klick verifizieren, und der Agent hat keinen Platz zum Verstecken, wenn er improvisiert.
Das Muster, auf das ich bestehen würde: Keine Quelle, keine Antwort. Wenn der Agent keine Textstelle nennen kann, die seine Antwort unterstützt, soll er sie nicht senden, sondern eskalieren. Ein Mitgründer eines Legal-Tech-Unternehmens, mit dem wir zusammenarbeiten, erläuterte, warum das in seiner Welt nicht verhandelbar ist: Es gibt eine feine Linie zwischen hilfreich sein und in die Rechtsberatung abgleiten, und der einzige Weg, KI an Kunden heranzulassen, war mit genauen Vorgaben zur Quellenangabe und einer transparenten Quellenangabe bei jeder Antwort. Das ist eine hohe Messlatte, aber der richtige Standard für alle – nicht nur für regulierte Branchen.
Konfidenz-Schwellenwert setzen und danach routen
Das ist die wichtigste Maßnahme, und sie ist das Tor, das „vertrau mir" in einen echten Sicherheitsmechanismus verwandelt. Es ist der Unterschied zwischen einem Deflection-Tool, das man laufen lassen kann, und einem, das man ständig beaufsichtigen muss, und es lohnt sich, das richtig hinzubekommen, bevor man die Tier-1-Deflection skaliert. Der Agent soll nur automatisch antworten, wenn er sicher ist und eine Quelle hat. Alles andere wird für einen Menschen vorbereitet oder weitergeleitet.
Ein CX-Leiter bei einer DTC-Nahrungsergänzungsmittelmarke mit etwa 7.000 Gorgias-Tickets pro Monat formulierte die Logik besser als ich es könnte:
Die KI werde nie 100 % der Fragen beantworten, sagte er uns, aber wenn sie alles versuche und einem Kunden einfach „tut mir leid, ich weiß es nicht" schreibe, könne er nicht Tausende von Tickets durchgehen, um zu prüfen, ob sie gute Arbeit geleistet hat. Er brauchte eine KI, die nur die Tickets bearbeitet, bei denen sie zuversichtlich ist, und den Rest in Ruhe lässt. Das ist konfidenzbasiertes Routing in einem Satz, und es war das entscheidende Kriterium bei seiner Bewertung.
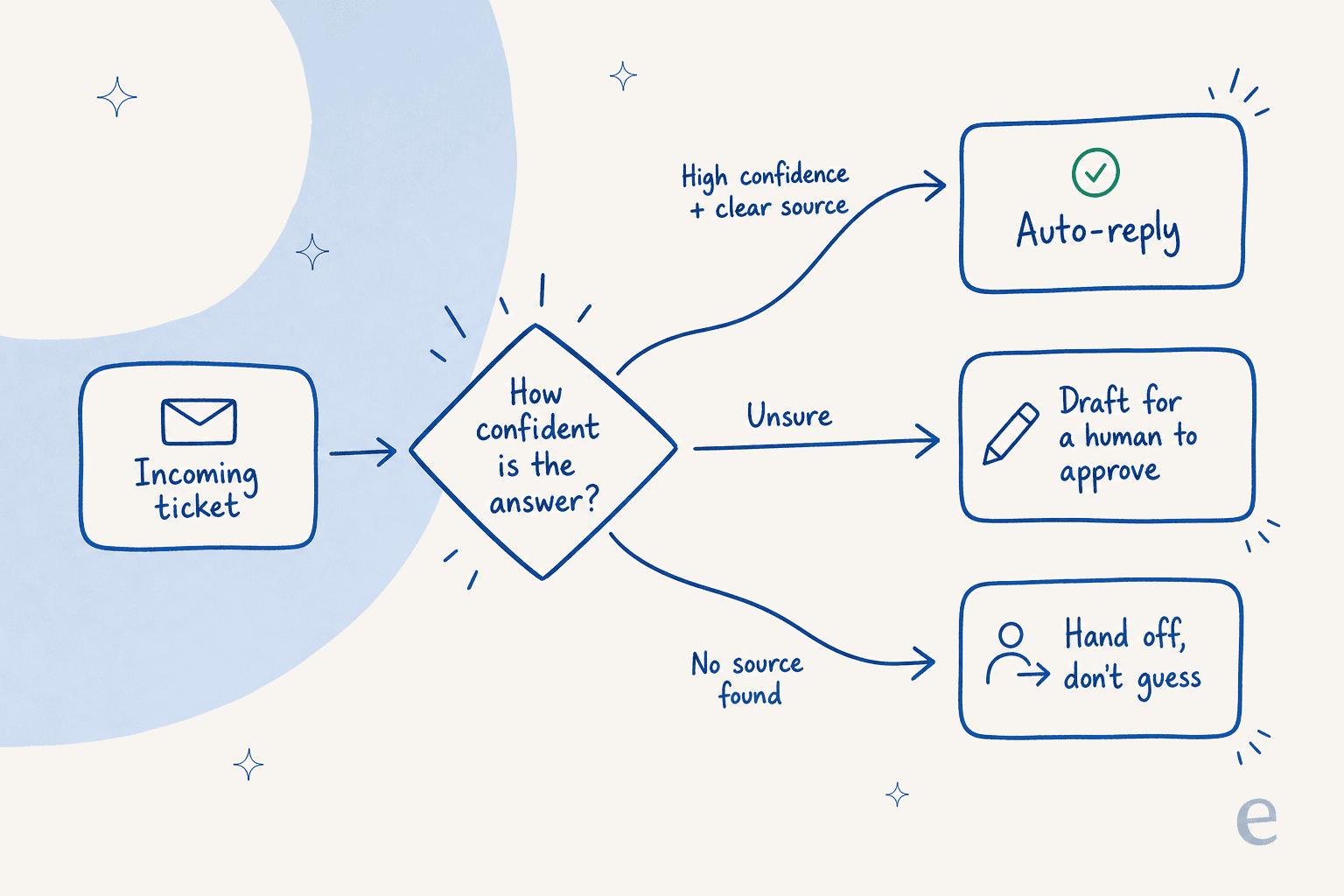
Die praktische Umsetzung: Lege eine Konfidenzgrenze fest, sende alles darunter als Entwurf an eine Person statt als automatische Antwort, und setze die Grenze zunächst hoch. Man kann sie immer senken, sobald man dem Agenten bei einem bestimmten Ticket-Typ vertraut. Hier zahlt sich auch gute KI-Chat-Eskalation aus, denn ein selbstsicheres „Ich hole einen Menschen" schlägt jede Mal eine selbstsichere falsche Antwort. Wenn man das mit älterer Technik vergleicht, ist das die klarste Grenzlinie zwischen einem KI-Agenten und einem regelbasierten Chatbot.
Themen absperren, die er nie anfassen darf
Einige Tickets sollten nie in die Nähe von Support-Automatisierung kommen, und das ist ein Feature, keine Einschränkung. Rückerstattungen über einem Schwellenwert, Kontolöschungen, alles Rechtliche, alles mit einem aufgebrachten Kunden mitten in einer Eskalation. Man will explizite Kontrolle, um diese Kategorien menschlich zu halten.
Das taucht ständig auf, wenn man sich anschaut, wie Leute tatsächlich deployen wollen. Ein Support-Leiter sagte uns geradeheraus, dass es bestimmte Tickets gibt, die er überhaupt nicht durch KI laufen lassen möchte. Das Hauptproblem eines eCommerce-Managers war nicht, dass die KI bei Fakten falsch lag, sondern dass sie zu viel versprach: „Hör auf, Kunden zu sagen, dass wir sie sortieren werden – du weißt das nicht." Beides ist im Grunde dieselbe Anfrage: Kontrolle darüber, was der Agent tun darf, nicht nur wie gut er es tut. Ein guter KI-Helpdesk-Agent lässt zu, diese Ausnahmen von Anfang an festzulegen und feste Leitplanken zu setzen, was er versprechen darf, ähnlich dem Ansatz von Breeze's Eskalation und Leitplanken.
Simulation auf vergangenen Tickets, bevor er mit einem einzigen Kunden spricht
Alle obigen Maßnahmen sind Hypothesen, bis man sie testet. Der Fehler, den Teams machen, ist, den Agenten live auf echten Kunden zu schalten und auf Feuer zu warten. Der weitaus sicherere Schritt ist, ihn zuerst im Simulationsmodus gegen Tausende historischer Tickets laufen zu lassen.
Eine Simulation spielt nach, wie der Agent auf Tickets geantwortet hätte, bei denen man das richtige Ergebnis bereits kennt. Man bekommt Abdeckung nach Thema, sieht genau, wo er halluziniert oder eskaliert hätte, und behebt die Wissenslücken, bevor irgendetwas davon ein echtes Gespräch berührt. Dann geht man schrittweise live, ein Ticket-Typ nach dem anderen.
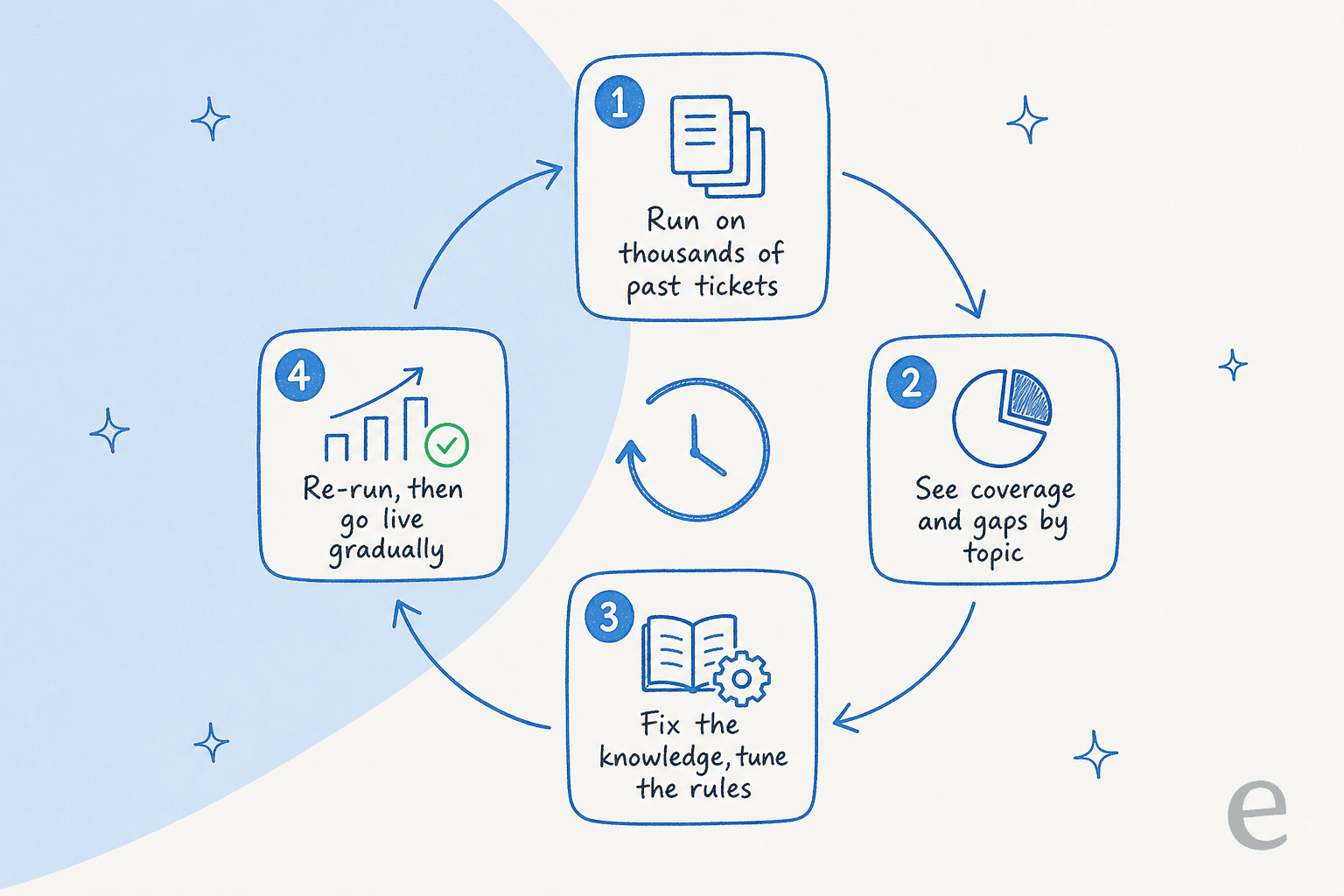
Das ist der Schritt, den wir nicht ohne einen Kunden ausliefern würden, denn er macht den Unterschied zwischen der Hoffnung, dass der Agent korrekt ist, und dem Wissen seiner Abdeckungszahl vor dem Launch. So hat auch das Fahrzeug-Telematik-Team, das ich erwähnt habe, sein „wir unterstützen alle Modelle"-Problem entdeckt – bevor die Kunden es taten, nicht danach.
Den Kreislauf schließen: Jede Korrektur ist Trainingsdaten
Das letzte Tor läuft nach dem Launch. Wenn ein Mensch einen Entwurf bearbeitet oder ablehnt, sollte dieses Signal direkt an den Agenten zurückfließen, damit derselbe Fehler nicht wieder auftritt. Bewerter fragen uns ständig danach, meist in einer Form wie „trackt ihr eigentlich, wenn ich eine Antwort genehmige oder ablehne?" Die Antwort sollte immer Ja sein, denn ein Agent, der aus Korrekturen lernt, wird jede Woche genauer, und einer, der es nicht tut, macht am Freitag dieselbe Halluzination, die man am Montag erkannt hat. Kombiniere das mit regelmäßiger Bewertung der Agentenleistung, und man hat ein System, das sich mit der Zeit verbessert statt zu driften.
Wie man erkennt, dass es wirklich funktioniert
Leitplanken, die man nicht misst, sind nur gute Absichten. Einige Kennzahlen zeigen, ob der Agent ehrlich ist:
- Containment- oder Lösungsrate bei den Tickets, auf die er tatsächlich geantwortet hat. Hohe Lösungsrate bei niedriger Eskalation ist gut. Hohe Lösungsrate bei steigender Wiedereröffnungsrate bedeutet, dass er selbstsicher Dinge abschließt, die er nicht sollte. Hier ist, wie man Containment-Rate und Eskalationsqualität zusammen betrachtet statt isoliert.
- Eskalationsrate nach Thema. Ein gesunder Agent eskaliert mehr bei mehrdeutigen Kategorien und weniger bei einfachen. Wenn die Eskalation bei allem flach ist, tut der Konfidenz-Schwellenwert wahrscheinlich nichts.
- Wiedereröffnungen und CSAT bei KI-bearbeiteten Tickets gegenüber menschlich bearbeiteten, als Teil der breiteren KI-Kundenservice-Metriken.
Der Sinn dieser Beobachtung ist, den Moment zu finden, in dem Konfidenz die Genauigkeit überholt hat, und den Schwellenwert zurückzudrehen. Richtig gemacht ist die „Ich weiß es nicht"-Rate des Agenten ein Feature, auf das man stolz ist, nicht eines, das man verbergen möchte.
eesel ausprobieren
Ich bin befangen, weil ich dabei helfe, es zu entwickeln, aber das ist genau die Konfiguration, auf die der eesel KI-Helpdesk-Agent ausgelegt ist. Er lernt am ersten Tag aus deinen vergangenen Tickets und Hilfedokumenten, zitiert seine Quellen und verwendet konfidenzbasiertes Routing, sodass er nur automatisch antwortet, wenn er sicher ist, und den Rest still deinem Team übergibt. Das Feature, auf das ich als erstes hinweisen würde, ist die Simulation: Man kann ihn über Tausende historischer Tickets laufen lassen und seine echte Abdeckung und Genauigkeit sehen, bevor ein einziger Kunde involviert ist, statt es live herauszufinden.
Diese Vorsicht zahlt sich aus. Für einen Logistik-Kunden haben wir im ersten Monat 73 % ihrer Tier-1-Anfragen gelöst (eesel KI-Helpdesk-Agent), und das funktioniert, weil der Agent die Tickets, die er nicht anfassen sollte, in Ruhe lässt. Er lässt sich in Zendesk, Freshdesk, Gorgias und weitere integrieren, und mit nutzungsbasierter Preisgestaltung zahlt man keine Kosten pro Nutzer, um einen Menschen in der Schleife zu halten. Man kann es kostenlos ausprobieren und in der Simulation beginnen.

Häufig gestellte Fragen
Warum halluziniert mein KI-Support-Agent überhaupt?
Kann man einen KI-Support-Agenten vollständig vor Halluzinationen schützen?
Was ist konfidenzbasiertes Routing bei einem KI-Support-Agenten?
Wie teste ich einen KI-Support-Agenten, bevor er Kunden antwortet?
Was kostet es, einen KI-Support-Agenten sicher zu betreiben?
Reicht es aus, einen KI-Agenten in meiner Wissensbasis zu verankern, um Halluzinationen zu stoppen?
Welche Ticket-Typen sollte ich von einem KI-Support-Agenten fernhalten?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








