
¿Qué es exactamente Gemma 4?
Construyo los agentes de IA en eesel, y he pasado los últimos años viendo cómo los modelos abiertos han pasado de "divertidos para experimentar" a "suficientemente buenos para poner frente a un cliente de pago". Ejecutamos agentes en colas de soporte en vivo todos los días; un cliente, Smava, procesa más de 100.000 tickets en alemán al mes a través de un agente automatizado. Así que cuando Google lanza un nuevo modelo abierto, lo leo desde una única perspectiva: ¿Realmente podrías confiar en esto para responder a un cliente sin supervisión humana?
Gemma 4 es la respuesta más interesante a esa pregunta que he visto de un modelo abierto.
En términos simples, Gemma es la línea de modelos abiertos de Google DeepMind: los primos más pequeños y descargables de los modelos Gemini cerrados. Gemma 4 está "construido a partir de la misma investigación y tecnología de clase mundial que Gemini 3 para maximizar la inteligencia por parámetro", según el post de lanzamiento de Google. La palabra clave es open-weight: Google publica los archivos reales del modelo, para que puedas ejecutarlos en tu propio portátil, servidor o teléfono sin que ninguna llamada API salga de tu red.
También es multimodal. Cada modelo maneja entrada de texto e imagen, los más pequeños añaden audio nativo, y la ficha del modelo indica un corte de entrenamiento de enero de 2025 con soporte para más de 140 idiomas. Si has leído nuestro artículo sobre RAG versus LLMs, Gemma 4 es la mitad "LLM" de esa imagen: el motor de razonamiento que apuntarías a tu propio conocimiento.
Los cinco tamaños, y cuál es para ti
Gemma 4 no es un modelo, son cinco, ordenados según dónde están destinados a ejecutarse. Esta es la parte que vale la pena entender antes que cualquier otra cosa, porque elegir el tamaño equivocado es el error más común que veo cometer a la gente.
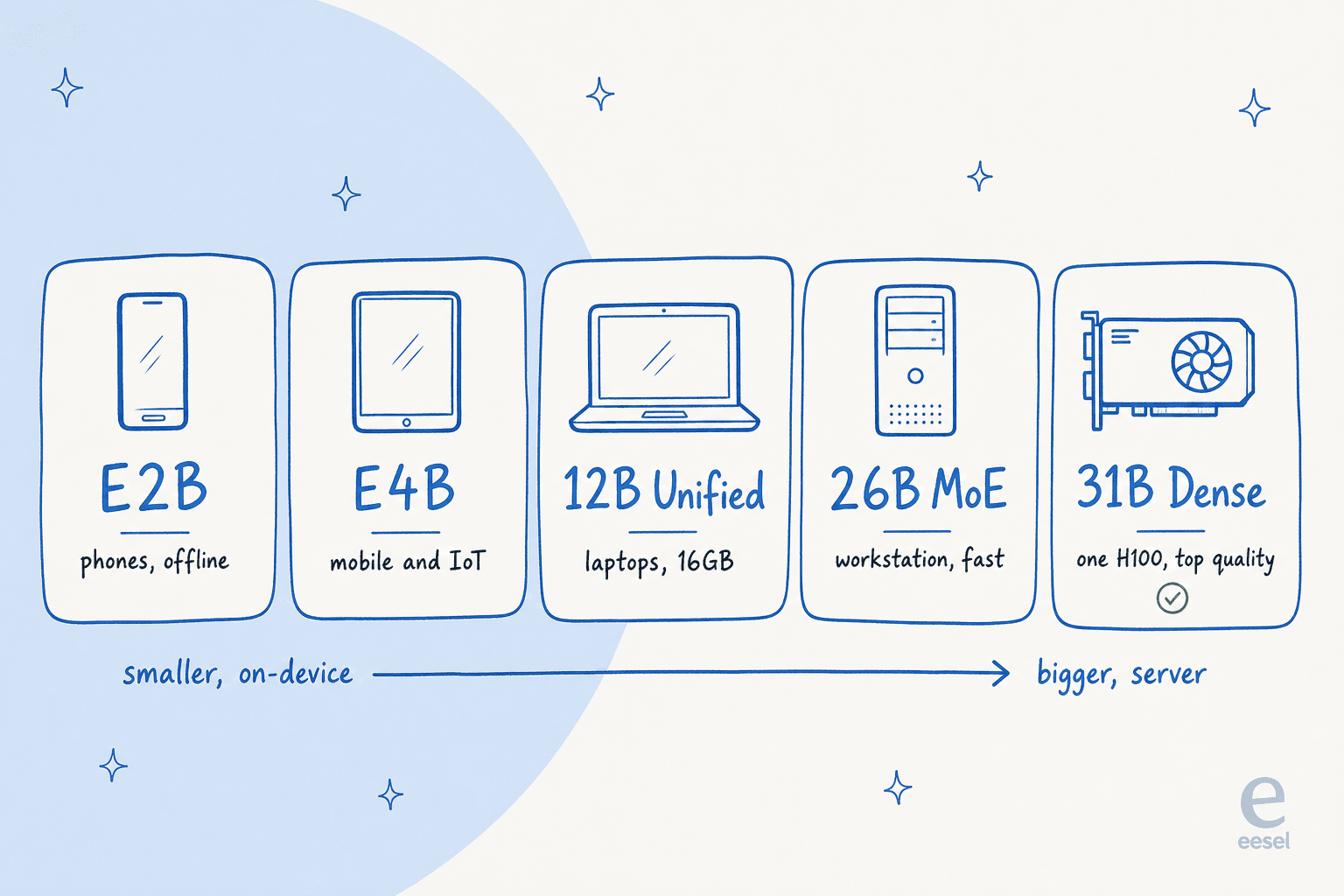
Aquí está la alineación, con las especificaciones extraídas directamente de la ficha del modelo:
| Modelo | Parámetros efectivos | Contexto | Modalidades | Se ejecuta en |
|---|---|---|---|---|
| E2B | 2,3B (5,1B con embeddings) | 128K | Texto, imagen, audio | Teléfonos, Raspberry Pi, edge |
| E4B | 4,5B (8B con embeddings) | 128K | Texto, imagen, audio | Teléfonos de gama alta, IoT |
| 12B Unified | 11,95B | 256K | Texto, imagen, audio | Portátiles (~16 GB) |
| 26B A4B (MoE) | 25,2B total, 3,8B activos | 256K | Texto, imagen | Estación de trabajo, baja latencia |
| 31B Dense | 30,7B | 256K | Texto, imagen | Una H100 de 80 GB, máxima calidad |
La "E" en E2B y E4B significa parámetros efectivos. Esos modelos usan un truco llamado Per-Layer Embeddings para mantener pequeño su uso de memoria, lo que permite a un teléfono ejecutarlos sin conexión con latencia casi nula. Google los construyó con el equipo de Pixel más Qualcomm y MediaTek, por lo que están optimizados para silicon móvil real, no solo para una demo.
El Unified de 12B es el recién llegado, añadido el 3 de junio de 2026. Es la opción "lista para portátil" y el primer modelo de tamaño medio de Google con entrada de audio nativa. El Dense de 31B es el buque insignia de calidad pura y la base desde la que todos hacen fine-tuning.
El del medio, el 26B, es el más ingenioso del grupo. Merece su propia sección.
Cómo un modelo de 26B se mantiene al día con modelos 20 veces más grandes
El 26B es un modelo Mixture-of-Experts (MoE), y entenderlo es la mejor manera de comprender por qué Gemma 4 es importante.
Un modelo "denso" normal activa todos los parámetros para cada token que procesa. Un modelo MoE divide sus parámetros en muchos "expertos" pequeños y, para cada token, solo activa el puñado que realmente necesita. Así es su estructura:
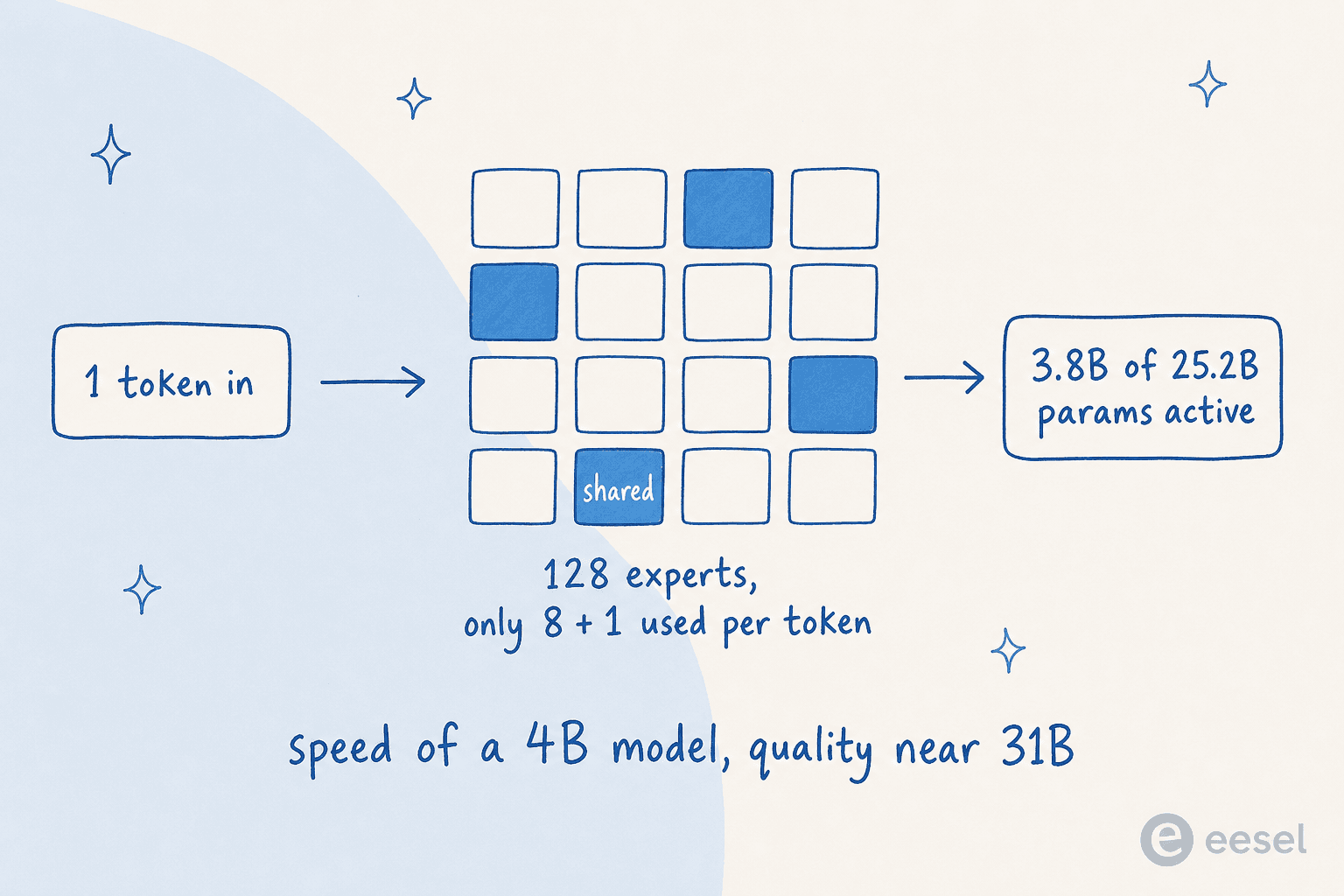
El 26B de Gemma 4 tiene 25,2B parámetros totales pero solo 3,8B activos por token, enrutando a través de 8 de sus 128 expertos más un experto compartido. El resultado práctico: se ejecuta aproximadamente tan rápido como un modelo denso de 4B, pero responde con una calidad más cercana al 31B. (Un aviso a tener en cuenta: los 25,2B parámetros aún deben cargarse en memoria para el enrutamiento, así que MoE ahorra cómputo, no RAM.)
¿Por qué importa esto? Porque rompe la vieja suposición de que "más inteligente" significa "más grande y más lento". Mira dónde aterrizan los modelos medianos de Gemma 4 en el propio gráfico de rendimiento versus tamaño de Google:
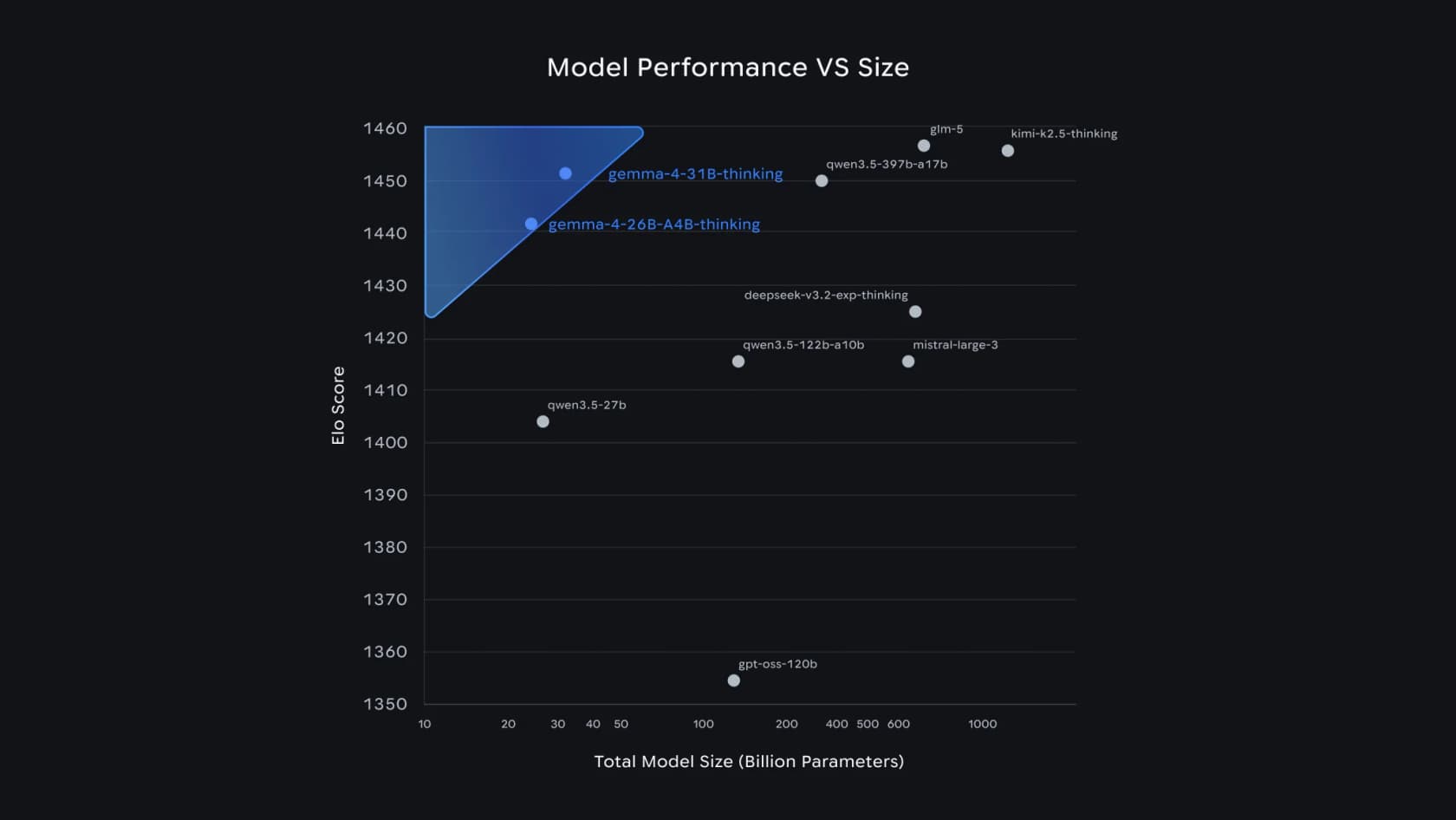
El 31B es el modelo abierto #3 en la clasificación de texto de Arena AI, y el 26B MoE ocupa el #6, que es como Google puede afirmar que Gemma 4 "supera a modelos 20 veces su tamaño". Para un equipo de soporte, la conclusión no es la posición en la clasificación, sino que esa calidad cabe en hardware que tú controlas.
Qué significa realmente "pesos abiertos" (y por qué cambió la licencia)
La gente usa "abierto" de forma imprecisa, así que seré preciso, porque aquí es donde Gemma 4 hizo su mayor movimiento.
Los modelos Gemma anteriores se distribuían bajo unos "Términos de Uso de Gemma" personalizados. Gemma 4 cambió a una licencia estándar Apache 2.0. En palabras de Google, es "comercialmente permisiva" y otorga "control completo sobre tus datos, infraestructura y modelos". El CEO de Hugging Face, Clément Delangue, calificó el movimiento de "un gran hito".
Esta es la diferencia que supone esa licencia en la práctica:
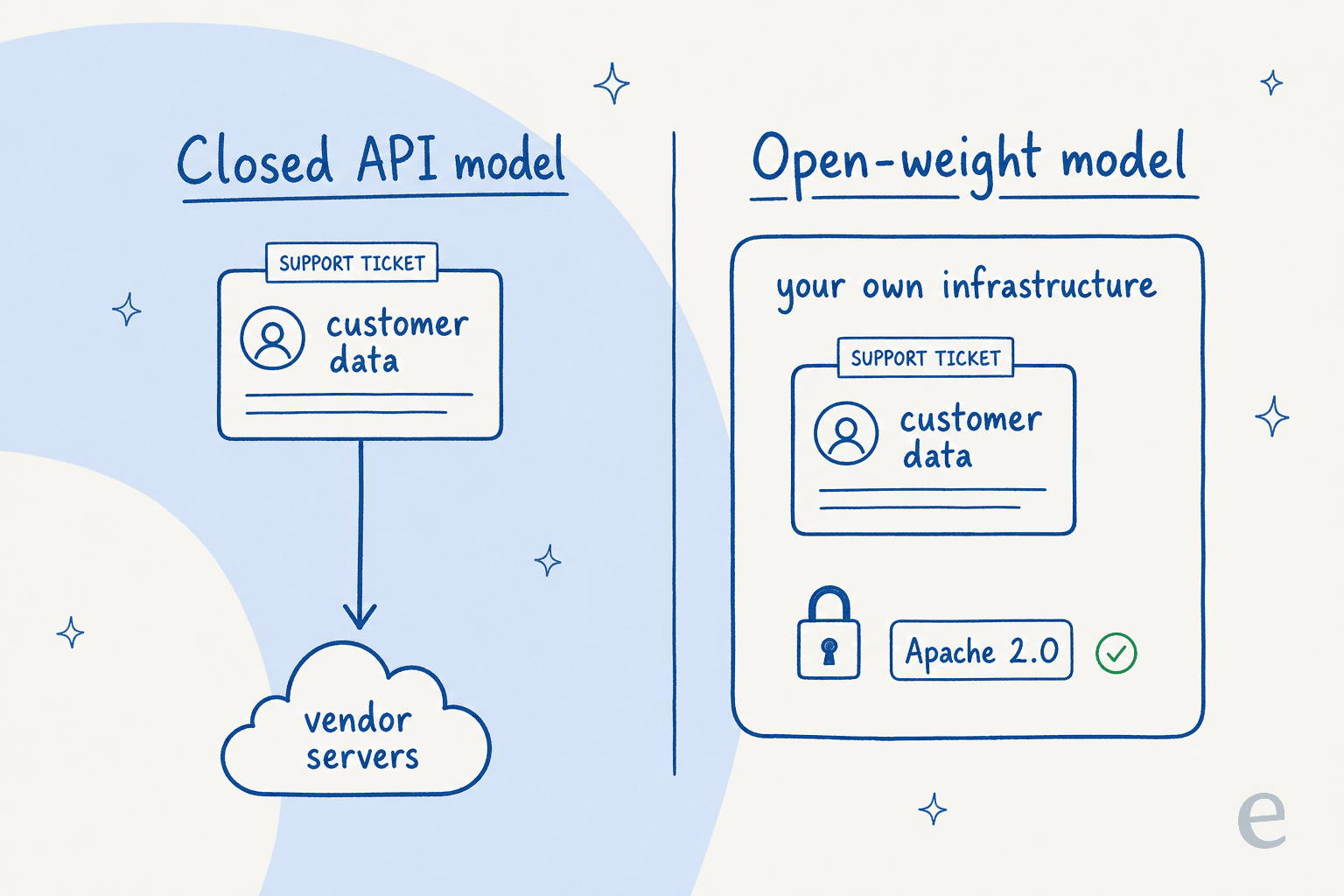
Con un modelo de API cerrado, cada mensaje de cliente que procesas se envía a los servidores del proveedor. Con un modelo de pesos abiertos bajo Apache 2.0, puedes ejecutar todo dentro de tu propia infraestructura, en las instalaciones o en tu propia nube, y los datos nunca salen. Para cualquiera en una industria regulada, ese control de residencia de datos es la única razón para preocuparse por los modelos abiertos. Es la misma razón por la que la gente recurre a sistemas de ticketing de código abierto y plataformas de chatbot de código abierto.
Para escalarlo, Google ofrece Gemma 4 en Vertex AI, Cloud Run y GKE, y funciona desde el primer día con las herramientas que ya usan los self-hosters, como Ollama, llama.cpp, vLLM y LM Studio.
Los benchmarks, y dónde brilla realmente Gemma 4
Ahora los números. Google publica una tabla completa de benchmarks comparando los modelos Gemma 4 con ajuste de instrucciones frente al Gemma 3 27B de la generación anterior:
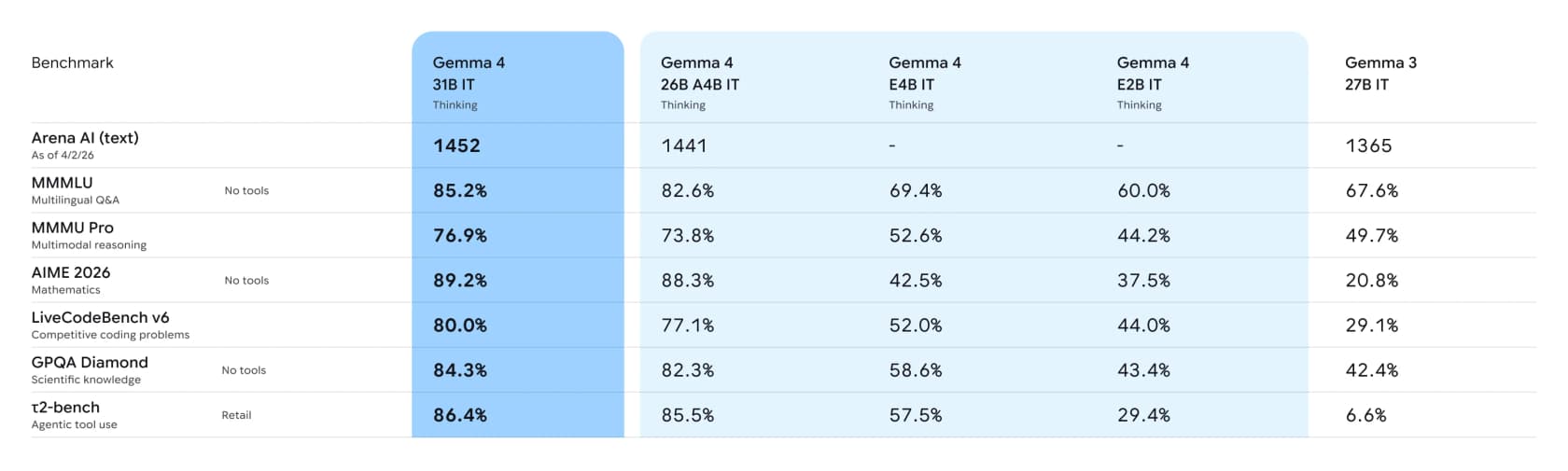
La línea que yo marcaría es el uso agéntico de herramientas. En el benchmark τ2-bench retail, que prueba si un modelo puede llamar herramientas para completar una tarea, el modelo de 31B obtiene un 86,4% frente al 6,6% de Gemma 3. Eso no es una mejora incremental, es un salto generacional, y es la capacidad que convierte un chatbot en algo que puede hacer trabajo real.
También se mantiene frente a los gigantes cerrados. En Arena Elo, el 31B con 1452 queda justo por detrás de modelos con 15–35 veces más parámetros:
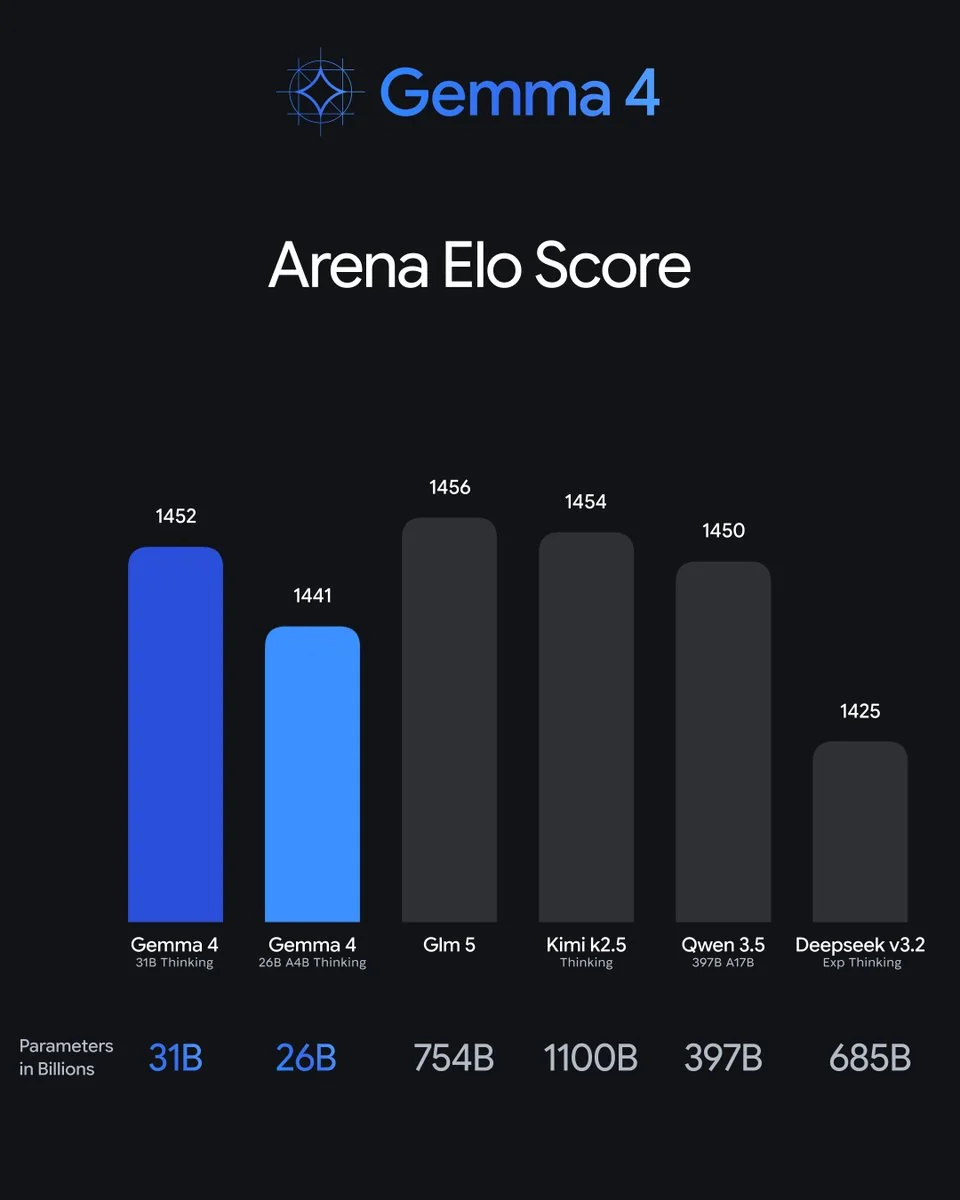
Arquitectónicamente, la nota interesante del análisis de Sebastian Raschka es que Gemma 4 está "prácticamente sin cambios" frente a Gemma 3 bajo el capó, por lo que el salto es "probablemente debido al conjunto de entrenamiento y la receta". En otras palabras, Google obtuvo este salto de mejores datos, no de una nueva arquitectura, lo cual es algo silenciosamente impresionante.
Cómo es ejecutarlo en la práctica
Los benchmarks son una cosa. ¿Qué dicen realmente las personas que ejecutan Gemma 4 todos los días? Lo busqué en las comunidades de modelos locales, porque ahí es donde viven las opiniones sin filtros.
El elogio es consistente: es rápido, ligero en memoria y no divaga.
"Rápido como el demonio en un M4Max, y maldita sea lo inteligente que es para su velocidad. No destruye tu carga de memoria. No razona durante horas (y se come todo el presupuesto de tokens en el razonamiento) como Qwen... Es perfecto para openclaw, hermes, claude code, etc. AMO este modelo para local. Es mi modelo preferido ahora." – u/styles01 en r/LocalLLaMA
El punto "no razona durante horas" aparece una y otra vez. Un self-hoster que ejecuta el 26B y el 31B para un caso de uso multimodal puso números reales, reportando aproximadamente 149 tokens/seg en el 31B y 88 en el 26B, y añadiendo que "los benchmarks realmente no capturan lo poco que divaga en comparación con los más grandes".
Pero aquí está la limitación honesta, y es la razón por la que no pondría Gemma 4 crudo en una cola en vivo sin supervisión:
"Estoy de acuerdo en que es mucho mejor en todo excepto en el coding. [...] Sin embargo, sufre mucho cuando los pesos o la caché kv son cualquier otra cuantización que no sea la nativa." – u/fragment_me en r/LocalLLM
Así que la lectura de la comunidad es esta: Gemma 4 es un excelente modelo de chat y seguimiento de instrucciones que rinde muy por encima de su peso, con dos advertencias: el coding y los flujos agénticos son sus áreas más débiles, y se degrada notablemente si se ejecuta con una cuantización diferente a la nativa. Bueno saberlo antes de elegirlo para un trabajo.
Lo que esto significa para el soporte al cliente
Aquí es donde se vuelve práctico para cualquiera que dirija un equipo de soporte. Un modelo abierto como Gemma 4 es un ingrediente fantástico. Por sí solo, no es un agente de soporte.
Un modelo crudo no sabe cuál es tu política de devoluciones, no puede ver tus tickets anteriores y no está conectado a tu helpdesk. Ponerlo frente a clientes sin supervisión produce exactamente el modo de fallo contra el que llevamos años trabajando: un bot que suena seguro pero da silenciosamente la respuesta equivocada. El modelo es el motor; el producto real es todo lo que lo rodea: el conocimiento, el enrutamiento seguro, la conexión con tus herramientas y la capacidad de probarlo antes de que salga al aire.
Esa brecha es la razón por la que existen plataformas como la nuestra. El movimiento de pesos abiertos te da control sobre la capa del modelo, pero la mayoría de los equipos de soporte no quieren convertirse también en un equipo de ML ops. La mejor respuesta para la mayoría de las personas es obtener los beneficios de control de datos y aprendizaje sin construir la infraestructura a mano, que es la línea que trazaría entre un modelo y una plataforma de atención al cliente con IA.
Prueba eesel para soporte con IA
Si leer sobre Gemma 4 te hizo pensar "quiero que la IA responda mis tickets, pero en mis términos", ese es exactamente el problema para el que fue creado eesel.
El agente de helpdesk de IA de eesel se conecta a las herramientas que ya usas, Zendesk, Freshdesk, Gorgias, Slack y más de 100 otras, y aprende de tus tickets e historial de ayuda desde el primer día, para que años de historial se conviertan en conocimiento inmediatamente. La parte que se mapea directamente a la pregunta "¿podrías confiar en él?" con la que abrí: puedes simular el agente contra miles de tus tickets históricos para ver exactamente cómo habría respondido, antes de que un solo cliente lo vea. Así es como Gridwise resolvió el 73% de las solicitudes de nivel 1 en su primer mes.

Es basado en uso, desde $0,40 por ticket sin cuotas por asiento, y puedes empezar con $50 de uso gratuito sin tarjeta de crédito. Sea cual sea el modelo bajo el capó, Gemma 4 o cualquier otro, lo que realmente quieres es un agente en el que puedas confiar en tu cola. Prueba eesel y ve cómo gestiona la tuya.
Preguntas Frecuentes
¿Qué es Gemma 4?
¿Es Gemma 4 gratuito?
¿Cuáles son los tamaños de los modelos Gemma 4?
¿Puede Gemma 4 ejecutarse en un portátil o teléfono?
¿Es Gemma 4 bueno para la atención al cliente?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.








