AIサポートエージェントのトレーニング方法(顧客の信頼を得るために)
Alicia Kirana Utomo
Katelin Teen
最終更新 June 20, 2026

まとめ
AIサポートエージェントのトレーニングはコーディングプロジェクトではなく、「FAQをアップロード」するだけの一回限りのステップでもありません。作業は4つのことです:実際の知識を与え、過去のチケットに対してシミュレーションし、間違った回答をコーチングし、確信がある時だけ返信するように信頼度で制御する。
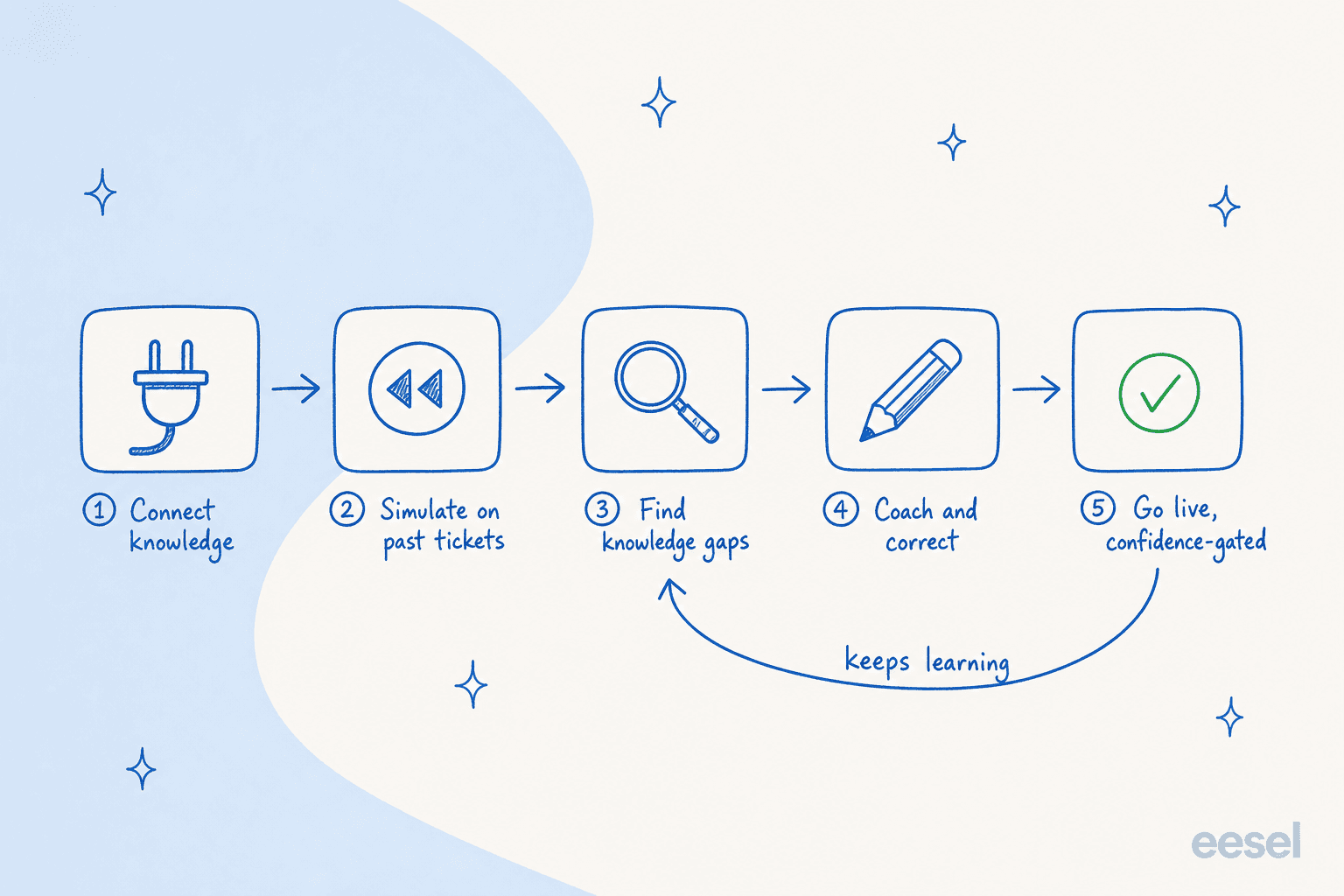
最も多く見かける間違いは、ヘルプセンターの記事だけでトレーニングすることです。記事はエージェントに公式の答えを教えます。しかし解決済みチケットは、チームが実際にどのように返信するかを、あなたのトーンで、顧客が本当に送る複雑な質問に対して教えます。チケット履歴をスキップすると、あなたらしくない礼儀正しいボットができあがります。
もう一方の半分は信頼です。自信を持って推測するエージェントは、エージェントがいないよりも悪いです。解決策はローンチ前にシミュレーションし、その後信頼度でルーティングすることで、低信頼度のチケットが間違った回答ではなくドラフトやクリーンな引き渡しになるようにすることです。これを自分で構築せずに実現したい場合、それがまさにeeselが既存のヘルプデスク内で行うことであり、何も支払う前に無料エージェントをトレーニングしシミュレーションすることができます。
私はeeselでAIエージェントを構築しているため、これらのほとんどは何千もの本番サポートロールアウトで何が機能し(そして何が爆発する)かを観察することから来ています。信頼部分は痛い教訓で学びました:自信があるように聞こえるボットが静かに間違った回答をしているのを見てきたため、今は顧客に触れる前に会社の過去のチケットに対して各ロールアウトをシミュレーションします。ゼロからどのようにトレーニングするかをお見せします。
AIサポートエージェントのトレーニングが実際に意味すること
「トレーニング」は機械学習のように聞こえます:データにラベルを付け、モデルを微調整し、ジョブの完了を待つ。現代のサポートエージェントでは、そうではありません。基礎となる言語モデルはすでにトレーニング済みです。あなたがしていることは、あなたのビジネスを教えることです:あなたのポリシー、製品、声、そして何をすることが許可されているかの境界。
内部的には、それは主にファインチューニングではなく検索を意味します。エージェントは回答時にあなたの知識を読み、ドキュメントを重みに記憶するのではなく、引用できるソースに各返信を基づかせます。その区別には実用的な理由があります:ヘルプ記事を修正すると、エージェントはモデルジョブを再実行することなく即座に「再トレーニング」されます。また、ルールベースのチャットボットとAIエージェントは同じものではないことも意味します。一方は手動で構築したデシジョンツリーに従い、もう一方はあなたの知識を推論して自分で決定します。
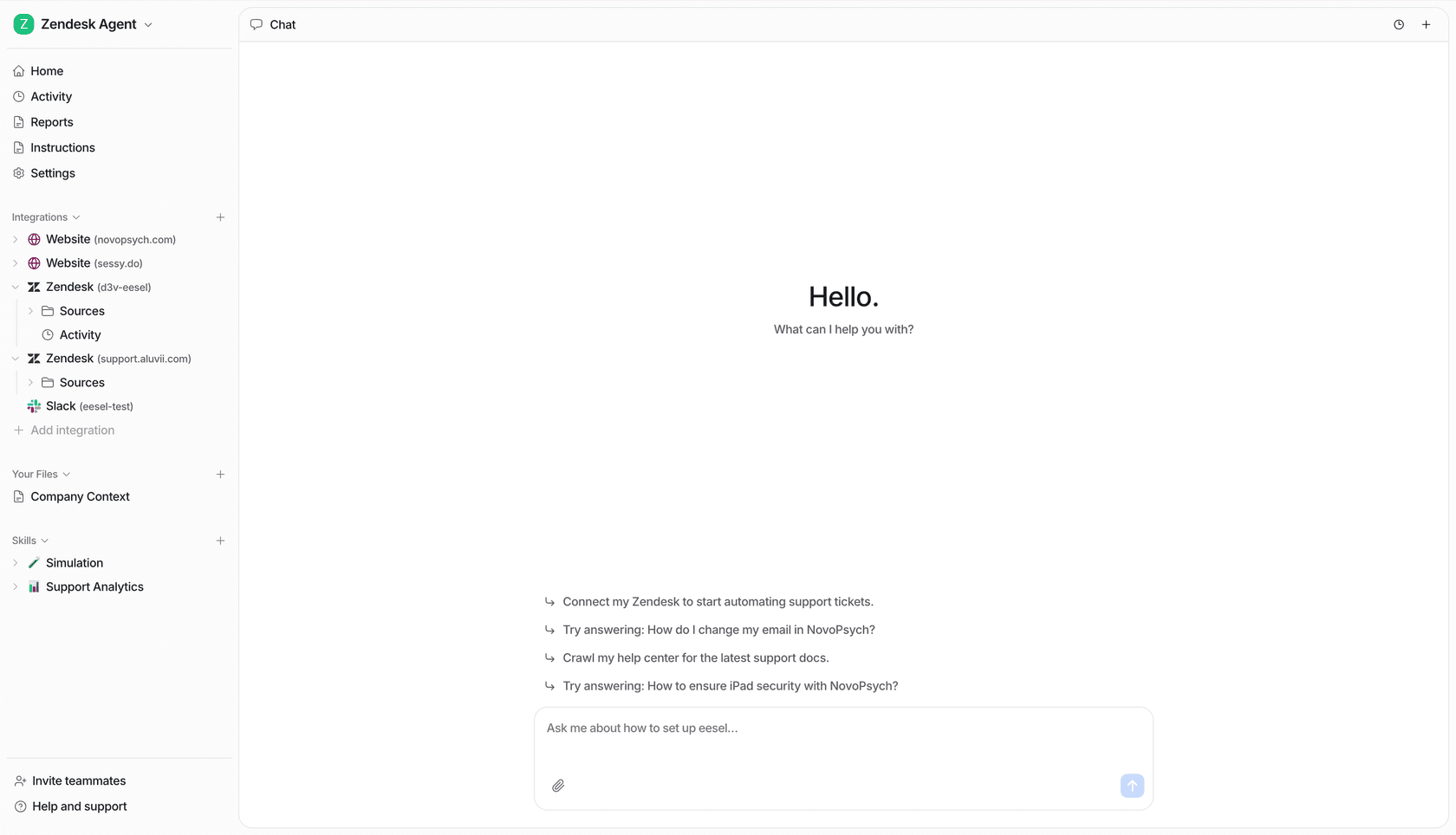
そのため、作業は5つのステージに分かれ、ループはステップと同じくらい重要です:最後のステージはローンチ後ずっとエージェントにフィードバックします。
ステップ1:チケットに合った知識を与える
これ以降のすべてはここにかかっています。エージェントは読めるものと同じくらい優秀なので、最初の仕事は正しい順序で正しいソースを指定することです。
解決済みチケットから始めましょう。これがチームがスキップする部分であり、最も重要な部分です。ヘルプセンターの記事は質問のきれいなバージョン向けに書かれています。実際のチケットは顧客が実際にどのように質問するか、そしてあなたの最良のエージェントが実際にどのように答えるかを示します。チケットでトレーニングすると、エージェントはあなたの表現、返金の言い回し、「修正している間の回避策はこれです」というトーンを受け継ぎます。過去チケットのトレーニングは、私がセールスコールで聞く中で最も多くリクエストされる機能です。チームが声の違いを見ると、それを求めるのをやめて、なぜ誰もがそうしないのかを聞き始めます。
次に残りを追加します:
- ヘルプセンターと公開ドキュメント:ポリシーと製品に関する標準的な回答のため。
- 内部知識:記事にはならなかったもので、Confluence、Google Docs、Notion、またはSlackチャンネルに存在するもの。
- マクロと保存済み返信:基本的にチームがすでに信頼している事前承認済みの回答。
- 注文とアカウントデータ:Shopifyなどのツールを通じて、エージェントが「注文はどこにありますか」を回避ではなく実際の検索で答えられるように。
注意すべきこと:ある対象者向けに書かれているが別の対象者に読まれる知識。私は、ドキュメントがすべて管理者向けに書かれているが、チケットは一般的な乗客から来ている交通技術チームとこれを解決しました。エージェントには事実があったが、間違ったレジスターでした。解決策はより多くのドキュメントではなく、エージェントに誰と話しているかを伝えることでした。これはコーチングステップ(ステップ3)であり、知識のギャップではありません。サポートのための優れた知識管理がエージェントのトレーニングの半分です。
eeselでは、これらを接続することが文字通り最初の画面です:ZendeskやFreshdeskなどのヘルプデスクに向け、ドキュメントを追加すると、100以上のインテグレーションでインデックス化されます。複数のブランドを運営している場合は、ブランドごとに別のエージェントをトレーニングすることができ、それぞれが自分自身の履歴からのみ学習します。
ステップ2:顧客が見る前に自社の履歴に対してシミュレーションする
これが責任あるロールアウトと希望的なロールアウトを分けるステップであり、ほとんどのツールが提供しないものです。
エージェントが1人の本番顧客に返信する前に、すでにクローズしたチケットに対して実行します。チームがすでに書いたため正しい答えを知っているので、シミュレーションはあなたのデータでエージェントがどのように行動したかを教えてくれます:何件のチケットを解決したか、どこで躊躇したか、そしてどこで確信を持って間違っていたか。最後のカテゴリが探すべきものです。「わかりません」と言うボットはうっとうしい;返金ポリシーを作り出すボットは責任問題です。
ここは早期に本番稼働させたいという誘惑に抵抗するところです。最初のクリーンな回答の後の誘惑はそれをオンにすることです。やめましょう。シミュレーションした回答をチケットごとに読んでください、特に間違えたものを。それぞれが顧客を失う前に無料で得られるコーチングの機会だからです。
シミュレーションはまた、ベンダーのマーケティング数字ではなく正直な予測を得る方法でもあります。実際のボリュームでのエージェントの見込み解決率が見え、それが本番稼働の決定を促進すべき数字です。これを実施したあるチームでは、成果が早かったです:
「最初の月で、eeselは当社の第1ティアリクエストの73%を解決しています...7日間のトライアル中に結果が出ました。」
Kim Simpson、Gridwise(G2レビュー)
ステップ3:コードではなく自然な言葉でコーチングする
エージェントが間違えた回答のリストができたら、それを修正します。良いニュースは、現代のトレーニングは会話的だということです:設定ファイルを編集するのではなく、新入社員にブリーフィングするように、エージェントに何を違う形でするかを伝えます。
コーチングは通常いくつかの形をとります:
- ソースを修正する。 ヘルプ記事が古いために回答が間違っていた場合、記事を更新すればエージェントは即座に修正されます。
- 指示を調整する。 トーン、長さ、いつエスカレートするか、絶対に言わないこと。「請求の質問には常にドラフト、自動送信しない」は1行の指示であり、ワークフロー構築ではありません。
- 対象者を設定する。 上記の乗客vs管理者の場合のように、内部の技術的なドキュメントを顧客に優しい回答に翻訳するようエージェントに伝えることができます。

ここで確認すべきことは、コーチングが実際に定着しているかどうかです。私が協力しているドッグトレーニングの小規模ビジネスはよく表現しました:エージェントを再テストするとコーチングを正しく取り込んでいることが確認でき、信念ではなく学習しているのを見ることができると気に入っていました。そのフィードバックループ、何かを変えて再シミュレーションする、がゲーム全体です。ツールがコーチングを許可するが再テストを許可しない場合、盲目で編集しています。
ここはまたエスカレーションルールを構築する場所でもあります。よくトレーニングされたエージェントは何を処理しないかを知り、クリーンに引き渡します。これは答える質問と同じくらい重要です。引き渡しを正しくすることが、顧客がボットに閉じ込められていると感じないようにするものです。
ステップ4:返信させる前に信頼度でゲートする
これがこのガイド全体で最も重要なアイデアであり、購入者が最も気にすることです。「AIがすべて答える」と「AIが何も答えない」の間で選ぶ必要はありません。信頼度しきい値を設定し、エージェントはバーをクリアしたときだけ自分で返信します。
月約7,000チケットを処理するサプリメントブランドのCXリードは私が言えるより直接的に言いました:AIは100%の質問には絶対に答えられず、それで構わないが、「自信を持って処理できるチケットだけを処理するAIが必要で、他のものはすべてそっとしておいてほしい。」それが安全なロールアウトの全命題です。高信頼度、自動返信。低信頼度、人間用ドラフトまたは引き渡し。推測なし。
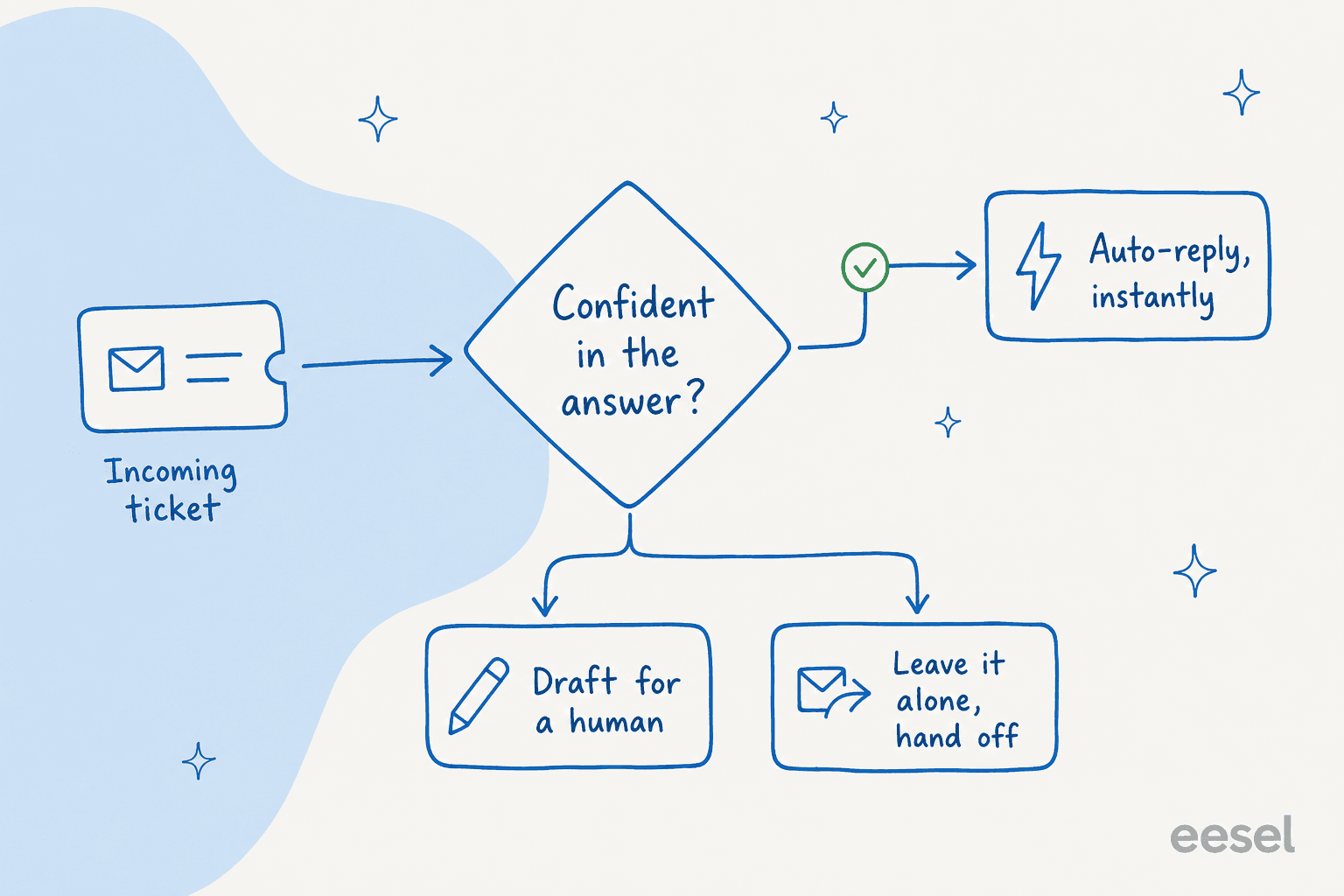
信頼度ゲーティングはまた安全にスケールする方法でもあります。エージェントをドラフトオンリーモードで開始して人間がすべての返信を承認し、品質を観察してから、パスワードリセットや注文状況などの獲得したチケットタイプで自律性を与え、難しいものは監視下に置きます。自動化から特定のカテゴリ全体を除外することもできます。これがチームが「AIに通してほしくない特定のチケットがある」と言うときに求めるものです。信頼度ルーティングと各回答への引用を組み合わせると、虚偽のボットに対する最も強力な2つのガードレールが得られます。この段階的アプローチがあらゆる合理的な第1ティアデフレクションプランの骨幹です。
ステップ5:ローンチ後もトレーニングを続ける
トレーニングは、完了してから忘れるローンチ日のマイルストーンではありません。最良のエージェントはチームがループを実行し続けるため毎週改善します。
3つの習慣がエージェントを鋭く保ちます:
- ミスをレビューする。 エージェントがドラフトまたはエスカレートしたチケット、そして顧客が押し返したものを見ます。それぞれがステップ3と同様のコーチングインプットです。
- 見つけたギャップを埋める。 優れたエージェントは、聞かれ続けているがソースのないトピックを浮上させます。そうすることで記事を書いたり(またはそれが代わりに下書きしたり)できます。ここであなたのナレッジベースとエージェントが互いを改善します。
- チケットだけでなくトレンドを見る。 解決率、エスカレーション率、処理時間などのサポートメトリクスは、トレーニングが成果を出しているか、静かにドリフトしているかを教えてくれます。

良い副次的効果:よくトレーニングされたAIエージェントは人間チームのコーチとしても機能します。ある小規模ビジネスは、新入社員が「24/7でお問い合わせの処理方法をコーチングしてくれる上司」を持てることが最も嬉しいと言いました。エージェントのドラフトが新しい担当者に良い回答がどのように見えるかを示すからです。AIをトレーニングすることは、チケットをそらすだけでなくチーム全体を向上させることになります。
AIサポートエージェントのトレーニングでよくある間違い
失敗パターンは予測可能なので、避けるべきことを示します:
- ドキュメントのみでトレーニングする。 上で説明しましたが、最も多い間違い第1位です。チケット履歴がないということは声がないということ。
- シミュレーションなしで本番稼働する。 自社の過去チケットでエージェントがどのように機能するか見ることができない場合、希望で立ち上げています。最初に適切なテストを主張してください。
- 全か無かの自律性。 1日目に完全自動返信にエージェントを切り替えることが恐ろしい話を生む方法です。信頼度ゲーティングで段階的に移行してください。
- セットアップを一度限りとして扱う。 1月のポリシーで1月にトレーニングされたエージェントは、誰もループを実行し続けなければ3月までに間違いになります。
- クリーンな引き渡しがない。 優雅にエスカレートできないエージェントは顧客を閉じ込めます。クレームが来た後ではなく、ローンチ前にエスカレーションパスを構築してください。
これらを正しく行うと、トレーニングはプロジェクトのように感じなくなり、たまたまとても早く学ぶチームメンバーを管理することのように感じ始めます。信頼側のより深いバージョンが必要な場合、ハルシネーション防止ガイドがさらに詳しく説明しています。またヘルプデスクエージェントまとめは、これを簡単にするツールと大変にするツールを比較しています。
eeselを試す
エージェントをトレーニングすることを好み、トレーニングパイプラインの構築は好まない場合、それがeeselの全ポイントです。既存のヘルプデスクに接続し、初日から過去チケットとドキュメントから学習し、1人の顧客が返信を見る前にチケット履歴に対してシミュレーションすることができます。楽観主義ではなく証拠でローンチできます。
指摘したい差別化要因は、シミュレーションプラス信頼度のループです:自社データで実際の解決率予測を得て、自然な言葉でコーチングし、AIが触れることを許可するチケットを正確に制御できます。料金は席ごとの料金なしの使用量ベースで、無料トライアルでコミットする前にエージェントをトレーニングしてテストするための$50の使用量が得られます。
よくある質問
AIサポートエージェントをトレーニングするにはどうすればよいですか?
AIカスタマーサポートエージェントのトレーニングにはどのくらい時間がかかりますか?
AIサポートエージェントのトレーニングにはどのようなデータが必要ですか?
トレーニングされたAIサポートエージェントが間違った回答をしないようにするにはどうすればよいですか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








