なぜサポートQAは今、まったく異なって見えるのか
私はeeselのカスタマーサポートチームにいるため、キューの中で生活しています。古いQAの儀式はいつも気になっていました:少数のチケットをスコアリングし、メモを書き、実際に問題を引き起こすパターン(誰もが間違える方針、あるチャンネルでのトーンの問題)は何週間も後になってようやく浮かび上がる、もし浮かび上がるとしても。ほとんどのチームはサポートインタラクションの1%〜3%を手動でレビューしています。残りの97%は盲点です。
しかし、QAが変わった最大の理由は、私が過去3年以上eeselでAIエージェントがライブサポートキューに参加するのを見てきて、自信満々に聞こえるボットが静かに間違った回答を提供するのを目撃したことです。あるデンマークの車両テレマティクスチームのZendeskユーザーは早い段階でこれを経験しました:ボットは、ヘルプセンターが「すべてのモデルをサポートします」と言っていたため、データベースにないブランドに対して顧客に「はい、あなたの車種をサポートしています」と言い始めました。それはルールとして書かれていませんでした。AIはそれを推測し、自信満々に聞こえ、そして間違っていました。
その経験が、なぜ今、すべてのロールアウトを最初に過去のチケットに対してシミュレーションするのかという理由であり、「サポートQA」が何を意味するかを再定義します。今や2つの仕事があります:
- すでに起こった会話のQA(人間またはAI)——古典的なスコアカードの仕事。
- AIエージェントが回答する前後のQA——上記の自信満々な間違った回答を送らないように。
このリストのほとんどのツールは仕事1に非常に優れています。より少数が仕事2を行います。最良のスタックは両方を行い、各ツールについてどちらがどちらかをフラグ立てします。
AIサポートQAが実際にどのように機能するか
手動QAしか経験したことがない場合、AutoQAツールの仕組みをざっと見ておく価値があります。なぜなら、ここにある全てのベンダーでほぼ同じだからです。ヘルプデスクやコンタクトセンタープラットフォームを接続し、スコアカードを平易な言葉で定義し(挨拶、確認、共感、解決、コンプライアンス)、AIはすべての会話をそれに照らして読み、理由が添付されたスコアを返し、人間が見るべきリスクの高いものを表示します。
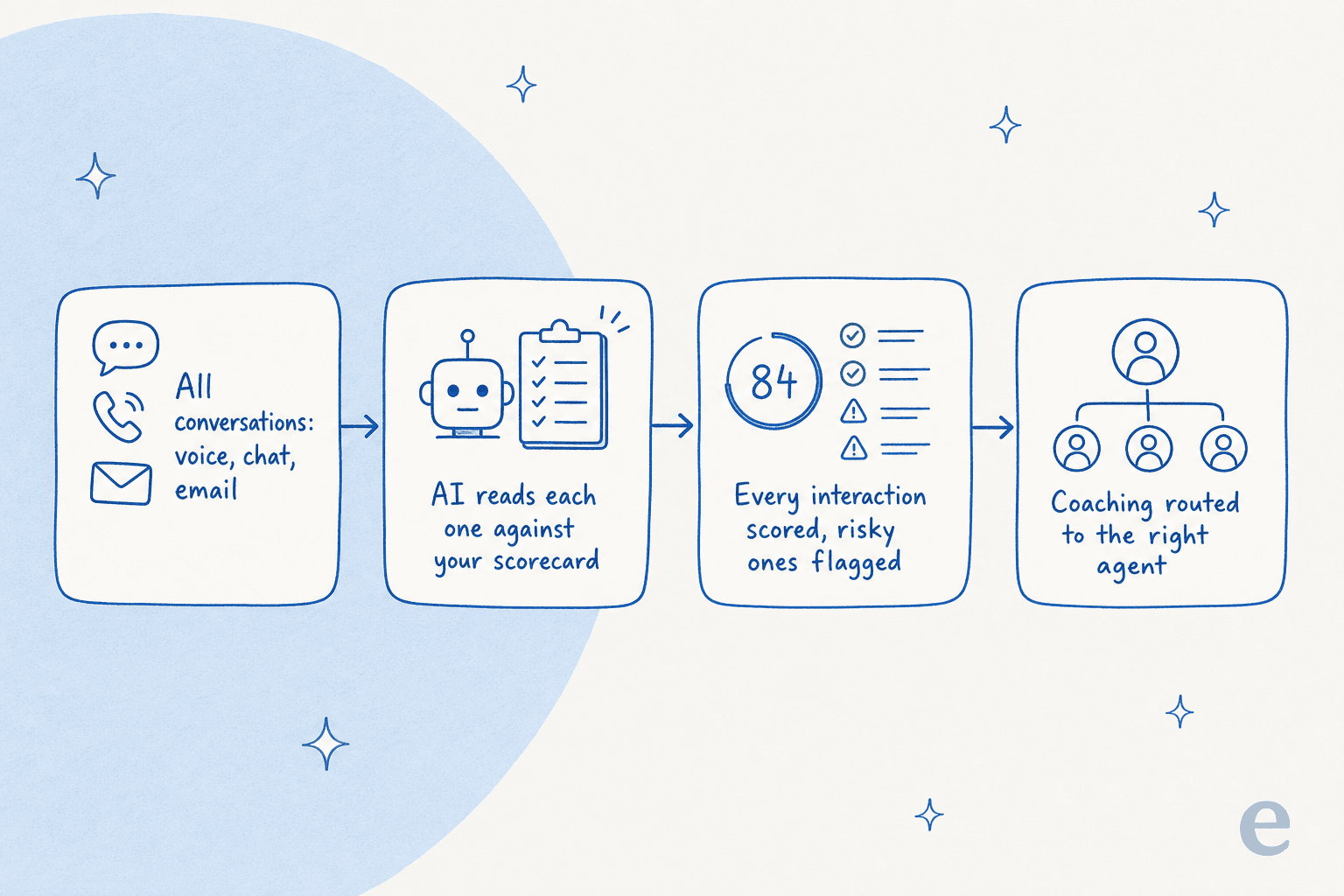
サンプリングから完全カバレッジへのジャンプは現実のものであり、最終的に信頼できるサポート指標(一貫した品質スコア、感情トレンド、エスカレーションパターン)は、抽選ではなく会話の100%に基づいている場合はるかに正直です。念頭に置いておくべきこと:自動スコアはキャリブレーションの品質によってのみ良くなります。そのため、ここのすべての真剣なツールでは、数値を信頼する前に過去のチケットでスコアリングをテストできます。
私が探したもの
自分のチームのために購入する場合と同じように重み付けしました:
- カバレッジ。 会話の100%を実際にスコアリングしているか、それとも追加のステップを持つサンプリングなのか?
- スコアカードの柔軟性。 平易な言葉で独自の基準を書き、各スコアの背後にある理由を見ることができるか?
- コーチングループ。 スコアリングは仕事の半分です。エージェントコーチングと改善のループを閉じているか?
- AIエージェントQA。 人間だけでなく、ボットの会話も評価(および事前テスト)するか?
- 価格の誠実さ。 数字を見ることができるか、それとも費用を知るためにセールスコールを受ける必要があるか?
- 適合性。 ヘルプデスクネイティブで小規模チームに優しいか、それとも500席の音声コンタクトセンター向けに構築されているか?
2026年のサポートQA向けAIツール最良の一覧
| ツール | 最適用途 | AutoQAカバレッジ | AIエージェントを評価? | 開始価格 | 評価 |
|---|---|---|---|---|---|
| eesel AI | 本番稼働前のAIエージェントのQA | 過去チケット100%のシミュレーション | はい、これが主要機能 | 0.40ドル/チケット、シート料金なし | 4.6 / 5 (G2) |
| Zendesk QA | すでにZendesk上のチーム | 100% (AutoQA) | はい(AIエージェントQA) | 約35ドル/エージェント/月(アドオン) | 4.9 / 5 (Capterra, n=23) |
| MaestroQA | エンタープライズ、深いカスタマイズ | 100% (AutoQA) | はい | 見積もり制 | 4.7 / 5 (G2, 324) |
| EvaluAgent | 中堅企業、QA+コーチング | 100% (AutoQM) | はい(ボット可観測性) | 35ドル/ユーザー/月 | 4.5 / 5 (G2, 440) |
| Loris (Contentsquare) | 大規模な会話分析 | 100% | はい(AIエージェント分析) | 見積もり制 | 4.8 / 5 (G2, 11) |
| Level AI | リアルタイムを求めるコンタクトセンター | 100% (QA-GPT) | 部分的 | 見積もり制 | 4.7 / 5 (G2, 200) |
| Playvox (NiCE) | WFMとバンドルされたQA | 100% (AutoQA) | 限定的 | 見積もり制 | 4.8 / 5 (G2, 1,163) |
| Cresta | 大規模エンタープライズ音声 | 100%(品質管理) | はい(統合スコアリング) | 見積もり制 | 4.2 / 5 (G2, 43) |
フィールドを読む一つの方法:誰であるかによってきれいに分かれています。一方はヘルプデスクネイティブで小規模チームに適したもの、他方はエンタープライズ音声とコンタクトセンター。
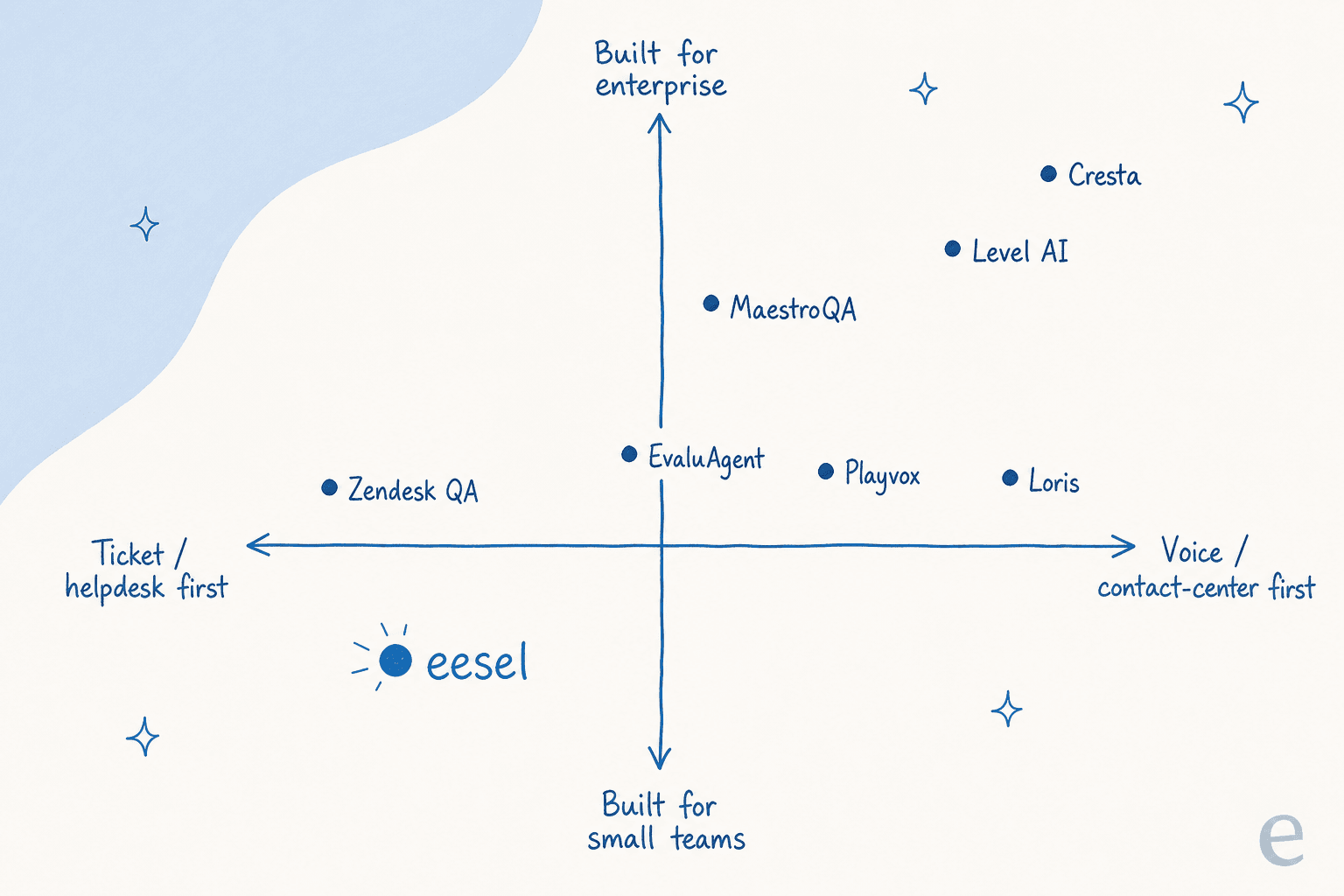
象限を見たくない場合は、同じロジックをクイックピッカーとして示します。
それでは、ツールの詳細を見ていきましょう。
1. eesel AI
最適用途: 顧客に触れる前後のAIサポートエージェントのQA。
eeselがQAリストの先頭に来る理由を率直に説明しましょう。これは従来のスコアカードツールではありません。eeselは既存のヘルプデスクに接続し、過去のチケットとドキュメントから学習し、チケットに回答するAIサポートエージェントです。ここに掲載される理由は、2026年において最も高リスクなQAがAI自身の回答に関するものであり、eeselはそれらの回答を本番稼働前にテストすることを中心に構築されているからです。
QAのために何をするか。 eeselのシミュレーションモードは、AIを数千の実際の過去チケットに対して実行し、テーマ別に分類して、AIがどのように回答したか、何を解決したか、どこでつまずいたかを正確に表示します。一人の顧客も影響を受ける前に、カバレッジと精度を確認し、ギャップを修正して再実行します。ライブ側では、信頼度ベースのルーティングにより、AIが確信していない場合は回答しません:信頼度の低いチケットは自律的な返信ではなく人間のドラフトになります。それが「あなたの車種をサポートしています」という誤りを検出したはずのガードレールです。
強み。
- ほとんどのリストが無視するもの(AIの出力自体、本番稼働前)を評価します。
- ヘルプセンターの記事だけでなく解決済みチケットから学習するため、シミュレーションはチームが実際にどのように回答するかを反映します。
- すべてのライブ回答をレビューして修正でき、それらの修正が将来の回答を改善します。
- 真にセルフサービスのセットアップで、Zendesk、Freshdesk、Gorgias、Front、HubSpot、Slack全体で100以上のインテグレーションがあります。
制限事項。
- 人間エージェント向けのスコアカードプラットフォームではありません。ルーブリックに基づいて200人の人間エージェントを評価し、キャリブレーションセッションを実施することが仕事なら、Zendesk QAやMaestroQAのような専用ツールの方が適しており、正直な答えはeeselをその横で実行することです。
- レポーティングはAIパフォーマンスとチケットテーマを中心に構築されており、正式なQAアピールやHR対応のパフォーマンスプランには向いていません。
価格設定。 このカテゴリでは珍しい、使用量ベースで透明な設定です。
| プラン | 価格 | 備考 |
|---|---|---|
| 無料トライアル | 50ドル分の無料使用 | クレジットカード不要 |
| 従量課金 | 0.40ドル/チケットから | シート料金なし、プラットフォーム料金なし、最低料金なし |
| 年間コミット | 25%引き | 年間300ドル以上/月のコミット |
| エンタープライズ | 1,000ドル/月のプラットフォーム料金+使用量 | SSO、HIPAA、BAA、専任SE |
私の見解: AIエージェントがQAする必要があるものである場合にeeselを選びましょう。あるお客様Gridwiseは、7日間のトライアル期間中に結果が表示され、最初の月にeeselがティア1リクエストの73%を解決するのを見ました。それは彼らが最初にシミュレーションし、それを有効にする前にカバレッジを信頼できたからです。人間エージェントの正式なQAも必要な場合は、以下のスコアカードツールと組み合わせてください。
2. Zendesk QA(旧Klaus)
最適用途: すでにZendeskに住んでいるチーム。
Zendesk QAは旧エストニアのスタートアップKlausで、2024年初頭にZendeskに買収され、エージェントごとのアドオンとしてプラットフォームに統合されました。サポートがすでにZendeskで実行されている場合の最も自然な選択であり、eeselのお客様はAIエージェントのパフォーマンス評価に定期的に使用しています。
何をするか。 AutoQAは、すぐに使えるカテゴリ(共感、解決)とコードなしのカスタムプロンプトベースカテゴリを使って、AIエージェントと音声を含むすべてのチャンネルのすべてのインタラクションをスコアリングします。Spotlightは自動的にチャーンリスク、エスカレーション、知識ギャップにフラグを立て、AIエージェントQAは人間とボットのスコアを並べて比較します。
強み。
- Zendeskネイティブで、サンプリングではなく100%カバレッジ。
- 平易な言葉で書くコードなしのカスタムカテゴリ。
- Klaus時代の強力な評判。ベンダーを比較したRedditユーザーの言葉:「+1 for Klaus、彼らに問題はなく、サポートは素晴らしかった。」
「サンプリング+CSATは問題のごく一部しか捉えないため、パターンが遅れて現れます。」 ——AutoQAが解決する問題を説明するサポートマネージャー、r/Zendesk
制限事項。
- すでに高価なベースの上に有料のアドオンです。Capterra レビュアーは欠点を率直に表現しています:「少し高い。」
- MaestroQAと比べ、独自ルーブリックに対するカスタマイズは浅い。
- レポーティングUIは多くのエージェントがいると遅くなります。
価格設定。 スタンドアローンのQAアドオン価格は公開されていません。コミュニティの推定では約$35/エージェント/月、バンドルされたWFM + QAパックは50ドル/エージェント/月、すべて$19〜$115/エージェントのベースプランの上に乗ります。
私の見解: Zendesk上にいる場合、これがデフォルトの選択であり良い選択です。Capterra で4.9/5(小サンプル、n=23)の評価を受けています。積み重なったアドオンコストを予算に入れ、事後に会話をスコアリングするのではなく、ボットを事前テストしないことを覚えておいてください。
3. MaestroQA
最適用途: 深く、透明で、カスタマイズ可能なスコアリングを求めるエンタープライズチーム。
MaestroQAは2017年にコンタクトセンターQAツールとして始まり、「会話データプラットフォーム」として再ポジショニングし、Etsy、DraftKings、Stitch Fix、Brexのサポート組織で使用されています。エンタープライズ寄りの立ち位置にあり、それに相応しい機能を持っています。
何をするか。 AutoQAはチケットの100%を分析し、判断が重要な場所に人間レビュアーを明示的に誘導します。際立っているのはAIプラットフォームで、ルールを記述し、実際のチケットでテストし、起動前に理由を確認できるプロンプトからメトリクスへのエンジンです。「ブラックボックスツール」に対抗するものとして位置付けられています。GPTを活用したルートコーズ分析とAIキャリブレーションも搭載しています。
強み。
- 深いカスタマイズ性。複数の企業で使用したサポートオペレーターは、「高度なカスタマイズが可能」であり、「データ駆動型メトリクスを持つ大規模な環境」に適していると述べています。
- 透明で制御可能なスコアリング(理由が見える)。
- 強力なZendesk統合と16以上のコネクタ。
制限事項。
- 見積もり制で高価。G2は知覚コストを最高の「$$$$$」バンドとしてマークしており、繰り返される欠点は「AI機能は追加購入が必要でコストを大幅に押し上げる」というものです。
- 約3ヶ月の実装期間;小規模チームには負担が大きい。
「私はいくつかの会社でMaestroを使用し、概ね満足しています...高度なカスタマイズが可能です。彼らの新しいAIベースの機能はある意味興味深いですが、実際にどれほどうまく機能するかは言えません。」 ——Brosenjew、r/Zendesk
私の見解: 自分のルーブリックを所有し、すべてのスコアの背後にある理由を見たい真剣でリソースが豊富なQAチームのための選択です。324件のG2レビューで4.7/5の評価を受けています。小規模チームにはやり過ぎと感じ、セールスコールなしでは価格を確認できません。
4. EvaluAgent
最適用途: 実際に見ることができる価格設定でQAとコーチングを求めるミッドマーケットチーム。
EvaluAgentは、「すべてのエージェント(人間とAI)にわたる完全な可視性」を約束するイギリス発のQAと会話インテリジェンスプラットフォームです。このカテゴリでは珍しく概算価格を公開しているツールで、それを評価しています。
何をするか。 AutoQMは各スコアに理由を付けるSmartScore AIラインアイテムで、音声、チャット、メール全体のすべての会話を自動的にスコアリングします。ブレンドスコアカードは自動チェックと人間の観察を混合し(「AIが定型的なものを処理し、人間が判断を処理する」)、コンテキストエンジンには本番稼働前にアーカイブされた会話でスコアリングの変更を試すテストコンソールがあります。AIエージェント可観測性はハルシネーション検出を含む、あらゆるベンダーのボットを知識ベースに対して採点します。
強み。
- カテゴリで最も完全なコーチングループの一つ:1対1、HR対応プラン、ゲーミフィケーション、エージェント異議申し立て。
- 真に透明な価格設定とすべてのティアに専任CSM。
- 強力なコンプライアンス体制(SOC 2 Type II、ISO 27001、GDPR、HIPAA)、規制業種に適しています。
制限事項。
- スコアカードの設定が摩擦ポイントです。G2レビュアーの主な不満:「スコアカードを設計するために必要な時間と明確さ...AIアシストのスコアカードビルダーを改善すべき。」
- G2によると、UIは初心者に学習曲線がある。
価格設定。 公開されており、シートあたり。
| プラン | 価格 | 対象 |
|---|---|---|
| AutoQM & 改善 | 35ドル/ユーザー/月から | 人間エージェント:自動スコアリング+コーチング |
| AutoQM+会話インテリジェンス | 65ドル/ユーザー/月から | 感情、インテント、予測的VoCを追加 |
| AIエージェント向けAutoQM | 0.05ドル/会話から | ボット品質スコアリング |
| AIエージェント向けフルバンドル | 0.13ドル/会話から | ボットQA+会話インテリジェンス |
私の見解: ミッドマーケットチーム向けの専用スコアカードツールの中で私のお気に入りです。440件のG2レビューで4.5/5の評価を受けており、コーチングの深さは本物で、実際に予算を立てることができます。スコアカードの設定には時間を計画してください。
5. Loris(現在はContentsquare Conversation Intelligence)
最適用途: 大規模な会話分析と顧客の声。
Lorisには知っておく価値のある独特の歴史があります:Crisis Text Lineの営利目的のスピンオフとして始まり、2022年に注目のプライバシー論争になり、2025年にContentsquareに買収されました。現在はContentsquareの会話インテリジェンスラインとして提供されています。
何をするか。 自動化されたQAはすべての会話を評価し、重要なことに、スコアが虚栄の数字にならないように、繰り返しの連絡やエスカレーションなどの実際の成果に品質シグナルを結びつけます。会話インサイトはインテントと時間の経過に伴う感情の変化を表面化し、AIエージェント分析はボットの封じ込め、転送、放棄を追跡します。
強み。
- レビュアーが挙げる分析の深さとすぐに使えるインテントタグ付け。
- 傑出した実装とサポートチーム(G2で最も一貫した称賛)。
- QAをルーブリックの合格率ではなく、成果に結びつける。
制限事項。
- 感情は完璧ではありません。G2自身の要約は、AIが「顧客の感情を常に正確に表現するとは限らない」ことをフラグ立てしており、これは自動スコアリングを売りにするツールにとって重要です。
- 現在は独立した専用QAベンダーではなく、より大きな分析スイートの機能です。
- 見積もり制、エンタープライズ志向、そして小さなG2サンプル(11件のレビュー)はクラウドバリデーションを困難にします。
私の見解: QAと並んで会話分析とVoCを求めており、Contentsquareエコシステムへの投資に問題がない場合は強力な選択肢です。G2で4.8/5の評価ですが、少ないレビュー数と買収による変化は実際の考慮事項です。
6. Level AI
最適用途: セマンティックAutoQAとリアルタイムアシストを求めるコンタクトセンター。
Level AIは「カスタマーエクスペリエンスのインテリジェンスとオーケストレーション層」として自らを位置付け、キーワードマッチングではなくセマンティック理解を使用して、音声、チャット、メール全体のインタラクションの100%を分析します。
何をするか。 QA-GPTエンジンは独自のデータでトレーニングされたLLMを使用して、主観的な項目を含むスコアカード基準の90%以上を評価し、証拠を裏付けとした透明なスコアを提供します。エージェントの画面録画、リアルタイムAgentGPTアシスト、コーチングモジュールと組み合わせています。
強み。
- セマンティックNLUが正確なフレーズだけでなく、主観的なルーブリック項目をスコアリング。あるオペレーター:「私たちは通話の1〜2%を手動でスコアリングすることから、100%をスコアリングするようになりました。」
- リアルタイムアシストと強力な編集機能を持つ画面録画、規制業界で評価されています。
制限事項。
- スコアリングの精度はまだ成熟中——G2で最も一般的な不満。あるレビュアーは、エージェントが明確に準拠していた場合でも、システムが「正確な単語を使用しなかったためにエージェントを減点する可能性がある」と述べています。
- 404エラーが出る公開価格ページがある見積もり制と、約3ヶ月の実装期間。
- コール/コンタクトセンター向けに構築されており、小規模なチケットベースのチームには重すぎる。
「チームにとってQAが有意義になりました。設定と使用が簡単でした。」(欠点:「プロンプト設定はちょうど良くなるまで少し調整が必要です。」) ——認証済みレビュアー、G2のLevel AI
私の見解: 200件のG2レビューで4.7/5の評価を受けた強力なコンタクトセンターの選択肢です。リアルタイム層が差別化要因です。スコアリングを調整し、数字のためにセールスに話す準備をしてください。
7. Playvox by NiCE
最適用途: フルワークフォーススイートにバンドルされたQAを求めるチーム。
Playvoxはデジタルファーストのワークフォースエンゲージメントスイート(QA、WFM、コーチング、学習、VoC、ゲーミフィケーション)で、2024年10月にNiCEに買収され、CXoneスタックに統合されています。
何をするか。 AutoQA(Prodsight買収上に構築)は感情ベースのスコアリングでQAをインタラクションの100%に拡張し、WFMとコーチングと並んで一つのスイートに存在します。Zendesk、Salesforce、Freshdesk、Kustomer、Help Scoutに接続します。
強み。
- 幅広さ:一つのプラットフォームにQA、WFM、コーチング、学習、ゲーミフィケーション。
- 強力なネイティブインテグレーション(20以上)とレビューでの使いやすさの主要テーマ。
- 非常に高い評価:1,163件のG2レビューで4.8/5。
制限事項。
- 買収後の不確実性。NiCEはWFM角度でリードし、スタンドアローンサイトは空洞化され、ロードマップは流動的。
- G2の欠点は弱いレポーティングと限られたカスタマイズをフラグ立て。
- 見積もり制、無料バージョンなし、小規模チームには重い広いスイートの重さ。
私の見解: 特にNiCE CXoneに向かっている場合、フルワークフォース管理スタックの一部としてQAを求める場合に最も意味があります。集中した、独立した進化のQAツールとして、1年前より不確かです。
8. Cresta
最適用途: リアルタイムコーチングを求める大規模エンタープライズ音声オペレーション。
Crestaは2017年にスタンフォードAIラボからスピンアウトしたエンタープライズCX AIプラットフォームで、$2億8000万以上を調達し、United Airlines、Marriott、Verizonなどの大規模音声オペレーションにサービスを提供しています。十分な資金があり、スケールされており、かつエンタープライズ向けです。
何をするか。 Cresta品質管理は生成AIで会話の100%を自動スコアリングし、エージェントの行動をビジネス成果に相関させ、人間とバーチャルエージェントの両方を一つのルーブリックでスコアリングします。その特徴はリアルタイムエージェントアシストで、通話後だけでなく会話の途中でエージェントをライブでコーチします。
強み。
- 通話後だけでなくリアルタイム。Holiday Inn Club Vacationsのディレクター:「Crestaは即時です...それは瞬時のコーチングなので100%優れています。」
- 定量化された結果を伴う100%カバレッジ。OportunのVP:「サンプリングアプローチから100%のQAに移行し」、QAチームの作業負荷を50%削減しました。
- フォレスター会話インテリジェンスウェーブのリーダー、Q2 2025に指名されました。
制限事項。
- エンタープライズ専用。Crestaの自社ICPは「250名以上の従業員」と「2億5000万ドル以上」の売上高を指定し、中小企業は理想的でないとしています。
- 推定するためにもセールスサイクルが必要な不透明なモジュールベースの価格設定。
- インテグレーションはサービス主導。Redditのある元従業員は、それらが「すべてプロフェッショナルサービスチームによって管理されている」と述べています。
私の見解: 大規模な音声コンタクトセンターを運営し、ライブコーチングを求める場合、Crestaは43件のG2レビューで控えめな4.2/5の評価にもかかわらず真のリーダーです。最新のチケットベースのヘルプデスクや小規模チームには、形が合わず予算も合いません。
では、実際にどれを選ぶべきか?
このスペースに住んだ後、決断は「どのツールが最良か」より「何をQAするか」です:
- ヘルプデスクで人間エージェントをスコアリングしている場合: Zendesksを使っているならZendesk QA、透明な価格設定とコーチングが欲しいならEvaluAgent、エンタープライズでルーブリックを所有したいならMaestroQA。
- 大規模な音声オペレーションを運営している場合: リアルタイム層にはCrestaかLevel AI、WFMとバンドルしたい場合はPlayvox。
- キューにAIエージェントを配置している場合: AI自体のQAから始めましょう。それが自信満々な間違った回答を送る可能性が最も高い会話であり、スコアカードツールが顧客がすでにそれを見た後にしか検出できないものです。
最後のポイントが最も強調したいもので、チームが落ち込む落とし穴だからです。このリストで最高のスコアカードプラットフォームを購入しても、AIエージェントが顧客に間違ったことを伝え続ける可能性があります。なぜならQAは返信後に行われるからです。解決策は、ボットが話す前にQAすることです。
AIエージェントQAにeeselを試す
AIサポートエージェントをデプロイしている場合、ここでeeselはリストでの地位を証明します。顧客がそれらを見た後にAIの回答を採点するのを待つのではなく、eeselのシミュレーションモードは実際の過去チケットの何千ものものを再生し、本番稼働前にAIがどのように回答したか、何を解決したか、どこで見逃したかを正確に表示します。そして信頼度ベースのルーティングは確信がない場合に回答することを防ぎます。

数分で既存のヘルプデスクに接続し、解決済みチケットから学習し、クレジットカードなしで無料でお試しいただけます。AIサポートについての本当の心配が「間違って回答するか」であれば、それはまさにeeselが解消するために構築された心配です。eeselを試す。
よくある質問
2026年のカスタマーサポートQAに最適なAIは何ですか?
AIサポートQAソフトウェアのコストはどのくらいですか?
AIはサポートの会話の100%を本当にスコアリングできますか?
AIサポートQAとAIエージェントのQAは違いますか?
ZendeskにはAI品質保証が内蔵されていますか?
本番稼働前にAIサポートエージェントのQAを行うにはどうすればよいですか?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.