
Resumen
AA-Briefcase es un nuevo benchmark de Artificial Analysis que califica modelos de IA en trabajo del conocimiento real de varias semanas (modelos financieros, presentaciones para la junta, especificaciones de producto) en lugar de preguntas aisladas. Cada modelo recibe miles de archivos desordenados (correos electrónicos, hilos de Slack, hojas de cálculo) y debe producir entregables reales, que se puntúan por corrección, calidad analítica y presentación.
El hallazgo principal es revelador: incluso el mejor modelo supera todos los criterios de la rúbrica en solo el 3 % de las tareas, y en 31 de 91 tareas ningún modelo supera el 50 %. Claude Fable 5 encabeza el leaderboard, con el open-weight GLM-5.2 rindiendo muy por encima de su precio.
Aquí está la parte que la mayoría de las coberturas omite: una alta puntuación en el benchmark indica que un modelo es capaz en general, no que sea seguro con tus datos. Esa brecha es la razón exacta por la que creo que cualquiera que busque servicio al cliente con IA debería probar con su propio trabajo histórico antes de salir en vivo, en lugar de confiar simplemente en un leaderboard.
Yo construyo agentes de IA a diario en eesel, así que un benchmark que finalmente mide el trabajo real desordenado en lugar de trivialidades es algo que me hace dejar todo lo que estoy haciendo para leerlo. A continuación, explico qué mide realmente AA-Briefcase, cómo califica, quién está ganando y la única lección que extraería de él para cualquier despliegue de agentes de IA.
Qué mide realmente AA-Briefcase
La mayoría de los benchmarks de IA hacen preguntas cortas y autocontenidas: un problema de matemáticas, un rompecabezas de programación, un cuestionario de opción múltiple. Eso está bien para medir el razonamiento en bruto, pero no se parece en nada a cómo la gente usa realmente estos modelos en el trabajo. El trabajo del conocimiento real es largo, ambiguo y está enterrado en el desorden.
AA-Briefcase fue construido para cerrar esa brecha. En lugar de un prompt, cada modelo es lanzado a un proyecto empresarial de varias semanas con muchas tareas vinculadas y miles de archivos fuente, y se le pide que produzca el tipo de entregables que haría un analista o un PM real: modelos financieros, presentaciones para la junta, maquetas de diseño, memorandos de estrategia. Los escenarios fueron desarrollados durante meses por expertos de la industria de empresas como Google, McKinsey y Boston Consulting Group, por lo que el trabajo se parece a lo que esas empresas hacen realmente.
Los números dan una idea de la escala. Hay cuatro escenarios de proyectos reservados y 91 tareas en total, extraídas de ciencia de datos, gestión de productos y estrategia corporativa. A través de ellos hay casi 2.000 archivos fuente, incluyendo más de 3.500 correos electrónicos y 25.000 mensajes de Slack, deliberadamente fragmentados y llenos de contradicciones realistas. Los cuatro escenarios de puntuación son un proyecto de Ciencia de Datos, un proyecto de Gestión de Productos, una transformación de Operaciones Bancarias y un proyecto de Estrategia de Industria Pesada; un quinto escenario de Due Diligence es público y no cuenta para las puntuaciones.
Ese marco importa porque refleja el modo de fallo de cada agente de IA que he lanzado: el modelo raramente lucha con la idea, lucha con encontrar el requisito oculto en el archivo 1.400 sin contradecir el correo que silenciosamente lo anuló.
Cómo califica AA-Briefcase a un modelo
Aquí es donde AA-Briefcase se vuelve inteligente. Una puntuación única ocultaría lo más interesante sobre la producción de IA, que es que parecer profesional y ser correcto son dos habilidades completamente diferentes. Por eso cada tarea se califica en tres dimensiones separadas.
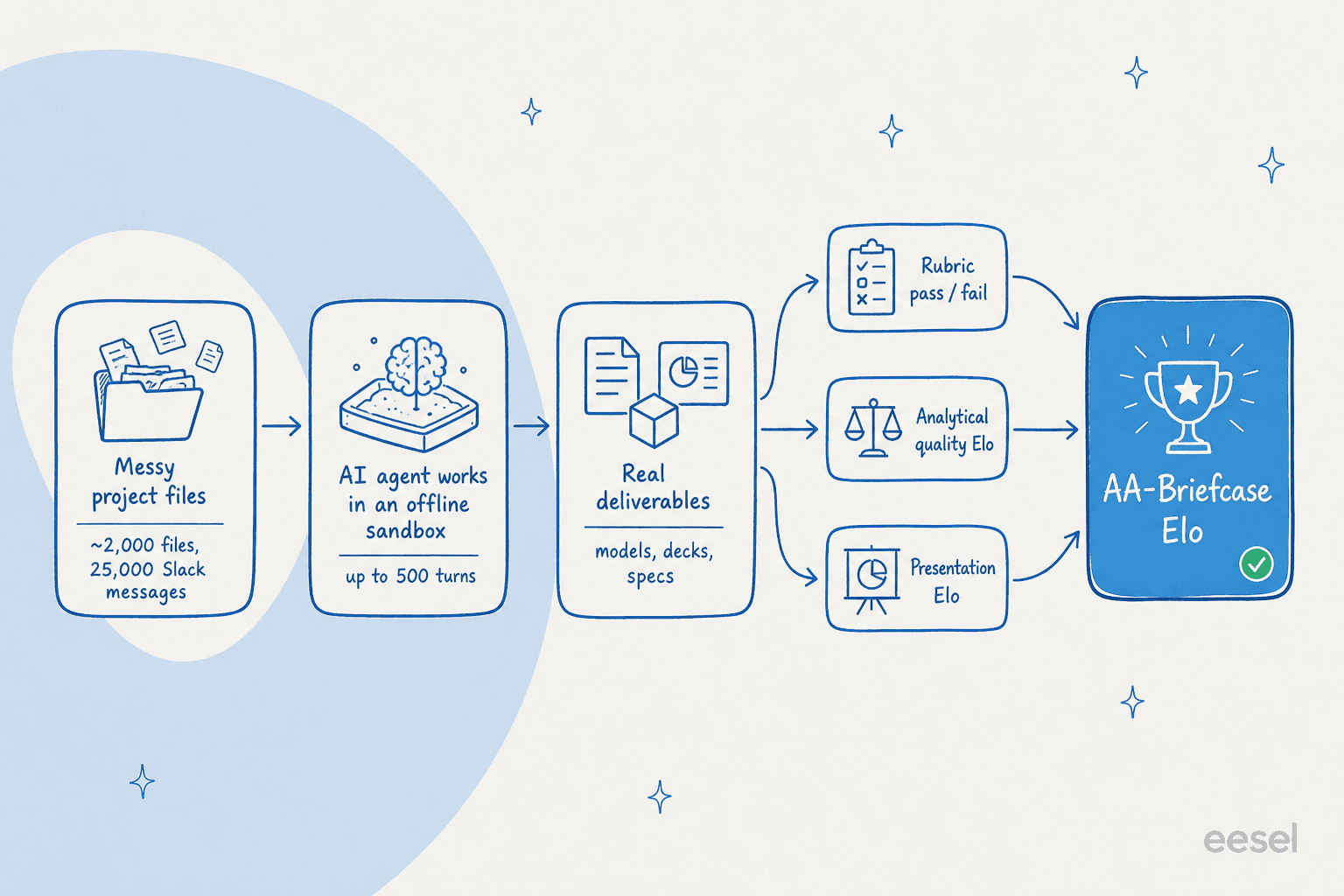
La primera es una rúbrica binaria: aprobado o reprobado en cada verificación, sin crédito parcial. ¿Siguió el modelo las instrucciones, encontró los requisitos dispersos entre archivos, usó la evidencia correcta y llegó a la conclusión correcta? La segunda es calidad analítica, juzgada por comparación por pares con la entrega de otro modelo: ¿qué entregable es más completo y mejor respaldado? La tercera es presentación, también por pares: ¿qué resultado está mejor estructurado de manera profesional?
Esas tres se combinan en un número titular único, el Elo de AA-Briefcase, que mezcla Elo de calidad analítica, Elo de presentación y tasa de aprobación de rúbrica usando agregación Elo de máxima verosimilitud. Para evitar que alguna familia de modelos se califique favorablemente, cada comparación es decidida por un panel de tres jueces: Claude Opus 4.8, GPT-5.5 y Gemini 3.1 Pro Preview.
La infraestructura también es abierta. Los modelos se ejecutan en Stirrup, el harness de agente de código abierto de Artificial Analysis, dentro de un sandbox sin conexión sin internet, por hasta 500 turnos por tarea. Es una configuración genuinamente exigente y está bastante más cerca de un flujo de trabajo agéntico real que una ventana de chat.
Qué dicen realmente los resultados
El leaderboard de arriba cuenta la historia feliz (Claude Fable 5 al frente, niveles de capacidad ordenadamente apilados). La historia más difícil está en las tasas de aprobación.
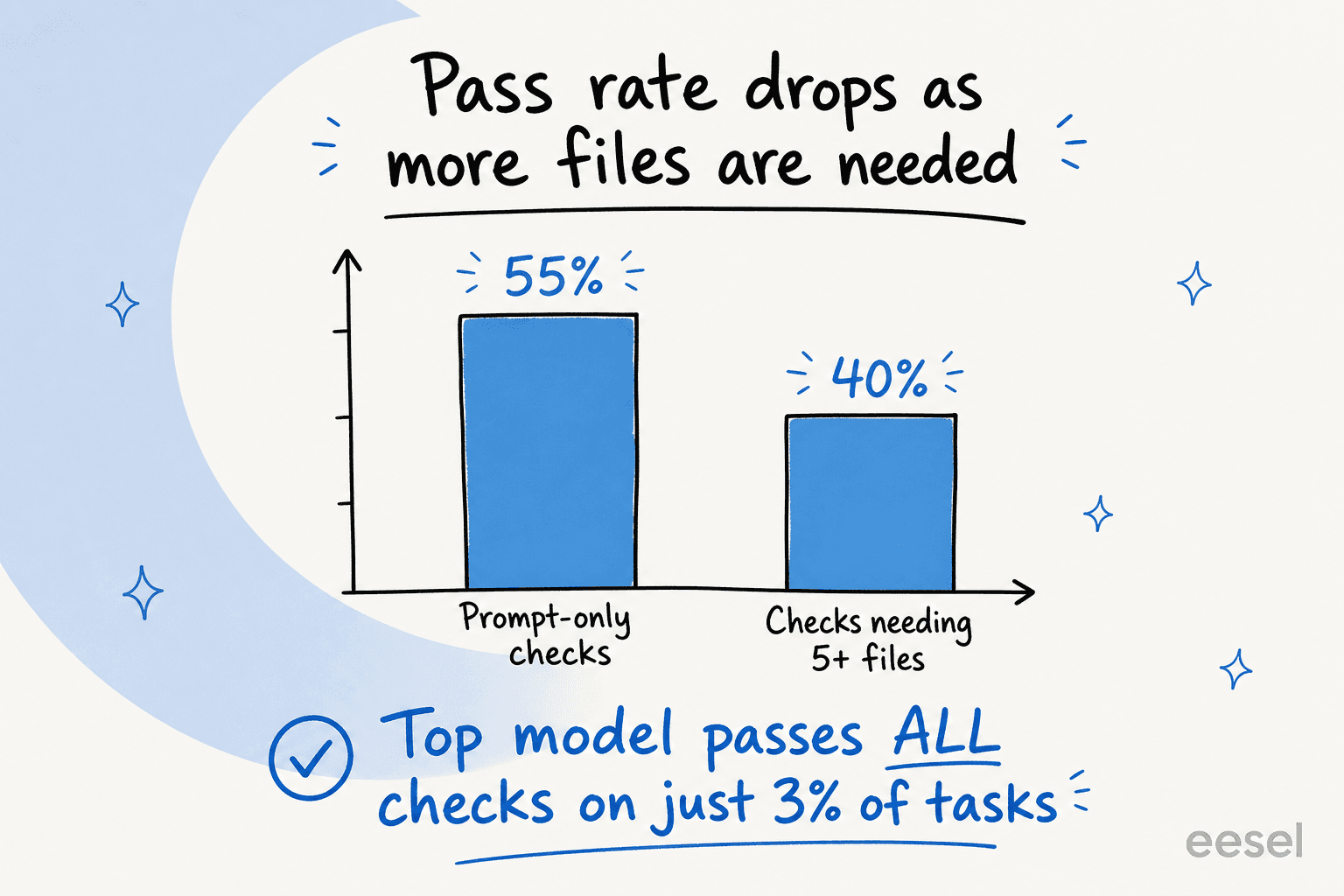
Incluso el modelo líder satisface todos los criterios de la rúbrica en solo el 3 % de las tareas, y en 31 de las 91 tareas ningún modelo supera el 50 %. La dificultad también escala con el número de archivos requeridos: los modelos de alta inteligencia caen de alrededor del 55 % en verificaciones solo de prompt a aproximadamente el 40 % una vez que una tarea necesita cinco o más. Cuanto más se parece una tarea al trabajo real, peor lo hace todo el mundo.
El leaderboard tiene algunos puntos clave que vale la pena destacar. GLM-5.2 es el claro líder de peso abierto y el destacado en precio/rendimiento, situándose aproximadamente 90 Elo por debajo de Claude Opus 4.8 a menos de un cuarto del costo. MiniMax-M3 y GLM-5.2 ambos superan sus puntuaciones de inteligencia general, mientras que los modelos Gemini de Google en realidad rinden menos en AA-Briefcase en comparación con donde se sitúan en los rankings de inteligencia amplia. Y como muestra la vista de costo en el widget, la diferencia entre el modelo más caro y el más barato supera 800×, lo cual es un recordatorio útil cuando se sopesa el costo real de un agente de IA contra las métricas que realmente importan.
El problema de "parece correcto pero está mal"
Mi hallazgo favorito de toda la publicación es uno de comportamiento, y explica mucho sobre por qué el trabajo de IA puede sentirse poco confiable.
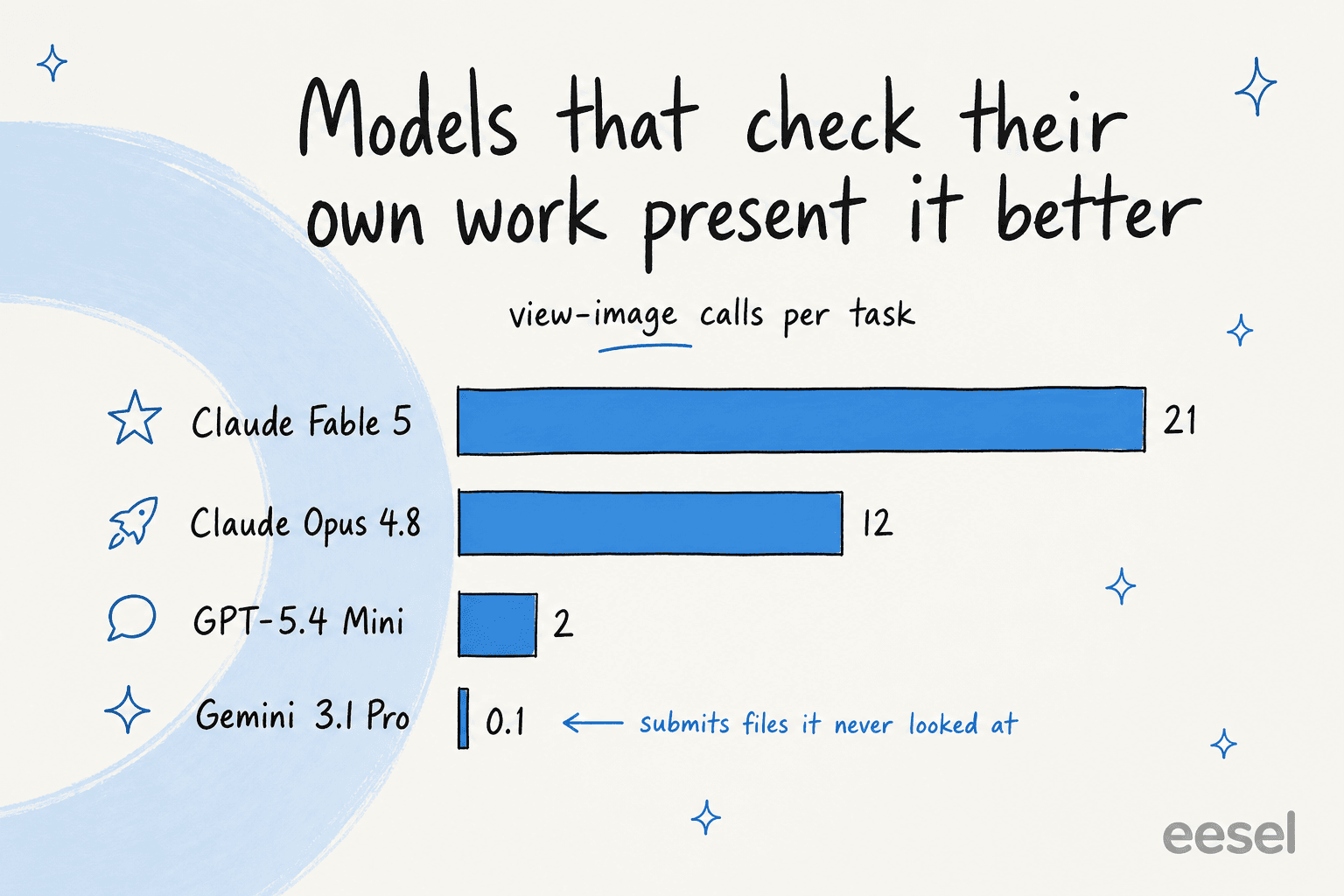
Los modelos que mejor puntúan en presentación son los que realmente revisan su propio resultado renderizado. Claude Fable 5 hizo alrededor de 21 llamadas view-image por tarea y Opus 4.8 unas 12, mientras que algunos modelos enviaron archivos que apenas habían examinado (Gemini 3.1 Pro Preview promedió aproximadamente 0,1 llamadas view-image). Resulta que "revisar tu trabajo antes de entregarlo" es tan buen consejo para una IA como para una persona.
Hay un punto más profundo debajo. AA-Briefcase separa el pulido de la corrección precisamente porque una respuesta confiada y bien formateada que está silenciosamente equivocada es más peligrosa que una que es obviamente incompleta. Ese es el riesgo exacto que aparece cuando un chatbot de IA responde a un cliente, y es por eso que prevenir alucinaciones es lo fundamental en el soporte, no un extra agradable.
Por qué una puntuación en el leaderboard no es un plan de despliegue
Entonces, un modelo de frontera puede hacer trabajo del conocimiento real, a veces de manera brillante, y aun así fallar la mayoría del tiempo en las tareas más difíciles y con más archivos. Si te llevas una cosa de AA-Briefcase, llévate esto: un puesto en un benchmark es una señal de capacidad general, no una promesa sobre cómo se comporta un modelo en tus datos desordenados específicos.
He visto esto suceder en primera persona. Hemos pasado años poniendo agentes de IA en colas de soporte en vivo, y lo que afecta a los equipos no es si el modelo subyacente es lo suficientemente inteligente en abstracto, sino si se mantiene preciso en sus tickets específicos, las peculiaridades de su producto y sus casos extremos. Un modelo que lidera cada leaderboard público aún puede citar confiadamente tu política de reembolso de forma incorrecta el primer día, mucho antes de llegar a la resolución automatizada de tickets. Eso no es una crítica al modelo; es la diferencia entre un benchmark y la producción.
La solución es el mismo instinto sobre el que está construido AA-Briefcase: califica el trabajo contra la verdad antes de confiar en él. Para un helpdesk, eso significa ejecutar la IA contra tus propios tickets históricos y ver exactamente lo que habría respondido, en lugar de leer una ficha técnica y esperar lo mejor. Piénsalo como ejecutar tu propio AA-Briefcase privado, donde el conjunto de prueba es tu historial de soporte real.
Prueba eesel para soporte de IA en el que realmente puedas confiar
Si AA-Briefcase te convenció de que capacidad y fiabilidad no son lo mismo, ese es exactamente el problema alrededor del cual está construido eesel AI. eesel funciona como un nuevo compañero de soporte que se conecta a tu helpdesk y base de conocimiento existentes en minutos, y luego te permite simularlo en miles de tus tickets pasados antes de que hable con un cliente, para que veas su tasa de resolución real y las respuestas exactas de antemano en lugar de adivinarlas en un leaderboard.

Mantienes el control de lo que se le permite responder y cuándo escala, y es gratis de probar con tus propios datos. Si estás evaluando IA para el servicio al cliente, ese enfoque de simular primero es lo más cercano a llevar el rigor de "demuéstralo en trabajo real" de AA-Briefcase a tu propia cola.
Preguntas frecuentes
¿Qué es el benchmark AA-Briefcase?
¿Qué modelo de IA es mejor en AA-Briefcase?
¿Cómo se puntúa AA-Briefcase?
¿Por qué los modelos de IA puntúan tan bajo en AA-Briefcase?
¿Un alto puntaje en AA-Briefcase significa que el modelo es seguro para desplegar?
¿En qué se diferencia AA-Briefcase de otros benchmarks de IA?
¿Puedo usar AA-Briefcase para elegir una herramienta de IA para el soporte al cliente?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








