Implemento IA en colas de soporte reales, así que esta es mi lectura empresarial
Empezaré donde la mayoría de los artículos sobre modelos no empiezan, porque es el punto que decide si Opus 4.8 hace mella en su negocio. He pasado años viendo cómo los modelos de frontera se encuentran con colas de soporte reales y desordenadas, y la lección nunca cambia: el modelo rara vez es la parte difícil.
Un par de cifras para fundamentarlo, ambas de nuestros propios despliegues. Gridwise vio cómo eesel resolvía el 73% de sus solicitudes de nivel 1 en el primer mes, con resultados dentro de una prueba de 7 días. Smava gestiona un agente de Zendesk completamente automatizado que procesa más de 100.000 tickets en alemán al mes. Ninguno de estos resultados provino de elegir el modelo más inteligente. Vinieron de entrenar con tickets resueltos, enrutar por confianza y simular contra el historial real antes de entrar en producción.
Así que cuando llega un nuevo Opus, la pregunta que me importa para una empresa no es "¿es más inteligente en un benchmark?". Es "¿cambia esto lo que realmente enviaría a la bandeja de entrada de un cliente o a la mesa de mi equipo?". Veamos Opus 4.8 con esa lente.
Qué es Claude Opus 4.8 en términos empresariales
Claude Opus 4.8 es el último modelo de la familia Opus de Anthropic, el nivel de alta capacidad de Claude. Se lanzó el 28 de mayo de 2026 como sucesor de Opus 4.7, y en la API se invoca como claude-opus-4-8. Si prefiere la explicación general en lugar del enfoque empresarial, hemos escrito un artículo separado sobre qué es Claude Opus 4.8.
Las especificaciones clave que importan a un comprador: una ventana de contexto de 1M tokens al precio estándar, hasta 128k tokens de salida, y pensamiento adaptativo que el modelo gestiona por sí mismo (sin interruptor de pensamiento extendido que administrar). Lee texto e imágenes, maneja más de 80 idiomas, y su entrenamiento llega hasta enero de 2026 (resumen de modelos). Anthropic lo lanza en todas partes desde el primer día, incluidos AWS Bedrock, Vertex AI y Microsoft Foundry, lo que importa si su equipo de compras ya tiene una nube preferida.
El propio marco de Anthropic para describir el salto es refrescantemente moderado. El anuncio lo califica como una "mejora modesta pero tangible respecto a su predecesor", y esa es la expectativa correcta para comunicar internamente. Es una versión de pulido y corrección, no un salto generacional, y las correcciones son donde reside el valor empresarial.
Qué cambió realmente para los compradores en Opus 4.8
Algunos cambios vale la pena conocer si está decidiendo en qué estandarizar su equipo, no solo si quiere chatear con él.
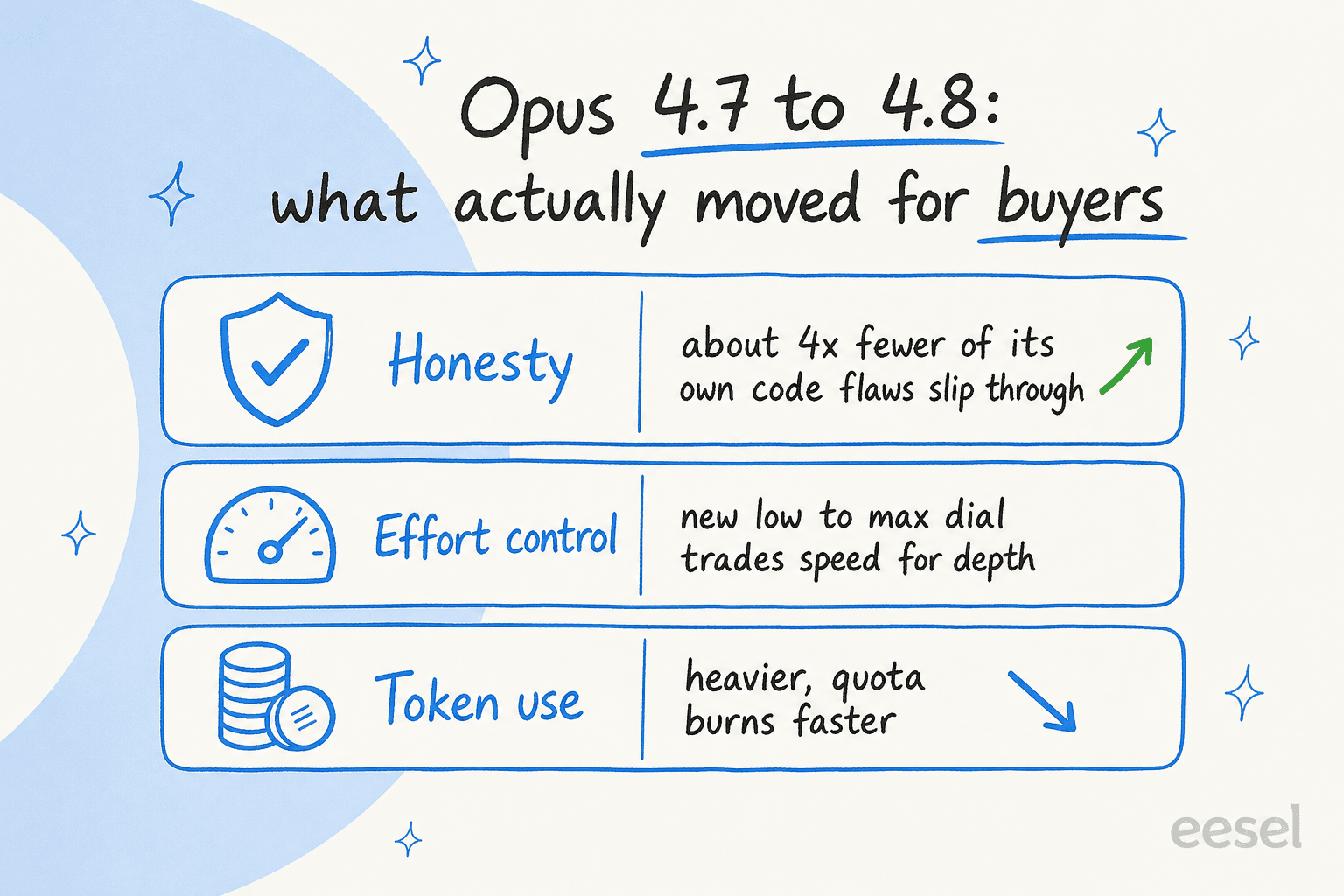
La honestidad recibió una mejora real. Anthropic llama a esto "una de las mejoras más destacadas", y es por lo que yo pagaría en un entorno empresarial. Se informa que Opus 4.8 es aproximadamente cuatro veces menos propenso que el 4.7 a dejar pasar defectos en su propio código sin comentario, y está más dispuesto a señalar la incertidumbre que a inventar una respuesta con confianza. En cualquier lugar donde una respuesta incorrecta tenga un costo —en finanzas, legal, soporte regulado— "te dice cuándo no está seguro" supera a un punto más en un benchmark de programación.
Un nuevo control de esfuerzo. Ahora hay un control que establece cuánto trabaja el modelo, desde low hasta max, con high como predeterminado (anuncio). Para una empresa, esto es una palanca de presupuesto: súbalo para el análisis difícil, bájelo para las tareas rutinarias de alto volumen donde la velocidad y el costo importan más que la profundidad.
Trabajo agéntico a largo plazo. En Claude Code, Opus 4.8 puede planificar un trabajo, lanzar cientos de subagentes paralelos en una sesión y luego verificar el resultado antes de informar, orientado al trabajo a escala de base de código como grandes migraciones (publicación dynamic-workflows). Si dirige una organización de ingeniería, este es el titular. La System Card afirma que el rendimiento es "superior al de Opus 4.7 en casi todas las evaluaciones".
El inconveniente: consume mucho. La queja más repetida de la comunidad es que Opus 4.8 agota los límites de uso, en parte porque Opus 4.7 y versiones posteriores usan un nuevo tokenizador que "puede usar hasta un 35% más de tokens para el mismo texto fijo". Así que incluso con un precio de catálogo sin cambios, su costo real por tarea puede aumentar. Planifique para ello.
Precios de Claude Opus 4.8 para empresas
Los precios son la parte fácil, porque no se movieron. Opus 4.8 cuesta $5 por millón de tokens de entrada y $25 por millón de tokens de salida, idéntico a Opus 4.7 (página de precios). También hay un modo rápido que funciona a 2,5 veces la velocidad y, según Anthropic, cuesta notablemente menos que el modo rápido en modelos anteriores.
Aquí está la gama más amplia a mediados de 2026, que es el contexto que necesita para elegir realmente un modelo para una carga de trabajo:
| Modelo | Entrada / salida (por 1M de tokens) | Contexto | Mejor para |
|---|---|---|---|
| Claude Fable 5 | $10 / $50 | 1M | El modelo más capaz de Anthropic ampliamente disponible |
| Claude Opus 4.8 | $5 / $25 | 1M | Top nivel Opus; razonamiento complejo, agentes a largo plazo |
| Claude Opus 4.7 / 4.6 | $5 / $25 | 1M | Las generaciones Opus anteriores |
| Claude Sonnet 4.6 | $3 / $15 | 1M | Mejor equilibrio entre velocidad e inteligencia |
| Claude Haiku 4.5 | $1 / $5 | 200k | El más rápido y económico para tareas simples de alto volumen |
Lo que hay que señalar para finanzas: el precio de catálogo por token es la línea más pequeña en su factura real. La mayor parte del costo de ejecutar un modelo en producción es todo lo que lo rodea. Esa es la trampa en la que veo caer a las empresas.
Si los precios son su única razón para leer, nuestra guía de precios de Claude va nivel por nivel, y los precios de Claude Pro cubre los planes por asiento en los que su equipo ya podría estar. Para el cálculo específico de soporte, costo de agente de IA vs. agente humano es la comparación más útil que una tasa de token bruta.
¿Construir sobre la API o comprar una plataforma?
Esta es la decisión real que enfrentan la mayoría de las empresas cuando llega un modelo como Opus 4.8, y la respuesta honesta depende de lo que esté construyendo.
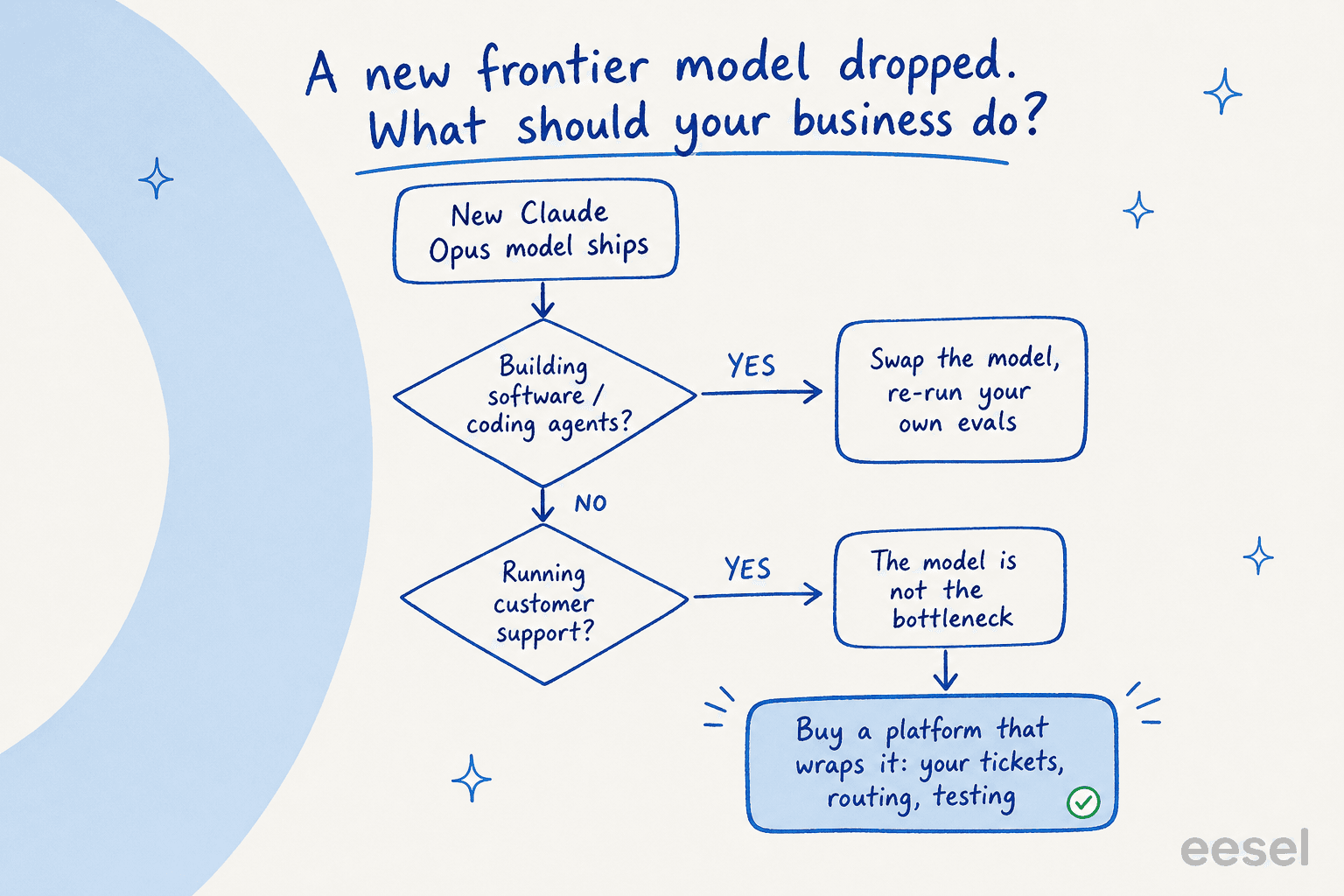
Si está lanzando un producto de software o un flujo de trabajo de programación, construir directamente sobre la API de Claude suele ser la decisión correcta: cambie el nuevo modelo, vuelva a ejecutar sus propias evaluaciones, lance. El modelo es el producto ahí.
Para un flujo de trabajo empresarial como soporte al cliente, es lo contrario. He visto a muchos equipos capaces llegar a esto por las malas. Hemos visto clientes que se fueron a conectar la API de Claude por sí mismos, razonando que si Opus es tan bueno, pueden llamarlo directamente. Unos meses después, la realidad del mantenimiento se instala. Un líder de ingeniería que eligió comprar en su lugar planteó el cálculo claramente:
"Podríamos haber intentado escribir nuestra propia aplicación LLM, pero no queríamos invertir nuestro tiempo en eso. Queríamos algo que no tuviéramos que mantener."
Eso proviene del caso práctico de GENERAL BYTES, un equipo de ingeniería en una empresa de hardware cripto que eligió comprar en lugar de construir. Es la versión más común de la historia: la llamada a la API es trivial, y la recuperación, las barreras y el mantenimiento son el trabajo real. El mismo patrón aparece en las decisiones de RAG vs. LLM: el modelo rara vez es donde vive el trabajo.
Qué hace (y no hace) un modelo más inteligente para el soporte
Aquí es donde llego a lo que realmente sé. Si dirige un equipo de soporte, la tentación cuando llega Opus 4.8 es pensar "genial, el soporte de IA mejoró". A veces. Pero vale la pena ser preciso sobre de qué está hecho realmente el software de atención al cliente con IA, porque un modelo de frontera es solo una parte de ello.
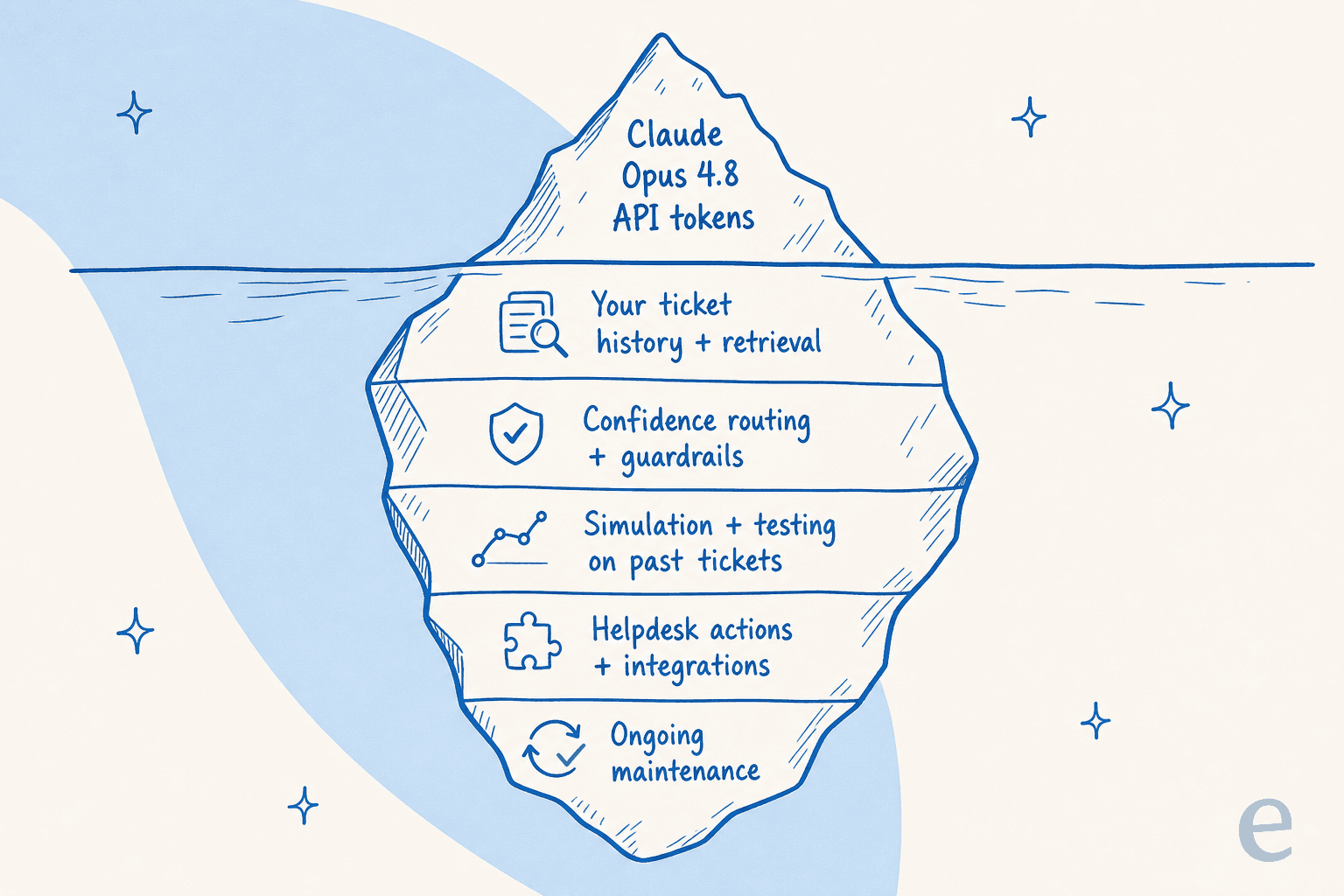
Un agente de soporte en producción es el modelo más mucho andamiaje poco glamoroso que Opus 4.8 simplemente no incluye:
- Su conocimiento, no el del modelo. El corte de entrenamiento de enero de 2026 de Opus 4.8 no sabe nada sobre su política de reembolso o la interrupción de la semana pasada. Un agente útil aprende de sus tickets anteriores, documentos de ayuda y macros, que es el punto ciego del conocimiento general del mundo. (Qué es RAG cubre el lado de la recuperación.)
- Enrutamiento basado en confianza. Las ganancias de honestidad en Opus 4.8 son reales, pero aún así no quiere que un modelo decida por sí solo cuándo responder en vivo. Quiere que redacte cuando no está seguro y solo envíe automáticamente cuando esté seguro, que es una barrera de protección a nivel del sistema, no una configuración del modelo.
- Una forma de probar antes de ir en vivo. Antes de que un solo cliente vea una respuesta de IA, quiere ejecutarla contra miles de sus tickets reales y resueltos y ver exactamente dónde habría acertado o fallado. Un modelo más nuevo no le da eso; la simulación sí.
- Escalada limpia y acciones. Etiquetado, triaje, búsqueda de un pedido, transferencia a un humano. Eso vive en sus integraciones de helpdesk, no en el modelo sin procesar.
Por eso "¿qué modelo es el mejor?" suele ser la pregunta equivocada para un equipo de soporte. Hemos encontrado que un sistema bien construido sobre un modelo de nivel medio a menudo supera a un modelo de frontera sin andamiaje, que es todo el argumento en qué LLM es el mejor para casos de uso de soporte. Que Opus 4.8 sea más honesto es una buena noticia; simplemente no cambia la forma del trabajo ni mueve la tasa de resolución por sí solo. Si está evaluando la mejor IA para servicio al cliente o mirando alternativas a Claude para un flujo de trabajo, el modelo es la parte barata y fácil. El resto es el trabajo.
Una divulgación, ya que solo es justo: construimos sobre modelos de frontera como Claude, así que tengo un interés en esto. Eso también es por qué confío en que el modelo no es la ventaja competitiva; he visto la diferencia que hace un sistema bien construido en cientos de equipos que usan IA para servicio al cliente.
Pruebe eesel
Si ha llegado hasta aquí, probablemente esté menos interesado en los deltas de benchmark y más interesado en si la IA puede quitar trabajo de forma segura de la mesa de su equipo. Eso es lo que hace eesel AI: se sienta sobre modelos de frontera como Claude (para que obtenga razonamiento de clase Opus sin poseer ninguna de la infraestructura), aprende de sus tickets anteriores y documentos de ayuda, enruta por confianza para que solo responda automáticamente cuando está seguro, y le permite simular en su historial de tickets real antes de que hable con un cliente. Los precios son basados en uso sin tarifas por asiento, por lo que un mes más tranquilo cuesta menos.

Puede conectar su helpdesk y tener una simulación en marcha en minutos. Pruebe eesel y apúntelo a sus propios tickets para ver qué resolvería realmente, sin necesidad de un modelo más inteligente.
Preguntas frecuentes
¿Es Claude Opus 4.8 adecuado para uso empresarial?
¿Cuánto cuesta Claude Opus 4.8 para una empresa?
¿Debería mi empresa construir sobre la API de Claude Opus 4.8 o comprar una plataforma?
¿Qué cambió en Claude Opus 4.8 respecto a Opus 4.7?
¿Puede Claude Opus 4.8 gestionar mi soporte al cliente por sí solo?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.