GLM-5.2とは何か
GLM-5.2はZ.aiの最新フラッグシップモデルです。Z.aiはかつてZhipu AIとして知られ、2019年に清華大学からスピンアウトし、2026年1月に香港証券取引所に上場しました。簡単なスペックシート:
- オープンウェイト、MITライセンス。 ウェイトはHugging FaceとModelScopeで公開されており、地域制限なし。自分でダウンロードして実行できます。
- 7530億パラメータ、約400億が有効。 Mixture-of-Expertsモデルのため、トークンごとにパラメータの一部のみが起動します。
- 100万トークンコンテキスト。 GLM-5.1の20万から5倍の拡大。Z.aiは長く複雑なコーディングエージェントの実行全体で信頼性が保てるよう訓練されている点を強調しており、単に名目上トークンを受け付けるだけではないとしています。
- ロングホライズン作業向け設計。 5.2リリース全体が、何時間も続く自律的なコーディング・エンジニアリングタスクを念頭に設計されており、新しいエフォートレベル制御(最高品質の
Max、出力トークンを約半分にするHigh)が追加されています。
一言で言えば:合法的に自分のハードウェアで実行できるフロンティアクラスのコーディングモデルです。 この組み合わせが注目を集めているのは、この品質でそのようなモデルが以前は存在しなかったからであり、チームが生成AIの予算について考える方法を変えつつあります。
ベンチマークとビジネスへの示唆
Z.aiの主要な主張は、GLM-5.2が標準コーディングベンチマークで最強のオープンソースモデルであり、Terminal-Benchで80%を超えた初のオープンウェイトモデルだということです。数字がそのフレーミングを裏付けています。
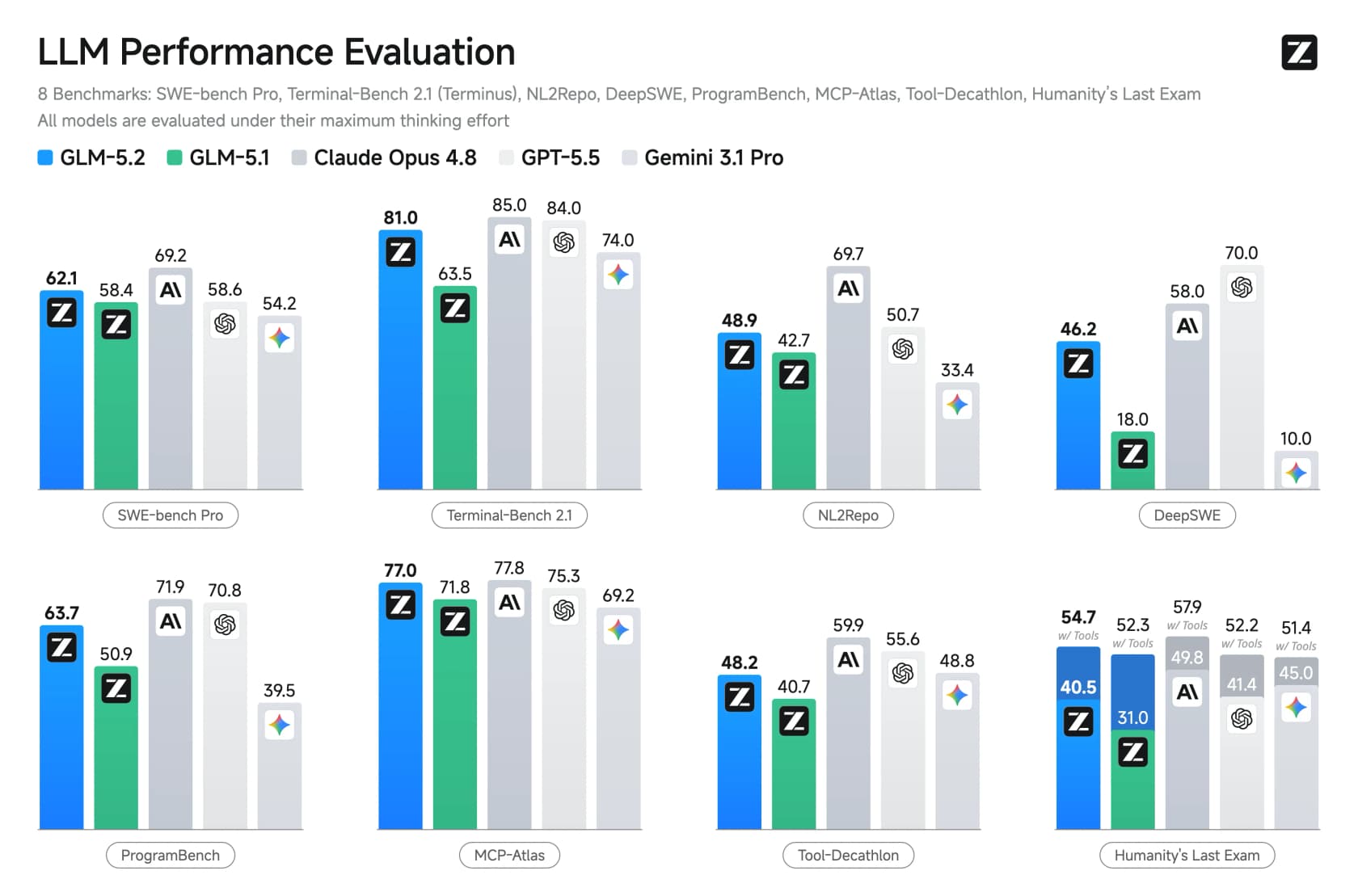
標準コーディングスイートでは、GLM-5.2はSWE-bench Proで62.1、Terminal-Bench 2.1で81.0を記録し、Opus 4.8(85.0)のすぐ後ろに位置し、複数の指標でGPT-5.5を上回っています。GLM-5.1からの飛躍が注目ポイントです:Terminal-Benchは1回のリリースで63.5から81.0へと上昇しました。
ロングホライズンの状況はさらに一方的で、Z.aiが力を注いだ部分です。
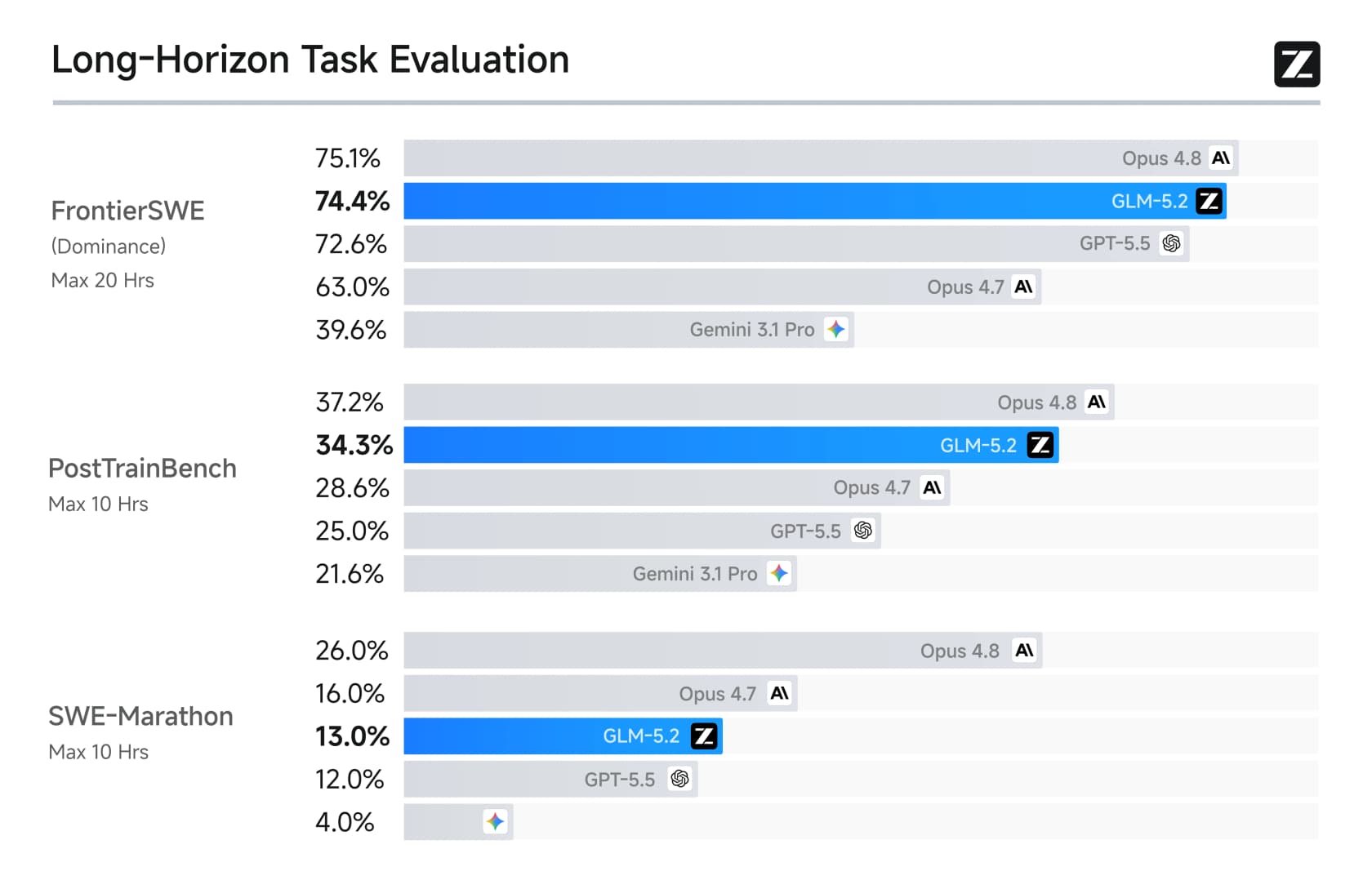
FrontierSWEでは74.4%を達成し、Opus 4.8の75.1%とほぼ互角で、GPT-5.5を大きく上回っています。著名な実践者たちも注目しました。fast.aiのJeremy Howardはこれを驚異的と呼びました:
「@Zai_org GLM 5.2は驚異的です!少なくともOpus 4.8やGPTと同等以上です…超高速で低コスト、冗長でもない。ニュアンスと判断力のある回答をし、長いコンテキストの処理が非常に優れています。」
CMUでコーディングエージェントに取り組むGraham Neubigはさらに踏み込み、「おそらくワークフローからクローズドモデルを完全に排除できるほど優れた初のモデル」と投稿しました。お世辞を言う理由のない人物からの力強い言葉です。
ただし、一点注意が必要です。これらはコーディングベンチマークです。GLM-5.2が長いセッションにわたるコードの記述と修正に優れていることは示されていますが、夜中の2時に混乱した顧客に回答する場面での挙動についてはほとんど何も教えてくれません。その場合の失敗は失敗したテストではなく、誰も気づかない自信を持った誤回答です。詳しくは後述します。
本当のヘッドラインはコスト
ベンチマークが注目を集めますが、ビジネスを実際に動かすのはコストです。GLM-5.2は入力100万トークンあたり$1.40、出力100万トークンあたり$4.40で動作し、GPT-5.5の$5/$30、Opus 4.8の$5/$25と比較されます。
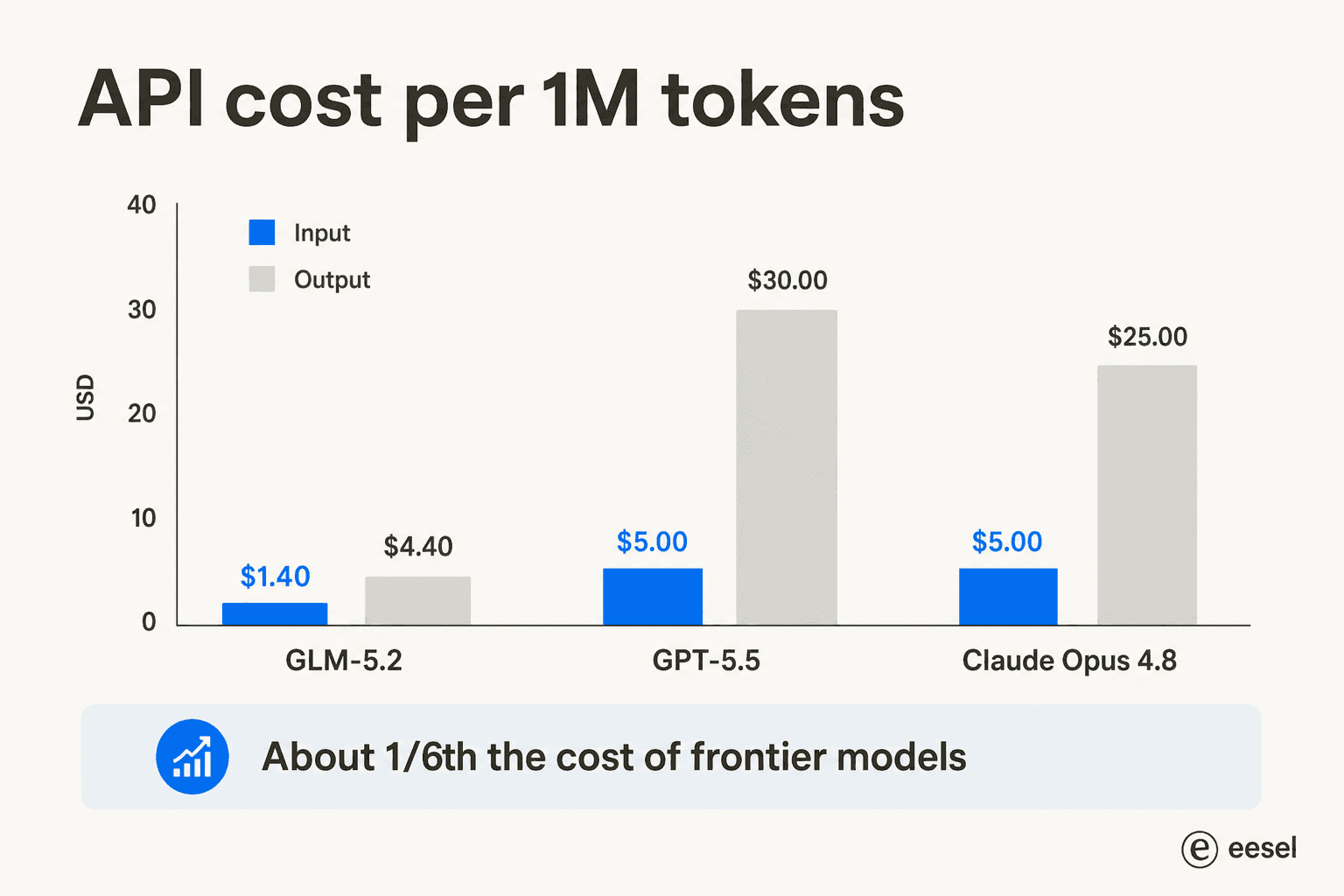
この差が多くのチームにとっての全てです。RedditやLinkedInでの評価は一致しており、日常的なコーディングに使える「安価なフロンティアキラー」という位置付けです。Nate HerkelmanはLinkedInの投稿でその雰囲気を端的に表現しました:「Claude CodeでのGLM 5.2は頭が吹き飛びそうです(5倍安い)。」
ただし「安価」にはアスタリスクが必要で、予算計画においては重要な点です。GLM-5.2は重いリーズナーで、特にMaxエフォートでは多くの出力トークンを消費して思考します。そのため、エフォートレベルを管理しないと、トークン課金APIでは表示価格が示唆するよりも速く請求額が増える可能性があります。定額プランはまさにこのコストを予測可能にするために存在しており、これがアクセスの問題につながります。
ビジネスでGLM-5.2を実行する3つの方法
「ビジネス向けGLM-5.2」に唯一の道はなく、3つあり、それぞれ非常に異なるチームに適しています。

| アクセス方法 | 価格 | 最適用途 |
|---|---|---|
| Z.ai API(トークン課金) | 入力$1.40 / 出力$4.40(100万あたり) | 独自アプリやエージェントへの組み込み;従量制利用 |
| OpenRouter / アグリゲーター | 入力$1.20 / 出力$4.10から(100万あたり) | ルーティングプロバイダー経由の同モデル、しばしばやや安価 |
| GLM Coding Plan、Lite | $18/月(年払い$12.60/月) | Claude Codeと20以上のツールでの軽量コーディング |
| GLM Coding Plan、Pro | $72/月(年払い$50.40/月) | 中規模リポジトリでの日常的な開発、Liteの5倍利用 |
| GLM Coding Plan、Max | $160/月(年払い$112/月) | 大規模リポジトリ、ヘビーユース、Liteの20倍利用 |
| セルフホスティング(オープンウェイト) | 無料(MIT)+ハードウェア | 完全なデータ制御、規制環境またはエアギャップ環境 |
トークン課金APIは、GLM-5.2を自社製品に組み込む最も迅速な方法です。OpenAI互換とAnthropic互換の両エンドポイントが付属しているため、Claude Codeや同様のハーネスをそのまま向けることができます。GLM Coding Planは、コーディングツールで作業する開発者が、従量制ではなく予測可能な月額料金を求める場合の定額ルートです。
セルフホスティングは最も過大評価されている選択肢です。確かにウェイトは無料でMITライセンスであり、これは規制産業にとって本当に大きな意味を持ちます。しかし7530億パラメータのモデルは、空きGPUで実行できるものではありません。r/LocalLLaMAのある開発者が述べたように、「753Bという巨大なフットプリントは、エンタープライズクラスターなしでは自宅で実行できないことを意味します。」現実的には、クォンタイゼーションによる品質低下を考慮する前に約15万ドル相当のハードウェアを要するマルチGPUサーバーが必要です。ほとんどのビジネスにとって「セルフホスティング」とは実際には「信頼するクラウドプロバイダーでホスティングする」ことを意味し、「社内で実行する」ことではありません。
GLM-5.2が適している場所と注意すべき場所
要素を組み合わせると、状況はかなり明確になります。社内エンジニアリング作業については、GLM-5.2は少なくとも試用する価値が十分にあります:エージェンティックコーディング、リファクタリング、長いデバッグセッション、大規模コードベースでの自動調査。品質は確かで、価格は代替手段の何分の一かであり、コストに敏感なら反論するのは難しいです。タスク構成がシンプルなら、ルーティン作業ではさらに安価なDeepSeekの価格も検討する価値があります。
注意すべきは顧客向けのあらゆる作業で、これはベンチマークがカバーしていない部分です。

生のモデル——どんな生のモデルであれ——をライブの顧客に向けることに慎重にさせる3つの点があります:
- データ所在地。 GLM-5.2は中国拠点のラボによるオープンウェイトモデルで、Z.aiは2025年に米国商務省エンティティリストに追加されました。オープンウェイトはここでは問題ではなく、実際には解決策です。顧客データがファーストパーティAPIに触れないよう、セルフホスティングや審査済みプロバイダー経由のルーティングが可能です。ただしそれは意図的に行う必要がある判断です。いくつかのチームがプライバシーの懸念を声高に指摘しており、それは正当な指摘です。
- 信頼性。 「ビッグモデルの匂い」は現実で、コーディングスコアが優秀でも返金ポリシーを自信を持って作り上げないとは限りません。セキュリティ研究者のZack Kormanは、GLM-5.2が「AIエージェントのサンドボックスエスケープとバイパスが非常に得意に見える」と指摘しており、システムへのツールアクセスを与える前に知っておきたい情報です。実際のチケットでのハルシネーションは信頼の問題であり、だからこそ私たちは本番稼働前に歴史的チケットでシミュレーションを行います。
- レイテンシとコスト管理。 GLM-5.2をコーディングで優れたものにしている重いリーズニングの特性は、
Maxエフォートでの回答を遅くかつ高価にします。顧客が待っている場合、これは重要です。
これらはどれも致命的な問題ではありません。「モデルが高スコアだった」と「明日顧客の前に置く」の間の差にすぎません。解決策はより良いモデルではなく、その周辺の層です。
GLM-5.2(またはあらゆるモデル)をサポートに使う:eesalの方法
サポートキューでAIを何年も運用した後に繰り返し気づくことがあります:ハーネスがモデルより重要だということです。同じ点がコミュニティでも見られます——人々は劣ったセットアップの強力なモデルよりも、優れたセットアップの能力の低いモデルが上回ることをしばしば発見します。実際のチケットで結果を決めるのは、AIがナレッジに根付いているか、いつ発言するかを制御しているか、そして本番前にテストしたかです。これが本物のAIサポートエージェントをルールベースチャットボットと分ける同じ教訓です。
それがeeselです。最良のモデルの上に座る審査済みの層で、過去のチケットとヘルプドキュメントから学び、確信があるときにのみ回答し、それ以外はすべて人間に引き渡します。本番稼働前には、何千もの実際の歴史的チケットに対してシミュレーションを実行し、どのように回答していたかを正確に確認します——本番で初めて気づくことがないように。これが生のGLM-5.2 APIキーでは得られない部分であり、実際のリスクの大部分が存在する場所です——サポートAIのビルドvs購入を決める同じギャップです。

私の率直な見解:エンジニアのためにGLM-5.2に興奮し、今週コーディングで試してみてください。顧客向けの部分については、モデルを交換可能なパーツとして扱い、安全にデプロイできる層にエネルギーを注いでください。eeselは無料で試用でき、1円も使う前に自分のチケットでシミュレーションできます——それが私がどのモデルもビジネスに準備できているかを判断する唯一の方法です。AIサポートのコスト全体を評価しているなら、それが本当に重要な数字です。
よくある質問
GLM-5.2はビジネス利用に十分なレベルですか?
GLM-5.2のビジネス向けコストはどのくらいですか?
GLM-5.2は会社データに使っても安全ですか?
GLM-5.2をカスタマーサポートに使えますか?
GLM-5.2はDeepSeekやGPT-5.5よりビジネス向けに優れていますか?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.