
Dirijo IA en colas de soporte reales, así que aquí está mi lectura honesta
Empezaré por donde la mayoría de las explicaciones de modelos no empezarán, porque es la parte que realmente importa. He pasado años viendo cómo los modelos de frontera se encuentran con colas de soporte reales y desordenadas, y el patrón nunca cambia: el modelo rara vez es la parte difícil.
Algunos números de nuestros propios despliegues para fundamentar eso. Un cliente, Gridwise, vio cómo eesel resolvía el 73 % de sus solicitudes de nivel 1 en el primer mes, con resultados durante una prueba de 7 días. Otro, Smava, gestiona un agente de Zendesk completamente automatizado que procesa más de 100.000 tickets en alemán al mes. Nada de eso vino de elegir el modelo más inteligente. Vino de entrenar en tickets resueltos, enrutar por confianza y simular en el historial real antes de entrar en producción.
Así que cuando llega un nuevo Opus, la pregunta que me importa no es "¿es más inteligente en un benchmark?" Es "¿esto cambia lo que realmente enviaría a la bandeja de entrada de un cliente?" Miremos Opus 4.8 con ese enfoque.
¿Qué es Claude Opus 4.8?
Claude Opus 4.8 es el último modelo de la familia Opus de Anthropic, el nivel de alta capacidad de Claude. Anthropic lo lanzó el 28 de mayo de 2026 y lo presenta como un "colaborador más eficaz" que "se basa en Opus 4.7 con mejoras en todos los benchmarks." En la API, se llama con el ID de modelo claude-opus-4-8.
Las especificaciones principales son fáciles de resumir: una ventana de contexto de 1M tokens al precio estándar, hasta 128k tokens de salida y pensamiento adaptativo que el modelo controla por sí mismo (ya no hay un interruptor de pensamiento extendido separado que gestionar). Lee texto e imágenes, maneja más de 80 idiomas y sus datos de entrenamiento llegan hasta enero de 2026 (descripción general de modelos).
El propio encuadre de Anthropic del salto es refrescantemente poco exagerado. El anuncio lo llama una "mejora modesta pero tangible sobre su predecesor," que es también cómo lo tituló el hilo de Hacker News. Si recuerdas los saltos generacionales más grandes, este no es uno de ellos. Es un lanzamiento de pulido y corrección, y está bien; las correcciones son la parte interesante.
Novedades en Opus 4.8
Algunos cambios merecen ser conocidos, especialmente si estás eligiendo un modelo para construir en lugar de solo chatear.
La honestidad mejoró de verdad. Anthropic llama esto "una de las mejoras más destacadas," y es la que realmente me pagaría. Se dice que Opus 4.8 tiene alrededor de cuatro veces menos probabilidades que 4.7 de dejar pasar sin comentar los fallos en su propio código, y está más dispuesto a señalar la incertidumbre en lugar de inventar una respuesta con confianza. Para cualquiera que despliegue IA donde una respuesta incorrecta tiene un coste, "te dice cuando no está seguro" vale más que otro punto en un benchmark de codificación.
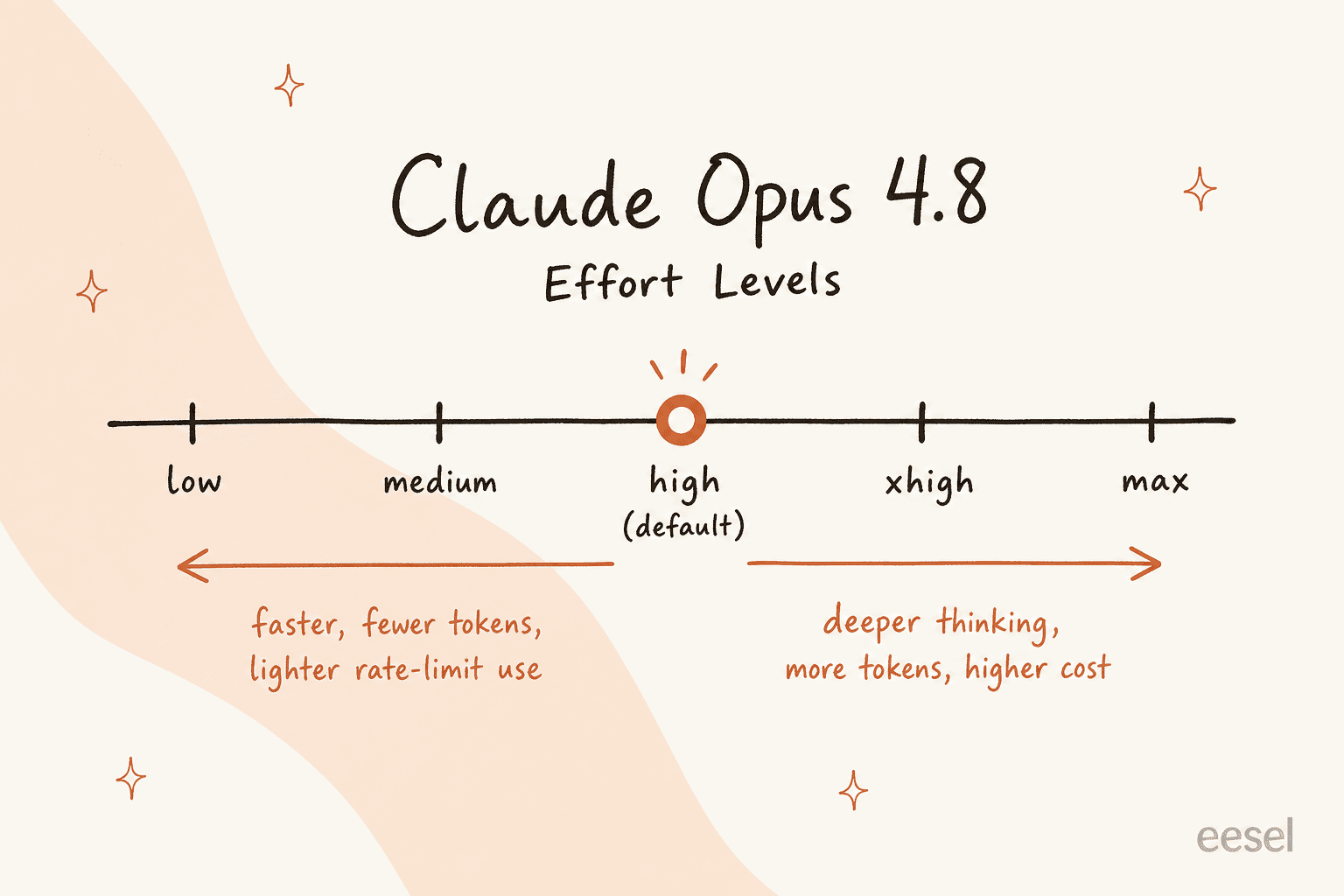
Un control de esfuerzo. Ahora hay un dial que establece cuánto trabaja el modelo en una respuesta, desde low hasta max (con xhigh entre high y max). El valor predeterminado es high. Súbelo para un razonamiento más profundo, bájalo para mayor velocidad y uso más ligero. El compromiso es real y vale la pena entenderlo antes de integrarlo en cualquier cosa.
Flujos de trabajo dinámicos en Claude Code. En Claude Code, Opus 4.8 puede planificar un trabajo, desplegar cientos de subagentes paralelos en una sesión y luego verificar su salida antes de informar, lo que está orientado al trabajo a escala de codebase como migraciones en cientos de miles de líneas. Si usas subagentes de Claude Code, esta es la funcionalidad a probar.
Instrucciones del sistema a mitad de tarea. Para los desarrolladores, la API de Messages ahora acepta entradas system dentro del array de mensajes, para que puedas actualizar instrucciones, permisos o presupuestos de tokens a mitad de la ejecución sin romper tu caché de prompts. Cambio pequeño, genuinamente útil si estás construyendo agentes.
Una voz más cálida. Los primeros probadores lo describen como más fácil de colaborar y mejor para mantener el contexto y el estilo a lo largo de una sesión larga. El lado negativo aparece en la reacción de la comunidad a continuación.
Precios de Claude Opus 4.8 y su posición en la gama
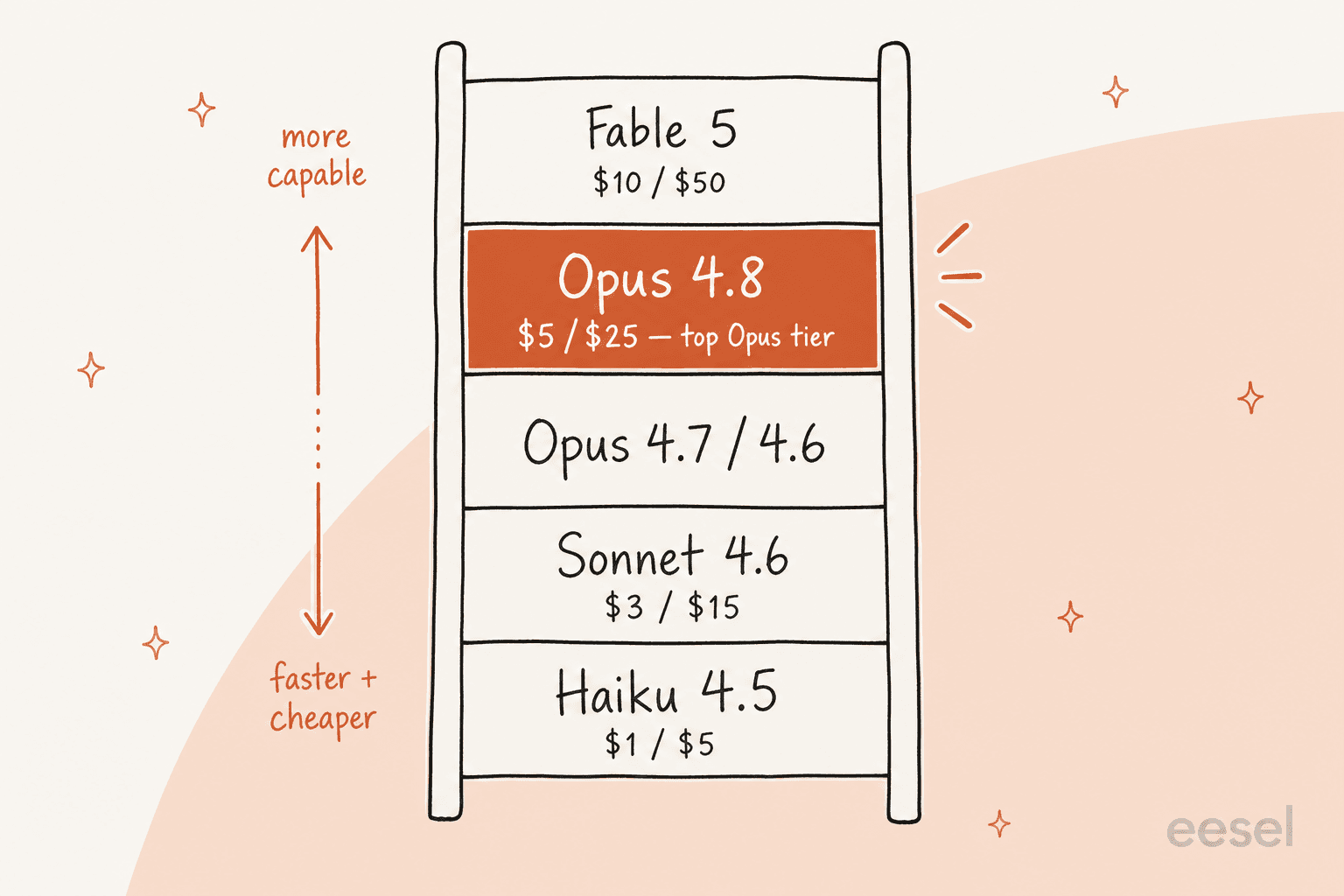
Los precios son la parte fácil, porque no cambiaron. Opus 4.8 cuesta 5 $ por millón de tokens de entrada y 25 $ por millón de tokens de salida, exactamente igual que Opus 4.7 (página de precios). También hay un modo rápido que funciona a 2,5 veces la velocidad y, según Anthropic, cuesta notablemente menos que el modo rápido en modelos anteriores.
Aquí está la gama completa de Claude a mediados de 2026, que es el contexto que necesitas para elegir realmente un modelo:
| Modelo | Entrada / salida (por 1M tokens) | Contexto | Mejor para |
|---|---|---|---|
| Claude Fable 5 | 10 $ / 50 $ | 1M | El modelo más capaz y ampliamente disponible de Anthropic |
| Claude Opus 4.8 | 5 $ / 25 $ | 1M | Mejor nivel Opus; razonamiento complejo, agentes de largo horizonte |
| Claude Opus 4.7 / 4.6 | 5 $ / 25 $ | 1M | Las generaciones Opus anteriores |
| Claude Sonnet 4.6 | 3 $ / 15 $ | 1M | Mejor equilibrio entre velocidad e inteligencia |
| Claude Haiku 4.5 | 1 $ / 5 $ | 200k | El más rápido y económico, para tareas simples de alto volumen |
Lo que hay que notar: Opus 4.8 es el modelo de nivel Opus más potente, pero ya no es la cima de todo el stack. Aproximadamente dos semanas después de su lanzamiento, Anthropic lanzó Claude Fable 5 como su modelo ampliamente disponible más capaz, al doble de precio. Así que Opus 4.8 es el estándar sensato de alta capacidad; Fable 5 es la opción "el dinero no importa, dame lo absolutamente mejor." Pusimos cara a cara la generación anterior con rivales en Gemini 3 Pro vs Claude Opus 4.6 si quieres una idea de cómo se comparan los modelos de Anthropic.
Una trampa de costes que vale la pena señalar, porque sorprende a la gente: Opus 4.7 y versiones posteriores usan un nuevo tokenizador que "puede usar hasta un 35 % más de tokens para el mismo texto fijo." Así que incluso a un precio de lista sin cambios, tu coste real por tarea puede aumentar frente a un modelo más antiguo. Ese detalle explica mucho del murmullo de la comunidad, lo que me lleva a la siguiente parte. (Si los precios son tu razón principal para leer esto, nuestra guía de precios de Claude repasa nivel por nivel.)
Lo que la gente dice realmente
La lectura más clara de la reacción de la comunidad es que Opus 4.8 es la corrección de un 4.7 que la gente abiertamente no quería. Las opiniones de "regreso a la forma" están por todas partes y coinciden con nuestra reseña de Claude a largo plazo. Un desarrollador, unas horas después de probarlo en r/ClaudeAI, lo expresó bien:
"4.8 es preciso, piensa rápido y no ha alucinado nada. Cuando no sabe algo, me pregunta directamente en lugar de inventarse algo. Se siente como en lo que debería haberse convertido 4.6."
Eso coincide con las afirmaciones de honestidad de Anthropic y es el positivo más repetido. Pero dos tensiones honestas merecen exponerse, porque son el tipo de cosas que una página de marketing no te dirá.
Primero, es voraz. La queja más común es que Opus 4.8 agota los límites de uso rápidamente, en parte gracias a ese nuevo tokenizador. Como señaló un usuario en un hilo que lo compara con GPT-5.5:
"Opus 4.8 es una bestia, mucho mejor que 4.7 en ejecución pero también en diseño, creo; el problema real son los tokens, consume muchos más tokens y por primera vez alcancé un límite dentro de mi suscripción máxima."
Segundo, la autonomía no es magia. Los usuarios avanzados que ejecutan tareas largas y difíciles informan que Opus 4.8 todavía necesita un alcance ajustado, con un arquitecto de sistemas cuantitativos señalando que "para usar Opus 4.8 de manera efectiva, el humano todavía necesita pensar mucho. Necesitas definir más, guiar más y mantener más del contexto tú mismo." Y el lado negativo de las celebradas ganancias de honestidad es que una minoría vocal lo encuentra demasiado cauteloso o apologético para el trabajo creativo abierto. Nada de esto es condenatorio. Es simplemente la imagen calibrada: un modelo potente, honesto y hambriento de tokens que recompensa las instrucciones claras.
Lo que un modelo más inteligente significa realmente para el soporte al cliente
Aquí llego a lo que realmente sé. Si diriges un equipo de soporte, la tentación cuando llega un modelo como Opus 4.8 es pensar "genial, el soporte de IA acaba de mejorar." A veces. Pero el modelo es el motor, no el coche, y vale la pena ser preciso sobre de qué está hecho realmente el software de servicio al cliente con IA.
He visto a muchos equipos técnicamente competentes llegar a la misma conclusión por las malas. Hemos visto clientes marcharse para integrar la API de Claude por sí mismos, razonando que si Opus es tan bueno, pueden llamarla directamente. Unos meses después, la realidad del mantenimiento se impone. Un jefe de ingeniería que eligió comprar en lugar de construir resumió el cálculo claramente: podía escribir su propia aplicación LLM, pero "no quería invertir tiempo en eso" y quería "algo que no tendríamos que mantener."
Eso es porque un agente de soporte en producción es el modelo más una gran cantidad de andamiaje poco glamoroso:
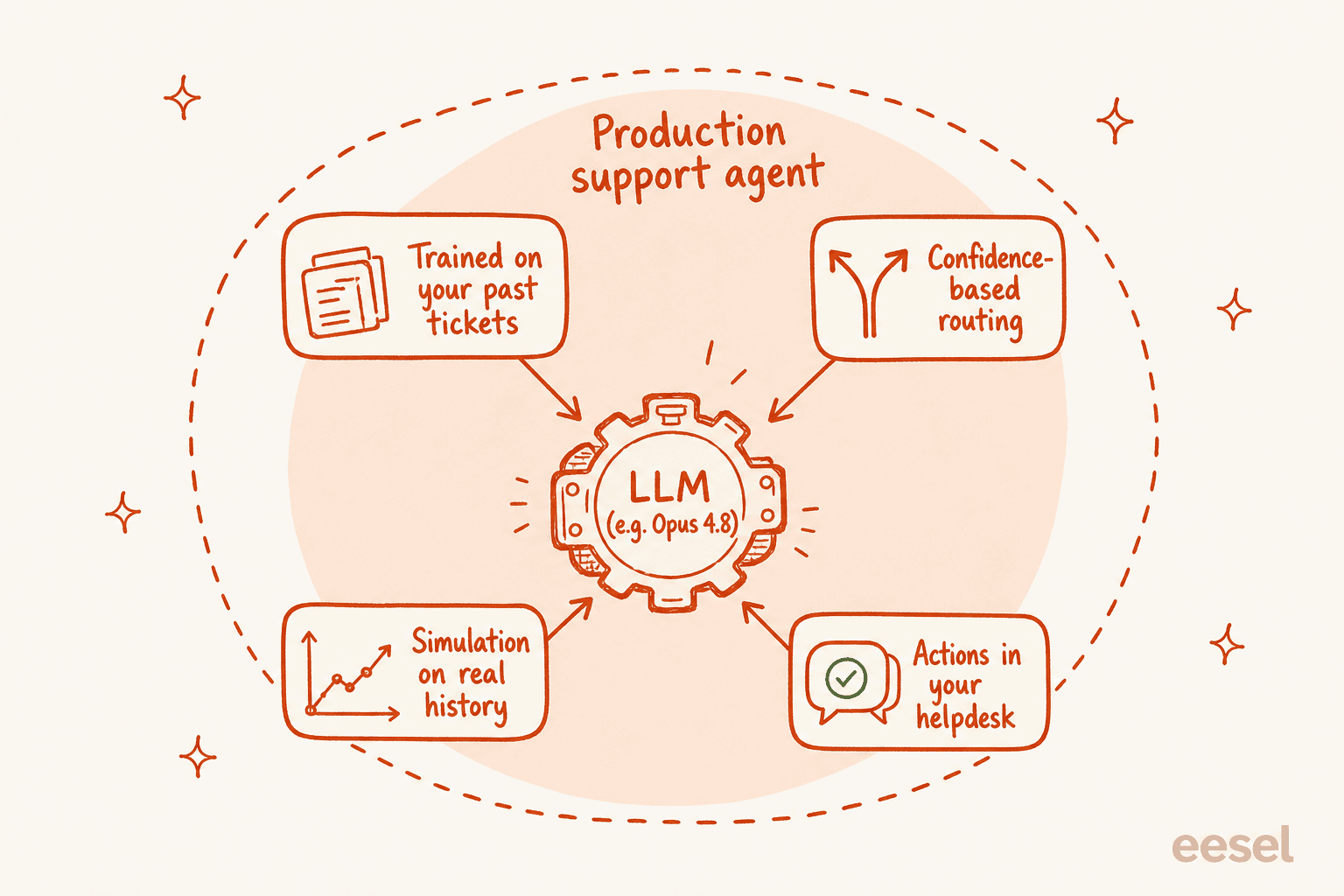
- Tu conocimiento, no el del modelo. La fecha de corte de entrenamiento de Opus 4.8 en enero de 2026 no sabe nada sobre tu política de reembolsos o la interrupción de la semana pasada. Un agente útil aprende de tus tickets anteriores, documentación de ayuda y macros, no del conocimiento general del mundo.
- Enrutamiento basado en confianza. Las ganancias de honestidad en Opus 4.8 son reales, pero aún no quieres que un modelo decida por sí solo cuándo responder en vivo. Quieres que redacte cuando no esté seguro y solo envíe automáticamente cuando esté seguro, lo cual es una salvaguarda a nivel de sistema, no una configuración del modelo.
- Una forma de probar antes de entrar en producción. Antes de que un solo cliente vea una respuesta de IA, quieres ejecutar el sistema contra miles de tus tickets reales y resueltos y ver exactamente dónde habría acertado o fallado. Elegir un modelo más nuevo no te da eso; la simulación sí.
- Acciones, no solo respuestas. Etiquetar, clasificar, buscar un pedido, escalar limpiamente a un humano. Todo eso vive en tus integraciones de helpdesk, no en el modelo en bruto.
Esta también es la razón por la que "qué modelo es mejor" es la pregunta equivocada para soporte. Hemos encontrado que un sistema bien construido sobre un modelo de nivel medio generalmente supera a un modelo de frontera en bruto sin andamiaje, que es el punto central de nuestro artículo sobre qué LLM es mejor para casos de uso de soporte. Que Opus 4.8 sea más honesto son buenas noticias; simplemente no cambia la forma del trabajo. Si estás sopesando construir tu propio soporte de IA frente a comprar una plataforma, el modelo es la parte barata y fácil. El resto es el trabajo.
Prueba eesel
Si has llegado hasta aquí, probablemente estés menos interesado en los deltas de benchmarks y más en si la IA puede tomar tickets de forma segura de tu equipo. Eso es exactamente lo que hace eesel AI: se sitúa sobre modelos de frontera como Claude (para que obtengas el razonamiento de clase Opus sin tener que gestionar la infraestructura), aprende de tus tickets anteriores y documentos de ayuda, enruta por confianza para que solo responda automáticamente cuando esté seguro, y te permite simular con tu historial real de tickets antes de hablar con un cliente. El precio es por uso sin tarifas por puesto, así que un mes más tranquilo cuesta menos en lugar de lo mismo.

Puedes conectar tu helpdesk y tener una simulación funcionando en minutos. Prueba eesel y apúntalo a tus propios tickets para ver qué resolvería realmente.
Preguntas frecuentes
¿Qué es Claude Opus 4.8?
¿Cuánto cuesta Claude Opus 4.8?
¿Cuál es la diferencia entre Claude Opus 4.8 y Opus 4.7?
¿Es Claude Opus 4.8 bueno para el soporte al cliente?
¿Debería construir mi propio soporte de IA sobre la API de Claude Opus 4.8?
¿Dónde se ubica Claude Opus 4.8 en la gama de Anthropic?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.






