
Eu opero IA em filas de suporte reais — aqui está minha leitura honesta
Vou começar por onde a maioria das explicações de modelos não começa, porque é a parte que realmente importa. Passei anos observando modelos de fronteira encontrarem filas de suporte reais e desordenadas, e o padrão nunca muda: o modelo raramente é a parte difícil.
Alguns números de nossos próprios deployments para fundamentar isso. Um cliente, Gridwise, viu o eesel resolver 73% das suas solicitações de nível 1 no primeiro mês, com resultados durante um teste de 7 dias. Outro, Smava, opera um agente Zendesk totalmente automatizado processando mais de 100.000 tickets em alemão por mês. Nada disso veio de escolher o modelo mais inteligente. Veio de treinar em tickets resolvidos, rotear por confiança e simular no histórico real antes de entrar em produção.
Então, quando um novo Opus chega, a pergunta que me importa não é "ele é mais inteligente num benchmark." É "isso muda o que eu realmente enviaria para a caixa de entrada de um cliente?" Vamos olhar o Opus 4.8 com essa lente.
O que é o Claude Opus 4.8?
Claude Opus 4.8 é o modelo mais recente da família Opus da Anthropic, o nível de alta capacidade do Claude. A Anthropic o lançou em 28 de maio de 2026 e o apresenta como um "colaborador mais eficaz" que "se baseia no Opus 4.7 com melhorias em todos os benchmarks." Na API, você o chama com o ID de modelo claude-opus-4-8.
As especificações principais são fáceis de resumir: uma janela de contexto de 1M tokens ao preço padrão, até 128k tokens de saída e pensamento adaptativo que o modelo controla por si mesmo (não há mais um interruptor de pensamento estendido separado para gerenciar). Lê texto e imagens, lida com mais de 80 idiomas e seus dados de treinamento vão até janeiro de 2026 (visão geral de modelos).
O enquadramento da própria Anthropic para o salto é refrescantemente sem exageros. O anúncio o chama de "melhoria modesta, mas tangível sobre seu predecessor," que é também como o thread do Hacker News o intitulou. Se você se lembra dos saltos geracionais maiores, este não é um deles. É um lançamento de polimento e correção, e está tudo bem; as correções são a parte interessante.
O que há de novo no Opus 4.8
Algumas mudanças valem a pena ser conhecidas, especialmente se você está escolhendo um modelo para construir em vez de apenas conversar.
A honestidade recebeu uma melhoria real. A Anthropic chama isso de "uma das melhorias mais proeminentes," e é a que eu realmente pagaria. O Opus 4.8 é relatado como sendo cerca de quatro vezes menos provável do que o 4.7 de deixar passar erros no próprio código sem comentário e está mais disposto a sinalizar incerteza em vez de inventar uma resposta com confiança. Para qualquer pessoa que implanta IA onde uma resposta errada tem um custo, "te diz quando não tem certeza" vale mais do que mais um ponto num benchmark de codificação.
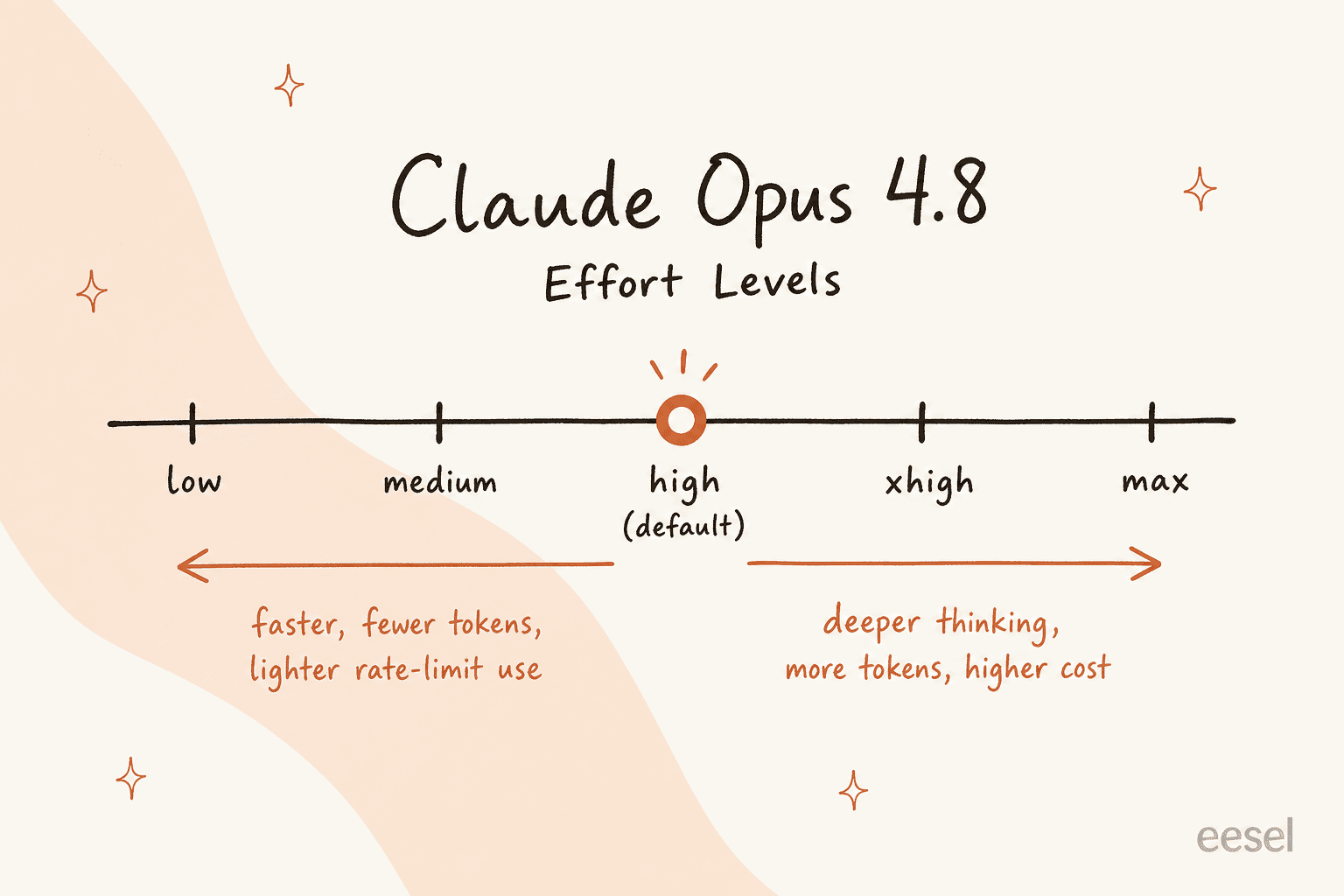
Um controle de esforço. Agora há um dial que define o quanto o modelo trabalha numa resposta, de low a max (com xhigh entre high e max). O padrão é high. Aumente para raciocínio mais profundo, diminua para velocidade e uso mais leve. O trade-off é real e vale a pena entender antes de integrá-lo a qualquer coisa.
Fluxos de trabalho dinâmicos no Claude Code. No Claude Code, o Opus 4.8 pode planejar um trabalho, desdobrar centenas de subagentes paralelos numa sessão e então verificar a saída deles antes de reportar de volta — voltado para trabalho em escala de codebase como migrações em centenas de milhares de linhas. Se você usa subagentes do Claude Code, este é o recurso a experimentar.
Instruções de sistema no meio da tarefa. Para desenvolvedores, a API de Messages agora aceita entradas system dentro do array de mensagens, para que você possa atualizar instruções, permissões ou orçamentos de tokens no meio da execução sem quebrar seu cache de prompts. Mudança pequena, genuinamente útil se você está construindo agentes.
Uma voz mais calorosa. Os primeiros testadores a descrevem como mais fácil de colaborar e melhor em manter contexto e estilo ao longo de uma sessão longa. O lado negativo aparece na reação da comunidade abaixo.
Preços do Claude Opus 4.8 e onde ele se encaixa
Os preços são a parte fácil, porque não mudaram. O Opus 4.8 custa US$ 5 por milhão de tokens de entrada e US$ 25 por milhão de tokens de saída, exatamente o mesmo que o Opus 4.7 (página de preços). Há também um modo rápido que opera a 2,5 vezes a velocidade e, segundo a Anthropic, custa notavelmente menos do que o modo rápido nos modelos anteriores.
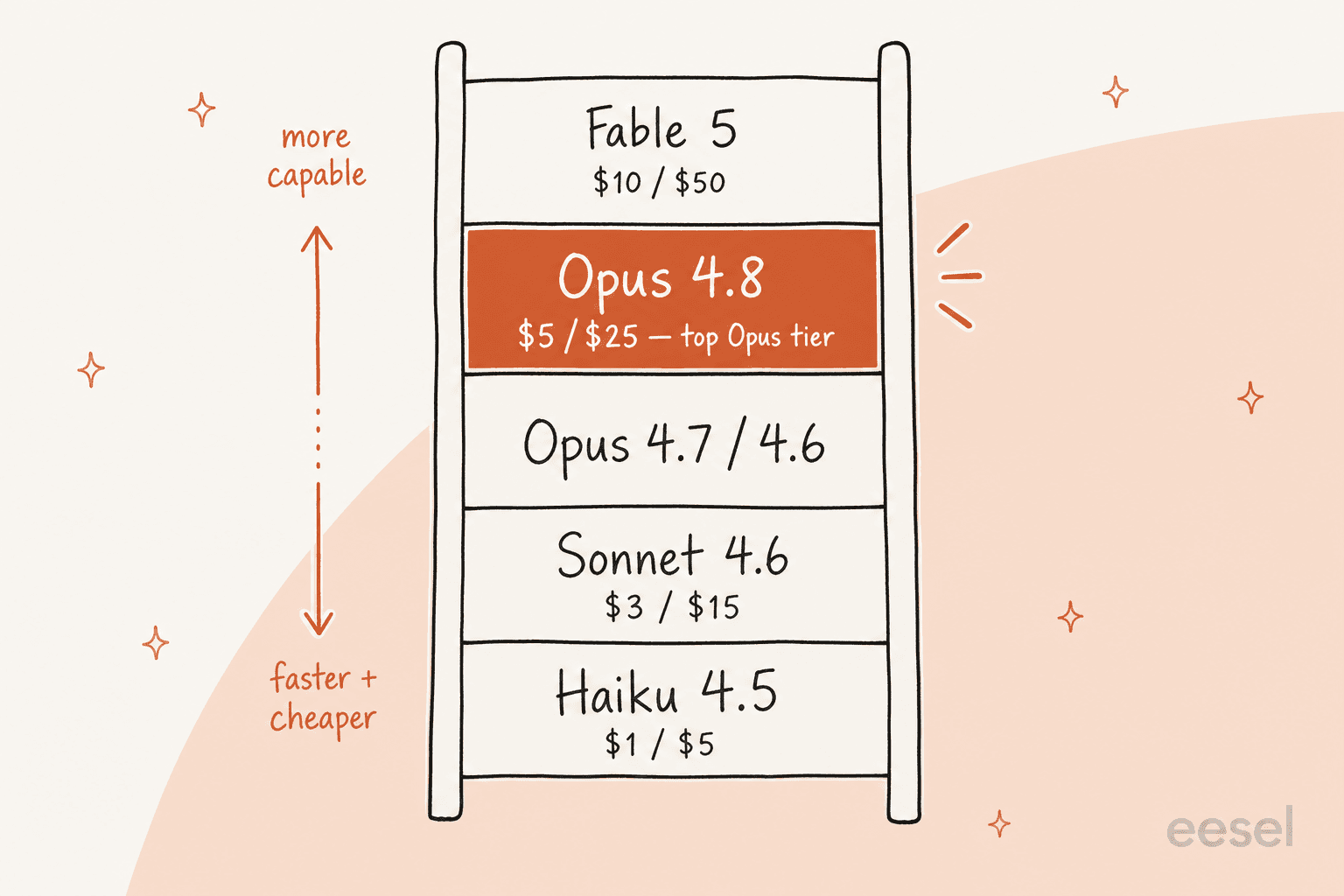
Aqui está a linha completa do Claude em meados de 2026, que é o contexto que você precisa para realmente escolher um modelo:
| Modelo | Entrada / saída (por 1M tokens) | Contexto | Melhor para |
|---|---|---|---|
| Claude Fable 5 | US$ 10 / US$ 50 | 1M | Modelo mais capaz e amplamente disponível da Anthropic |
| Claude Opus 4.8 | US$ 5 / US$ 25 | 1M | Melhor nível Opus; raciocínio complexo, agentes de longo horizonte |
| Claude Opus 4.7 / 4.6 | US$ 5 / US$ 25 | 1M | As gerações Opus anteriores |
| Claude Sonnet 4.6 | US$ 3 / US$ 15 | 1M | Melhor equilíbrio entre velocidade e inteligência |
| Claude Haiku 4.5 | US$ 1 / US$ 5 | 200k | O mais rápido e econômico, para tarefas simples de alto volume |
O que vale notar: o Opus 4.8 é o modelo de nível Opus mais potente, mas não é mais o topo de toda a pilha. Cerca de duas semanas após seu lançamento, a Anthropic lançou o Claude Fable 5 como seu modelo amplamente disponível mais capaz, ao dobro do preço. Então o Opus 4.8 é o padrão sensato de alta capacidade; o Fable 5 é a opção "dinheiro não é problema, dê-me o absolutamente melhor." Colocamos a geração anterior frente a frente com rivais em Gemini 3 Pro vs Claude Opus 4.6 se você quiser ter uma ideia de como os modelos da Anthropic se comparam.
Uma armadilha de custo que vale a pena mencionar, porque surpreende as pessoas: o Opus 4.7 e versões posteriores usam um novo tokenizador que "pode usar até 35% mais tokens para o mesmo texto fixo." Então, mesmo a um preço de tabela inalterado, seu custo real por tarefa pode aumentar em relação a um modelo mais antigo. Esse detalhe explica muito do resmungo da comunidade, o que me leva à próxima parte. (Se os preços são seu principal motivo para ler, nosso guia de preços do Claude vai nível por nível.)
O que as pessoas estão realmente dizendo
A leitura mais clara da reação da comunidade é que o Opus 4.8 é a correção de um 4.7 que as pessoas claramente não gostavam. As opiniões de "retorno à forma" estão por toda parte e se alinham com nossa análise de longa data do Claude. Um desenvolvedor, algumas horas depois de testar em r/ClaudeAI, expressou bem:
"4.8 é preciso, pensa rápido e não alucionou nada. Quando não sabe algo, me pergunta diretamente em vez de inventar algo. Parece o que o 4.6 deveria ter evoluído para ser."
Isso corresponde às afirmações de honestidade da Anthropic e é o positivo mais repetido. Mas duas tensões honestas merecem ser ventiladas, porque são o tipo de coisa que uma página de marketing não vai te contar.
Primeiro, é voraz. A reclamação mais comum é que o Opus 4.8 consome os limites de uso rapidamente, em parte graças ao novo tokenizador. Como um usuário observou em um thread comparando-o ao GPT-5.5:
"O Opus 4.8 é uma besta, muito melhor que o 4.7 na execução mas também no design, acho; o problema real são os tokens, ele consome muito mais tokens e pela primeira vez atingi um limite dentro da minha assinatura máxima."
Segundo, a autonomia não é mágica. Usuários avançados executando tarefas longas e difíceis relatam que o Opus 4.8 ainda precisa de escopo preciso, com um arquiteto de sistemas quantitativos notando que "para usar o Opus 4.8 de forma eficaz, o humano ainda precisa pensar muito. Você precisa definir mais, guiar mais e manter mais do contexto você mesmo." E o lado negativo dos celebrados ganhos de honestidade é que uma minoria vocal o acha muito cauteloso ou apologético para trabalho criativo aberto. Nada disso é condenatório. É apenas a imagem calibrada: um modelo potente, honesto e faminto por tokens que recompensa instruções claras.
O que um modelo mais inteligente significa realmente para o suporte ao cliente
Aqui chego ao que eu realmente sei. Se você gerencia uma equipe de suporte, a tentação quando um modelo como o Opus 4.8 chega é pensar "ótimo, o suporte com IA acabou de melhorar." Às vezes. Mas o modelo é o motor, não o carro, e vale a pena ser preciso sobre o que o software de atendimento ao cliente com IA realmente é feito.
Já vi muitas equipes tecnicamente competentes chegarem à mesma conclusão do jeito difícil. Vimos clientes saírem para integrar a API do Claude por conta própria, raciociando que se o Opus é tão bom, podem chamá-la diretamente. Alguns meses depois, a realidade da manutenção se impõe. Um líder de engenharia que optou por comprar em vez de construir resumiu o cálculo claramente: ele poderia escrever sua própria aplicação LLM, mas "não queria investir tempo nisso" e queria "algo que não tivéssemos que manter."
Isso porque um agente de suporte em produção é o modelo mais muito andaime não glamoroso:
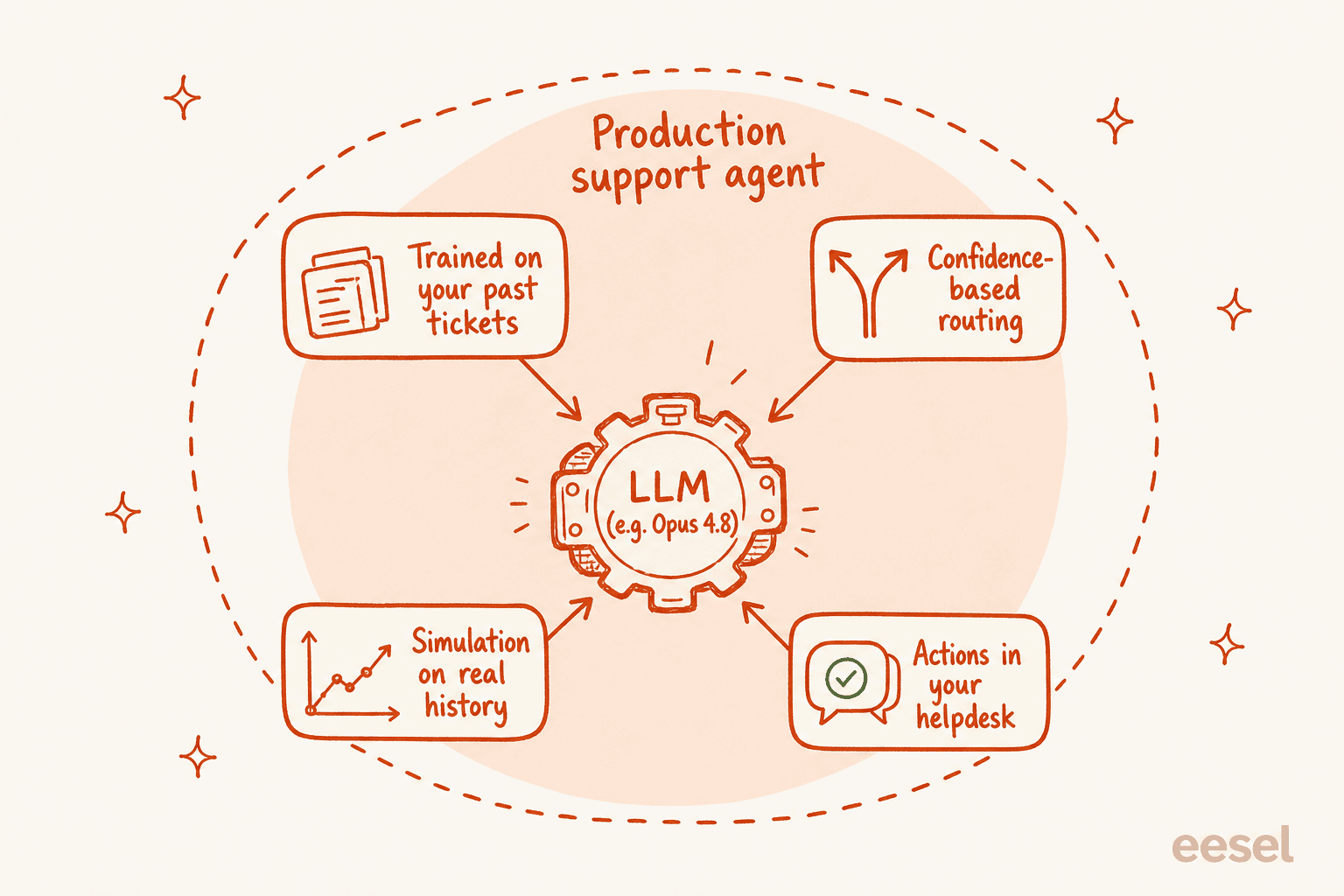
- Seu conhecimento, não o do modelo. A data de corte de treinamento do Opus 4.8 em janeiro de 2026 não sabe nada sobre sua política de reembolso ou a interrupção da semana passada. Um agente útil aprende com seus tickets anteriores, documentos de ajuda e macros — não com o conhecimento geral do mundo.
- Roteamento baseado em confiança. Os ganhos de honestidade no Opus 4.8 são reais, mas você ainda não quer que um modelo decida por conta própria quando responder ao vivo. Você quer que ele esboce quando não tiver certeza e só envie automaticamente quando estiver seguro — o que é uma salvaguarda a nível de sistema, não uma configuração do modelo.
- Uma forma de testar antes de entrar em produção. Antes de um único cliente ver uma resposta de IA, você quer executar o sistema contra milhares de seus tickets reais e resolvidos e ver exatamente onde teria acertado ou errado. Escolher um modelo mais novo não lhe dá isso; a simulação sim.
- Ações, não apenas respostas. Marcar, classificar, consultar um pedido, escalar de forma limpa para um humano. Tudo isso vive em suas integrações de helpdesk, não no modelo bruto.
Também é por isso que "qual modelo é melhor" é a pergunta errada para suporte. Descobrimos que um sistema bem construído num modelo de nível médio geralmente supera um modelo de fronteira bruto sem andaime — que é o ponto central do nosso artigo sobre qual LLM é melhor para casos de uso de suporte. O Opus 4.8 ser mais honesto são boas notícias; apenas não muda a forma do trabalho. Se você está pesando construir seu próprio suporte de IA versus comprar uma plataforma, o modelo é a parte barata e fácil. O resto é o trabalho.
Experimente o eesel
Se você chegou até aqui, provavelmente está menos interessado em deltas de benchmarks e mais em saber se a IA pode tirar tickets da fila da sua equipe com segurança. É exatamente isso que o eesel AI faz: ele se posiciona sobre modelos de fronteira como o Claude (para que você obtenha o raciocínio de classe Opus sem possuir nenhuma da infraestrutura), aprende com seus tickets anteriores e documentos de ajuda, roteia por confiança para que só responda automaticamente quando tiver certeza, e permite que você simule com seu histórico real de tickets antes de falar com um cliente. O preço é baseado em uso sem tarifas por usuário, então um mês mais tranquilo custa menos, não o mesmo.

Você pode conectar seu helpdesk e ter uma simulação funcionando em minutos. Experimente o eesel e aponte-o para seus próprios tickets para ver o que ele realmente resolveria.
Perguntas frequentes
O que é o Claude Opus 4.8?
Quanto custa o Claude Opus 4.8?
Qual é a diferença entre o Claude Opus 4.8 e o Opus 4.7?
O Claude Opus 4.8 é bom para suporte ao cliente?
Devo construir meu próprio suporte de IA com a API do Claude Opus 4.8?
Onde o Claude Opus 4.8 se encaixa na linha da Anthropic?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.





