AIサポートが機能しているかどうかを知る方法
Alicia Kirana Utomo
Katelin Teen
最終更新 June 17, 2026

まとめ
「AIサポートは機能しているか?」という問いは、1つではなく5つの数値を合わせて確認することに集約されます:解決率、偏向率、回答品質、エスカレーション精度、事実誤認率。解決率と偏向率が上昇しながら品質とCSATが安定しているなら、機能しています。ボリュームが増えているのに満足度が低下しているか、ボットが何も引用せずに自信を持って回答しているなら、どれだけ忙しく見えても機能していません。
落とし穴は、AIエージェントを成果ではなく活動量(「4,000件のチケットに返答した!」)で評価することです。ボットは非常に忙しくありながら、静かに間違いを犯し続けることができます。解決策は、以下に示す少数の指標を監視し、良いシグナルと警戒シグナルを見分けることを学び、できれば本番運用を信頼する前に実際の過去チケットでシミュレーションを行うことです。
私はeeselでAIエージェントをライブサポートキューに導入して3年以上経ちます。これが実際に使うスコアカードです。
「機能しているか?」が見た目より難しい理由
ほとんどのダッシュボードが教えてくれないことがあります。AIサポートにおける怖い失敗パターンは、ボットが黙ってしまうことではなく、ボットが間違いながら素晴らしく聞こえることです。
自信満々な口調のエージェントが「はい、そのカーモデルをサポートしています」と顧客に伝えているのを見たことがあります。その車のブランドはナレッジベースに全くなかったのに、ヘルプドキュメントに「すべてのモデルをサポートしています」と書かれていたためです。ボットは壊れていませんでした。言われた通りのことをし、完璧に流暢に見えていました。だからこそ、今ではすべてのロールアウトをまず過去チケットでシミュレーションしてから、スイッチを入れて期待するのではなく進めています。
数値に移る前に:「機能する」とは、AIが正しいチケットを正しく解決し、残りを適切に引き継ぎ、その間に何も作り上げないことを意味します。活動数は虚栄心です。成果が真実です。この記事から1つだけアイデアを持ち帰るとすれば、それがそれです。
実際に教えてくれる5つの数値
チームがAIエージェントをどのように読むかを尋ねてきたとき、私は同じ5つのカスタマーサポート指標を指し示します。合わせて読むことで、ほぼすべての失敗パターンをキャッチできます。
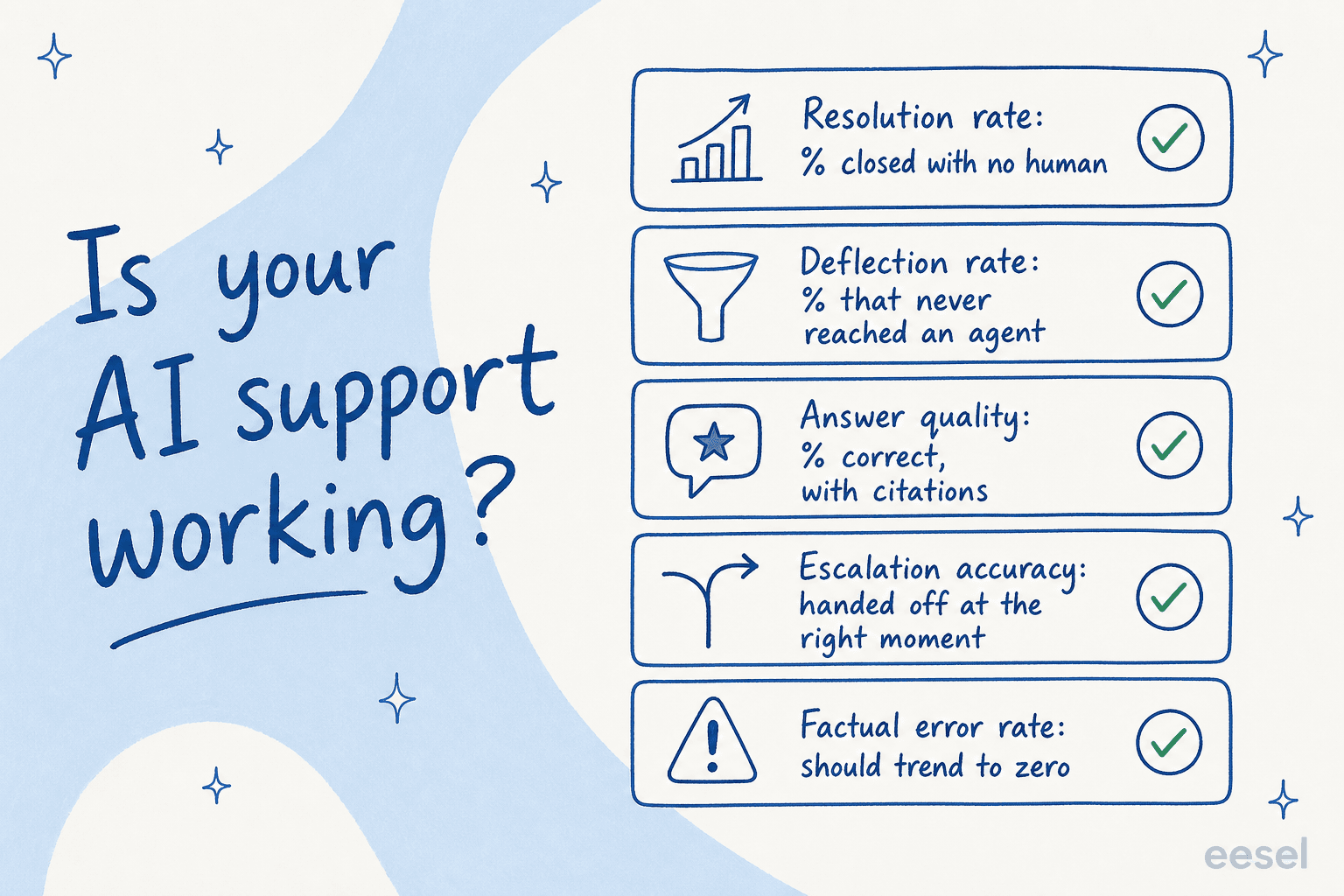
1. 解決率
主要な数値:AIが人間を介さずにエンドツーエンドでクローズしたチケットの割合。これはコストに直結します。なぜなら、解決されたチケット1件はエージェントが開かなくて済んだ1件だからです。
「良い」とはどれくらいか?それはチケットの種類によって完全に異なりますが、ティア1はAIが最初に価値を発揮する場所です。Zendesk上のあるギグエコノミーのドライバー分析アプリは、公開G2レビューでeeselが最初の月にティア1リクエストの73%を解決し、7日間のトライアル内で結果が確認できたと述べました。一方で、Jira上の社内ITヘルプデスクは偏向率15%から始まり55%を目標に設定しました。どちらも「機能している」状態です。重要なのは普遍的なベンチマークではなく、傾向です:エージェントにより多くのナレッジを与えるにつれて解決率は上昇していますか?
2. 偏向率
偏向と解決は互換的に使われることがありますが、そうすべきではありません。解決は人間なしでクローズされたチケットです。偏向は、顧客が回答を得てチケットをまったく開かなかったこと、通常はチャットウィジェットやセルフサービスを通じてサポートケースになる前に解決されることです。
これを別途追跡する価値があるのは、高い偏向率がキューを静かに縮小させるものだからです。正確な定義と計算式を知りたい場合は、偏向率とは何か、どのように改善するかについて書きました。また、二重カウントしないようAI偏向と人間の偏向を測定する方法についての別の記事もあります。
3. 回答品質
質のないボリュームは落とし穴です。解決率の背後にある本当の問いはこうです:AIが回答したとき、それは正しかったか、そして作業を示したか?
これは測定可能です。581件のチャットにわたる1週間のサンプルで、チャット品質を96%と評価しました。434件のチャットの別のサンプルでは内訳は86%良好、7%部分的、6%偏向、1%完全失敗で、実際のwebhookトリガーチケット(より難しいテスト)では79%良好でした。正確な方法よりも方法を持つことの方が重要です:正確性と引用の有無について回答のサンプルを評価してください。ソースが添付されていない回答は信頼できない回答です。私たちが協力しているあるリーガルテックの創業者はうまく表現しました。eeselで「ソースに正確なガードレールを設定でき、常に透明な引用を提供する」ことができ、彼らの世界では役立つことと訴訟の違いだと。
4. エスカレーション精度
良いAIエージェントは自分が何を知らないかを知っています。そのため、エスカレーション精度は本当に判断力の測定です:AIが不確かだったとき、推測する代わりに人間に引き継ぎましたか?
これはリストで最も過小評価されている数値です。すべてに回答するのではなく、自信を持って解決し誠実にエスカレートするエージェントが欲しいです。あるSMSプラットフォームのサポートリードがG2レビューで理想を見事に表現しました:AIは「自信を持って、でも過度な自信を持たずに回答する」と。その後半部分がすべてです。エスカレーション率と、さらに重要なことに、エスカレーションが適切なタイミングで発生しているかどうかを追跡してください。
5. 事実誤認率
最後に、ゼロに向かって傾向するべき数値:AIが誤ったことを述べる頻度。これは「部分的な」回答とは異なります。事実誤認は、ボットが誤った事実を確実なものとして述べることです。
あるドイツのジュエリー小売業者の実際のZendeskトラフィック(月間約1,000チケット)での試験で、トリアージ精度93%、スパム検出100%(偽陽性ゼロ)を測定しましたが、同時にナレッジベースにギャップがある場所を正確に教えてくれた7%の事実誤認率もありました。その7%はロールアウトを断念する理由ではありませんでした。それは地図でした。各事実誤認は欠落または矛盾したドキュメントを指し示し、通常は修正可能であり、サポートにおけるAIハルシネーションを防ぐガイドのほとんどがカバーする内容です。
良いシグナル(と警戒シグナル)
数値は傾向を示します。しかし、1つの午後にトランスクリプトをざっと見るだけで読み取れる定性的なシグナルがあり、1ヶ月分のデータを待つよりも速いことが多いです。
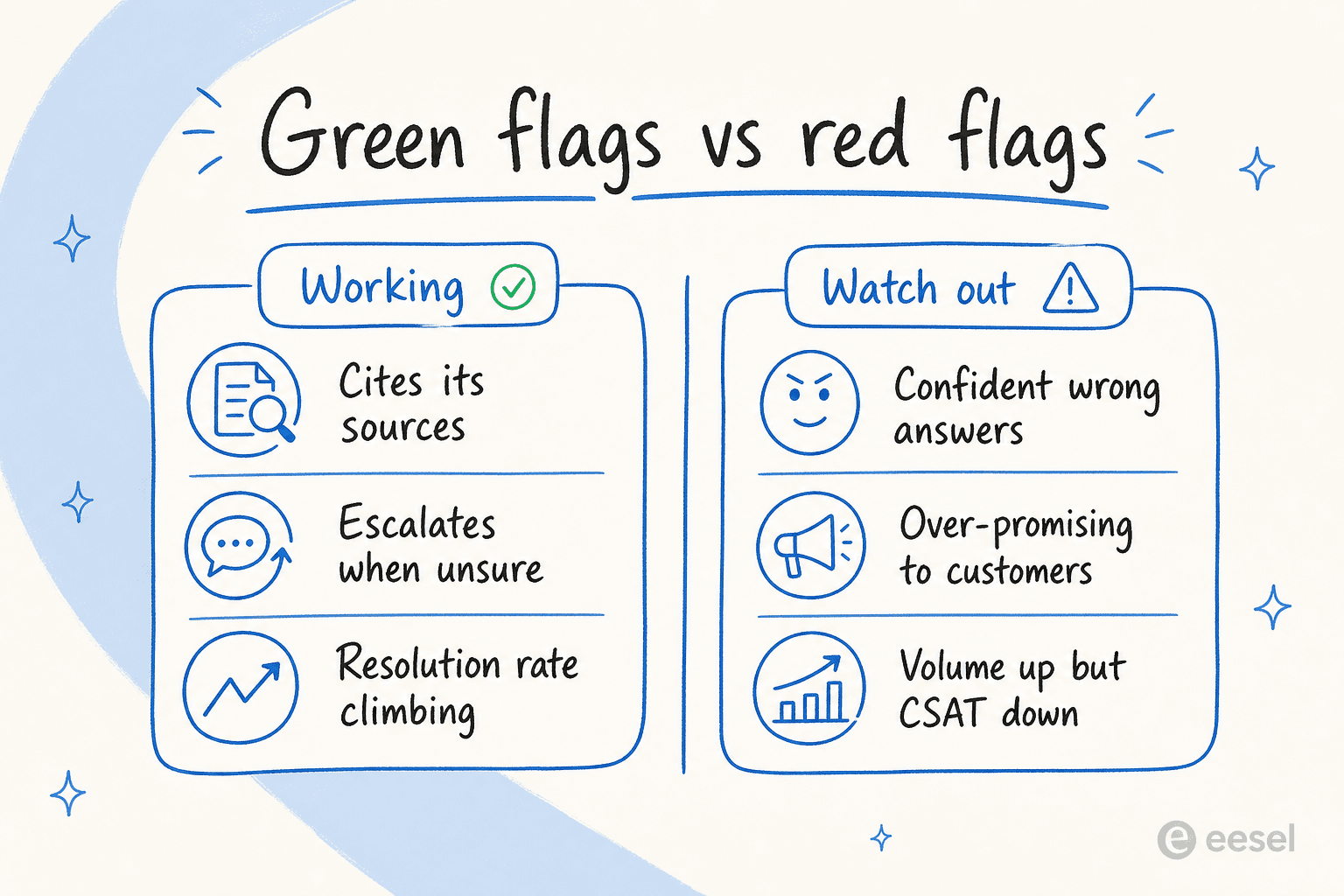
良いシグナルは簡単です。AIはすべての回答でソースを引用します。虚勢を張る代わりに本当に不確かなときにエスカレートします。解決率が週ごとに上昇傾向にあり、横ばいではありません。そして最も単純なサイン、エージェントが繰り返しのチケットについての不満を言わなくなります。
警戒シグナルは、見た目の良いダッシュボードの裏に隠れているため、注意を向けるべきところです:
- 自信ある誤回答。 先ほどの車のモデルの例。ボットは流暢で確信があり、不正確です。これが最も有害なパターンです。なぜなら顧客はそれを信じるからです。
- 過度な約束。 エージェントが企業がバックアップできない方法で顧客を安心させるのを見てきました。あるサポートマネージャーは直接的に指摘し、AIに「解決できると顧客に伝えるのを止めろ。知らないだろう」、「できないことを顧客に約束するな」と言いました。ボットが配送日や結果についての約束をしているなら、それはナレッジの問題ではなくコントロールの問題です。
- ボリューム増加、CSAT低下。 エージェントはより多くを処理しているが、顧客の満足度は低下している。その乖離が「忙しい」と「機能している」が分離した最も明確なサインです。
- 引用なし。 回答がどこから来たかわからなければ、顧客もわかりません。後で監査する際もあなたもわかりません。
これらのほとんどはナレッジギャップまたはガードレールの欠如に起因しており、それは良いニュースです。なぜなら両方とも何も取り壊さずに修正可能だからです。AIチャットボットの一般的な問題の記事で通常の原因をより深く掘り下げています。
実際にどこを確認するか
これはすべて、AIエージェントが何をしているかを見られることを前提としています。ツールが合計数しか表示しない場合、それが最初に修正すべきことです。読めないものは管理できません。
私が最もよく確認する2つのビューは、レポートダッシュボードと生のアクティビティログです。レポートビューは傾向が見える場所です:時間ごとのタスクボリューム、タスクがどのようにトリガーされたか(チャット、メール、内部メモ)、そしてAIアクションが承認・拒否・人間の決定待ちが何件あるか。その承認対拒否の比率は信頼の速やかな代替指標です。

アクティビティログは実際の作業を確認する場所です。すべての会話、そのチャンネル、リンクされたチケット、解決済みか保留中かのステータス。ここで回答品質をスポットチェックし、集計数値が滑らかにしてしまう自信ある誤回答のケースを発見します。最低でも週に10件はざっと見るべきです。

ヘルプデスクがすでにクローズした会話にCSATサーベイを実施している場合、そのスコアを特にAI対応チケットに紐付けてください。AI解決チケットと人間解決チケットのCSATを比較するその1つの切り口が、「実際に良いのか?」という議論をほかの何よりも早く解決します。
ライブになるまで待たないで
ほとんどのチームが省略するこの部分が、私が最も強調したい部分です:実際の顧客でテストすることなく、AIが機能するかどうかを発見する必要はありません。
失敗は、本番稼動をオン/オフスイッチとして扱うことです。より良いモデルはランプです。数値が証明されるにつれて、AIを自律性の段階を経てランクアップさせます。それより前ではありません。
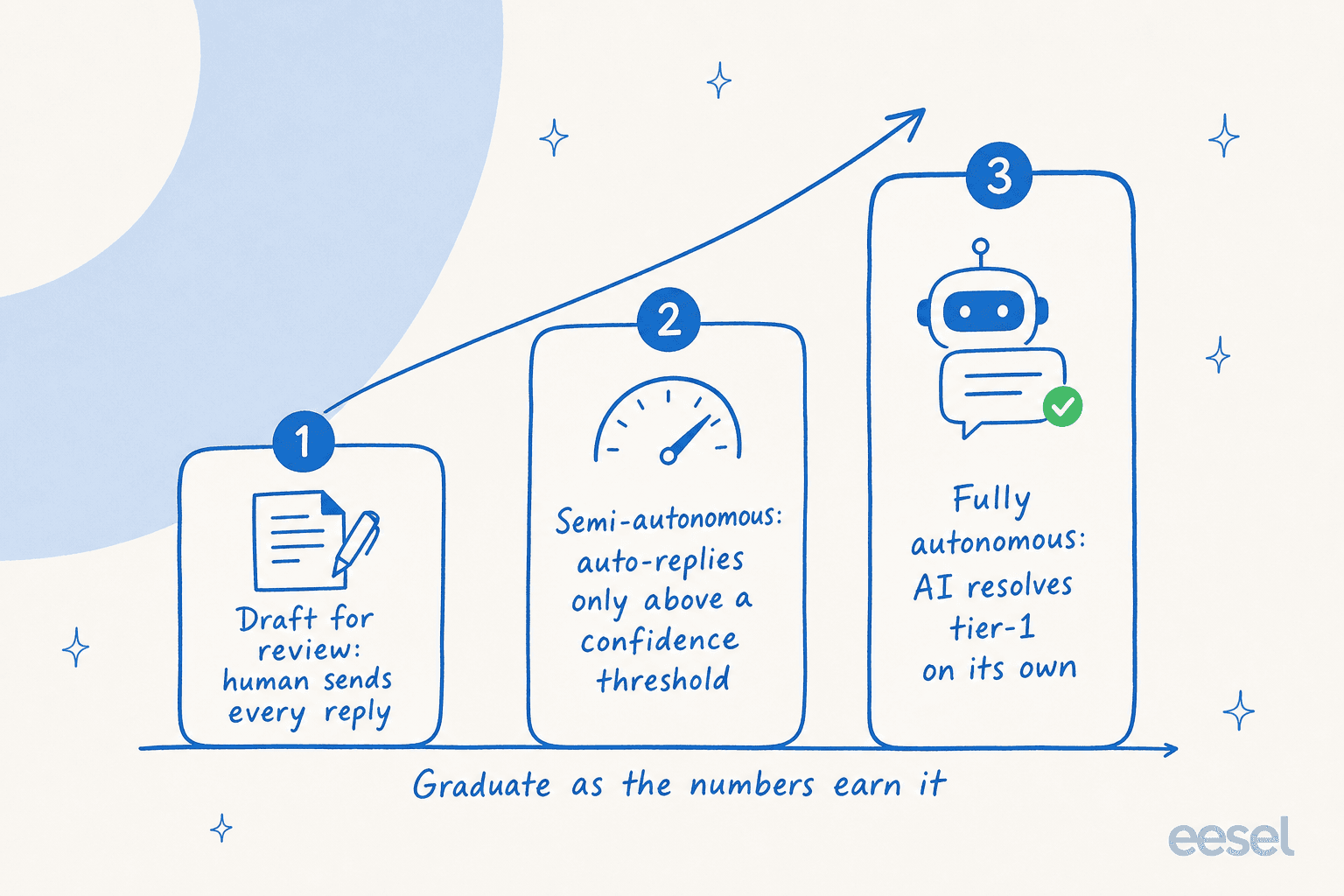
ドラフトモードから始めます。AIが返答を書き、人間が1件ずつ送るので、顧客リスクなしで品質を評価できます。回答が証明されるにつれて、準自律に移行し、信頼閾値以上のみAIが自動返答し、残りは人に転送します。数値が維持されたら、獲得したティア1ケースで完全自律で実行させます。
ドラフトモードの前でも、実際の過去チケット数千件に対してシミュレーションを実行し、予測解決率とともにAIが各チケットにどのように回答したかを確認できます。それはライブ返答が1件も送られる前です。先ほど言及したドイツのジュエリートライアルは正確にこの方法で100チケットのクロスバリデーションを実行しました。シミュレーションを先に行うことが、顧客を1人もリスクにさらす前に「機能しているか?」に回答する方法です。それはまた、正直に言えば、より多くのチームにやってほしい部分です。なぜなら信仰の跳躍を測定に変えるからです。
公平な注意事項として、私はこれに取り組んでいるため:eeselはZendesk、Freshdesk、Help Scoutなどのヘルプデスクと深く統合されているため、カテゴリーの中立的な観察者ではありません。しかし、ランプアンドシミュレーションのアプローチは使用するツールを問わず成り立ちます。AIベンダーが自分のチケットに対するドライランを見せられない場合、それ自体が尋ねるべき黄色のシグナルです。
eeselを試す
「AIサポートは機能しているか?」を感覚ではなく数値で答えたいなら、それがeeselが解決するために作られた問題です。ヘルプデスクとナレッジソースを接続し、シンプルな言葉でエージェントを設定し、過去チケットのシミュレーションを実行して本番稼動前に予測解決率を取得し、各ステップを裏付けるレポートとともにドラフトモードから自律性へとランプアップします。

1席ごとの料金なしで使用量ベースの料金設定で動作し、自分のキューでテストするための無料ティアもあります。他のチームがロールアウトをどのように測定したかは顧客事例ページで確認できます。また、完全なプレイブックのためにカスタマーサポートにおけるAIの実践ガイドをお読みください。eeselを試して、本当の解決率がどれくらいかを確認してください。
よくある質問
AIサポートが機能しているかどうかをどうやって知ることができますか?
AIサポートエージェントの良い解決率はどれくらいですか?
AI偏向とAI解決の違いは何ですか?
AIサポートエージェントが失敗しているサインは何ですか?
顧客に返答する前にAIサポートをテストできますか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.