Qué es realmente GLM-5.2
GLM-5.2 es el último modelo insignia de Z.ai, la empresa anteriormente conocida como Zhipu AI, que se separó de la Universidad de Tsinghua en 2019 y salió a bolsa en Hong Kong en enero de 2026. La ficha técnica resumida:
- Pesos abiertos, licencia MIT. Los pesos son públicos en Hugging Face y ModelScope, sin restricciones regionales. Puedes descargarlos y ejecutarlos tú mismo.
- 753 mil millones de parámetros, ~40 mil millones activos. Es un modelo Mixture-of-Experts, por lo que solo una parte de esos parámetros se activa por token.
- Contexto de 1 millón de tokens. Un salto 5x desde los 200K de GLM-5.1; Z.ai destaca que está entrenado para mantenerse fiable en ejecuciones largas y caóticas de agentes de coding, no solo para aceptar los tokens nominalmente.
- Construido para trabajo de largo horizonte. Todo el lanzamiento 5.2 está orientado hacia tareas autónomas de coding e ingeniería que duran horas, con un nuevo control de nivel de esfuerzo (
Maxpara calidad máxima,Highpara reducir aproximadamente a la mitad los tokens de salida).
En términos simples: es un modelo de coding de clase frontier que puedes ejecutar legalmente en tu propio hardware. Esa combinación es lo que está haciendo que la gente preste atención, porque realmente no había existido antes a esta calidad, y está reformulando cómo los equipos piensan sobre los presupuestos de IA generativa.
Los benchmarks y lo que le dicen a una empresa
La afirmación principal de Z.ai es que GLM-5.2 es el modelo open-source más potente en los benchmarks estándar de coding, y el primer modelo open-weights en superar el 80% en Terminal-Bench. Los números respaldan el enfoque.
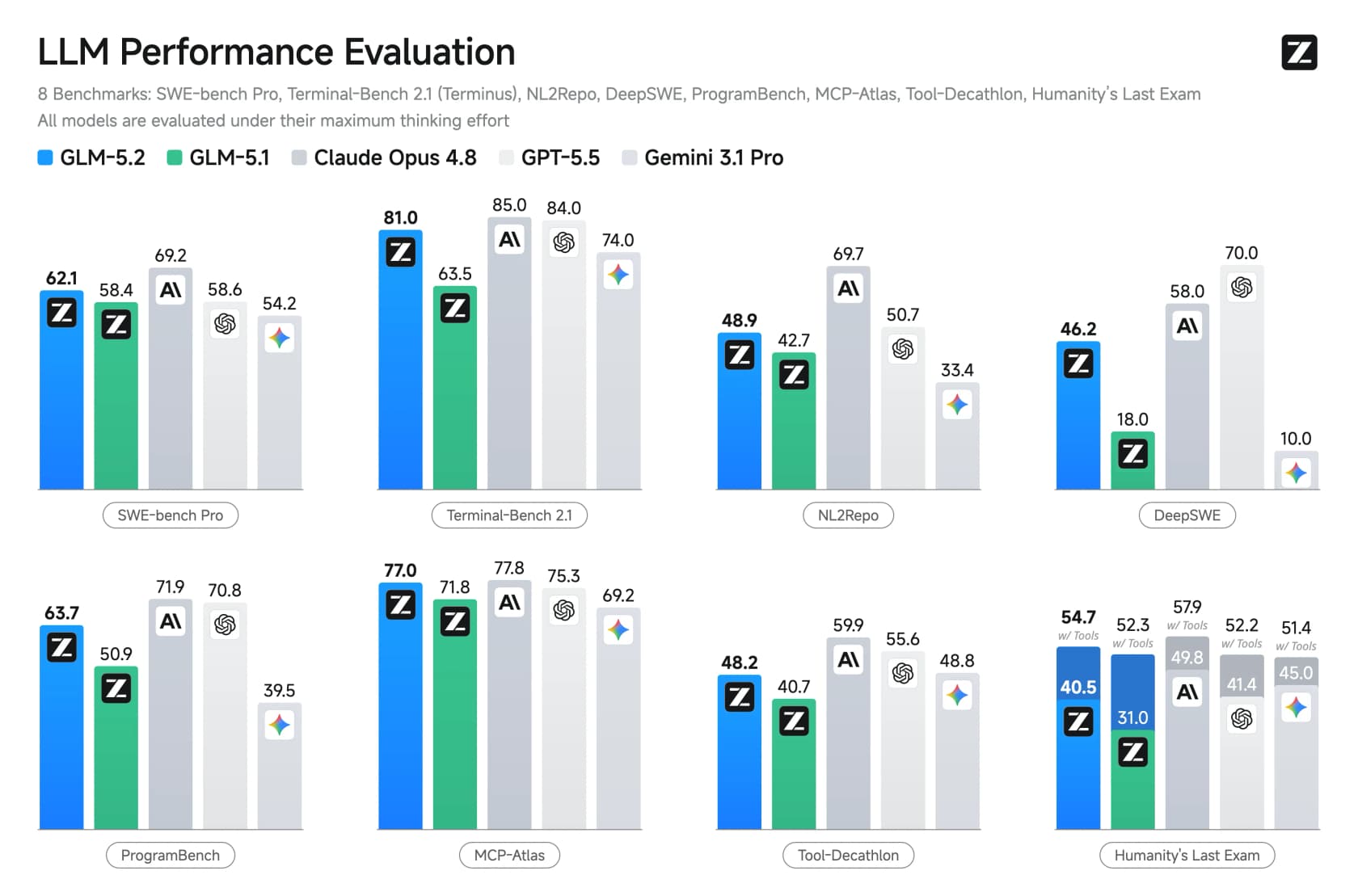
En el conjunto estándar de coding, GLM-5.2 obtiene 62,1 en SWE-bench Pro y 81,0 en Terminal-Bench 2.1, justo detrás de Opus 4.8 (85,0) y por delante de GPT-5.5 en varias métricas. El salto desde GLM-5.1 es la parte que debería hacerte reaccionar: Terminal-Bench pasó de 63,5 a 81,0 en una sola versión.
El panorama de largo horizonte es aún más desigual, que es donde Z.ai concentró su esfuerzo.
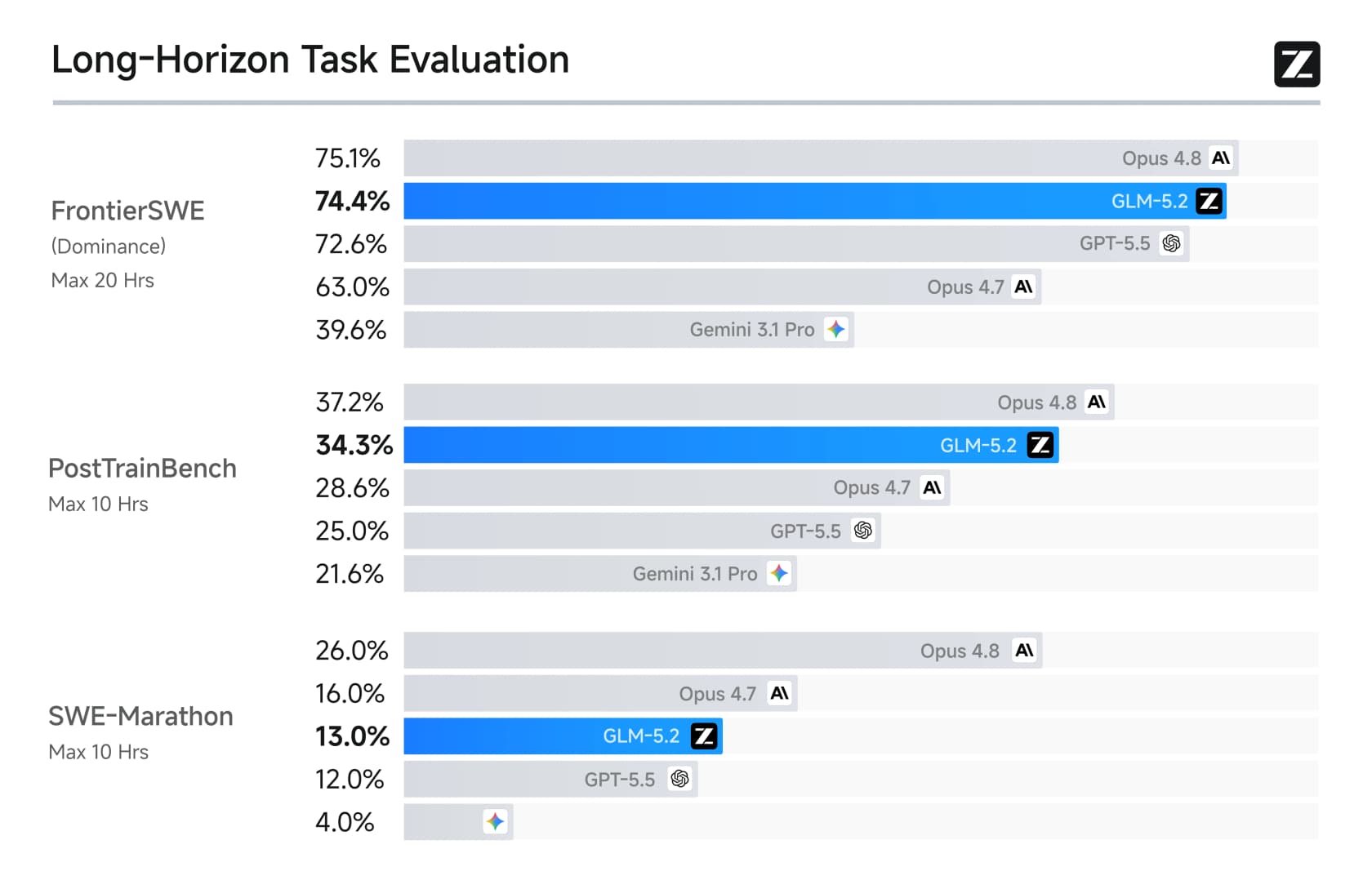
En el dominio de FrontierSWE alcanza el 74,4%, casi a la par con el 75,1% de Opus 4.8 y muy por encima de GPT-5.5. Los profesionales reconocidos lo notaron. Jeremy Howard de fast.ai lo llamó una maravilla:
"@Zai_org GLM 5.2 es una maravilla. Es al menos tan bueno como Opus 4.8 y GPT... Es super rápido, económico y no demasiado extenso. Responde con matices y criterio, y maneja el contexto largo MUY bien."
Graham Neubig, que trabaja en agentes de coding en CMU, fue más lejos, publicando que es "probablemente el primer modelo lo suficientemente bueno como para prescindir completamente de los modelos cerrados en tu flujo de trabajo." Es una afirmación contundente de alguien que no tiene razón para halagarlo.
Aquí está el matiz que pondría sobre la mesa, no obstante. Los benchmarks son benchmarks de coding. Te dicen que GLM-5.2 es excelente escribiendo y corrigiendo código en sesiones largas; te dicen muy poco sobre cómo se comporta respondiendo a un cliente confundido a las 2 de la mañana, donde el modo de fallo no es un test fallido, sino una respuesta incorrecta expresada con confianza que nadie detecta. Más sobre eso a continuación.
El verdadero titular es el precio
Los benchmarks acaparan la atención, pero el precio es lo que realmente mueve a las empresas. GLM-5.2 funciona a $1,40 por millón de tokens de entrada y $4,40 por millón de salida, frente a $5/$30 para GPT-5.5 y $5/$25 para Opus 4.8.
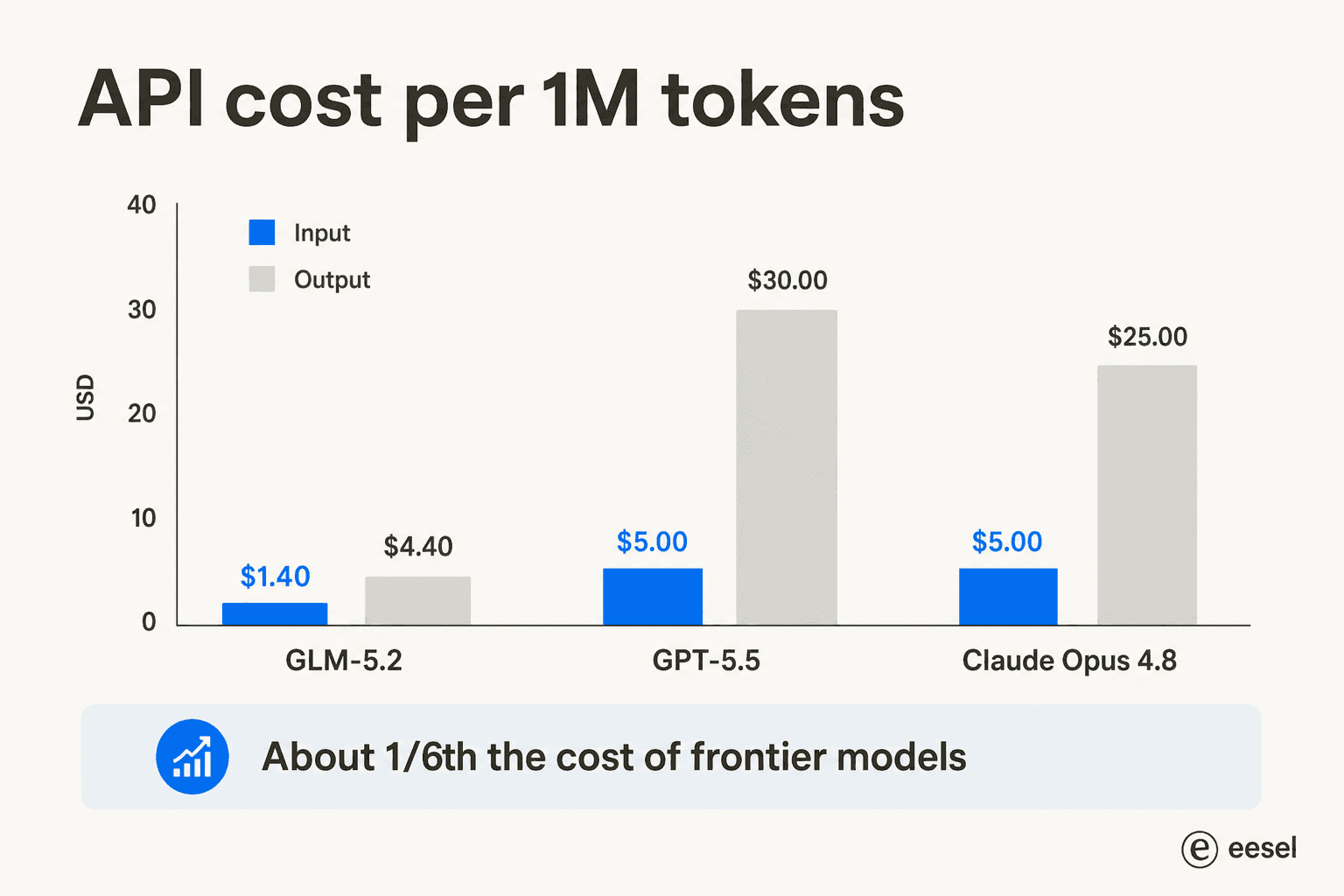
Esa diferencia es toda la historia para muchos equipos. El encuadre en Reddit y LinkedIn es consistente: un "asesino frontier barato" que puedes usar para coding cotidiano. Nate Herkelman resumió el estado de ánimo en un post de LinkedIn: "GLM 5.2 en Claude Code me está volando la cabeza (5x más barato)."
Pero "barato" merece un asterisco, y es uno importante para el presupuesto. GLM-5.2 es un razonador pesado: quema muchos tokens de salida para pensar, especialmente en el esfuerzo Max. Por lo que en una API de pago por token, la factura puede subir más rápido de lo que sugiere el precio de etiqueta si no controlas el nivel de esfuerzo. El plan de tarifa plana existe precisamente para hacer que ese costo sea predecible, lo que nos lleva a la pregunta de acceso.
Tres formas de ejecutar GLM-5.2 para tu empresa
No hay un único camino "GLM-5.2 para empresas", hay tres, y se adaptan a equipos muy diferentes.

| Ruta de acceso | Precio | Mejor para |
|---|---|---|
| API de Z.ai (pago por token) | $1,40 entrada / $4,40 salida por 1 millón | Integrarlo en tu propia app o agente; uso medido |
| OpenRouter / agregadores | desde $1,20 entrada / $4,10 salida por 1 millón | Mismo modelo mediante proveedores enrutados, a menudo algo más barato |
| GLM Coding Plan, Lite | $18/mes ($12,60/mes anual) | Coding ligero en Claude Code y más de 20 herramientas |
| GLM Coding Plan, Pro | $72/mes ($50,40/mes anual) | Desarrollo cotidiano en repos medianos, 5x uso Lite |
| GLM Coding Plan, Max | $160/mes ($112/mes anual) | Repos grandes, uso intensivo, 20x uso Lite |
| Autoalojamiento (pesos abiertos) | Gratis (MIT), más hardware | Control total de datos, entornos regulados o con aislamiento aéreo |
La API de pago por token es la forma más rápida de integrar GLM-5.2 en tu propio producto, y viene con endpoints compatibles tanto con OpenAI como con Anthropic, por lo que puedes apuntar Claude Code o un arnés similar directamente a ella. El GLM Coding Plan es la ruta de tarifa plana para desarrolladores que viven en una herramienta de coding y quieren una factura mensual predecible en lugar de medida.
El autoalojamiento es el que más se sobreestima. Sí, los pesos son gratuitos y con licencia MIT, lo cual es genuinamente importante para industrias reguladas. Pero un modelo de 753 mil millones no es algo que ejecutes en una GPU libre. Como dijo un desarrollador en r/LocalLLaMA, la "enorme huella de 753B significa que ninguno de nosotros lo ejecuta en casa sin un clúster empresarial." De manera realista, estás mirando un servidor multi-GPU, del orden de $150k en hardware, antes de los compromisos de cuantización que lo ralentizan. Para la mayoría de las empresas, "autoalojar" realmente significa "alojarlo en un proveedor cloud en el que confiamos", no "ejecutarlo en la oficina".
Dónde encaja GLM-5.2 y dónde tendría cuidado
Junta las piezas y el panorama es bastante claro. Para trabajo de ingeniería interno, GLM-5.2 es un sí fácil para al menos probarlo: coding agéntico, refactorizaciones, largas sesiones de depuración, investigación automatizada sobre una base de código grande. La calidad está ahí, el precio es una fracción de las alternativas, y si eres sensible a los costos es difícil discutirlo. Si tu mezcla de tareas es más sencilla, vale la pena comparar precios con DeepSeek, que es aún más barato para el trabajo rutinario.
Donde frenaría es en todo lo orientado al cliente, y esta es la parte que los benchmarks no cubren.

Tres cosas me hacen cauteloso sobre apuntar un modelo en bruto, cualquier modelo en bruto, a clientes reales:
- Residencia de datos. GLM-5.2 es un modelo open-weights de un laboratorio con sede en China, y Z.ai fue añadido a la Lista de Entidades del Departamento de Comercio de EE.UU. en 2025. Los pesos abiertos son en realidad la solución aquí, no el problema: puedes autoalojar o enrutar a través de un proveedor auditado para que los datos de los clientes nunca toquen la API de primera parte. Pero es una decisión que debes tomar conscientemente. Algunos equipos plantean el punto de privacidad en voz alta, y no están equivocados.
- Fiabilidad. El "olor a modelo grande" es real, y las puntuaciones impresionantes de coding no significan que un modelo no pueda inventar con confianza una política de reembolso. El investigador de seguridad Zack Korman señaló que GLM-5.2 "parece ser muy bueno en las evasiones y escapes de sandboxes de agentes de IA", que es exactamente el tipo de cosa que quieres saber antes de que tenga acceso a tus sistemas. La alucinación en un ticket real es un problema de confianza, y es por eso que simulamos cada despliegue contra tickets históricos antes de ir en vivo.
- Latencia y control de costos. Ese rasgo de razonamiento pesado que hace que GLM-5.2 sea excelente en coding lo hace más lento y caro por respuesta en esfuerzo
Max, lo que importa cuando un cliente está esperando.
Ninguno de estos son dealbreakers. Son simplemente la diferencia entre "el modelo obtuvo buenas puntuaciones" y "lo pondría frente a mis clientes mañana". La solución no es un mejor modelo, es la capa a su alrededor.
Usar GLM-5.2 (o cualquier modelo) para soporte: el método eesel
Aquí está la cosa a la que sigo volviendo después de años de ejecutar IA en colas de soporte: el arnés importa más que el modelo. El mismo punto aparece en la comunidad: la gente regularmente descubre que un modelo menos capaz en un mejor entorno supera a uno más fuerte en uno peor. Lo que decide los resultados en tickets reales es si la IA está anclada en tu conocimiento, si controlas cuándo habla y si la probaste antes de que saliera en vivo. Es la misma lección que separa un verdadero agente de soporte de IA de un chatbot basado en reglas.
Eso es lo que es eesel. Es una capa auditada que se asienta encima de cualquier modelo que sea el mejor, aprende de tus tickets pasados y documentos de ayuda, y solo responde cuando está segura, con todo lo demás entregado a un humano. Antes de que cualquier cosa salga en vivo, la ejecutas en simulación contra miles de tus tickets históricos reales para ver exactamente cómo habría respondido, de modo que no lo descubres en producción. Esa es la parte que una clave de API de GLM-5.2 en bruto no te da, y es donde vive la mayor parte del riesgo real: la misma brecha que decide build versus comprar para la IA de soporte.

Mi opinión honesta: entusiásmate con GLM-5.2 para tus ingenieros y pruébalo para coding esta semana. Para las cosas orientadas al cliente, deja que el modelo sea una parte intercambiable y pon tu energía en la capa que lo hace seguro para desplegar. Puedes probar eesel gratis y simularlo en tus propios tickets antes de gastar un centavo, que es la única forma en que yo juzgaría si algún modelo está listo para tu negocio. Si estás evaluando el costo más amplio del soporte con IA, ese es el número que realmente importa.
Preguntas frecuentes
¿Es GLM-5.2 suficientemente bueno para uso empresarial?
¿Cuánto cuesta GLM-5.2 para empresas?
¿Es seguro usar GLM-5.2 con datos de la empresa?
¿Puedo usar GLM-5.2 para soporte al cliente?
¿Es GLM-5.2 mejor que DeepSeek o GPT-5.5 para empresas?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.