フィンテック向けAI知識ベース:チームが信頼できるものを構築する方法
Riellvriany Indriawan
Katelin Teen
最終更新 June 19, 2026

要約
フィンテック向けAI知識ベースとは、AIが回答できるようにしたサポート知識ベースですが、金融事業が実際に必要とするガードレール付きのものです:承認済みソースに根拠付けられた回答、処理前に除去される個人情報、すべての返信への引用、そして監査員が読める監査証跡。速さは簡単な部分です。正確であることが仕事のすべてです。
多くのチームが陥る罠は、汎用のAI知識ベースを購入し、ヘルプセンターに向けて解き放つことです。規制された業界では、それが誰かのお金について自信満々な誤った回答を生み出す原因になり、遅い回答よりはるかに悪いことです。解決策は構造的なもので、より良いプロンプトではありません:ソースを限定し、信頼度でルーティングし、実際の顧客に触れる前に自分の過去のチケットで証明することです。
構築すべき内容の短縮版として:承認された知識のみを与え、引用させ、不確かなものは人間に送り、試験前(後ではなく)にセキュリティボックス(EU居住、DPA、個人情報編集、データでのトレーニングなし)を確認してください。eesel AIのようなツールはこれをすぐに実現しますが、以下の原則は使用するツールに関わらず適用されます。
フィンテック向けAI知識ベースとは実際何か
単純なナレッジベースは人間が検索するヘルプ記事の集まりです。AI知識ベースはその集まりの上にモデルを置き、顧客やエージェントが自然言語で質問して10個のリンクではなくドキュメントから引き出された回答を得られるようにします。内部的には通常検索拡張生成です:システムがセマンティック検索で知識から最も関連性の高いパッセージを取得し、モデルがそこから回答を書きます。
フィンテックでは、同じ仕組みがはるかに大きな重みを運びます。ECサイトでの誤った回答は怒った顧客です。失敗した振込、カードの凍結、KYCの保留、手数料が適用されるかどうかについての誤った回答は、コンプライアンスインシデント、チャージバック、または規制当局の質問です。そのためフィンテックグレードのAI知識ベースは同じ基本的なアイデアに4つの追加タスクを付け加えます:承認したソースからのみ回答し、センシティブなデータを編集し、引用で仕事を示し、すべての返信を記録して何が言われ、なぜそうなったかを再構築できるようにします。
サポートキューで働いていると、その違いはチケットごとに感じられます。汎用版は「役に立った聞こえたか」に最適化します。フィンテック版は「誰かに聞かれたときにこの回答を守れるか」に最適化します。
汎用のAI知識ベースがフィンテックで失敗する理由
私が最も考えるフェイルモードです。初期に、AIがサポートしていないものをサポートしていると顧客に自信を持って伝えるのを見ました。ヘルプセンターに「すべてのモデルをサポートしています」と書いた人がいたためです。その背後にいたチーム、B2B車両テレマティクスサポートグループが月数百チケットから数千に拡大中で、初期のセットアップを「最初は試行錯誤」と表現しました。AIは壊れていませんでした。汎用知識ベースが命じることを正確に行っていました:ドキュメントを信頼し、確信を持って聞こえる。
その同じ行動をフィンテックに移してみましょう。ドキュメントには「振込は即座に決済される」とありますが、実際には国内の確認済みアカウントでの振込を意味しています。汎用のAI知識ベースは顧客に国際振込が即座に決済されると伝え、苦情が来たときに初めて気づきます。核心的な問題は、汎用セットアップには「確かでないので回答すべきではない」という概念がないことであり、その謙虚さが規制されたサポートで最も重要な特性です。
経済的な側面もあります。よく聞くチームは通常、繰り返しの簡単に答えられる質問(「明細はどこですか」「なぜ請求されたのか」「2FAをリセット」)に溺れており、本当に難しいものがその後ろに積み重なっています。ここでのAIの約束はチームを置き換えることではありません。安全なTier-1の質問でのチケット量を削減して、人間が実際に判断が必要なケースに注意を向けられるようにすることです。しかしそれは両者の間の線を信頼する場合にのみ機能し、これが根拠付けとルーティングに戻ることになります。
フィンテックグレードのAI知識ベースの構成要素
シンプルに言うと、規制された顧客の前に置ける知識ベースには4つの層があり、どれか一つをスキップするとチームが痛い目を見ます。
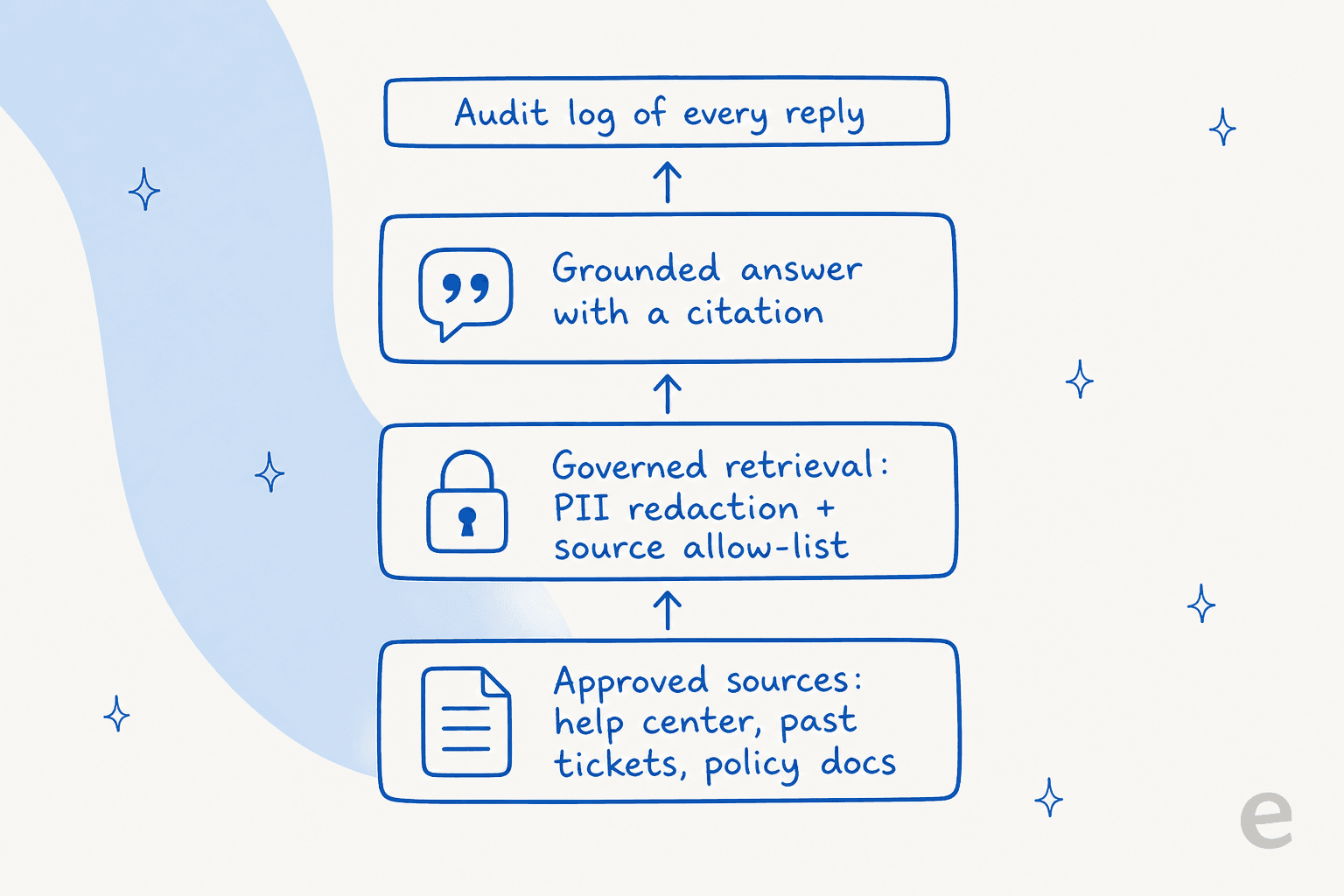
- 承認済みソース。「インターネット全体」でも「Confluenceのすべて」でもありません。厳選されたセット:ヘルプセンター、解決済みの過去のチケット、内部ポリシードキュメント、そしてコンプライアンスチームが承認する特定のNotionまたはGoogle Docsページ。最大の精度レバーは解決済みチケットから学ぶことです。ヘルプセンターのコンテンツだけでなく、そこに実際の承認された回答があるからです。
- **管理された取得。**質問と回答の間には、個人情報(カード番号、アカウント番号、パスワード)を除去し、ソース許可リストを適用する層があります。モデルが生の機密データを見ることも、承認していないドキュメントを取得することもありません。
- **引用付きの根拠ある回答。**すべての返信は引用元のソースに戻ります。ある法律テック創業者が自分の規制された設定について言ったように、「ソースの正確なガードレールを設定でき、常に透明な引用を提供する」。その引用が「信じてください」を「自分で確認してください」に変えます。
- **すべての返信の監査ログ。**誰が質問し、AIが何と答え、どのソースを使用し、人間がレビューしたかどうか。これは監査員やリスクチームが気にする層であり、汎用ツールが静かに省略する層です。
通常の知識ベースは最初の層を提供します。フィンテック向けは4つ全て必要であり、優れたAI知識ベースツールはそれらをデフォルトとして扱い、後で発見するエンタープライズアップセルではありません。
作り話をせずにチケットに回答する方法
これが玩具と実際にデプロイできるものを分ける部分です。メカニズムは信頼度ベースのルーティングであり、以前の「すべてのモデルをサポート」の問題への直接の回答です。
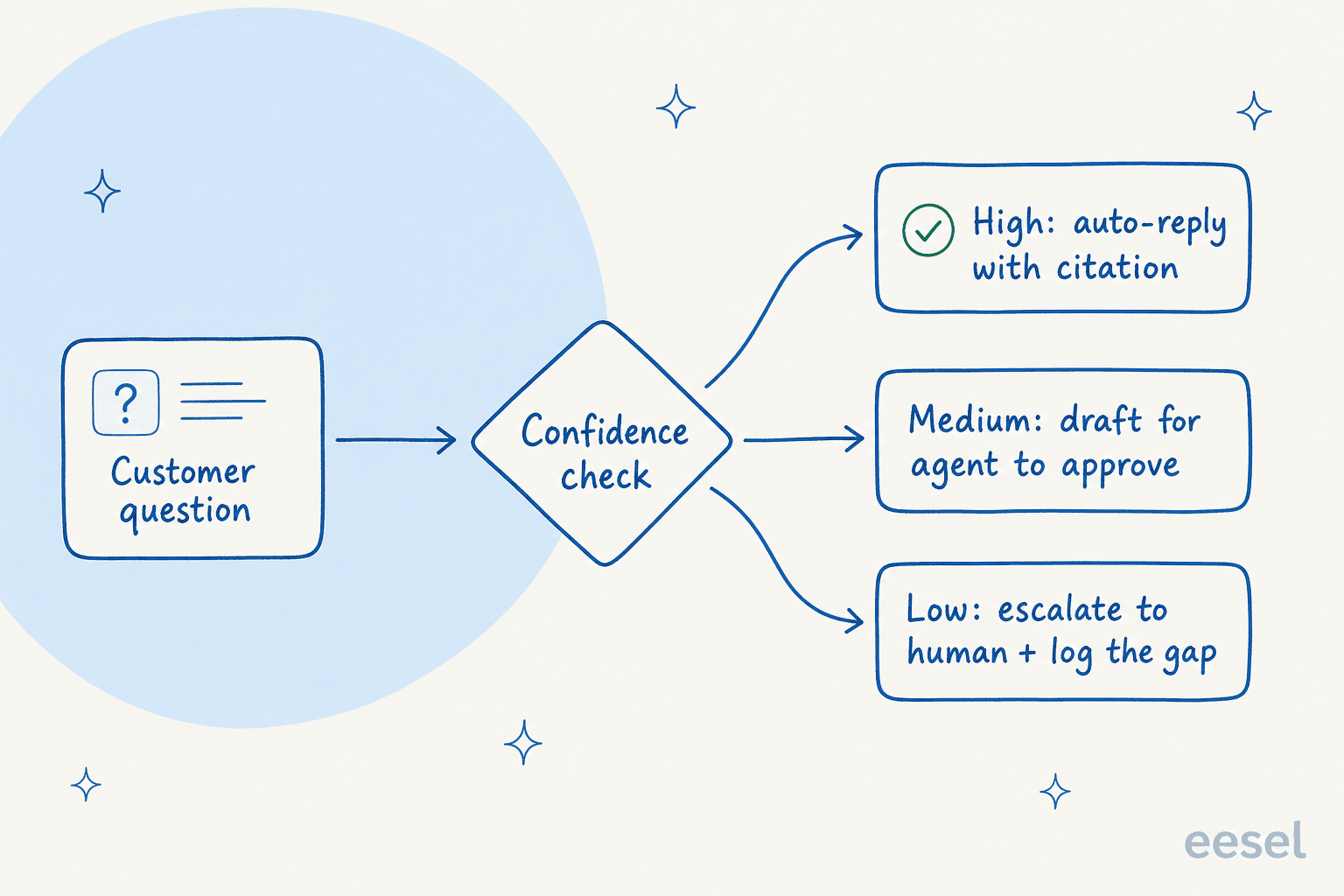
質問が来ると、システムは承認済みの知識がそれをどれだけカバーしているかをスコアリングします。明確なソース付きの高信頼度?引用を添付して直接回答できます。中程度?返信の下書きをして、送信前にエージェントが承認するために残します。低信頼度、または完全に封鎖したトピック(紛争、アカウント閉鎖、法的に重い内容)?推測しません。チケットを人間に渡し、後で教えるかどうか決められるようにギャップを記録します。
私が聞いた中で最も的確な表現は、DTCサポートリードが実際にAIに求めていたことを説明したものでした:「自信を持って対応できるチケットだけを処理し、他のものはすべてそのままにするAIが必要だ。」これが一文での全哲学であり、フィンテックでは二倍重要です。すべてを自動化しようとしているのではありません。安全なスライスを完璧に自動化し、残りをきれいにルーティングしようとしているのです。
これがサポートでの幻覚防止がより賢いモデルよりも規律に関係する理由です:回答を根拠付け、引用を要求し、システムに「わかりません」と言う許可を与える。

セキュリティとコンプライアンス:実際に取引を成立させる部分
ほとんどの業界では、セキュリティは最後のチェックボックスです。フィンテックでは最初の会話であり、紙の上では素晴らしく見える取引を潰します。ツールにSOC 2がない、規制されたビジネスの部分にHIPAA/BAAがない、または内部ISO審査を通過できないため、購入者が去るのを見てきました。これらはソフトな好みではなくハードゲートであり、そうでなければ強力なカスタマーサポート自動化プロジェクトを沈没させます。
したがって、AI知識ベースに惚れ込む前に、以下について明確な回答を得てください:
- **データはどこに保存され、どこに行くか?**EUの顧客にサービスを提供する場合はEUデータ居住、署名済みDPA、そしてあなたの顧客データが誰かのモデルのトレーニングに使用されないという明文化された保証。参考として、eeselはアカウントごとにデータをサイロ化し、基礎となるモデルは不正使用監視のみを目的として最大30日間保持し、データでのトレーニングはありません。
- **個人情報の取り扱い。**フィンテックのチケットはカード番号とアカウントの詳細で溢れています。処理される前に編集が行われ、カスタム保持ルールが必要です。これはeeselが金融および医療クライアント向けに特別に行うことであり、標準的な保持では不十分な場合です。
- **認定資格自体。**関連する場合はSOC 2、ISO 27001、GDPR、HIPAA/BAA。マーケティングページのロゴを信頼するのではなく、現在のステータスを書面で提供者に求めてください。認定が「進行中」の場合、調達目的では未完了として扱ってください。
リスクチームを納得させる信頼性のポイントは再び監査ログです:AIが何を言い、どの承認済みソースを使用したかを正確に示すことができれば、「AIが処理した」は怖い文ではなくなります。
キュー全体に賭けずに導入する方法
間違いは初日にすべてのチケットタイプでAIをオンにすることです。安全な方法は、まず現実に対して証明することです。ここでシミュレーションが役立ちます。
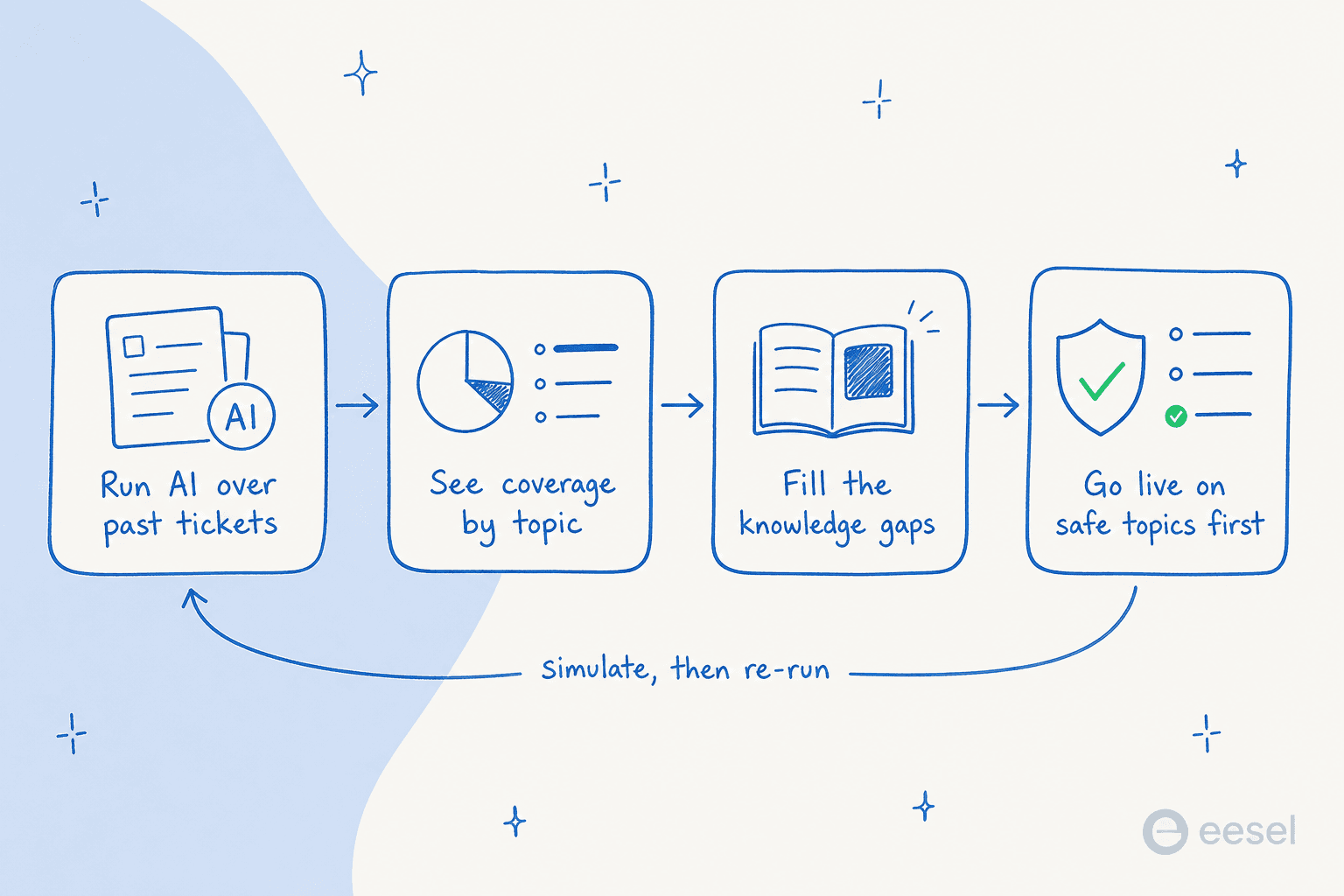
何千もの過去のチケットでAIを実行し、トピック別に分類して何を言っていたかを確認します。カバレッジが強い(明細の質問、パスワードリセット)場所と薄いまたはリスクの高い場所(紛争や制限に触れるもの)を正確に確認できます。明らかなギャップを埋め、リスクの高いトピックを封鎖し、その後初めてライブ開始します。信頼できるカテゴリから始めて、そこから広げます。変更のたびにシミュレーションを再実行して、影響を推測しないようにします。
これが正しく行われたときの成果は現実的で迅速です。あるチームでは、eesel AIが最初の月にTier-1リクエストの73%を解決し、7日間のトライアルで結果が現れました。
規模について言えば、ドイツのレンディングマーケットプレイスSmavaは、月10万件以上のドイツ語チケットを処理する完全自動化されたZendeskエージェントを運営しており、eeselによると、大手決済会社はドキュメント全体で回答を探すだけで最大80%の時間節約を報告しています。これらはフィンテックの数字であり、フィンテック企業からのものです。なぜなら根拠付けとルーティングの規律がまさに規制されたサポートに必要なものだからです。まだビジネスケースを構築している場合は、目標を設定する前にAIがサポートでどれだけ節約できるかを読む価値があります。

知識ベースを陳腐化させない方法
フィンテックの知識ベースはほとんどのものより速く陳腐化します。手数料、ポリシー、製品ルールが変わり、ドキュメントが遅れるからです。静的な知識ベースは誤った回答のスローモーションの源であり、より良いナレッジマネジメント設定がそれを自己更新するものとして扱う理由です。
解決策は自己管理する知識ベースです。AIは回答できなかったトピックにフラグを立て(それらが実際のコンテンツギャップであり、顧客が質問する頻度でランク付けされています)、人間が承認するためにそれらを埋める記事を下書きし、同じミスが繰り返されないようにエージェントの修正から学ぶべきです。それをチケットトリアージ、サポートタグ付け、テーマ分析と組み合わせると、知識ベースは最後の監査以来誰も開いていないフォルダではなく、顧客が実際に混乱していることの生きた写真になります。また、ギャップがまだ小さい間に閉じられるため、顧客サービス全体を静かに改善します。

フィンテックサポートでeeselを試す
まさにこの規律に基づいて構築されたAIヘルプデスクエージェントをお探しなら、eeselは検討に値します。初日から過去のチケットと承認済みドキュメントから学習し、信頼度でルーティングして確信があるものだけを自動回答し、金融クライアント向けにカスタム保持付きで個人情報を編集し、1人の顧客もそれを見る前に履歴全体でシミュレーションできます。
Zendesk、Freshdesk、Salesforce、その他のスタックと統合し、価格はシート料金なしでチケットあたり$0.40から始まり、量が急増してもコストは予測可能です。

eeselを無料で試して、実際のチケットの一部に向けて、コミットする前に解決率を自分で確認できます。規制されたサポートでは、「語らず、示せ」が唯一のカウントされる基準です。
よくある質問
フィンテック向けAI知識ベースとは何ですか?
AI知識ベースがアカウントや支払いについて誤った回答をしないようにするにはどうすればよいですか?
フィンテック向けAI知識ベースはコンプライアンスに十分安全ですか?
フィンテック向けAI知識ベースのコストはどのくらいですか?
AI知識ベースは複数言語でのサポートに対応できますか?
フィンテック知識ベースが陳腐化しないようにするにはどうすればよいですか?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.








