Pelo que você está realmente pagando
O principal erro que as pessoas cometem com os preços do Hugging Face é tratar o preço do plano de conta como o custo total. Não é. Como o guia de custos de 2026 da Metacto explica: "Esses planos não cobrem o custo total de executar seus modelos — pense nisso como o preço de entrada no parque de diversões; você ainda precisa pagar pelas atrações."
O plano de conta — Gratuito, PRO, Team, Enterprise — é a sua assinatura do Hub. Ele cobre hospedagem de repositórios, cotas de armazenamento, recursos de colaboração e controles de governança. Executar modelos é uma conta separada, dividida em três sistemas distintos: Spaces (hospedagem de demos e aplicativos com GPU opcional), Inference Providers (roteamento serverless para APIs de modelos de terceiros) e Inference Endpoints (infraestrutura dedicada e sempre ativa que você controla).
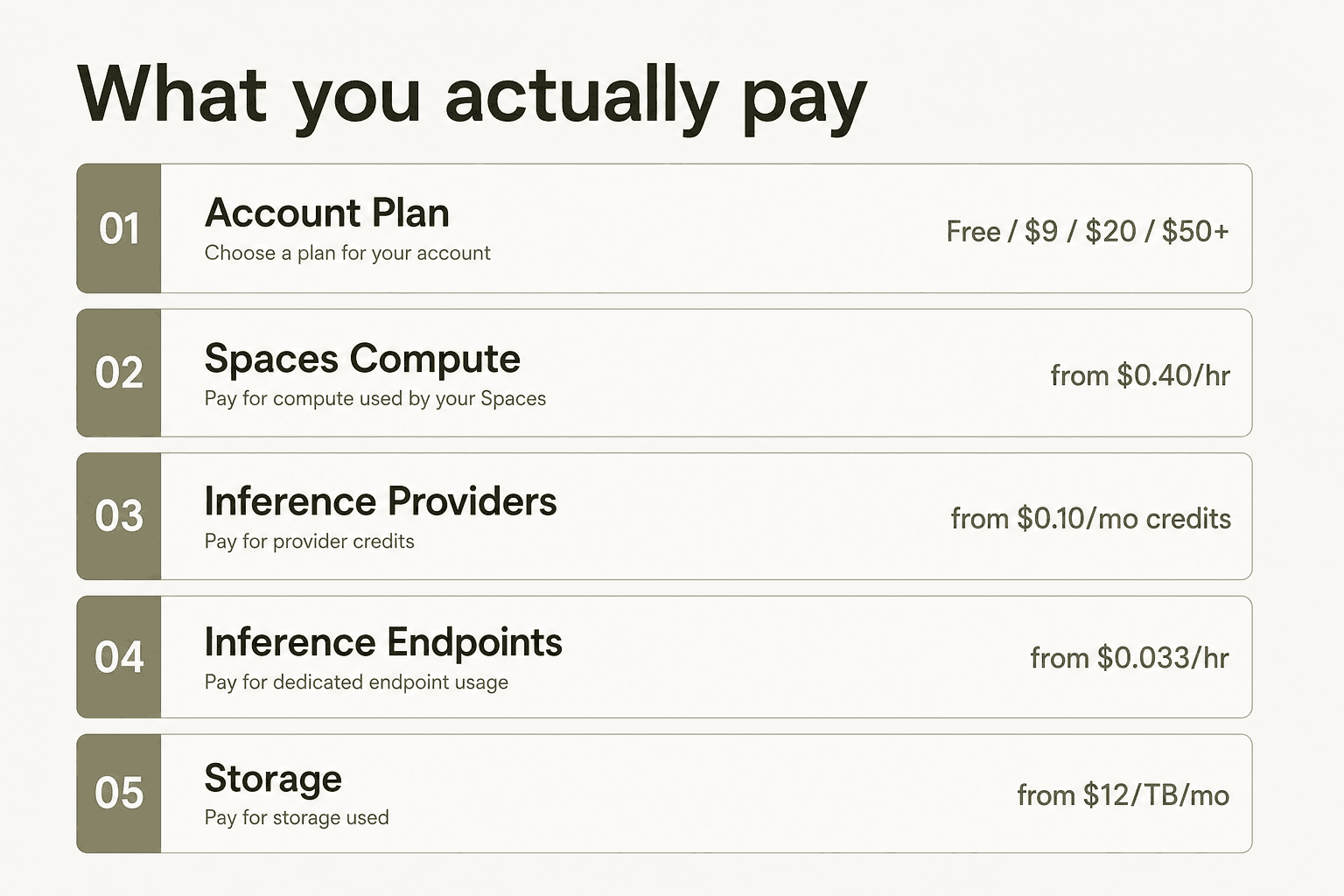
Entender essa separação é o pré-requisito para interpretar corretamente qualquer preço do Hugging Face.
Planos de conta
Gratuito
O nível gratuito é mais generoso do que a maioria das pessoas espera. Você tem acesso a mais de 2 milhões de modelos, 500 mil datasets e mais de 1 milhão de Spaces no Hub, 100 GB de armazenamento em repositório privado, acesso ZeroGPU da comunidade e $0,10/mês em créditos de Inference Provider. Esse crédito não vai longe em produção, mas é suficiente para pequenos experimentos.
O que você não tem: sem SSO, sem logs de auditoria, sem grupos de recursos, sem fila prioritária. Os limites de taxa na Inference API são nitidamente mais restritivos do que nos planos pagos. O nível gratuito é adequado para quem está aprendendo o ecossistema ou realizando experimentos ocasionais — não para equipes que trabalham com serviços em produção.
PRO - $9/mês
Este é o salto de valor mais claro na página de preços. Por $9/mês, o PRO oferece:
- 8× sua cota ZeroGPU com prioridade máxima na fila (40 min/dia vs. 5 min/dia no gratuito)
- 1 TB de armazenamento privado (ante 100 GB)
- $2/mês em créditos de Inference Provider (20× o valor gratuito)
- Spaces Dev Mode — acesso via SSH e VS Code ao seu Space para iteração rápida sem reimplantação
- Private Dataset Viewer para trabalhar com dados de treinamento não públicos
- Acesso antecipado a novos recursos do Hub e um emblema PRO
O aumento da cota ZeroGPU é o principal atrativo. O ZeroGPU dá a todos os usuários acesso a um pool compartilhado de GPUs Nvidia RTX Pro 6000 Blackwell sem cobrança por hora — mas os usuários do nível gratuito atingem sua cota em cerca de 5 minutos de tempo de GPU por dia. O PRO eleva isso para 40 minutos com agendamento prioritário.
A SaaSLens avaliou o Hugging Face com 4,7/5 em sua análise de março de 2026, chamando-o de "uma das nossas escolhas mais bem avaliadas para fundadores individuais" e destacando especificamente o plano PRO como oferecendo "acesso GPU de nível empresarial pelo custo de alguns cafés por mês". É uma avaliação justa. Optaríamos pelo PRO sempre que precisamos executar demos com GPU sem pagar por infraestrutura dedicada.
Team - $20/usuário/mês
O Team é o primeiro plano de nível organizacional. A cobrança passa a ser por assento: cada membro da sua organização do Hugging Face paga $20/mês. Além das vantagens do PRO para todos na organização, você tem:
- 12 TB de armazenamento público base + 1 TB/assento público + 1 TB/assento privado
- $2/mês em créditos de Inference Provider por assento (acumulados em toda a organização)
- Controles de cobrança no nível da organização para Inference Providers — defina limites de gastos, desative provedores específicos
- Suporte prioritário da equipe do Hugging Face
- Todos os membros recebem o aumento de 8× na cota ZeroGPU
Os controles de cobrança para Inference Providers são genuinamente úteis para equipes de pesquisa onde indivíduos podem acidentalmente acumular custos com modelos frontier caros. Os administradores podem limitar os gastos mensais da organização e desativar provedores específicos.
Uma ressalva importante: o Team não inclui SSO, logs de auditoria ou grupos de recursos. Esses são exclusivos do Enterprise. Se sua equipe precisar se conectar ao provedor de identidade da empresa ou gerar relatórios de conformidade, o Team não será suficiente independentemente do número de membros.
Enterprise - a partir de $50/usuário/mês
O Enterprise é onde o conjunto de governança é desbloqueado. O valor de $50/usuário/mês é o piso — contratos maiores com compromissos de volume, faturamento anual e SLAs personalizados são negociados com a equipe de vendas do Hugging Face. Clientes Enterprise notáveis incluem NVIDIA, Google, OpenAI, Meta, Salesforce, IBM Research, Shopify e Roblox.
Os recursos que levam equipes a este nível:
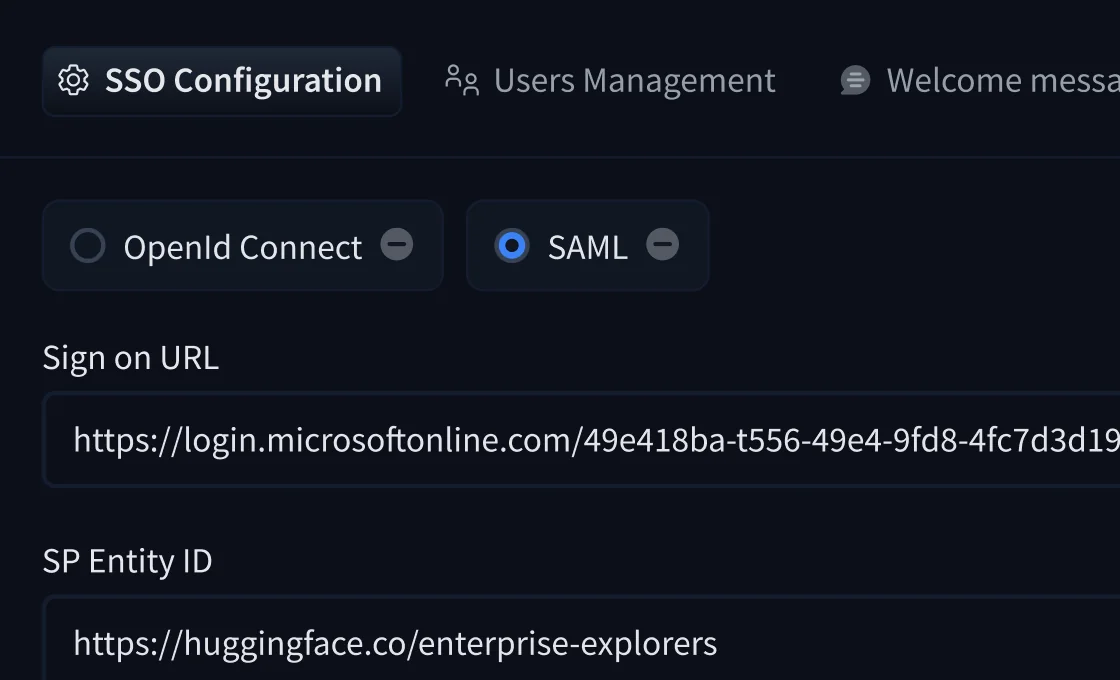
O SSO conecta seu provedor de identidade — Okta, Azure AD, Google Workspace ou qualquer IdP compatível com SAML/OpenID Connect. O Enterprise Plus adiciona SCIM para provisionamento automatizado de usuários.
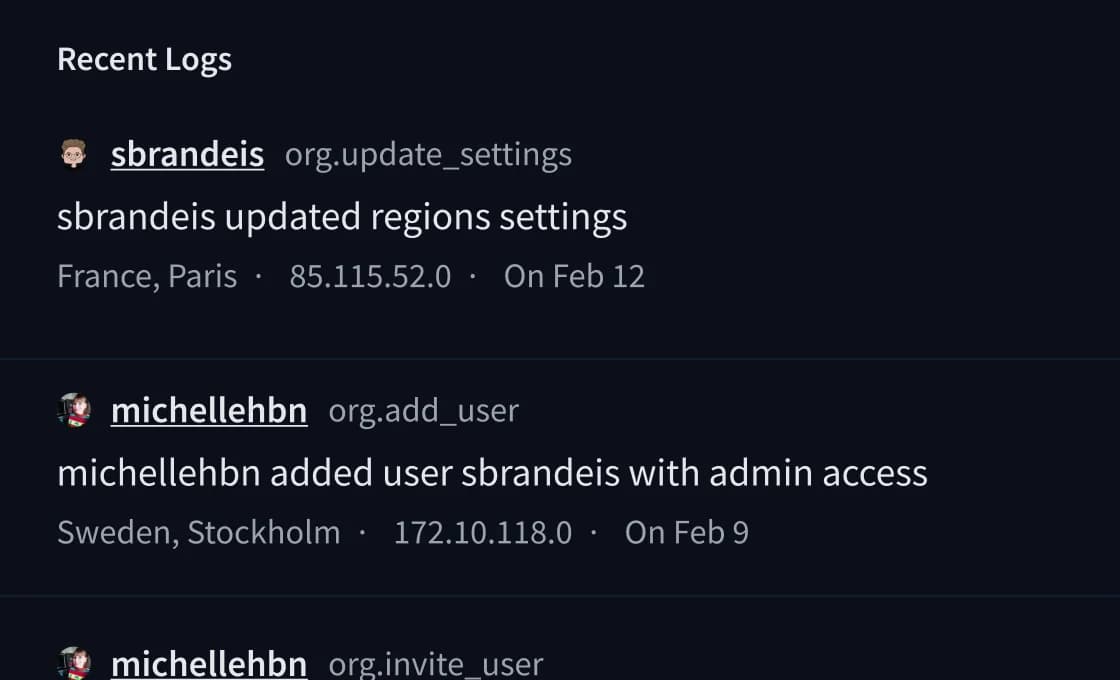
Os logs de auditoria registram cada ação da organização — quem alterou o quê, de onde, em que momento — com atribuição de usuário, endereço IP e localização. Útil para revisões SOC 2 Tipo II e documentação de conformidade com o GDPR.
Os grupos de recursos permitem que administradores atribuam repositórios a grupos nomeados e concedam acesso READ, WRITE ou CONTRIBUTOR por usuário — útil para separar workspaces de pesquisa, produção e experimentais dentro de uma única organização.
A análise de repositórios mostra tendências de downloads, uso de modelos e acesso a datasets em toda a organização em um único painel — prático para entender quais modelos internos estão sendo realmente utilizados.
A residência de dados permite que você escolha e audite a região geográfica onde seus repositórios são armazenados — relevante para requisitos de GDPR e soberania de dados. O Enterprise Plus adiciona controles de segurança de rede e lista de permissões de IP.
O armazenamento para o Enterprise é substancial: 200 TB público base + 1 TB/assento, escalando para 1 PB em contratos maiores.
Comparação de planos de uma vez
| Gratuito | PRO | Team | Enterprise | |
|---|---|---|---|---|
| Preço | $0 | $9/mês | $20/usuário/mês | $50+/usuário/mês |
| Armazenamento privado | 100 GB | 1 TB | 1 TB/assento | 1 TB/assento |
| Armazenamento público | Melhor esforço | Até 10 TB | 12 TB + 1 TB/assento | 200 TB + 1 TB/assento |
| Créditos de inferência | $0,10/mês | $2/mês | $2/assento/mês | $2/assento/mês |
| Cota ZeroGPU | Padrão | 8× + prioridade | 8× (todos os membros) | 8× (todos os membros) |
| Spaces Dev Mode | Não | Sim | Sim | Sim |
| Private Dataset Viewer | Não | Sim | Sim | Sim |
| Controles de cobrança da organização | Não | Não | Sim | Sim |
| SSO | Não | Não | Não | Sim |
| Logs de auditoria | Não | Não | Não | Sim |
| Grupos de recursos | Não | Não | Não | Sim |
| Análise de repositórios | Não | Não | Não | Sim |
| Residência de dados | Não | Não | Não | Sim |
| Suporte prioritário | Não | Não | Sim | Sim (dedicado) |
| Contratos anuais | Não | Não | Não | Sim |
Preços de hardware dos Spaces
Os Spaces são aplicativos e demos interativos de ML hospedados no Hub. O nível CPU Basic é gratuito; os níveis com GPU são pay-as-you-go por hora, cobrados enquanto o Space está em execução.
| Hardware | vCPU | RAM | Acelerador | VRAM | Por hora |
|---|---|---|---|---|---|
| CPU Basic | 2 | 16 GB | - | - | Gratuito |
| CPU Upgrade | 8 | 32 GB | - | - | $0,03 |
| ZeroGPU | dinâmico | dinâmico | RTX Pro 6000 Blackwell | até 96 GB | Gratuito* |
| T4 - small | 4 | 15 GB | T4 | 16 GB | $0,40 |
| T4 - medium | 8 | 30 GB | T4 | 16 GB | $0,60 |
| L4 (1×) | 8 | 30 GB | L4 | 24 GB | $0,80 |
| L4 (4×) | 48 | 186 GB | L4 | 96 GB | $3,80 |
| L40S (1×) | 8 | 62 GB | L40S | 48 GB | $1,80 |
| L40S (4×) | 48 | 382 GB | L40S | 192 GB | $8,30 |
| L40S (8×) | 192 | 1.534 GB | L40S | 384 GB | $23,50 |
| A10G - small | 4 | 15 GB | A10G | 24 GB | $1,00 |
| A10G - large | 12 | 46 GB | A10G | 24 GB | $1,50 |
| A100 - large | 12 | 142 GB | A100 | 80 GB | $2,50 |
| 4× A100 | 48 | 568 GB | A100 | 320 GB | $10,00 |
| 8× A100 | 96 | 1.136 GB | A100 | 640 GB | $20,00 |
*O ZeroGPU é gratuito dentro da cota. Membros PRO e Team/Enterprise têm 8× a cota padrão. O excedente é cobrado a $1 por 10 minutos.
Os Spaces ficam em hibernação após 48 horas de inatividade no nível CPU gratuito. Spaces com GPU pagos permanecem em execução até você pausá-los — um T4-small deixado rodando por 30 dias custa $288. Não há desligamento automático.
Vale saber: Bolsas de GPU da comunidade estão disponíveis para projetos independentes qualificados. Se você está publicando pesquisa aberta e precisa de acesso persistente a GPU, vale a pena se candidatar antes de se comprometer com um nível pago.
Inference Providers (serverless)
Os Inference Providers permitem que você roteie chamadas de API para mais de 45.000 modelos em mais de 18 parceiros de inferência — Groq, Fireworks, Mistral, Cohere, Nebius, SambaNova e outros — por meio de um único endpoint unificado em router.huggingface.co/v1. O Hugging Face repassa os preços dos provedores sem acréscimo.
Créditos mensais por plano, aplicados ao rotear pelo Hugging Face:
| Plano | Créditos mensais |
|---|---|
| Gratuito | $0,10 |
| PRO | $2,00 |
| Team / Enterprise (por assento) | $2,00 |
Quando os créditos acabam, o uso passa para o pay-as-you-go. Você pode deixar o HF cobrar sua conta (mais simples, créditos mensais se aplicam) ou trazer sua própria chave de API do provedor e pagar o provedor diretamente (créditos HF não se aplicam, mas você controla diretamente a relação de cobrança).
Organizações Team e Enterprise podem definir limites de gastos e desativar provedores específicos nas configurações da organização — útil para controlar custos quando membros individuais estão executando modelos frontier caros.
O Hugging Face também mantém seu próprio backend hf-inference — a "Inference API (serverless)" original — agora focado em tarefas vinculadas a CPU, como embeddings, classificação de texto e modelos menores (BERT, GPT-2). Executar o Llama 3.1 70B ou qualquer LLM de geração atual é roteado por um provedor terceiro.
Inference Endpoints (implantação dedicada)
Os Inference Endpoints são para equipes que precisam de latência previsível e infraestrutura dedicada — sem cold starts, sem fila compartilhada, implantações com escalonamento automático na AWS, Azure ou GCP. Você escolhe o hardware, o Hugging Face gerencia o container e o escalonamento.
O modelo de cobrança é o que mais provavelmente vai surpreendê-lo. Os Endpoints são cobrados por minuto à taxa da instância, vezes o número de réplicas ativas — independentemente do volume de requisições. Isso não é cobrança por requisição ou por token.
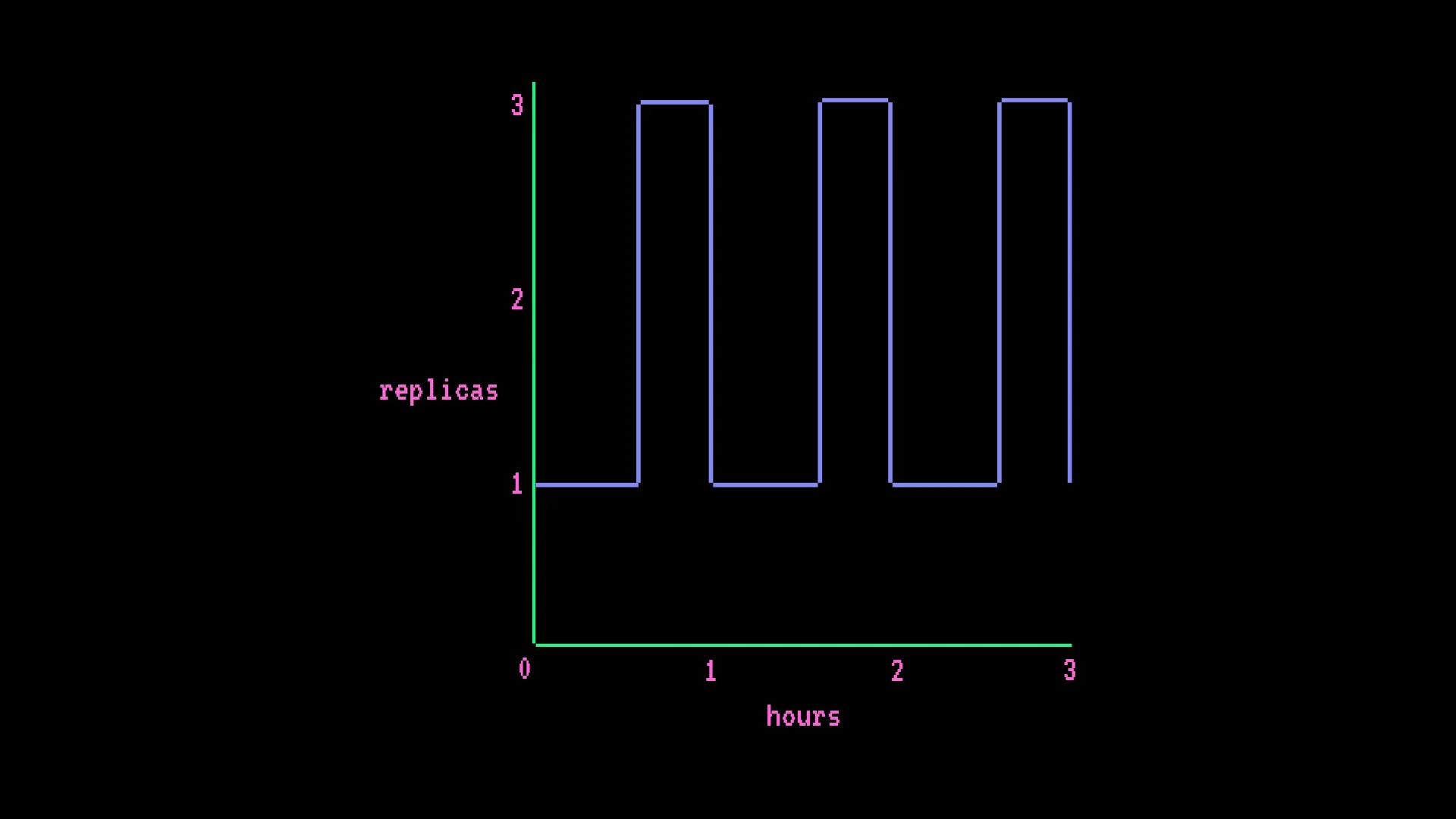
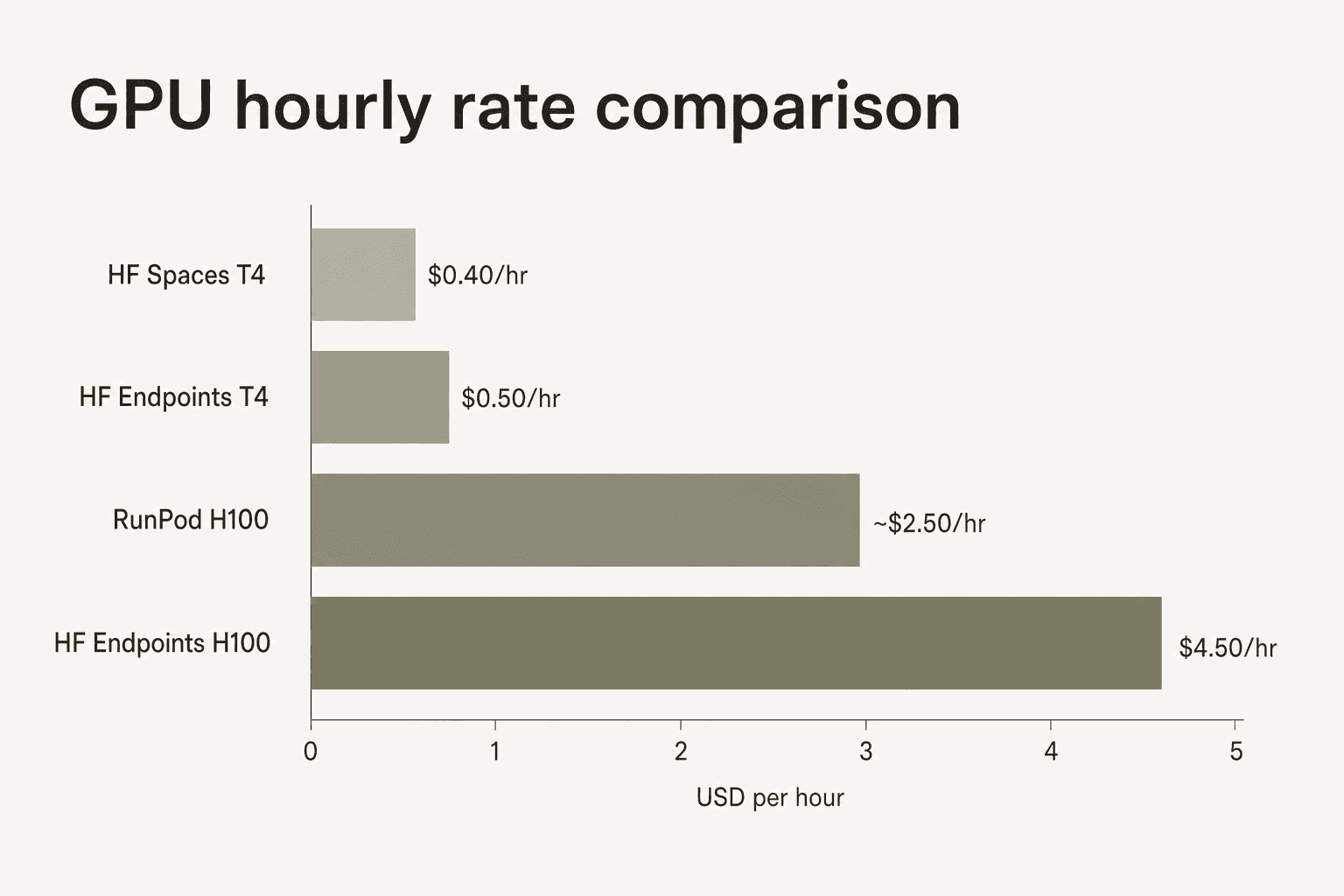
Preços de instâncias GPU (AWS)
| GPU | Quantidade | VRAM | Por hora |
|---|---|---|---|
| T4 | 1 | 14 GB | $0,50 |
| T4 | 4 | 56 GB | $3,00 |
| L4 | 1 | 24 GB | $0,80 |
| L40S | 1 | 48 GB | $1,80 |
| A100 | 1 | 80 GB | $2,50 |
| A100 | 4 | 320 GB | $10,00 |
| A100 | 8 | 640 GB | $20,00 |
| H100 | 1 | 80 GB | $4,50 |
| H100 | 4 | 320 GB | $18,00 |
| H100 | 8 | 640 GB | $36,00 |
| H200 | 1 | 141 GB | $5,00 |
| B200 | 1 | 179 GB | $9,25 |
| B200 | 8 | 1.432 GB | $74,00 |
| RTX PRO 6000 | 1 | 96 GB | $2,75 |
As opções para GCP e Azure também estão disponíveis com preços ligeiramente diferentes por nível de hardware. A tabela completa incluindo instâncias CPU e acelerador (Inferentia2, TPU v5e) está na página de preços dos Inference Endpoints.
Exemplos concretos de custo
Endpoint CPU sempre ativo — AWS 2-vCPU, 1 réplica:
- $0,067/h × 730 horas = ~$49/mês
Endpoint GPU com escalonamento automático — AWS T4 x1, mínimo 1 réplica, máximo 3, com picos de 15 minutos a cada hora:
- $0,50 × (730 h × 1 + 182,5 h × 2 réplicas adicionais) = $547,50/mês
A fórmula de cobrança: taxa horária × ((horas × réplicas mínimas) + (horas de escalonamento × réplicas adicionais))
Esse modelo sempre ativo é a fonte mais comum de cobranças surpresa. Uma pergunta nos fóruns do Hugging Face que atraiu mais de 3.700 visualizações captura bem a confusão:
"Estou um pouco confuso sobre o modelo de preços. Digamos que eu implante um modelo em uma máquina CPU Basic ($0,06/hora). Então pago enquanto o modelo está implantado ou pago apenas pelo tempo de computação (por exemplo, faço 2 requisições e cada uma leva 10 segundos para ser executada, então pago apenas pelos 20 segundos)?"
A resposta é: você paga enquanto o modelo está implantado, não por requisição. Essa distinção pega muita gente de surpresa.
Preços de armazenamento
O armazenamento no Hub é sua própria camada de cobrança, cobrada por TB por mês. As taxas variam por volume e se os repositórios são públicos ou privados:
| Volume | Taxa pública | Taxa privada |
|---|---|---|
| Base | $12/TB/mês | $18/TB/mês |
| 50 TB+ | $10/TB/mês | $16/TB/mês |
| 200 TB+ | $9/TB/mês | $14/TB/mês |
| 500 TB+ | $8/TB/mês | $12/TB/mês |
Egress e entrega por CDN estão incluídos sem custo extra — o que se compara favoravelmente ao AWS S3 a ~$23/TB/mês com taxas de egress separadas.
Cada plano pago inclui armazenamento base significativo antes de as cobranças por TB entrarem em vigor:
- PRO: até 10 TB público + 1 TB privado
- Team: 12 TB público base + 1 TB/assento público + 1 TB/assento privado
- Enterprise: 200 TB público base + 1 TB/assento, escalando para 1 PB em contratos maiores
Complementos de armazenamento público para planos pagos: 1 TB por $12/mês, 5 TB por $60/mês, 10 TB por $120/mês, 50 TB por $500/mês. O armazenamento privado além dos limites incluídos é pay-as-you-go a partir de $18/TB/mês.
As armadilhas de cobrança que vale conhecer
Não há limites de gastos integrados para Spaces ou Inference Endpoints. Os gastos com Inference Provider podem ser limitados no nível da organização no Team e Enterprise, mas Spaces com GPU e endpoints dedicados não têm desligamento automático. Uma discussão no fórum de abril de 2025 descreveu uma cobrança que saltou de $78,22 para $519,24 da noite para o dia:
"Há um aumento repentino de cerca de 1.100 horas em menos de 24 horas, o que é tecnicamente impossível. Mesmo com uso contínuo de GPU: Máximo possível = 24 horas/dia por instância. Esse pico implicaria dezenas de instâncias em paralelo, o que não é o caso."
Seja um bug de cobrança ou um processo fora de controle, o usuário não tinha como limitar a exposição previamente. A lição: defina políticas de pausa manual para Spaces com GPU e mantenha o número mínimo de réplicas dos Inference Endpoints o mais baixo possível.
As taxas horárias e mensais nem sempre se reconciliam de forma limpa. Um thread de outubro de 2024 identificou uma inconsistência real: o nível de armazenamento persistente Medium está listado a $0,03/h, o que implica ~$21,60/mês — mas a cobrança mensal real é de $25. Vale verificar os totais mensais em vez de extrapolar a partir dos valores horários.
Os Inference Endpoints cobram sempre-ativo. Se o número mínimo de réplicas do seu endpoint for 1, você está pagando a taxa do hardware 24 horas por dia, 7 dias por semana, independentemente do volume de tráfego. Isso pega equipes acostumadas com modelos de preços serverless, onde o tempo ocioso não custa nada.
Comparando custos de computação
Os Inference Endpoints do Hugging Face têm um prêmio de conveniência em relação a provedores de GPU commodity. Um H100 nos Endpoints Dedicados do HF custa $4,50–$10/h dependendo da região do cloud; o mesmo hardware no RunPod custa $2–3/h. Os dados de avaliação da comunidade apontam consistentemente essa diferença — "os custos de computação GPU somam rapidamente" aparece como uma reclamação recorrente — ao mesmo tempo em que observam que a integração com o Hub, a disponibilidade de modelos e a ausência de gerenciamento de infraestrutura justificam o prêmio para equipes que querem permanecer no ecossistema HF.
Para cargas de trabalho vinculadas a CPU (embeddings, classificação, modelos menores), o cálculo é diferente — as taxas do HF são competitivas e a infraestrutura gerenciada economiza tempo de engenharia. O prêmio aparece de forma mais acentuada no extremo de alta GPU, onde a Together AI e provedores similares oferecem melhor economia de computação bruta para equipes que não precisam do registro de modelos e das ferramentas de implantação do Hub.
O Inference Playground é a maneira mais fácil de experimentar modelos antes de se comprometer com qualquer nível de computação — permite que você teste provedores pela interface do navegador sem configuração de cobrança.
Qual plano e produto se encaixa na sua situação
Gratuito — explorar modelos, realizar experimentos ocasionais, aprender o ecossistema. O registro de modelos e o acesso ZeroGPU o tornam genuinamente útil sem gastar nada.
PRO a $9/mês — desenvolvimento individual ativo onde você precisa do aumento de cota ZeroGPU, mais armazenamento privado ou Spaces Dev Mode. Difícil argumentar contra a esse preço para qualquer pessoa que trabalha regularmente com ML.
Team a $20/usuário/mês — equipes reais colaborando em modelos ou datasets. Os controles de cobrança no nível da organização para Inference Providers e o armazenamento acumulado começam a fazer diferença nessa escala.
Enterprise a $50+/usuário/mês — SSO, logs de auditoria ou requisitos de conformidade. Não pague pelo Enterprise porque sua equipe é grande — pague quando realmente precisar do conjunto de governança.
Inference Providers — acesso serverless conveniente a modelos de terceiros às taxas do provedor, sem infraestrutura para gerenciar. Os créditos de $2/mês não vão longe em produção, mas a API unificada é ótima para avaliação e prototipagem.
Inference Endpoints — hardware dedicado com latência previsível e escalonamento automático. Planeje para cobrança sempre-ativa, defina réplicas mínimas de forma conservadora e implemente políticas de pausa manual. Não é o padrão certo para implantações de baixo tráfego ou experimentais.
Se você está comparando o ecossistema mais amplo, as alternativas ao Hugging Face cobrem outras sete plataformas que vale avaliar para implantação de modelos.
Experimente o eesel
Se você está avaliando o Hugging Face para IA no suporte ao cliente — automatizando respostas a tickets, criando um agente de helpdesk, desviando consultas repetitivas — o eesel oferece um caminho mais direto. Em vez de gerenciar infraestrutura de hospedagem de modelos em cinco superfícies de cobrança, o eesel implanta agentes de IA totalmente autônomos diretamente no Zendesk, Slack, Freshdesk e em mais de 100 outras ferramentas. Você instrui o agente em linguagem simples, ele resolve tickets de ponta a ponta, e os preços escalam com o uso a $0,40 por tarefa em vez de horas de computação. Sem gerenciamento de GPU, sem picos de cobrança, sem Inference Endpoints para configurar.
Comece com $50 em créditos gratuitos — sem cartão necessário →
Perguntas Frequentes
Quanto custa o Hugging Face?
O Hugging Face é gratuito?
O que está incluído no Hugging Face PRO?
Quanto custa o Hugging Face Enterprise?
Como funciona a cobrança dos Inference Endpoints do Hugging Face?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.