
O mundo da IA move-se a um ritmo alucinante. Mal você consegue entender um modelo, outro aparece, prometendo ser mais rápido, mais inteligente e mais barato. O mais recente grande lançamento, o GPT-4o, não é exceção. É o novo e brilhante sucessor da OpenAI para o GPT-4 Turbo e, no papel, os benchmarks parecem fantásticos.
Mas a verdadeira questão para quem gere um negócio é: como é que ele se comporta no mundo real? Quando se está a construir um agente de IA para algo tão importante como o apoio ao cliente, as especificações numa página da web não contam a história toda. Este guia é uma comparação prática e sem rodeios entre o GPT-4 Turbo e o GPT-4o. Vamos deixar os benchmarks de lado e focar-nos no que realmente importa para o seu negócio: desempenho sob pressão, precisão em tarefas complexas e o custo real de manter a sua IA em funcionamento.
GPT-4 Turbo vs GPT-4o: O que são estes modelos?
Antes de entrarmos nos pormenores, vamos fazer uma breve apresentação para ver o que cada um destes modelos tem para oferecer.
O que é o GPT-4 Turbo?
O GPT-4 Turbo foi lançado como uma grande atualização do GPT-4 original. Pode pensar nele como a versão refinada e mais eficiente da família. Foi construído para ser mais rápido, mais barato e capaz de lidar com muito mais contexto, graças à sua enorme janela de 128k tokens. O seu conhecimento está atualizado até abril de 2023, e rapidamente se tornou o favorito dos programadores que criam aplicações que necessitavam da capacidade intelectual do GPT-4 sem o seu preço original elevado.
O que é o GPT-4o?
O GPT-4o, onde o "o" significa "omni", é o mais recente modelo de referência da OpenAI. Isto não é apenas um pequeno ajuste; é um motor completamente novo. O seu maior ponto de venda é a sua multimodalidade nativa, que é uma forma elegante de dizer que consegue compreender texto, áudio e imagens em conjunto, num único modelo. Isto torna as interações muito mais naturais e humanas. Além disso, oferece respostas muito mais rápidas e custa 50% menos que o GPT-4 Turbo, posicionando-se como o novo padrão de excelência para IA interativa e em tempo real.
Desempenho e velocidade: O que os benchmarks não lhe dizem
No papel, o debate sobre a velocidade parece bastante claro. A OpenAI afirma que o GPT-4o é duas vezes mais rápido que o GPT-4 Turbo, e os testes iniciais parecem concordar. Tem um débito (throughput) muito maior (o número de palavras que consegue gerar por segundo), pelo que, para uma empresa, respostas mais rápidas deverão significar clientes mais satisfeitos. Uma vitória clara, certo?
Bem, não tão depressa. O problema com estes números é que não são imutáveis. O desempenho no mundo real para modelos de pagamento por utilização pode ser uma verdadeira montanha-russa. Como demonstraram algumas excelentes análises de empresas como a New Relic, quando um novo modelo se torna popular, o seu desempenho pode começar a diminuir sob a carga intensa. O modelo super-rápido que testou na semana passada pode parecer lento esta semana.
Isto cria uma enorme dor de cabeça para qualquer empresa que dependa de tempos de resposta consistentes e previsíveis para a sua IA de contacto com o cliente. Um bot lento pode ser ainda mais frustrante do que não ter bot nenhum, resultando numa experiência de cliente genuinamente má. É aqui que a simples escolha do modelo "mais recente e melhor" se pode virar contra si. Precisa de uma forma de testar e confirmar o desempenho antes de o lançar.
É exatamente por isso que a simulação é tão importante. Em vez de lançar um novo modelo e cruzar os dedos, uma plataforma como a eesel AI permite-lhe executar qualquer configuração de IA num poderoso modo de simulação. Pode testá-lo com milhares dos seus próprios tickets de suporte antigos para ver precisamente como irá funcionar, qual será a sua taxa de resolução e com que rapidez responde. Isto permite-lhe eliminar completamente o risco do lançamento de um novo modelo antes que este interaja com um cliente real.

Uma comparação de desempenho frente a frente
Aqui está uma visão rápida de como os dois modelos se comparam nas principais métricas de desempenho.
| Característica | GPT-4 Turbo | GPT-4o ("Omni") |
|---|---|---|
| Débito (Throughput) | ~20 tokens/segundo | ~109 tokens/segundo (no lançamento) |
| Latência | Mais alta | Mais baixa |
| Consistência no Mundo Real | Mais previsível (especialmente com versões provisionadas) | Variável; pode abrandar sob carga intensa |
| Multimodalidade | Texto, imagens | Texto, imagens, áudio e vídeo nativos |
Precisão e raciocínio para tarefas empresariais
A velocidade é apenas uma peça do puzzle. De que serve uma resposta rápida se estiver errada ou ignorar completamente o objetivo das suas instruções? É aqui que o debate entre o GPT-4 Turbo e o GPT-4o se torna realmente interessante.
Se passar algum tempo em fóruns da comunidade como o Reddit ou os próprios fóruns de programadores da OpenAI, irá notar um padrão: muitos programadores ainda confiam no GPT-4 Turbo para trabalhos complexos. Consideram-no mais fiável para tarefas como programação, resolução de quebra-cabeças lógicos e seguimento de instruções detalhadas e com várias etapas.
Em contrapartida, o GPT-4o é por vezes descrito como sendo um pouco mais "superficial". Embora seja incrivelmente rápido e conversacional, alguns utilizadores descobriram que pode ficar preso em ciclos, ignorar partes de um prompt detalhado ou perder o contexto da conversa. É um dilema clássico: precisa de velocidade vertiginosa ou de profundidade ponderada?
Para uma equipa de suporte, isto tem consequências muito reais. O GPT-4o pode ser perfeito para despachar rapidamente questões simples e repetitivas de Nível 1. Mas para guiar um cliente através de um processo de resolução de problemas complicado ou para lidar com uma questão de faturação sensível, o raciocínio ligeiramente mais lento, mas mais robusto, do GPT-4 Turbo pode ainda ser a melhor aposta.
A capacidade de "dirigir" um modelo e guiar o seu comportamento é um fator muito importante aqui. É por isso que ter uma camada de controlo forte entre si e o modelo é tão importante. Por exemplo, com o editor de prompts personalizável e o motor de fluxos de trabalho da eesel AI, obtém controlo total sobre a sua IA. Pode afinar a sua personalidade, definir regras estritas sobre o que pode e não pode falar e criar ações personalizadas que pode executar. Isto dá-lhe as barreiras de proteção para guiar qualquer modelo, garantindo que fornece respostas precisas e alinhadas com a marca, e que escala de forma fiável questões complicadas quando necessário.

Quando usar cada modelo
Aqui está uma análise simples para o ajudar a decidir:
-
Escolha o GPT-4 Turbo para:
- Resolução de problemas complexos e com várias etapas, como suporte técnico ou análise financeira.
- Tarefas onde precisa que a IA siga instruções detalhadas à risca.
- Situações onde o raciocínio lógico profundo é mais importante do que obter uma resposta instantânea.
-
Escolha o GPT-4o para:
- Chats de alto volume e em tempo real, como um chatbot na linha da frente de um website.
- Tarefas multimodais, como analisar a captura de ecrã de uma mensagem de erro de um cliente.
- Aplicações onde a velocidade e o custo são as suas principais prioridades.
Custo e capacidades: Um olhar para além do preço de tabela
Vamos falar de dinheiro. À primeira vista, o GPT-4o é o vencedor claro, sendo 50% mais barato para utilização via API do que o GPT-4 Turbo. Para qualquer empresa a operar em grande escala, esse tipo de poupança é difícil de ignorar.
Mas há um custo oculto que precisa de ter em atenção: o consumo de tokens. Como a análise da New Relic também observou, é bastante comum que modelos mais recentes e conversacionais sejam um pouco mais "faladores". Eles podem usar mais palavras (e, portanto, mais tokens) para dizer a mesma coisa. Assim, um modelo que é 50% mais barato por token, mas que usa 20% mais tokens para cada resposta, na verdade não irá reduzir a sua fatura para metade. Isto pode levar a custos operacionais imprevisíveis que são difíceis de orçamentar, especialmente se o seu volume de suporte flutuar.
Claro, a característica principal do GPT-4o é a sua multimodalidade nativa. Isto é algo muito importante para as equipas de suporte. Um cliente pode enviar uma foto de uma peça partida, uma captura de ecrã de um bug de software, ou até mesmo um vídeo curto, e a IA consegue compreendê-lo diretamente. Essa é uma forma incrivelmente poderosa de resolver problemas mais rapidamente, e é algo que o GPT-4 Turbo simplesmente não consegue fazer sozinho.
Custos imprevisíveis são um dos maiores obstáculos quando se tenta escalar a automação do suporte. É por isso que uma ferramenta como a eesel AI utiliza preços transparentes e previsíveis. Os nossos planos baseiam-se num número fixo de interações de IA mensais, sem taxas ocultas por resolução. Esta abordagem protege-o de faturas surpresa se uma atualização do modelo tornar subitamente o seu agente de IA muito mais falador, permitindo-lhe orçamentar com confiança e escalar sem receio.

Preços oficiais
Como prometido, aqui estão os preços oficiais da API diretamente da OpenAI. Lembre-se apenas que estes preços podem mudar, por isso é sempre sensato verificar a fonte para obter os números mais recentes.
| Modelo | Custo de Entrada | Custo de Saída |
|---|---|---|
| GPT-4 Turbo | $10.00 | $30.00 |
| GPT-4o | $5.00 | $15.00 |
Nota: Os preços são por 1 milhão de tokens e estão sujeitos a alterações. Verifique sempre a página de preços oficial da OpenAI para obter as informações mais atuais.
GPT-4 Turbo vs GPT-4o: Que modelo deve escolher?
Então, depois de tudo isto, quem vence o confronto GPT-4 Turbo vs GPT-4o? A resposta honesta é: depende. Não existe um único modelo "melhor" para todos. A escolha certa depende das suas necessidades específicas.
O GPT-4o é o campeão indiscutível em velocidade, custo e em qualquer tarefa que envolva imagens, áudio ou vídeo. Para chats de alto volume e em tempo real, é o novo rei. No entanto, o GPT-4 Turbo ainda é um concorrente de peso para trabalhos complexos e de alto risco, onde o raciocínio profundo e a fiabilidade são o que mais importa.
A principal conclusão aqui não é sobre escolher um modelo em detrimento do outro. Trata-se de reconhecer que construir uma IA eficaz e fiável para o seu negócio exige mais do que simplesmente ligar-se à API mais recente. Requer uma plataforma que lhe permita testar, controlar e implementar estas ferramentas poderosas com confiança.
A forma mais inteligente de implementar suporte com IA
Encontrar o equilíbrio certo entre velocidade, custo e precisão é o desafio central na construção de um excelente agente de suporte de IA. Precisa de uma solução que se integre nas suas ferramentas existentes, aprenda com o conhecimento da sua empresa e lhe dê o poder de afinar toda a experiência do cliente.
A eesel AI é uma plataforma de IA concebida para fazer exatamente isso. Liga-se diretamente ao seu helpdesk (como Zendesk ou Freshdesk) e conecta-se a todas as suas fontes de conhecimento para automatizar o suporte de forma imediata.
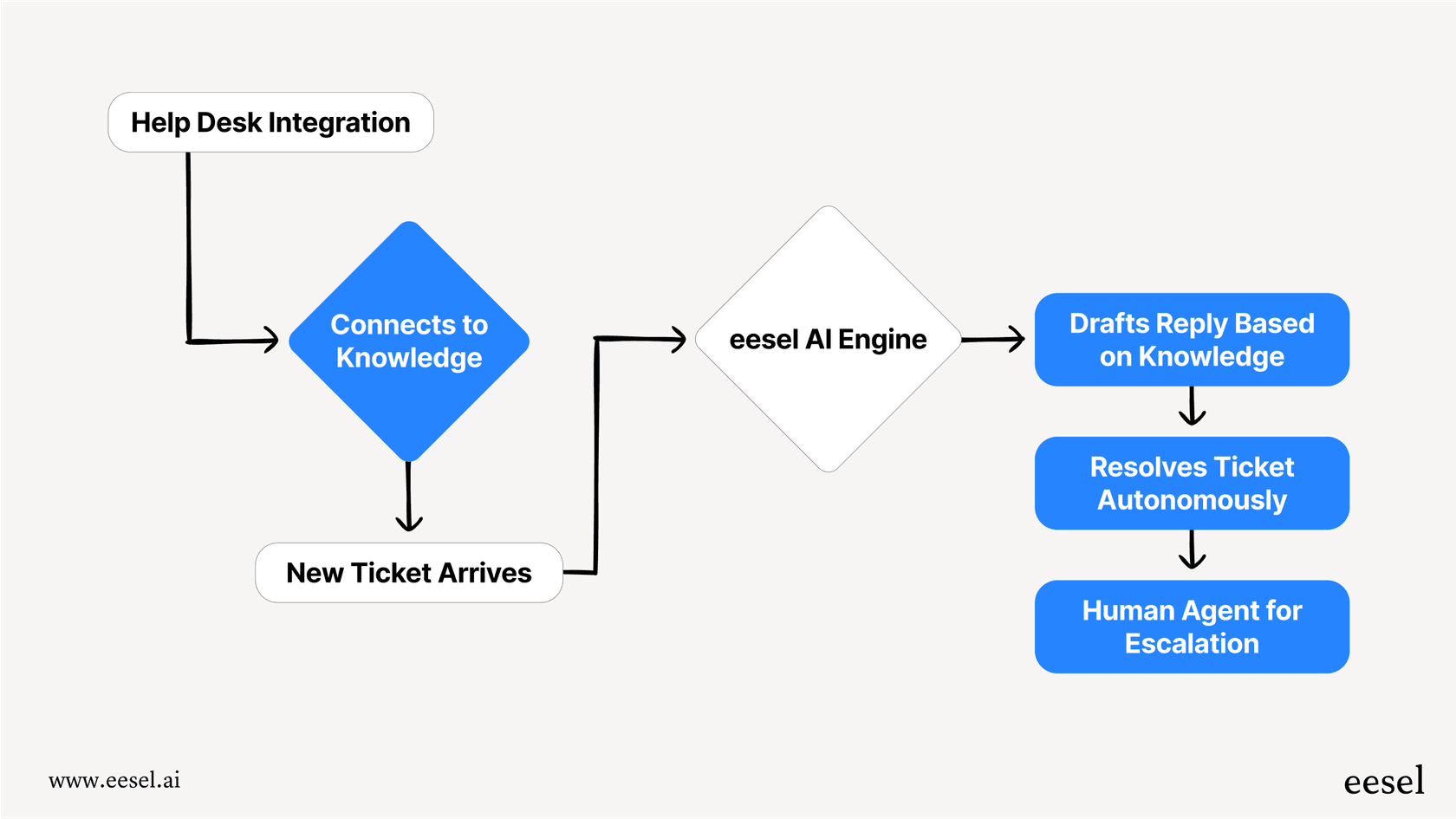
Com funcionalidades poderosas como simulação sem riscos, um motor de fluxo de trabalho totalmente personalizável e preços previsíveis, a eesel permite-lhe aproveitar o melhor dos modelos da OpenAI sem as dores de cabeça operacionais e os riscos técnicos. Pode entrar em funcionamento em minutos, não em meses, e finalmente construir uma experiência de suporte com IA da qual se possa orgulhar.
Perguntas frequentes
A principal distinção é que o GPT-4o é um [modelo nativamente multimodal](https://learn.microsoft.com/en-us/answers/questions/1689547/choosing-between-gpt-4-turbo-and-gpt-4o-evaluating) mais recente, capaz de compreender texto, áudio e imagens em conjunto, oferecendo respostas mais rápidas e custos de API mais baixos. O GPT-4 Turbo é um modelo de texto e imagem altamente refinado, conhecido pela sua eficiência e maior janela de contexto.
O GPT-4o é geralmente mais rápido, com um débito (throughput) mais elevado no papel, mas a sua consistência no mundo real pode variar sob carga intensa. O GPT-4 Turbo, especialmente as versões provisionadas, tende a oferecer um desempenho mais previsível, o que é crucial para uma [experiência do cliente](https://www.eesel.ai/pt/blog/customer-experience-automation) consistente.
Sim, embora o GPT-4o tenha custos de API por token mais baixos, por vezes pode ser mais "falador", utilizando potencialmente mais tokens por interação. Este aumento no consumo de tokens pode anular parte da poupança por token, levando a custos operacionais menos previsíveis.
Muitos programadores ainda preferem o GPT-4 Turbo para tarefas complexas que exigem raciocínio lógico profundo, programação e adesão precisa a instruções com várias etapas. Embora o GPT-4o seja rápido e conversacional, alguns utilizadores consideram que pode ser mais superficial ou, ocasionalmente, ignorar elementos detalhados do prompt.
Escolha o GPT-4 Turbo para a resolução de problemas complexos e tarefas que necessitem de raciocínio lógico profundo. Opte pelo GPT-4o para chats de alto volume em tempo real e qualquer tarefa que envolva entrada nativa multimodal, como a análise de capturas de ecrã ou áudio de clientes.
O GPT-4o oferece multimodalidade nativa, o que significa que pode processar e compreender texto, áudio e imagens diretamente num único modelo. Isto permite interações mais naturais com os clientes, como analisar a captura de ecrã de um erro ou um vídeo curto de um cliente, algo que o GPT-4 Turbo não consegue fazer sozinho.
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.