
¿Qué es Claude Fable 5?
Claude Fable 5 es la quinta generación de modelos de Anthropic y la mitad pública de un par de dos modelos (el otro, Mythos 5, es el mismo modelo con las salvaguardas eliminadas, restringido a socios de investigación verificados). Anthropic lo presenta como «un modelo de nivel Mythos creado para tus proyectos más ambiciosos y de larga duración», diseñado para manejar «tareas complejas, asíncronas y de días de duración que los modelos anteriores no podían sostener».
Esto es lo que importa una vez que quitas el ruido del día del lanzamiento:
- Está en lo más alto de la escalera. Fable 5 se sitúa por encima de Opus 4.8, que se sitúa por encima de Sonnet 4.6. Si has leído nuestra visión general de Claude, este es el nuevo techo.
- Cuesta el doble que Opus. 10 $ por millón de tokens de entrada, 50 $ por millón de salida, exactamente 2x los 5 $ / 25 $ de Opus 4.8. Los tokens de entrada en caché obtienen un descuento del 90 %, y la inferencia solo en EE. UU. lleva un recargo de 1,1x.
- Es grande. Una ventana de contexto de 1.000.000 de tokens, 128.000 tokens de salida máxima y un corte de conocimiento en enero de 2026.
- Está en todas partes. Disponible en claude.ai, la API de Claude, Amazon Bedrock y Claude Platform en AWS y Microsoft Foundry, además de Claude Code y Claude Managed Agents.
La historia de los benchmarks respalda el bombo, al menos sobre el papel. La propia comparación de Anthropic sitúa a Fable 5 muy por delante del resto de la frontera:
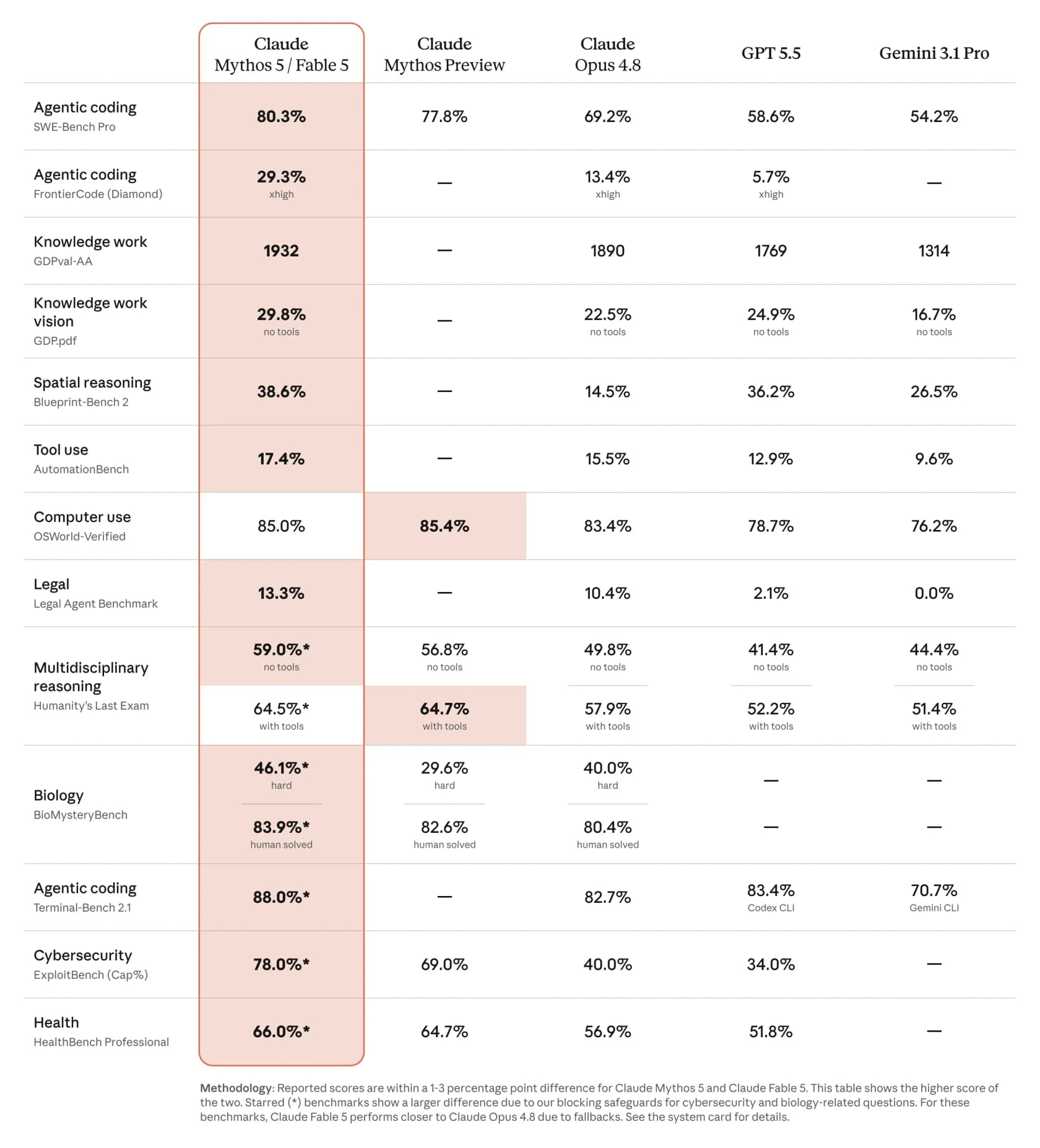
En SWE-Bench Pro (codificación agéntica), Fable 5 obtiene un 80,3 % frente al 69,2 % de Opus 4.8, con GPT 5.5 en un 58,6 % y Gemini 3.1 Pro en un 54,2 %. CNBC informó de la brecha como «más de un 10 % superior a Claude Opus 4.8» en algunos benchmarks. Cifras reales, ventaja real. La pega es lo que cuesta conseguirlas, a lo que volveremos.
Qué lo hace realmente diferente para las empresas
Muchos lanzamientos de modelos son unos cuantos puntos de benchmark y una nota de prensa. Fable 5 hace algo más específico: está construido para funcionar durante mucho tiempo sin desmoronarse. Esa es la capacidad que debería importarles a las empresas, no la tabla de clasificación.
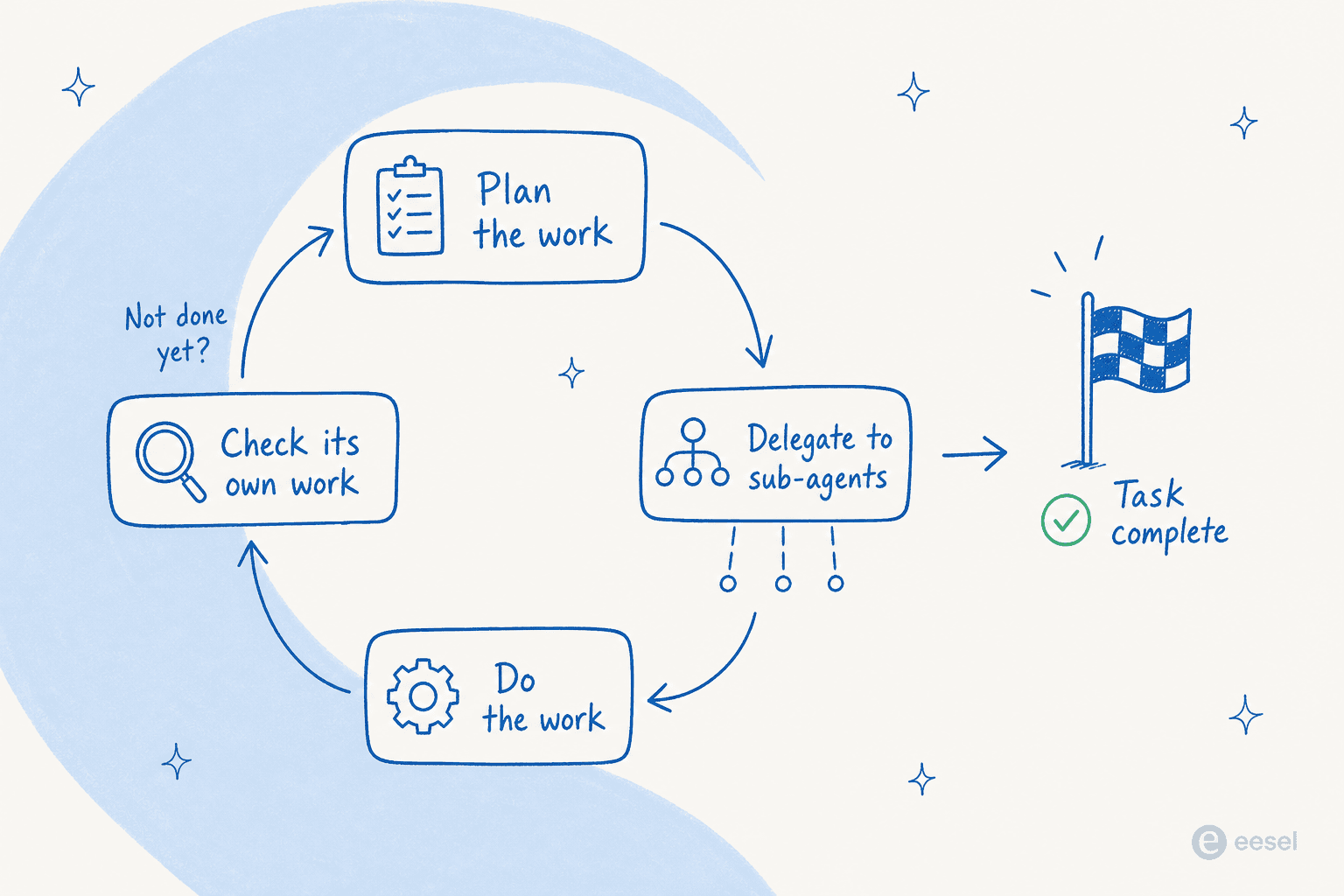
Puede trabajar durante días, no minutos
El caso de uso estrella es el trabajo autónomo de largo horizonte. Ejecuta Fable 5 dentro de un arnés de agentes como Claude Code o Claude Managed Agents y, en palabras de Anthropic, «puede trabajar durante días seguidos: planificando a lo largo de varias etapas, delegando en subagentes y revisando su propio trabajo». Stripe lo apuntó a una base de código Ruby de 50 millones de líneas y ejecutó una migración sobre todo el conjunto en un día.
Ese bucle —planificar, delegar, trabajar, revisar, repetir— es la parte que es genuinamente nueva. Los modelos anteriores se agotaban en tareas de varias etapas; este mantiene el equilibrio.
Las pruebas independientes coinciden con el marketing. El desarrollador Simon Willison pasó cinco horas y media con él y concluyó:
«This is something of a beast. It's slow, expensive and has been quite happily churning through everything I've thrown at it so far. As is frequently the case with current frontier models the challenge is finding tasks that it can't do.»
Lee los documentos desordenados que tu equipo tiene de verdad
Fable 5 «entiende diagramas, gráficos y tablas anidados en archivos y PDF», algo que Anthropic enmarca en torno al trabajo financiero, jurídico y de análisis. Un usuario de Hacker News informó de que marcó correctamente «hecho / algo hecho / faltante» a lo largo de un PDF de 50 páginas de especificaciones densas e interconectadas. Para cualquier empresa sentada sobre una pila de contratos, hojas de especificaciones o documentos de políticas, eso es más útil que un punto más en un benchmark de codificación.
Pone a prueba su propio trabajo
Anthropic comercializa Fable como «minucioso, proactivo y que pone a prueba su propio trabajo», y los proveedores de la nube describen un bucle de planificar / revisar / refinar integrado. La autocorrección es la diferencia entre un agente que tienes que vigilar y uno al que puedes dejar solo, que es exactamente lo que importa cuando estás automatizando trabajo real.
La pega que nadie pone en la página de inicio
Aquí es donde frenaríamos. Fable 5 es potente, pero las primeras 24 horas de uso en el mundo real sacaron a la luz algunos problemas muy prácticos, y todos cuestan dinero.
Consume el presupuesto rápido. Simon Willison registró un solo día de pruebas en 110,42 $ de gasto en tokens. Un usuario del plan Max agotó su límite de uso de 5 horas en 20 minutos ejecutando 1.000 subagentes; otro quemó una ventana entera de 5 horas en menos de 8 minutos más 15 $ de exceso. Cuando un modelo cuesta el doble y trabaja mucho más por tarea, la factura se acumula rápido.
Para ser justos, hay una contranarrativa que conviene tener presente: el responsable de evaluaciones de Canva descubrió que Fable usaba aproximadamente la mitad de los tokens de Opus 4.8 en sus arneses agénticos internos, así que el coste en el mundo real puede acabar siendo más o menos el mismo una vez que tienes en cuenta la eficiencia. La lección no es «Fable es inasequible», sino «tus costes dependen por completo de cómo lo ejecutes».
Su enrutamiento de seguridad puede fallar. Para temas de ciberseguridad, biología y química, Fable ejecuta clasificadores que enrutan silenciosamente la respuesta a Opus 4.8 en su lugar. Anthropic dice que al menos el 95 % de las sesiones se ejecutan enteramente en Fable sin ningún recurso de respaldo, pero ese 5 % incluye falsos positivos: a un usuario de la automatización de laboratorios se le denegó un protocolo básico de manejo de líquidos sin nada arriesgado en él. Si tu empresa está en un sector técnico, haz pruebas antes de comprometerte.
El precio que ves hoy puede no durar. Fable es gratis en los planes Pro, Max, Team y seat-Enterprise solo hasta el 22 de junio de 2026, después de lo cual pasa a créditos de uso. Construye tu flujo de trabajo asumiendo el precio medido, no la promoción de lanzamiento.
Nada de esto convierte a Fable 5 en un mal modelo. Lo convierte en una herramienta de frontera con economía de herramienta de frontera, y eso tiene consecuencias directas para cómo lo desplegarías de verdad.
Qué significa Claude Fable 5 para la atención al cliente
Aquí es donde vivimos, así que seamos concretos. Si diriges un equipo de soporte, ¿debería importarte Fable 5?
En su mayoría: no tanto como sugiere el bombo. Esta es la verdad incómoda sobre la IA para el servicio al cliente: para los tickets de nivel 1, el modelo rara vez es el cuello de botella. Un Opus 4.8 bien fundamentado o incluso Sonnet 4.6 ya responde correctamente la inmensa mayoría de las preguntas de tipo «dónde está mi pedido», «cómo restablezco mi contraseña», «cuál es vuestra política de reembolsos». Pagar el doble por Fable 5 para responderlas es como alquilar un coche de Fórmula 1 para llevar a los niños al colegio.
Lo que realmente decide si tu agente de mesa de ayuda con IA funciona es todo lo que rodea al modelo:
- ¿Conoce tu negocio? Un modelo es solo tan bueno como aquello en lo que está fundamentado. La ganancia viene de entrenar con tus tickets pasados y documentos de ayuda, no de un modelo base más inteligente.
- ¿Sabe cuándo callarse? Los modelos en bruto responden con seguridad incluso cuando se equivocan, que es precisamente por qué los chatbots dan malas respuestas. Los agentes en producción necesitan un enrutamiento basado en la confianza para que las preguntas con baja confianza se redacten o escalen, en lugar de enviarse automáticamente.
- ¿Puedes confiar en él antes de que salga en vivo? Necesitas ver la tasa de error en tus propios tickets primero, no descubrirla delante de los clientes.
Ese último punto es el que más les importa a los compradores. Los responsables de soporte con los que hablamos no piden una IA que responda todo; piden una que conozca sus límites. Como dijo la responsable de CX de una empresa de suplementos DTC en una entrevista con un cliente, la IA nunca responderá el 100 % de las preguntas, así que lo que realmente quieren es un agente que solo gestione los tickets de los que está seguro y deje el resto en paz. Eso es una capacidad de producto, no una capacidad de modelo.
Fable 5 no resuelve nada de eso por ti. Un modelo en bruto sin recuperación, sin enrutamiento y sin pruebas es un becario seguro de sí mismo con acceso a tu botón de responder. El nivel del modelo es la menor de tus preocupaciones.
Construir o comprar: ¿deberías cablear Fable 5 tú mismo?
Esta es la decisión real para una empresa, y surge constantemente. «Anthropic acaba de lanzar un modelo increíble, ¿por qué no construimos sin más nuestro bot de soporte sobre la API?»
Puedes. También es un proyecto más grande de lo que parece. El modelo te da inteligencia. No te da la conexión con tu mesa de ayuda, las barreras de seguridad, el entorno de simulación, los informes ni el mantenimiento continuo. Todo eso es tuyo, te toca construirlo y poseerlo.
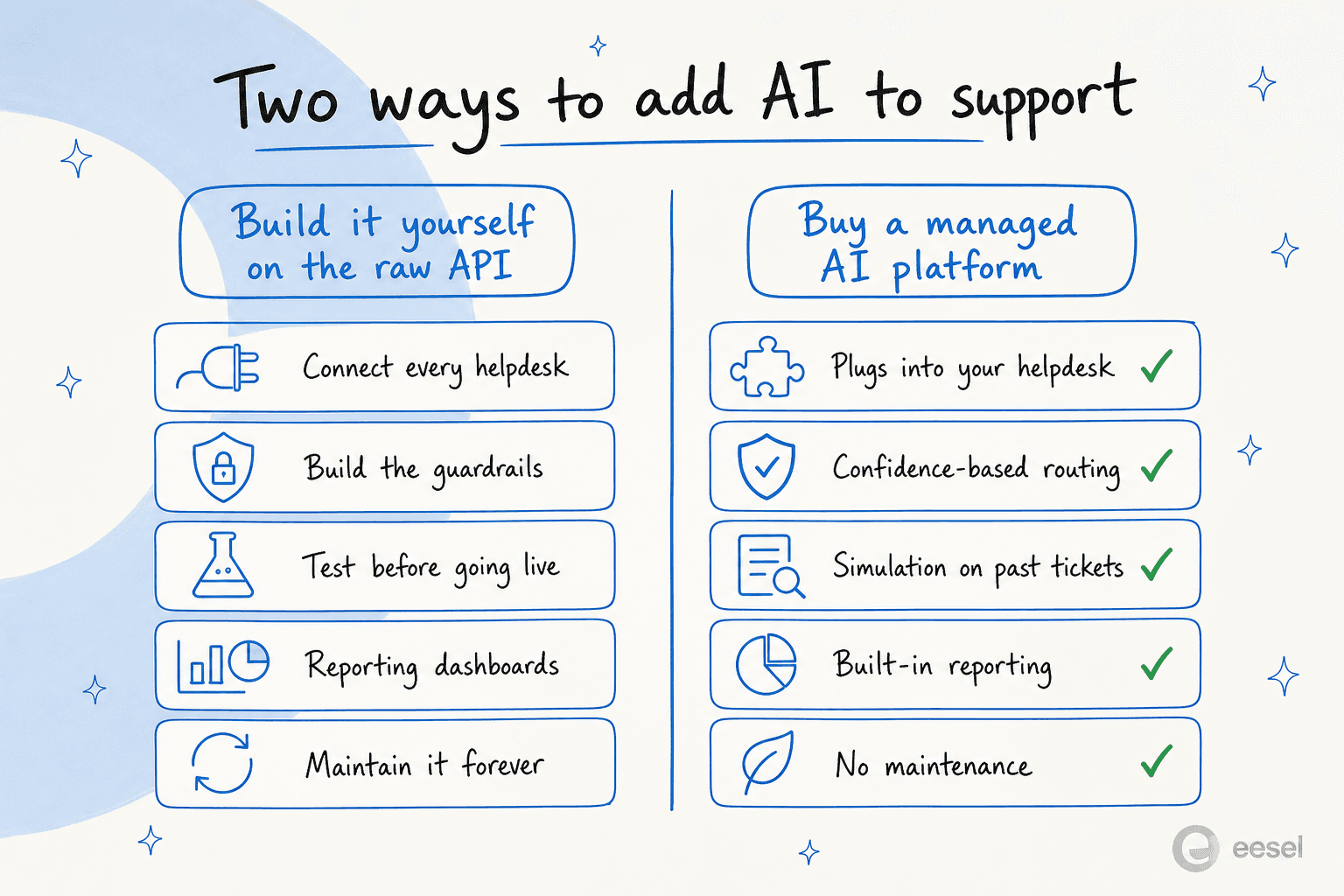
Vemos cómo termina esto, porque «lo construiremos sin más sobre la API de Claude» es una de las razones más comunes que dan los equipos técnicos antes de comprar. Algunos lo hacen de verdad. Varios que lo intentaron se pasaron luego a comprar en su lugar, porque mantener una app de LLM casera resultó ser un trabajo que nadie quería. Un cliente resumió el cálculo:
«We could try to write our own LLM application but we didn't want to invest our time into that. We wanted something that we would not have to maintain.»
La forma de pensarlo: un modelo de frontera es la capa más baja del stack, no todo el stack. Todo lo que lo convierte en un agente listo para el cliente se asienta encima, y esa es la parte que lleva tiempo.
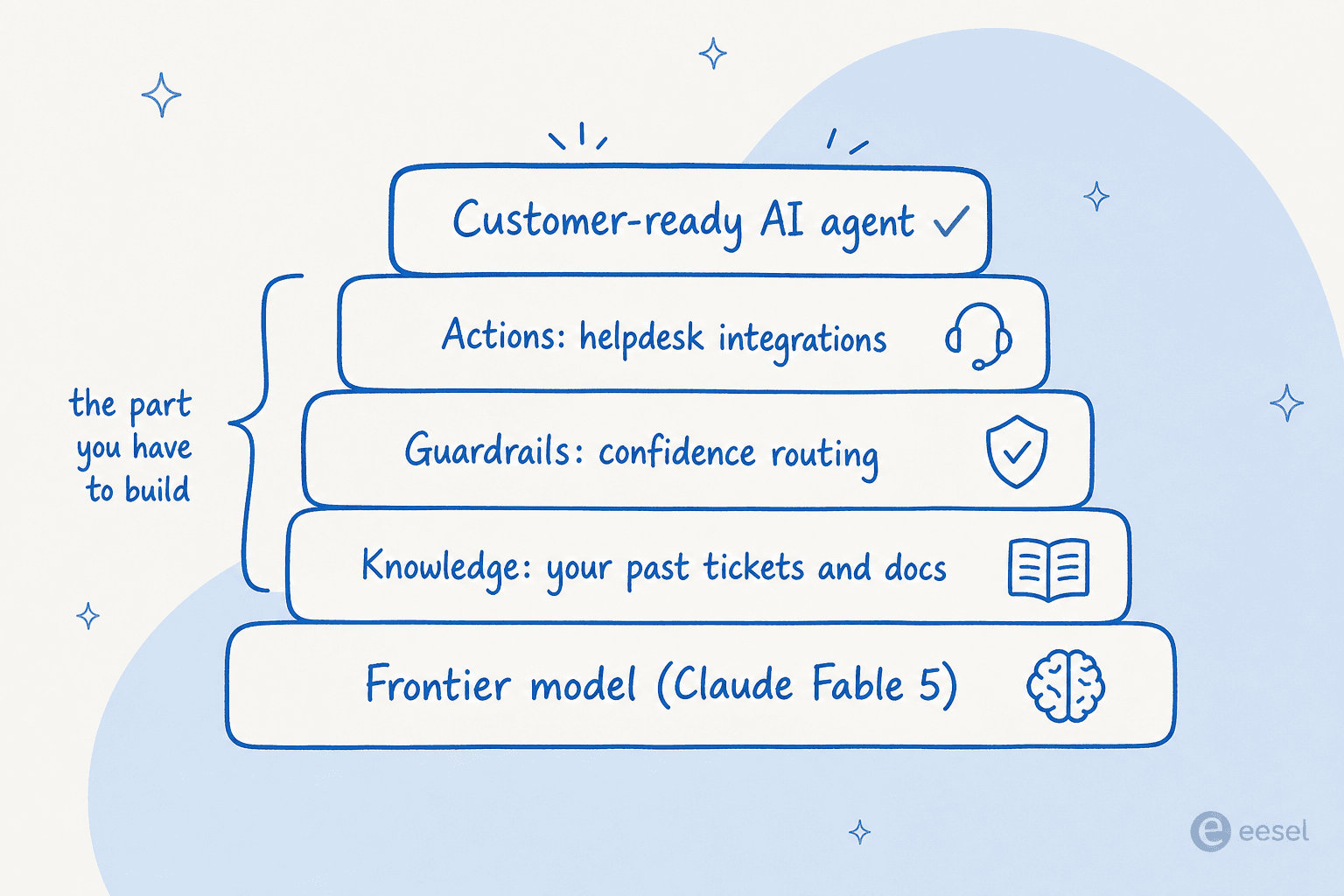
Si el producto principal de tu equipo es la IA, constrúyelo sin dudarlo. Si tu producto principal es cualquier otra cosa, y solo quieres que los tickets se respondan bien, comprar las capas por encima del modelo casi siempre es más rápido, más barato y menos frágil. Es la misma lógica detrás de elegir cualquier agente de IA frente a un chatbot basado en reglas: quieres el resultado, no el contrato de mantenimiento.
Prueba eesel
eesel AI es la capa que se asienta sobre modelos de frontera como Claude para que no tengas que construirla. Se conecta a tu mesa de ayuda existente (Zendesk, Freshdesk, HubSpot, Gorgias, Front y más de 100 integraciones), aprende de tus tickets pasados y documentos de ayuda desde el primer día, y responde en más de 80 idiomas, todo con precios basados en el uso que empiezan en 0,40 $ por ticket y sin tarifas por puesto.
El diferenciador que importa aquí es la parte que Fable 5 no puede darte por sí solo: un modo de simulación que ejecuta el agente contra miles de tus tickets pasados para que veas exactamente cómo habría respondido, y cuál sería tu tasa de resolución, antes de que un solo cliente hable con él. Así es como Gridwise llegó a resolver el 73 % de las solicitudes de nivel 1 en su primer mes, con resultados que aparecieron durante una prueba de 7 días.

Obtienes la inteligencia de la frontera, sin el proyecto de ingeniería. Puedes empezar gratis con 50 $ de uso y sin tarjeta de crédito.
Preguntas frecuentes
¿Qué es Claude Fable 5 y es bueno para empresas?
¿Cuánto cuesta Claude Fable 5?
¿Debería construir mi propio agente de soporte sobre la API de Claude Fable 5?
¿Es Claude Fable 5 mejor que Claude Opus 4.8 para la atención al cliente?
¿Qué pasa cuando Claude Fable 5 responde mal una pregunta de soporte?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








