
O que exatamente e o Gemma 4?
Construo os agentes de IA na eesel, e passei os ultimos anos observando como os modelos abertos foram de "divertidos para brincar" a "bons o suficiente para colocar na frente de um cliente pagante". Executamos agentes em filas de suporte ao vivo todos os dias; um cliente, Smava, processa mais de 100.000 tickets em alemao por mes por meio de um agente automatizado. Entao, sempre que o Google lanca um novo modelo aberto, leio com uma unica perspectiva: voce poderia realmente confiar nisso para responder a um cliente sem supervisao humana?
O Gemma 4 e a resposta mais interessante a essa pergunta que vi de um modelo aberto.
Em termos simples, Gemma e a linha de modelos abertos do Google DeepMind — os primos menores e baixaveis dos modelos Gemini fechados. O Gemma 4 e "construido a partir da mesma pesquisa e tecnologia de nivel mundial que o Gemini 3 para maximizar inteligencia por parametro", segundo o post de lancamento do Google. A palavra-chave e open-weight: o Google publica os arquivos reais do modelo, para que voce possa executa-los em seu proprio laptop, servidor ou telefone sem nenhuma chamada de API sair da sua rede.
Tambem e multimodal. Cada modelo processa entrada de texto e imagem, os menores adicionam audio nativo, e o cartao do modelo indica um corte de treinamento de janeiro de 2025 com suporte a mais de 140 idiomas. Se voce leu nosso artigo sobre RAG versus LLMs, o Gemma 4 e a metade "LLM" dessa imagem — o motor de raciocinio que voce apontaria para seu proprio conhecimento.
Os cinco tamanhos, e qual e para voce
O Gemma 4 nao e um modelo, sao cinco, ordenados pelo local onde devem ser executados. Esta e a parte que vale a pena entender antes de qualquer outra coisa, porque escolher o tamanho errado e o erro mais comum que vejo as pessoas cometendo.
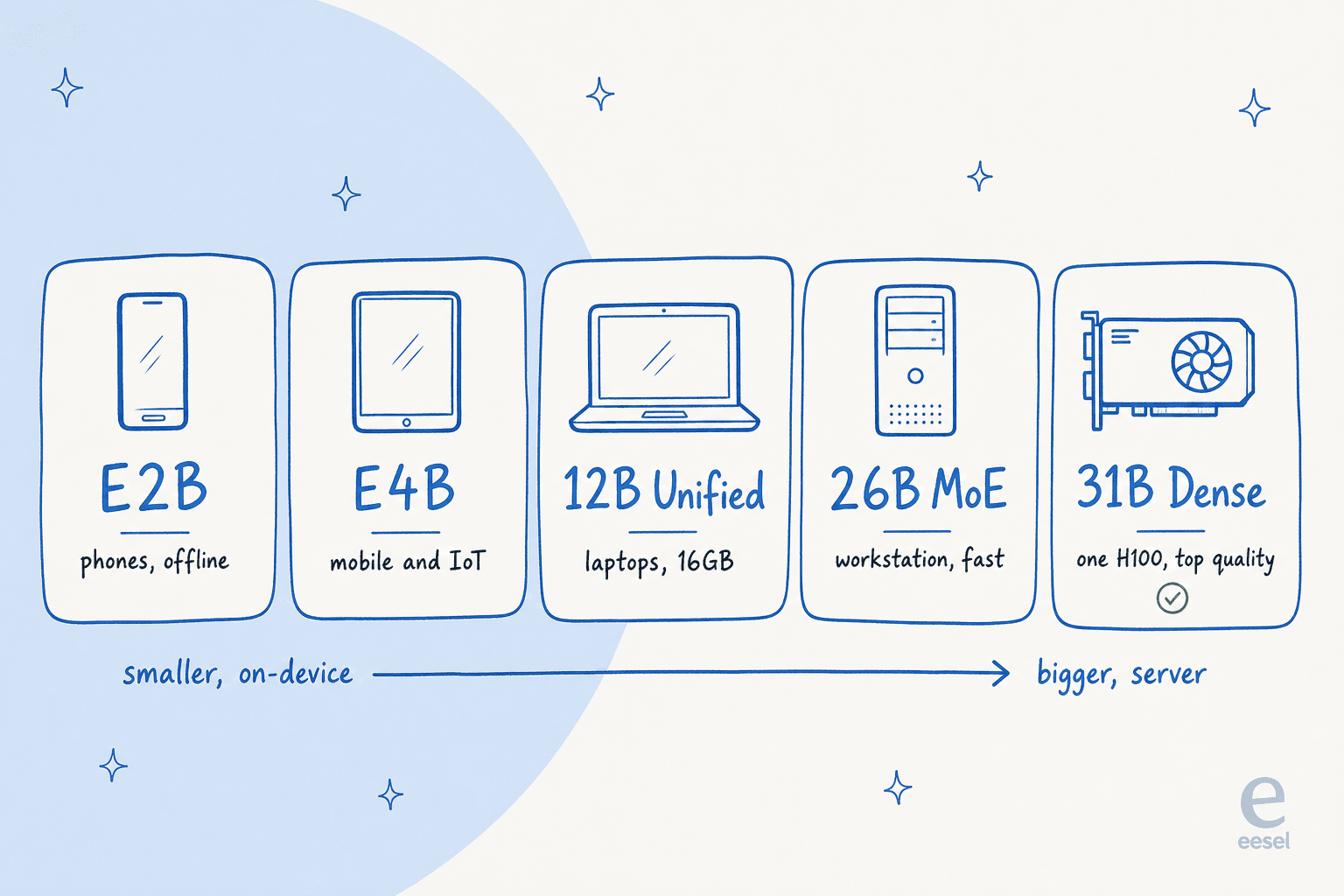
Aqui esta a linha completa, com as especificacoes extraidas diretamente do cartao do modelo:
| Modelo | Parametros efetivos | Contexto | Modalidades | Roda em |
|---|---|---|---|---|
| E2B | 2,3B (5,1B com embeddings) | 128K | Texto, imagem, audio | Telefones, Raspberry Pi, borda |
| E4B | 4,5B (8B com embeddings) | 128K | Texto, imagem, audio | Telefones de ponta, IoT |
| 12B Unified | 11,95B | 256K | Texto, imagem, audio | Laptops (~16 GB) |
| 26B A4B (MoE) | 25,2B total, 3,8B ativos | 256K | Texto, imagem | Estacao de trabalho, baixa latencia |
| 31B Dense | 30,7B | 256K | Texto, imagem | Uma H100 de 80 GB, maxima qualidade |
O "E" em E2B e E4B significa parametros efetivos. Esses modelos usam um truque chamado Per-Layer Embeddings para manter pequeno o uso de memoria, o que permite a um telefone executa-los offline com latencia proxima de zero. O Google os construiu com a equipe do Pixel mais Qualcomm e MediaTek, entao eles sao otimizados para silicon movel real, nao apenas para uma demo.
O Unified de 12B e o recem-chegado, adicionado em 3 de junho de 2026. E a opcao "pronta para laptop" e o primeiro modelo de tamanho medio do Google com entrada de audio nativa. O Dense de 31B e o carro-chefe de qualidade pura e a base da qual todos fazem fine-tuning.
O do meio, o 26B, e o mais inteligente do grupo. Ele merece sua propria secao.
Como um modelo de 26B se mantém competitivo com modelos 20 vezes maiores
O 26B e um modelo Mixture-of-Experts (MoE), e entende-lo e a melhor maneira de compreender por que o Gemma 4 e importante.
Um modelo "denso" normal ativa todos os parametros para cada token que processa. Um modelo MoE divide seus parametros em muitos "especialistas" pequenos e, para cada token, ativa apenas os poucos que realmente precisa. Veja como ele funciona:
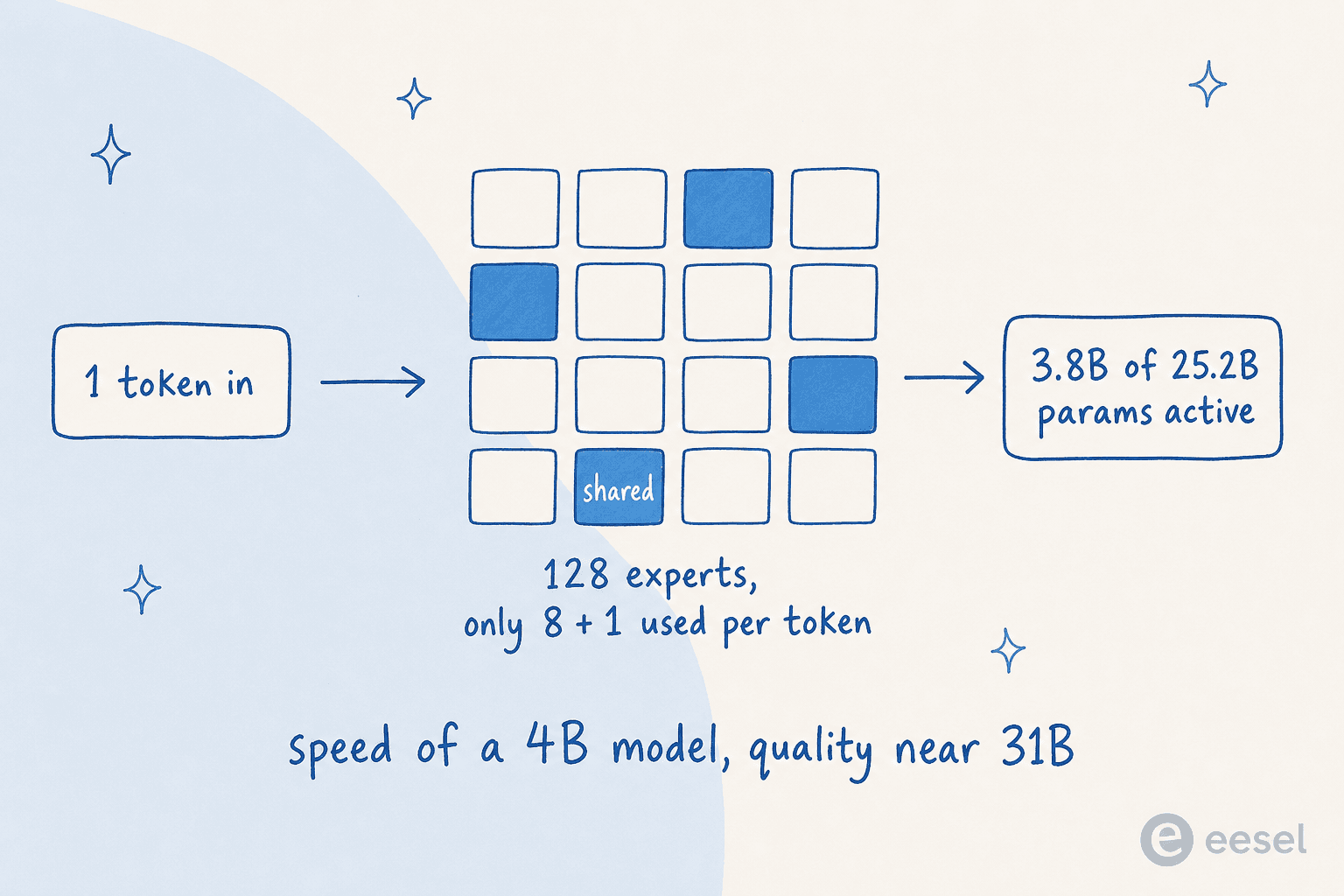
O 26B do Gemma 4 tem 25,2B parametros totais, mas apenas 3,8B ativos por token, roteando por 8 dos seus 128 especialistas mais um especialista compartilhado. O resultado pratico: ele roda aproximadamente tao rapido quanto um modelo denso de 4B enquanto responde com qualidade mais proxima do 31B. (Um aviso a ter em mente: todos os 25,2B parametros ainda precisam ser carregados na memoria para o roteamento, entao o MoE economiza computacao, nao RAM.)
Por que isso importa? Porque quebra a velha suposicao de que "mais inteligente" significa "maior e mais lento". Veja onde os modelos medios do Gemma 4 ficam no proprio grafico de desempenho versus tamanho do Google:
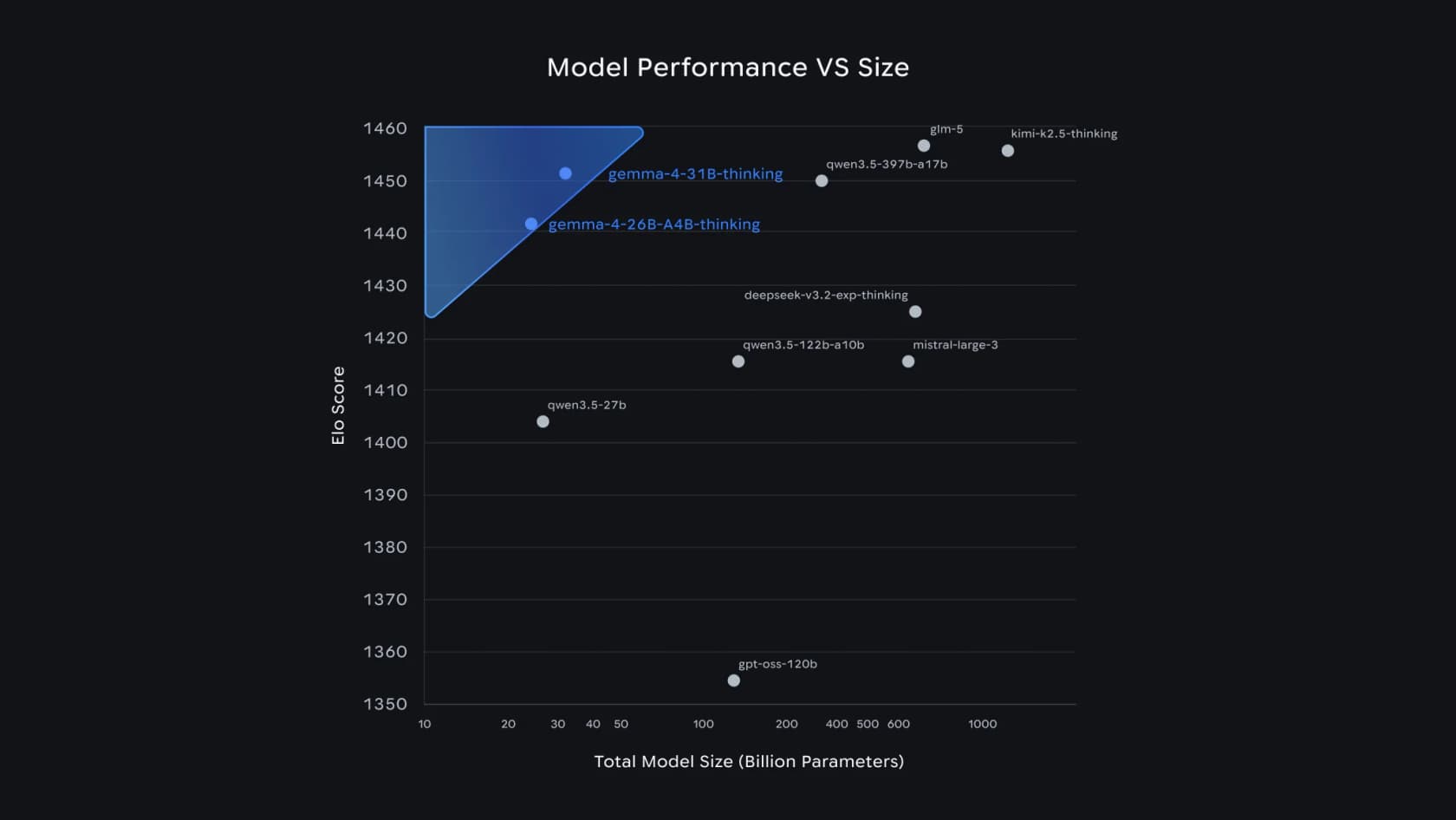
O 31B e o modelo aberto #3 na classificacao de texto do Arena AI, e o 26B MoE ocupa o #6 — e assim que o Google pode afirmar que o Gemma 4 "supera modelos 20 vezes seu tamanho". Para uma equipe de suporte, a conclusao nao e a posicao no ranking, mas que essa qualidade cabe em hardware que voce controla.
O que "pesos abertos" realmente significa (e por que a licenca mudou)
As pessoas usam "aberto" de forma imprecisa, entao deixa-me ser preciso, porque e aqui que o Gemma 4 fez seu maior movimento.
Modelos Gemma anteriores eram distribuidos sob "Termos de Uso do Gemma" personalizados. O Gemma 4 mudou para uma licenca padrao Apache 2.0. Nas palavras do Google, e "comercialmente permissiva" e concede "controle completo sobre seus dados, infraestrutura e modelos". O CEO do Hugging Face, Clement Delangue, chamou o movimento de "um grande marco".
Veja a diferenca que essa licenca faz na pratica:
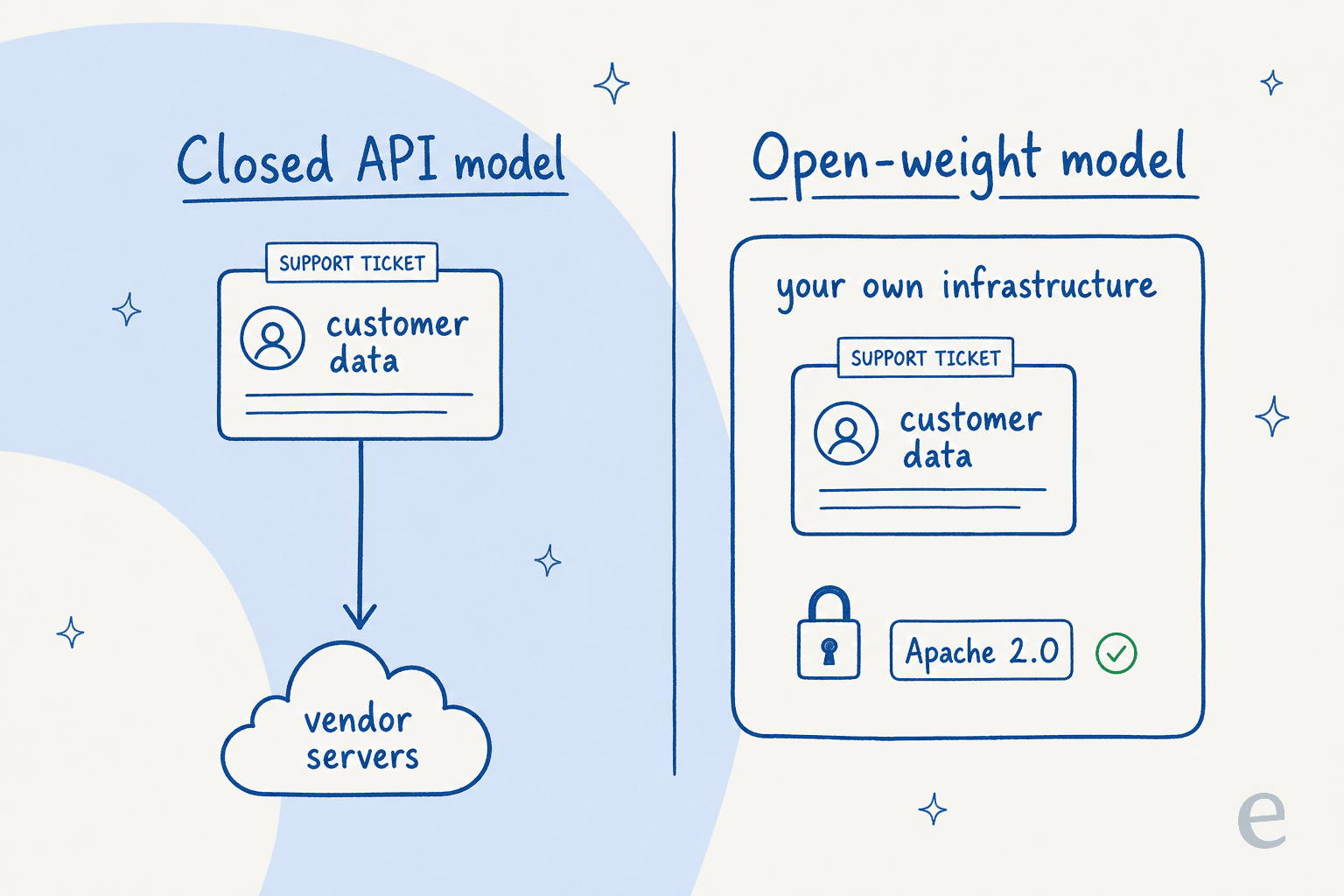
Com um modelo de API fechado, cada mensagem de cliente que voce processa e enviada para os servidores do fornecedor. Com um modelo de pesos abertos sob Apache 2.0, voce pode executar tudo dentro de sua propria infraestrutura — nas instalacoes ou em sua propria nuvem — e os dados nunca saem. Para qualquer pessoa em um setor regulamentado, esse controle de residencia de dados e a unica razao para se preocupar com modelos abertos. E a mesma razao pela qual as pessoas recorrem a sistemas de ticketing de codigo aberto e plataformas de chatbot de codigo aberto.
Para dimensionar isso, o Google oferece o Gemma 4 no Vertex AI, Cloud Run e GKE, e funciona desde o primeiro dia com as ferramentas que os self-hosters ja usam, como Ollama, llama.cpp, vLLM e LM Studio.
Os benchmarks, e onde o Gemma 4 realmente brilha
Agora os numeros. O Google publica uma tabela completa de benchmarks comparando os modelos Gemma 4 com ajuste de instrucoes versus o Gemma 3 27B da geracao anterior:
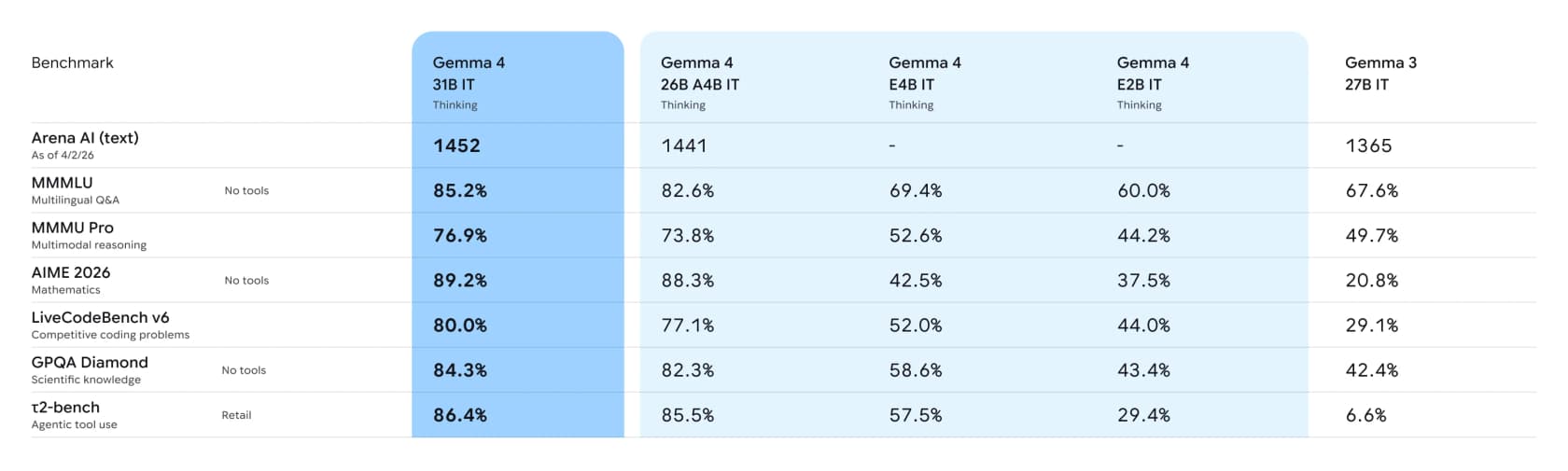
A linha que eu circularia e o uso agenctico de ferramentas. No benchmark τ2-bench retail, que testa se um modelo pode realmente chamar ferramentas para concluir uma tarefa, o modelo de 31B obtem 86,4% contra 6,6% do Gemma 3. Isso nao e uma melhora incremental, e um salto geracional — e a capacidade que transforma um chatbot em algo que pode fazer trabalho real.
Ele tambem se sustenta contra os gigantes fechados. No Arena Elo, o 31B com 1452 fica logo atras de modelos com 15–35 vezes mais parametros:
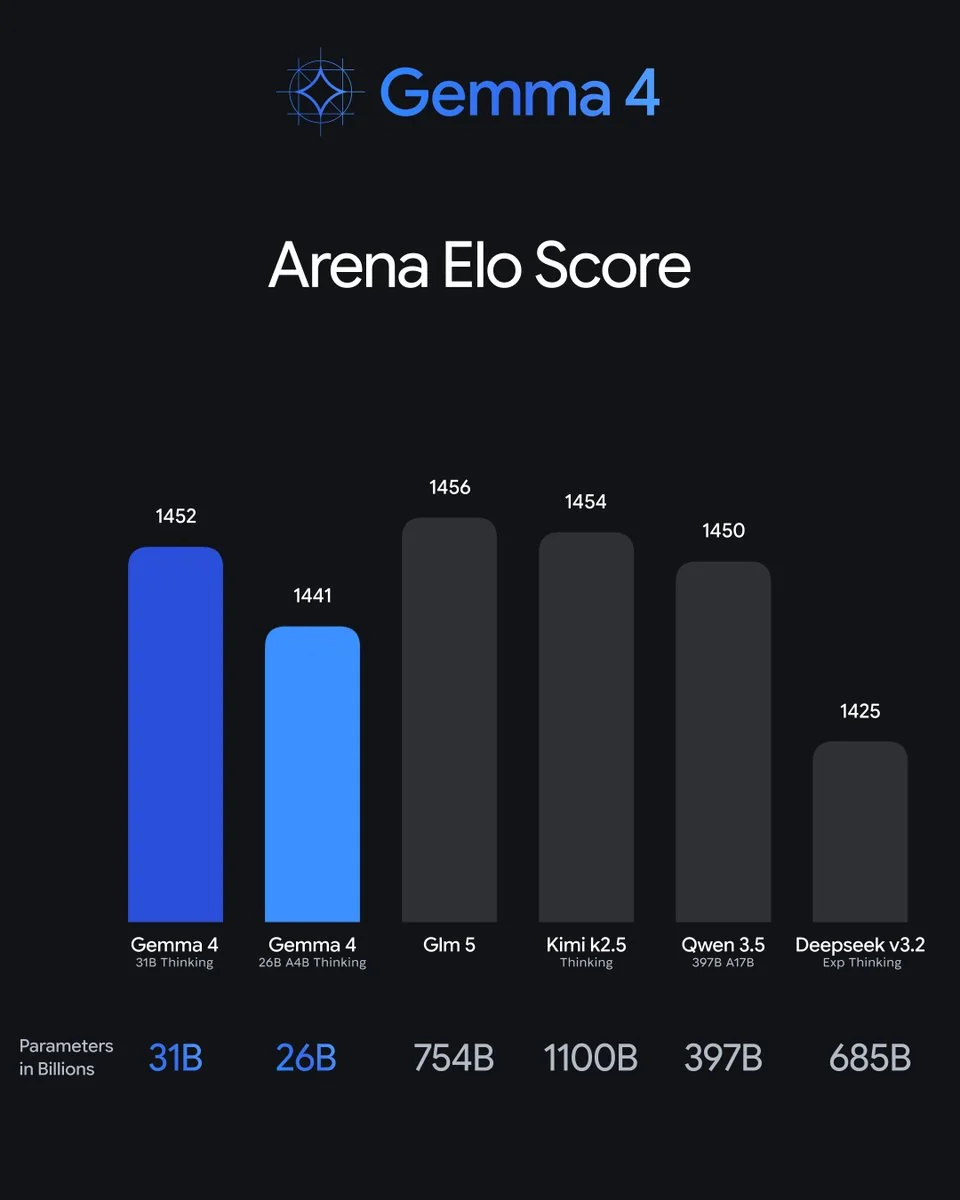
Arquitetonicamente, a nota interessante da leitura de Sebastian Raschka e que o Gemma 4 esta "praticamente inalterado" em relacao ao Gemma 3 por baixo, entao o salto e "provavelmente devido ao conjunto de treinamento e a receita". Em outras palavras, o Google obteve esse salto de dados melhores, nao de uma nova arquitetura — o que e algo silenciosamente impressionante.
Como e na pratica
Benchmarks sao uma coisa. O que as pessoas que executam o Gemma 4 todos os dias realmente dizem? Fui procurar nas comunidades de modelos locais, porque e la que vivem as opinioes sem filtro.
O elogio e consistente: e rapido, leve em memoria e nao fica repetindo.
"Rapido pra caramba em um M4Max, e incrivelmente inteligente para sua velocidade. Nao destroca sua carga de memoria. Nao fica raciocinando por horas (e comendo todo o orcamento de tokens no raciocinio) como o Qwen faz... E perfeito para openclaw, hermes, claude code etc. AMO esse modelo localmente. E meu modelo preferido agora."
O ponto "nao raciocina por horas" aparece repetidamente. Um self-hoster que executa o 26B e o 31B para um caso de uso multimodal colocou numeros reais nisso, relatando aproximadamente 149 tokens/seg no 31B e 88 no 26B, e acrescentando que "os benchmarks realmente nao capturam o quanto ele bloqueia menos comparado aos maiores".
Mas aqui esta a limitacao honesta, e e a razao pela qual eu nao colocaria o Gemma 4 bruto em uma fila ao vivo sem supervisao:
"Concordo que e muito melhor em tudo, exceto em coding. [...] No entanto, sofre muito quando os pesos ou o cache kv sao qualquer outra quantizacao que nao a nativa."
Entao a leitura da comunidade e esta: o Gemma 4 e um excelente modelo de chat e seguimento de instrucoes que rende muito acima de seu peso, com dois alertas — coding e fluxos agencticos sao suas areas mais fracas, e ele se degrada nitidamente se for executado com uma quantizacao diferente da nativa. Bom saber antes de escolhe-lo para uma tarefa.
O que isso significa para o suporte ao cliente
Aqui e onde fica pratico para qualquer pessoa gerenciando uma equipe de suporte. Um modelo aberto como o Gemma 4 e um ingrediente fantastico. Por si so, nao e um agente de suporte.
Um modelo bruto nao sabe qual e sua politica de reembolso, nao consegue ver seus tickets anteriores e nao esta conectado ao seu helpdesk. Coloca-lo na frente dos clientes sem supervisao produz exatamente o modo de falha contra o qual passamos anos desenvolvendo defesas: um bot que parece confiante mas da silenciosamente a resposta errada. O modelo e o motor; o produto real e tudo ao redor dele — o conhecimento, o roteamento seguro, a conexao com suas ferramentas e a capacidade de testa-lo antes de ir ao ar.
Essa lacuna e a razao pela qual existem plataformas como a nossa. O movimento de pesos abertos da controle sobre a camada do modelo, mas a maioria das equipes de suporte nao quer tambem se tornar uma equipe de ML ops. A melhor resposta para a maioria das pessoas e obter os beneficios de controle de dados e aprendizado sem construir a infraestrutura manualmente — que e a linha que eu tracaria entre um modelo e uma plataforma de atendimento ao cliente com IA.
Experimente a eesel para suporte com IA
Se ler sobre o Gemma 4 fez voce pensar "quero que a IA responda meus tickets, mas nos meus termos", esse e exatamente o problema para o qual a eesel foi criada.
O agente de helpdesk de IA da eesel se conecta as ferramentas que voce ja usa — Zendesk, Freshdesk, Gorgias, Slack e mais de 100 outras — e aprende com seus tickets e documentacao de ajuda desde o primeiro dia, para que anos de historico se tornem conhecimento imediatamente. A parte que se mapeia diretamente para a pergunta "voce poderia confiar nele?" com a qual abri: voce pode simular o agente contra milhares de seus tickets historicos para ver exatamente como ele teria respondido, antes de um unico cliente vê-lo. E assim que a Gridwise resolveu 73% das solicitacoes de nivel 1 em seu primeiro mes.

E baseado em uso, a partir de $0,40 por ticket sem taxas por assento, e voce pode comecar com $50 de uso gratuito sem cartao de credito. Seja qual for o modelo por baixo, Gemma 4 ou qualquer outro, o que voce realmente quer e um agente em que possa confiar na sua fila. Experimente a eesel e veja como ela lida com a sua.
Perguntas Frequentes
O que e o Gemma 4?
O Gemma 4 e gratuito?
Quais sao os tamanhos dos modelos Gemma 4?
O Gemma 4 pode ser executado em um laptop ou telefone?
O Gemma 4 e bom para suporte ao cliente?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








