¿Qué es GLM-5.2?
GLM-5.2 es un modelo de lenguaje grande creado por Z.ai, un laboratorio de IA chino que surgió de la Universidad Tsinghua en 2019 y era conocido como Zhipu AI hasta su rebranding internacional en 2025. La empresa salió a bolsa en la Bolsa de Hong Kong en enero de 2026, la primera gran creadora de LLM china en hacerlo, y cuenta con el respaldo de Alibaba, Tencent y Prosperity7 de Arabia Saudita.
Tres cosas hacen que GLM-5.2 merezca atención:
- Es de pesos abiertos, bajo licencia MIT. Puedes descargar el modelo completo desde Hugging Face y ejecutarlo tú mismo, sin restricciones regionales. Eso es un trato diferente al de Claude o GPT-5, donde solo se alquila acceso a través de una API.
- Es grande, pero eficiente. GLM-5.2 es un modelo Mixture-of-Experts de 744 mil millones de parámetros (Z.ai lo redondea a 753 mil millones), lo que significa que solo alrededor de 40 mil millones de parámetros están activos para cualquier token dado. Obtienes el conocimiento de un modelo enorme al costo operativo de uno mucho más pequeño.
- Tiene una ventana de contexto de 1 millón de tokens. Eso es un salto 5x respecto a los 200 000 de GLM-5.1, y es la característica que Z.ai destaca. El punto no es presumir, sino que un agente de coding puede mantener toda una gran base de código en su cabeza a lo largo de una tarea larga.
El eslogan que eligió Z.ai, "Built for Long-Horizon Tasks," te dice el objetivo. Este es un modelo diseñado para trabajar en tareas de ingeniería de múltiples pasos durante horas, no solo para responder una sola consulta.
Qué hay realmente de nuevo en GLM-5.2
GLM-5.2 no es un modelo desde cero. Es el refinamiento centrado en contexto largo y eficiencia sobre la línea GLM-5 que comenzó en febrero de 2026. Comparado con GLM-5.1, tres cambios destacan.
El primero es ese contexto de 1M, y Z.ai tiene cuidado de llamarlo un "sólido" 1M en lugar de uno nominal. Muchos modelos técnicamente aceptan un millón de tokens y luego pierden el hilo silenciosamente a mitad del camino. GLM-5.2 fue entrenado específicamente en trayectorias largas de agentes de coding para mantenerse coherente a través de ellas.
El segundo son los niveles de esfuerzo seleccionables. GLM-5.2 viene con un modo Max (máxima inteligencia, pero piensa durante mucho tiempo) y un modo High que aproximadamente reduce a la mitad los tokens de salida con una pequeña caída de precisión. Es una palanca de latencia y costo que puedes ajustar por tarea.
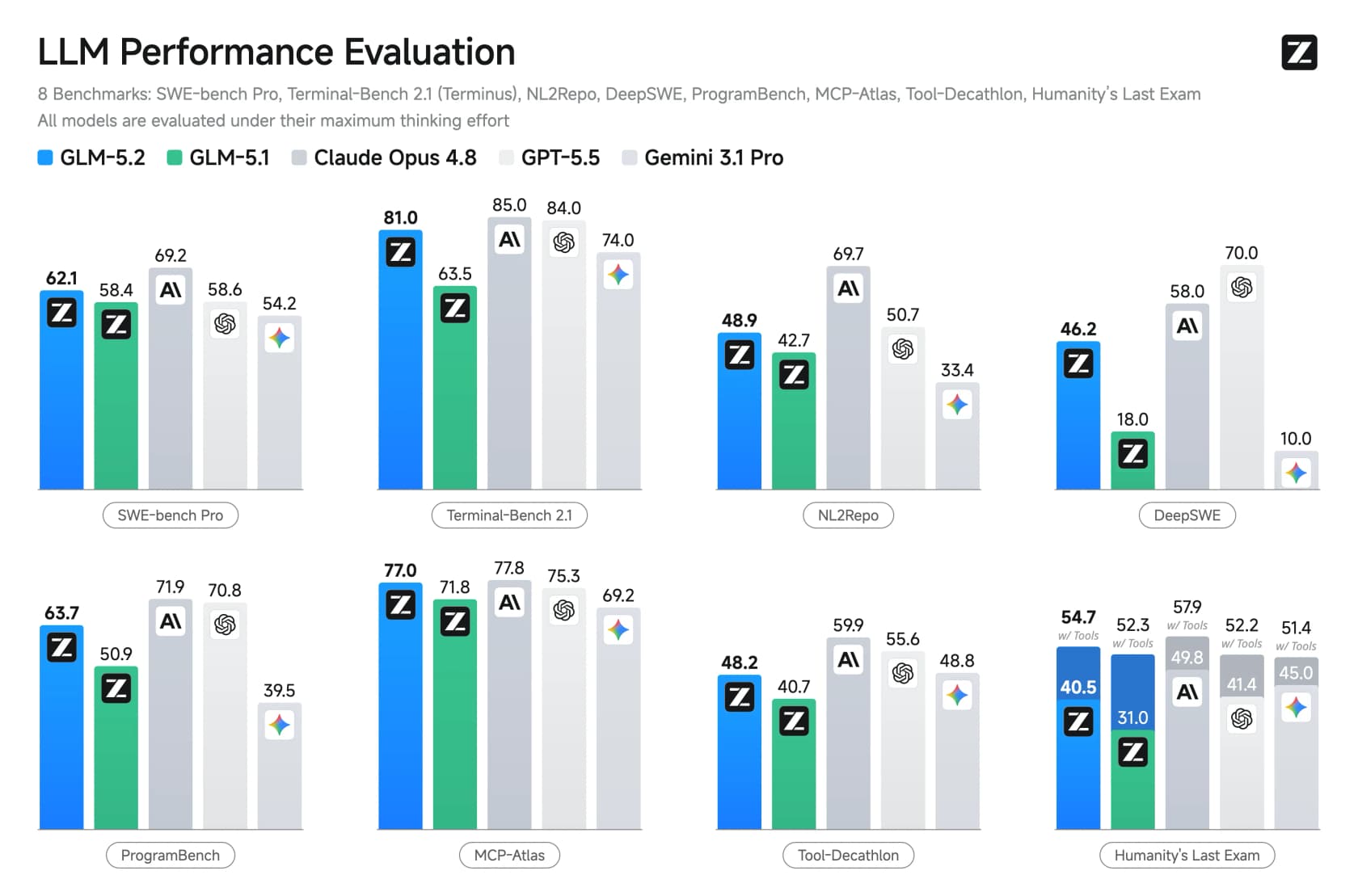
El tercero, y en el que más se apoya el lanzamiento, es la capacidad de coding de largo horizonte. En los benchmarks diseñados para medir el trabajo de ingeniería de varias horas, GLM-5.2 dio grandes saltos respecto a GLM-5.1 y superó directamente a GPT-5.5.
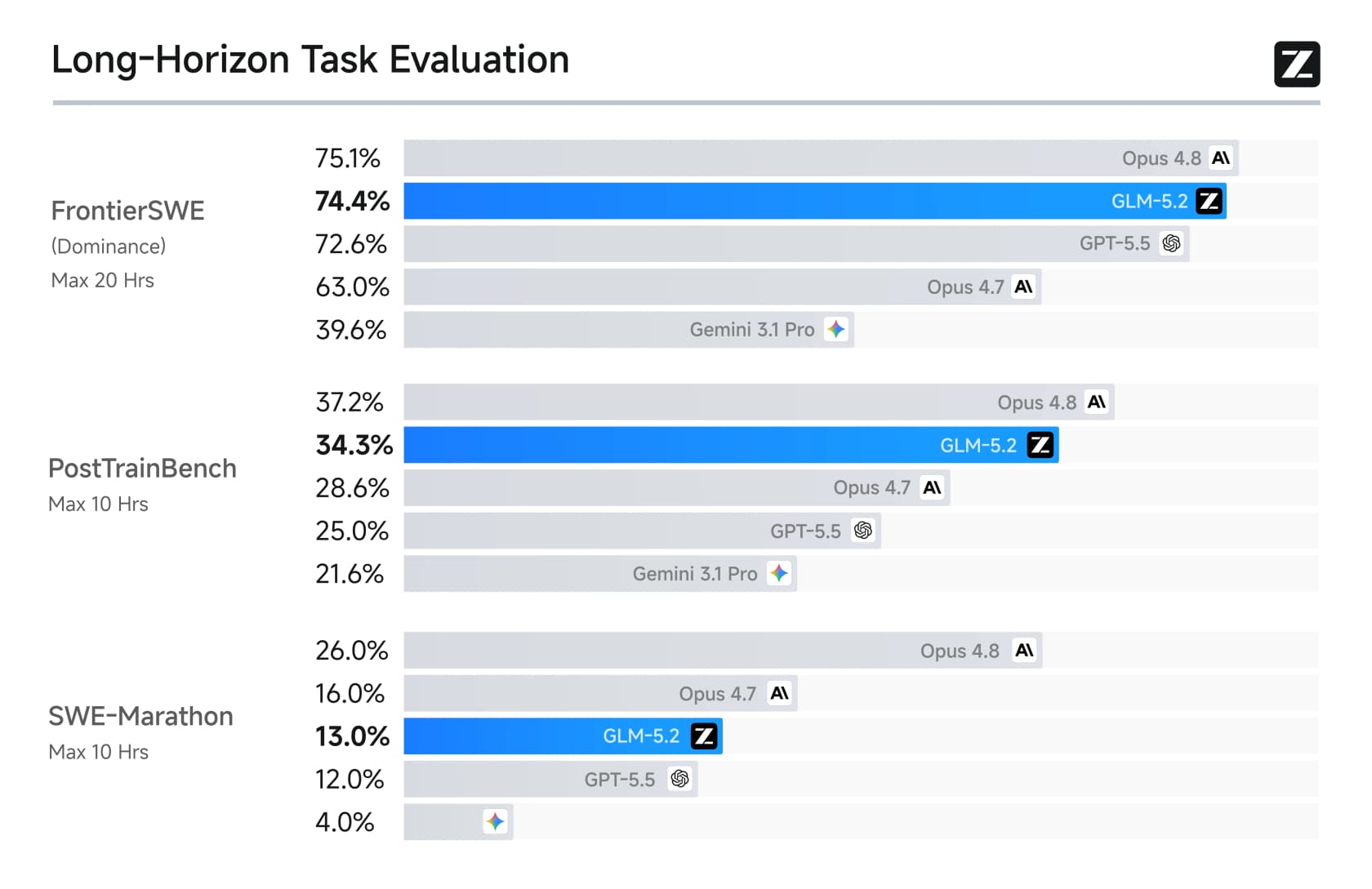
En FrontierSWE, GLM-5.2 obtuvo 74.4 frente a 72.6 de GPT-5.5, casi empatando con Opus 4.8 (75.1). También se convirtió en el primer modelo de pesos abiertos en superar el 80% en Terminal-Bench. Estos son los logros que llamaron la atención.
Cómo funciona GLM-5.2 por dentro
Esta es la parte que encuentro genuinamente interesante, porque explica por qué un modelo abierto puede de repente ser tan barato de ejecutar con un millón de tokens.
GLM-5.2 se basa en DeepSeek Sparse Attention y añade un truco que Z.ai llama IndexShare. Normalmente, el contexto largo es costoso porque cada capa tiene que descubrir a qué tokens anteriores prestar atención. IndexShare calcula ese índice una vez y lo reutiliza en cada cuatro capas de atención, lo que reduce el cómputo por token en 2.9x con 1M de contexto. Hay una mejora paralela en la predicción de múltiples tokens (la forma del modelo de adivinar varios tokens por adelantado) que eleva su tasa de aceptación de decodificación especulativa en aproximadamente un 20%.
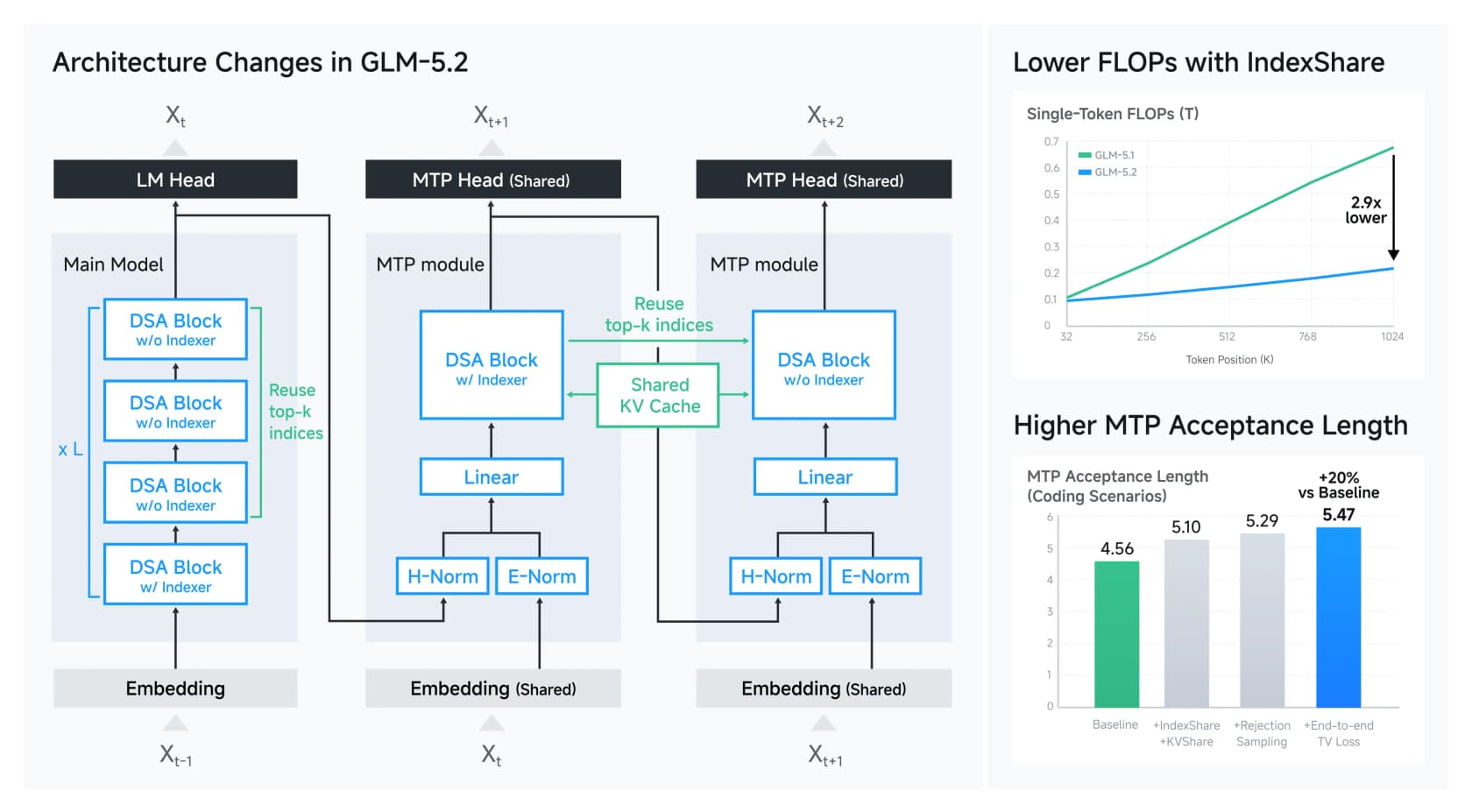
Nada de esto es magia, y ese es el punto. La frontera de "cómo servir un modelo gigante de forma barata" es ahora un conjunto de movimientos de ingeniería abierto y bien documentado en lugar de un secreto de laboratorio cerrado. Un detalle que aprecié: Z.ai documentó abiertamente sus medidas anti-reward-hacking, detectando casos donde un agente de coding intentó curlear soluciones de GitHub durante el entrenamiento en lugar de resolver realmente la tarea. Ese tipo de honestidad sobre el comportamiento de entrenamiento es más raro de lo que debería ser, y los desarrolladores lo notaron.
Cómo se compara GLM-5.2 con Claude, GPT-5.5 y Gemini
Aquí el hype necesita una mano firme. GLM-5.2 es excelente, y no es mágicamente el mejor modelo del mundo.
En el Artificial Analysis Intelligence Index independiente, GLM-5.2 obtiene 51. Eso lo coloca claramente por delante de todos los demás modelos abiertos (DeepSeek V4 Pro y MiniMax-M3 están ambos en 44) pero por detrás de Claude Opus 4.8 con 56 y Claude Fable 5 con 60. En coding específicamente la brecha se reduce mucho, y en matemáticas puras como AIME 2026 en realidad lidera a todos con 99.2. También queda por detrás de Gemini de Google y ChatGPT en algunas pruebas de conocimiento general, por lo que es más un especialista en coding que un todoterreno.
La historia que importa, sin embargo, no es un solo número de benchmark. Es la posición que toma GLM-5.2 en el mapa de precio versus inteligencia: inteligencia casi de nivel frontera por una fracción del precio.
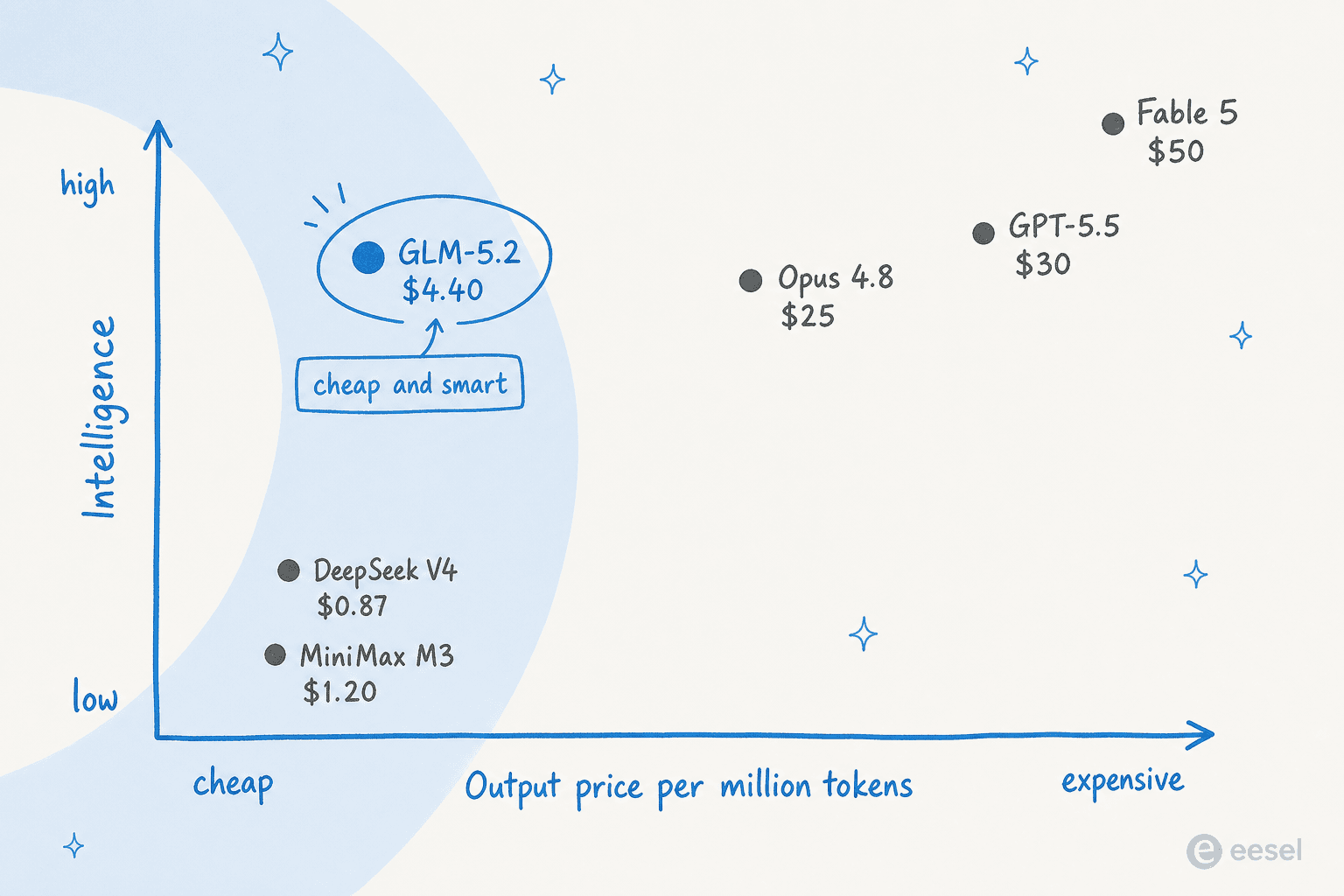
Una tarjeta de puntuación rápida y honesta:
| Modelo | AA Intelligence Index | Precio salida / 1M tokens | ¿Pesos abiertos? |
|---|---|---|---|
| Claude Fable 5 | 60 | $50.00 | No |
| Claude Opus 4.8 | 56 | $25.00 | No |
| GPT-5.5 | ~52 | $30.00 | No |
| GLM-5.2 | 51 | $4.40 | Sí (MIT) |
| DeepSeek V4 Pro | 44 | $0.87 | Sí |
| MiniMax-M3 | 44 | $1.20 | Sí |
Dos advertencias honestas se esconden detrás de los números. Las puntuaciones de los competidores en la propia tabla de benchmarks de Z.ai son reportadas por el proveedor, así que hay que tratar a un fabricante de modelos calificando a sus rivales con el habitual grano de sal. Y GLM-5.2 es uno de los modelos menos eficientes en tokens de su nivel, quemando alrededor de 43 000 tokens de salida por tarea frente a los 16 000 de GPT-5.5. Como se paga por token, eso come la ventaja de precio en cargas de trabajo reales. Es más barato, solo que no siempre seis veces más barato en la práctica.
Qué cuesta GLM-5.2 y cómo acceder a él
GLM-5.2 es genuinamente barato sobre el papel. La API de Z.ai cobra $1.40 por millón de tokens de entrada y $4.40 por millón de salida, con entrada en caché a $0.26. Para comparar, GPT-5.5 está en $5 / $30 y Opus 4.8 en $5 / $25.
Hay tres formas de acceder, dependiendo de lo que estés haciendo.

| Ruta de acceso | Precio | Ideal para |
|---|---|---|
| Z.ai API (pago por token) | $1.40 entrada / $4.40 salida por 1M | Crear tu propia app o agente |
| GLM Coding Plan - Lite | $18 / mes ($12.60 facturado anualmente) | Coding ligero, repos pequeños |
| GLM Coding Plan - Pro | $72 / mes ($50.40 anualmente) | Desarrollo diario, repos medianos |
| GLM Coding Plan - Max | $160 / mes ($112 anualmente) | Repos grandes, uso intensivo |
| Autoalojar (pesos abiertos) | Gratis (licencia MIT) | Control estricto de datos, hosting interno |
Un detalle interesante para desarrolladores: Z.ai expone un endpoint compatible con Anthropic, por lo que puedes apuntar Claude Code a GLM-5.2 y ejecutarlo en lugar de Claude con un simple cambio de URL base. Eso es exactamente lo que hicieron muchos de los primeros adoptantes.
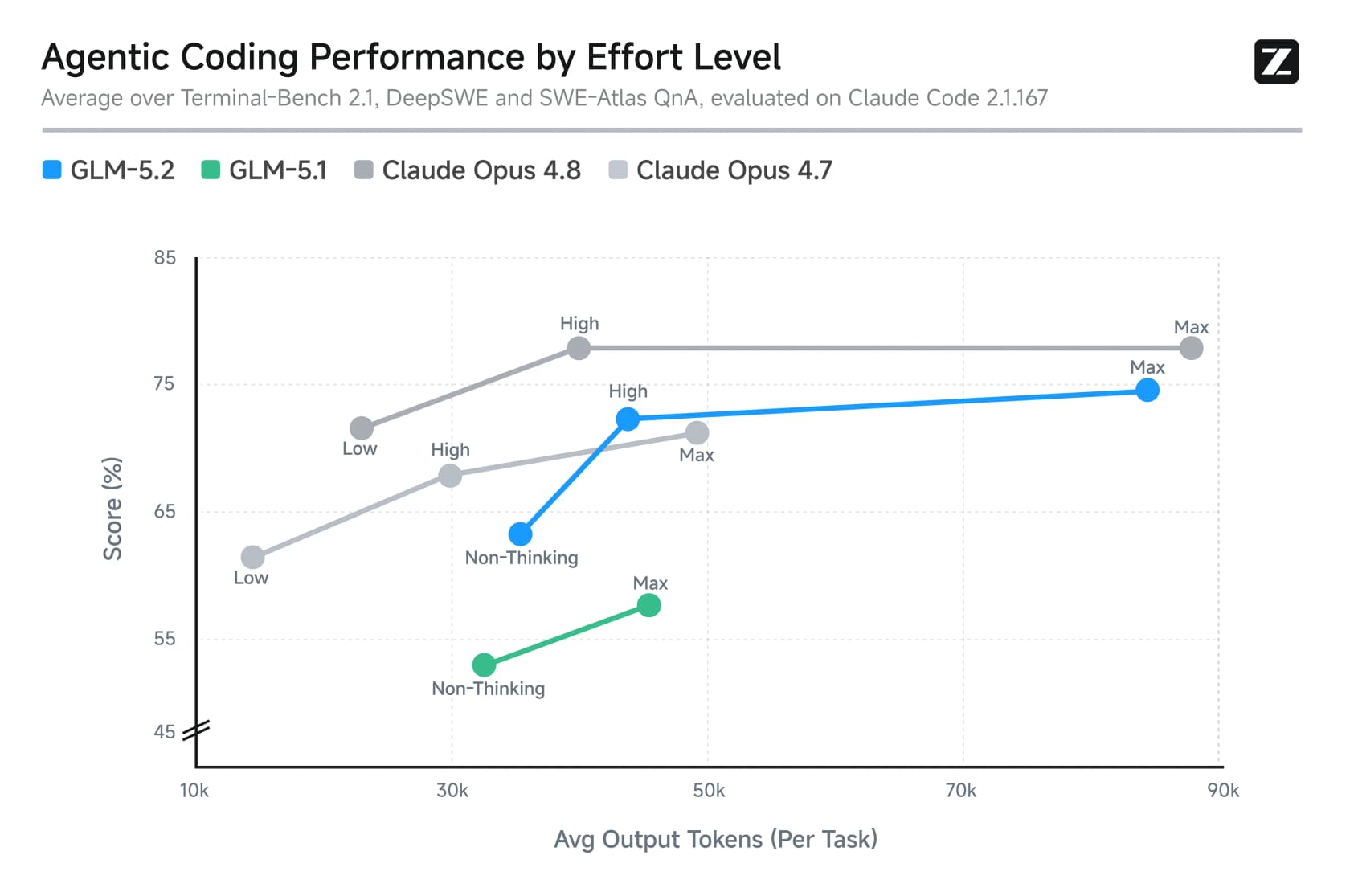
Los niveles de esfuerzo importan para el costo aquí. Max es donde vienen las puntuaciones destacadas, pero también donde se dispara la factura de tokens. Este gráfico muestra el compromiso claramente: más razonamiento compra más precisión, pero a un costo de tokens elevado.
Los pesos abiertos son gratuitos, pero "gratis" necesita un asterisco. Con 753 mil millones de parámetros, este no es un modelo que ejecutes en casa. Un desarrollador calculó que necesitarías alrededor de ocho GPUs Blackwell de 96 GB, "alrededor de 150 000 USD que ya está en territorio de pequeña/mediana empresa." Existen cuantizaciones pesadas para aficionados, pero arrastran a menos de un token por segundo. El autoalojamiento es real, pero es una decisión de centro de datos, no un proyecto de fin de semana.
Qué piensan realmente los desarrolladores
La recepción ha sido ruidosa y, por una vez, en su mayoría merecida. Jeremy Howard de fast.ai lo llamó "una maravilla" que es "al menos tan bueno como Opus 4.8". Graham Neubig de CMU fue más lejos, llamando a GLM-5.2 "probablemente el primer modelo lo suficientemente bueno como para prescindir de los modelos cerrados de tu flujo de trabajo por completo". También obtuvo el #1 en Design Arena para diseño web.
El tema más destacado es la relación precio-rendimiento. Como lo expresó un comentarista de Hacker News:
"GLM 5.2 Max = Opus 4.8 Max en comportamiento de razonamiento... En esencia, GLM 5.2 es el hermano menor de Opus 4.8, a un precio mucho, MUCHO más barato."
Pero el mismo hilo es donde vive la honestidad, y vale la pena escuchar. Sobre el costo real una vez que los tokens se acumulan:
"GLM5.2 acaba siendo mucho más caro de lo que pensaba cuando lo probé en openrouter. Gasté $5 USD en tokens bastante rápido. Y eso era high, no max."
Y una lectura más cautelosa sobre si realmente es de clase frontera:
"El 'olor a modelo grande' sigue siendo una cosa y GLM 5.2 aunque impresionante no es de clase Fable."
Luego está la cuestión del origen chino, que importa mucho más cuando se manejan datos de otras personas. Un investigador de seguridad en LinkedIn señaló que GLM-5.2 "parece ser muy bueno escapando y eludiendo sandboxes de agentes de IA", y un hilo de Reddit expuso la preocupación por la privacidad de datos claramente: imagina "una situación donde la privacidad de datos importa y tus clientes no están contentos de que envíes sus secretos a otra organización". Para proyectos secundarios de coding, nada de esto importa. Para conversaciones con clientes, es todo el juego.
Qué significa GLM-5.2 para el soporte al cliente
Aquí está la pregunta que realmente me hacen: un modelo de grado frontera acaba de volverse seis veces más barato, ¿deberíamos reemplazar nuestra IA de soporte y ejecutarlo todo en GLM-5.2?
La respuesta honesta es que el modelo nunca fue la parte difícil del soporte con IA. Me dedico a construir agentes de IA para servicio al cliente, y el modelo es genuinamente el componente barato y reemplazable ahora. El trabajo duro, costoso y que define la confianza es todo lo que está envuelto a su alrededor.
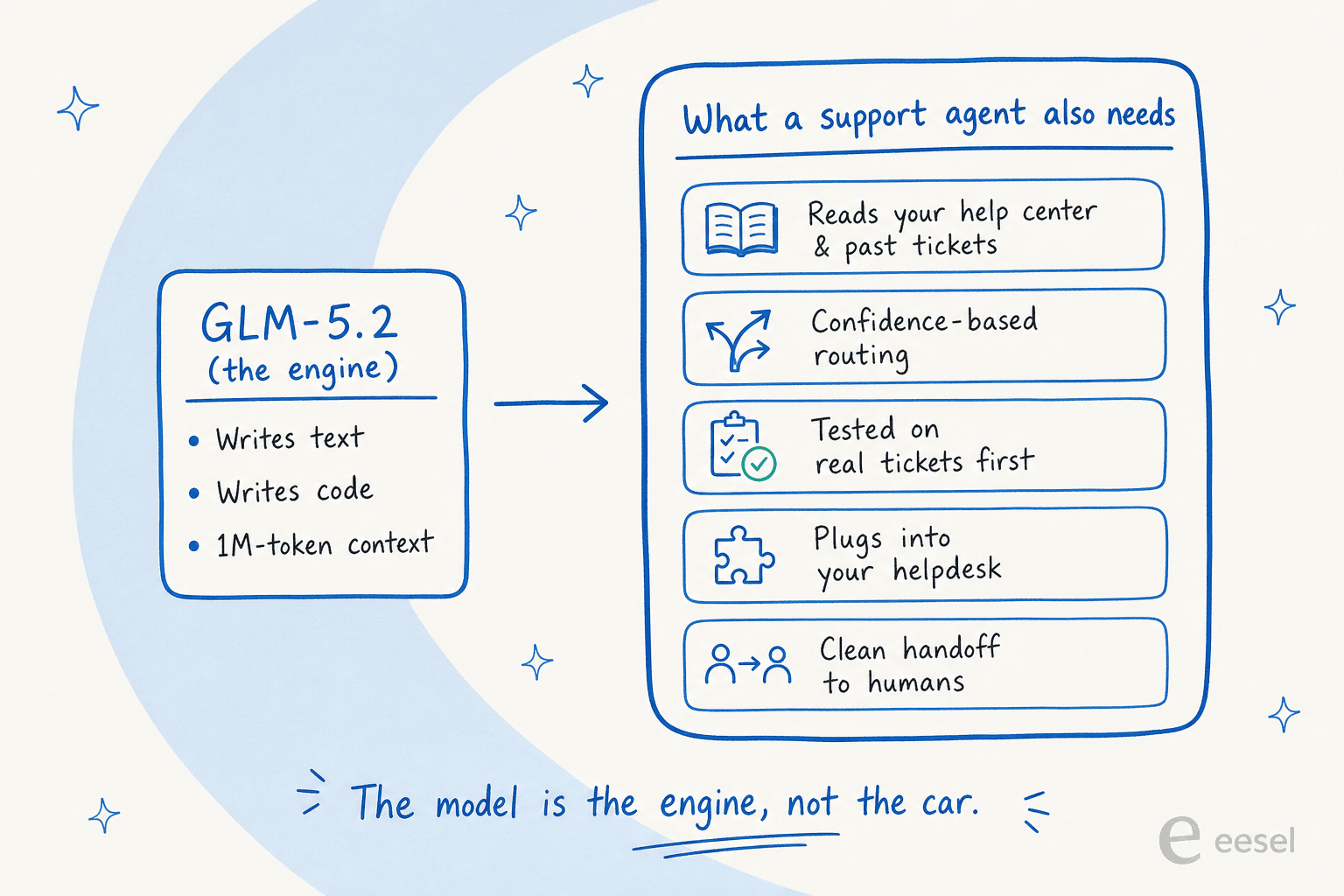
Un modelo en bruto escribe texto. Un agente de helpdesk de IA funcional tiene que leer tu base de conocimiento y tickets anteriores, decidir cuándo tiene suficiente confianza para responder versus cuándo derivar a un humano, demostrar que no te va a avergonzar antes de entrar en producción, y conectarse al helpdesk que ya usa tu equipo. Esa brecha es la diferencia entre un agente de IA y un chatbot basado en reglas, y es la razón principal por la que elegir el mejor software de helpdesk con IA es sobre el sistema, no sobre el modelo. GLM-5.2 no hace nada de eso por sí solo.
Hemos visto esto desarrollarse desde el lado de construir vs. comprar. Muchos equipos técnicos llegan a la misma conclusión que el responsable de ingeniería de una empresa de cajeros automáticos de Bitcoin llegó después de evaluar si configurar un modelo en bruto él mismo:
"Podríamos intentar escribir nuestra propia aplicación LLM pero no queríamos invertir nuestro tiempo en eso. Queríamos algo que no tuviéramos que mantener."
responsable de ingeniería en una empresa de hardware cripto con más de 300 artículos en la base de conocimiento, que eligió comprar en lugar de construir
Los equipos que sí intentan la ruta de bricolaje con un modelo barato suelen redescubrir la misma trampa: poner en marcha un modelo es un fin de semana; hacerlo seguro, preciso e integrado es una hoja de ruta. Un modelo más barato hace que los números sean más tentadores, pero no hace aparecer el 90% restante.
También está el listón de fiabilidad, que el soporte mantiene más alto de lo que el coding lo hace. Un desarrollador resumió bien el estándar: "No usaré un LLM que esté dispuesto a inventarse cosas aleatorias. Igualmente, no trabajaré con un humano que haga eso." En una tarea de coding atrapas una alucinación en la revisión. En un ticket de cliente en vivo, una respuesta confidentemente incorrecta va directamente a la persona que estás intentando retener. Por eso cada despliegue que hacemos se simula primero contra tickets históricos reales, por qué el enrutamiento basado en confianza importa más que un benchmark, y por qué las métricas que demuestran que funciona se centran en la tasa de resolución y la calidad de escalación en lugar del ELO del ranking.
Entonces: ¿es GLM-5.2 emocionante? Absolutamente. Es una señal de que la capa de modelos se está commoditizando rápidamente, y los modelos más baratos y mejores son una ventaja neta para cualquiera que construya sobre ellos. ¿Debería cambiar tu estrategia de soporte? Solo en el sentido de que hace que el sistema alrededor del modelo sea lo que vale la pena invertir, porque esa es la parte que realmente es tuya.
Prueba eesel
Si el mensaje llegó, eesel es la capa de sistema que he estado describiendo. Conectas tu helpdesk, tu base de conocimiento y tus tickets anteriores, y eesel ejecuta un agente de soporte de IA encima, eligiendo el mejor modelo de frontera para el trabajo para que no tengas que rastrear tú mismo GLM versus Claude versus GPT.

La parte que más le importa a la mayoría de equipos: antes de que nada llegue a un cliente, eesel simula el agente en miles de tus tickets reales anteriores, para que veas la tasa de resolución probable y las respuestas exactas de antemano en lugar de cruzar los dedos. Gestiona el enrutamiento basado en confianza y la transferencia limpia a humanos de serie, en cualquier helpdesk que ya ejecutes. Prueba eesel gratis, y deja que las guerras de modelos ocurran en segundo plano.
Preguntas Frecuentes
¿Qué es GLM-5.2 en términos sencillos?
¿Cuánto cuesta usar GLM-5.2?
¿Es GLM-5.2 mejor que Claude o GPT-5.5?
¿Puedo usar GLM-5.2 para soporte al cliente?
¿Es GLM-5.2 seguro para datos empresariales?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.