
O que e um modelo de IA baseado em difusao?
Um modelo de difusao e um modelo generativo que aprende a construir dados revertendo um processo gradual de adicao de ruido. A ideia vem da fisica: voce define uma cadeia de etapas que adicionam lentamente ruido aleatorio a dados reais e, em seguida, treina uma rede para reverter esse processo e reconstruir amostras a partir do ruido. O trabalho fundacional e o de Sohl-Dickstein et al. (2015) e o artigo de 2020 sobre modelos probabilisticos de difusao com remocao de ruido.
Ha duas metades. No processo direto, voce pega uma imagem real e adiciona um pouco de ruido gaussiano repetidamente, ate que ela se torne pura estatica. Essa parte nao requer aprendizado; sua unica funcao e fabricar pares de treinamento. No processo reverso, uma rede neural aprende a desfazer uma etapa de ruido por vez. No momento da geracao, voce parte de ruido aleatorio e executa a rede repetidamente, cada passagem removendo um pouco mais ate que surja um resultado coerente.
Aqui esta a intuicao que faz tudo se encaixar. Imagine filmar uma escultura de gelo derretendo ate virar uma poca e depois rodar o filme de tras para frente: partindo de uma poca disforme e, quadro a quadro, recongelando-a de volta na escultura. Como o modelo trabalha em toda a tela a cada etapa, ele pode continuar corrigindo erros anteriores ao longo do caminho.
Esta e a tecnica que alimenta a maioria das geracoes modernas de imagem, video e audio. A difusao esta por tras de Sora, Midjourney e Riffusion, junto com o DALL-E 2, o Imagen e o Stable Diffusion. O fio condutor: todos partem de ruido e removem o ruido iterativamente em direcao a um resultado, guiados pelo seu prompt.
Como os LLMs autorregressivos geram texto
Para entender por que a difusao e um marco para texto, voce precisa do contraste. Quase todo modelo de linguagem grande que voce ja usou, incluindo ChatGPT, Claude, Gemini e Llama, e um modelo autorregressivo. Ele gera texto da esquerda para a direita, um token por vez, e um token nao pode ser produzido ate que tudo antes dele exista.
Duas consequencias decorrem desse design, e ambas importam para a comparacao:
- A latencia e sequencial. Produzir cada token requer uma passagem completa por bilhoes de parametros, entao resultados longos (pense em longas cadeias de raciocinio) inflam diretamente quanto tempo voce espera e quanto paga.
- Nao ha como voltar atras. Uma vez que um token foi emitido, ele esta fixo. O modelo nao pode revisar uma palavra anterior a luz de uma posterior. Esse habito unidirecional e apontado como causa de peculiaridades como a maldicao da reversao, em que um modelo sabe que "A e B" mas tropeca em "B e A".
A vantagem e que o resultado de comprimento variavel e facil: o modelo simplesmente emite um token de fim de sequencia quando termina. Essa flexibilidade e uma das razoes pelas quais a autorregressao se manteve dominante para texto.
Como os modelos de linguagem por difusao geram texto de forma diferente
Os modelos de linguagem por difusao (dLLMs) adaptam a receita das imagens para o texto. Em vez de pixels a partir de ruido, eles fazem tokens a partir de mascaras. O Google DeepMind descreve isso de forma direta: em vez de prever o texto diretamente, o modelo aprende a gerar resultados refinando o ruido passo a passo, de modo que pode iterar sobre uma solucao rapidamente e corrigir erros durante a geracao.
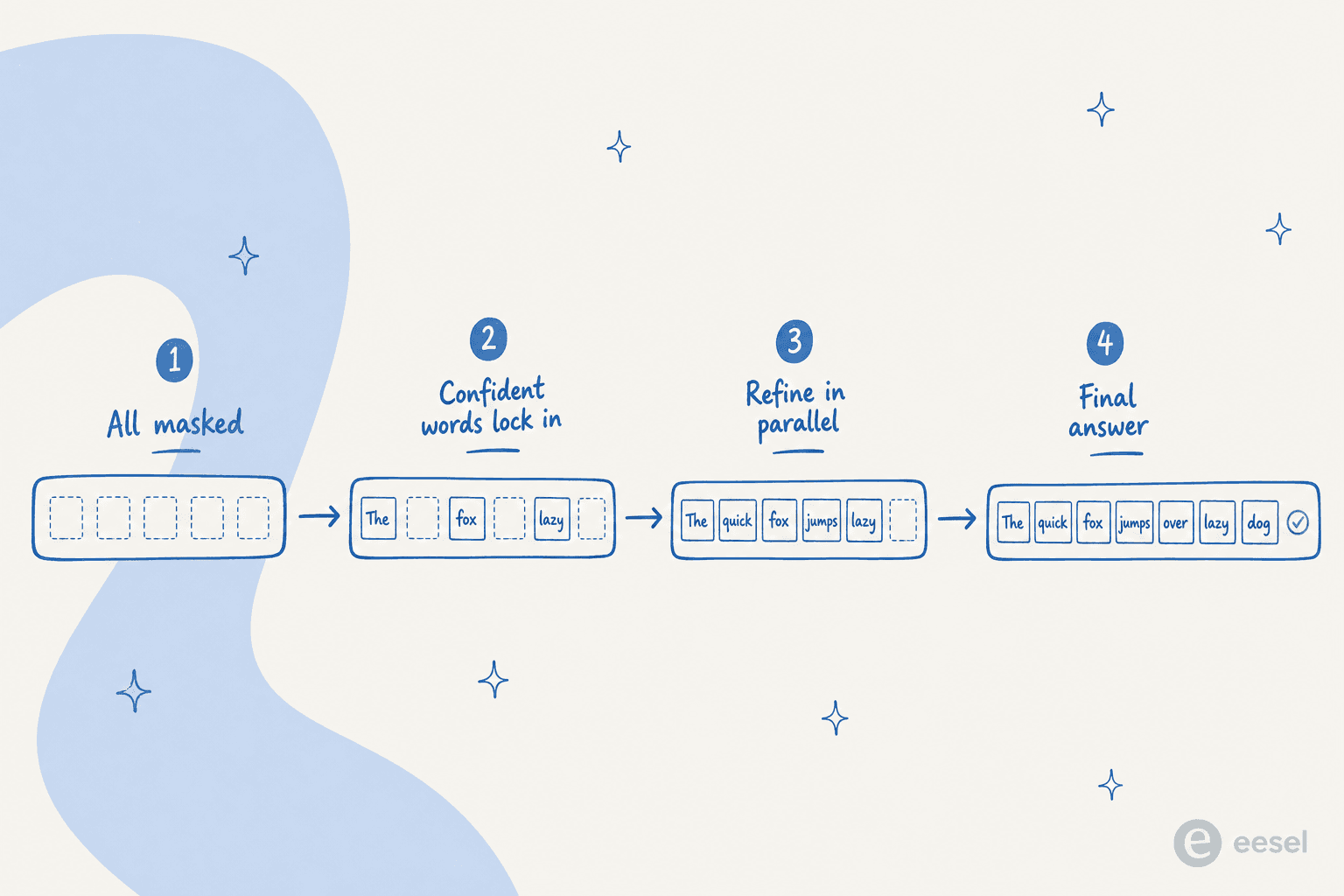
A abordagem dominante para texto e a difusao mascarada. No LLaDA, um modelo de difusao aberto de 8B, o processo direto mascara tokens e o processo reverso usa um "preditor de mascara" baseado em transformer para preencher todos os tokens mascarados de uma vez, simulando a difusao do estado totalmente mascarado de volta ao texto totalmente escrito. Uma linha anterior, o Diffusion-LM, usava difusao continua sobre vetores de palavras.
A principal diferenca e a decodificacao paralela. Um dLLM gera tokens em paralelo em vez de um por vez, e o transformer subjacente pode modificar varios tokens de uma vez para melhorar globalmente a resposta. Como a formulacao e nao autorregressiva, ela tambem permite a geracao em qualquer ordem: o modelo pode fixar primeiro as palavras de que tem certeza em qualquer ponto da sequencia e depois preencher o restante.
Uma das explicacoes mais claras veio, na verdade, de um desenvolvedor no Hacker News, cortando a confusao do tipo "a difusao substitui os transformers":
"Apesar do nome, os LMs de difusao tem pouco a ver com a difusao de imagens e estao muito mais proximos do BERT e da boa e velha modelagem de linguagem mascarada... para gerar algo do zero, voce comeca alimentando o modelo com todos os [MASK]s... em 10 etapas voce tera gerado uma sequencia inteira." nvtop, na discussao sobre o Gemini Diffusion no Hacker News
Essa visao paralela e bidirecional tambem e o motivo pelo qual um modelo de difusao consegue enxergar o contexto em ambos os lados de uma lacuna. O LLaDA, por exemplo, supera o GPT-4o em uma tarefa de completar poemas reversos, superando a maldicao da reversao que derruba os modelos da esquerda para a direita.
Autorregressivo vs difusao: a diferenca central
Se voce guardar uma imagem deste post, que seja esta. Modelos autorregressivos constroem uma frase como uma corrida de revezamento, cada palavra passando o bastao para a proxima. Modelos de difusao a constroem como revelar uma Polaroid, com a imagem inteira aparecendo de uma vez e ficando mais nitida a cada passagem.
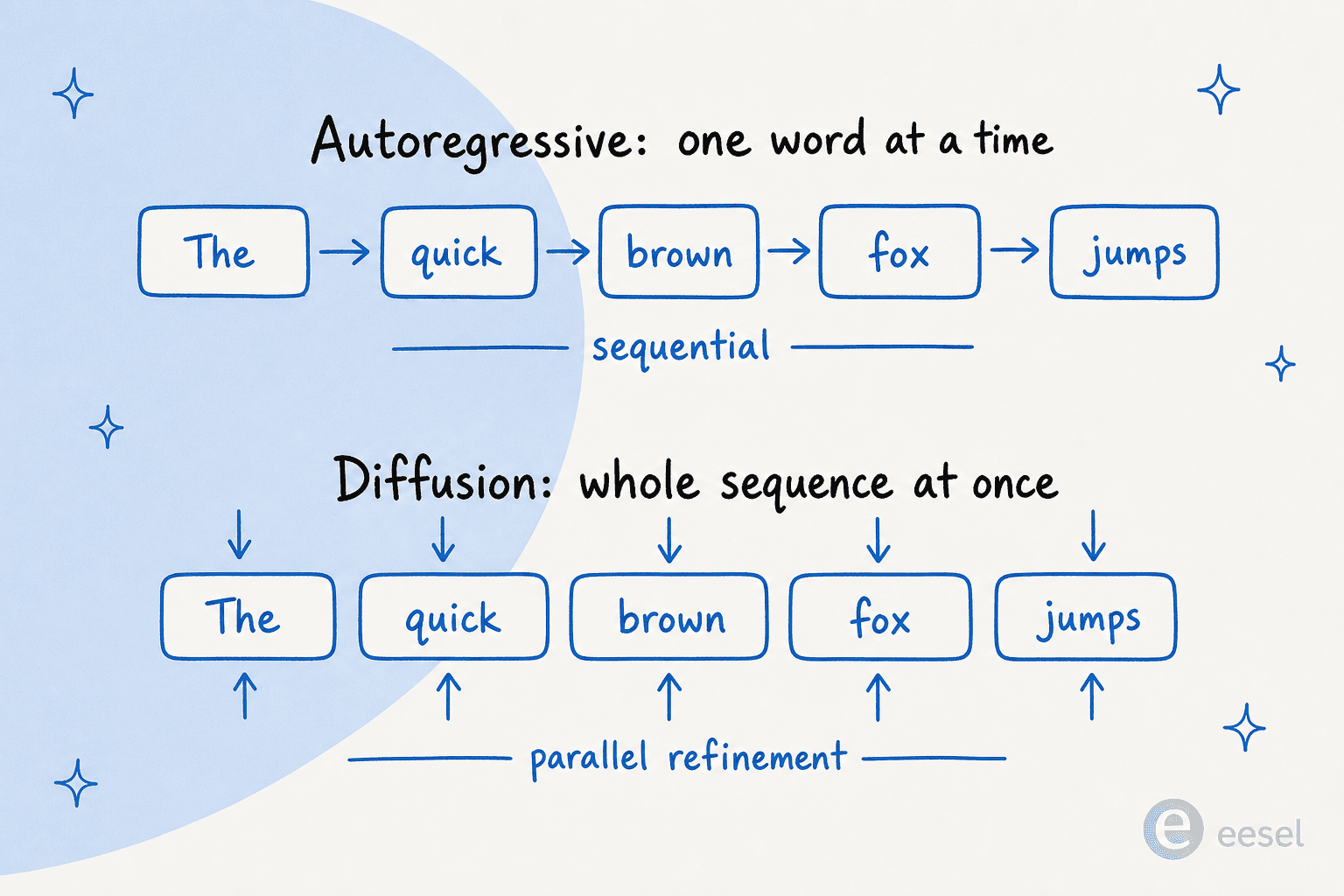
Veja como as duas se comparam nas dimensoes com que um comprador realmente se importa:
| Dimensao | Autorregressivo (GPT, Claude, Gemini) | Difusao (Mercury, Gemini Diffusion) |
|---|---|---|
| Ordem de geracao | Da esquerda para a direita, um token por vez | Sequencia inteira em paralelo, em qualquer ordem |
| Velocidade | Dezenas a ~200 tokens/seg | ~1.000 a ~1.500 tokens/seg |
| Pode revisar tokens anteriores? | Nao, uma vez emitido fica fixo | Sim, ao longo das passagens de remocao de ruido |
| Edicao e preenchimento | Desajeitado (apenas anexa) | Natural (condiciona-se aos dois lados) |
| Raciocinio dificil | Mais forte hoje | Fica atras, especialmente em escala de fronteira |
| Contexto longo | Mais eficiente (reutiliza o cache KV) | Mais fraco (recalcula a atencao a cada passagem) |
| Comprimento do resultado | Variavel, flexivel | Frequentemente blocos de comprimento fixo |
| Maturidade do ecossistema | Cinco anos de ferramentas | Inicial, em rapida evolucao |
Note a simetria: as vitorias da difusao (velocidade, revisao, preenchimento) e suas derrotas (profundidade de raciocinio, contexto longo, maturidade) remontam todas a mesma causa raiz. Trabalhar na sequencia inteira em paralelo e o que a torna rapida e editavel, e tambem o que torna o contexto longo e o raciocinio passo a passo mais dificeis.
O ganho de velocidade, e o porem
Os numeros de velocidade sao genuinamente impressionantes, e nao sao apenas marketing. O desenvolvedor e blogueiro de LLM Simon Willison saiu da lista de espera do Gemini Diffusion e o testou:
"A funcionalidade principal, entao, e a velocidade. Consegui passar pela lista de espera e acabei de testa-lo e uau, eles nao estavam brincando quando disseram que e rapido." Simon Willison, primeiras impressoes do Gemini Diffusion
Veja como o throughput se compara entre alguns modelos, com as referencias autorregressivas para contexto:
| Modelo | Tipo | Throughput (tokens/seg) | Fonte |
|---|---|---|---|
| Gemini Diffusion | Difusao | ~1.479 (excl. overhead) | Fornecedor |
| Mercury 2 (Inception) | Difusao | ~1.196 pico | Artificial Analysis |
| Mercury Coder Mini | Difusao | 1.109 | Fornecedor, corroborado pela AA |
| Gemini 2.0 Flash-Lite | Autorregressivo | ~201 | Segundo a Inception |
| Claude 4.5 Haiku | Autorregressivo | ~89 | Segundo a Inception |
| GPT-5 Mini | Autorregressivo | ~71 | Segundo a Inception |
Duas coisas para manter a honestidade aqui. Primeiro, a maioria dos numeros de throughput e medida em uma NVIDIA H100 e muitos sao alegacoes dos fornecedores; a Artificial Analysis e a principal fonte independente, e ela corroborou a velocidade do Mercury, mas ainda nao sua qualidade. Segundo, a vantagem de velocidade e real, mas condicional. A geracao de alta qualidade geralmente precisa de muitas etapas de remocao de ruido, e cortar etapas de forma ingenua degrada a qualidade drasticamente, entao a velocidade precisa ser gasta com cuidado.
E a diferenca de qualidade ainda e visivel, especialmente em tarefas dificeis. O Gemini Diffusion pontua 40,4% contra 56,5% no GPQA Diamond, e 69,1% contra 79,0% no Global MMLU em relacao ao Flash-Lite, embora lidere em alguns benchmarks de codigo e matematica. A leitura honesta de um engenheiro que trabalha com stacks de agentes em producao vale a citacao, porque nomeia o problema historico diretamente:
"[Os primeiros LMs de difusao] eram rapidos da mesma forma que um relogio quebrado e rapido: nao importa quao rapido voce chega a resposta errada." vainkop, "Mercury 2 and the End of Autoregressive Monopoly"
O veredito dele para as equipes hoje e ponderado: este e um momento de "acompanhar de perto e se preparar para agir rapido", nao de "reescrever sua stack de agentes imediatamente".
Os modelos que lideram a investida
O campo passou de curiosidade de pesquisa a produtos lancados rapidamente. O sinal de financiamento e alto: a Inception Labs, fundada por Stefano Ermon, de Stanford, levantou US$ 50 milhoes em novembro de 2025 de uma lista estrategica que inclui Nvidia, a M12 da Microsoft, Databricks e Snowflake, alem dos investidores-anjo Andrew Ng e Andrej Karpathy. Quando os players de infraestrutura apostam, e porque acham que a velocidade e servivel.
| Modelo | Quem | Status | O que se destaca |
|---|---|---|---|
| Mercury / Mercury 2 | Inception Labs | API no ar, US$ 0,25 / US$ 0,75 por 1M de tokens | Primeiro LLM de difusao comercial; ~1.196 tok/s |
| Gemini Diffusion | Google DeepMind | Experimental, lista de espera | Qualidade ~ Gemini 2.0 Flash-Lite a varias vezes a velocidade |
| DiffusionGemma | Google DeepMind | Pesos abertos (Apache 2.0), junho de 2026 | Mistura de especialistas de 26B; >1.000 tok/s, abaixo do Gemma 4 em qualidade |
| LLaDA 8B | ML-GSAI (pesquisa) | Pesos abertos | MMLU 65,9, aproximadamente igualando o Llama3 8B |
| Dream 7B | HKU NLP + Huawei | Pesos abertos | Domina tarefas de planejamento (Sudoku 81,0 vs 21,0 do Qwen) |
Um esclarecimento rapido, porque os nomes sao confusamente parecidos: "Gemini Diffusion" (fechado, lista de espera) e "DiffusionGemma" (pesos abertos) sao dois lancamentos diferentes do Google. O primeiro e um modelo hospedado experimental mostrado no Google I/O 2025; o segundo e um modelo de 26B disponivel para download lancado em 10 de junho de 2026 sob a licenca Apache 2.0, que gera removendo o ruido de blocos de 256 tokens em paralelo e fica abaixo do Gemma 4 padrao em todos os benchmarks publicados. Velocidade trocada por qualidade, abertamente.
O padrao recorrente em todos esses casos: uma vantagem de throughput de mais de 10x que reduz a diferenca de qualidade em escala pequena e media (LLaDA aproximadamente igualando o Llama3 8B, Mercury competitivo em codigo), mas que ainda aparece na fronteira. O principal caso de uso hoje e a geracao de codigo e loops agenticos de baixa latencia, onde a velocidade da decodificacao paralela se acumula.
Por que os modelos de IA baseados em difusao importam para as empresas
A velocidade nao e uma metrica de vaidade quando voce coloca um modelo dentro de um produto. O enquadramento mais claro vem da experiencia em producao: a latencia em sistemas autorregressivos se acumula em cadeias.
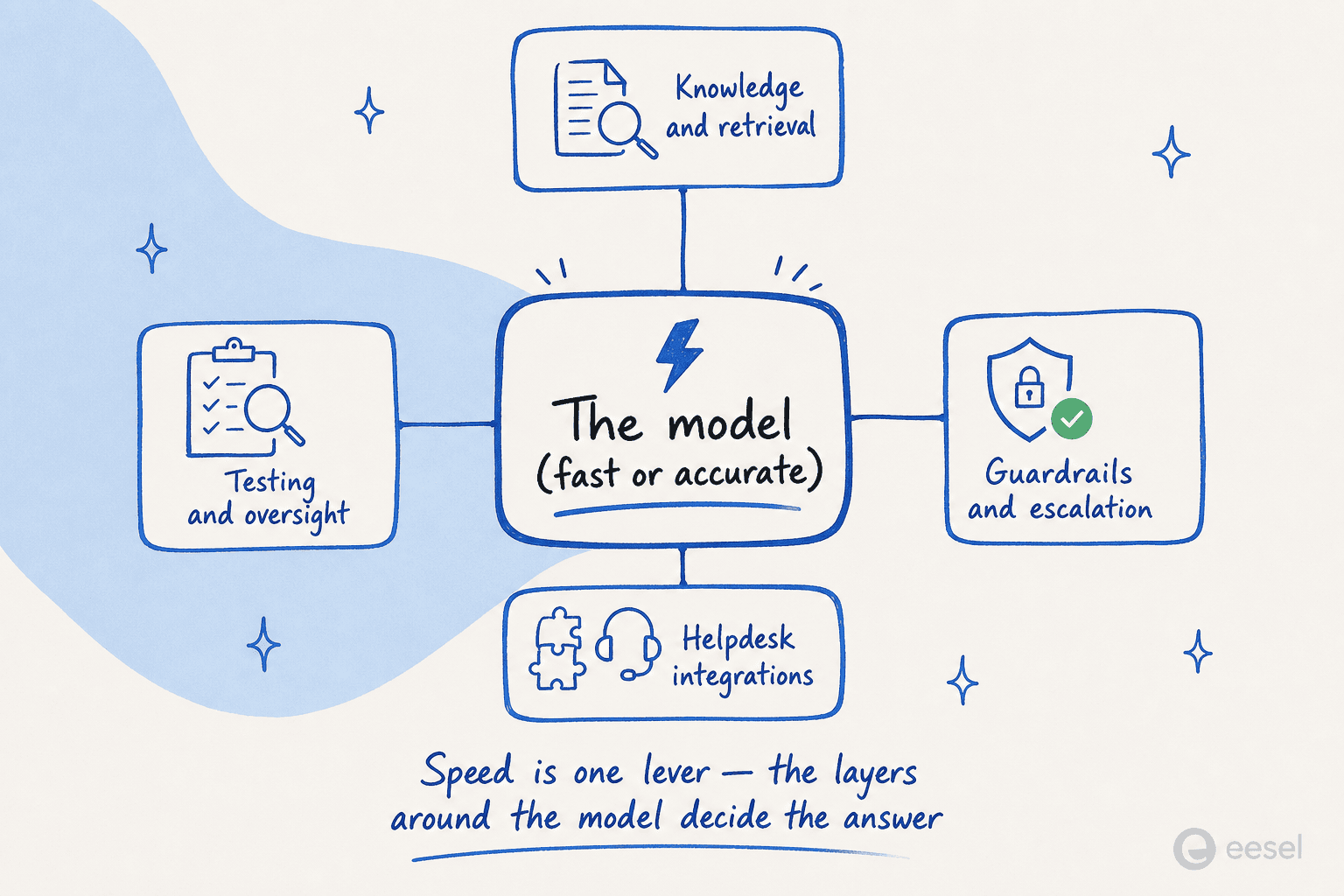
Como um engenheiro descreveu, uma unica etapa de agente que chama o modelo tres vezes (raciocinar, planejar, agir) sao tres passagens sequenciais; encadeie algumas dessas e voce chega a sete ou oito segundos, o que "nao e um agente em tempo real, e um trabalho em lote lento". Uma geracao por etapa mais rapida torna viaveis cadeias de agentes de IA mais profundas. O mesmo artigo observa que as equipes atualmente limitam a profundidade da cadeia a tres a cinco etapas para ficar dentro de seu SLA; com inferencia na velocidade da difusao, cadeias de dez etapas comecam a parecer viaveis.
Alguns lugares concretos onde a velocidade compensa:
- Chat e copilotos em tempo real. Respostas em menos de um segundo sao, como diz esse engenheiro, "a diferenca entre a adocao e o abandono" de uma camada de assistente em um produto SaaS.
- Texto em lote de alto volume. Resumo, classificacao, reformatacao e traducao sao limitados por throughput e paralelizaveis, que e exatamente onde a difusao brilha.
- Assistentes de codificacao. A natureza de preenchimento da difusao se encaixa em edicoes de codigo, gerando o inicio e o fim de um bloco na mesma passagem e editando o meio.
Depois ha o custo. A geracao mais rapida no mesmo hardware significa menor custo de inferencia por token, e o cofundador da Inception argumenta que a abordagem "realiza mais computacao por unidade de memoria transferida", o que abre novas formas de reduzir os custos de inferencia de IA em hardware mais antigo. Para equipes que executam centenas de milhares de chamadas de agente por dia, isso se acumula. O preco publico do Mercury 2 de US$ 0,25 por milhao de tokens de entrada e US$ 0,75 por milhao de saida e genuinamente barato.
Mas aqui esta a parte que a maioria das coberturas ignora. Para a maioria das aplicacoes em producao, os modelos autorregressivos continuam sendo o padrao, e por um bom motivo: eles lidam com o contexto longo de forma mais eficiente, raciocinam de forma mais profunda (a difusao faz menos trabalho por token, entao ha menos espaco para "pensar") e tem cinco anos de ferramentas por tras. A jogada pragmatica nao e a substituicao, mas o roteamento: enviar as etapas simples e de alta frequencia (busca, formatacao, classificacao) para um modelo de difusao rapido e reservar os modelos autorregressivos de fronteira para o raciocinio profundo. Compare isso com a economia de agentes de IA versus agentes humanos e o apelo fica obvio: fazer mais do trabalho barato de forma barata.
O que isso significa para o atendimento ao cliente com IA
O atendimento ao cliente parece o caso de uso perfeito para a difusao a primeira vista. O chat ao vivo e os agentes de suporte com IA sao exatamente o cenario de baixa latencia e voltado ao usuario em que a diferenca de um segundo versus varios segundos decide se a experiencia parece responsiva ou lenta. Um modelo mais rapido deveria significar respostas mais ageis no seu chatbot de IA.
A reformulacao que vale a pena considerar: para uma equipe de suporte, a arquitetura do modelo importa muito menos do que a orquestracao ao redor dela. Uma resposta de suporte real quase nunca e uma geracao do zero. E uma resposta fundamentada na sua base de conhecimento, no historico de tickets e nos documentos de politica. Isso coloca a fraqueza da difusao, o tratamento de contexto longo, diretamente no caminho do caso de uso de suporte, e significa que a qualidade da recuperacao, a atualidade do conhecimento e as salvaguardas determinam a resposta muito mais do que o fato de os tokens finais terem sido emitidos da esquerda para a direita ou em paralelo.
Sem rodeios: um modelo mais rapido conectado a conhecimento desatualizado ou a regras fracas de escalonamento apenas produz respostas erradas mais rapido. O problema do relogio quebrado, aplicado ao suporte. E tambem por isso que os problemas de chatbots de IA raramente se reduzem ao modelo base e tao frequentemente se reduzem a fundamentacao, testes e as metricas que voce realmente acompanha.
O conselho genuinamente util, entao, e permanecer agnostico em relacao ao modelo. Escolha uma camada que permita ao modelo subjacente melhorar por baixo de voce, seja um modelo de difusao mais rapido no proximo ano ou um modelo autorregressivo mais inteligente. As equipes que mais se beneficiarao da difusao sao aquelas que construiram primeiro sobre uma orquestracao solida e trataram o modelo como um componente substituivel.
Experimente a eesel
E exatamente assim que a eesel AI e construida. Em vez de apostar em uma arquitetura de modelo, a eesel e a camada de orquestracao: ela aprende com seus tickets anteriores, documentos de ajuda e ferramentas desde o primeiro dia, depois rascunha respostas, faz triagem e escala atraves do helpdesk que voce ja usa, com roteamento baseado em confianca para que respostas de baixa confianca permanecam como rascunhos em vez de irem ao ar.

O diferencial que importa para este tema: um modo de simulacao que executa o agente contra seus tickets anteriores para que voce possa ver a cobertura e corrigir lacunas antes de ir ao ar, que e como voce impede um modelo rapido de enviar respostas erradas com confianca. Ele funciona em mais de 100 integracoes e mais de 80 idiomas, entao, seja qual for o modelo mais rapido ou mais inteligente no proximo ano, sua configuracao de suporte continua funcionando. Voce pode experimentar a eesel gratuitamente, sem precisar de cartao de credito.
Perguntas frequentes
O que e um modelo de IA baseado em difusao em termos simples?
Em que os modelos de linguagem por difusao diferem dos LLMs autorregressivos como GPT ou Claude?
Os modelos de IA baseados em difusao sao mesmo mais rapidos que os LLMs comuns?
Minha empresa deveria migrar para um modelo de linguagem por difusao?
A arquitetura do modelo importa para o atendimento ao cliente com IA?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








