¿Qué es DiffusionGemma?
DiffusionGemma es un modelo de la familia abierta Gemma de Google que genera texto con un proceso de difusión en lugar del enfoque autorregresivo detrás de casi todos los chatbots que has usado. Fue publicado por Google DeepMind el 10 de junio de 2026 como un modelo experimental de pesos abiertos bajo Apache 2.0, con la tarjeta del modelo oficial alojada en el sitio de DeepMind.
Aquí está la ficha técnica principal:
| Atributo | DiffusionGemma |
|---|---|
| Lanzado | 10 de junio de 2026 |
| Licencia | Apache 2.0 (pesos abiertos) |
| Arquitectura | Construido sobre Gemma 4, Mixture-of-Experts |
| Tamaño | 25,2B de parámetros totales, ~3,8B activos por paso ("26B A4B") |
| Generación | Elimina ruido de bloques de 256 tokens en paralelo |
| Entrada / salida | Multimodal de entrada (texto/imagen/video), texto de salida |
| Velocidad | >1.000 tok/s en una H100, hasta 4 veces más rápido que modelos AR comparables |
| Hardware | ~52 GB de VRAM con BF16, ~28 GB con INT8, ejecutable desde ~18 GB cuantizado |
La mayoría de esas cifras provienen de la cobertura del lanzamiento de MarkTechPost y la guía de despliegue de Spheron, con el detalle del bloque en paralelo del artículo de Digg. La etiqueta "26B A4B" es la abreviatura de Google: un modelo Mixture-of-Experts de clase 26B que solo activa unos 3,8B de parámetros en cualquier paso dado, lo cual es parte de por qué es barato ejecutarlo rápido.
La razón por la que esto es importante no son las puntuaciones de los benchmarks. Es que un laboratorio de frontera lanzó un modelo de lenguaje de difusión real y descargable. Durante años, la difusión fue el método dominante para imágenes y video (piensa en Midjourney, Sora) mientras el texto se mantuvo obstinadamente autorregresivo, la misma familia que impulsa asistentes cotidianos como ChatGPT y Claude. DiffusionGemma es una de las señales más claras hasta ahora de que el lado del texto está poniéndose al día.
Cómo funciona realmente DiffusionGemma
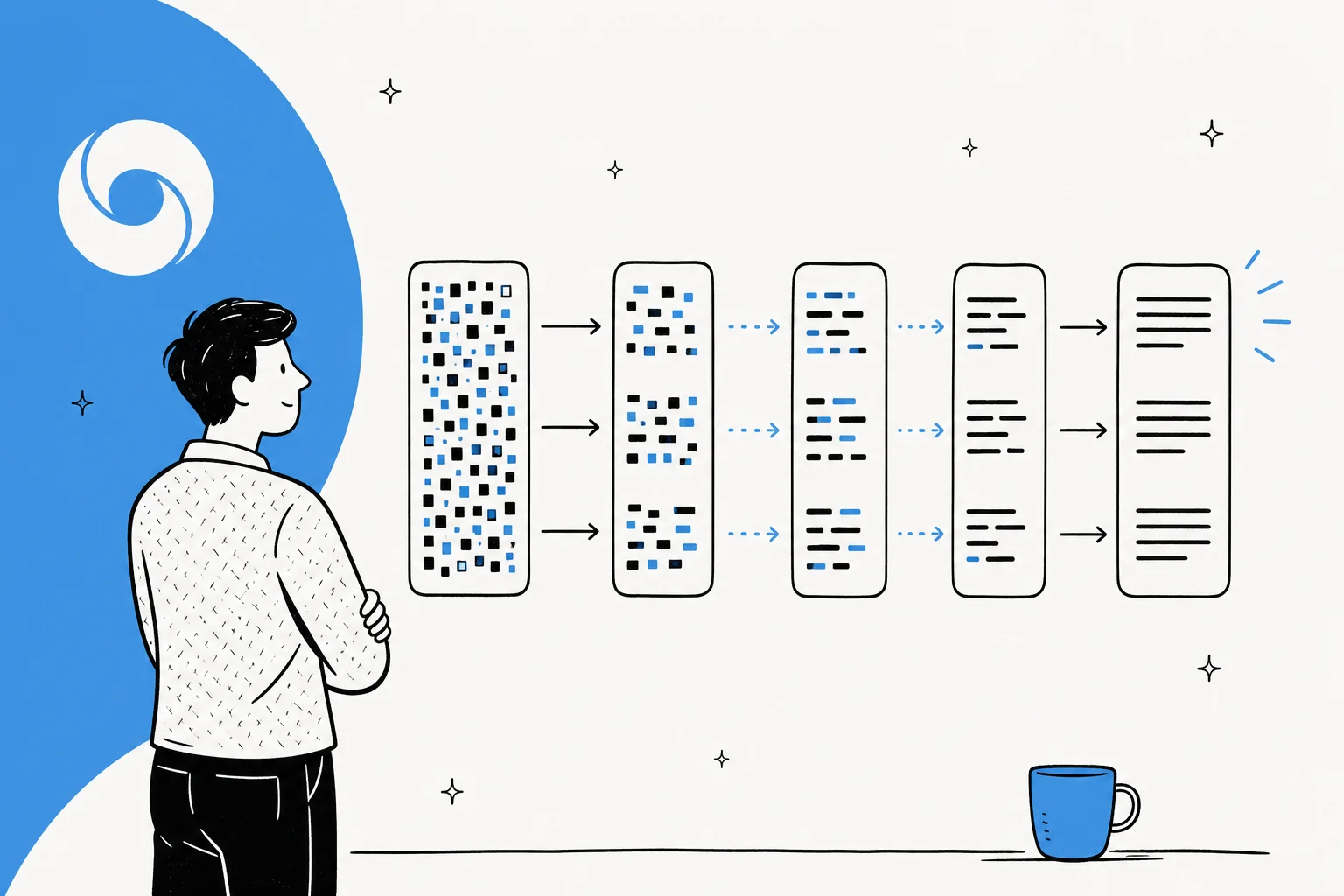
Los grandes modelos de lenguaje estándar son autorregresivos. Como lo expresa Inception Labs, "generan texto de izquierda a derecha, un token a la vez, donde un token no puede generarse hasta que todo el texto anterior se haya generado." Cada palabra espera a la anterior, así que una respuesta larga significa una larga secuencia de pasadas hacia adelante a través de miles de millones de parámetros. De ahí viene la latencia.
La difusión le da la vuelta a esto. El enfoque dominante para el texto es la difusión enmascarada: comienzas con un bloque de tokens que están todos enmascarados, y un transformer predice las versiones sin máscara, luego refina su conjetura a lo largo de un puñado de pasadas. Google lo describe como generar texto "de la forma en que funciona la difusión de imágenes: en lugar de predecir el texto directamente, el modelo aprende a generar salidas refinando ruido paso a paso, de modo que puede iterar sobre una solución rápidamente y corregir errores durante la generación."
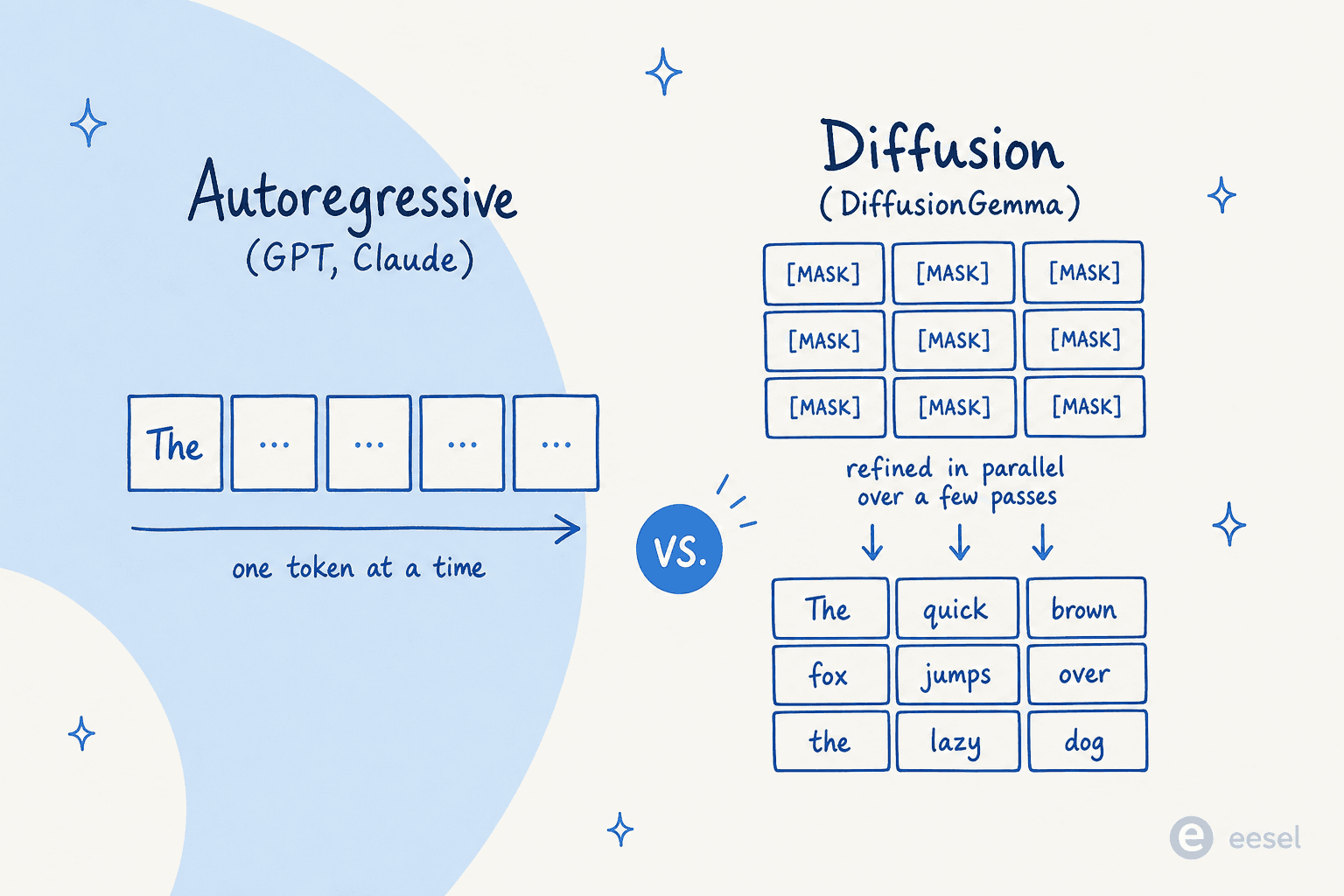
Una aclaración, porque el nombre confunde a la gente. La difusión aquí no reemplaza al transformer; reemplaza a la autorregresión. Como lo explicó un comentario muy citado de Hacker News del usuario synapsomorphy:
"La difusión no está en lugar de los transformers, está en lugar de la autorregresión. Los LLM de difusión anteriores como Mercury todavía usan un transformer, pero no hay enmascaramiento causal, así que toda la entrada se procesa de una vez y la generación de la salida es obviamente diferente."
Las ventajas prácticas de generar en paralelo son tres: velocidad pura, la capacidad de corregir errores a mitad de la generación y relleno natural (porque el modelo puede ver contexto a ambos lados de un hueco, es bueno editando el medio de una secuencia, no solo añadiendo al final). Andrej Karpathy señaló la novedad temprano, notando que la difusión "no va de izquierda a derecha, sino todo a la vez. Comienzas con ruido y gradualmente lo eliminas hasta convertirlo en un flujo de tokens."
DiffusionGemma vs Gemini Diffusion: no los confundas
Este atrapa a casi todos, porque Google lanzó dos cosas de difusión de texto en aproximadamente un año y les dio nombres casi idénticos.
Gemini Diffusion se mostró en Google I/O en mayo de 2025 como un modelo experimental, solo accesible por lista de espera, que funciona en la infraestructura de Google. No puedes descargarlo. DiffusionGemma, en cambio, es el de pesos abiertos que puedes descargar y ejecutar tú mismo.
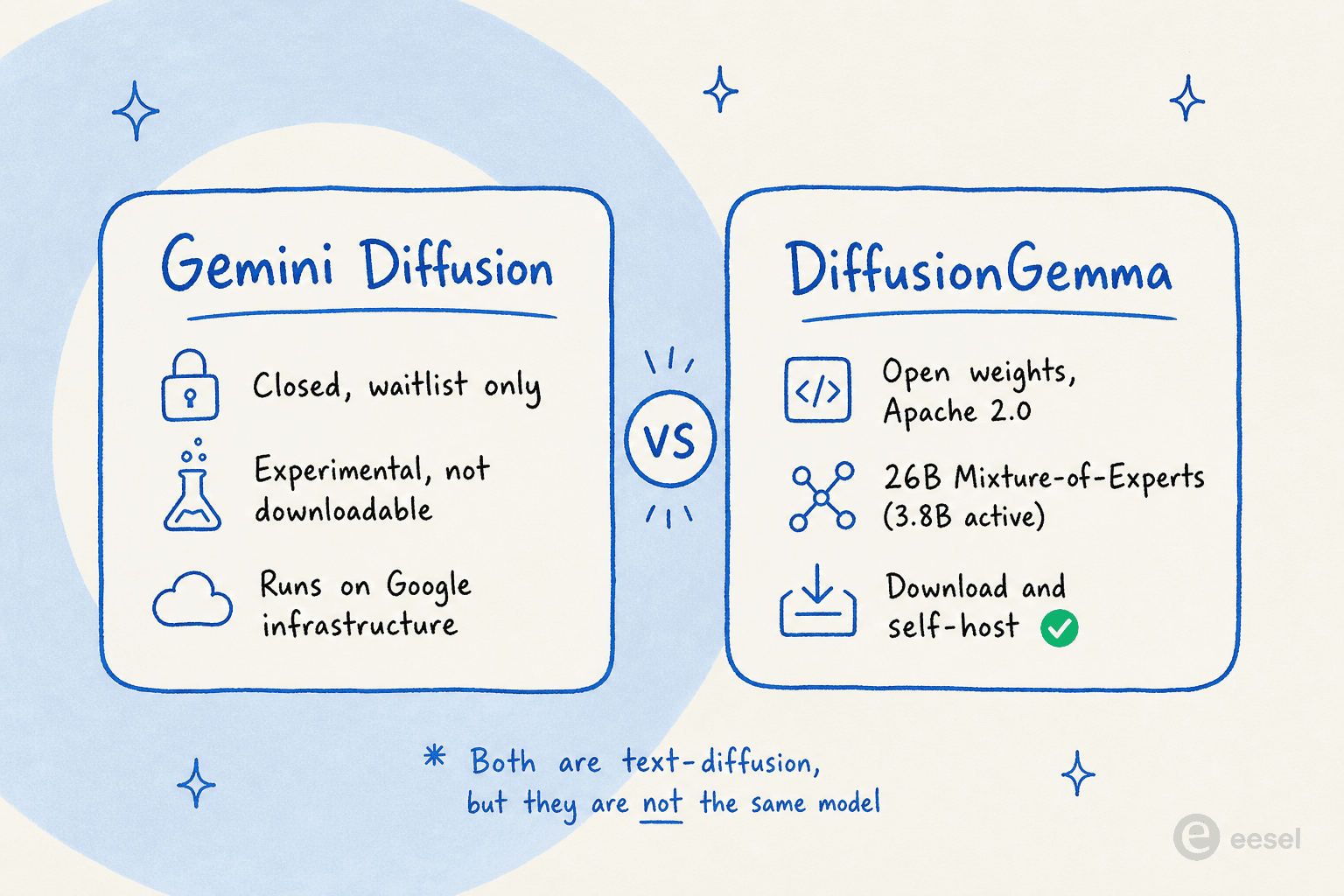
El hecho de que Google haya lanzado tanto un modelo cerrado experimental como un lanzamiento de pesos abiertos es en sí mismo la historia: es la señal más fuerte de que los modelos de lenguaje de difusión han superado la etapa de curiosidad de investigación. Cuando un laboratorio de frontera libera una arquitectura como código abierto, está apostando a que otras personas construirán sobre ella.
Las cifras de velocidad (y por qué son más o menos reales)
La velocidad es todo el argumento, así que veamos las cifras honestamente. Los >1.000 tok/s de DiffusionGemma se sitúan junto a sus primos de difusión, y la brecha con los modelos autorregresivos es grande:
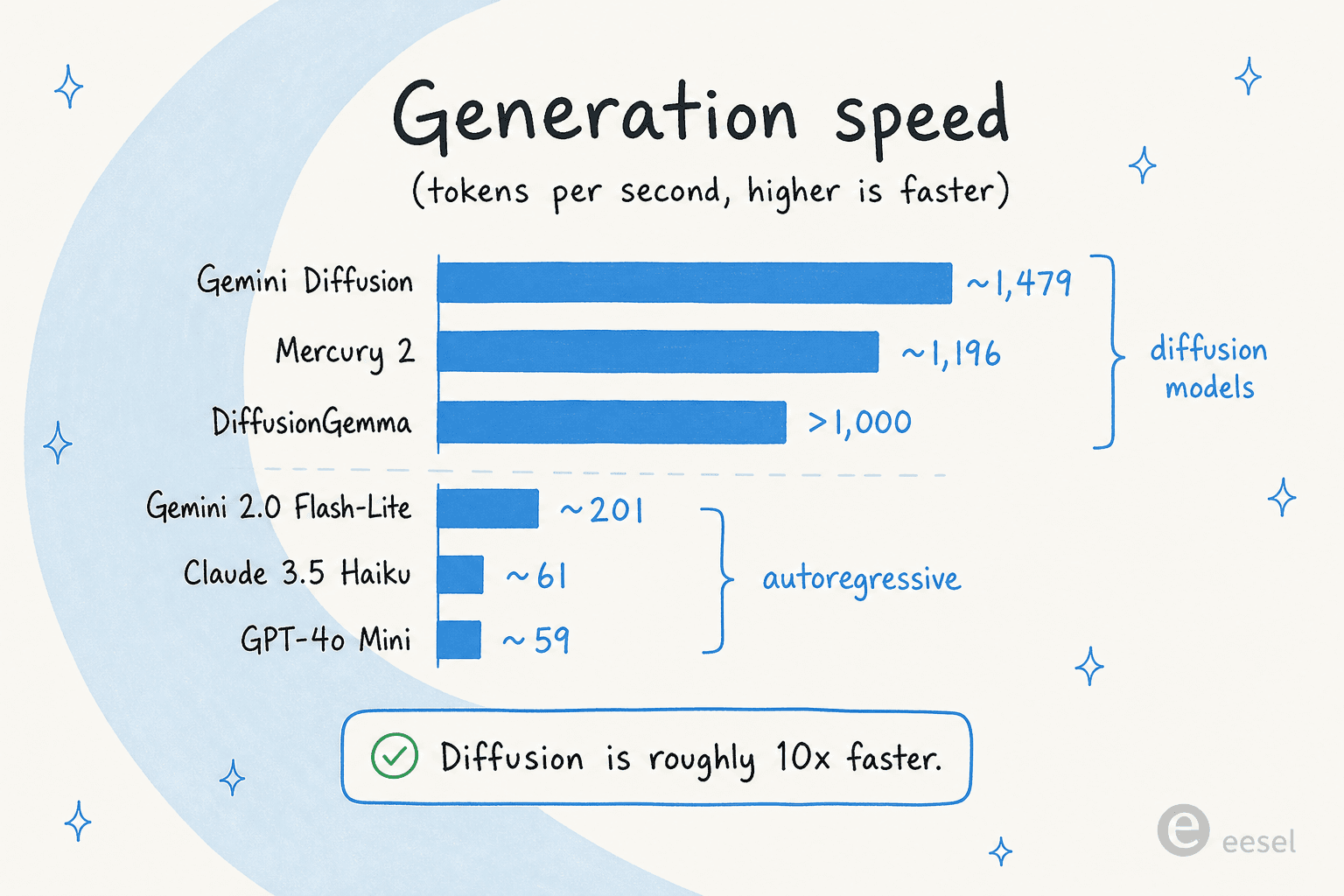
Unas pocas salvedades mantienen esto con los pies en la tierra. Casi todas las cifras se miden en una NVIDIA H100, y la mayoría son afirmaciones de los proveedores. El único punto de referencia independiente en este espacio, Artificial Analysis, ha corroborado la velocidad de los modelos Mercury de Inception pero aún no su calidad. Para DiffusionGemma específicamente, las cifras de >1.000 tok/s y hasta 4 veces provienen de Google y de artículos de socios como Yellow.com, todavía no de benchmarks de terceros.
Para comparar, los modelos autorregresivos que la gente realmente usa en producción se sitúan mucho más abajo en rendimiento: según los propios benchmarks de Inception, GPT-4o Mini funciona en torno a 59 tok/s y Claude 3.5 Haiku en torno a 61, con el Gemini 2.0 Flash-Lite optimizado para velocidad en unos 201. Así que el marco de "aproximadamente 10 veces más rápido" para la difusión se sostiene, al menos sobre el papel.
Dónde brilla y dónde no
La lectura honesta es que la difusión realmente es más rápida en trabajo limitado por rendimiento y paralelizable, pero la autorregresión todavía gana para mucho de lo que las aplicaciones de producción realmente necesitan. La mejor fuente única aquí es el desglose del ingeniero Sean Goedecke sobre las limitaciones de la difusión, y se mapea limpiamente sobre una decisión.
Recurre a la difusión cuando el trabajo sea de alto volumen y paralelizable: resumen masivo, clasificación, reformateo, traducción o bucles de agente de baja latencia donde una respuesta rápida por paso se acumula. La generación de código es un caso particularmente bueno porque la naturaleza de relleno de la difusión coincide con cómo editas código, generando el inicio y el final de un bloque en la misma pasada.
Quédate con la autorregresión cuando necesites salidas cortas (la difusión ejecuta todas sus pasadas de eliminación de ruido independientemente, así que hace trabajo extra para producir una respuesta de seis tokens), ventanas de contexto largas (la difusión no puede reutilizar la caché clave-valor tan fácilmente, así que recalcula la atención sobre todo el contexto en cada pasada) o razonamiento en cadena de pensamiento difícil. Sobre ese último punto, Goedecke hace el argumento más afilado:
"Una razón para ser ampliamente escéptico sobre el potencial de los modelos de difusión para razonar es precisamente que hacen mucho menos trabajo por token que los modelos autorregresivos. Eso es simplemente menos espacio para que el modelo dedique a 'pensar'."
Sean Goedecke, "Strengths and limitations of diffusion language models"
El propio DiffusionGemma confirma el compromiso: se mantiene por debajo del Gemma 4 estándar en cada benchmark publicado. Un ingeniero que escribió sobre stacks de agentes de producción expresó memorablemente la crítica histórica a la difusión, que los primeros modelos "eran rápidos de la forma en que un reloj roto es rápido, no importa qué tan rápido obtengas la respuesta equivocada" (dev.to). La brecha de calidad se está cerrando a escala pequeña y media, pero todavía es visible en la frontera.
El movimiento pragmático en el que aterrizarán la mayoría de los equipos no es el reemplazo, es el enrutamiento: envía pasos simples y de alta frecuencia (búsquedas, formateo, clasificación) a un modelo de difusión rápido y reserva un modelo autorregresivo de frontera para razonamiento profundo. Es la misma lógica detrás de elegir la herramienta adecuada para una tarea en lugar de que un helpdesk con IA lo haga todo.
Qué significa DiffusionGemma para los equipos de atención al cliente
La difusión suena perfecta para el soporte. El chat en vivo y los agentes de soporte con IA son exactamente el caso de baja latencia y orientado al usuario donde la diferencia entre una respuesta de un segundo y una de varios segundos decide si la herramienta se siente en tiempo real o como "un servicio en el que esperas." Para copilotos orientados al cliente, una respuesta por debajo del segundo realmente puede ser la diferencia entre la adopción y el abandono.
Pero aquí está lo que rebatiríamos: para un equipo de soporte, la arquitectura del modelo importa mucho menos que la orquestación a su alrededor. Dos salvedades aterrizan directamente sobre este caso de uso.
Primero, las respuestas de soporte reales se apoyan en contexto largo y recuperación, y el contexto largo es precisamente el punto débil de la difusión. Una buena respuesta no es una generación desde cero; es una respuesta fundamentada sobre tu base de conocimiento, historial de tickets y documentos de políticas. La recuperación y la fundamentación importan más para la calidad de la respuesta que si los tokens finales salieron de izquierda a derecha o en paralelo, que es el corazón de la cuestión RAG vs LLM.
Segundo, la calidad y la fiabilidad superan a la velocidad pura para cualquier cosa orientada al cliente. Un modelo más rápido conectado a conocimiento obsoleto o a reglas de escalado débiles simplemente produce respuestas equivocadas más rápido. Ese es el problema del reloj roto, aplicado al soporte.

Así que si eres un líder de soporte leyendo sobre DiffusionGemma y preguntándote si lo necesitas: probablemente no directamente. Lo que quieres es una plataforma que acierte con la fundamentación, las barreras y las integraciones de helpdesk, y que luego se beneficie discretamente de cualquier modelo que sea el más rápido y mejor bajo el capó. La latencia es una palanca entre muchas, y rara vez es la que está frenando tu tasa de resolución. La cuestión más grande suele ser el coste por ticket frente a un humano que lo gestiona.
Prueba eesel
eesel AI vende compañeros de equipo con IA que viven dentro de tu helpdesk existente (Zendesk, Freshdesk, HubSpot, Gorgias, Front) y gestionan el soporte de nivel 1 aprendiendo de tus tickets pasados y documentos de ayuda desde el primer día. La razón por la que es relevante aquí: eesel es deliberadamente agnóstico respecto al modelo, así que el debate de arquitectura de arriba es uno que no tienes que ganar. Lo que acierta es la orquestación que de verdad mueve las cifras, como el enrutamiento basado en confianza que redacta en lugar de enviar cuando no está seguro, y un modo de simulación que se ejecuta contra tus tickets pasados para que puedas ver la cobertura antes de salir en vivo. Gridwise vio el 73 % de las solicitudes de nivel 1 resueltas en el primer mes, y los precios son basados en el uso desde 0,40 $ por ticket resuelto sin tarifas por puesto, así que pagas por resultados en lugar de por horas de GPU.
Preguntas frecuentes
¿Qué es DiffusionGemma en términos simples?
¿Es DiffusionGemma lo mismo que Gemini Diffusion?
¿Qué tan rápido es DiffusionGemma comparado con un LLM normal?
¿Puedo usar DiffusionGemma para atención al cliente?
¿Cuánto cuesta ejecutar DiffusionGemma?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








