Resumen
Los precios de Hugging Face tienen cinco superficies de facturación independientes: el plan de cuenta base (Gratuito → Enterprise), el hardware de Spaces que activas bajo demanda, la inferencia sin servidor a través de Inference Providers, el despliegue dedicado de modelos mediante Inference Endpoints y el almacenamiento. La mayor confusión surge del hecho de que el precio del plan solo cubre tu asiento en el Hub; cada modelo que ejecutas añade cargos de cómputo separados por encima.
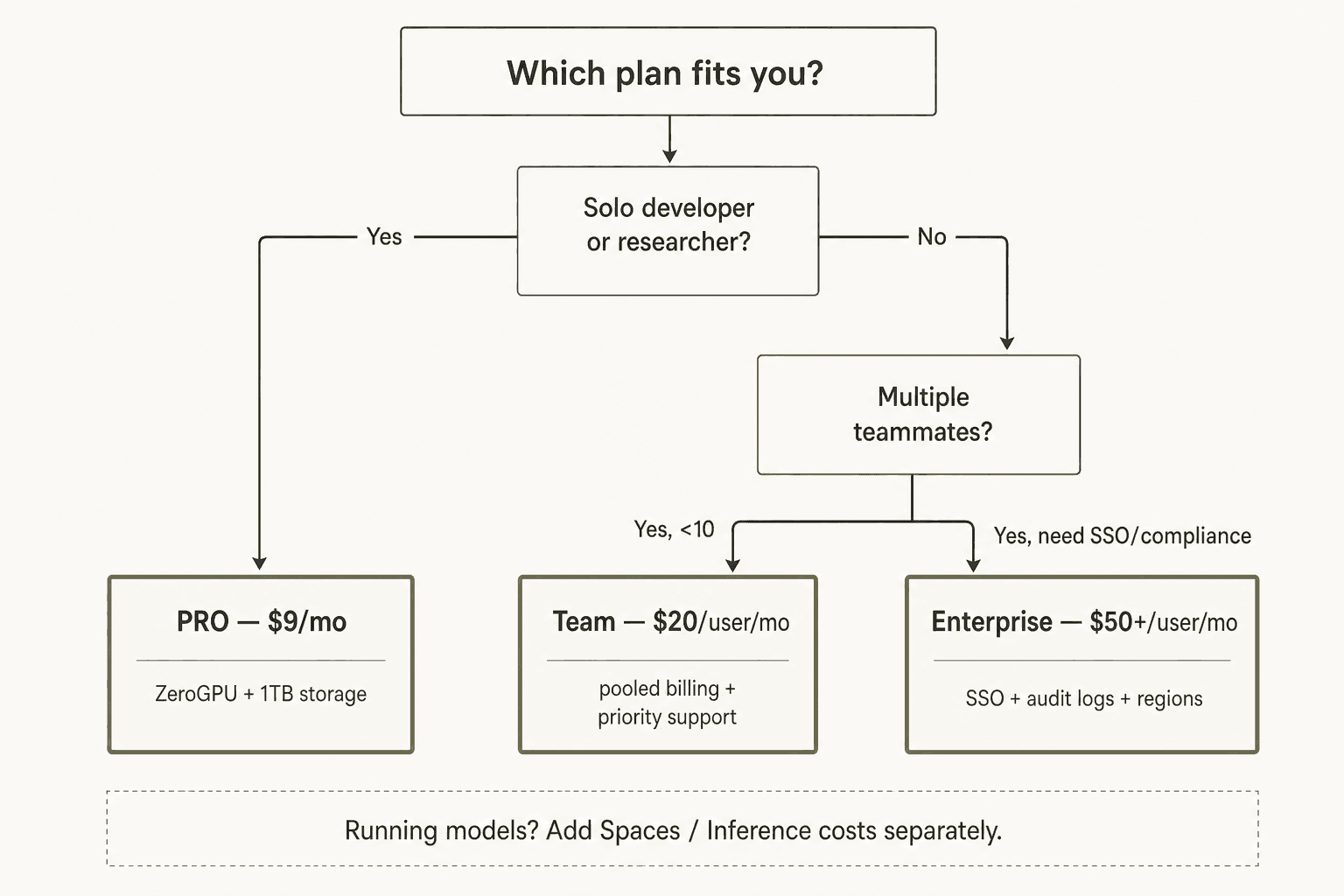
Versión corta: el nivel gratuito es sólido para exploración. PRO a $9/mes es la mejor actualización en términos de valor para desarrolladores individuales, principalmente por el aumento de cuota ZeroGPU y Spaces Dev Mode. Team a $20/usuario/mes tiene sentido cuando colaboras en grupo. Enterprise a $50+/usuario/mes es donde se desbloquean SSO y registros de auditoría; vale la pena si tu organización los necesita, no antes. Y si ejecutas Inference Endpoints dedicados, presupuesta con cuidado: una sola GPU T4 siempre activa cuesta $0.50/hr, o ~$365/año antes de haber procesado una sola solicitud.
Por qué pagas lo que pagas
El principal error que comete la gente con los precios de Hugging Face es tratar el precio del plan de cuenta como el costo total. No lo es. Como señala la guía de costos 2026 de Metacto: "Estos planes no cubren el costo total de ejecutar tus modelos; piénsalo como el precio de entrada al parque de atracciones: todavía tienes que pagar por los juegos."
El plan de cuenta —Gratuito, PRO, Team, Enterprise— es tu suscripción al Hub. Cubre el alojamiento de repositorios, límites de almacenamiento, funciones de colaboración y controles de gobernanza. Ejecutar modelos es una factura separada, dividida en tres sistemas distintos: Spaces (alojamiento de demos y aplicaciones con GPU opcional), Inference Providers (enrutamiento sin servidor a APIs de modelos de terceros) e Inference Endpoints (infraestructura dedicada y siempre activa que tú controlas).
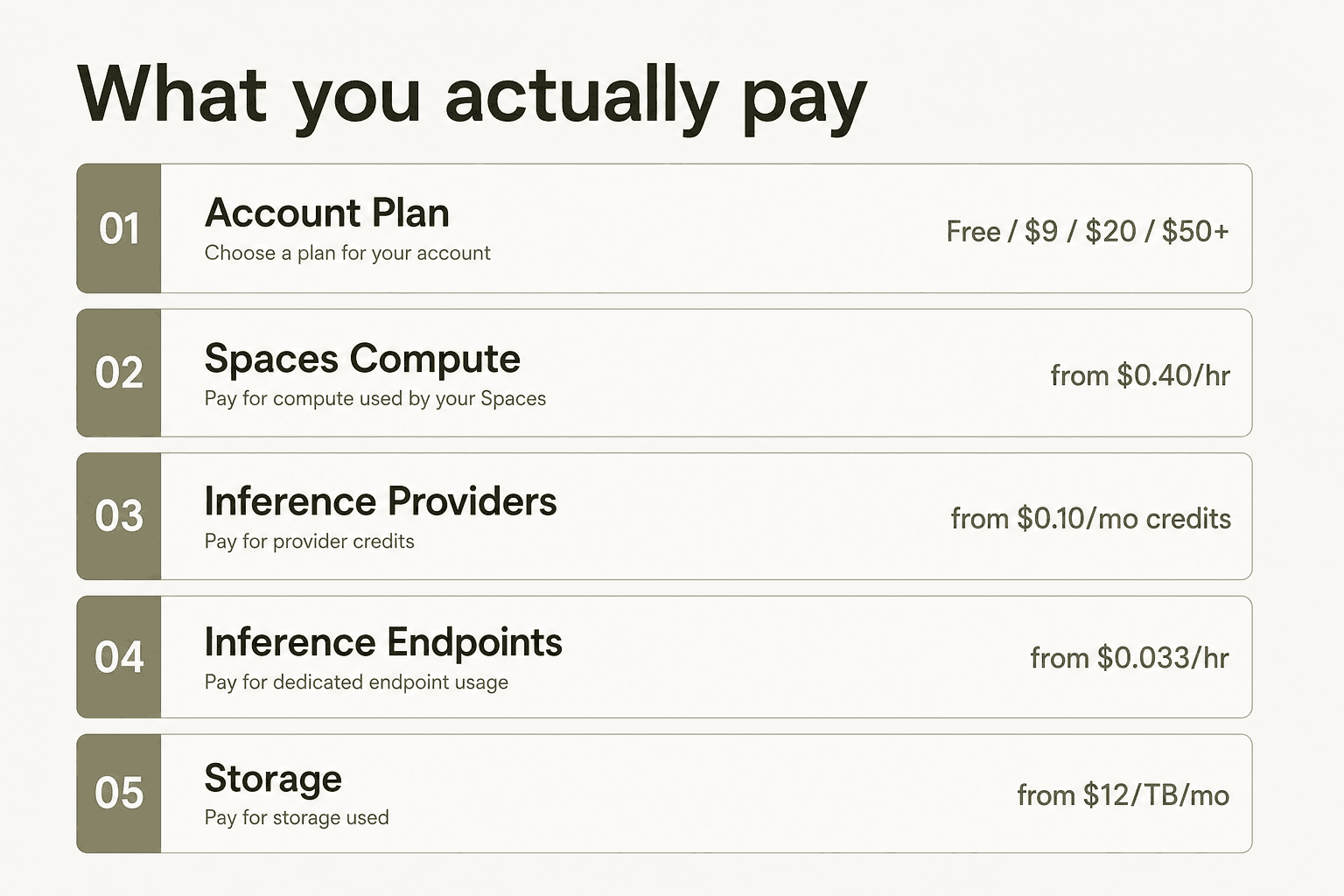
Entender esa separación es el requisito previo para leer correctamente cualquier precio de Hugging Face.
Planes de cuenta
Gratuito
El nivel gratuito es más generoso de lo que la mayoría espera. Tienes acceso a más de 2M de modelos, 500k+ conjuntos de datos y más de 1M de Spaces en el Hub, 100 GB de almacenamiento en repositorios privados, acceso ZeroGPU de la comunidad y $0.10/mes en créditos de Inference Providers. Ese crédito no llega lejos en producción, pero es suficiente para pequeños experimentos.
Lo que no obtienes: sin SSO, sin registros de auditoría, sin grupos de recursos, sin cola prioritaria. Los límites de velocidad en la Inference API son notablemente más estrictos que en los planes de pago. El nivel gratuito es ideal para quien está aprendiendo el ecosistema o realizando experimentos ocasionales, no para equipos que ofrecen servicios en producción.
PRO - $9/mes
Este es el salto de valor más claro en la página de precios. Por $9/mes, PRO te ofrece:
- 8× tu cuota ZeroGPU con prioridad máxima en la cola (40 min/día frente a 5 min/día en el nivel gratuito)
- 1 TB de almacenamiento privado (frente a los 100 GB del nivel gratuito)
- $2/mes en créditos de Inference Providers (20× la cantidad del nivel gratuito)
- Spaces Dev Mode - acceso SSH y VS Code a tu Space para iteración rápida sin redespliegue
- Visor de Conjuntos de Datos privados para trabajar con datos de entrenamiento no públicos
- Acceso anticipado a nuevas funciones del Hub y una insignia PRO
El aumento de cuota ZeroGPU es el principal atractivo. ZeroGPU da a todos los usuarios acceso a un grupo compartido de GPUs Nvidia RTX Pro 6000 Blackwell sin cargo por hora, pero los usuarios del nivel gratuito alcanzan su cuota en unos 5 minutos de tiempo de GPU al día. PRO eleva eso a 40 minutos con programación prioritaria.
SaaSLens puntuó Hugging Face con 4.7/5 en su reseña de marzo de 2026, calificándolo como "uno de nuestros favoritos más valorados para fundadores individuales", y destacando específicamente el plan PRO por ofrecer "acceso a GPU de nivel empresarial por el costo de un par de cafés al mes". Es una valoración justa. Optaríamos por PRO siempre que necesitemos ejecutar demos con GPU sin pagar por infraestructura dedicada.
Team - $20/usuario/mes
Team es el primer plan a nivel de organización. La facturación pasa a ser por asiento: cada miembro de tu organización en Hugging Face paga $20/mes. Además de las ventajas de PRO para todos en la organización, obtienes:
- 12 TB de almacenamiento público base + 1 TB/asiento público + 1 TB/asiento privado
- $2/mes en créditos de Inference Providers por asiento (agrupados en la organización)
- Controles de facturación a nivel de organización para Inference Providers: establece límites de gasto y desactiva proveedores específicos
- Soporte prioritario del equipo de Hugging Face
- Todos los miembros obtienen el aumento de cuota ZeroGPU de 8×
Los controles de facturación para Inference Providers son genuinamente útiles para equipos de investigación donde los individuos podrían acumular costos accidentalmente con modelos frontier costosos. Los administradores pueden limitar el gasto mensual de la organización y desactivar proveedores específicos.
Una advertencia importante: Team no incluye SSO, registros de auditoría ni grupos de recursos. Esos son exclusivos de Enterprise. Si tu equipo necesita conectarse a tu proveedor de identidad corporativo o generar informes de cumplimiento, Team no será suficiente independientemente del número de miembros.
Enterprise - desde $50/usuario/mes
Enterprise es donde se desbloquea el conjunto de gobernanza. La cifra de $50/usuario/mes es el precio mínimo; los contratos grandes con compromisos de volumen, facturación anual y SLAs personalizados se negocian con el equipo de ventas de Hugging Face. Los clientes Enterprise destacados incluyen NVIDIA, Google, OpenAI, Meta, Salesforce, IBM Research, Shopify y Roblox.
Las funciones que llevan a los equipos a este nivel:
SSO conecta tu proveedor de identidad: Okta, Azure AD, Google Workspace o cualquier IdP compatible con SAML/OpenID Connect. Enterprise Plus añade SCIM para el aprovisionamiento automatizado de usuarios.
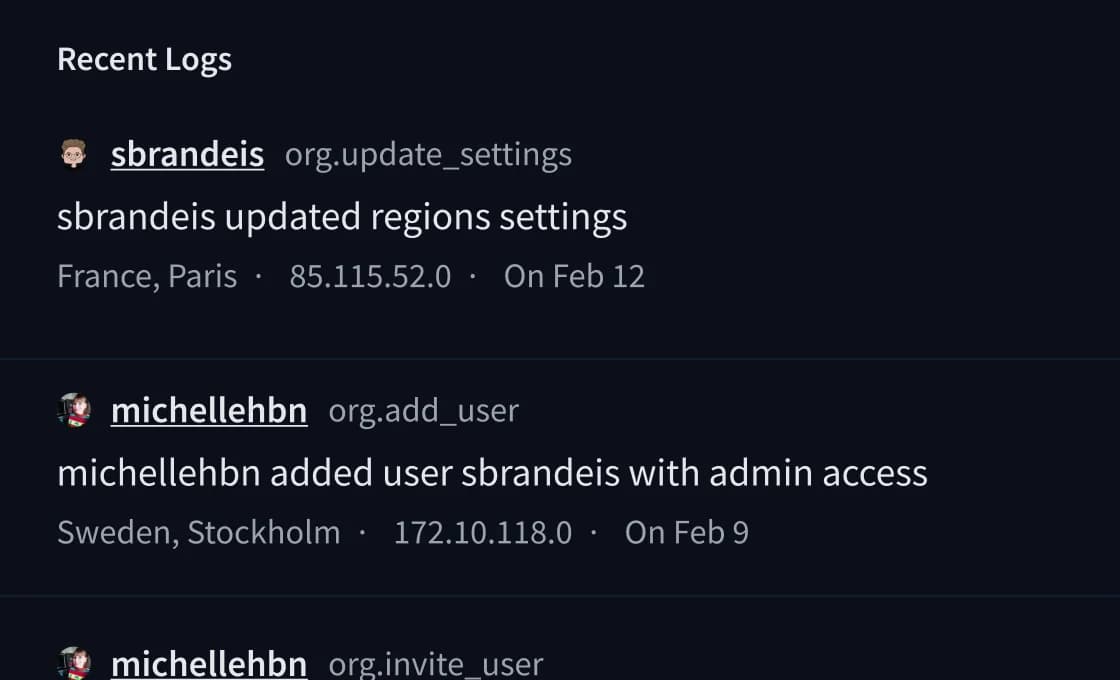
Los registros de auditoría registran cada acción de la organización: quién cambió qué, desde dónde y en qué momento, con atribución de usuario, dirección IP y ubicación. Útil para revisiones SOC 2 Tipo II y documentación de cumplimiento GDPR.
Los grupos de recursos permiten a los administradores asignar repositorios a grupos con nombre y conceder acceso de LECTURA, ESCRITURA o COLABORADOR por usuario, útil para separar los espacios de trabajo de investigación, producción y experimentación dentro de una única organización.
El análisis de repositorios muestra tendencias de descargas, uso de modelos y acceso a conjuntos de datos en toda la organización en un único panel, práctico para entender qué modelos internos se utilizan realmente.
La residencia de datos te permite elegir y auditar la región geográfica donde se almacenan tus repositorios, relevante para los requisitos de GDPR y soberanía de datos. Enterprise Plus añade controles de seguridad de red y listas blancas de IP.
El almacenamiento para Enterprise es sustancial: 200 TB públicos base + 1 TB/asiento, escalando hasta 1 PB para contratos grandes.
Comparación de planes de un vistazo
| Gratuito | PRO | Team | Enterprise | |
|---|---|---|---|---|
| Precio | $0 | $9/mes | $20/usuario/mes | $50+/usuario/mes |
| Almacenamiento privado | 100 GB | 1 TB | 1 TB/asiento | 1 TB/asiento |
| Almacenamiento público | Sin garantía | Hasta 10 TB | 12 TB + 1 TB/asiento | 200 TB + 1 TB/asiento |
| Créditos de inferencia | $0.10/mes | $2/mes | $2/asiento/mes | $2/asiento/mes |
| Cuota ZeroGPU | Estándar | 8× + prioridad | 8× (todos los miembros) | 8× (todos los miembros) |
| Spaces Dev Mode | No | Sí | Sí | Sí |
| Visor de Conjuntos de Datos privados | No | Sí | Sí | Sí |
| Controles de facturación org. | No | No | Sí | Sí |
| SSO | No | No | No | Sí |
| Registros de auditoría | No | No | No | Sí |
| Grupos de recursos | No | No | No | Sí |
| Análisis de repositorios | No | No | No | Sí |
| Residencia de datos | No | No | No | Sí |
| Soporte prioritario | No | No | Sí | Sí (dedicado) |
| Contratos anuales | No | No | No | Sí |
Precios del hardware de Spaces
Los Spaces son aplicaciones y demos de ML interactivos alojados en el Hub. El nivel CPU Basic es gratuito; los niveles GPU son de pago por uso por hora, facturados mientras el Space está en ejecución.
| Hardware | vCPU | RAM | Acelerador | VRAM | Por hora |
|---|---|---|---|---|---|
| CPU Basic | 2 | 16 GB | - | - | Gratis |
| CPU Upgrade | 8 | 32 GB | - | - | $0.03 |
| ZeroGPU | dinámico | dinámico | RTX Pro 6000 Blackwell | hasta 96 GB | Gratis* |
| T4 - small | 4 | 15 GB | T4 | 16 GB | $0.40 |
| T4 - medium | 8 | 30 GB | T4 | 16 GB | $0.60 |
| L4 (1×) | 8 | 30 GB | L4 | 24 GB | $0.80 |
| L4 (4×) | 48 | 186 GB | L4 | 96 GB | $3.80 |
| L40S (1×) | 8 | 62 GB | L40S | 48 GB | $1.80 |
| L40S (4×) | 48 | 382 GB | L40S | 192 GB | $8.30 |
| L40S (8×) | 192 | 1.534 GB | L40S | 384 GB | $23.50 |
| A10G - small | 4 | 15 GB | A10G | 24 GB | $1.00 |
| A10G - large | 12 | 46 GB | A10G | 24 GB | $1.50 |
| A100 - large | 12 | 142 GB | A100 | 80 GB | $2.50 |
| 4× A100 | 48 | 568 GB | A100 | 320 GB | $10.00 |
| 8× A100 | 96 | 1.136 GB | A100 | 640 GB | $20.00 |
*ZeroGPU es gratuito dentro de la cuota. Los miembros PRO y de organizaciones Team/Enterprise obtienen 8× la cuota estándar. El exceso se factura a $1 por cada 10 minutos.
Los Spaces se suspenden tras 48 horas de inactividad en el nivel CPU gratuito. Los Spaces con GPU de pago permanecen en ejecución hasta que los pausas manualmente; un T4-small que permanezca activo durante 30 días cuesta $288. No hay apagado automático.
Vale la pena saber: las subvenciones de GPU de la comunidad están disponibles para proyectos personales que cumplan los requisitos. Si publicas investigación abierta y necesitas acceso persistente a GPU, vale la pena solicitarlas antes de comprometerse con un nivel de pago.
Inference Providers (sin servidor)
Inference Providers te permite enrutar llamadas a la API a más de 45.000 modelos a través de más de 18 socios de inferencia —Groq, Fireworks, Mistral, Cohere, Nebius, SambaNova y otros— mediante un único endpoint unificado en router.huggingface.co/v1. Hugging Face traslada los precios del proveedor sin margen adicional.
Créditos mensuales por plan, aplicados al enrutar a través de Hugging Face:
| Plan | Créditos mensuales |
|---|---|
| Gratuito | $0.10 |
| PRO | $2.00 |
| Team / Enterprise (por asiento) | $2.00 |
Una vez agotados los créditos, el uso pasa a pago por uso. Puedes dejar que HF facture tu cuenta (más sencillo, se aplican los créditos mensuales) o traer tu propia clave de API del proveedor y pagar directamente al proveedor (no se aplican créditos de HF, pero controlas la relación de facturación directamente).
Las organizaciones de Team y Enterprise pueden establecer límites de gasto y desactivar proveedores específicos desde la configuración de la organización, útil para controlar los costos cuando los miembros individuales ejecutan modelos frontier costosos.
Hugging Face también mantiene su propio backend hf-inference, la original "Inference API (sin servidor)", ahora centrada en tareas vinculadas a CPU como embeddings, clasificación de texto y modelos más pequeños (BERT, GPT-2). Ejecutar Llama 3.1 70B o cualquier LLM de generación actual se enruta a través de un proveedor externo.
Inference Endpoints (despliegue dedicado)
Los Inference Endpoints son para equipos que necesitan latencia predecible e infraestructura dedicada: sin arranques en frío, sin cola compartida, despliegues con escalado automático en AWS, Azure o GCP. Tú eliges el hardware, Hugging Face gestiona el contenedor y el escalado.
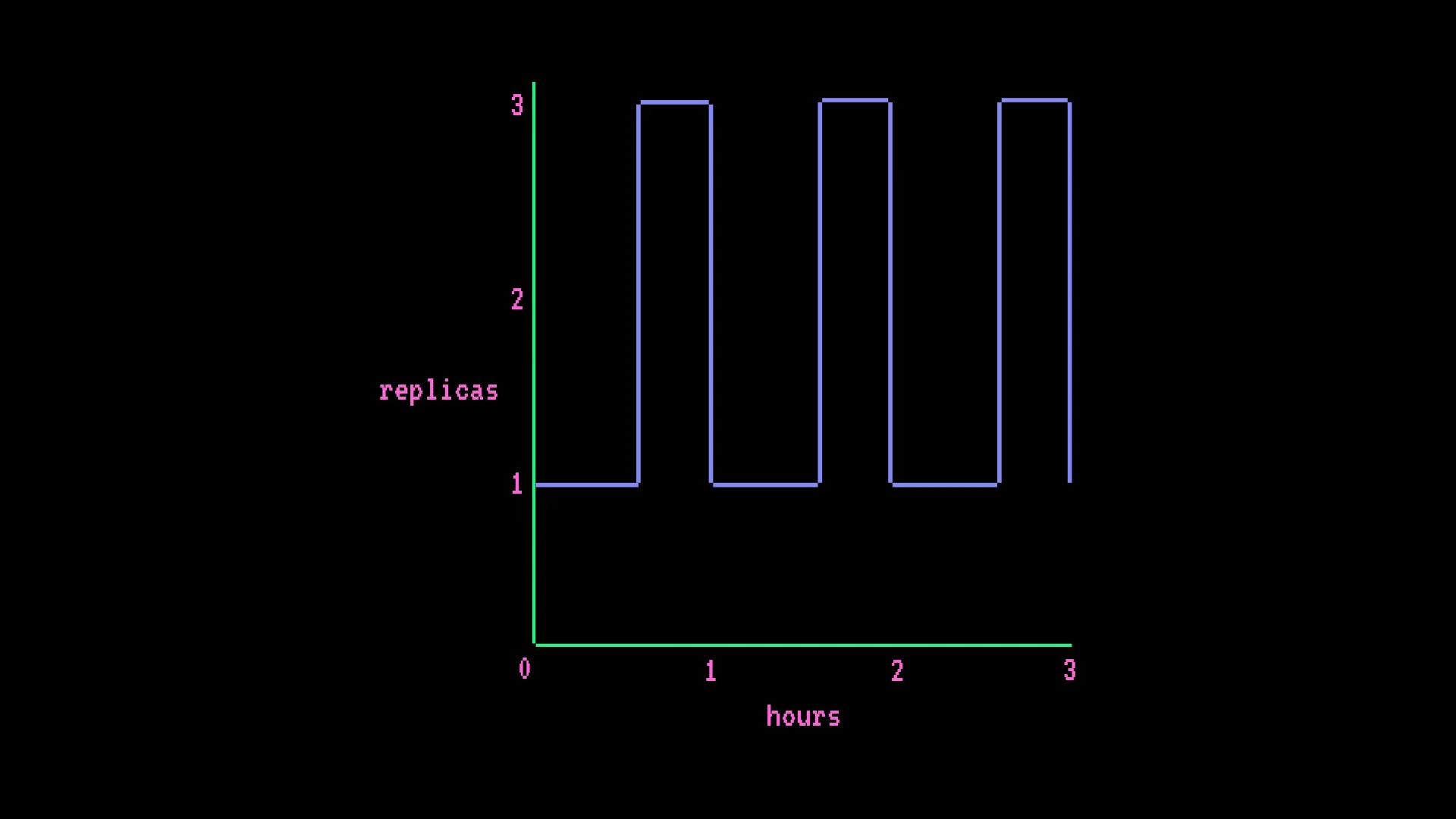
El modelo de facturación es el que más sorprende. Los Endpoints se facturan por minuto a la tarifa de la instancia, multiplicada por el número de réplicas activas, independientemente del volumen de solicitudes. No es facturación por solicitud ni por token.
Precios de instancias GPU (AWS)
| GPU | Cantidad | VRAM | Por hora |
|---|---|---|---|
| T4 | 1 | 14 GB | $0.50 |
| T4 | 4 | 56 GB | $3.00 |
| L4 | 1 | 24 GB | $0.80 |
| L40S | 1 | 48 GB | $1.80 |
| A100 | 1 | 80 GB | $2.50 |
| A100 | 4 | 320 GB | $10.00 |
| A100 | 8 | 640 GB | $20.00 |
| H100 | 1 | 80 GB | $4.50 |
| H100 | 4 | 320 GB | $18.00 |
| H100 | 8 | 640 GB | $36.00 |
| H200 | 1 | 141 GB | $5.00 |
| B200 | 1 | 179 GB | $9.25 |
| B200 | 8 | 1.432 GB | $74.00 |
| RTX PRO 6000 | 1 | 96 GB | $2.75 |
Las opciones de GCP y Azure también están disponibles con precios ligeramente diferentes por nivel de hardware. La tabla completa que incluye instancias de CPU y aceleradores (Inferentia2, TPU v5e) está en la página de precios de Inference Endpoints.
Ejemplos concretos de costos
Endpoint CPU siempre activo - AWS 2-vCPU, 1 réplica:
- $0.067/hr × 730 horas = ~$49/mes
Endpoint GPU con escalado automático - AWS T4 x1, mín. 1 réplica, máx. 3, con picos de 15 minutos cada hora:
- $0.50 × (730 hrs × 1 + 182.5 hrs × 2 réplicas adicionales) = $547.50/mes
La fórmula de facturación: tarifa horaria × ((horas × réplicas mínimas) + (horas de escalado × réplicas adicionales))
Este modelo siempre activo es la fuente más común de cargos inesperados. Una pregunta en los foros de Hugging Face que atrajo más de 3.700 visitas resume bien la confusión:
"Estoy un poco confundido con el modelo de precios. Supongamos que despliego un modelo en una máquina CPU Basic ($0.06/hora). ¿Pago mientras el modelo está desplegado o pago solo por el tiempo de cómputo (p. ej., hago 2 solicitudes y cada una tarda 10 segundos, ¿pago solo los 20 segundos)?"
La respuesta es: pagas mientras el modelo esté desplegado, no por solicitud. Esa distinción sorprende a mucha gente.
Precios de almacenamiento
El almacenamiento en el Hub es su propia capa de facturación, cobrada por TB al mes. Las tarifas varían según el volumen y si los repositorios son públicos o privados:
| Volumen | Tarifa pública | Tarifa privada |
|---|---|---|
| Base | $12/TB/mes | $18/TB/mes |
| 50 TB+ | $10/TB/mes | $16/TB/mes |
| 200 TB+ | $9/TB/mes | $14/TB/mes |
| 500 TB+ | $8/TB/mes | $12/TB/mes |
La transferencia de datos y la entrega CDN están incluidas sin cargo adicional, lo que compara favorablemente con AWS S3 a ~$23/TB/mes con tarifas de transferencia de datos separadas.
Cada plan de pago incluye almacenamiento base significativo antes de que se apliquen los cargos por TB:
- PRO: hasta 10 TB público + 1 TB privado
- Team: 12 TB público base + 1 TB/asiento público + 1 TB/asiento privado
- Enterprise: 200 TB público base + 1 TB/asiento, escalando hasta 1 PB para contratos grandes
Complementos de almacenamiento público para planes de pago: 1 TB a $12/mes, 5 TB a $60/mes, 10 TB a $120/mes, 50 TB a $500/mes. El almacenamiento privado más allá de los límites incluidos es de pago por uso a partir de $18/TB/mes.
Los imprevistos de facturación que vale la pena conocer
No existen límites de gasto incorporados para Spaces ni para Inference Endpoints. El gasto en Inference Providers se puede limitar a nivel de organización en los planes Team y Enterprise, pero los Spaces con GPU y los endpoints dedicados no tienen interruptor automático. Un hilo del foro de abril de 2025 describió un cargo que saltó de $78.22 a $519.24 de la noche a la mañana:
"Hay un aumento repentino de ~1.100 horas en menos de 24 horas, lo que es técnicamente imposible. Incluso con uso continuo de GPU: el máximo posible es de 24 horas/día por instancia. Este pico implicaría decenas de instancias en paralelo, lo cual no es el caso."
Ya sea un error de facturación o un proceso descontrolado, el usuario no tenía forma de limitar la exposición de antemano. La lección: establece políticas de pausa manual para los Spaces con GPU y mantén el número mínimo de réplicas de los Inference Endpoints lo más bajo posible.
Las tarifas horarias y mensuales no siempre concuerdan exactamente. Un hilo de octubre de 2024 detectó una inconsistencia real: el nivel de almacenamiento persistente Medium aparece listado a $0.03/hr, lo que implica ~$21.60/mes, pero el cargo mensual real es de $25. Vale la pena verificar los totales mensuales en lugar de extrapolar a partir de las cifras horarias.
Los Inference Endpoints facturan siempre activos. Si el número mínimo de réplicas de tu endpoint es 1, estás pagando la tarifa del hardware 24/7 independientemente del volumen de tráfico. Esto sorprende a los equipos acostumbrados a modelos de precios sin servidor donde el tiempo inactivo no cuesta nada.
Comparación de costos de cómputo
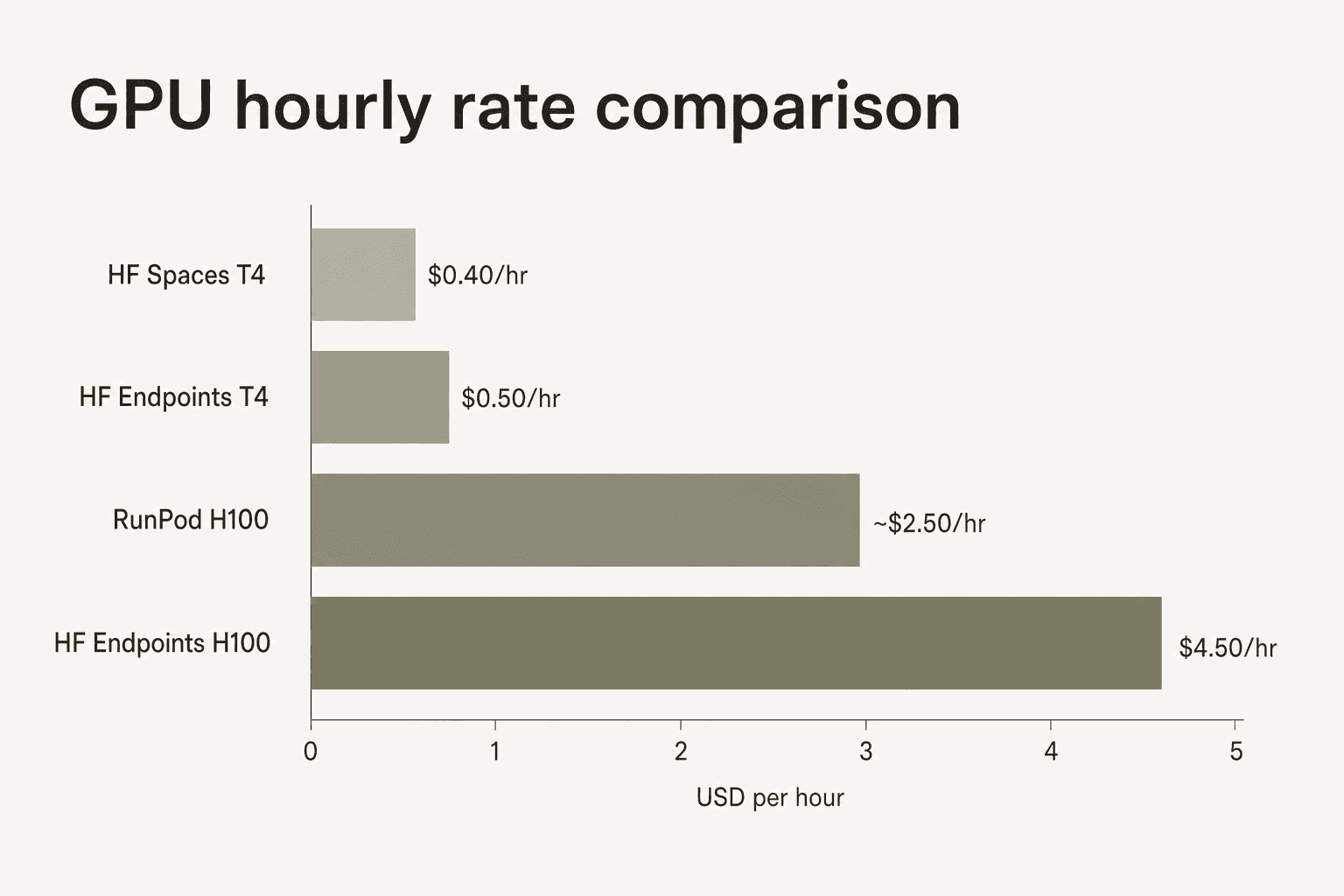
Los Inference Endpoints de Hugging Face tienen una prima de conveniencia sobre los proveedores de GPU básicos. Una H100 en los Endpoints Dedicados de HF cuesta entre $4.50 y $10/hr según la región cloud; el mismo hardware en RunPod cuesta entre $2 y $3/hr. Los datos de reseñas de la comunidad señalan sistemáticamente esta diferencia —"los costos de cómputo de GPU se acumulan rápidamente" aparece como una queja recurrente— mientras también señalan que la integración con el Hub, la disponibilidad de modelos y la ausencia de gestión de infraestructura justifican la prima para los equipos que quieren permanecer dentro del ecosistema de HF.
Para cargas de trabajo vinculadas a CPU (embeddings, clasificación, modelos más pequeños), el cálculo es diferente: las tarifas de HF son competitivas y la infraestructura gestionada ahorra tiempo de ingeniería. La prima aparece con más fuerza en el extremo de alta GPU, donde Together AI y proveedores similares ofrecen mejor economía de cómputo bruto para equipos que no necesitan el registro de modelos y las herramientas de despliegue del Hub.
El Inference Playground es la forma más sencilla de probar modelos antes de comprometerse con cualquier nivel de cómputo; te permite probar con proveedores a través de la interfaz del navegador sin necesidad de configuración de facturación.
Qué plan y producto se adapta a tu situación
Gratuito - exploración de modelos, experimentos ocasionales, aprendizaje del ecosistema. El registro de modelos y el acceso ZeroGPU lo hacen genuinamente útil sin gastar nada.
PRO a $9/mes - desarrollo individual activo donde necesitas el aumento de cuota ZeroGPU, más almacenamiento privado o Spaces Dev Mode. Difícil de objetar a ese precio para cualquiera que realice trabajo de ML regularmente.
Team a $20/usuario/mes - equipos reales que colaboran en modelos o conjuntos de datos. Los controles de facturación a nivel de organización para Inference Providers y el almacenamiento agrupado empiezan a importar a esta escala.
Enterprise a $50+/usuario/mes - SSO, registros de auditoría o requisitos de cumplimiento. No pagues por Enterprise porque tu equipo es grande; págalo cuando realmente necesites el conjunto de gobernanza.
Inference Providers - acceso sin servidor conveniente a modelos de terceros a las tarifas del proveedor, sin infraestructura que gestionar. Los créditos de $2/mes no llegarán lejos en producción, pero la API unificada es excelente para evaluación y prototipado.
Inference Endpoints - hardware dedicado con latencia predecible y escalado automático. Presupuesta para facturación siempre activa, establece réplicas mínimas de forma conservadora e implementa políticas de pausa manual. No es la opción predeterminada adecuada para despliegues con poco tráfico o experimentales.
Si estás comparando el ecosistema más amplio, alternativas a Hugging Face cubre otras siete plataformas que vale la pena evaluar para el despliegue de modelos.
Prueba eesel
Si estás considerando Hugging Face para IA en atención al cliente —automatizar respuestas a tickets, construir un agente de helpdesk, desviar consultas repetitivas— eesel ofrece un camino más directo. En lugar de gestionar infraestructura de alojamiento de modelos en cinco superficies de facturación, eesel despliega agentes de IA completamente autónomos directamente dentro de Zendesk, Slack, Freshdesk y más de 100 otras herramientas. Briefeas al agente en lenguaje natural, resuelve tickets de principio a fin, y los precios escalan con el uso a $0.40 por tarea en lugar de horas de cómputo. Sin gestión de GPU, sin picos de facturación, sin Inference Endpoints que configurar.
Empieza con $50 en créditos gratuitos; no se requiere tarjeta →
Preguntas Frecuentes
¿Cuánto cuesta Hugging Face?
¿Hugging Face es gratis?
¿Qué incluye el plan PRO de Hugging Face?
¿Cuánto cuesta Hugging Face Enterprise?
¿Cómo funciona la facturación de Inference Endpoints en Hugging Face?

Article by
Rama Adi Nugraha
Rama is a software engineer at eesel AI with two years of experience writing about B2B SaaS, AI tools, and customer support technology. Based in Bali, Indonesia, he brings a developer's perspective to product comparisons — cutting through marketing copy to what the integrations and APIs actually do.