Implemento IA em filas de suporte reais — esta e minha analise para empresas
Vou comecar onde a maioria dos artigos sobre modelos nao comeca, porque e o ponto que decide se o Opus 4.8 faz diferenca no seu negocio. Passei anos observando como modelos de fronteira encontram filas de suporte reais e desorganizadas, e a licao nunca muda: o modelo raramente e a parte dificil.
Alguns numeros para fundamentar isso, ambos de nossos proprios deployments. A Gridwise viu o eesel resolver 73% das solicitacoes de nivel 1 no primeiro mes, com resultados dentro de um teste de 7 dias. A Smava opera um agente Zendesk totalmente automatizado que processa mais de 100.000 tickets em alemao por mes. Nenhum desses resultados veio de escolher o modelo mais inteligente. Vieram do treinamento em tickets resolvidos, do roteamento por confianca e da simulacao contra o historico real antes de entrar em producao.
Entao, quando um novo Opus chega, a pergunta que me importa para uma empresa nao e "ele e mais inteligente em um benchmark". E "isso muda o que eu realmente enviaria para a caixa de entrada de um cliente ou para a mesa da minha equipe?". Vamos olhar o Opus 4.8 com essa perspectiva.
O que e o Claude Opus 4.8 em termos empresariais
O Claude Opus 4.8 e o modelo mais recente da familia Opus da Anthropic — o nivel de alta capacidade do Claude. Foi lancado em 28 de maio de 2026 como sucessor do Opus 4.7, e na API voce o chama como claude-opus-4-8. Se preferir a explicacao geral em vez do angulo empresarial, escrevemos um artigo separado sobre o que e o Claude Opus 4.8.
As especificacoes principais que importam para um comprador: uma janela de contexto de 1M de tokens ao preco padrao, ate 128k tokens de saida e pensamento adaptativo que o modelo gerencia por si mesmo (sem interruptor de pensamento estendido para administrar). Le texto e imagens, lida com mais de 80 idiomas, e seu treinamento vai ate janeiro de 2026 (visao geral dos modelos). A Anthropic o lanca em todos os lugares desde o primeiro dia, incluindo AWS Bedrock, Vertex AI e Microsoft Foundry — o que importa se sua equipe de compras ja tem uma nuvem preferida.
O proprio enquadramento da Anthropic para o salto e refrescantemente moderado. O anuncio o descreve como uma "melhoria modesta, mas tangivel em relacao ao seu predecessor", e essa e a expectativa correta para comunicar internamente. Este e um lancamento de polimento e correcao, nao um salto geracional, e as correcoes sao onde reside o valor empresarial.
O que realmente mudou para os compradores no Opus 4.8
Algumas mudancas valem a pena conhecer se voce esta decidindo em que padronizar sua equipe, em vez de apenas conversar com ele.
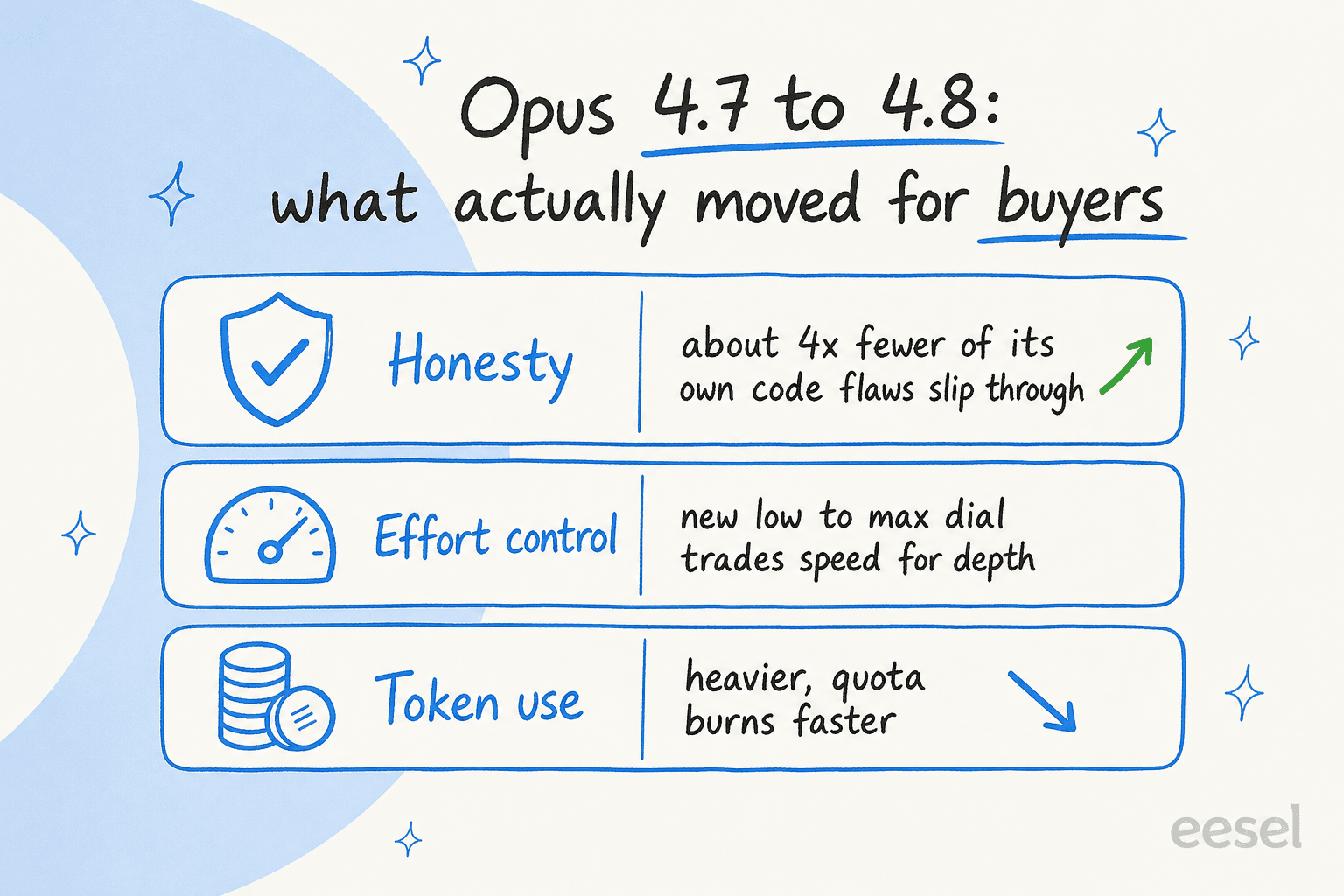
A honestidade recebeu uma melhoria real. A Anthropic chama isso de "uma das melhorias mais proeminentes", e e pelo que eu pagaria em um contexto empresarial. Relata-se que o Opus 4.8 e aproximadamente quatro vezes menos propenso que o 4.7 a deixar passar falhas no proprio codigo sem comentario, e esta mais disposto a sinalizar incerteza do que inventar uma resposta com confianca. Em qualquer lugar onde uma resposta errada tenha um custo — em financas, juridico, suporte regulado — "diz quando nao tem certeza" supera mais um ponto em um benchmark de programacao.
Um novo controle de esforco. Agora ha um controle que define com que intensidade o modelo trabalha, de low ate max, com high como padrao (anuncio). Para uma empresa, isso e uma alavanca de orcamento: aumente para a analise dificil, reduza para tarefas de rotina de alto volume onde velocidade e custo importam mais do que profundidade.
Trabalho agentivo de longo prazo. No Claude Code, o Opus 4.8 pode planejar um trabalho, lançar centenas de subagentes paralelos em uma sessao e, em seguida, verificar o resultado antes de reportar — voltado para trabalho em escala de base de codigo como grandes migracoes (post dynamic-workflows). Se voce gerencia uma organizacao de engenharia, este e o destaque. O System Card afirma que o desempenho e "superior ao do Opus 4.7 em quase todas as avaliacoes".
O problema: ele consome muito. A reclamacao mais repetida da comunidade e que o Opus 4.8 esgota os limites de uso, em parte porque o Opus 4.7 e versoes posteriores usam um novo tokenizador que "pode usar ate 35% mais tokens para o mesmo texto fixo". Entao, mesmo com um preco de tabela sem alteracao, seu custo real por tarefa pode aumentar. Planeje para isso.
Precos do Claude Opus 4.8 para empresas
Os precos sao a parte facil, porque nao mudaram. O Opus 4.8 custa $5 por milhao de tokens de entrada e $25 por milhao de tokens de saida, identico ao Opus 4.7 (pagina de precos). Ha tambem um modo rapido que funciona a 2,5 vezes a velocidade e, segundo a Anthropic, custa visivelmente menos do que o modo rapido em modelos anteriores.
Aqui esta a linha mais ampla de meados de 2026, que e o contexto necessario para realmente escolher um modelo para uma carga de trabalho:
| Modelo | Entrada / saida (por 1M de tokens) | Contexto | Melhor para |
|---|---|---|---|
| Claude Fable 5 | $10 / $50 | 1M | O modelo mais capaz da Anthropic amplamente lancado |
| Claude Opus 4.8 | $5 / $25 | 1M | Top nivel Opus; raciocinio complexo, agentes de longo prazo |
| Claude Opus 4.7 / 4.6 | $5 / $25 | 1M | As geracoes Opus anteriores |
| Claude Sonnet 4.6 | $3 / $15 | 1M | Melhor equilibrio entre velocidade e inteligencia |
| Claude Haiku 4.5 | $1 / $5 | 200k | O mais rapido e economico para tarefas simples de alto volume |
O que destacar para o financeiro: o preco de tabela por token e a menor linha na sua fatura real. A maior parte do custo de executar um modelo em producao e tudo o que o rodeia. Essa e a armadilha em que vejo as empresas caindo.
Se os precos sao o seu unico motivo para ler, nosso guia de precos do Claude vai nivel por nivel, e os precos do Claude Pro cobre os planos por assento em que sua equipe ja pode estar. Para o calculo especifico de suporte, custo de agente de IA vs. agente humano e a comparacao mais util do que uma taxa de token bruta.
Construir sobre a API ou comprar uma plataforma?
Esta e a decisao real que a maioria das empresas enfrenta quando um modelo como o Opus 4.8 chega, e a resposta honesta depende do que voce esta construindo.
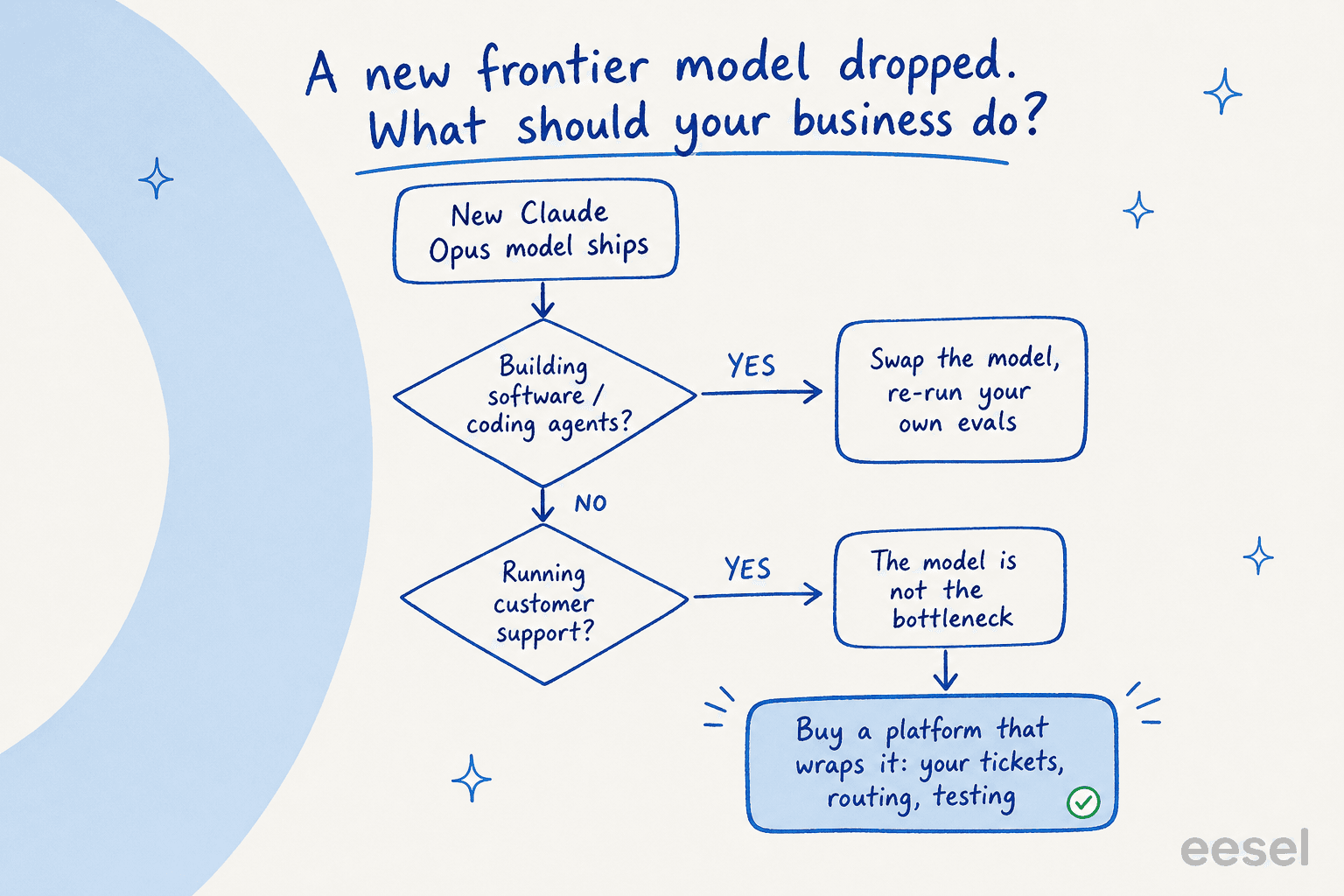
Se voce esta lancando um produto de software ou um fluxo de trabalho de programacao, construir diretamente sobre a API do Claude costuma ser a decisao certa — troque o novo modelo, execute novamente suas proprias avaliacoes, lance. O modelo e o produto ali.
Para um fluxo de trabalho empresarial como suporte ao cliente, e o contrario. Vi muitas equipes capazes chegarem a isso da forma dificil. Vimos clientes saindo para conectar a API do Claude por conta propria, argumentando que se o Opus e tao bom, podem chama-lo diretamente. Alguns meses depois, a realidade de manutencao se instala. Um lider de engenharia que escolheu comprar expressou o calculo claramente:
"Poderiamos tentar escrever nosso proprio aplicativo LLM, mas nao queriamos investir nosso tempo nisso. Queriamos algo que nao precisassemos manter."
Isso vem do estudo de caso da GENERAL BYTES, uma equipe de engenharia em uma empresa de hardware cripto que escolheu comprar em vez de construir. E a versao mais comum da historia: a chamada da API e trivial, e a recuperacao, as barreiras e a manutencao sao o trabalho real. O mesmo padrao aparece nas decisoes de RAG vs. LLM — o modelo raramente e onde o trabalho vive.
O que um modelo mais inteligente faz (e nao faz) para o suporte
Aqui e onde chego ao que realmente conheco. Se voce gerencia uma equipe de suporte, a tentacao quando o Opus 4.8 chega e pensar "otimo, o suporte de IA melhorou". As vezes. Mas vale a pena ser preciso sobre do que realmente e feito o software de atendimento ao cliente com IA, porque um modelo de fronteira e apenas uma parte disso.
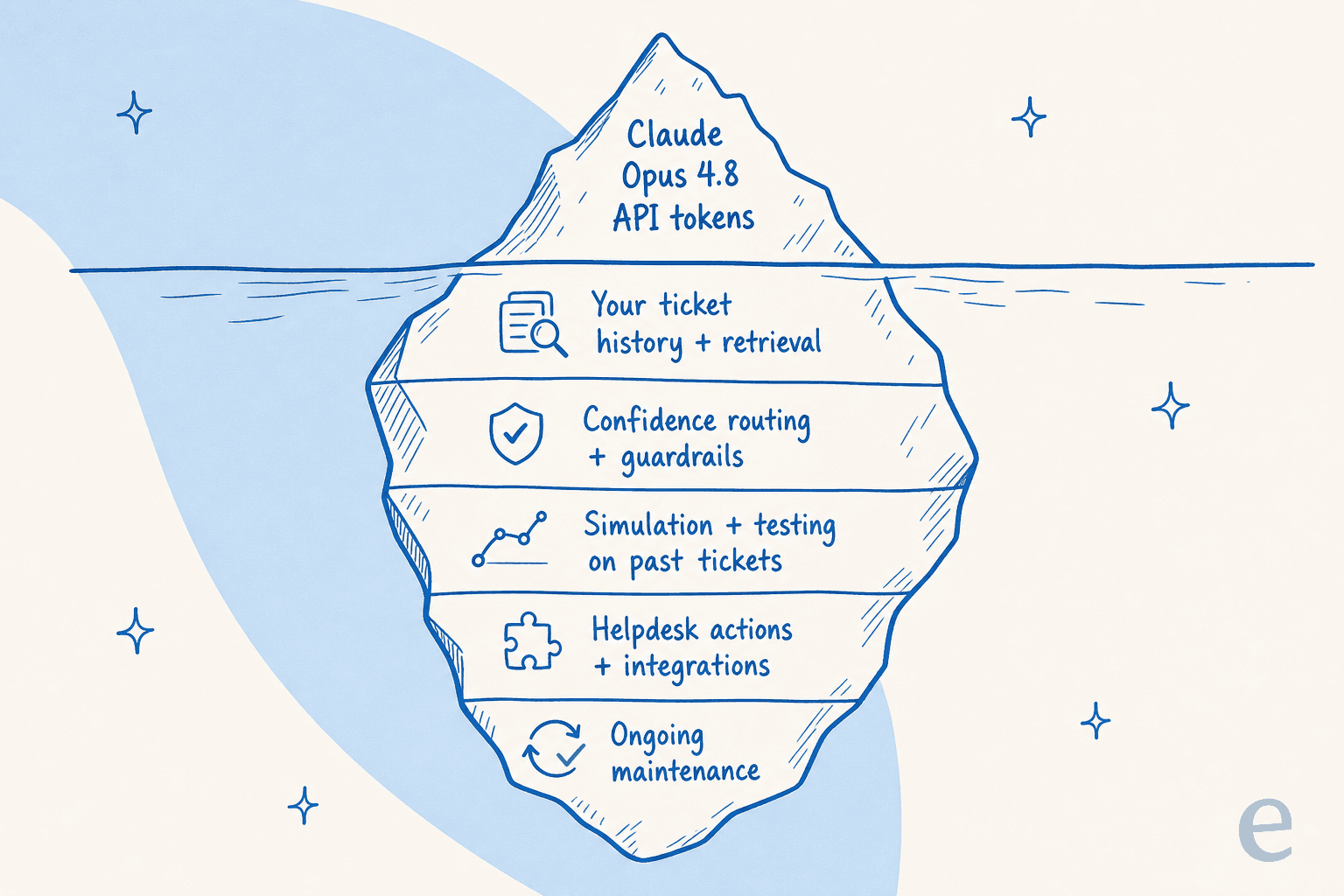
Um agente de suporte em producao e o modelo mais muito andaime nao glamoroso que o Opus 4.8 simplesmente nao inclui:
- Seu conhecimento, nao o do modelo. O corte de treinamento de janeiro de 2026 do Opus 4.8 nao sabe nada sobre sua politica de reembolso ou a interrupcao da semana passada. Um agente util aprende com seus tickets anteriores, documentos de ajuda e macros — que e o ponto cego do conhecimento geral do mundo. (O que e RAG cobre o lado da recuperacao.)
- Roteamento baseado em confianca. Os ganhos de honestidade no Opus 4.8 sao reais, mas voce ainda nao quer que um modelo decida sozinho quando responder ao vivo. Voce quer que ele faça um rascunho quando estiver inseguro e envie automaticamente apenas quando estiver confiante — isso e uma barreira de protecao no nivel do sistema, nao uma configuracao do modelo.
- Uma forma de testar antes de entrar em producao. Antes que um unico cliente veja uma resposta de IA, voce quer executa-la contra milhares de seus tickets reais e resolvidos e ver exatamente onde teria acertado ou errado. Um modelo mais novo nao te da isso; a simulacao sim.
- Escalonamento limpo e acoes. Marcacao, triagem, consulta de pedidos, transferencia para um humano. Isso vive nas suas integracoes de helpdesk, nao no modelo bruto.
E por isso que "qual modelo e o melhor?" costuma ser a pergunta errada para uma equipe de suporte. Descobrimos que um sistema bem construido em um modelo de nivel medio frequentemente supera um modelo de fronteira bruto sem andaime — esse e o argumento inteiro em qual LLM e o melhor para casos de uso de suporte. O Opus 4.8 ser mais honesto e uma boa noticia; ele simplesmente nao muda a forma do trabalho nem move a taxa de resolucao sozinho. Se voce esta avaliando a melhor IA para atendimento ao cliente ou olhando para alternativas ao Claude para um fluxo de trabalho, o modelo e a parte barata e facil. O resto e o trabalho.
Uma divulgacao, ja que e justo: construimos sobre modelos de fronteira como o Claude, entao tenho interesse nisso. E tambem por isso que confio que o modelo nao e a vantagem competitiva — vi a diferenca que um sistema bem construido faz em centenas de equipes que usam IA para atendimento ao cliente.
Experimente o eesel
Se voce chegou ate aqui, provavelmente esta menos interessado em deltas de benchmark e mais interessado em saber se a IA pode tirar trabalho da mesa da sua equipe com seguranca. E isso que o eesel AI faz: ele fica em cima de modelos de fronteira como o Claude (para que voce obtenha raciocinio de classe Opus sem possuir nenhuma da infraestrutura), aprende com seus tickets anteriores e documentos de ajuda, roteia por confianca para que responda automaticamente apenas quando estiver seguro e permite que voce simule no seu historico real de tickets antes de falar com um cliente. Os precos sao baseados em uso sem taxas por assento, entao um mes mais tranquilo custa menos.

Voce pode conectar seu helpdesk e ter uma simulacao em andamento em minutos. Experimente o eesel e aponte-o para seus proprios tickets para ver o que ele realmente resolveria — sem necessidade de um modelo mais inteligente.
Perguntas frequentes
O Claude Opus 4.8 e bom para uso empresarial?
Quanto custa o Claude Opus 4.8 para uma empresa?
Minha empresa deve construir sobre a API do Claude Opus 4.8 ou comprar uma plataforma?
O que mudou no Claude Opus 4.8 em relacao ao Opus 4.7?
O Claude Opus 4.8 pode gerenciar meu suporte ao cliente sozinho?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.