Wie erkenne ich, ob mein KI-Support funktioniert?
Alicia Kirana Utomo
Katelin Teen
Zuletzt bearbeitet June 17, 2026

Zusammenfassung
„Funktioniert mein KI-Support?" lässt sich auf fünf Zahlen herunterbrechen, die gemeinsam betrachtet werden müssen, nicht einzeln: Lösungsrate, Deflection-Rate, Antwortqualität, Eskalationsgenauigkeit und Fehlerrate bei Fakten. Wenn Lösungs- und Deflection-Rate steigen, während Qualität und CSAT stabil bleiben, funktioniert es. Wenn das Volumen steigt, aber die Zufriedenheit sinkt – oder der Bot selbstsicher antwortet, ohne irgendetwas zu zitieren –, dann funktioniert es nicht, egal wie aktiv er aussieht.
Die Falle besteht darin, einen KI-Agenten nach Aktivität zu beurteilen („Er hat auf 4.000 Tickets geantwortet!") statt nach Ergebnissen. Ein Bot kann enorm beschäftigt und still falsch liegen. Die Lösung ist, die nachfolgend beschriebenen Kennzahlen zu beobachten, grüne und rote Signale zu erkennen und idealerweise eine Simulation mit Ihren echten vergangenen Tickets durchzuführen, bevor Sie ihm live vertrauen.
Ich habe die letzten drei-plus Jahre damit verbracht, KI-Agenten auf Live-Support-Warteschlangen bei eesel einzusetzen – das ist die Scorecard, die ich tatsächlich verwenden würde.
Warum „Funktioniert es?" schwieriger ist als es aussieht
Hier ist etwas, das die meisten Dashboards Ihnen nicht sagen. Das beängstigende Versagensmuster im KI-Support ist nicht, dass der Bot still wird – es ist, dass der Bot großartig klingt, während er falsch liegt.
Ich habe beobachtet, wie ein selbstsicher klingender Agent einem Kunden sagte: „Ja, wir unterstützen Ihr Automodell" für Marken, die überhaupt nicht in der Wissensdatenbank standen, einfach weil jemand „wir unterstützen alle Modelle" in einem Hilfedokument geschrieben hatte. Der Bot war nicht kaputt. Er tat genau das, was man ihm gesagt hatte, und sah dabei vollkommen flüssig aus. Das ist der Grund, warum wir jetzt jeden Rollout zunächst gegen historische Tickets simulieren, anstatt einen Schalter umzulegen und zu hoffen.
Bevor wir zu den Zahlen kommen: „Funktionieren" bedeutet, dass die KI die richtigen Tickets korrekt löst, den Rest sauber weiterleitet und dazwischen nichts erfindet. Aktivitätszahlen sind Eitelkeit. Ergebnisse sind die Wahrheit. Wenn Sie nur eine Idee aus diesem Beitrag mitnehmen, dann diese.
Die fünf Zahlen, die wirklich Auskunft geben
Wenn Teams mich fragen, wie sie ihren KI-Agenten ablesen sollen, verweise ich sie auf dieselben fünf Customer-Support-Kennzahlen. Zusammen betrachtet, erfassen sie fast jeden Versagensmodus.
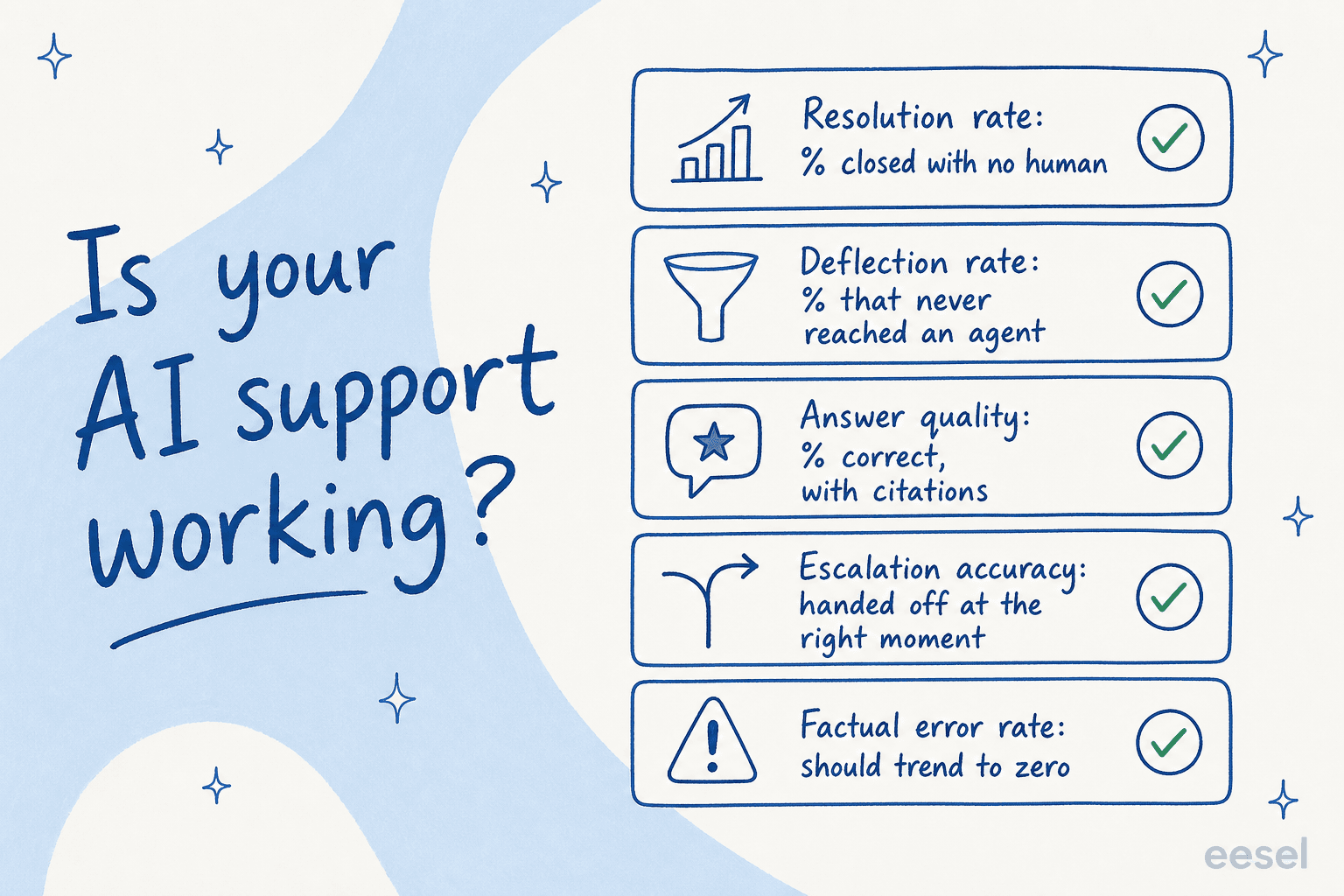
1. Lösungsrate
Die wichtigste Kennzahl: Wie viel Prozent der Tickets hat die KI vollständig ohne menschliches Eingreifen abgeschlossen? Diese ist direkt mit den Kosten verknüpft, denn jedes gelöste Ticket ist eines, das ein Agent nicht öffnen musste.
Was ist „gut"? Das hängt vollständig von Ihrem Ticket-Mix ab, aber Tier-1 ist der Bereich, in dem KI zuerst ihren Wert beweist. Eine Gig-Economy-Fahrer-Analyse-App auf Zendesk teilte uns in einer öffentlichen G2-Bewertung mit, dass eesel 73 % ihrer Tier-1-Anfragen im ersten Monat löste, mit Ergebnissen innerhalb eines 7-Tage-Tests. Am anderen Ende startete ein interner IT-Helpdesk auf Jira bei 15 % Deflection und setzte sich ein Ziel von 55 %. Beide sind „funktionierend." Der Punkt ist nicht ein universeller Benchmark, sondern der Trend: Steigt die Lösungsrate, wenn Sie den Agenten mit mehr Wissen versorgen?
2. Deflection-Rate
Deflection und Lösung werden synonym verwendet – und das sollten sie nicht. Lösung ist ein Ticket, das ohne einen Menschen geschlossen wurde. Deflection ist ein Kunde, der seine Antwort bekommen hat und nie ein Ticket geöffnet hat – meist über ein Chat-Widget oder Self-Service, bevor das Gespräch überhaupt zu einem Support-Fall wurde.
Es lohnt sich, dies separat zu verfolgen, denn eine hohe Deflection-Rate ist das, was Ihre Warteschlange still schrumpft. Wenn Sie die genaue Definition und die Formel möchten, haben wir aufgeschrieben, was Deflection-Rate ist und wie man sie verbessert, sowie einen separaten Artikel über das Messen von KI-Deflection gegenüber menschlicher Deflection, damit Sie keine Doppelzählung vornehmen.
3. Antwortqualität
Volumen ohne Qualität ist die Falle. Die eigentliche Frage hinter der Lösung lautet also: Als die KI antwortete, hatte sie recht, und hat sie ihre Arbeit gezeigt?
Das ist messbar. In einer einwöchigen Stichprobe über 581 Chats haben wir die Chat-Qualität mit 96 % bewertet. In einer anderen Stichprobe von 434 Chats war die Aufschlüsselung 86 % gut, 7 % teilweise, 6 % abgeleitet und 1 % vollständig gescheitert, und bei echten webhook-ausgelösten Tickets (dem schwierigeren Test) waren es 79 % gut. Die genaue Methode ist weniger wichtig als das Vorhandensein einer: Bewerten Sie eine Stichprobe von Antworten auf Korrektheit und ob sie eine Quellenangabe enthielten. Eine Antwort ohne angehängte Quelle ist eine Antwort, der Sie nicht vertrauen können. Ein Legal-Tech-Gründer, mit dem wir zusammenarbeiten, brachte es gut auf den Punkt: Mit eesel konnten sie „genaue Leitplanken für die Quellenangabe festlegen, und es liefert immer transparente Zitate" – in ihrer Branche ist das der Unterschied zwischen hilfreich und einem Rechtsstreit.
4. Eskalationsgenauigkeit
Ein guter KI-Agent weiß, was er nicht weiß. Daher ist die Eskalationsgenauigkeit wirklich ein Maß für das Urteilsvermögen: Wenn die KI unsicher war, hat sie an einen Menschen weitergeleitet, anstatt zu raten?
Das ist die am meisten unterschätzte Kennzahl auf der Liste. Sie möchten einen Agenten, der selbstsicher löst und ehrlich eskaliert – nicht einen, der alles beantwortet. Ein Support-Lead einer SMS-Plattform brachte das Ideal in einer G2-Bewertung auf den Punkt: Die KI „antwortet selbstsicher, aber nicht zu selbstsicher." Dieser zweite Teil ist das eigentliche Spiel. Verfolgen Sie Ihre Eskalationsrate und, noch wichtiger, ob Eskalationen zum richtigen Zeitpunkt erfolgen.
5. Fehlerrate bei Fakten
Schließlich die Kennzahl, die gegen null tendieren sollte: Wie oft behauptet die KI etwas Unwahres. Das ist getrennt von „teilweisen" Antworten. Ein faktischer Fehler ist, wenn der Bot eine falsche Tatsache als sicher darstellt.
In einem Test mit echtem Zendesk-Traffic eines deutschen Schmuckhändlers (rund 1.000 Tickets pro Monat) maßen wir 93 % Triage-Genauigkeit und 100 % Spam-Erkennung ohne falsche Positive, aber auch eine 7 % Fehlerrate bei Fakten, die uns genau zeigte, wo die Wissensdatenbank Lücken hatte. Diese 7 % waren kein Grund, den Rollout abzubrechen. Es war eine Karte. Jeder faktische Fehler zeigt auf ein fehlendes oder widersprüchliches Dokument, das normalerweise behoben werden kann – und das ist das Kernthema unseres Leitfadens zur Vermeidung von KI-Halluzinationen im Support.
Die grünen Signale (und die roten Signale)
Zahlen zeigen Ihnen den Trend. Aber es gibt qualitative Signale, die Sie an einem einzigen Nachmittag beim Durchblättern von Transkripten ablesen können, und die sind oft schneller als ein Monat Daten zu warten.
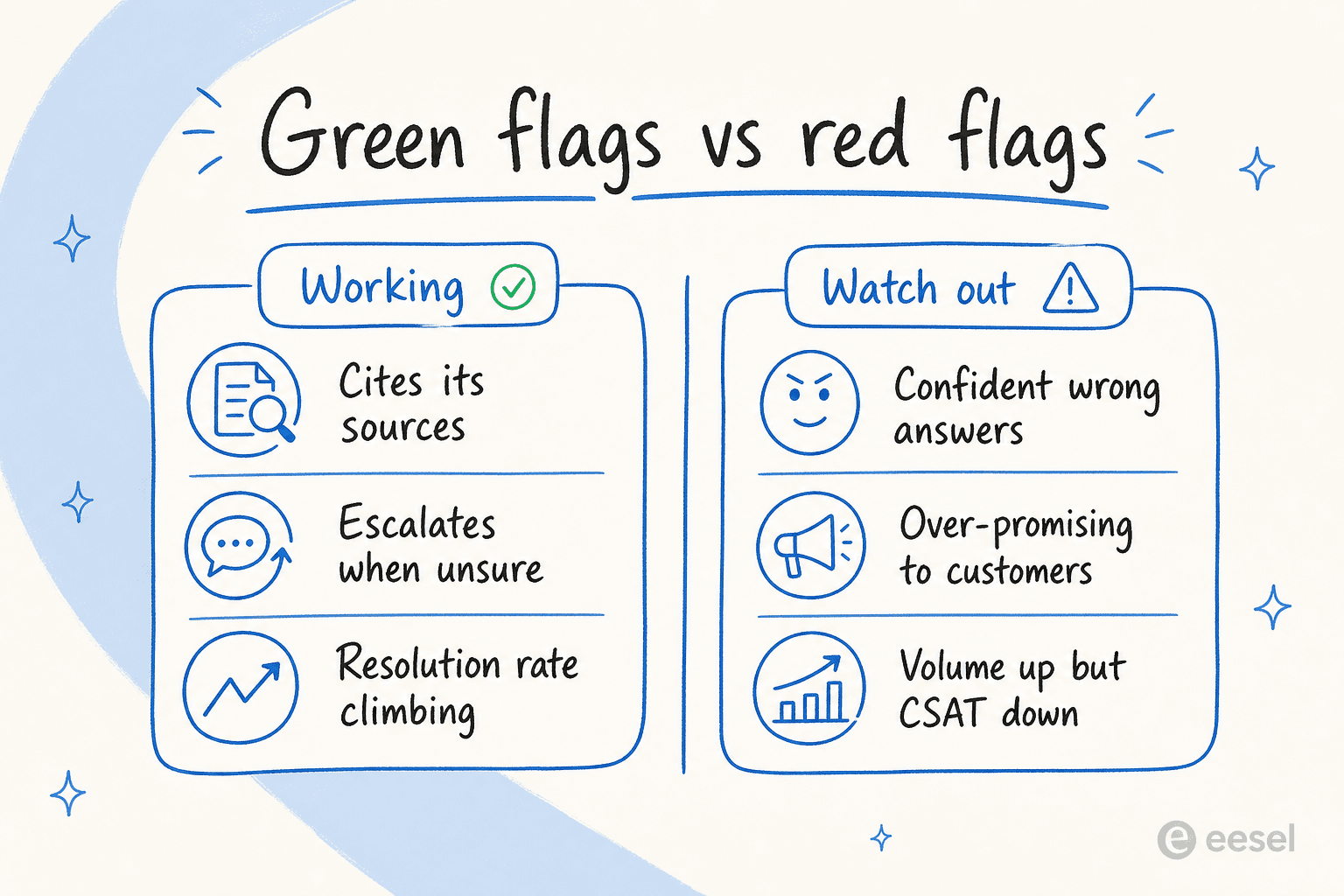
Die grünen Signale sind die einfachen. Die KI zitiert bei jeder Antwort ihre Quellen. Sie eskaliert, wenn sie tatsächlich unsicher ist, anstatt zu bluffen. Ihre Lösungsrate steigt Woche für Woche, nicht stagniert. Und, das einfachste Zeichen von allen: Ihre Agenten hören auf, sich über sich wiederholende Tickets zu beklagen.
Die roten Signale sind die, auf die ich Ihre Aufmerksamkeit lenken würde, denn sie verstecken sich hinter gut aussehenden Dashboards:
- Selbstsichere falsche Antworten. Das Automodell-Beispiel von vorhin. Der Bot ist flüssig, sicher und falsch. Das ist das schädlichste Muster überhaupt, weil Kunden es glauben.
- Überversprechungen. Ich habe gesehen, wie Agenten Kunden auf eine Weise beruhigten, die das Unternehmen nicht einhalten kann. Ein Support-Manager machte uns gegenüber deutlich darauf aufmerksam, der KI zu sagen: „Hör auf, Kunden zu sagen, dass wir uns darum kümmern werden. Du weißt das nicht," und „Hör auf, Kunden Dinge zu versprechen, die wir nicht tun können." Wenn Ihr Bot Verpflichtungen zu Lieferterminen oder Ergebnissen macht, ist das ein Kontrollproblem, kein Wissensproblem.
- Volumen steigt, CSAT sinkt. Der Agent bearbeitet mehr, und die Kunden sind weniger zufrieden. Diese Divergenz ist das klarste Zeichen, dass „beschäftigt" und „funktionierend" auseinandergegangen sind.
- Keine Quellenangaben. Wenn Sie nicht sehen können, woher eine Antwort stammt, kann es der Kunde auch nicht – und Sie auch nicht, wenn Sie später eine Prüfung vornehmen.
Das meiste lässt sich auf Wissenslücken oder fehlende Leitplanken zurückführen, was gute Nachrichten sind, denn beides ist behebbar, ohne irgendetwas auseinanderzureißen. Der Beitrag zu häufigen KI-Chatbot-Problemen geht tiefer auf die üblichen Ursachen ein.
Wo Sie tatsächlich nachschauen
All das setzt voraus, dass Sie sehen können, was Ihr KI-Agent tut. Wenn Ihr Tool Ihnen nur eine Gesamtzahl zeigt, ist das das erste, was Sie beheben müssen – denn Sie können nicht verwalten, was Sie nicht lesen können.
Die zwei Ansichten, die ich am häufigsten prüfe, sind das Berichte-Dashboard und das rohe Aktivitätsprotokoll. Die Berichteansicht zeigt den Trend: Aufgabenvolumen im Zeitverlauf, wie Aufgaben ausgelöst wurden (Chat, E-Mail, interne Notiz) und wie viele KI-Aktionen genehmigt, abgelehnt wurden oder noch auf eine menschliche Entscheidung warten. Dieses Verhältnis von Genehmigung zu Ablehnung ist ein schneller Stellvertreter für Vertrauen.

Das Aktivitätsprotokoll zeigt die tatsächliche Arbeit. Jedes Gespräch, seinen Kanal, das verknüpfte Ticket und ob es als gelöst oder ausstehend endete. Hier gehen Sie hin, um Antwortqualität stichprobenartig zu prüfen und die selbstsicheren-falschen Fälle zu erkennen, die die aggregierten Zahlen glätten. Ich würde mindestens zehn davon pro Woche überfliegen.

Wenn Ihr Helpdesk bereits CSAT-Umfragen bei abgeschlossenen Gesprächen durchführt, verknüpfen Sie diese Scores speziell mit KI-bearbeiteten Tickets. Dieser eine Schnitt – CSAT bei KI-gelösten Tickets gegenüber menschlich-gelösten – klärt die meisten „Ist es eigentlich gut?"-Debatten schneller als alles andere.
Warten Sie nicht, bis es live ist
Hier ist der Teil, den die meisten Teams überspringen – und der, auf den ich am stärksten drängen würde: Sie müssen nicht herausfinden, ob Ihre KI funktioniert, indem Sie sie an echten Kunden testen.
Der Fehler ist, den Go-Live als Ein/Aus-Schalter zu behandeln. Das bessere Modell ist eine Rampe. Sie stufen die KI durch Phasen der Autonomie hoch, wenn die Zahlen es rechtfertigen, nicht vorher.
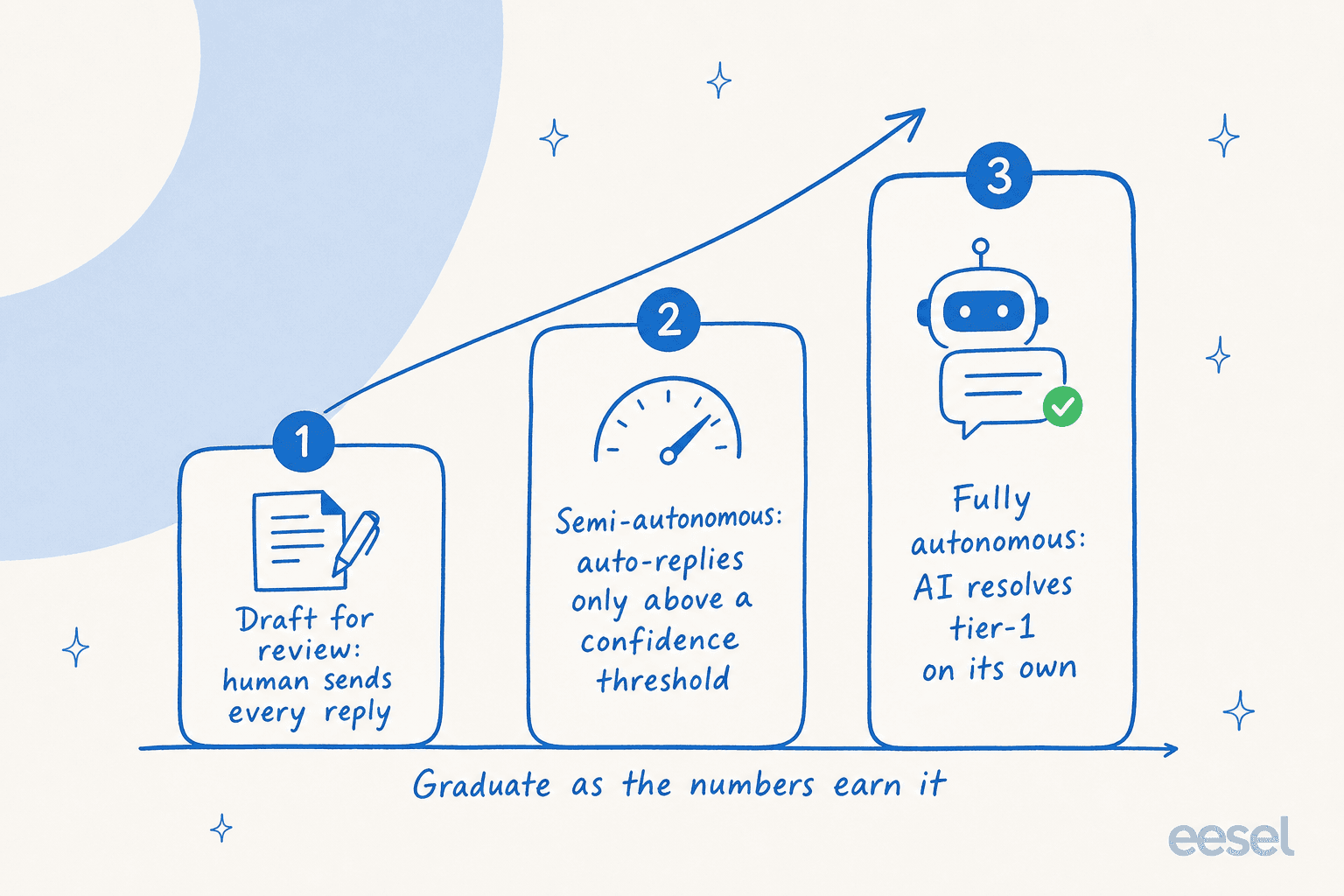
Sie beginnen im Entwurfsmodus, in dem die KI Antworten schreibt, aber ein Mensch jede sendet – so bewerten Sie Qualität ohne jegliches Kundenrisiko. Wenn sich die Antworten bewähren, wechseln Sie zu semi-autonom und lassen die KI nur über einem Vertrauensschwellenwert automatisch antworten, während der Rest an eine Person weitergeleitet wird. Sobald die Zahlen halten, lassen Sie sie vollständig autonom bei den Tier-1-Fällen laufen, die sie verdient hat.
Noch vor dem Entwurfsmodus können Sie eine Simulation über Tausende Ihrer echten vergangenen Tickets durchführen, um zu sehen, wie die KI jeden einzelnen beantwortet hätte – mit einer vorhergesagten Lösungsrate –, bevor eine einzige Live-Antwort ausgeht. Dieser deutsche Schmuckhändler-Test, den ich erwähnte, führte eine 100-Ticket-Kreuzvalidierung genau auf diese Weise durch. Erst zu simulieren ist, wie Sie die Frage „Funktioniert es?" beantworten, bevor Sie einen einzigen Kunden riskiert haben. Es ist auch ehrlich gesagt der Teil, den ich mir von mehr Teams wünsche, denn er verwandelt einen Vertrauenssprung in eine Messung.
Ein fairer Vorbehalt, da ich daran arbeite: eesel ist tief in Helpdesks wie Zendesk, Freshdesk und Help Scout integriert, daher bin ich kein neutraler Beobachter der Kategorie. Aber der Rampen-und-Simulieren-Ansatz gilt unabhängig davon, welches Tool Sie verwenden. Wenn Ihr KI-Anbieter Ihnen keinen Trockenlauf gegen Ihre eigenen Tickets zeigen kann, ist das selbst ein gelbes Signal, das Sie ansprechen sollten.
eesel ausprobieren
Wenn Sie „Funktioniert mein KI-Support?" tatsächlich mit Zahlen statt mit Bauchgefühl beantworten möchten, ist das das Problem, das eesel zu lösen ist. Sie verbinden Ihren Helpdesk und Ihre Wissensquellen, briefen den Agenten in klarer Sprache und führen eine Simulation Ihrer vergangenen Tickets durch, um eine vorhergesagte Lösungsrate zu erhalten – bevor Sie live gehen –, dann steigen Sie vom Entwurfsmodus auf Autonomie mit den Berichten um, die jeden Schritt unterstützen.

Es läuft auf nutzungsbasierter Preisgestaltung ohne Sitzplatzgebühren, und es gibt eine kostenlose Stufe, um es gegen Ihre eigene Warteschlange zu testen. Sie können sehen, wie andere Teams ihre Rollouts gemessen haben, auf der Kundenseite, oder lesen Sie unseren praktischen Leitfaden zu KI im Kundensupport für das vollständige Playbook. Probieren Sie eesel aus und finden Sie heraus, wie Ihre echte Lösungsrate wäre.
Häufig gestellte Fragen
Wie erkenne ich, ob mein KI-Support funktioniert?
Was ist eine gute Lösungsrate für einen KI-Support-Agenten?
Wie unterscheidet sich KI-Deflection von KI-Lösung?
Was sind die Warnsignale, dass mein KI-Support-Agent versagt?
Kann ich meinen KI-Support testen, bevor er Kunden antwortet?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.