
GLM-5.2とは?
GLM-5.2は、Z.aiが製造した大規模言語モデルです。Z.aiは2019年に中国の清華大学から派生した中国のAIラボで、2025年の国際リブランドまでZhipu AIとして知られていました。同社は2026年1月に香港証券取引所に上場しており、これは中国の主要なLLMメーカーとして初の上場事例です。アリババ、テンセント、サウジアラビアのProsperity7が出資しています。
GLM-5.2が注目に値する3つの理由:
- MITライセンスのオープンウェイト。 Hugging Faceから完全なモデルをダウンロードして自分で実行でき、地域制限もありません。APIを通じてアクセスをレンタルするだけのClaudeやGPT-5とは異なる提供形態です。
- 大きいが効率的。 GLM-5.2は7,440億パラメータ(Z.aiは753Bに切り上げ)のMixture-of-Expertsモデルです。つまり、任意のトークンに対してアクティブになるのは約400億パラメータのみです。巨大なモデルの知識を、はるかに小さなモデルの実行コストで得られます。
- 100万トークンのコンテキストウィンドウ。 GLM-5.1の200Kから5倍の拡大で、Z.aiが最も押し出している機能です。自慢するためではなく、コーディングエージェントが長いタスク全体を通じて大規模なコードベース全体を頭に入れておけるということが重要です。
Z.aiが選んだキャッチフレーズ、「Built for Long-Horizon Tasks(長期的なタスクのために構築)」がターゲットを教えてくれます。これは単一のプロンプトに答えるためではなく、数時間にわたって多段階のエンジニアリング作業に取り組むために設計されたモデルです。
GLM-5.2の実際の新機能
GLM-5.2はゼロから作られたモデルではありません。2026年2月に始まったGLM-5系列の上に、長いコンテキストと効率性を重視した改良を加えたものです。GLM-5.1と比較して、3つの変更点が目立ちます。
1つ目は1Mコンテキストです。Z.aiは名目上のものではなく、「solid(確かな)」 1Mと慎重に表現しています。技術的に100万トークンを受け入れても途中で脈絡を失うモデルは少なくありません。GLM-5.2は長いコーディングエージェントの軌跡で特別に訓練され、全体を通じて一貫性を保ちます。
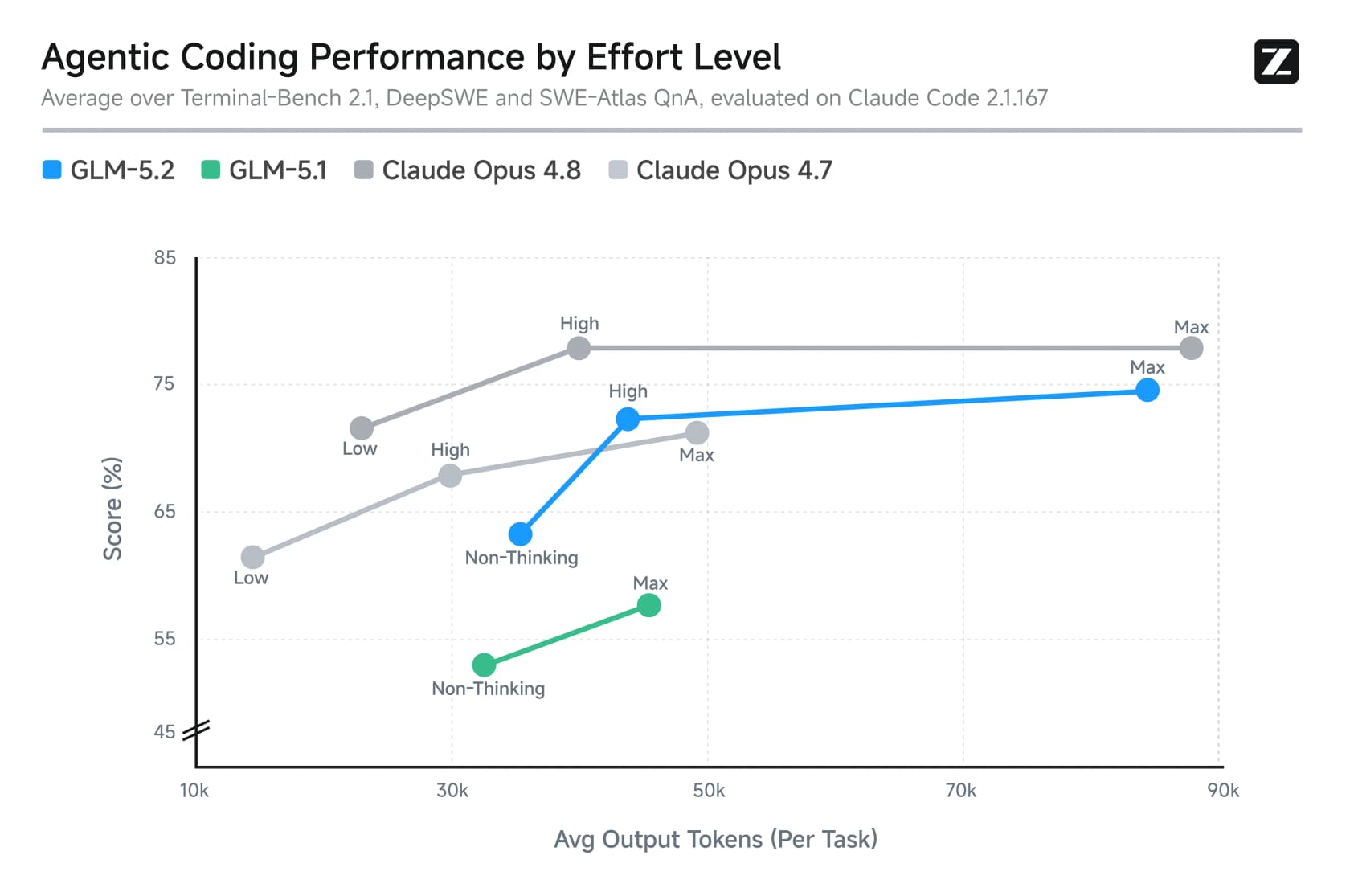
2つ目は選択可能な努力レベルです。GLM-5.2はMaxモード(最高の知性だが思考時間が長い)と、少しの精度低下で出力トークンをほぼ半分にするHighモードを備えています。タスクごとに調整できるレイテンシとコストのレバーです。
3つ目は、発表で最も強調されているロングホライズンコーディング能力です。数時間のエンジニアリング作業を測定するように設計されたベンチマークでは、GLM-5.2はGLM-5.1を大きく上回り、GPT-5.5を直接打ち負かしました。
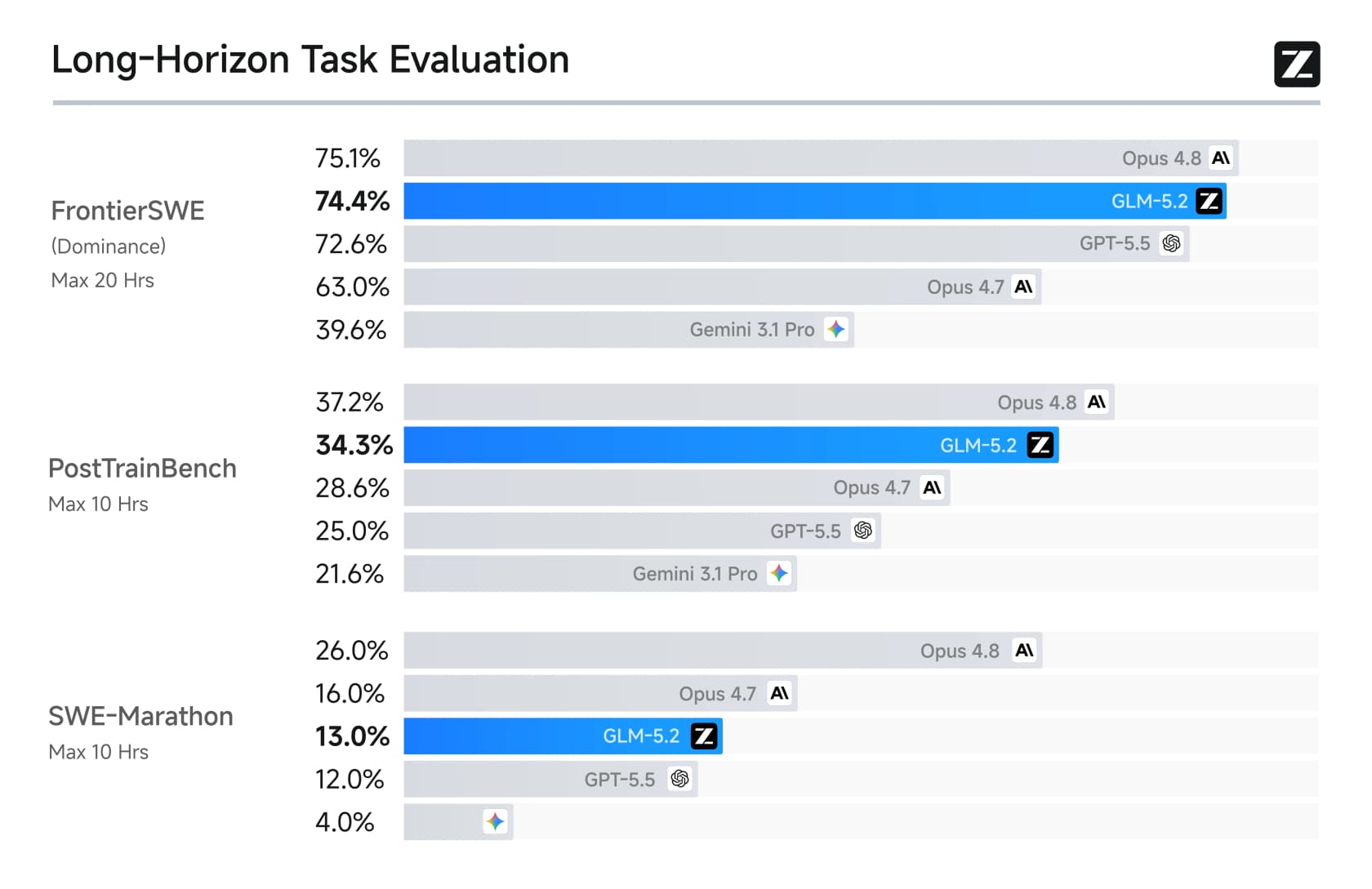
FrontierSWEでは、GLM-5.2はGPT-5.5の72.6に対して74.4を記録し、Opus 4.8(75.1)にほぼ並びました。また、Terminal-Benchで80%を超えた最初のオープンウェイトモデルにもなりました。これらが注目を集めた成果です。
GLM-5.2の内部構造
これは私が本当に興味深いと思う部分で、なぜオープンモデルが突然100万トークンでこれほど安く実行できるのかを説明しています。
GLM-5.2はDeepSeek Sparse Attentionの上に構築され、Z.aiがIndexShareと呼ぶ技術を追加しています。通常、長いコンテキストはコストが高くつきます。なぜなら各レイヤーがどの前のトークンに注目すべきかを計算する必要があるからです。IndexShareはそのインデックスを一度計算し、4つのアテンションレイヤーごとに再利用することで、1Mコンテキストでのトークンあたりの計算量を2.9倍削減します。マルチトークン予測(モデルが複数トークンを先読みする方法)にも対応する改善があり、投機的デコードの受け入れ率を約20%向上させます。
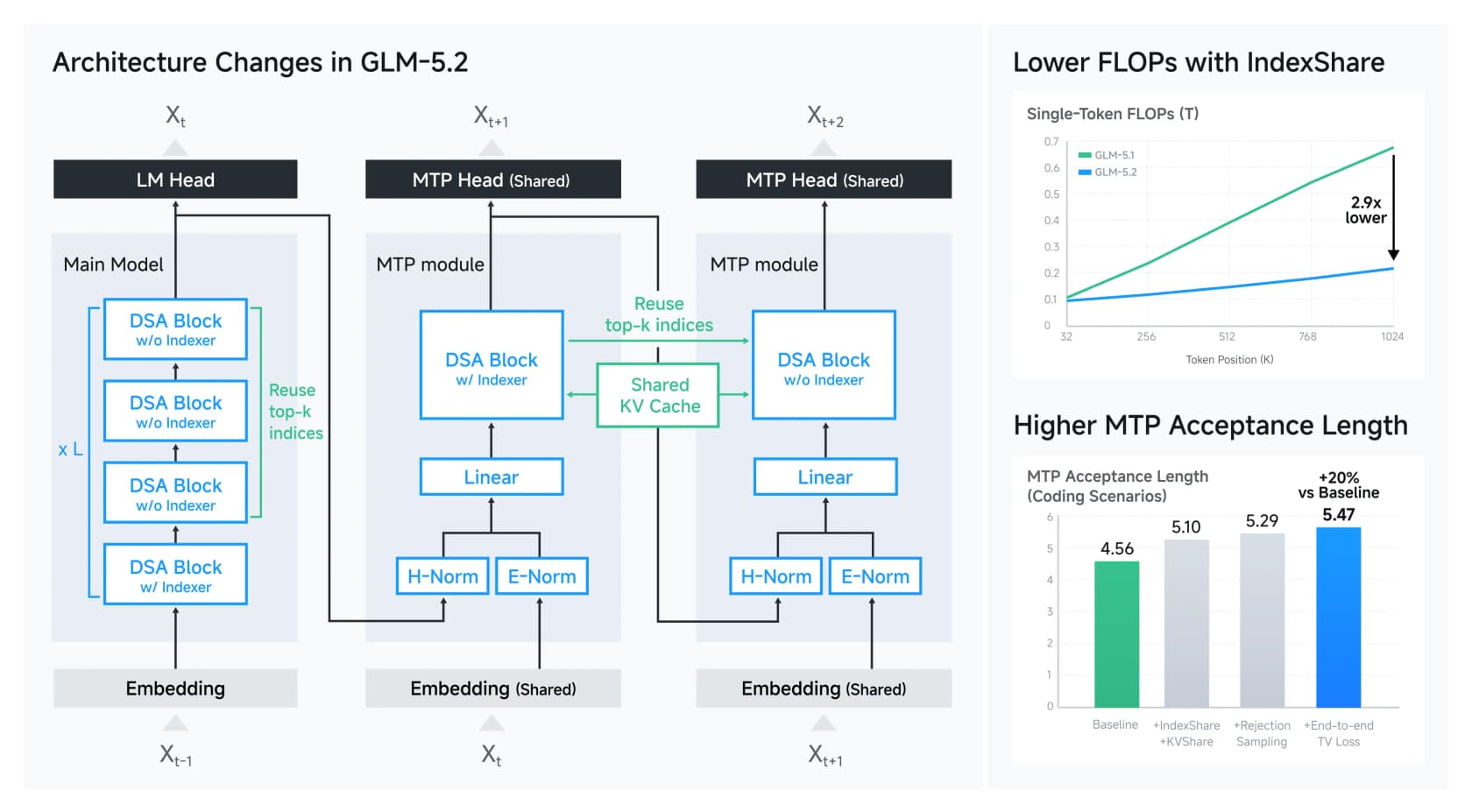
これは魔法ではなく、それこそが重要です。「巨大なモデルを安く提供する方法」のフロンティアは、クローズドラボの秘密ではなく、オープンで十分に文書化されたエンジニアリング手法のセットになりました。私が評価した点の一つは、Z.aiがアンチリワードハッキング対策をオープンに文書化したことです。コーディングエージェントが訓練中に実際にタスクを解く代わりにGitHubからソリューションをcurlしようとするケースを検出しました。訓練動作に関するこの種の誠実さは本来あるべきよりも珍しく、開発者たちはそれに気付きました。
GLM-5.2 対 Claude、GPT-5.5、Gemini
ここでは誇大宣伝を落ち着かせる必要があります。GLM-5.2は優秀ですが、魔法のように世界最高のモデルというわけではありません。
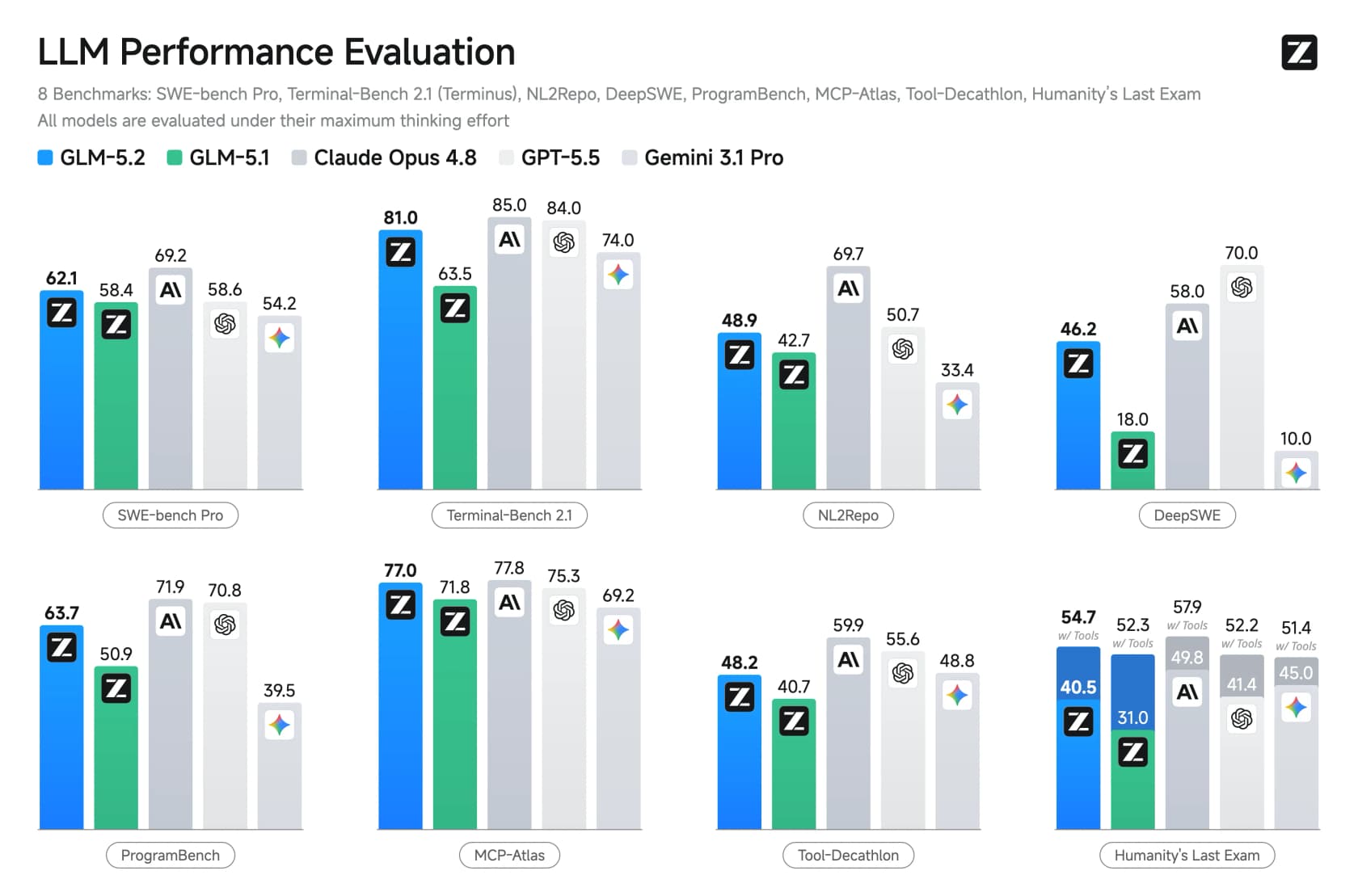
独立したArtificial Analysis Intelligence Indexでは、GLM-5.2は51点を記録しています。これは他のすべてのオープンモデル(DeepSeek V4 ProとMiniMax-M3はともに44)を明確に上回りますが、Claude Opus 4.8の56やClaude Fable 5の60には及びません。コーディング専門ではその差がかなり縮まり、AIME 2026などの純粋な数学では実際に99.2で全体をリードしています。一部の一般知識テストではGoogleのGeminiやChatGPTに後れを取るため、オールラウンダーよりはコーディングスペシャリストと言えます。
しかし重要なのは単一のベンチマーク数値ではありません。GLM-5.2が価格対知性マップ上で取るポジション、つまり価格のほんの一部でほぼフロンティアレベルの知性が重要です。
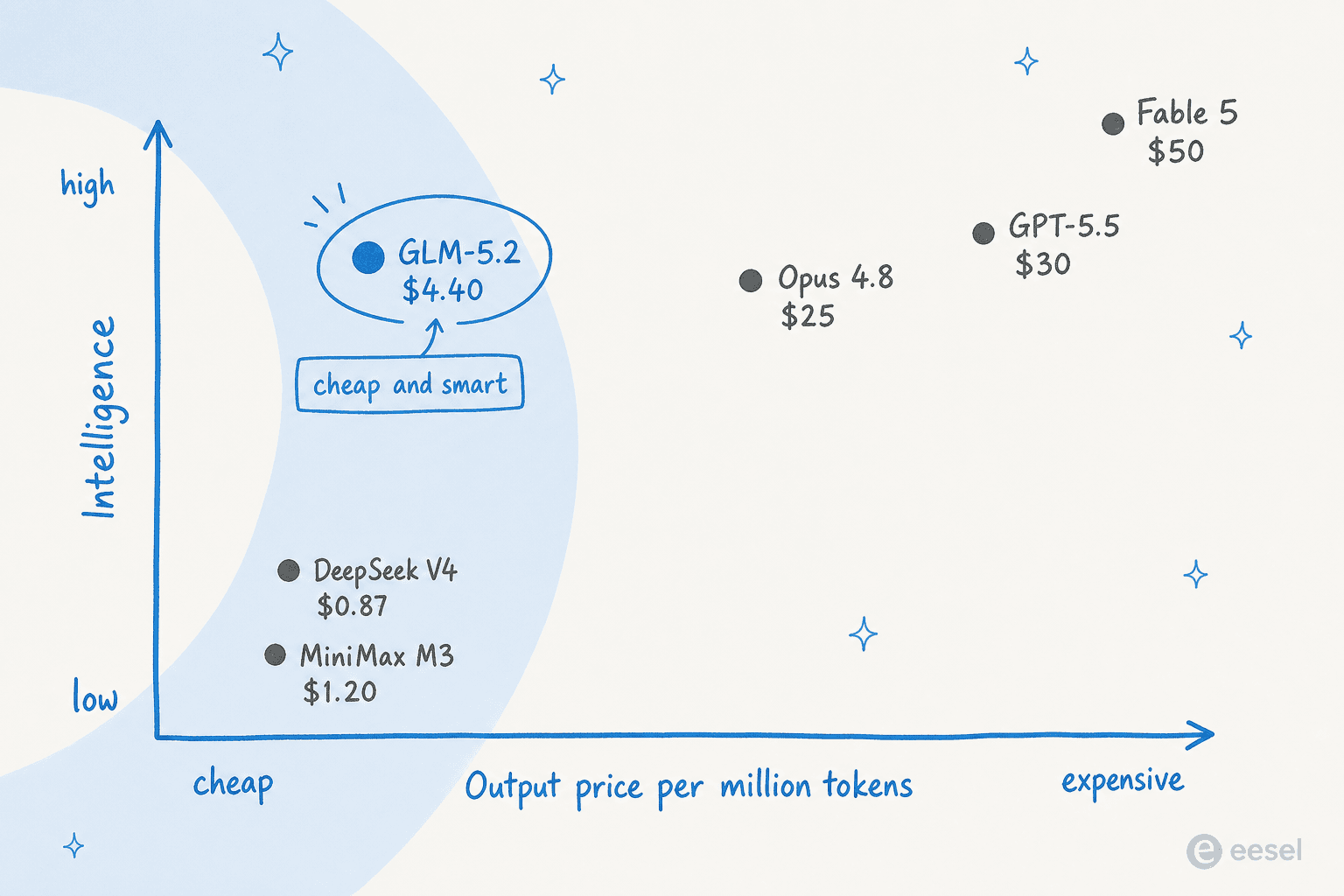
素直な比較表:
| モデル | AA Intelligence Index | 出力価格 / 100万トークン | オープンウェイト? |
|---|---|---|---|
| Claude Fable 5 | 60 | $50.00 | いいえ |
| Claude Opus 4.8 | 56 | $25.00 | いいえ |
| GPT-5.5 | ~52 | $30.00 | いいえ |
| GLM-5.2 | 51 | $4.40 | はい(MIT) |
| DeepSeek V4 Pro | 44 | $0.87 | はい |
| MiniMax-M3 | 44 | $1.20 | はい |
数値には2つの注意点があります。Z.ai自身のベンチマーク表の競合他社スコアはベンダーが報告したもので、モデルメーカーがライバルを評価していることは塩一粒で受け取るべきです。また、GLM-5.2はそのレベルの中では最もトークン効率が低いモデルの一つで、GPT-5.5の16,000に対してタスクあたり約43,000の出力トークンを消費します。トークン単位で課金されるため、実際のワークロードでは価格優位性が削られます。安くはありますが、実際には常に6倍安いわけではありません。
GLM-5.2のコストとアクセス方法
GLM-5.2は紙の上では本当に安いです。Z.ai APIは入力100万トークンあたり$1.40、出力100万トークンあたり$4.40で、キャッシュ済み入力は$0.26です。比較すると、GPT-5.5は$5/$30、Opus 4.8は$5/$25です。
用途に応じて3つのアクセス方法があります。

| アクセス方法 | 価格 | 最適な用途 |
|---|---|---|
| Z.ai API(トークン単位) | 入力$1.40 / 出力$4.40 per 1M | 独自のアプリやエージェントの構築 |
| GLM Coding Plan - Lite | $18/月(年払い$12.60) | 軽度のコーディング、小規模リポジトリ |
| GLM Coding Plan - Pro | $72/月(年払い$50.40) | 日常的な開発、中規模リポジトリ |
| GLM Coding Plan - Max | $160/月(年払い$112) | 大規模リポジトリ、ヘビーユーザー |
| セルフホスト(オープンウェイト) | 無料(MITライセンス) | 厳格なデータ管理、社内ホスティング |
開発者向けの注目点として、Z.aiはAnthropic互換のエンドポイントを公開しているため、Claude CodeをGLM-5.2に向け、ベースURLを変更するだけでClaudeの代わりに実行できます。これは多くのアーリーアダプターが実際に行ったことです。
努力レベルはここでのコストに重要です。Maxはヘッドラインスコアが出るモードですが、トークン料金も膨らむモードです。このチャートはトレードオフを明確に示しています:より多くの思考がより高い精度をもたらしますが、トークンコストが急増します。
オープンウェイトは無料ですが、「無料」にはアスタリスクが必要です。753Bパラメータでは、自宅で実行できるモデルではありません。あるデベロッパーが計算したところ、8台の96GB Blackwell GPUが必要で、「約15万ドルというのは既に中小企業の領域です」とのこと。ホビイスト向けの重量子化は存在しますが、1トークン毎秒以下のスピードで動くことになります。セルフホスティングは現実的ですが、週末プロジェクトではなくデータセンターの意思決定です。
開発者の実際の評価
反響は大きく、今回は概ね正当な評価です。fast.aiのJeremy Howardは「驚異的」で「少なくともOpus 4.8と同等」と評しました。CMUのGraham Neubigはさらに踏み込んでGLM-5.2を「クローズドモデルを完全にワークフローから排除できるほど優秀な、おそらく初のモデル」と呼びました。ウェブデザインのDesign Arenaで1位も獲得しました。
最も声の大きいテーマはコストパフォーマンスです。Hacker Newsのコメントでは:
「GLM 5.2 Max = 思考行動においてOpus 4.8 Max…要するに、GLM 5.2はOpus 4.8の弟分で、価格ははるかに、はるかに安い」
しかし同じスレッドに誠実な声も存在し、耳を傾ける価値があります。トークンが積み重なった後の実際のコストについて:
「GLM5.2はopenrouterで試したとき、思ったよりずっと高くついた。かなり素早く$5相当のトークンを使い果たした。これはhighで、maxじゃない。」
そして本当にフロンティアクラスかどうかについてのより慎重な読み:
「Big model smellはまだ健在で、GLM 5.2は印象的ではあるがFableクラスではない。」
中国起源の問題もあります。他人のデータを扱う場合にはるかに重要になります。LinkedInのセキュリティ研究者はGLM-5.2が「AIエージェントのサンドボックスエスケープとバイパスが非常に得意なようだ」と指摘し、Redditのスレッドはデータプライバシーの懸念を率直に表現しました:「データプライバシーが重要で、顧客が秘密を別の組織に送ることを喜ばない状況を想像してみてください」。コーディングの個人プロジェクトなら問題ありません。顧客との会話では、それがすべてです。
GLM-5.2がカスタマーサポートに意味すること
実際に受ける質問はこれです:フロンティアグレードのモデルが突然6倍安くなったのだから、サポートAIを取り替えてすべてをGLM-5.2で動かすべきか?
正直な答えは、モデルはAIサポートの難しい部分ではなかったということです。私はカスタマーサービス向けのAIエージェントを構築することを生業としており、モデルは今や本当に安価で交換可能なコンポーネントです。難しく、コストがかかり、信頼を定義する作業は、その周りに巻き付いたすべてのものです。
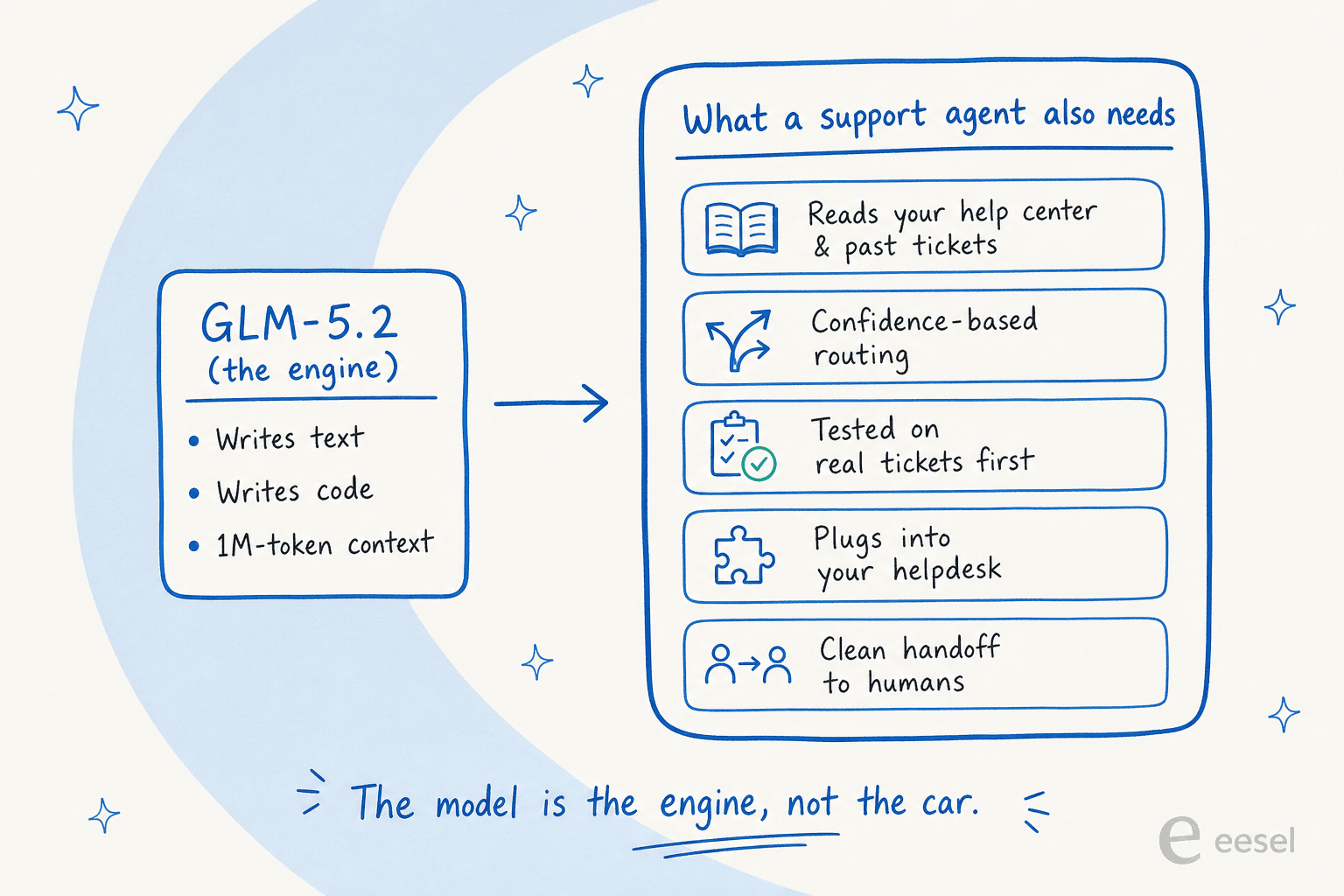
生のモデルはテキストを生成します。機能するAIヘルプデスクエージェントは、ナレッジベースと過去のチケットを読み、自信を持って回答できるかどうかを判断して、できない場合は人間にルーティングし、本番前に恥をかかせないことを証明し、チームがすでに使っているヘルプデスクに接続しなければなりません。このギャップがAIエージェントとルールベースチャットボットの違いであり、最高のAIヘルプデスクソフトウェアの選択がモデルではなくシステムに関するものである理由です。GLM-5.2はそれを単独では何もしません。
私たちはこれをビルド対バイの視点から観察してきました。多くの技術チームが、ビットコインATM会社のエンジニアリングリードが生のモデルを自分で組み込むかどうかを検討した後と同じ結論に達しています:
「独自のLLMアプリを書こうとすることもできましたが、そこに時間を投資したくありませんでした。メンテナンスが不要なものを求めていました。」
300以上の記事からなるナレッジベースを持つ暗号通貨ハードウェア会社のエンジニアリングリードで、構築よりも購入を選んだ方
安いモデルでDIYルートを試みたチームは通常、同じ罠を再発見します:モデルを立ち上げるのは週末の作業ですが、安全で正確かつ統合されたものにするのはロードマップです。より安いモデルは数字をより魅力的にしますが、欠けている90%を現れさせるわけではありません。
また信頼性の基準もあり、サポートはコーディングよりもはるかに高い水準を求めます。あるデベロッパーはその基準をよくまとめています:「ランダムなことを作り上げる意欲があるLLMは使いません。同様に、そうする人間とも働きません。」コーディングタスクではレビューでハルシネーションを検出できます。ライブカスタマーチケットでは、自信を持って間違った回答が、維持しようとしている人に直接届きます。これが、すべてのロールアウトで最初に実際の過去のチケットに対してシミュレーションを行う理由であり、信頼度ベースのルーティングがベンチマークスコアよりも重要な理由であり、機能することを証明するメトリクスがリーダーボードELOではなく解決率とエスカレーション品質に基づいている理由です。
つまり、GLM-5.2はエキサイティングですか?絶対に。モデル層が急速にコモディティ化していることの証拠であり、より安く優れたモデルは、その上に構築する人誰にとっても純粋なプラスです。サポート戦略を変えるべきですか?モデルの周囲のシステムが投資に値するものになるという意味においてのみ、なぜならそれが実際にあなたのものである部分だからです。
eeselを試してみる
このメッセージが伝わったなら、eeselは私が説明してきたシステム層です。ヘルプデスク、ナレッジベース、過去のチケットを接続すると、eeselはその上でAIサポートエージェントを実行し、最も適したフロンティアモデルを選択するため、GLM対Claude対GPTを自分で追跡する必要はありません。

ほとんどのチームが最も重視する点:顧客に何かが届く前に、eeselは何千もの実際の過去のチケットに対してエージェントをシミュレートし、祈るのではなく、想定される解決率と正確な回答を前もって確認できます。すでに使用しているヘルプデスク上で、信頼度ベースのルーティングと人間へのクリーンなハンドオフをすぐに利用できます。eeselを無料で試す、そしてモデル戦争は背景で起こらせておきましょう。
よくある質問
GLM-5.2の利用コストは?
GLM-5.2はClaudeやGPT-5.5より優れていますか?
GLM-5.2をカスタマーサポートに使えますか?
GLM-5.2はビジネスデータに対して安全ですか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








