Sprachgesteuerte Technologien scheinen die neue Normalität zu sein, von Meeting-Assistenten, die Notizen für Sie machen, bis hin zu Sprachbefehlen, die Ihre Einkaufsliste verwalten. Aber die Technologie dahinter kann sich ein wenig wie Buchstabensuppe anfühlen. Sie werden oft von OpenAIs Whisper- und Text-to-Speech (TTS)-APIs hören, und obwohl sie verwandt klingen, erledigen sie tatsächlich gegensätzliche Aufgaben.
Den Unterschied zu verstehen, ist ziemlich wichtig für jeden, der Apps mit Sprachfunktionen entwickeln oder einfach nur sein Unternehmen mit KI ein wenig reibungsloser gestalten möchte. Dieser Leitfaden erklärt genau, was Whisper- und TTS-APIs tun, wie sie sich unterscheiden, wie sie zusammenspielen und hilft Ihnen herauszufinden, welche Sie tatsächlich benötigen.
Der Kern von Whisper vs. TTS-API: Sprache-zu-Text vs. Text-zu-Sprache
Bevor wir in einen direkten Vergleich einsteigen, wollen wir die Grundlagen klären. Diese beiden Technologien sind wirklich nur zwei Seiten derselben Medaille: die eine ist zum Zuhören da, die andere zum Sprechen.
Was ist OpenAI Whisper?
OpenAI Whisper ist ein sogenanntes Sprache-zu-Text-Modell. Seine gesamte Aufgabe besteht darin, gesprochenes Audio aufzunehmen und in geschriebenen Text umzuwandeln. So einfach ist das.
Es wurde mit massiven 680.000 Stunden Audio aus dem gesamten Web trainiert, weshalb es so gut darin ist, verschiedene Akzente zu verstehen, Hintergrundgeräusche herauszufiltern und sogar Fachjargon zu erfassen. Es kann 98 verschiedene Sprachen transkribieren und viele davon sogar ins Englische übersetzen. Sie können es als Open-Source-Modell erhalten, um es auf Ihrer eigenen Hardware auszuführen, oder die kostenpflichtige API verwenden, die viel einfacher in Ihre Projekte zu integrieren ist.
Im Grunde genommen ist Whisper das „Ohr“ eines KI-Systems.
Was ist eine TTS-API?
Eine Text-zu-Sprache (TTS) API macht genau das Gegenteil. Sie nimmt geschriebenen Text und wandelt ihn in gesprochenes Audio um. OpenAI hat seine eigene TTS-API, die aus einem Textblock sehr menschlich klingende Stimmen erzeugen kann. Diese Systeme sind darauf ausgelegt, natürlich zu klingen, mit dem richtigen Rhythmus und Ton, den man von einer Person erwarten würde.
You can think of a TTS API as the "voice" of an AI system. It’s the technology that lets your GPS give you turn-by-turn directions, your phone read an article out loud, or an AI assistant give you a verbal answer.
Wie Whisper und TTS-APIs zusammenarbeiten
Hier ist der Hauptpunkt, den viele Leute in der Debatte „Whisper vs. TTS-API“ falsch verstehen: Man wählt nicht das eine über das andere. Sie sind Kollaborateure. Man verwendet sie an verschiedenen Punkten in einem Prozess, um einen vollständigen Konversationszyklus zu schaffen.
Nehmen wir an, Sie entwickeln einen Sprachassistenten. So würden die beiden zusammenarbeiten:
-
Sie sprechen: Sie stellen eine Frage, wie zum Beispiel: „Wie sind Ihre Geschäftszeiten?“
-
Whisper hört zu: Das System erfasst das Audio und Whisper transkribiert es in einen einfachen Text: „Wie sind Ihre Geschäftszeiten?“
-
Die App denkt nach: Ihre Anwendung (oder ein großes Sprachmodell) erhält diesen Text, findet heraus, was Sie möchten, und findet die Antwort. Die Antwort ist ebenfalls Text: „Wir haben von Montag bis Freitag von 9 bis 17 Uhr geöffnet.“
-
Die TTS-API spricht: Schließlich nimmt die TTS-API diese Textantwort und wandelt sie in eine Audiodatei mit einer synthetisierten Stimme um, die die Worte spricht, damit Sie die Antwort hören können.
Wie Sie sehen, arbeiten sie nacheinander. Sie sind nicht austauschbar. Audio wird zu Text, der Text wird verarbeitet, und dann wird die Textantwort wieder zu Audio.
Die wirkliche Herausforderung besteht nicht darin, zwischen ihnen zu wählen, sondern sie reibungslos zu integrieren und die gesamte Logik dazwischen zu entwickeln. Dies erfordert normalerweise viel Entwicklerzeit, laufende Wartung und man muss vorsichtig sein mit Fehlern oder „Halluzinationen“, bei denen die KI etwas falsch versteht oder einfach eine falsche Antwort erfindet.
Das richtige Werkzeug für die Aufgabe auswählen
Wenn Sie etwas mit Sprache entwickeln möchten, müssen Sie einige wichtige Dinge beachten. Während Whisper eine erstklassige Wahl für Sprache-zu-Text ist, gibt es andere Anbieter wie Deepgram, Google und Amazon.
Hier sind die Faktoren, über die Sie nachdenken sollten:
-
Genauigkeit: Wie gut versteht das Modell tatsächlich, was gesagt wird? Dies wird oft durch die „Wortfehlerrate“ (WER) gemessen, wobei ein niedrigerer Wert besser ist. Whisper ist dafür bekannt, sehr genau zu sein, aber nichts ist 100 % perfekt. Ein paar falsche Wörter können Ihre Anwendung komplett verwirren.
-
Geschwindigkeit: Wie schnell erhalten Sie eine Antwort? Für ein Echtzeitgespräch benötigen Sie eine sehr geringe Latenz. Wenn Sie jedoch nur eine lange Meeting-Aufzeichnung im Nachhinein transkribieren, ist die Geschwindigkeit nicht so entscheidend.
-
Kosten: Die API-Preise werden in der Regel pro Minute des verarbeiteten Audios berechnet. Aber vergessen Sie nicht die „versteckten Kosten“. Wenn Sie den Open-Source-Weg mit Whisper gehen, benötigen Sie leistungsstarke Server, jemanden, der sie wartet, und Entwicklerstunden, was schnell teuer werden kann.
-
Zusätzliche Funktionen: Benötigen Sie Dinge wie die Identifizierung verschiedener Sprecher, Echtzeit-Transkription oder ein benutzerdefiniertes Vokabular für den Fachjargon Ihrer Branche? Die Basis-APIs haben diese möglicherweise nicht.
An dieser Stelle kann die Entwicklung von Grund auf wirklich zu einem Kopfzerbrechen werden. Für viele Unternehmen, insbesondere im Kundensupport, besteht das Hauptziel einfach darin, Kundenfragen schneller zu beantworten. Ein benutzerdefinierter Voice-Bot ist eine Möglichkeit, dies zu tun, aber es ist ein riesiges, langfristiges Projekt.
Ein direkterer Weg ist oft die Nutzung einer Plattform, die das eigentliche Geschäftsproblem ohne die steile Lernkurve löst. Ein Tool wie eesel AI ist beispielsweise darauf ausgelegt, den Support zu automatisieren, indem es sich direkt mit dem Helpdesk und den Wissensdatenbanken verbindet, die Sie bereits verwenden. Es umgeht das ganze STT/TTS-Pipeline-Chaos, indem es sich auf Text konzentriert, wo die meisten Support-Tickets ohnehin anfallen. So können Sie in Minuten statt in Monaten loslegen.
| Merkmal | Erstellung mit reinen APIs (Whisper/TTS) | Nutzung einer Plattform wie eesel AI |
|---|---|---|
| Einrichtungszeit | Wochen bis Monate Entwicklungszeit | Minuten, mit Ein-Klick-Integrationen |
| Wissensquelle | Erfordert für jede Quelle benutzerdefinierte Programmierung | Verbindet sich sofort mit Helpdesks, Dokumenten usw. |
| Wartung | Laufende Entwicklerzeit und Serverkosten | Wird von der Plattform verwaltet |
| Testen | Schwierig, die Leistung in der realen Welt zu simulieren | Robuste Simulation auf Basis historischer Tickets |
| Kernfokus | Technische Implementierung von Sprach-I/O | Lösung des Geschäftsproblems (Support-Automatisierung) |
Praxisbeispiele für Whisper- und TTS-APIs
Whisper- und TTS-APIs sind die Motoren hinter vielen Werkzeugen, die wir bereits täglich nutzen:
-
Meeting-Transkription: Automatische Erstellung einer schriftlichen Zusammenfassung von Anrufen und Meetings.
-
Video-Untertitelung: Erzeugung von Untertiteln für Videos, um sie zugänglicher zu machen.
-
Sprachassistenten: Die Gehirne hinter intelligenten Lautsprechern und In-App-Sprachbefehlen.
-
Kundensupport-Voicebots: Automatisierte Telefonsysteme, die Menschen tatsächlich verstehen und auf sie reagieren können.
Aber manchmal verpasst man durch die Konzentration auf einen schicken Voicebot einen größeren, einfacheren Gewinn. Der größte Teil des Kundensupports findet immer noch per E-Mail und Live-Chat statt. Die Automatisierung dieser textbasierten Kanäle kann Ihnen eine viel schnellere Rendite bringen und gleichzeitig genau dasselbe Problem lösen: Menschen schnelle, genaue Antworten zu geben.
Anstatt ein kompliziertes Sprachsystem von Grund auf neu zu entwickeln, ermöglicht Ihnen eine Plattform wie eesel AI, KI genau dort einzusetzen, wo Ihr Team und Ihre Kunden bereits sind.
- Es kennt Ihre Inhalte sofort: eesel AI trainiert mit Ihren vergangenen Support-Tickets, Help-Center-Artikeln und internen Dokumenten an Orten wie Confluence oder Google Docs. Es übernimmt vom ersten Tag an die Stimme und die Lösungen Ihrer Marke, etwas, das bei einem benutzerdefinierten Bot Ewigkeiten dauern würde.

- Sie können es sicher testen: Sie wollen definitiv wissen, dass eine KI funktioniert, bevor Sie sie mit Ihren Kunden sprechen lassen. eesel AI verfügt über einen Simulationsmodus, mit dem Sie es an Tausenden Ihrer vergangenen Tickets testen können, damit Sie genau sehen, wie gut es funktionieren wird.
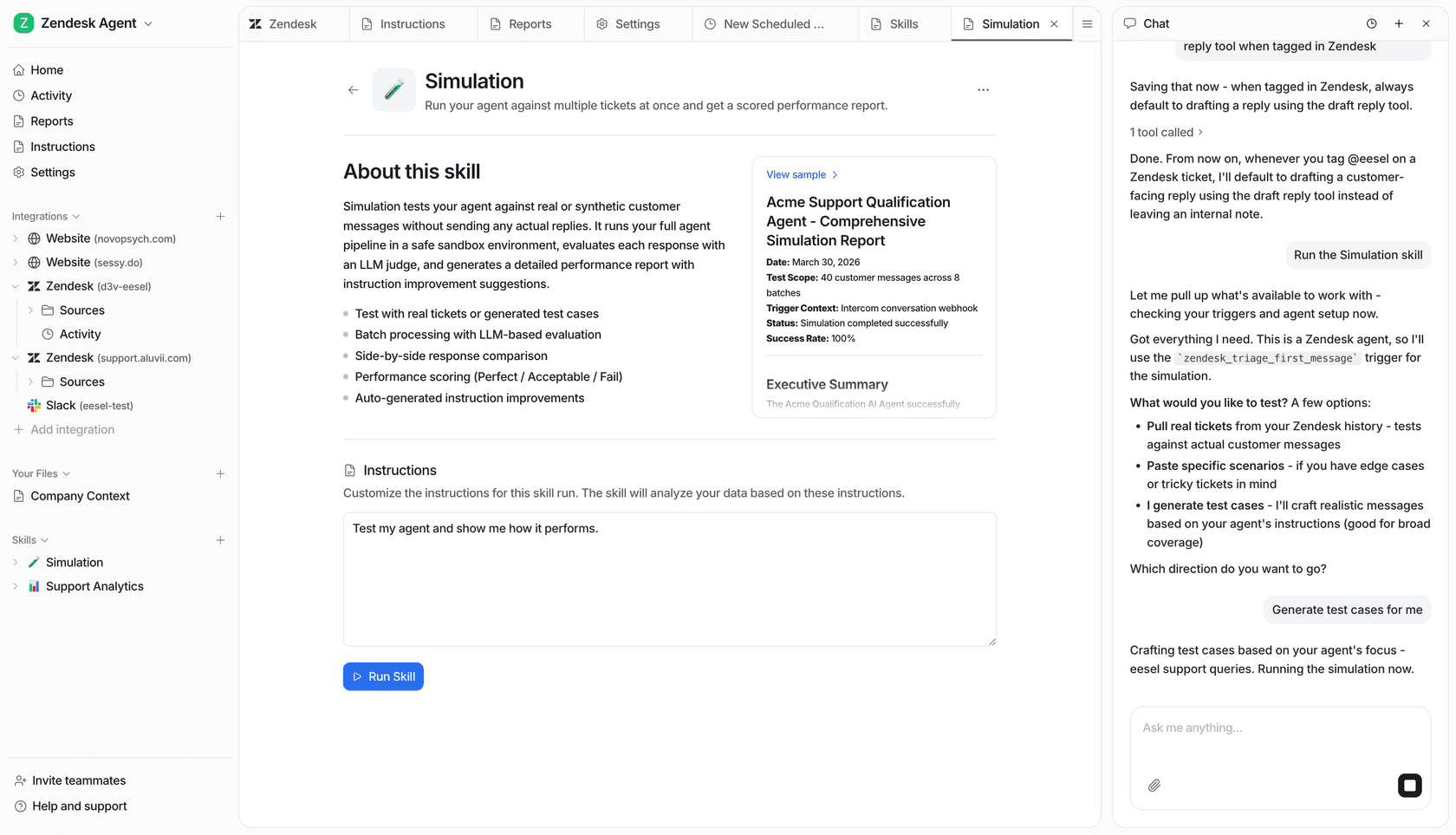
- Sie haben immer die Kontrolle: Sie entscheiden, welche Fragen die KI bearbeitet und wann es Zeit ist, ein Gespräch an einen Menschen weiterzuleiten. So können Sie es schrittweise einführen und Ihr Kundenerlebnis großartig halten.
Preise für OpenAI Whisper und TTS-API
Wenn Sie sich entscheiden, die APIs direkt zu verwenden, ist es gut zu wissen, was es kosten wird. Die Preise von OpenAI sind nutzungsabhängig.
-
Preise für die Whisper-API: Die Whisper-API kostet $0,006 pro Minute Audio, aufgerundet auf die nächste Sekunde. Die Transkription eines einstündigen Meetings würde Sie also etwa 0,36 $ kosten.
-
Preise für die TTS-API: Die Text-to-Speech-API kostet 0,015 $ pro 1.000 Zeichen für das Standardmodell und 0,030 $ pro 1.000 Zeichen für das hochwertigere HD-Modell.
Obwohl diese Raten niedrig erscheinen, können die Kosten bei hohem Verkehrsaufkommen schnell ansteigen. Wichtiger ist, dass diese Preise nicht die Kosten für die KI-Modellaufrufe zur Ermittlung der Antworten oder die Entwickler- und Serverkosten für den Betrieb des Ganzen beinhalten.
Fokus auf die Lösung, nicht nur auf die Technik
So, da haben Sie es. Whisper (Sprache-zu-Text) und TTS (Text-zu-Sprache) sind leistungsstarke Werkzeuge, die zusammenarbeiten, um Sprachschnittstellen zum Leben zu erwecken. Whisper hört zu, und TTS spricht. Sie sind zwei Teile eines Ganzen, keine Konkurrenten.
Aber eine Geschäftslösung aus diesen rohen Komponenten zu entwickeln, ist ein ernsthaftes Projekt. Es erfordert viel technisches Geschick, laufende Wartung und eine große Investition in Entwicklungszeit.
Für Unternehmen, die einfach nur ihren Kundensupport verbessern möchten, gibt es oft einen viel direkteren Weg. Indem Sie die textbasierten Konversationen automatisieren, in denen Ihr Team bereits die meiste Zeit verbringt, können Sie große Ergebnisse erzielen, ohne den Aufwand eines benutzerdefinierten Sprachsystems.
Plattformen wie eesel AI bieten eine einsatzbereite Lösung, die sich in Ihre vorhandenen Tools integriert, vom Wissen Ihres Unternehmens lernt und Ihnen die Kontrolle gibt, die Sie benötigen, um den Support richtig zu automatisieren.
Bereit zu sehen, was eine speziell für diesen Zweck entwickelte KI-Support-Plattform leisten kann? Testen Sie eesel AI kostenlos und Sie können in wenigen Minuten loslegen.
Häufig gestellte Fragen
Was ist der grundlegende Unterschied zwischen Whisper und einer TTS-API?
Der grundlegende Unterschied liegt in ihrer Wirkungsrichtung: Whisper wandelt gesprochenes Audio in geschriebenen Text um (Sprache-zu-Text) und fungiert als das „Ohr“ des Systems. Umgekehrt wandelt eine TTS-API geschriebenen Text in gesprochenes Audio um (Text-zu-Sprache) und dient als die „Stimme“ des Systems.
Wie arbeiten Whisper und TTS-APIs typischerweise in einer realen Anwendung zusammen?
Sie arbeiten sequenziell zusammen, um einen Konversationszyklus zu schaffen. Whisper transkribiert zunächst die Sprache des Benutzers in Text, den eine Anwendung dann verarbeitet, um eine textbasierte Antwort zu formulieren. Schließlich wandelt die TTS-API diese Textantwort wieder in gesprochenes Audio für den Benutzer um.
Sollte ich zwischen Whisper und einer TTS-API wählen, oder dienen sie unterschiedlichen Zwecken?
Sie sind keine Konkurrenten und erfüllen entgegengesetzte, komplementäre Funktionen. Sie verwenden normalerweise beide in Verbindung für eine vollständige Zwei-Wege-Sprachinteraktion, wobei Whisper die Eingabe und eine TTS-API die Ausgabe übernimmt.
Was sind die Hauptfaktoren, die bei der Bewertung von Sprachtechnologien wie Whisper- und TTS-APIs zu berücksichtigen sind?
Schlüsselfaktoren sind Genauigkeit (z. B. Wortfehlerrate), Geschwindigkeit (Latenz für Echtzeitanwendungen), Kosten (API-Preise plus versteckte Infrastruktur- und Entwicklungskosten) und zusätzliche Funktionen wie Sprecheridentifikation oder benutzerdefinierte Vokabulare.
Kann ich Whisper oder eine TTS-API unabhängig voneinander verwenden?
Ja, Sie können sie je nach Ziel unabhängig voneinander verwenden. Zum Beispiel ist Whisper allein perfekt für die Transkription von Meeting-Aufzeichnungen, während eine TTS-API für sich allein verwendet werden kann, um Artikel vorzulesen. Ein vollständiger konversationeller Sprachassistent erfordert jedoch beides.
Was sind einige gängige Anwendungsfälle für Whisper- und TTS-APIs?
Sie treiben Anwendungen wie Meeting-Transkription, Video-Untertitelung, interaktive Sprachassistenten (z. B. intelligente Lautsprecher) und automatisierte Kundensupport-Voicebots an. Sie bilden den Kern jedes Systems, das sowohl menschenähnliche Sprache verstehen als auch erzeugen muss.