要点
AIエージェントループとは、言語モデルをエージェントに変える反復サイクルです。入力を知覚し、何をすべきかを推論し、ツールを呼び出して行動し、結果を観察し、そして再びループに戻る——これを何度も繰り返し、タスクが完了するか停止ルールが発動するまで続けます。この単一のアーキテクチャ的アイデアこそが、エージェントとチャットボットの違いそのものです。チャットボットは1回のパスで答えますが、エージェントは進み続け、ステップを連鎖させ、何かが失敗しても回復できます。
だからこそ人々は半ば冗談で、エージェントを「ツールを持ったwhileループの中のLLM」と呼ぶのです。このループは、エージェントがカスタマーサポートで機能する理由そのものでもあります。チケットは複数ステップの仕事(問題を特定し、調べ、アクションを実行し、機能したか確認し、解決またはエスカレーションする)であり、それは直線ではなくループです。このループを、配管部分を自分で構築・お守りすることなくヘルプデスク内で動かしたいなら、それこそがeeselの役割です。
一文での定義
AIエージェントループ(エージェンティックループとも呼ばれます)とは、あらゆるエージェンティックシステムの中核にある反復実行サイクルのことです。モデルは入力を繰り返し知覚し、次に何をすべきかを推論し、ツールを呼び出して行動し、その結果を観察して次のラウンドに送り込み、タスクが完了するか停止条件に達するまでこれを繰り返します。
Oracleの開発者チームはこの区別を率直に言い表しています。「チャットボットとAIエージェントのアーキテクチャ上の違いは、たった1つのパターン、すなわちエージェントループだ」。実務家のSimon Willison版はさらに短いです。エージェントとは、彼によれば、「目標を達成するためにツールをループで実行するもの」です。
これが実際、概念のほとんどです。面白いのは、ループの各段階が実際に何をするのか、なぜループが単一のモデル呼び出しではできないことを可能にするのか、そしてどこで真価を発揮するのか、という点です。
4つの段階:知覚、推論、行動、観察
ほとんどの説明は、ループを繰り返す4つの段階に集約します。Oracleは5段階版を使っています(推論から計画を分離している)が、メカニズムはどちらでも同じです。
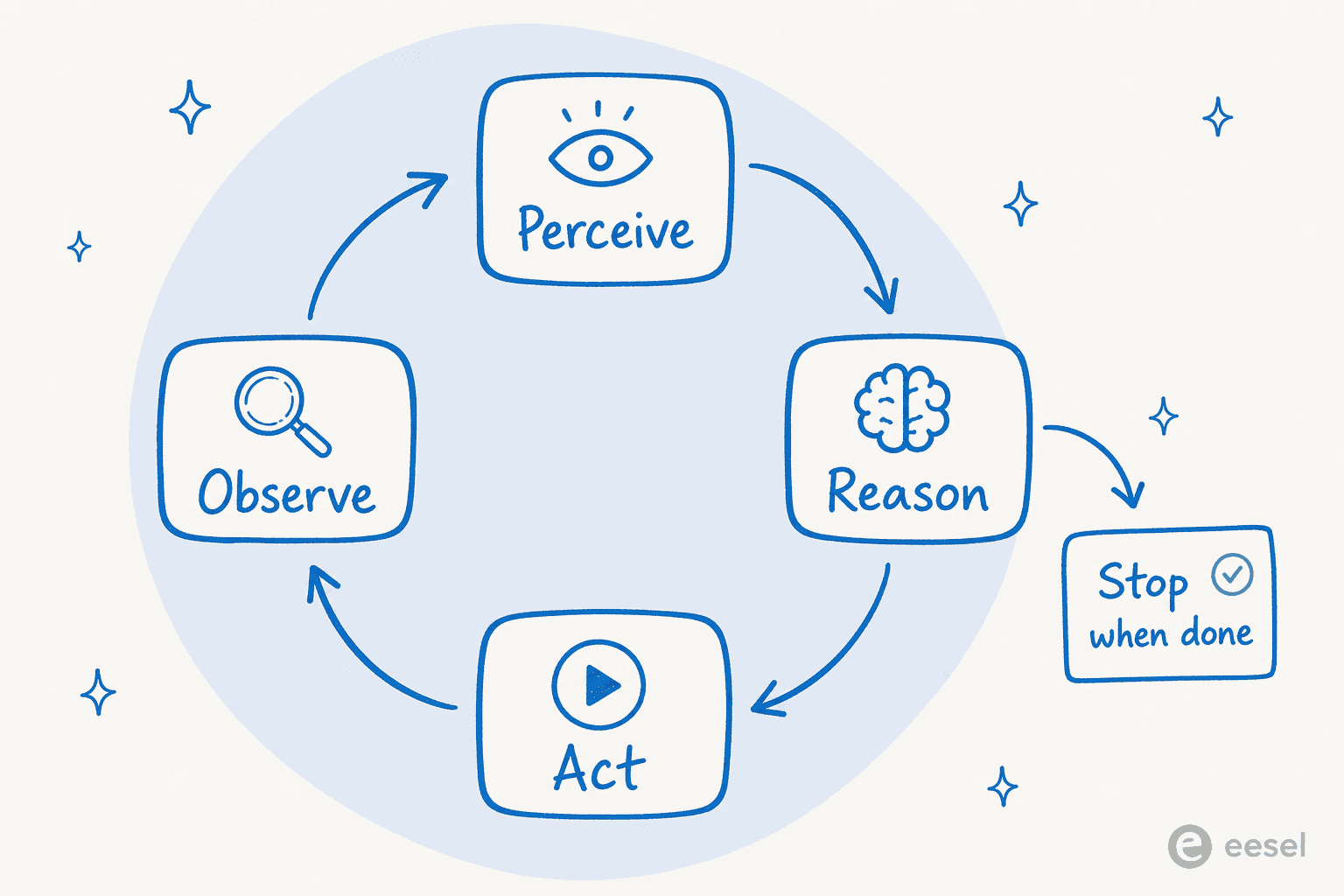
- 知覚。 エージェントは入力を取り込みます。ユーザーのメッセージ、APIの応答、エラー、または自分自身の直前のアクションの結果。
- 推論。 モデルはコンテキスト内のすべてを見て、次に何をすべきかを決めます。より難しい仕事では、ここで計画も立て、行動の前に目標をより小さなステップに分解します。
- 行動。 エージェントは世界に対して何かを行います。ツール呼び出し、APIリクエスト、データベースクエリ、コード実行など。
- 観察。 エージェントは結果を吟味します。機能したか?タスクは完了したか?計画を変える必要があるか?
そして再びループに戻ります。全体はわずか数行の擬似コードに集約され、これが「ただのwhileループだ」という言い回しが定着した理由です。
while not done:
response = call_llm(messages)
if response has tool_calls:
results = execute_tools(response.tool_calls)
messages.append(results)
else:
done = True
return response
主要なラボはいずれも独立してここにたどり着きました。Anthropicはエージェントを「典型的には、環境からのフィードバックに基づいてループの中でツールを使うLLMにすぎない」と説明しています。OpenAIのAgents SDKは、そのランナーを文字どおりのループとして文書化しています。モデルを呼び出し、ツール呼び出しのない最終回答が返ってきたら停止し、そうでなければツールを実行し、結果を追加して再び実行する。便利な一行要約は、元々はLilian Wengによるもので、エージェント = LLM + メモリ + 計画 + ツール使用です。ループは、この4つを結びつけるランタイムです。
具体例で見てみる
具体的にするために、「2026年に発表されたエージェントメモリに関する最も引用された論文を特定し、その主要な発見を要約する」というタスクの、実際の3回反復の実行例をOracleの記事から紹介します。
- 反復1。 推論:検索が必要だ。行動:検索APIを呼び出す。観察:引用数付きで15本の論文が返ってくる。
- 反復2。 推論:340件の引用を持つトップの結果を選ぶ。行動:文書取得ツールを呼び出す。観察:要旨と主要セクションが返される。
- 反復3。 推論:十分に集まった。行動:要約を書く。観察:タスク完了、ループを抜ける。
Oracleの言葉を借りれば、「3回の反復。3回のツール呼び出し。1パスのチャットボットには決して生み出せなかった、1つの完全な答え」。この最後の一節こそが、すべての肝です。
アイデアの出どころ:ReAct
ループは2026年の発明ではありません。その学術的な背骨はReAct論文(Yao et al., 2022)であり、「reasoning and acting(推論と行動)」の略です。その洞察は、推論のトレースをアクションと交互に織り込むことでした。何をすべきかについてのThought(思考)、次にAction(行動)、次にObservation(観察)、さらに次の思考、というように。論文は、推論が「モデルが行動計画を誘導・追跡・更新し、例外を処理するのを助ける一方、行動はモデルが外部ソースとインターフェースすることを可能にする」と論じています。
測定された効果は、漠然としたものではなく現実的でした。最強のベースラインに対して、ALFWorldベンチマークで34%、WebShopで10%の絶対的な成功率の向上です(arXiv:2210.03629)。推論のみのモデルは「外部環境に接地していないため誤情報に苦しみ」、行動のみのモデルは「推論の欠如に苦しむ」。両者をループで組み合わせることで、その両方が解消されます。検索があなたの構想の一部なら、これが素朴な検索拡張生成(RAG)とどう関係するかを理解しておく価値があります。これについてはすぐ後で触れます。
エージェントループ対チャットボット:たった1つのwhileループ
これが重要な比較です。なぜなら、ほとんどの人が実際に抱えてやってくる問いだからです。
| 観点 | 従来型チャットボット / シングルターンRAG | エージェントループ |
|---|---|---|
| リクエストあたりのモデルパス | 1回 | 多数(反復ごとに1回) |
| ステップをまたいだ状態 | ステートレスで孤立 | 持続的なコンテキストを引き継ぐ |
| ツール使用 | なし、または1回の呼び出し | 繰り返し・連鎖したツール呼び出し |
| 失敗からの回復 | なし | エラーを観察し、再計画する |
| 複数ステップのタスク | 分解できない | 分解して連鎖させる |
| 実際のアクションの実行 | 読み取りと回答のみ | 行動する(返金、予約、書き込み) |
| 制御フローの決定者 | ハードコードされた経路 | モデルが、実行時に決定 |
| 終了するのは | 1つの応答が生成されたとき | タスク完了または停止条件 |
決定的な詳細、そして人々が見落とすのは、これがモデルの能力の差ではないという点です。同じ基盤となるモデル(Claude、GPT、Gemini)が両方を動かしています。Oracleは、ChatGPT、Claude、Geminiが「いずれも複数ステップの問題を推論し抜く能力を持つ。制限はアーキテクチャ上のものだ」と明言しています。素朴なチャットボットのやり取りはステートレスです。各プロンプトは孤立して処理され、中間結果の記憶もなく、判断を連鎖させる手段もありません。ループは、その天井を取り払うものです。
シングルターンRAGは特に名指しておく価値があります。中間に位置し、人々を混乱させるからです。RAGチャットボットは確かに回答前に外部知識を取得するため、エージェントのように感じられます。しかし、やはり1回だけ実行されます。取得して、答える。最初の検索で分かったことに基づいて2回目の検索が必要だと判断することはできず、副作用を伴うアクションも実行できず、最初の検索が外れても回復できません。エージェントループは、その1回の取得を、繰り返し他と連鎖できる単一のアクションに変えます。なぜAIチャットボットが正しく答え続けないのかと疑問に思ったことがあるなら、このループの不在が原因であることが多いのです。1回のチャンスしかなく、自分を確認する機会がないのです。
もう1つ心に留めておくべき捉え方があります。「エージェンティック」はイエスかノーではなく、スペクトルだということです。LangChainのHarrison Chaseは、システムは「LLMがシステムの振る舞いをどう決めるかが多いほど、よりエージェンティックである」と論じ、単純なルーターから、完了までループするステートマシン、そして自分自身のツールを構築・再利用する完全自律エージェントまでの範囲を挙げています。最も有用なサポート自動化は、その範囲の極端な端ではなく真ん中に位置します。
ループには派生形がある
基本的なReActループはほとんどのケースに対応しますが、名前で知っておくに値するほど頻繁に登場する拡張がいくつかあります。Andrew Ngは中核的なアイデアを4つのエージェンティック・デザインパターンにまとめました。リフレクション、ツール使用、計画、マルチエージェント協調です。ループの言葉で言うと:
- Plan-and-execute(計画と実行)。 計画を実行から分離します。プランナーがタスクの完全な分解を前もって書き、エグゼキューターがそれをこなし、リプランナーが現実が乖離したときに調整します。これは各ステップで推論する場合に比べてモデル呼び出しを削減します。LangChainのLLMCompilerは、逐次的なReActスタイルの実行に対して3.6倍の高速化を報告しました。
- リフレクション。 1つのモデル呼び出しが結果を生成し、別の呼び出しがそれを批評してフィードバックを返し、出力が基準を満たすまでループします。Ngはこれを「自分自身の仕事を批評し、修正する」LLMと表現しています。
- マルチエージェント。 リードエージェントがサブエージェントを生成し、スレッドを並列で処理させます。Anthropicは、そのマルチエージェント・リサーチシステムが「社内のリサーチ評価でシングルエージェント構成を90.2%上回った」と報告しました。
すべての情報源に共通する助言、そして最も無視されがちな部分は次のとおりです。機能する最もシンプルなループから始め、それが実際に役立ったと測定できる場合にのみ、複雑さを追加すること。
ガードレール:なぜループにブレーキが必要なのか
自分で実行できるループは、暴走できるループでもあります。停止条件は任意ではありません。それがなければ、エージェントは無限に回り続け、「トークンを燃やし、ますます支離滅裂な結果を生み出す」可能性があります。
標準的なブレーキは次のとおりです。
- 最大反復回数。 ループのターン数に対する厳格な上限です。OpenAIは設定された上限を超えると
MaxTurnsExceeded例外を発生させ、Anthropicは「制御を維持するために」最大反復回数を推奨しています。 - トークンとコストの予算。 ループは安くありません。Oracleによれば、エージェントは標準的なチャット呼び出しの約4倍のトークンを消費し、マルチエージェント構成では最大15倍に達します。このコストこそ、本番チームがあらゆるステップを計測する主な理由です。
- 進捗なし検出。 繰り返しの反復が新しいものを何も生み出さなくなったら終了します。
- 人間が介在するチェックポイント。 エージェントは障害に直面したとき人間のために一時停止でき、これはサポートで非常に重要です。
Oracleはここで素晴らしい教訓的な逸話を語っています。スクレイピングエージェントの対象サイトが密かに構造を変えたために空の結果を返し始め、「データが取れるまで再試行せよ」というプロンプトと厳格な停止がない状態で、レート制限が救うまでに「壊れたツールを5分間で400回呼び出した」のです。修正策はほとんど侮辱的なほど単純でした。「最大反復回数を3サイクルに制限していれば、この失敗は完全に防げただろう」。この記事全体から運用上の教訓を1つだけ持ち帰るなら、それにしてください。
ループをサポートチケットにどう対応させるか
ここで抽象的なパターンが製品になります。Anthropicはカスタマーサポートを「より自由度の高いエージェントに自然に適した領域」として挙げています。なぜなら、その仕事には会話とアクションの両方が必要だからです。サポートチケットは教科書どおりのループです。
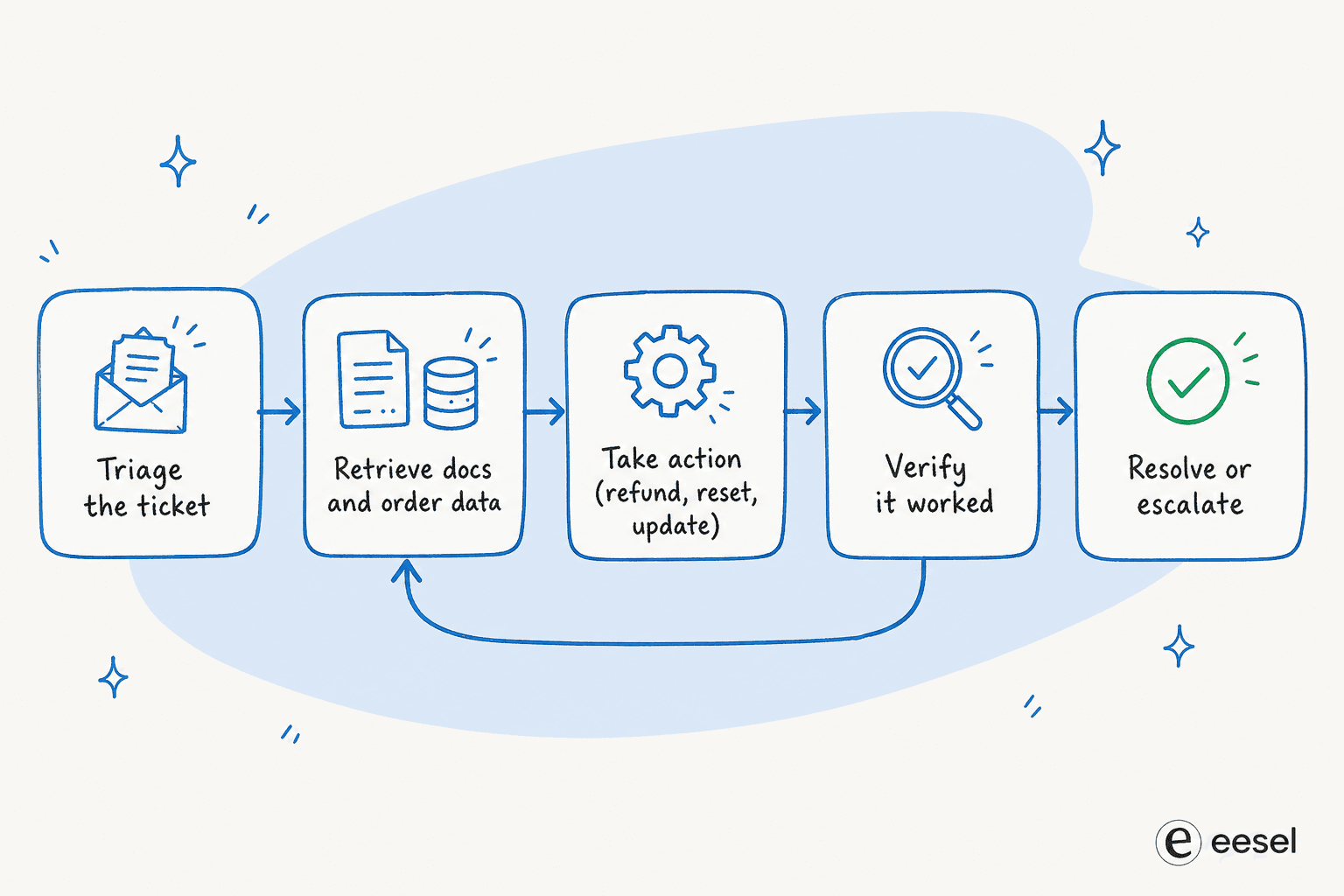
- トリアージ。 ループは入ってきたチケットを知覚し、モデルが意図を推論します。請求、返金、パスワードリセット、技術的なバグ。これは古典的なチケットのトリアージステップです。
- 取得。 データツールを呼び出します。ナレッジベース検索、注文履歴、アカウント照会など。
- 行動。 実際の副作用を伴うアクションツールを呼び出します。返金の発行、サブスクリプションの変更、配送先住所の更新、パスワードのリセット、チケットの更新。
- 観察と検証。 アクションが実際に機能したか確認します。照会が空で返ってきたり、APIがエラーになったりしたら、ループは再計画します。これは1パスのボットには到底できない回復です。
- 解決またはエスカレーション。 完了していれば、クローズします。エージェントが信頼度の限界に達したら、人間にクリーンに引き継ぎます。
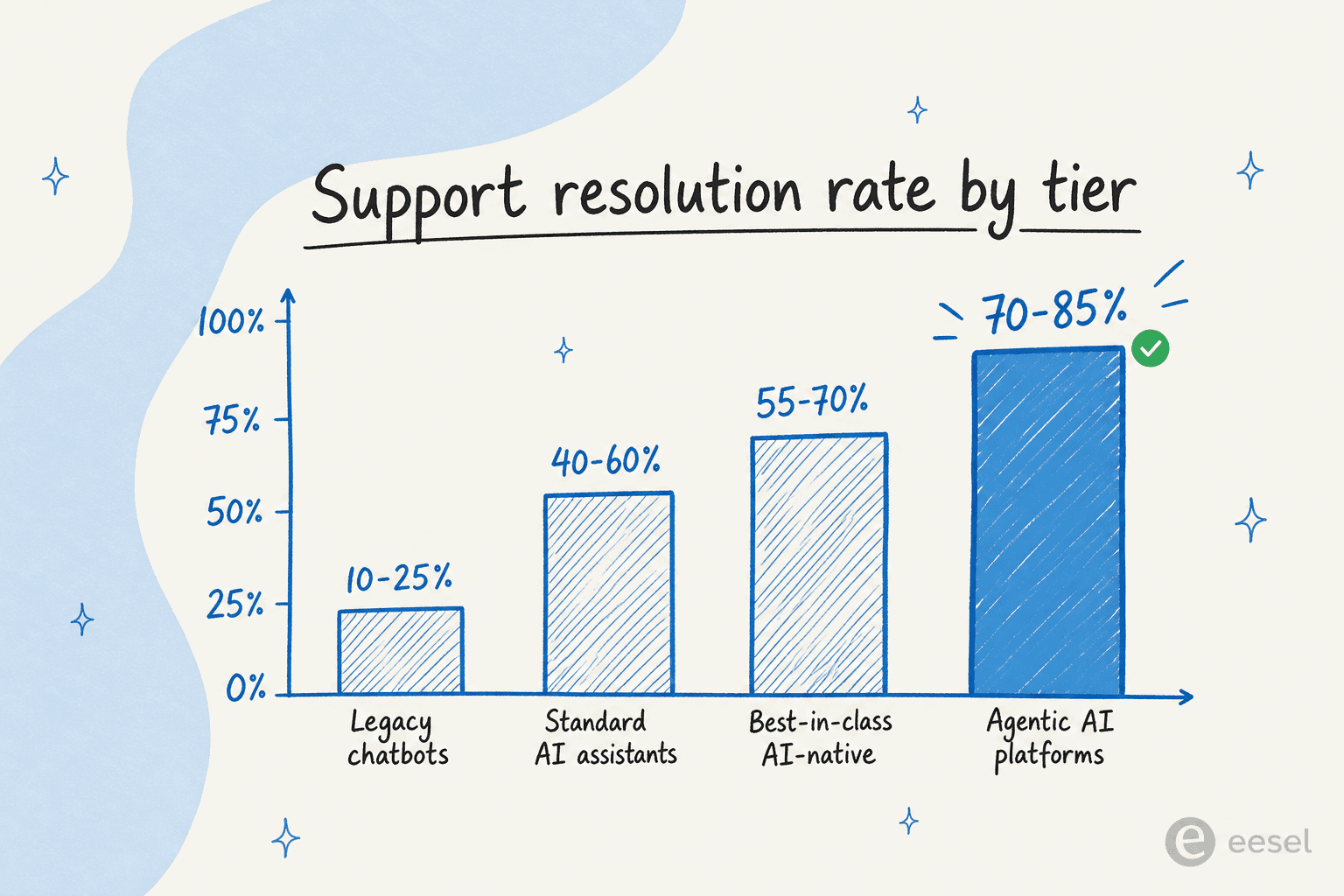
これは、エージェントループが古いボットよりもはるかに多く解決する理由でもあります。Notchの2026年ベンチマークレポートによれば、レガシーチャットボットは問題の10〜25%しか解決しません(解決ではなくルーティングのために作られていた)。一方、「CRM、請求、保険金請求システムに直接接続して実行する」エージェンティックなプラットフォームは、70〜85%のエンドツーエンド解決に到達します。
同じレポートからの、どんなベンダーとの会話にも持ち込むべき警告が1つあります。解決は、デフレクションやコンテインメントとは同じではないということです。デフレクションは単に、AIが応答を生成して顧客が立ち去ったことを意味するだけで、根本的な問題は依然として未解決かもしれません。コンテインメント(エスカレーションなし)は、Notchの言葉を借りれば「おそらく最も誤解を招く」ものです。ベンダーに尋ねるべき正直な問いは、「解決率がいくつか、ではなく、何を解決済みとみなすか」です。これは、実際のアクションを伴う本物のループだからこそ実際に裏付けられる種類のニュアンスであり、デフレクション専用のボットにはできません。ツールを選んでいるなら、チケット自動化に最適なAIと最高のカスタマーサービスAIのまとめ記事で、どのプラットフォームが本当に解決し、どれがデフレクトするだけかを掘り下げています。
実際のヘルプデスク内でライブで動き、提案するだけでなくチケットに対してアクションを実行するエージェントループは、こんな様子です。
信頼度ベースの引き継ぎが、ループのクリーンな出口
サポートチームから最も多く聞く要望は、「AIにすべてに答えさせろ」ではありません。その逆です。AIには自信のあるものだけを処理させ、残りはそのままにしておけ、というものです。月に約7,000件のチケットを扱うD2CサプリメントブランドのあるCXリーダーは、これを完璧に言い表しました。
「AIが質問の100%に答えられるようになることは決してありません……私が必要なのは、自信を持って処理できるチケットだけを扱い、それ以外はそのままにしておくAIです。」
これがサポートに適用された停止条件です。信頼度しきい値がループを解決させるか引き継ぐかを決め、人間へのクリーンな引き継ぎが残りを処理します。これはまた、見出しの解決数以上に、エスカレーション率と48〜72時間の再問い合わせ率が注視に値する指標である理由でもあります。それらは、ループが実際に問題を解決しているのか、それとも単にチケットをクローズしているだけなのかを教えてくれます。
実務家がループについて実際に言っていること
開発者コミュニティはエージェントループについて、強くて面白く、少し矛盾した意見を持っています。それこそが、このアイデアが本物であることの最良の証拠です。
そのシンプルさについて、広く共有されたこの見解が代表的です。
「ツールを呼び出せるLLMを備えたループが、今やあらゆる種類のタスクでこれほどうまく機能するのは、本当に驚くべきことだ。」
ループを制約なしに走らせることの危険について、Docker創業者のSolomon Hykesには、誰もが引用する一節があります。
「AIエージェントとは、ループの中で自分の環境を破壊しているLLMだ。」
両方が同時に真実であり、その緊張こそが実際のエンジニアリング上の問題です。ループは驚くほど有能で、本当にリスキーです。だからこそ、上のガードレールのセクションは任意のお決まり文句ではありません。Simon Willisonは、「エージェンティックループの設計」がそれ自体1つの専門分野になりつつあるとさえ論じています。その妙技は、彼いわく、「彼ら(モデル)が使うためのツールとループを注意深く設計することにある」のです。
自分で作るか、買うか?
ループは説明するのがあまりにシンプルなので、多くの技術チームは明白な結論にたどり着きます。ClaudeやOpenAIのAPIで自分たちのものを作ればいい、と。そして正直なところ、動くプロトタイプは1日の午後で立ち上げられます。whileループは簡単な20%です。
難しい80%は、その周りのすべてです。持続的なメモリ、あらゆるツール呼び出しにわたる可観測性、暴走ループを止めるガードレール、ヘルプデスクとナレッジベースの統合、そしてモデルとAPIが足元で変わっていくなかでの継続的なメンテナンス。それこそチームが過小評価する部分です。私たちは、技術的に優れた多くの顧客がデモを作り、それを長期的に抱え込まずに済むよう購入を選ぶのを見てきました。ビットコインATMのハードウェア企業のあるエンジニアリングリーダーは、作るより買うを選び、私たちにこう語りました。
「自分たちで独自のLLMアプリケーションを書こうとすることもできたが、そこに時間を投資したくなかった。メンテナンスしなくて済むものが欲しかったのです。」
チームの強みがエージェントランタイムの維持ではなく自社製品にあるなら、その計算はたいてい購入に味方します。私たちはこのトレードオフを、カスタマーサービス向けカスタムGPTの構築に関する記事でより詳しく掘り下げています。また、成熟したループが実際の現場でどう見えるかは、すでにカスタマーサービスにAIを使っている企業で確認できます。
eeselを試す
eeselは、サポート、IT、オペレーションのチームのために製品化された、構築不要のエージェントループです。そのAIヘルプデスクエージェントは、知覚・推論・行動・観察の完全なサイクルを、あなたがすでに使っているヘルプデスク(Zendesk、Freshdesk、HubSpot、Gorgias、Front、Slack、そして100以上の統合)の中で直接実行します。だから単に回答を下書きするだけでなく、チケットに対してアクションを実行し、それらを解決します。

上記すべてに直接対応する差別化要因が、そのシミュレーションモードです。エージェントを過去の数千件のチケットに対して実行し、ライブの返信が1つも出る前に、テーマごとに何を解決していたはずかを正確に確認できます。これがガードレール優先・信頼度ベースのループ版であり、サポートチームが実際に求めるものです。初日からあなたの解決済みチケットとヘルプドキュメントから学習し、80以上の言語で動作し、席数ではなく解決ごとに課金します。クレジットカード不要、50ドルの無料利用枠付きでeeselを試すことができ、コミットする前に自分自身の解決数を確認できます。
よくある質問
AIエージェントループを簡単に言うと何ですか?
AIエージェントとチャットボットの違いは何ですか?
AIエージェントループはカスタマーサポートにどう当てはまりますか?
AIエージェントループは永遠に実行され続ける可能性はありますか、またそれはどう防ぎますか?
自分でAIエージェントループを構築すべきか、それとも購入すべきか?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.




