カスタマーサポートにおけるAIセンチメント分析:仕組みと限界
Riellvriany Indriawan
Katelin Teen
最終更新 June 21, 2026
まとめ
AIセンチメント分析はサポート会話を読み取り、顧客の感情を通常「非常にポジティブ」から「非常にネガティブ」の段階的スケールでスコアリングします。サーベイに回答する小さな割合ではなく、すべてのチケットを対象とします。適切に実装すれば、本物の運用シグナルとなります:最も怒った顧客チケットをキューの上位に、解約前にリスクのあるアカウントにフラグを立て、どのやり取りがコーチングを必要とするかをマネージャーに伝えます。素朴に実装すれば、すべての問題チケットで誤発火し、実際に去ろうとしている落ち着いた皮肉な顧客を見逃します。
持ち帰ってほしいこと:センチメントスコアは、それに紐づくアクションと同じ価値しかありません。Zendesk、Freshdesk、Dialpad、Sprinklrなどのベンダーはすべて感情を適切に読み取ります。価値を得るチームとダッシュボードだけを得るチームの差は、スコアが何かをルーティング・エスカレーション・コーチングしているかどうかです。すでにTier-1の作業を自動化しているなら、センチメントの最も有用な場所はチケットを解決しているエージェントと同じ場所です。そうすることでネガティブな読み取りはログエントリーではなく、慎重な人間へのハンドオフになります。
センチメントスコアを「投げられる距離」以上には信用しない理由
私はサポートキューで仕事をしています。ツールがすべての顧客の気持ちを教えると約束する時、私の最初の反応は興奮ではありません。穏やかな顧客を自信満々に五段階警報と誤分類し、怒り心頭の顧客を丁寧すぎて罵倒できないという理由で3ページ下に埋めたシステムの記憶が蘇るのです。
このような直感は正しいことがわかり、これらのツールを毎日使う人々によって支持されています。eeselで私は過去数年間、AIが数千件の実際のチケットを持つライブサポートキューをどのように処理するかを見てきました。最も信頼できる教訓は、自信ありげに聞こえるシグナルが危険な種類だということです。だからこそ私たちはAIのロールアウトを本番稼働前に顧客の過去チケットでシミュレーションします:デモで素晴らしく見えるスコアが、午前2時に静かに間違ったことをする可能性があるからです。センチメント分析は有用です。しかし、値する以上の信頼を得やすいサポート機能でもあります。このガイドは両方を正しく扱うことについてです。
AIセンチメント分析の実体
最もシンプルに言えば、センチメント分析は「表現された意見や感情に基づいてテキストをポジティブ、ネガティブ、またはニュートラルとして識別・分類するAI技術」です(G2の定義)。サポートでは「顧客の知覚感情を測定する」(Observe.AIの表現)ものです。顧客が「このサービスはひどかった」と書くと、モデルはネガティブと読み取り、そのラベルがヘルプデスクが行動できるものになります。
問題は「ポジティブ、ネガティブ、ニュートラル」が幼児向けバージョンだということです。異なる役割を果たすため、知っておくべき4つのバリエーションがあります:

- 段階的(細粒度)センチメントは3つのバケツを超え、非常にポジティブから非常にネガティブなどのスケールを使用します。Zendeckの5段階スケールとDialpadのレンジはこれを実装しています。
- 感情検出は、G2が「通常のネガティブからポジティブのランキングの外にある、より複雑な顧客の反応」に適していると指摘する、フラストレーションや安堵などの具体的な感情を特定します。
- アスペクトベースのセンチメントは感情をトピック別に分割します:「アプリは好きだが、請求は嫌い」はプロダクト-ポジティブ、請求-ネガティブになります。これが実際のトレンド分析の背後にある技術です。怒りが存在するだけでなく、何が怒りを引き起こしているかを教えてくれます。
- インテント分析は近い親戚です:これはクレームか、解約か、購入の質問か?チケットトリアージでセンチメントと組み合わせて使われ、Zendeckがトピックとセンチメントを一緒に分類する理由です。
1つだけ覚えるとしたら、アスペクトベースを選んでください。「顧客が不満を感じている」はパニックです。「顧客は新しいチェックアウトフローに不満を感じている」はロードマップです。
内部でどう動いているか
これらを自分で構築しなくてもうまく使えますが、いつ嘘をつかれているかを見抜くための最低限の知識は必要です。
G2のグロッサリーによると、2つの基本的なアプローチがあります。古いシステムはセンチメント辞書に頼っています。「良い」言葉と「悪い」言葉の固定リストで、脆弱で、顧客が予測しなかった言葉でフラストレーションを表現した瞬間に壊れます。最新システムは自然言語処理と機械学習に頼り、キーワードをマッチングするのではなくパターンを読み取ります。この違いは、懐疑的なレビュアーが人気ツールを「美化されたCTRL+F」(G2より)と切り捨てた正確な理由です:システムが本当にキーワードマッチングだけをしている場合、すべての表現を自分で予測しなければなりません。
ほとんどの購入者が気づく以上に重要な第2の軸があります:テキスト対トーン。Observe.AIはラインを明確に引いており、単純なテキストスコアリングと、「何が言われたかだけでなくどのように言われたかも分析する」トーナリティベースのセンチメントを対比しています。音声通話では「いい」が誠実かも知れないし、怒っているかもしれません。トーンだけが違いを捉えます。テキストチケットでは、このシグナルを完全に失います。これがテキストの皮肉が難しい理由の一部です。
最後にタイミングがあります。リアルタイムスコアリングは会話が展開する中で実行され、スーパーバイザーが通話中に介入したり、センチメントが低下した瞬間にチケットをエスカレーションしたりできます。バッチスコアリングは事後的に実行され、QAとトレンドレポートに使われます。同じ基礎となるシグナルが両方を支えます。問いは、それを割り込みに使うか要約に使うかです。
実際に役立つもの
ここで私はより熱心になります。ユースケースは本物だからです。5つが効果を発揮します:
- 優先ルーティング。 タイムスタンプ順でキューを処理する代わりに、ネガティブなチケットを最初にサーフェスします。Zendeckはまさにこれを提唱しています:「これらのインサイトを使って、顧客の感情に基づいてチケットを優先順位付け、ルーティング、管理する。」これが最高のROIを誇る単一のユースケースであり、AIチケットトリアージと自然に組み合わされます。
- エスカレーショントリガー。 センチメントが閾値を超えると自動エスカレーション。適切に実装すれば、フラストレーションを感じている顧客が丁寧に無視されるスローモーション災害を防ぎます。エスカレーションの対処法ガイドでハンドオフメカニクスをより詳しく解説しています。
- 解約・リスク検出。 Freshdeskはこれを明示的にリストアップし、センチメントを「リスクのある顧客を特定し、解約を減らすためにプロアクティブにエンゲージする」方法として位置づけています。B2Bチームにとって、更新前に静かに悪化しているアカウントを早期に発見することは、機能全体の価値を単独で上回ります。
- エージェントコーチング。 Dialpadはフラグが立ったサンプルを「1対1のセッションやプレイリストで共有して新しいエージェントのトレーニングに役立てる」ことを提案しています。コーチングがマネージャーがたまたまレビューした少数ではなく、すべてのインタラクションに基づく場合、それは逸話的なものでなくなります。
- 顧客の声のトレンド。 センチメントを時間をかけて集計し、アスペクトベースのスコアリングがどの製品領域がそれを下げているかを伝えます。
コーチングのケースは最も正直な称賛を見たところです。あるヘルスケアQAリーダーがG2で上手く表現しました:
「過去、品質はスクリプトの遵守と規制のチェックボックスに焦点を当てた手動監査に限定されることが多かった。しかしObserve.AIを使用することで、より深く掘り下げ、すべてのインタラクションを臨床的精度と感情的知性の両方で分析できるようになりました...限られた通話サンプルに頼ることはもうありません。インタラクションの100%にわたってインサイトを捉えています...これにより、事後的な品質保証からプロアクティブなパフォーマンスコーチングへの転換が助けられました。」 - G2の確認済みレビュー
これが理想のバージョンです:通話の2%をサンプリングするところから、すべてを読み取るところへ。古い方法からの本物の前進であり、これは私が実際に購入するピッチの部分です。
失敗するところ(この部分を2回読んでください)
次がデモがスキップする部分です。センチメント分析は2つの反対方向で失敗し、両方を知ることが有用なセットアップとノイズの多いセットアップを分けます。
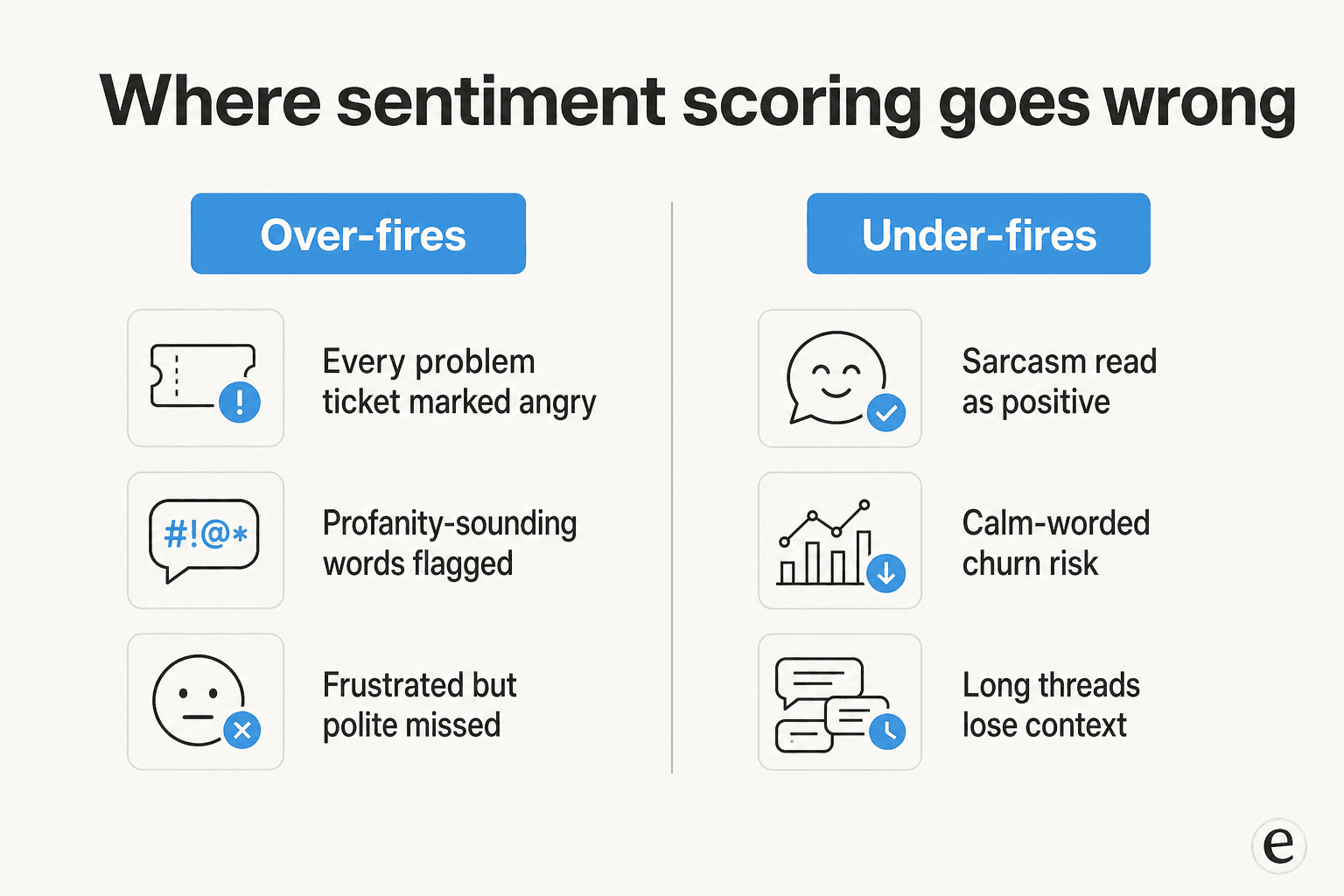
過剰発火。 素朴な失敗は、顧客に問題があるというだけですべての問題チケットを「怒り」とマークすることです。これはよくある落とし穴で、Zendeckはそれに対して専用の設計を施しました:そのセンチメントは「カスタマーサービスのコンテキスト向けにキャリブレーションされており、顧客が問題を抱えているというだけでチケットにネガティブなセンチメントが割り当てられることはない」と説明されています。これが意図的な設計を必要としたという事実は、デフォルトでどれだけ簡単に間違った方向に進むかを示しています。プラクティショナーも感じています:あるヘルスケアQAレビュアーが「実際にはコンテキスト上適切だが、冒涜的な言葉に似た音の言葉による」偽陽性の冒涜語問題を説明し、「QAプロセスにノイズを生み出し、追加の手動レビューが必要になる」(G2)と述べています。
過小発火。 より静かで、より怖い失敗は本物のフラストレーションを見逃すことです。皮肉が最大の事例です:G2のグロッサリーは「ポジティブに見えるがフラストレーションを表現する皮肉的な発言」と「言葉の文字通りの意味を逆転させる反語」を核心的な弱点として挙げています。コンテキストの喪失も同様です:レビュアーは、長く履歴の多い会話でツールが「混乱してコンテキストを完全に理解できない」と報告しています(G2)。そして、解約書類を更新しながら穏やかで文法的に正しいメモを書く「礼儀正しいが去ろうとしている顧客」はニュートラルとしてすり抜けます。
コミュニティの正直な評決はほぼ至る所で同じ地点に落着きます:
「AIの統合によって、レビューをより効率的に行えるようになりました。常に正確ではありませんが、フラグが立てられた情報は役立ちます。」 - Level AI on G2
「役立つが常に正確ではない」が設定すべき正しい期待値です。Observe.AIのG2ページでは、自動生成された否定的意見の集約が「精度の問題」「不正確さ」「不正確なデータ分析」でトップになっています(G2)。機能の欠如ではなく精度がチームが不満を言う対象です。実践的な意味合い:センチメントはキューを整理するために使用し、単一チケットに関する取り消し不可能な決定を下すためには使用しないでください。
主要ベンダーが実際にどう実装しているか
買い物をしているなら、違いは具体的です。2つのアーキテクチャが登場します:ヘルプデスクに組み込まれたメッセージごとのテキストセンチメント(Zendesk、Freshdesk)対、ライブのスーパーバイザー介入のために設計されたリアルタイム音声センチメント(Dialpad、Observe.AI、Sprinklr)。
| ベンダー | スコアリング対象 | リアルタイム? | スケール | 注目の詳細 | 配置場所 |
|---|---|---|---|---|---|
| Zendesk | チケットテキスト(音声トランスクリプト含む) | 最初のメッセージ時;動的検出がオンの場合は返信ごと | 5段階、非常にポジティブから非常にネガティブ | 問題があるだけでは「ネガティブ」にならないようキャリブレーション済み;スコアごとに高/中/低の信頼度 | インテリジェントトリアージ(Copilotアドオン) |
| Freshdesk | 最新の顧客メッセージ | メッセージごとにリアルタイム | ポジティブ / ニュートラル / ネガティブ | 解約・エスカレーションの明示的なユースケース;カスタマイズ可能なスコア範囲 | Freddy AI、ProおよびEnterpriseプラン |
| Dialpad | ライブ通話トランスクリプト | はい、通話ダッシュボードでライブ | 非常にポジティブから非常にネガティブ | スコアリングした正確な文を指摘;スーパーバイザーが引き継ぎ可能 | すべてのSellおよびSupportプラン |
| Observe.AI | 音声トーン + テキスト | はい、視覚的なエージェントアラート付き | 段階的 | トーナリティベース:言葉だけでなくどのように言われたかを読む | 会話インテリジェンス / エージェントアシスト |
| Sprinklr | オムニチャネルメッセージ | はい | 段階的 | 数字を公開する珍しいベンダー:80%以上の精度 | 会話分析 |
購入に関するいくつかのメモ。センチメントはほぼ常に上位層の機能です:ZendeckではCopilotアドオンで、Freshdeskではプロとエンタープライズにゲートされています。公に精度の数字をコミットしているのはSprinklrだけで、それ自体がこのカテゴリが測定されることにどれだけ慎重かを物語っています。コストが最重要な視点なら、AIと人間のエージェントのコストの比較分析が役立つ補完読み物です。
ほとんどのチームが見逃す部分:スコアは成果ではない
私が最も頻繁に見るのはこの落とし穴です。チームはセンチメントをオンにし、赤と緑でいっぱいのダッシュボードを得て、情報を得た気がして、何も変えません。アクションなしの測定は、生産的に感じることの最もコストのかかる形です。
これはAI CSATとAI解決率に現れる同じ教訓です:数字はそれが変えるものと隣り合わせる時だけ役立ちます。低い満足度の隣に高い解決率があるのは、AIが解決せずにチケットを閉じていることを意味します。何も速くルーティングしないネガティブなセンチメントの壁は、グラフのある不安に過ぎません。
機能する版は、センチメントをすでに作業をしているシステムに組み込みます。AIヘルプデスクエージェントがすでにTier-1チケットをトリアージして解決しているなら、ネガティブな読み取りはトリガーになります:自動返信を保留し、人間にエスカレーションし、顧客が繰り返さなくて済むように完全な履歴を添付します。それがレポートとしてのセンチメントではなく、コントロールとしてのセンチメントです。
そして、サポートにおいてAIを信頼することについての深い規則に繋がります。あるDTCサプリメントのCXリーダーが私たちに言ったように、目標はすべてを処理するAIではありません:「自信があるチケットだけを処理するAIが必要で、他のすべては放っておいてほしい。」センチメントはその線を引くための最も明確な信頼シグナルの1つですが、「これは放っておく」という答えに行動できるシステムに組み込まれている場合のみです。
本当に効果を発揮するsentimentのためにeeselを試してください
ほとんどのセンチメントツールは顧客がどう感じるかを伝えるところで止まります。eesel AIはその次の部分を行うように構築されています:初日から過去のチケット、ヘルプドキュメント、マクロから学び、既存のヘルプデスク内でチケットをトリアージ、ドラフト、解決します。顧客のフラストレーションをレポートの行ではなく、慎重にルーティングする理由として使用します。
サポート仲間に指摘したいのはシミュレーションモードです:1人のライブ顧客が関与する前に、何千もの実際の過去チケットに対してAIをサンドボックスで実行し、どのように処理したか(どこでエスカレーションしたか含む)を正確に確認します。それが自信ありげだが間違ったシグナルへの解毒剤であり、生のセンチメントダッシュボードを信頼しない方法でこのセットアップを信頼する理由です。信頼度ベースのルーティングでは、低信頼度の読み取りはライブ返信ではなく、人間のためのドラフトとして残ります。料金はシートフィーなしの使用量ベースで、クレジットカード不要の無料トライアルがあります。
最初により広い視点が欲しい場合は、最高のカスタマーサービスAI、カスタマーサポート自動化ツール、AIヘルプデスクソフトウェアのまとめがスタックの残りと並んでセンチメントをコンテキストに置いています。
よくある質問
カスタマーサポートにおけるAIセンチメント分析とは何ですか?
AIセンチメント分析の精度はどのくらいですか?
サポートにおいてAIセンチメント分析は実際に何に使えますか?
AIセンチメント分析が皮肉を正しく検出できないのはなぜですか?
小規模なサポートチームにとってセンチメント分析は価値がありますか?
AIセンチメント分析はCSATサーベイとどう違いますか?
AIセンチメント分析は複数言語に対応できますか?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.