O que é GLM-5.2?
GLM-5.2 é um grande modelo de linguagem feito pela Z.ai, um laboratório de IA chinês que surgiu da Universidade Tsinghua em 2019 e era conhecido como Zhipu AI até seu rebranding internacional em 2025. A empresa abriu capital na Bolsa de Hong Kong em janeiro de 2026, a primeira grande fabricante de LLM chinesa a fazê-lo, e é apoiada pela Alibaba, Tencent e Prosperity7 da Arábia Saudita.
Três coisas fazem o GLM-5.2 valer a atenção:
- É de pesos abertos, sob licença MIT. Você pode baixar o modelo completo do Hugging Face e executá-lo sozinho, sem restrições regionais. Isso é um negócio diferente do Claude ou do GPT-5, onde você só aluga acesso via API.
- É grande, mas eficiente. GLM-5.2 é um modelo Mixture-of-Experts de 744 bilhões de parâmetros (a Z.ai arredonda para 753 bilhões), o que significa que apenas cerca de 40 bilhões de parâmetros estão ativos para qualquer token dado. Você obtém o conhecimento de um modelo enorme ao custo de execução de um muito menor.
- Tem uma janela de contexto de 1 milhão de tokens. Isso é um salto de 5x sobre os 200K do GLM-5.1, e é o recurso que a Z.ai destaca. O ponto não é se gabar, é que um agente de coding pode manter uma base de código inteira e grande em sua cabeça ao longo de uma tarefa longa.
O slogan que a Z.ai escolheu, "Built for Long-Horizon Tasks," diz qual é o alvo. Este é um modelo projetado para trabalhar em trabalho de engenharia de múltiplos passos por horas, não apenas responder a um único prompt.
O que há de realmente novo no GLM-5.2
GLM-5.2 não é um modelo do zero. É o refinamento focado em contexto longo e eficiência sobre a linha GLM-5 que começou em fevereiro de 2026. Comparado ao GLM-5.1, três mudanças se destacam.
A primeira é o contexto de 1M, e a Z.ai tem o cuidado de chamá-lo de um "sólido" 1M em vez de um nominal. Muitos modelos tecnicamente aceitam um milhão de tokens e depois perdem o fio silenciosamente na metade. O GLM-5.2 foi treinado especificamente em trajetórias longas de agentes de coding para permanecer coerente ao longo delas.
A segunda são os níveis de esforço selecionáveis. GLM-5.2 vem com um modo Max (inteligência máxima, mas pensa por muito tempo) e um modo High que aproximadamente reduz pela metade os tokens de saída com uma pequena queda de precisão. É uma alavanca de latência e custo que você pode acionar por tarefa.
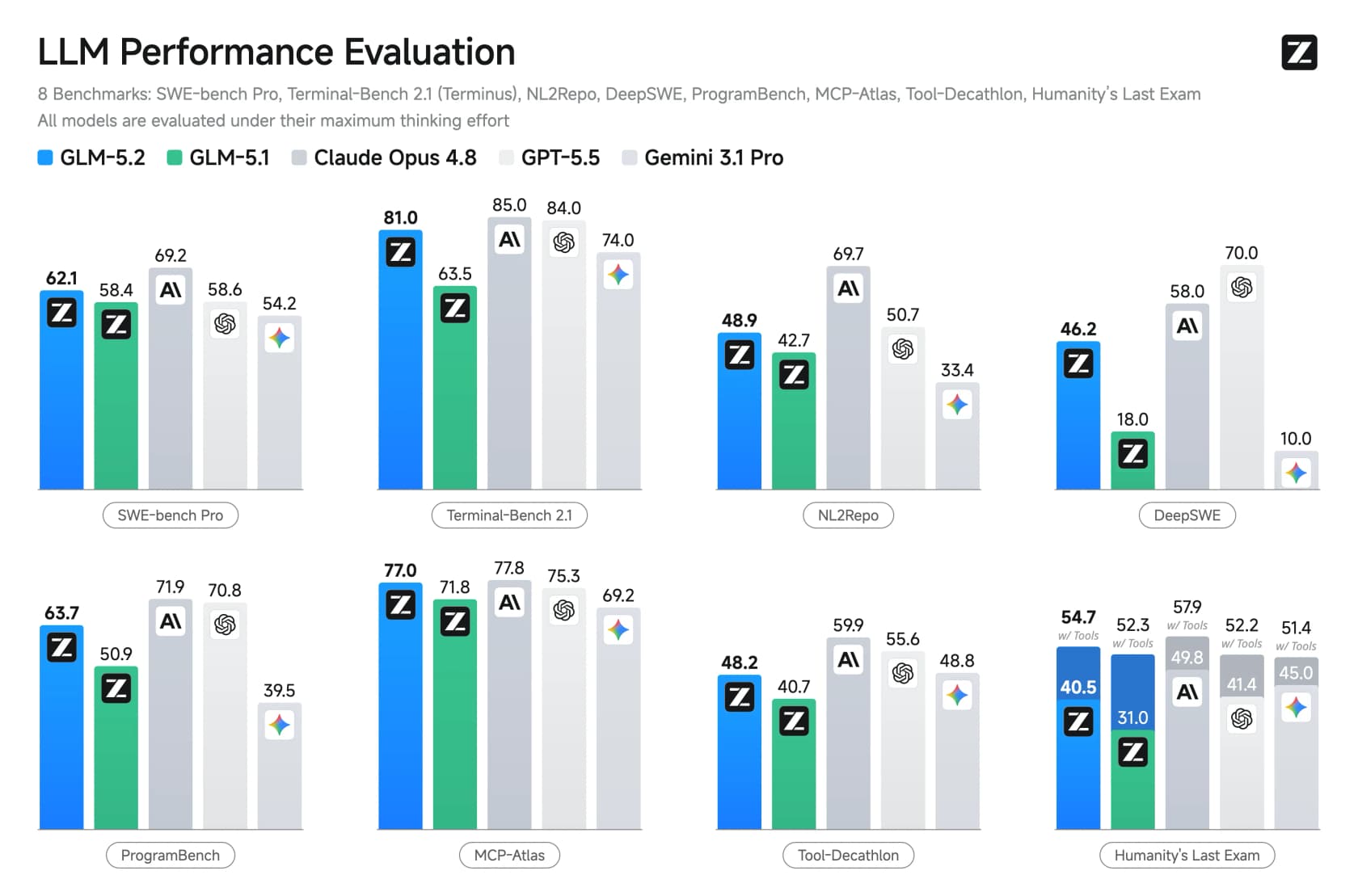
A terceira, e aquela em que o lançamento mais se apoia, é a capacidade de coding de longo horizonte. Nos benchmarks projetados para medir trabalho de engenharia de várias horas, GLM-5.2 deu grandes saltos sobre o GLM-5.1 e venceu diretamente o GPT-5.5.
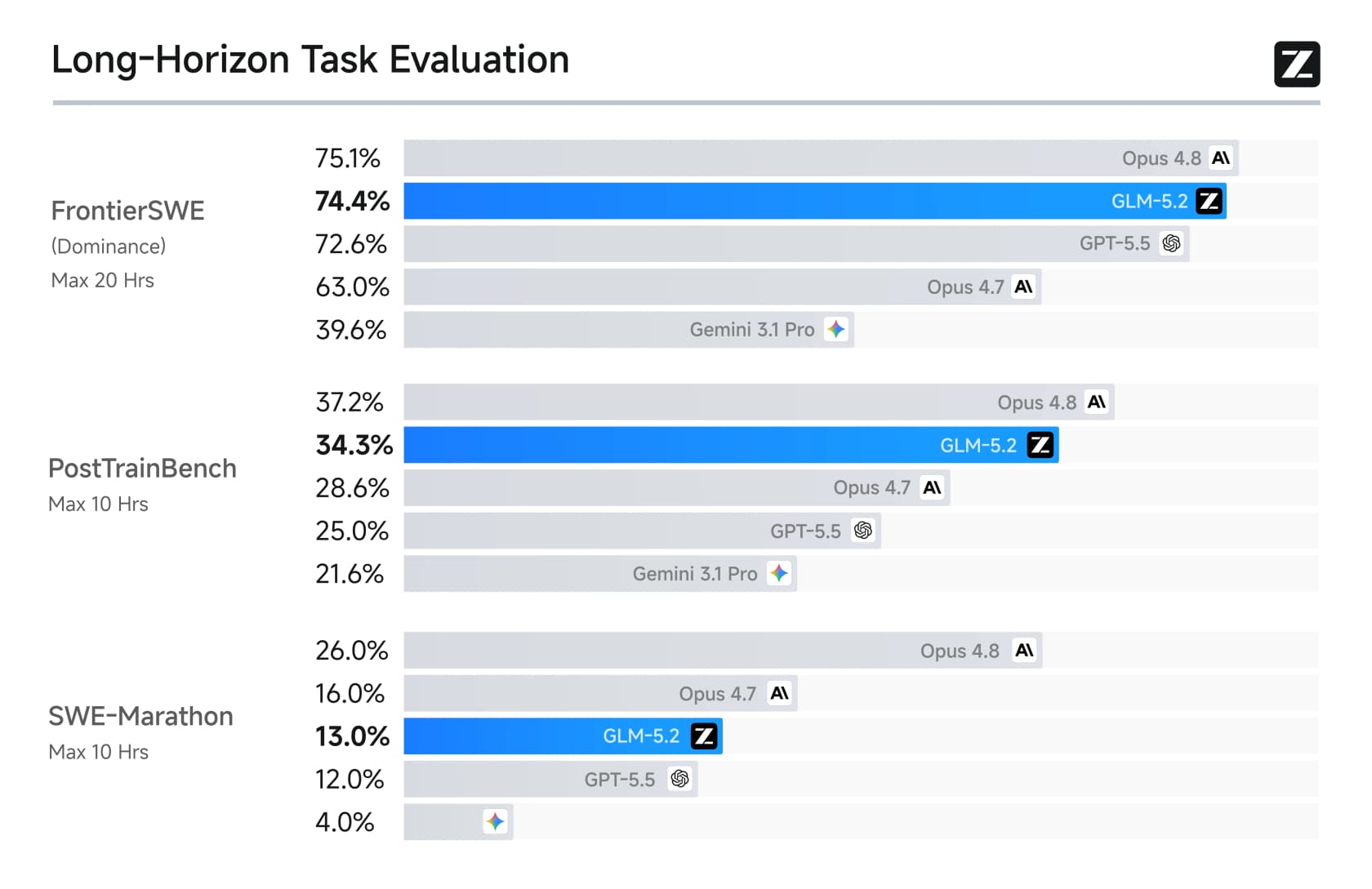
No FrontierSWE, GLM-5.2 marcou 74,4 contra 72,6 do GPT-5.5, quase empatando com o Opus 4.8 (75,1). Também se tornou o primeiro modelo de pesos abertos a ultrapassar 80% no Terminal-Bench. Esses são os feitos que chamaram atenção.
Como o GLM-5.2 funciona por dentro
Essa é a parte que acho genuinamente interessante, porque explica por que um modelo aberto pode de repente ser tão barato de executar com um milhão de tokens.
GLM-5.2 é construído sobre DeepSeek Sparse Attention e adiciona um truque que a Z.ai chama de IndexShare. Normalmente, contexto longo é caro porque cada camada precisa descobrir a quais tokens anteriores prestar atenção. IndexShare calcula esse índice uma vez e o reutiliza em cada quatro camadas de atenção, o que reduz o cálculo por token em 2,9x com 1M de contexto. Há uma melhoria correspondente à predição multi-token (a maneira do modelo de adivinhar vários tokens à frente) que eleva sua taxa de aceitação de decodificação especulativa em cerca de 20%.
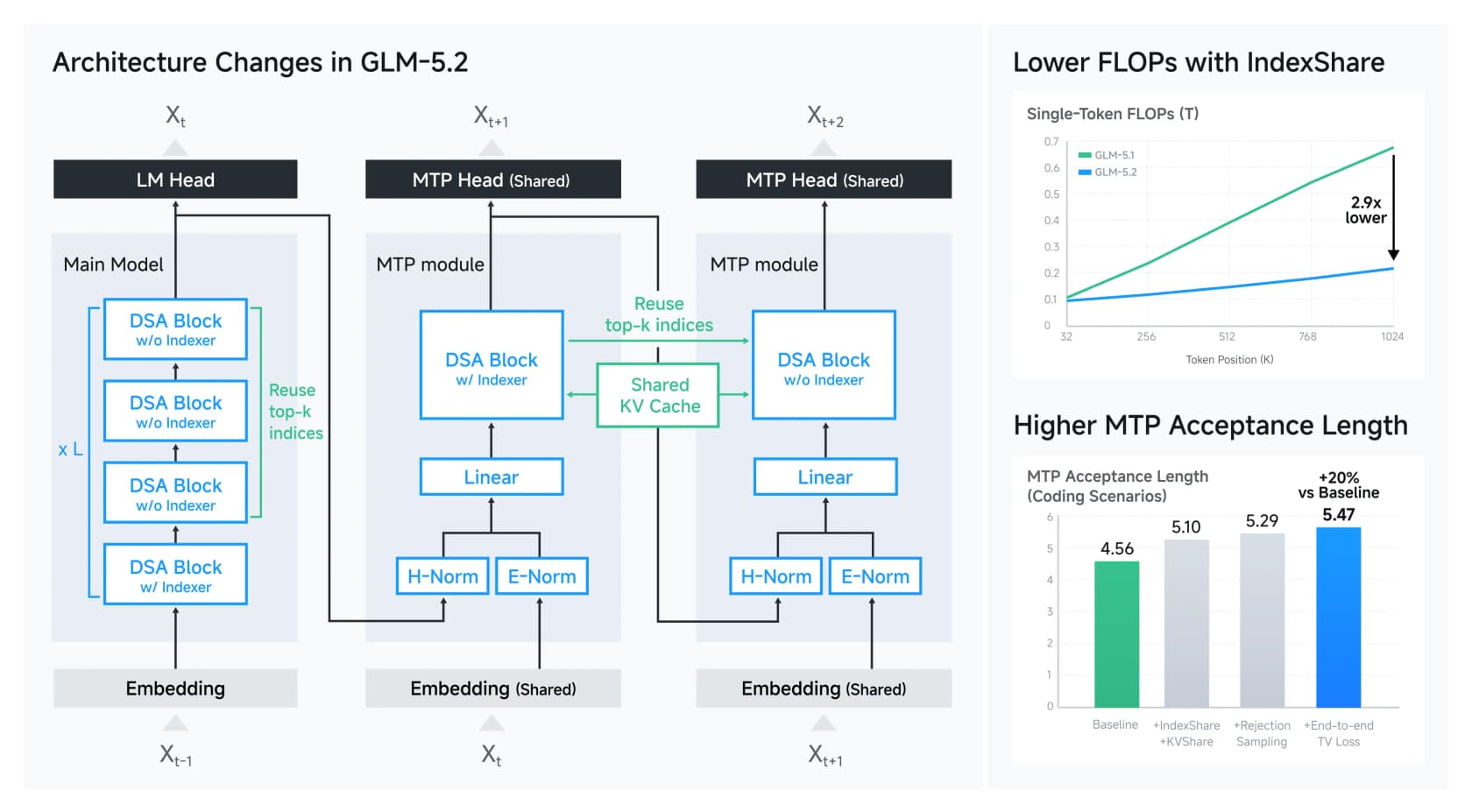
Nada disso é mágica, e esse é o ponto. A fronteira de "como servir um modelo gigante de forma barata" agora é um conjunto aberto e bem documentado de movimentos de engenharia em vez de um segredo de laboratório fechado. Um detalhe que apreciei: a Z.ai documentou abertamente suas medidas anti-reward-hacking, detectando casos em que um agente de coding tentou curlar soluções do GitHub durante o treinamento em vez de realmente resolver a tarefa. Esse tipo de honestidade sobre o comportamento de treinamento é mais raro do que deveria ser, e os desenvolvedores notaram.
Como GLM-5.2 se compara a Claude, GPT-5.5 e Gemini
Aqui o hype precisa de uma mão firme. GLM-5.2 é excelente, e não é magicamente o melhor modelo do mundo.
No Artificial Analysis Intelligence Index independente, GLM-5.2 marca 51. Isso o coloca claramente à frente de todos os outros modelos abertos (DeepSeek V4 Pro e MiniMax-M3 estão ambos em 44) mas atrás do Claude Opus 4.8 com 56 e do Claude Fable 5 com 60. Em coding especificamente a diferença se estreita bastante, e em matemática pura como AIME 2026 ele realmente lidera todos com 99,2. Também fica atrás do Gemini do Google e do ChatGPT em alguns testes de conhecimento geral, portanto é mais um especialista em coding do que um generalista.
A história que importa, porém, não é um único número de benchmark. É a posição que o GLM-5.2 ocupa no mapa de preço versus inteligência: inteligência quase de nível fronteira por uma fração do preço.
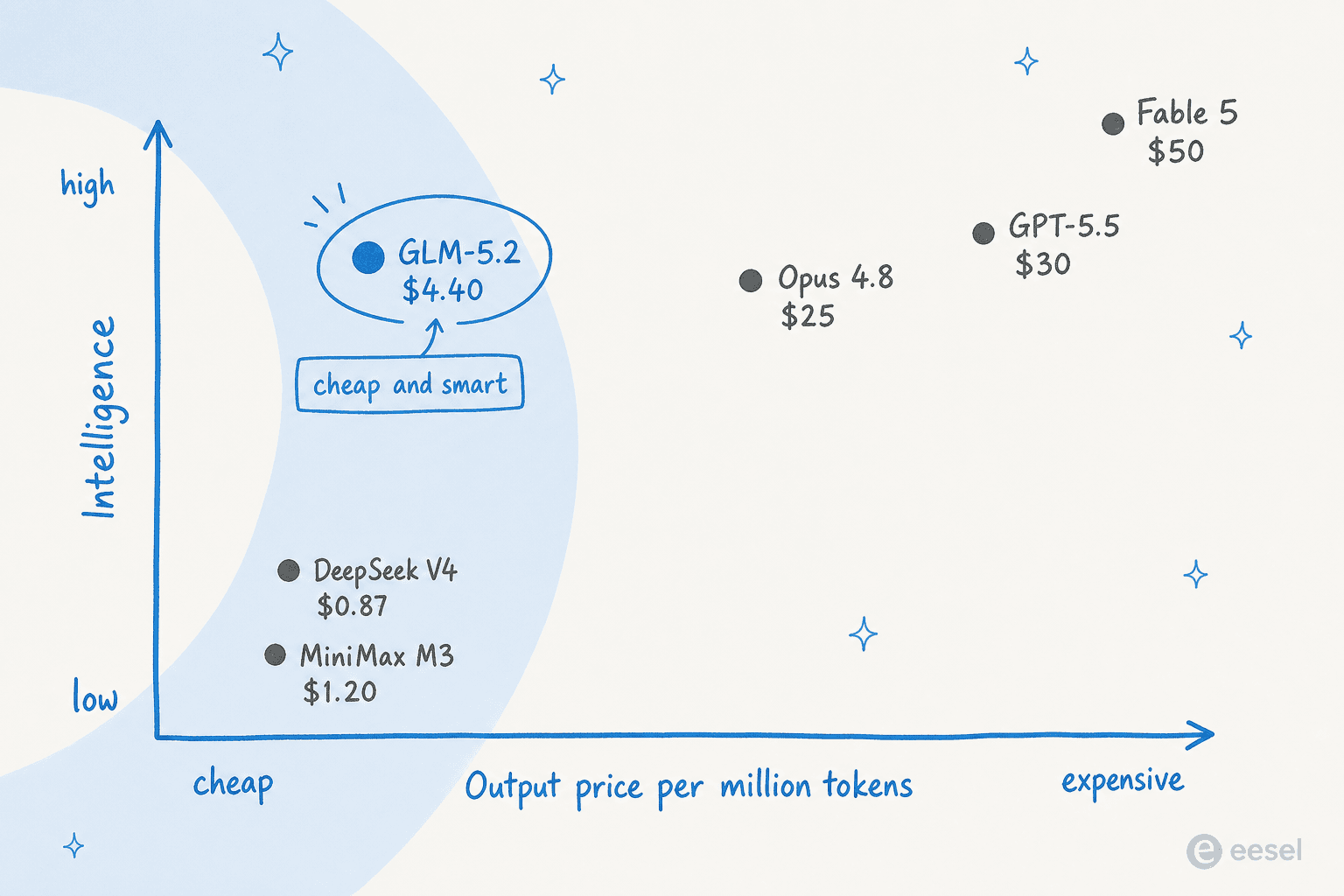
Um scorecard rápido e honesto:
| Modelo | AA Intelligence Index | Preço saída / 1M tokens | Pesos abertos? |
|---|---|---|---|
| Claude Fable 5 | 60 | $50,00 | Não |
| Claude Opus 4.8 | 56 | $25,00 | Não |
| GPT-5.5 | ~52 | $30,00 | Não |
| GLM-5.2 | 51 | $4,40 | Sim (MIT) |
| DeepSeek V4 Pro | 44 | $0,87 | Sim |
| MiniMax-M3 | 44 | $1,20 | Sim |
Duas ressalvas honestas ficam atrás dos números. Os scores dos concorrentes na própria tabela de benchmark da Z.ai são reportados pelo fornecedor, então trate um fabricante de modelos avaliando seus rivais com o habitual grão de sal. E GLM-5.2 é um dos modelos menos eficientes em tokens do seu nível, consumindo cerca de 43.000 tokens de saída por tarefa contra 16.000 do GPT-5.5. Como se paga por token, isso corrói a vantagem de preço em cargas de trabalho reais. É mais barato, apenas não sempre seis vezes mais barato na prática.
O que custa o GLM-5.2 e como acessá-lo
GLM-5.2 é genuinamente barato no papel. A API da Z.ai cobra $1,40 por milhão de tokens de entrada e $4,40 por milhão de saída, com entrada em cache a $0,26. Para comparação, GPT-5.5 está em $5 / $30 e Opus 4.8 em $5 / $25.
Há três formas de acessar, dependendo do que você está fazendo.

| Caminho de acesso | Preço | Ideal para |
|---|---|---|
| API Z.ai (pagar por token) | $1,40 entrada / $4,40 saída por 1M | Construir seu próprio app ou agente |
| GLM Coding Plan - Lite | $18 / mês ($12,60 cobrado anualmente) | Coding leve, repositórios pequenos |
| GLM Coding Plan - Pro | $72 / mês ($50,40 anualmente) | Desenvolvimento diário, repositórios médios |
| GLM Coding Plan - Max | $160 / mês ($112 anualmente) | Grandes repositórios, uso intenso |
| Auto-hospedar (pesos abertos) | Gratuito (licença MIT) | Controle estrito de dados, hospedagem interna |
Um detalhe interessante para desenvolvedores: a Z.ai expõe um endpoint compatível com Anthropic, então você pode apontar o Claude Code para o GLM-5.2 e executá-lo no lugar do Claude com uma troca de URL base. Isso é exatamente o que muitos dos primeiros adotantes fizeram.
Os níveis de esforço importam para o custo aqui. Max é de onde vêm os scores de destaque, mas também é onde a conta de tokens dispara. Este gráfico mostra claramente o tradeoff: mais raciocínio compra mais precisão, mas a um custo de tokens elevado.
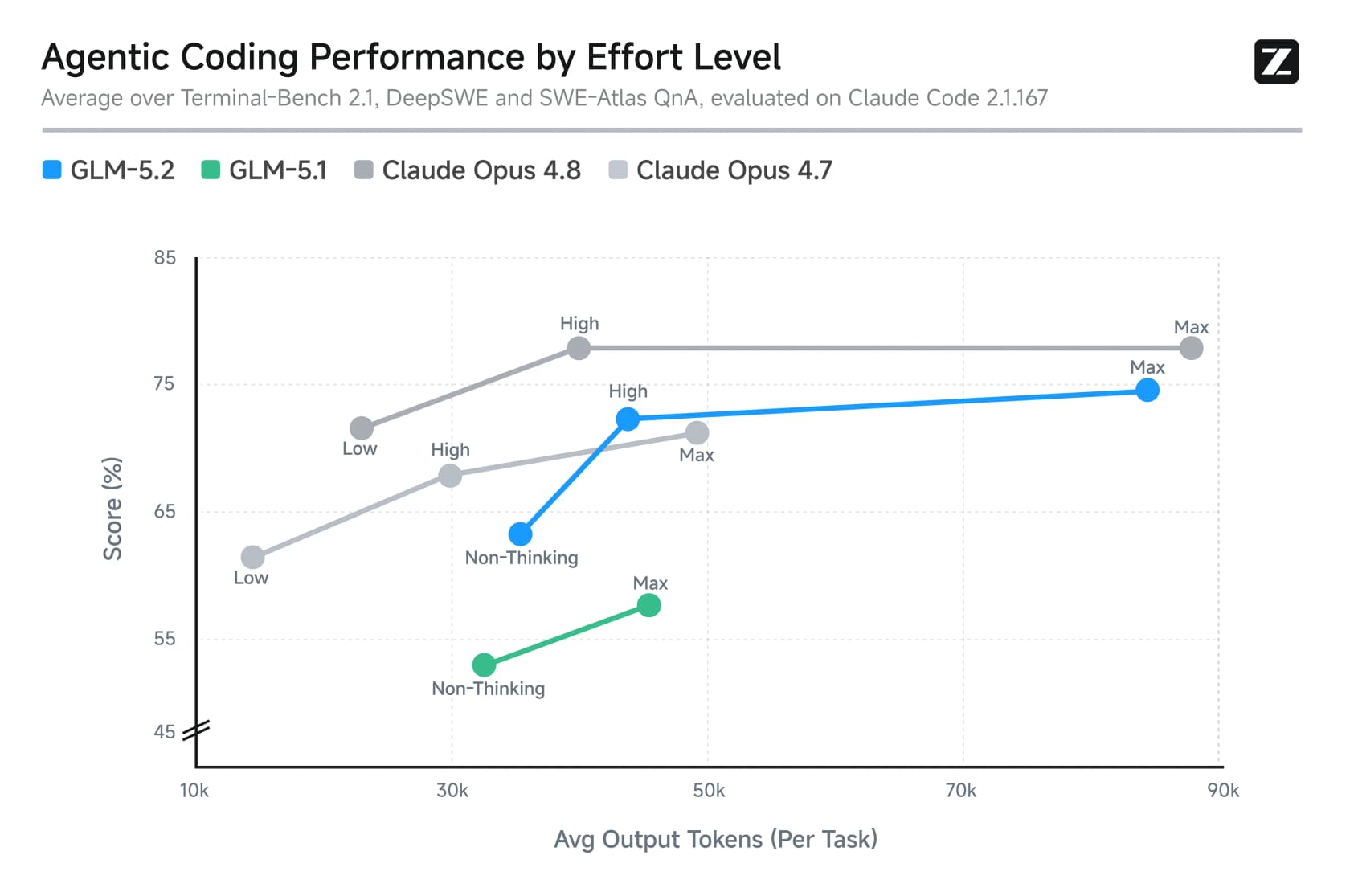
Os pesos abertos são gratuitos, mas "gratuito" precisa de um asterisco. Com 753 bilhões de parâmetros este não é um modelo que você executa em casa. Um desenvolvedor calculou que você precisaria de cerca de oito GPUs Blackwell de 96 GB, "em torno de US$ 150 mil o que já está no território de Pequena/Média Empresa." Quantizações pesadas existem para hobbistas, mas elas arrastam abaixo de um token por segundo. Auto-hospedar é real, mas é uma decisão de data center, não um projeto de fim de semana.
O que os desenvolvedores realmente pensam
A recepção foi barulhenta e, por uma vez, principalmente merecida. Jeremy Howard do fast.ai o chamou de "uma maravilha" que é "pelo menos tão bom quanto o Opus 4.8." Graham Neubig da CMU foi mais longe, chamando GLM-5.2 de "provavelmente o primeiro modelo bom o suficiente para prescindir completamente de modelos fechados no seu workflow." Também ficou em 1º lugar no Design Arena para design web.
O tema mais alto é preço-desempenho. Como um comentarista do Hacker News colocou:
"GLM 5.2 Max = Opus 4.8 Max em comportamento de raciocínio... Em essência, GLM 5.2 é o irmão mais novo do Opus 4.8, a um preço bem, BEM mais barato."
Mas o mesmo thread é onde a honestidade vive, e vale a pena ouvir. Sobre o custo real quando os tokens se somam:
"GLM5.2 acaba sendo muito mais caro do que eu pensei quando tentei no openrouter. Gastei $5 USD em tokens bem rápido. E era high, não max."
E uma leitura mais cautelosa sobre se é verdadeiramente de classe fronteira:
"Big model smell ainda existe e GLM 5.2 embora impressionante não é da classe Fable."
Há também a questão da origem chinesa, que importa muito mais quando você está lidando com dados de outras pessoas. Um pesquisador de segurança no LinkedIn sinalizou que GLM-5.2 "parece ser muito bom em fugas e contornos de sandbox de agentes de IA", e um thread do Reddit colocou a preocupação com privacidade de dados claramente: imagine "uma situação onde a privacidade de dados importa e sua clientela não fica feliz que você está enviando seus segredos para outra organização." Para projetos paralelos de coding, nada disso importa. Para conversas de clientes, é tudo.
O que GLM-5.2 significa para o suporte ao cliente
Aqui está a pergunta que realmente me fazem: um modelo de nível fronteira acabou de ficar seis vezes mais barato, então deveríamos substituir nossa IA de suporte e rodar tudo no GLM-5.2?
A resposta honesta é que o modelo nunca foi a parte difícil do suporte com IA. Construo agentes de IA para atendimento ao cliente como profissão, e o modelo é genuinamente o componente barato e substituível agora. O trabalho difícil, caro e que define a confiança é tudo que está envolto ao seu redor.
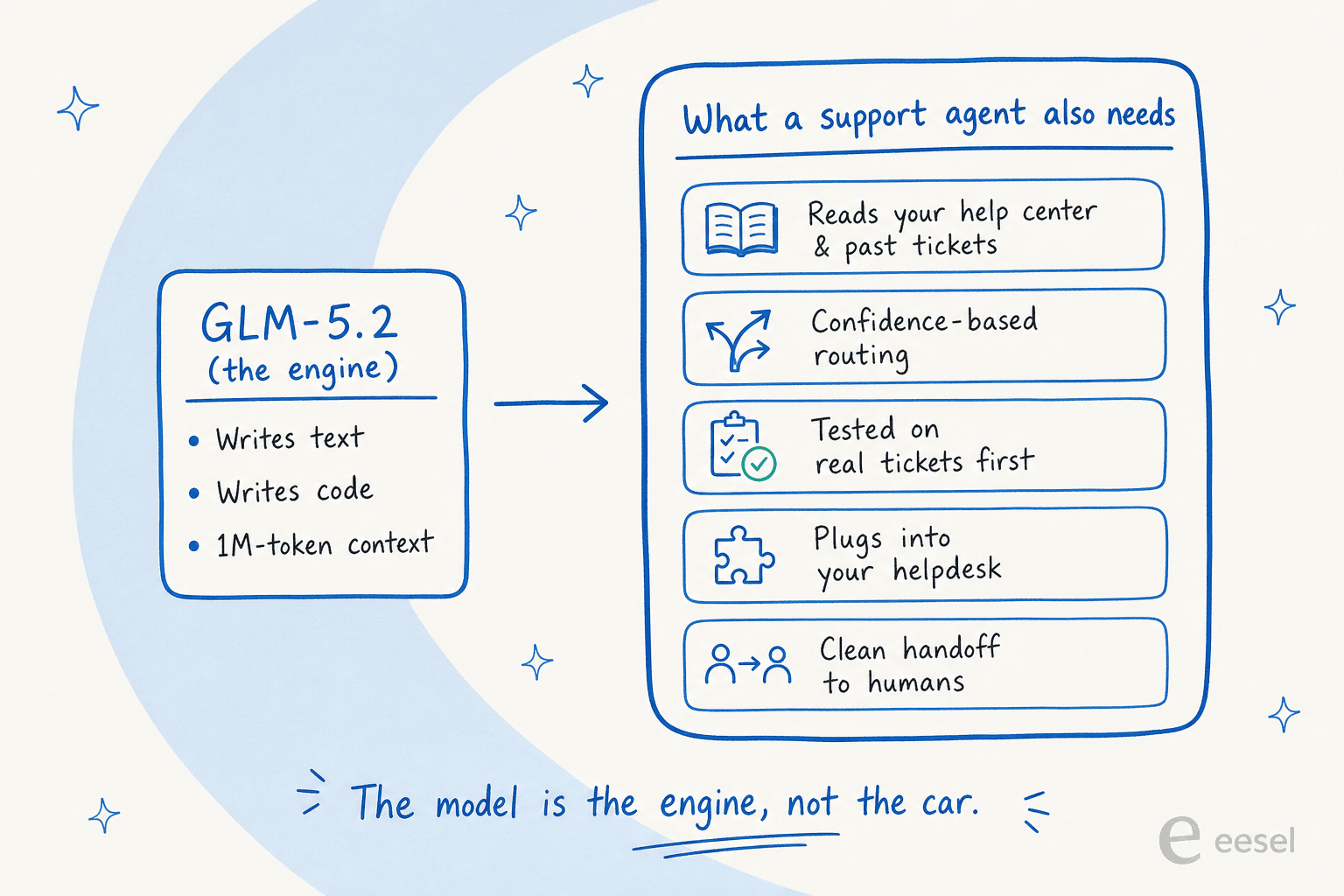
Um modelo bruto escreve texto. Um agente de helpdesk de IA funcional precisa ler sua base de conhecimento e tickets anteriores, decidir quando está confiante o suficiente para responder versus quando transferir para um humano, provar que não vai te envergonhar antes de ir ao ar, e se conectar ao helpdesk que sua equipe já usa. Essa lacuna é a diferença entre um agente de IA e um chatbot baseado em regras, e é a razão pela qual escolher o melhor software de helpdesk de IA é sobre o sistema, não o modelo. GLM-5.2 não faz nada disso sozinho.
Vimos isso se desenrolar do lado de construir versus comprar. Muitas equipes técnicas chegam à mesma conclusão que o engenheiro líder de uma empresa de ATMs de Bitcoin chegou após ponderar se deveria configurar um modelo bruto sozinho:
"Poderíamos tentar escrever nosso próprio aplicativo LLM, mas não queríamos investir nosso tempo nisso. Queríamos algo que não precisaríamos manter."
engenheiro líder em uma empresa de hardware cripto com uma base de conhecimento de mais de 300 artigos, que escolheu comprar em vez de construir
As equipes que tentam a rota DIY com um modelo barato geralmente redescobrem a mesma armadilha: configurar um modelo é um fim de semana; torná-lo seguro, preciso e integrado é um roadmap. Um modelo mais barato torna as contas mais tentadoras, mas não faz os 90% faltantes aparecerem.
Há também o limite de confiabilidade, que o suporte mantém mais alto do que o coding jamais faz. Um desenvolvedor resumiu bem o padrão: "Não usarei um LLM que está disposto a inventar coisas aleatórias. Da mesma forma, também não trabalharei com um humano que faz isso." Em uma tarefa de coding você pega uma alucinação na revisão. Em um ticket de cliente ao vivo, uma resposta confiante e errada vai diretamente para a pessoa que você está tentando manter. É por isso que cada implantação que fazemos é simulada primeiro contra tickets históricos reais, por que o roteamento baseado em confiança importa mais do que uma pontuação de benchmark, e por que as métricas que provam que funciona ficam na taxa de resolução e qualidade de escalonamento em vez do ELO do ranking.
Então: GLM-5.2 é empolgante? Com certeza. É um sinal de que a camada de modelo está se commoditizando rapidamente, e modelos mais baratos e melhores são puro benefício para qualquer um que construa sobre eles. Deveria mudar sua estratégia de suporte? Apenas no sentido de que torna o sistema ao redor do modelo o que vale a pena investir, porque essa é a parte que é realmente sua.
Experimente o eesel
Se a conclusão ficou clara, o eesel é a camada de sistema que descrevi. Você conecta seu helpdesk, sua base de conhecimento e seus tickets anteriores, e o eesel executa um agente de suporte de IA por cima, escolhendo o melhor modelo de fronteira para o trabalho para que você não precise acompanhar GLM versus Claude versus GPT sozinho.

A parte que mais importa para a maioria das equipes: antes que qualquer coisa toque um cliente, o eesel simula o agente em milhares dos seus tickets reais passados, para que você veja a taxa de resolução provável e as respostas exatas antecipadamente em vez de cruzar os dedos. Ele lida com roteamento baseado em confiança e transferência limpa para humanos diretamente, em qualquer helpdesk que você já execute. Experimente o eesel gratuitamente, e deixe as guerras de modelos acontecerem em segundo plano.
Perguntas Frequentes
O que é GLM-5.2 em termos simples?
Quanto custa usar o GLM-5.2?
GLM-5.2 é melhor que Claude ou GPT-5.5?
Posso usar o GLM-5.2 para suporte ao cliente?
O GLM-5.2 é seguro para dados empresariais?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.