O que é o DiffusionGemma?
O DiffusionGemma é um modelo da família aberta Gemma do Google que gera texto com um processo de difusão em vez da abordagem autorregressiva por trás de quase todos os chatbots que você já usou. Foi lançado pelo Google DeepMind em 10 de junho de 2026 como um modelo experimental de pesos abertos sob Apache 2.0, com o cartão oficial do modelo hospedado no site da DeepMind.
Aqui está a ficha técnica principal:
| Atributo | DiffusionGemma |
|---|---|
| Lançado | 10 de junho de 2026 |
| Licença | Apache 2.0 (pesos abertos) |
| Arquitetura | Construído sobre o Gemma 4, Mixture-of-Experts |
| Tamanho | 25,2B de parâmetros totais, ~3,8B ativos por passo ("26B A4B") |
| Geração | Remove ruído de blocos de 256 tokens em paralelo |
| Entrada / saída | Multimodal de entrada (texto/imagem/vídeo), texto de saída |
| Velocidade | >1.000 tok/s em uma H100, até 4x mais rápido que modelos AR comparáveis |
| Hardware | ~52 GB de VRAM em BF16, ~28 GB em INT8, executável a partir de ~18 GB quantizado |
A maioria desses números vem da cobertura de lançamento da MarkTechPost e do guia de implantação da Spheron, com o detalhe do bloco em paralelo do artigo da Digg. A etiqueta "26B A4B" é a abreviação do Google: um modelo Mixture-of-Experts da classe 26B que só dispara cerca de 3,8B de parâmetros em qualquer passo dado, o que é parte do motivo pelo qual é barato de rodar rápido.
A razão pela qual isso é importante não são as pontuações dos benchmarks. É que um laboratório de fronteira lançou um modelo de linguagem de difusão real e baixável. Por anos, a difusão foi o método dominante para imagens e vídeo (pense em Midjourney, Sora) enquanto o texto permaneceu teimosamente autorregressivo, a mesma família que alimenta assistentes do dia a dia como ChatGPT e Claude. O DiffusionGemma é um dos sinais mais claros até agora de que o lado do texto está alcançando.
Como o DiffusionGemma realmente funciona
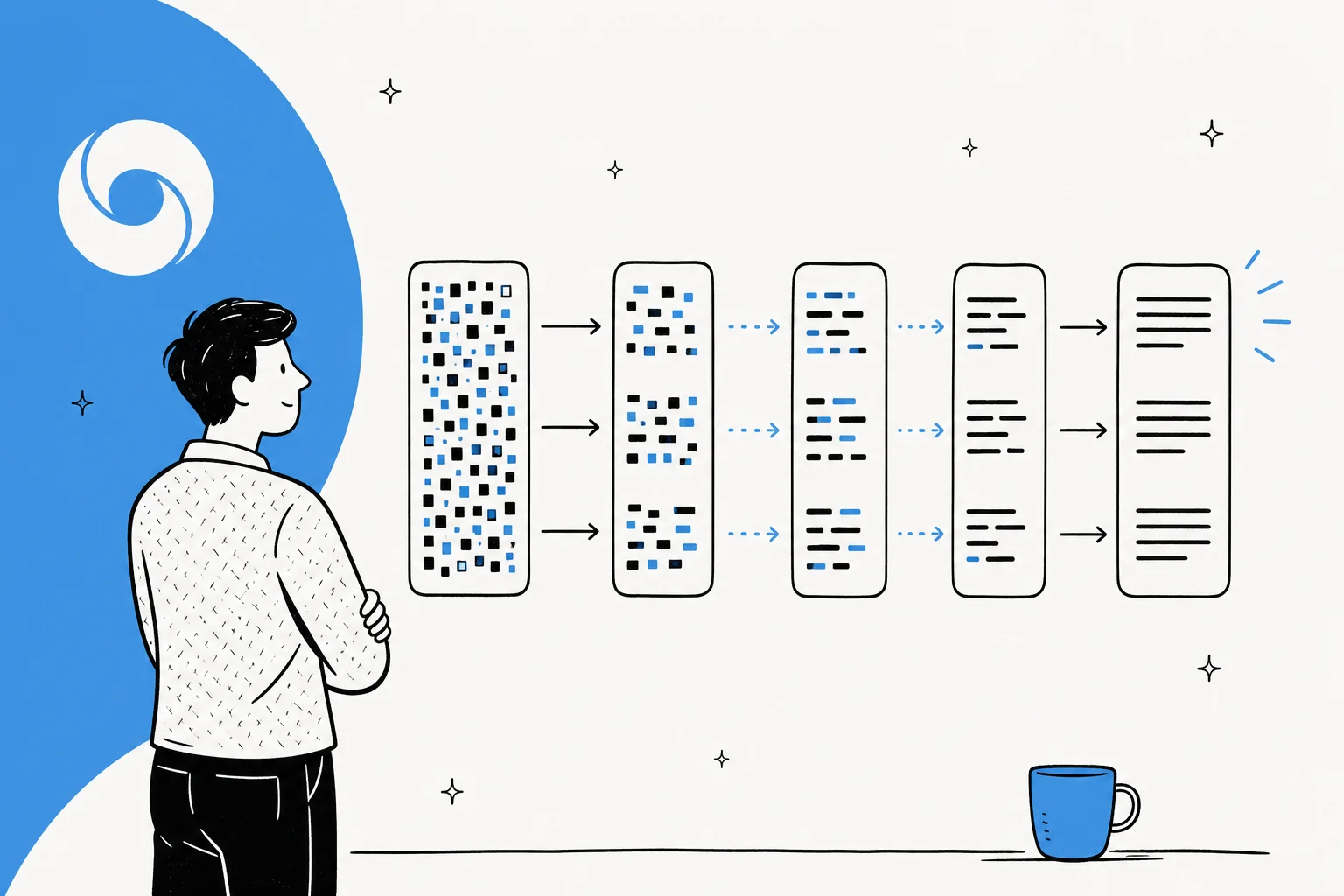
Os grandes modelos de linguagem padrão são autorregressivos. Como a Inception Labs coloca, eles "geram texto da esquerda para a direita, um token de cada vez, onde um token não pode ser gerado até que todo o texto anterior tenha sido gerado." Cada palavra espera pela anterior, então uma resposta longa significa uma longa sequência de passagens para a frente através de bilhões de parâmetros. É daí que vem a latência.
A difusão inverte isso. A abordagem dominante para texto é a difusão mascarada: você começa com um bloco de tokens que estão todos mascarados, e um transformer prevê as versões sem máscara, depois refina seu palpite ao longo de um punhado de passagens. O Google descreve isso como gerar texto "da maneira como a difusão de imagens funciona: em vez de prever o texto diretamente, o modelo aprende a gerar saídas refinando ruído passo a passo, para que possa iterar sobre uma solução rapidamente e corrigir erros durante a geração."
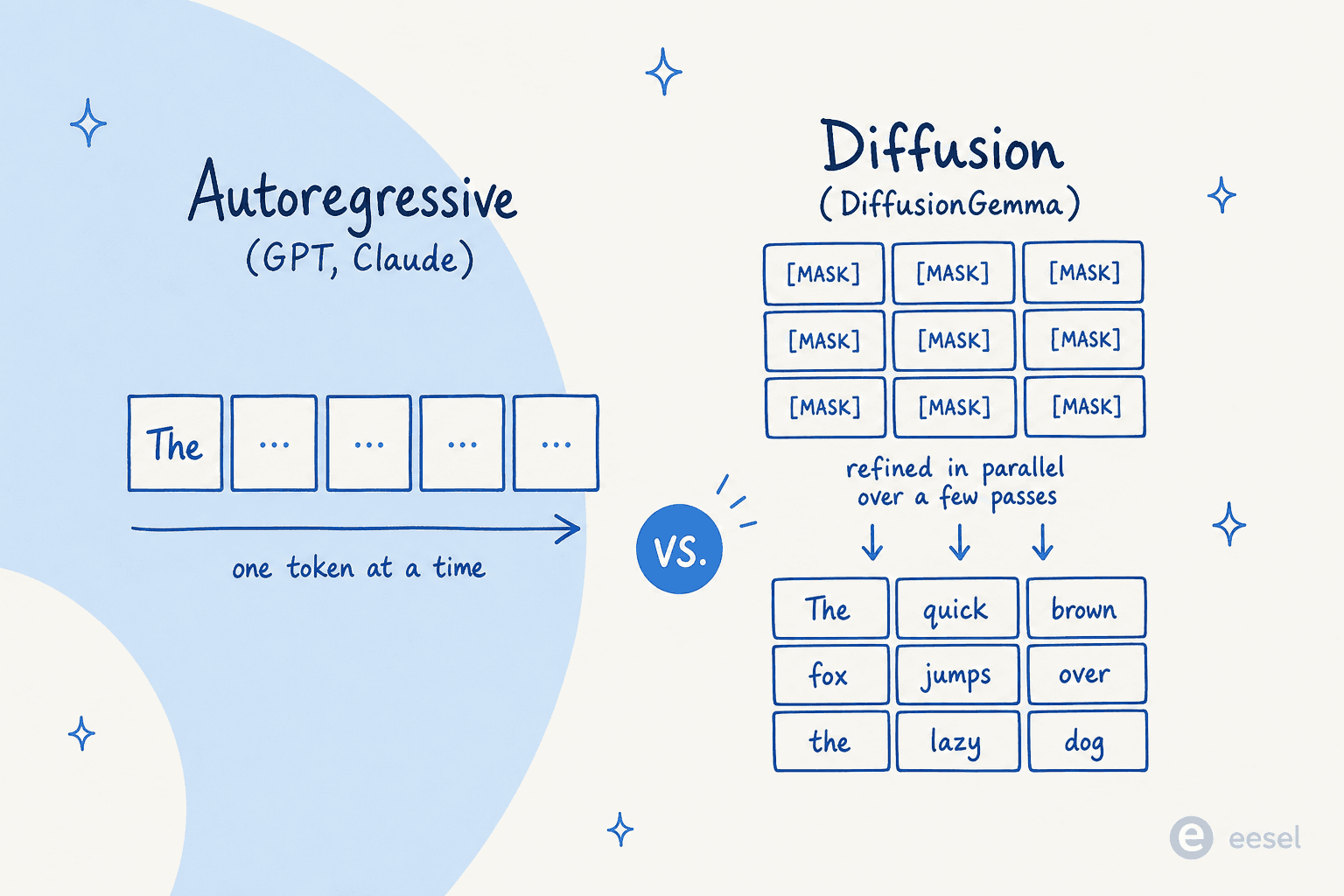
Um esclarecimento, porque o nome confunde as pessoas. A difusão aqui não substitui o transformer; ela substitui a autorregressão. Como explicou um comentário muito citado do Hacker News do usuário synapsomorphy:
"A difusão não está no lugar dos transformers, ela está no lugar da autorregressão. LLMs de difusão anteriores como o Mercury ainda usam um transformer, mas não há mascaramento causal, então toda a entrada é processada de uma só vez e a geração da saída é obviamente diferente."
As vantagens práticas de gerar em paralelo são três: velocidade pura, a capacidade de corrigir erros no meio da geração e preenchimento natural (porque o modelo pode ver o contexto dos dois lados de uma lacuna, ele é bom em editar o meio de uma sequência, não apenas anexar ao final). Andrej Karpathy destacou a novidade cedo, notando que a difusão "não vai da esquerda para a direita, mas tudo de uma vez. Você começa com ruído e gradualmente remove o ruído até um fluxo de tokens."
DiffusionGemma vs Gemini Diffusion: não os confunda
Este pega quase todo mundo, porque o Google lançou duas coisas de difusão de texto em cerca de um ano e deu a elas nomes quase idênticos.
O Gemini Diffusion foi mostrado no Google I/O em maio de 2025 como um modelo experimental, acessível apenas por lista de espera, rodando na infraestrutura do Google. Você não pode baixá-lo. O DiffusionGemma, por outro lado, é o de pesos abertos que você pode baixar e rodar por conta própria.
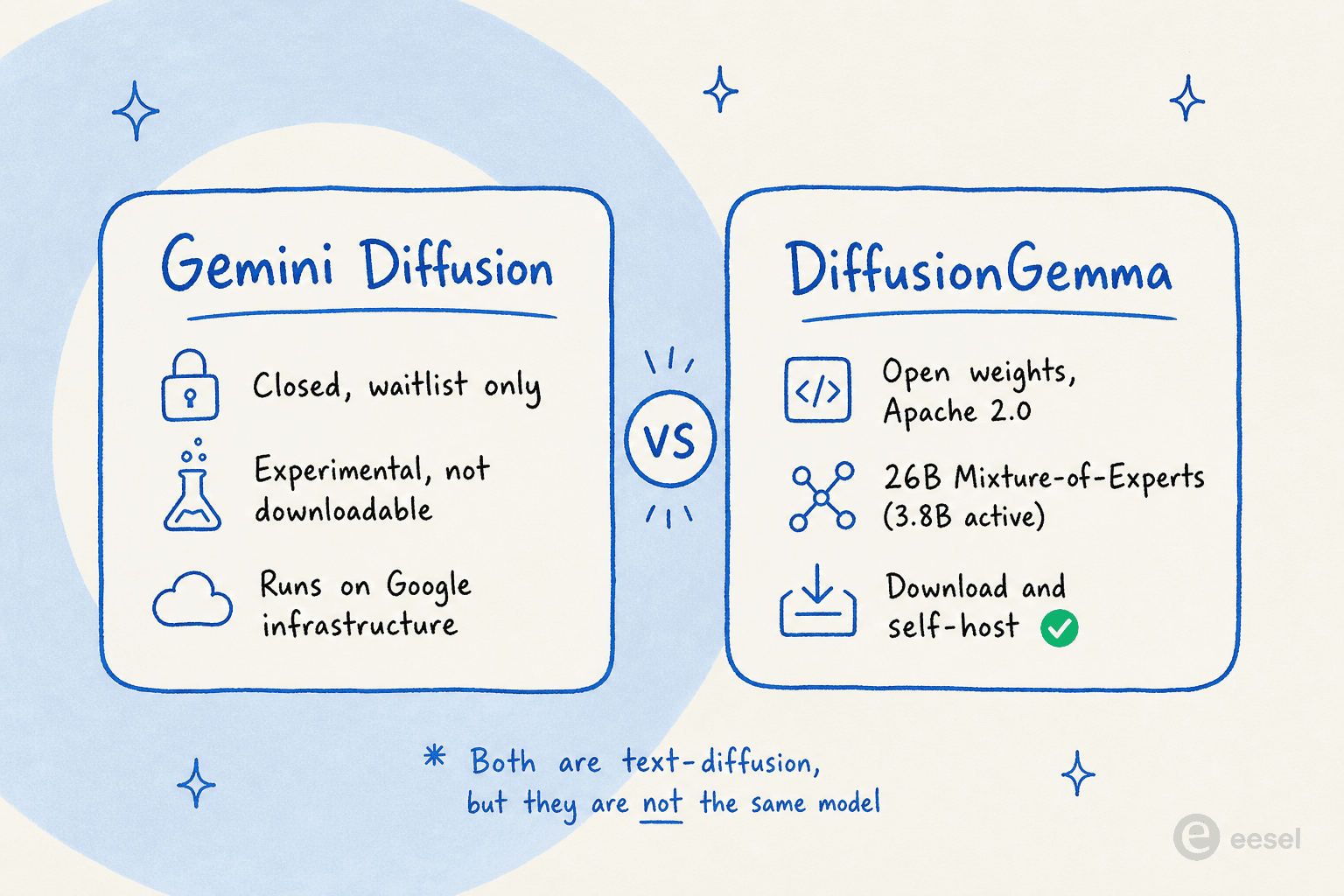
O fato de o Google ter lançado tanto um modelo fechado experimental quanto um lançamento de pesos abertos é em si a história: é o sinal mais forte de que os modelos de linguagem de difusão passaram do estágio de curiosidade de pesquisa. Quando um laboratório de fronteira disponibiliza uma arquitetura como código aberto, ele está apostando que outras pessoas construirão sobre ela.
Os números de velocidade (e por que são meio reais)
A velocidade é todo o argumento, então vamos olhar os números honestamente. Os >1.000 tok/s do DiffusionGemma ficam ao lado de seus primos de difusão, e a diferença para os modelos autorregressivos é grande:
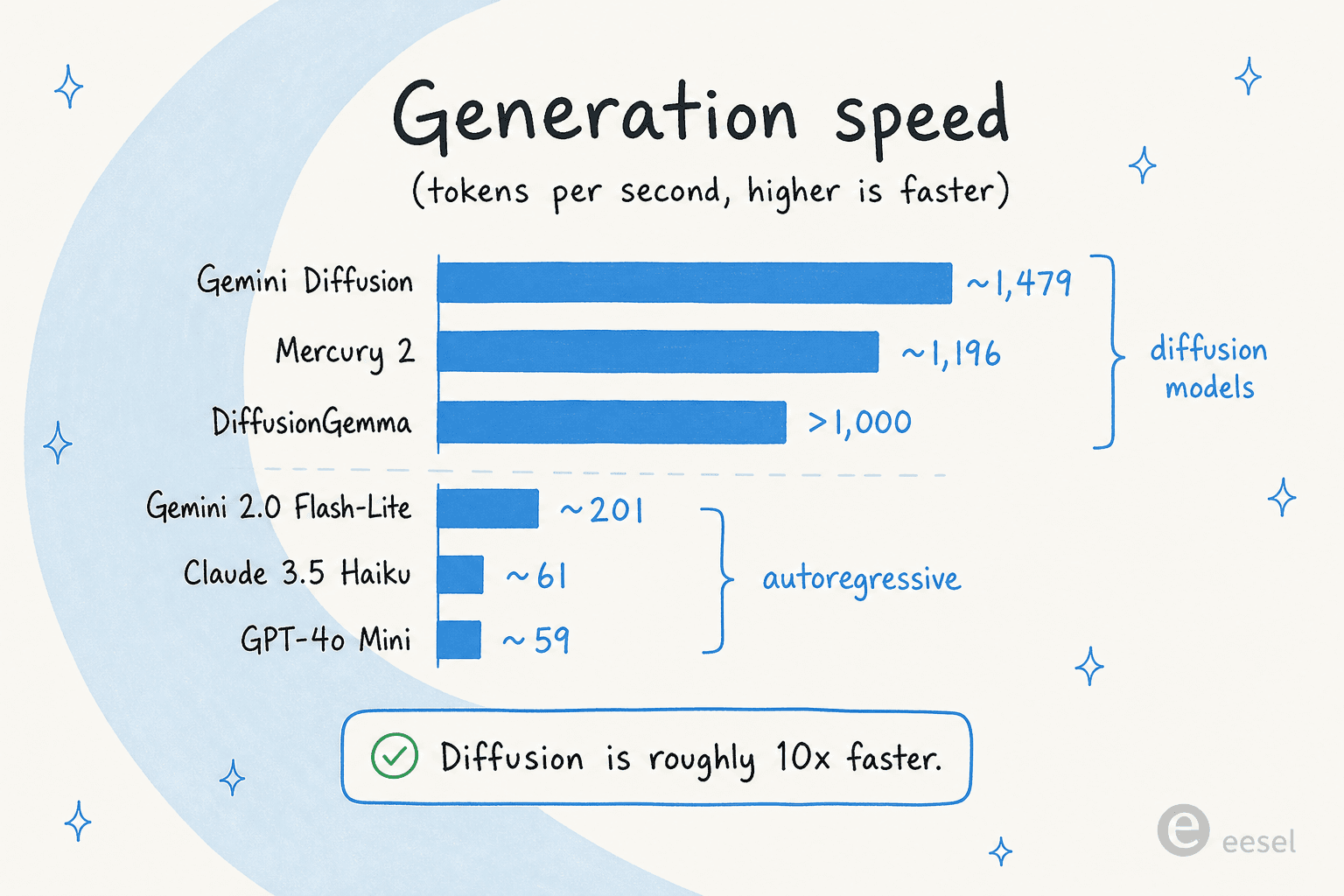
Algumas ressalvas mantêm isso com os pés no chão. Quase todos os números são medidos em uma NVIDIA H100, e a maioria são afirmações dos fornecedores. O único parâmetro independente neste espaço, a Artificial Analysis, corroborou a velocidade dos modelos Mercury da Inception, mas ainda não sua qualidade. Para o DiffusionGemma especificamente, os números de >1.000 tok/s e até 4x vêm do Google e de artigos de parceiros como a Yellow.com, ainda não de benchmarks de terceiros.
Para comparação, os modelos autorregressivos que as pessoas realmente usam em produção ficam muito mais baixos em taxa de transferência: de acordo com os próprios benchmarks da Inception, o GPT-4o Mini roda em torno de 59 tok/s e o Claude 3.5 Haiku em torno de 61, com o Gemini 2.0 Flash-Lite otimizado para velocidade em cerca de 201. Então o enquadramento de "cerca de 10x mais rápido" para a difusão se sustenta, pelo menos no papel.
Onde ele brilha e onde não
A leitura honesta é que a difusão realmente é mais rápida em trabalho limitado por taxa de transferência e paralelizável, mas a autorregressão ainda vence para muito do que os aplicativos de produção realmente precisam. A melhor fonte única aqui é a análise do engenheiro Sean Goedecke sobre as limitações da difusão, e ela se mapeia de forma limpa em uma decisão.
Recorra à difusão quando o trabalho for de alto volume e paralelizável: resumo em massa, classificação, reformatação, tradução ou loops de agente de baixa latência onde uma resposta rápida por passo se acumula. A geração de código é um caso particularmente bom porque a natureza de preenchimento da difusão combina com como você edita código, gerando o início e o fim de um bloco na mesma passagem.
Fique com a autorregressão quando você precisar de saídas curtas (a difusão executa todas as suas passagens de remoção de ruído independentemente, então faz trabalho extra para produzir uma resposta de seis tokens), janelas de contexto longas (a difusão não consegue reutilizar o cache chave-valor tão facilmente, então recalcula a atenção sobre todo o contexto a cada passagem) ou raciocínio em cadeia de pensamento difícil. Sobre esse último ponto, Goedecke faz o argumento mais afiado:
"Uma razão para ser amplamente cético sobre o potencial dos modelos de difusão para raciocinar é precisamente que eles fazem muito menos trabalho por token do que os modelos autorregressivos. Isso é simplesmente menos espaço para o modelo gastar 'pensando'."
Sean Goedecke, "Strengths and limitations of diffusion language models"
O próprio DiffusionGemma confirma o trade-off: ele permanece abaixo do Gemma 4 padrão em todos os benchmarks publicados. Um engenheiro que escreveu sobre stacks de agentes de produção colocou a crítica histórica à difusão de forma memorável, que os primeiros modelos "eram rápidos do jeito que um relógio quebrado é rápido, não importa quão rápido você obtém a resposta errada" (dev.to). A lacuna de qualidade está se fechando em pequena e média escala, mas ainda é visível na fronteira.
O movimento pragmático em que a maioria das equipes vai chegar não é a substituição, é o roteamento: envie passos simples e de alta frequência (buscas, formatação, classificação) para um modelo de difusão rápido e reserve um modelo autorregressivo de fronteira para raciocínio profundo. É a mesma lógica por trás de escolher a ferramenta certa para um trabalho em vez de um helpdesk com IA fazendo tudo.
O que o DiffusionGemma significa para as equipes de atendimento ao cliente
A difusão parece perfeita para o suporte. O chat ao vivo e os agentes de suporte com IA são exatamente o caso de baixa latência e voltado ao usuário onde a diferença entre uma resposta de um segundo e uma de vários segundos decide se a ferramenta parece em tempo real ou como "um serviço pelo qual você espera." Para copilotos voltados ao cliente, uma resposta abaixo de um segundo pode realmente ser a diferença entre a adoção e o abandono.
Mas aqui está o que contestaríamos: para uma equipe de suporte, a arquitetura do modelo importa muito menos do que a orquestração ao seu redor. Duas ressalvas pousam diretamente sobre esse caso de uso.
Primeiro, as respostas de suporte reais se apoiam em contexto longo e recuperação, e o contexto longo é exatamente o ponto fraco da difusão. Uma boa resposta não é uma geração do zero; é uma resposta fundamentada sobre sua base de conhecimento, histórico de tickets e documentos de políticas. A recuperação e a fundamentação importam mais para a qualidade da resposta do que se os tokens finais saíram da esquerda para a direita ou em paralelo, que é o cerne da questão RAG vs LLM.
Segundo, qualidade e confiabilidade superam a velocidade pura para qualquer coisa voltada ao cliente. Um modelo mais rápido conectado a conhecimento desatualizado ou a regras de escalonamento fracas apenas produz respostas erradas mais rápido. Esse é o problema do relógio quebrado, aplicado ao suporte.

Então, se você é um líder de suporte lendo sobre o DiffusionGemma e se perguntando se precisa dele: provavelmente não diretamente. O que você quer é uma plataforma que acerte na fundamentação, nas proteções e nas integrações de helpdesk, e que então se beneficie discretamente de qualquer modelo que seja o mais rápido e melhor por baixo dos panos. A latência é uma alavanca entre muitas, e raramente é a que está segurando sua taxa de resolução. A questão maior costuma ser o custo por ticket versus um humano lidando com ele.
Experimente a eesel
A eesel AI vende colegas de equipe com IA que vivem dentro do seu helpdesk existente (Zendesk, Freshdesk, HubSpot, Gorgias, Front) e cuidam do suporte de nível 1 aprendendo com seus tickets passados e documentos de ajuda desde o primeiro dia. A razão pela qual é relevante aqui: a eesel é deliberadamente agnóstica quanto ao modelo, então o debate de arquitetura acima é um que você não precisa vencer. O que ela acerta é a orquestração que de fato move os números, como o roteamento baseado em confiança que rascunha em vez de enviar quando está incerto, e um modo de simulação que roda contra seus tickets passados para que você possa ver a cobertura antes de entrar no ar. A Gridwise viu 73% das solicitações de nível 1 resolvidas no primeiro mês, e os preços são baseados no uso a partir de US$ 0,40 por ticket resolvido sem taxas por assento, então você paga por resultados em vez de horas de GPU.
Perguntas frequentes
O que é o DiffusionGemma em termos simples?
O DiffusionGemma é o mesmo que o Gemini Diffusion?
Quão rápido é o DiffusionGemma comparado a um LLM normal?
Posso usar o DiffusionGemma para atendimento ao cliente?
Quanto custa rodar o DiffusionGemma?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








