
Que es un modelo de IA basado en difusion?
Un modelo de difusion es un modelo generativo que aprende a construir datos invirtiendo un proceso gradual de adicion de ruido. La idea proviene de la fisica: defines una cadena de pasos que anaden lentamente ruido aleatorio a datos reales, luego entrenas una red para invertir ese proceso y reconstruir muestras a partir del ruido. El trabajo fundacional es el de Sohl-Dickstein et al. (2015) y el articulo de 2020 sobre modelos probabilisticos de difusion con eliminacion de ruido.
Hay dos mitades. En el proceso directo, tomas una imagen real y le anades un poco de ruido gaussiano una y otra vez hasta que se convierte en estatica pura. Esa parte no necesita aprendizaje; su unica funcion es fabricar pares de entrenamiento. En el proceso inverso, una red neuronal aprende a deshacer un paso de ruido a la vez. En el momento de la generacion partes de ruido aleatorio y ejecutas la red repetidamente, cada pasada elimina un poco mas hasta que emerge un resultado coherente.
Aqui esta la intuicion que lo hace encajar. Imagina filmar una escultura de hielo derritiendose hasta convertirse en un charco y luego reproducir la pelicula al reves: partiendo de un charco sin forma y, fotograma a fotograma, volviendolo a congelar hasta formar la escultura. Como el modelo trabaja sobre todo el lienzo en cada paso, puede seguir corrigiendo errores anteriores sobre la marcha.
Esta es la tecnica que impulsa la mayor parte de la generacion moderna de imagen, video y audio. La difusion esta detras de Sora, Midjourney y Riffusion, junto con DALL-E 2, Imagen y Stable Diffusion. El hilo conductor: todos parten de ruido y lo eliminan de forma iterativa hacia un resultado, guiados por tu prompt.
Como generan texto los LLM autorregresivos
Para ver por que la difusion es importante para el texto, necesitas el contraste. Casi todos los modelos de lenguaje grande que has usado, incluidos ChatGPT, Claude, Gemini y Llama, son modelos autorregresivos. Generan texto de izquierda a derecha, un token a la vez, y un token no puede producirse hasta que exista todo lo anterior.
De ese diseno se derivan dos consecuencias, y ambas importan para la comparacion:
- La latencia es secuencial. Producir cada token requiere una pasada completa hacia adelante a traves de miles de millones de parametros, asi que las salidas largas (piensa en largas trazas de razonamiento) inflan directamente cuanto esperas y cuanto pagas.
- No hay vuelta atras. Una vez que un token sale, queda fijo. El modelo no puede revisar una palabra anterior a la luz de una posterior. Este habito unidireccional se culpa de rarezas como la maldicion de la inversion, donde un modelo sabe que "A es B" pero tropieza con "B es A".
La ventaja es que la salida de longitud variable es facil: el modelo simplemente emite un token de fin de secuencia cuando ha terminado. Esa flexibilidad es una de las razones por las que la autorregresion ha seguido siendo dominante para el texto.
Como generan texto de forma diferente los modelos de lenguaje de difusion
Los modelos de lenguaje de difusion (dLLM) trasladan la receta de la imagen al texto. En lugar de pixeles a partir del ruido, hacen tokens a partir de mascaras. Google DeepMind lo describe claramente: en lugar de predecir el texto directamente, el modelo aprende a generar resultados refinando el ruido paso a paso, de modo que puede iterar sobre una solucion rapidamente y corregir errores durante la generacion.
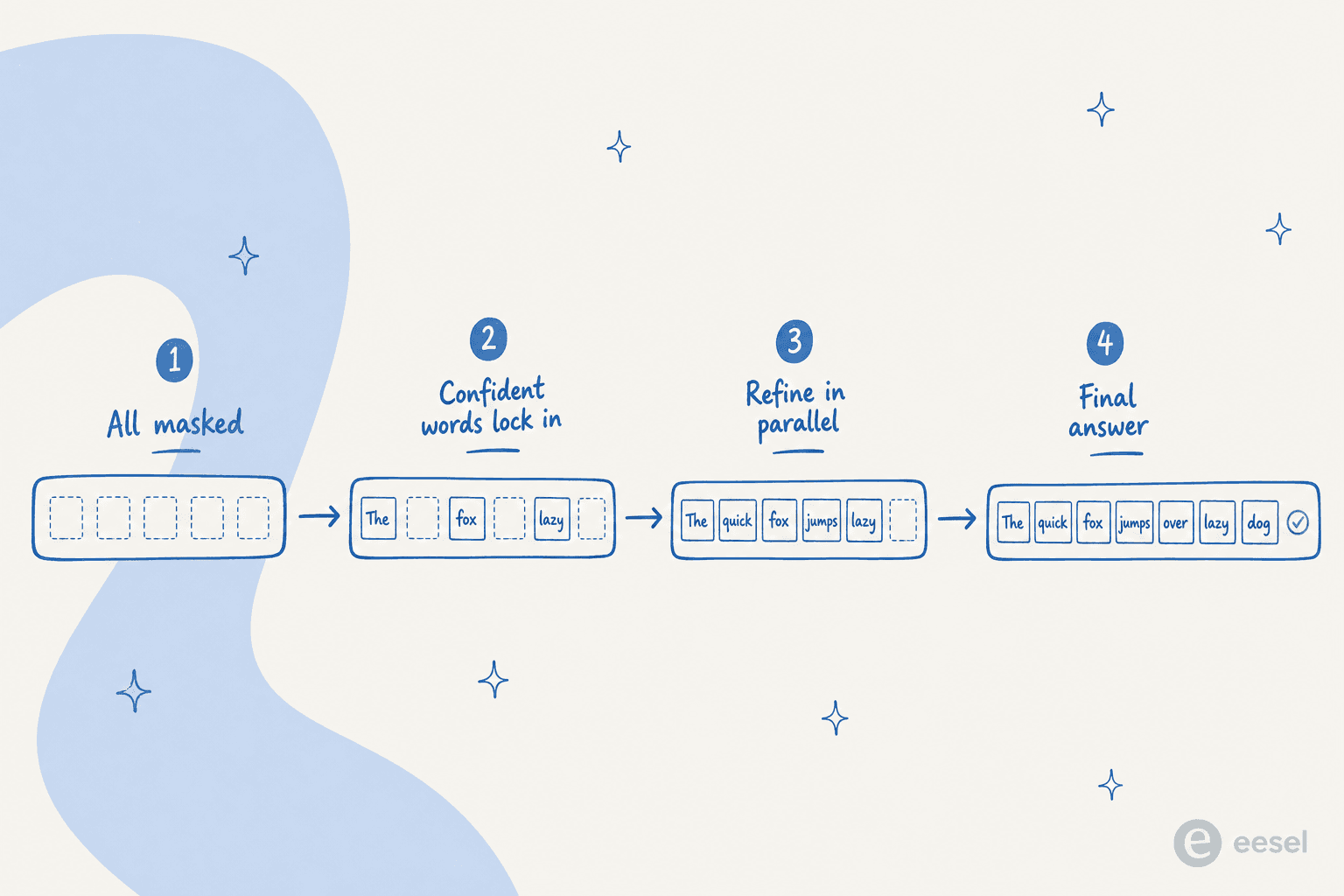
El enfoque dominante para el texto es la difusion enmascarada. En LLaDA, un modelo de difusion abierto de 8B, el proceso directo enmascara tokens y el proceso inverso usa un "predictor de mascaras" de tipo transformer para rellenar todos los tokens enmascarados a la vez, simulando la difusion desde estar totalmente enmascarado hasta estar totalmente escrito. Una linea anterior, Diffusion-LM, usaba difusion continua sobre vectores de palabras en su lugar.
La diferencia principal es la decodificacion en paralelo. Un dLLM genera tokens en paralelo en lugar de uno a uno, y el transformer subyacente puede modificar varios tokens a la vez para mejorar globalmente la respuesta. Como la formulacion no es autorregresiva, tambien permite la generacion en cualquier orden: el modelo puede fijar primero las palabras de las que tiene confianza en cualquier punto de la secuencia y luego rellenar el resto.
Una de las explicaciones mas claras vino en realidad de un desarrollador en Hacker News, que disipa la confusion de que "la difusion reemplaza a los transformers":
"A pesar del nombre, los LM de difusion tienen poco que ver con la difusion de imagenes y estan mucho mas cerca de BERT y del viejo y bueno modelado de lenguaje enmascarado... para generar algo desde cero, empiezas alimentando al modelo con todos los [MASK]... en 10 pasos habras generado una secuencia completa." nvtop, en la discusion sobre Gemini Diffusion en Hacker News
Esa vision paralela y bidireccional es tambien la razon por la que un modelo de difusion puede ver el contexto a ambos lados de un hueco. LLaDA, por ejemplo, supera a GPT-4o en una tarea de completar poemas invertidos, superando la maldicion de la inversion que hace tropezar a los modelos de izquierda a derecha.
Autorregresivo vs difusion: la diferencia esencial
Si recuerdas una sola imagen de este articulo, que sea esta. Los modelos autorregresivos construyen una frase como una carrera de relevos, cada palabra pasa el testigo a la siguiente. Los modelos de difusion la construyen como revelar una Polaroid, la imagen completa surge a la vez y se va afinando con cada pasada.
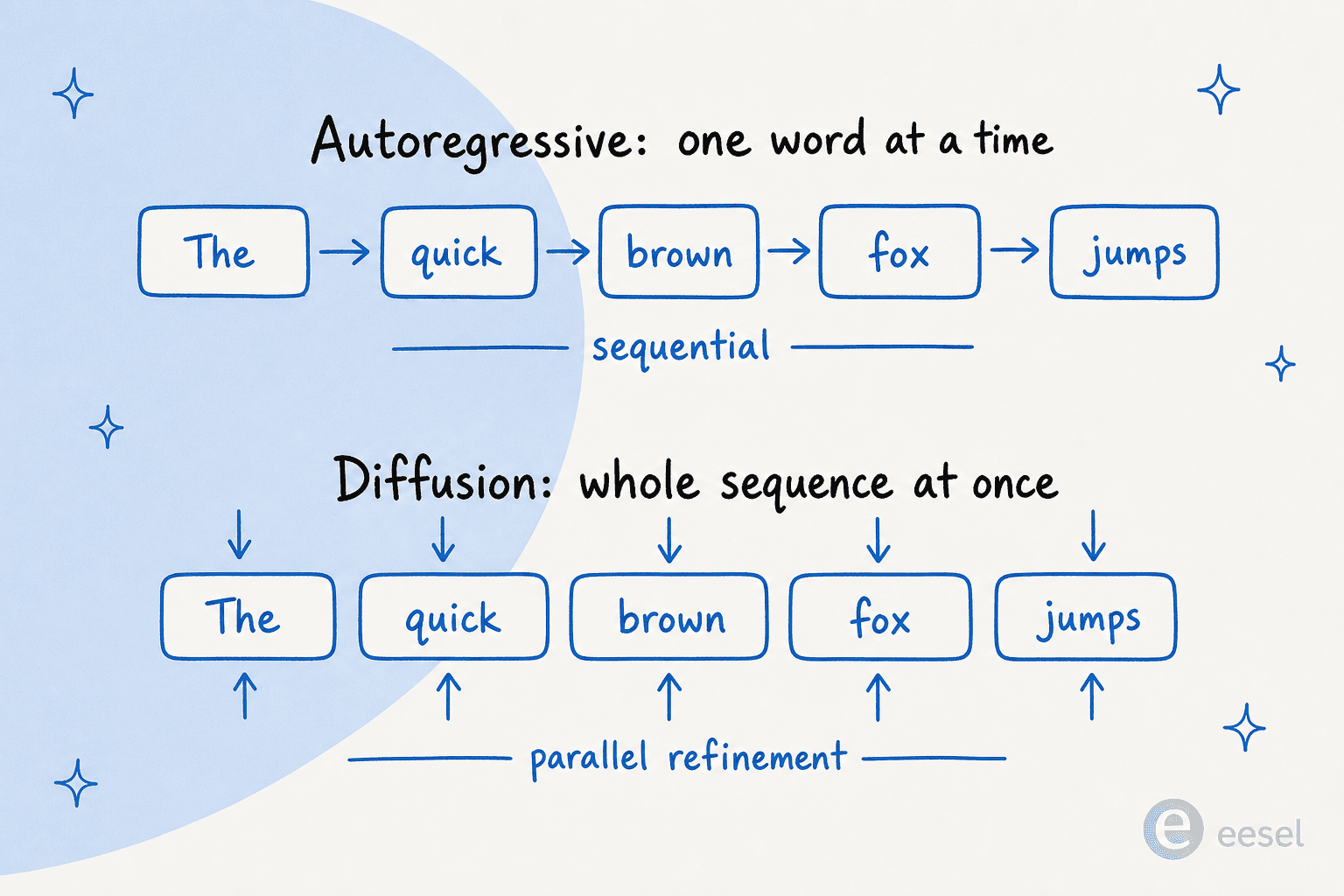
Asi se comparan ambos en las dimensiones que de verdad le importan a un comprador:
| Dimension | Autorregresivo (GPT, Claude, Gemini) | Difusion (Mercury, Gemini Diffusion) |
|---|---|---|
| Orden de generacion | De izquierda a derecha, un token a la vez | Toda la secuencia en paralelo, en cualquier orden |
| Velocidad | Decenas a ~200 tokens/seg | ~1.000 a ~1.500 tokens/seg |
| Puede revisar tokens anteriores? | No, una vez emitido queda fijo | Si, a lo largo de las pasadas de eliminacion de ruido |
| Edicion y relleno | Incomodo (solo anadir) | Natural (se condiciona a ambos lados) |
| Razonamiento dificil | Mas fuerte hoy | Queda por detras, sobre todo a escala de frontera |
| Contexto largo | Mas eficiente (reutiliza la cache KV) | Mas debil (recalcula la atencion en cada pasada) |
| Longitud de salida | Variable, flexible | A menudo bloques de longitud fija |
| Madurez del ecosistema | Cinco anos de herramientas | Incipiente, en rapido movimiento |
Fijate en la simetria: las victorias de la difusion (velocidad, revision, relleno) y sus derrotas (profundidad de razonamiento, contexto largo, madurez) se remontan a la misma causa raiz. Trabajar sobre toda la secuencia en paralelo es lo que la hace rapida y editable, y tambien lo que hace mas dificiles el contexto largo y el razonamiento paso a paso.
El beneficio de velocidad, y la trampa
Las cifras de velocidad son genuinamente llamativas, y no son todo marketing. El desarrollador y bloguero de LLM Simon Willison salio de la lista de espera de Gemini Diffusion y lo probo:
"La caracteristica clave, entonces, es la velocidad. Sali de la lista de espera y lo acabo de probar y guau, no estaban bromeando con lo de que es rapido." Simon Willison, primeras impresiones de Gemini Diffusion
Asi se compara el rendimiento entre unos cuantos modelos, con las referencias autorregresivas para contextualizar:
| Modelo | Tipo | Rendimiento (tokens/seg) | Fuente |
|---|---|---|---|
| Gemini Diffusion | Difusion | ~1.479 (excl. sobrecarga) | Proveedor |
| Mercury 2 (Inception) | Difusion | ~1.196 pico | Artificial Analysis |
| Mercury Coder Mini | Difusion | 1.109 | Proveedor, corroborado por AA |
| Gemini 2.0 Flash-Lite | Autorregresivo | ~201 | Segun Inception |
| Claude 4.5 Haiku | Autorregresivo | ~89 | Segun Inception |
| GPT-5 Mini | Autorregresivo | ~71 | Segun Inception |
Dos cosas que conviene mantener honestas aqui. Primero, la mayoria de las cifras de rendimiento se miden en una NVIDIA H100 y muchas son afirmaciones de los proveedores; Artificial Analysis es la principal fuente independiente, y ha corroborado la velocidad de Mercury pero todavia no su calidad. Segundo, la ventaja de velocidad es real pero condicional. La generacion de alta calidad suele necesitar muchos pasos de eliminacion de ruido, y recortar pasos de forma ingenua degrada la calidad bruscamente, asi que la velocidad hay que gastarla con cuidado.
Y la brecha de calidad todavia es visible, sobre todo en tareas dificiles. Gemini Diffusion obtiene 40,4% frente a 56,5% en GPQA Diamond, y 69,1% frente a 79,0% en Global MMLU frente a Flash-Lite, aunque lidera en algunos benchmarks de codigo y matematicas. La lectura honesta de un ingeniero que trabaja en stacks de agentes en produccion merece ser citada, porque nombra el problema historico directamente:
"[Los LM de difusion anteriores] eran rapidos de la misma forma en que un reloj averiado es rapido: no importa lo rapido que llegues a la respuesta equivocada." vainkop, "Mercury 2 and the End of Autoregressive Monopoly"
Su veredicto para los equipos de hoy es mesurado: este es un momento de "seguirlo de cerca y prepararse para moverse rapido", no de "reescribir tu stack de agentes de inmediato".
Los modelos que lideran la carga
El espacio paso rapidamente de curiosidad de investigacion a productos en el mercado. La senal de financiacion es fuerte: Inception Labs, fundada por Stefano Ermon de Stanford, recaudo 50 millones de dolares en noviembre de 2025 de una lista estrategica que incluye a Nvidia, M12 de Microsoft, Databricks y Snowflake, ademas de los inversores angel Andrew Ng y Andrej Karpathy. Cuando los actores de infraestructura apuestan, es porque creen que la velocidad puede servirse.
| Modelo | Quien | Estado | Lo que destaca |
|---|---|---|---|
| Mercury / Mercury 2 | Inception Labs | API en vivo, 0,25 $ / 0,75 $ por 1M de tokens | Primer LLM de difusion comercial; ~1.196 tok/s |
| Gemini Diffusion | Google DeepMind | Experimental, lista de espera | Calidad ~Gemini 2.0 Flash-Lite a varias veces la velocidad |
| DiffusionGemma | Google DeepMind | Pesos abiertos (Apache 2.0), junio de 2026 | Mezcla de expertos de 26B; >1.000 tok/s, por debajo de Gemma 4 en calidad |
| LLaDA 8B | ML-GSAI (investigacion) | Pesos abiertos | MMLU 65,9, a la par mas o menos con Llama3 8B |
| Dream 7B | HKU NLP + Huawei | Pesos abiertos | Domina las tareas de planificacion (Sudoku 81,0 frente al 21,0 de Qwen) |
Una aclaracion rapida, porque los nombres son confusamente similares: "Gemini Diffusion" (cerrado, lista de espera) y "DiffusionGemma" (pesos abiertos) son dos lanzamientos distintos de Google. El primero es un modelo experimental alojado que se mostro en Google I/O 2025; el segundo es un modelo descargable de 26B lanzado el 10 de junio de 2026 bajo Apache 2.0, que genera eliminando el ruido de bloques de 256 tokens en paralelo y se mantiene por debajo del Gemma 4 estandar en todos los benchmarks publicados. Velocidad a cambio de calidad, intercambiada abiertamente.
El patron recurrente en todos ellos: una ventaja de rendimiento de mas de 10x que estrecha la brecha de calidad a escala pequena y media (LLaDA a la par mas o menos con Llama3 8B, Mercury competitivo en codigo) pero que todavia se nota en la frontera. El caso de uso principal hoy es la generacion de codigo y los bucles agenticos de baja latencia, donde la velocidad de la decodificacion en paralelo se acumula.
Por que los modelos de IA basados en difusion importan para las empresas
La velocidad no es una metrica de vanidad una vez que pones un modelo dentro de un producto. El encuadre mas claro viene de la experiencia en produccion: la latencia en los sistemas autorregresivos se acumula en cadenas.
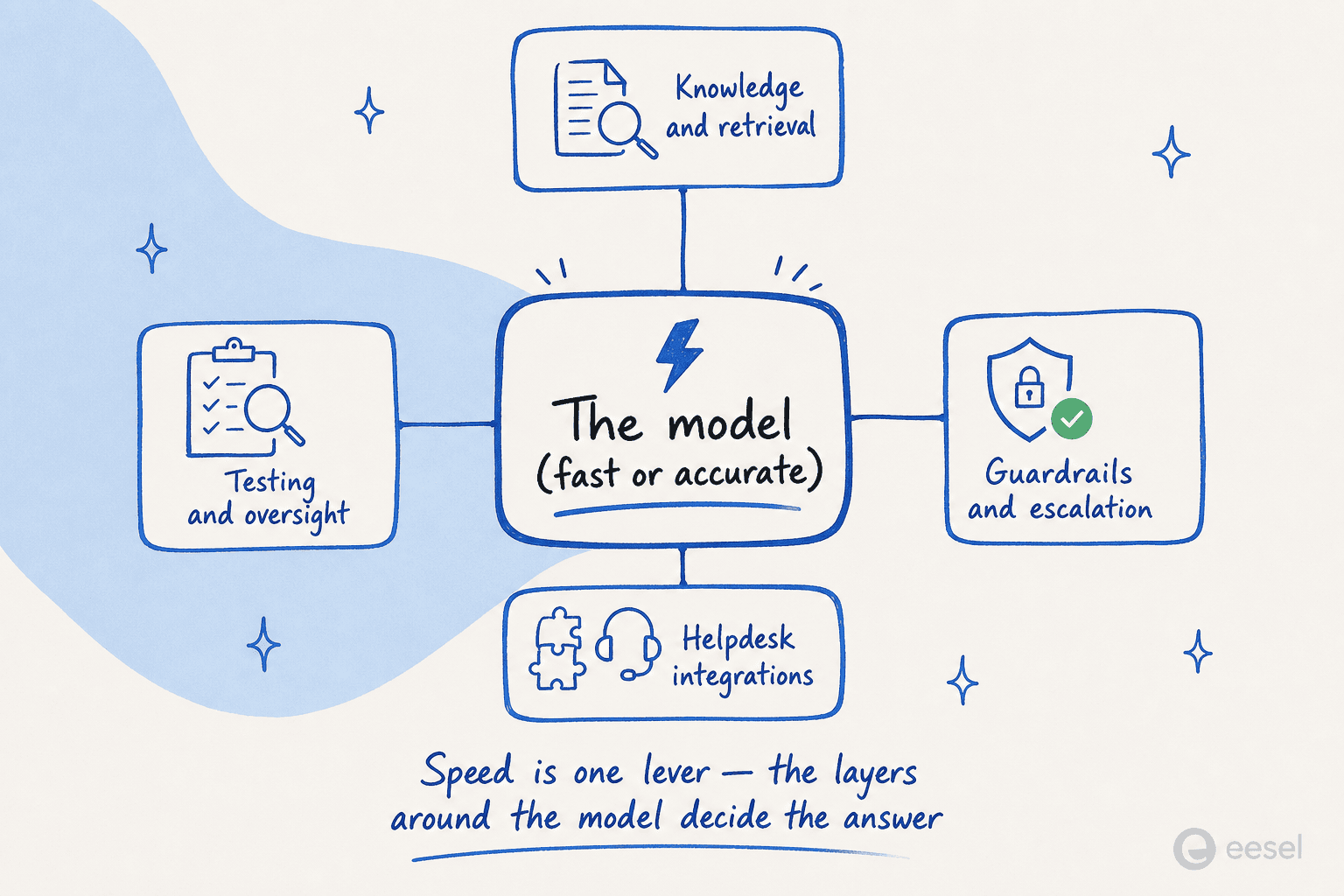
Como lo describio un ingeniero, un solo paso de agente que llama al modelo tres veces (razonar, planificar, actuar) son tres pasadas secuenciales; encadena unas cuantas de esas y estaras en siete u ocho segundos, lo que "no es un agente en tiempo real, eso es un trabajo por lotes lento". Una generacion mas rapida por paso hace asequibles las cadenas mas profundas de agentes de IA. El mismo articulo senala que los equipos actualmente limitan la profundidad de la cadena a entre tres y cinco pasos para mantenerse dentro de su SLA; con inferencia a velocidad de difusion, las cadenas de diez pasos empiezan a parecer viables.
Unos cuantos lugares concretos donde la velocidad rinde:
- Chat en tiempo real y copilotos. Las respuestas por debajo del segundo son, como dice ese ingeniero, "la diferencia entre la adopcion y el abandono" para una capa de asistente en un producto SaaS.
- Texto por lotes de alto volumen. El resumen, la clasificacion, el reformateo y la traduccion estan limitados por el rendimiento y son paralelizables, que es exactamente donde brilla la difusion.
- Asistentes de programacion. La naturaleza de relleno de la difusion encaja con las ediciones de codigo, generando el inicio y el final de un bloque en la misma pasada y editando el medio.
Luego esta el coste. Una generacion mas rapida en el mismo hardware significa un menor coste de inferencia por token, y el cofundador de Inception argumenta que el enfoque "realiza mas computacion por unidad de memoria transferida", lo que abre nuevas formas de reducir los costes de inferencia de IA en hardware mas antiguo. Para los equipos que ejecutan cientos de miles de llamadas de agente al dia, eso se acumula. El precio publico de Mercury 2 de 0,25 $ por millon de tokens de entrada y 0,75 $ por millon de salida es genuinamente barato.
Pero aqui esta la parte que la mayoria de la cobertura se salta. Para la mayoria de las aplicaciones en produccion, los modelos autorregresivos siguen siendo la opcion por defecto, y por una buena razon: manejan el contexto largo de forma mas eficiente, razonan con mas profundidad (la difusion hace menos trabajo por token, asi que hay menos margen para "pensar") y tienen cinco anos de herramientas a sus espaldas. La jugada pragmatica no es la sustitucion sino el enrutamiento: enviar los pasos simples y de alta frecuencia (busqueda, formato, clasificacion) a un modelo de difusion rapido, y reservar los modelos autorregresivos de frontera para el razonamiento profundo. Compara eso con la economia de los agentes de IA frente a los agentes humanos y el atractivo es obvio: hacer mas del trabajo barato de forma barata.
Que significa para la atencion al cliente con IA
La atencion al cliente parece a primera vista el caso de uso perfecto para la difusion. El chat en vivo y los agentes de soporte con IA son exactamente el escenario de baja latencia y de cara al usuario donde la diferencia entre un segundo y varios segundos decide si la experiencia se siente receptiva o lenta. Un modelo mas rapido deberia significar respuestas mas agiles en tu chatbot de IA.
El replanteamiento que vale la pena asimilar: para un equipo de soporte, la arquitectura del modelo importa mucho menos que la orquestacion que lo rodea. Una respuesta de soporte real casi nunca es una generacion desde cero. Es una respuesta fundamentada sobre tu base de conocimiento, el historial de tickets y los documentos de politicas. Eso pone la debilidad de la difusion, el manejo del contexto largo, justo en el camino del caso de uso de soporte, y significa que la calidad de la recuperacion, la frescura del conocimiento y las salvaguardas determinan la respuesta mucho mas que si los tokens finales se emitieron de izquierda a derecha o en paralelo.
Dicho sin rodeos: un modelo mas rapido conectado a conocimiento desactualizado o a reglas de escalado debiles solo produce respuestas equivocadas mas rapido. El problema del reloj averiado, aplicado al soporte. Por eso tambien los problemas de los chatbots de IA tan rara vez se reducen al modelo base y tan a menudo se reducen a la fundamentacion, las pruebas y las metricas que de verdad sigues.
El consejo genuinamente util, entonces, es mantenerse agnostico respecto al modelo. Elige una capa que permita que el modelo subyacente mejore debajo de ti, ya sea un modelo de difusion mas rapido el ano que viene o uno autorregresivo mas inteligente. Los equipos que mas se beneficiaran de la difusion son los que construyeron primero sobre una orquestacion solida y trataron al modelo como un componente intercambiable.
Prueba eesel
Asi es exactamente como esta construido eesel AI. En lugar de apostar por una sola arquitectura de modelo, eesel es la capa de orquestacion: aprende de tus tickets pasados, documentos de ayuda y herramientas desde el primer dia, luego redacta respuestas, clasifica y escala a traves del servicio de soporte que ya usas, con enrutamiento basado en la confianza para que las respuestas de baja confianza se queden como borradores en lugar de publicarse.

El diferenciador que importa para este tema: un modo de simulacion que ejecuta el agente contra tus tickets pasados para que puedas ver la cobertura y corregir los huecos antes de salir en vivo, que es como evitas que un modelo rapido publique con confianza respuestas equivocadas. Funciona en mas de 100 integraciones y mas de 80 idiomas, asi que sea cual sea el modelo mas rapido o mas inteligente el ano que viene, tu configuracion de soporte sigue funcionando. Puedes probar eesel gratis, sin necesidad de tarjeta de credito.
Preguntas frecuentes
Que es un modelo de IA basado en difusion en terminos sencillos?
En que se diferencian los modelos de lenguaje de difusion de los LLM autorregresivos como GPT o Claude?
Son los modelos de IA basados en difusion realmente mas rapidos que los LLM normales?
Deberia mi empresa cambiarse a un modelo de lenguaje de difusion?
Importa la arquitectura del modelo para la atencion al cliente con IA?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








