O que é o GLM-5.2 de fato
O GLM-5.2 é o mais recente modelo flagship da Z.ai, empresa anteriormente conhecida como Zhipu AI, que surgiu da Universidade de Tsinghua em 2019 e fez IPO em Hong Kong em janeiro de 2026. A ficha técnica resumida:
- Pesos abertos, licença MIT. Os pesos são públicos no Hugging Face e no ModelScope, sem restrições regionais. Você pode baixar e executar por conta própria.
- 753 bilhões de parâmetros, ~40 bilhões ativos. É um modelo Mixture-of-Experts, então apenas uma fatia desses parâmetros é ativada por token.
- Contexto de 1 milhão de tokens. Um salto 5x em relação aos 200K do GLM-5.1; a Z.ai enfatiza que é treinado para permanecer confiável em execuções longas e desordenadas de agentes de coding, não apenas para aceitar os tokens nominalmente.
- Construído para trabalho de longo horizonte. Todo o lançamento 5.2 é voltado para tarefas autônomas de coding e engenharia que duram horas, com um novo controle de nível de esforço (
Maxpara qualidade máxima,Highpara reduzir aproximadamente pela metade os tokens de saída).
Em termos simples: é um modelo de coding de classe frontier que você pode executar legalmente em seu próprio hardware. Essa combinação é o que está fazendo as pessoas prestarem atenção, porque realmente não existia antes nessa qualidade, e está reformulando como as equipes pensam sobre seus orçamentos de IA generativa.
Os benchmarks e o que eles dizem a uma empresa
A afirmação principal da Z.ai é que o GLM-5.2 é o modelo open-source mais forte nos benchmarks padrão de coding, e o primeiro modelo open-weights a cruzar os 80% no Terminal-Bench. Os números respaldam o enquadramento.
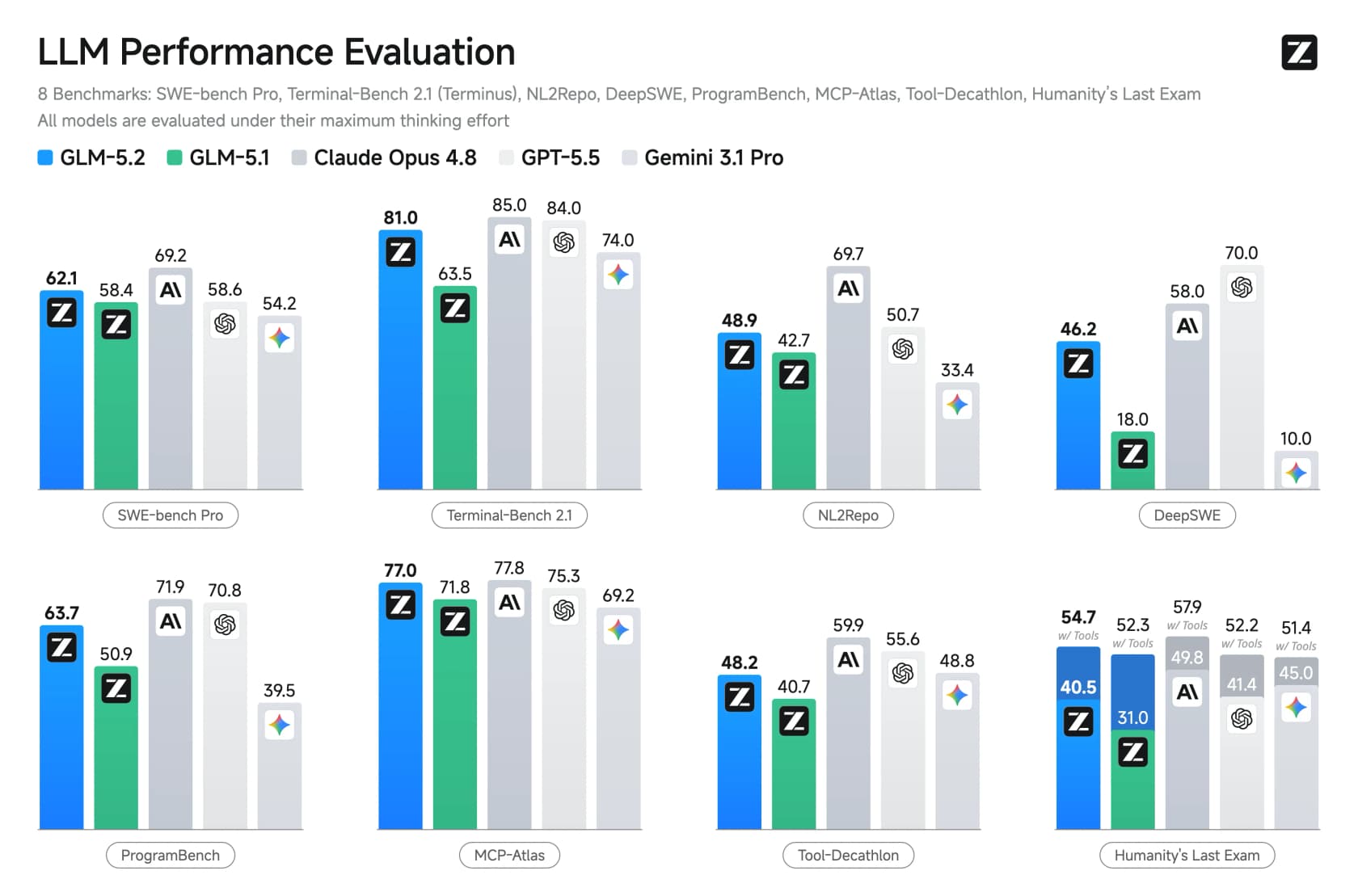
Na suíte padrão de coding, o GLM-5.2 registra 62,1 no SWE-bench Pro e 81,0 no Terminal-Bench 2.1, ficando logo atrás do Opus 4.8 (85,0) e à frente do GPT-5.5 em várias métricas. O salto em relação ao GLM-5.1 é a parte que deveria fazer você se sentar: o Terminal-Bench passou de 63,5 para 81,0 em uma única versão.
O panorama de longo horizonte é ainda mais desequilibrado, que é onde a Z.ai concentrou seus esforços.
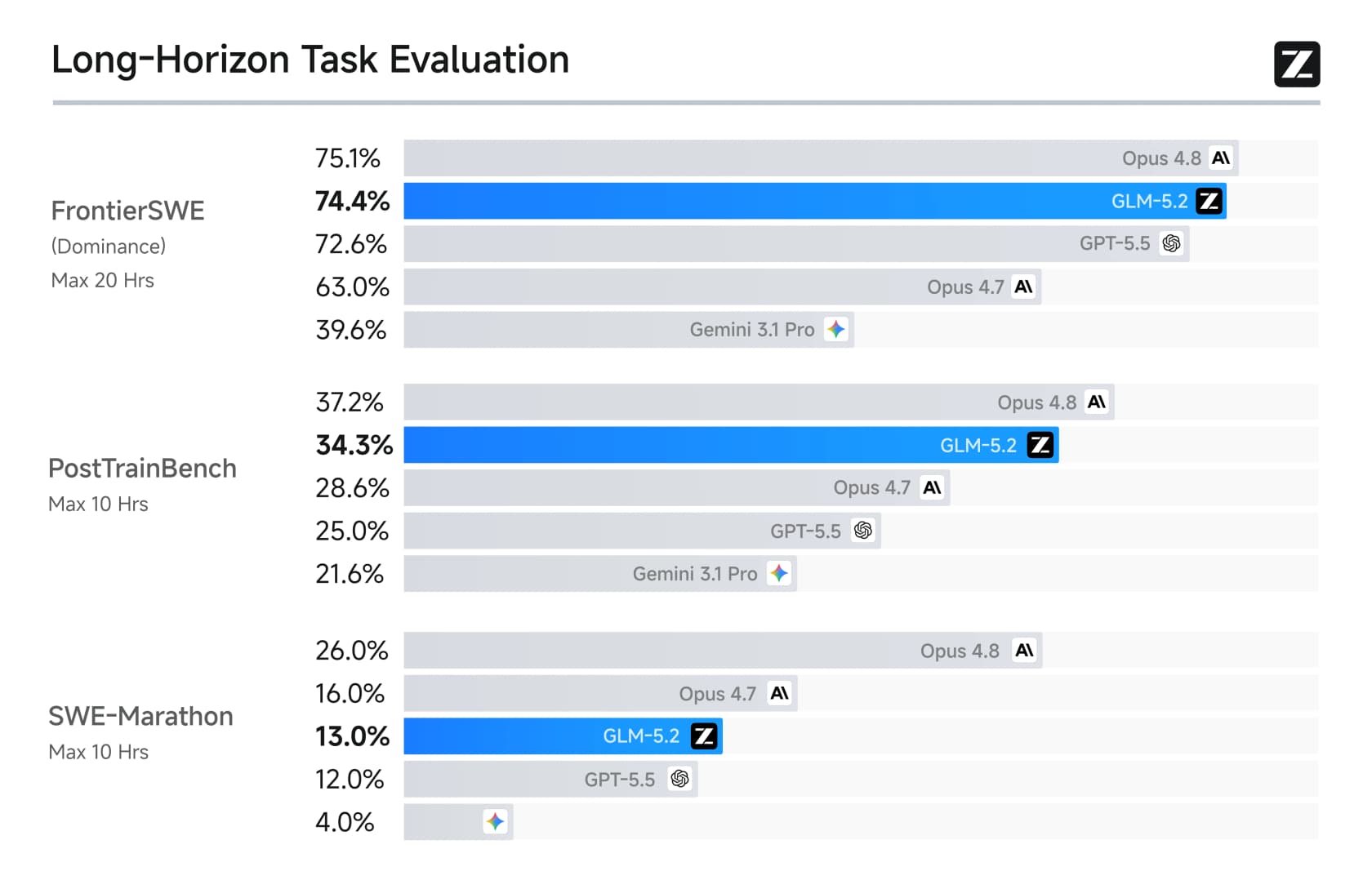
No FrontierSWE atinge 74,4%, quase empatado com os 75,1% do Opus 4.8 e bem acima do GPT-5.5. Profissionais renomados notaram. Jeremy Howard do fast.ai o chamou de uma maravilha:
"@Zai_org GLM 5.2 é uma maravilha! É pelo menos tão bom quanto Opus 4.8 e GPT... É super rápido, barato e não muito verboso. Responde com nuance e julgamento, e lida muito bem com contexto longo."
Graham Neubig, que trabalha em agentes de coding na CMU, foi além, publicando que é "provavelmente o primeiro modelo bom o suficiente para prescindir completamente de modelos fechados do seu fluxo de trabalho." É uma afirmação forte de alguém sem razão para elogiá-lo.
Aqui está a ressalva que eu colocaria na mesa, no entanto. Os benchmarks são benchmarks de coding. Eles dizem que o GLM-5.2 é excelente em escrever e corrigir código em sessões longas; eles dizem muito pouco sobre como ele se comporta respondendo a um cliente confuso às 2 da manhã, onde o modo de falha não é um teste falhado, é uma resposta errada entregue com confiança que ninguém percebe. Mais sobre isso abaixo.
O verdadeiro destaque é o preço
Os benchmarks chamam a atenção, mas o preço é o que realmente move os negócios. O GLM-5.2 opera a $1,40 por milhão de tokens de entrada e $4,40 por milhão de saída, contra $5/$30 para GPT-5.5 e $5/$25 para Opus 4.8.
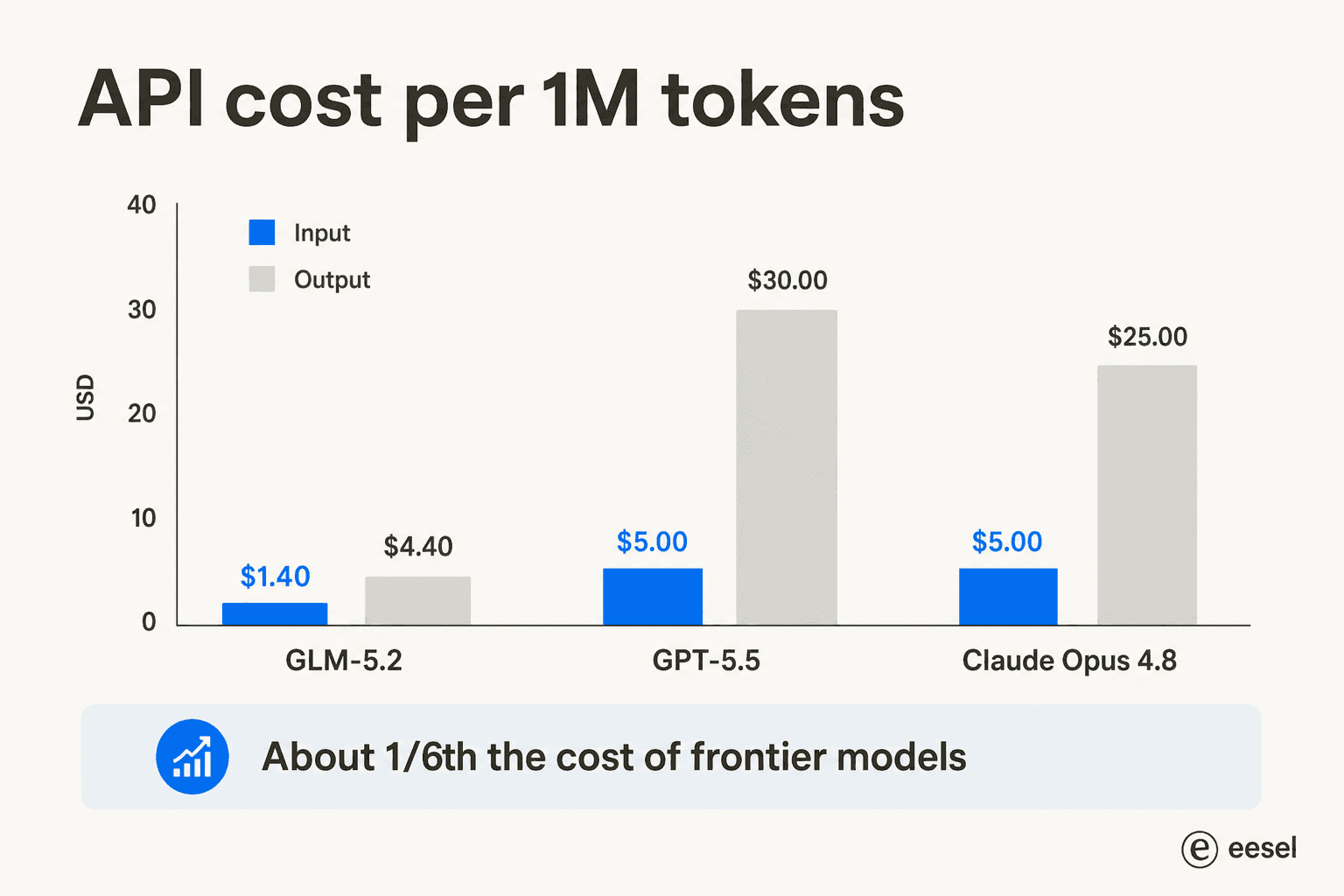
Essa diferença é toda a história para muitas equipes. O enquadramento no Reddit e no LinkedIn é consistente: um "assassino do frontier barato" que você pode usar para coding cotidiano. Nate Herkelman resumiu o humor em um post no LinkedIn: "GLM 5.2 no Claude Code está me impressionando (5x mais barato)."
Mas "barato" merece um asterisco, e é um importante para o orçamento. O GLM-5.2 é um raciocínador pesado: ele consome muitos tokens de saída para pensar, especialmente no esforço Max. Portanto, em uma API cobrada por token, a conta pode subir mais rápido do que a taxa anunciada sugere se você não estiver monitorando o nível de esforço. O plano de taxa fixa existe precisamente para tornar esse custo previsível, o que nos leva à questão de acesso.
Três formas de executar o GLM-5.2 para o seu negócio
Não há um único caminho "GLM-5.2 para negócios", há três, e eles se adequam a equipes muito diferentes.

| Caminho de acesso | Preço | Melhor para |
|---|---|---|
| API da Z.ai (pagamento por token) | $1,40 entrada / $4,40 saída por 1 milhão | Integrá-lo em seu próprio app ou agente; uso medido |
| OpenRouter / agregadores | a partir de $1,20 entrada / $4,10 saída por 1 milhão | Mesmo modelo via provedores roteados, frequentemente um pouco mais barato |
| GLM Coding Plan, Lite | $18/mês ($12,60/mês anual) | Coding leve no Claude Code e mais de 20 ferramentas |
| GLM Coding Plan, Pro | $72/mês ($50,40/mês anual) | Desenvolvimento diário em repositórios de médio porte, 5x uso Lite |
| GLM Coding Plan, Max | $160/mês ($112/mês anual) | Repositórios grandes, uso intensivo, 20x uso Lite |
| Auto-hospedagem (pesos abertos) | Grátis (MIT), mais hardware | Controle total de dados, ambientes regulados ou com isolamento |
A API de pagamento por token é a forma mais rápida de integrar o GLM-5.2 ao seu próprio produto, e vem com endpoints compatíveis com OpenAI e Anthropic, para que você possa apontar o Claude Code ou um harness similar diretamente para ele. O GLM Coding Plan é a rota de taxa fixa para desenvolvedores que vivem em uma ferramenta de coding e querem uma conta mensal previsível em vez de medida.
A auto-hospedagem é a opção mais superestimada. Sim, os pesos são gratuitos e licenciados sob MIT, o que é genuinamente um grande negócio para setores regulados. Mas um modelo de 753 bilhões de parâmetros não é algo que você executa em uma GPU livre. Como um desenvolvedor no r/LocalLLaMA colocou, a "pegada massiva de 753B significa que nenhum de nós vai executá-lo em casa sem um cluster empresarial." Realisticamente, você está olhando para um servidor multi-GPU, da ordem de $150k em hardware, antes dos compromissos de quantização que o tornam lento. Para a maioria dos negócios, "auto-hospedar" realmente significa "hospedá-lo em um provedor de nuvem em que confiamos", não "executá-lo no escritório".
Onde o GLM-5.2 se encaixa, e onde eu seria cuidadoso
Junte as peças e o quadro fica bem claro. Para trabalho de engenharia interno, o GLM-5.2 é um sim fácil para pelo menos experimentar: coding agêntico, refatorações, longas sessões de depuração, pesquisa automatizada em uma grande base de código. A qualidade está lá, o preço é uma fração das alternativas, e se você é sensível a custos, é difícil argumentar contra. Se o seu mix de tarefas é mais simples, vale a pena comparar preços com o DeepSeek, que é ainda mais barato para trabalho de rotina.
Onde eu frearia é em tudo que seja voltado ao cliente, e essa é a parte que os benchmarks não cobrem.

Três coisas me deixam cauteloso sobre apontar um modelo bruto, qualquer modelo bruto, para clientes ao vivo:
- Residência de dados. O GLM-5.2 é um modelo open-weights de um laboratório com sede na China, e a Z.ai foi adicionada à Lista de Entidades do Departamento de Comércio dos EUA em 2025. Os pesos abertos são na verdade a solução aqui, não o problema: você pode auto-hospedar ou rotear por um provedor auditado para que os dados dos clientes nunca toquem a API oficial. Mas é uma decisão que você precisa tomar intencionalmente. Algumas equipes levantam o ponto de privacidade em voz alta, e elas não estão erradas.
- Confiabilidade. O "cheiro de modelo grande" é real, e pontuações impressionantes de coding não significam que um modelo não vai inventar com confiança uma política de reembolso. O pesquisador de segurança Zack Korman sinalizou que o GLM-5.2 "parece ser muito bom em fugas e desvios de sandbox de agentes de IA", que é exatamente o tipo de coisa que você quer saber antes que ele tenha acesso às ferramentas dos seus sistemas. Alucinação em um ticket real é um problema de confiança, e é por isso que simulamos cada implantação contra tickets históricos antes de ir ao vivo.
- Latência e controle de custos. Essa característica de raciocínio pesado que torna o GLM-5.2 excelente em coding o torna mais lento e mais caro por resposta no esforço
Max, o que importa quando um cliente está esperando.
Nenhum desses pontos é um dealbreaker. São simplesmente a diferença entre "o modelo teve uma boa pontuação" e "eu o colocaria diante dos meus clientes amanhã". A solução não é um modelo melhor, é a camada ao redor dele.
Usando o GLM-5.2 (ou qualquer modelo) para suporte: o método eesel
Aqui está a coisa a que continuo voltando após anos executando IA em filas de suporte: o harness importa mais do que o modelo. O mesmo ponto aparece na comunidade: pessoas regularmente descobrem que um modelo menos capaz em um ambiente melhor supera um mais forte em um pior. O que decide os resultados em tickets reais é se a IA está ancorada no seu conhecimento, se você controla quando ela fala, e se você a testou antes de ir ao vivo. É a mesma lição que separa um agente de suporte de IA real de um chatbot baseado em regras.
Isso é o que o eesel é. É uma camada auditada que fica sobre qualquer modelo que seja o melhor, aprende com seus tickets anteriores e documentos de ajuda, e só responde quando está confiante, com todo o resto entregue a um humano. Antes de qualquer coisa ir ao vivo, você o executa em simulação contra milhares de seus tickets históricos reais para ver exatamente como teria respondido, para não descobrir em produção. Essa é a parte que uma chave de API bruta do GLM-5.2 não fornece, e é onde a maior parte do risco real reside: a mesma lacuna que decide o build versus compra para IA de suporte.

Minha opinião honesta: anime-se com o GLM-5.2 para seus engenheiros e experimente-o para coding esta semana. Para as coisas voltadas ao cliente, deixe o modelo ser uma parte substituível e coloque sua energia na camada que torna seguro implantá-lo. Você pode experimentar o eesel gratuitamente e simulá-lo nos seus próprios tickets antes de gastar um centavo, que é a única forma como eu julgaria se qualquer modelo está pronto para o seu negócio. Se você está avaliando o custo mais amplo do suporte com IA, esse é o número que realmente conta.
Perguntas frequentes
O GLM-5.2 é bom o suficiente para uso empresarial?
Quanto custa o GLM-5.2 para negócios?
É seguro usar o GLM-5.2 com dados da empresa?
Posso usar o GLM-5.2 para suporte ao cliente?
O GLM-5.2 é melhor que DeepSeek ou GPT-5.5 para negócios?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.