
El mundo de la IA se mueve a un ritmo vertiginoso. Justo cuando logras entender un modelo, aparece otro que promete ser más rápido, más inteligente y más barato. El último gran lanzamiento, GPT-4o, no es una excepción. Es el nuevo y brillante sucesor de OpenAI para GPT-4 Turbo y, sobre el papel, los benchmarks se ven fantásticos.
Pero aquí está la verdadera pregunta para cualquiera que dirija un negocio: ¿cómo se comporta en el mundo real? Cuando estás construyendo un agente de IA para algo tan importante como el soporte al cliente, las especificaciones en una página web no cuentan toda la historia. Esta guía es una comparación práctica y sin rodeos de GPT-4 Turbo vs. GPT-4o. Vamos a ir más allá de los benchmarks y a analizar lo que realmente importa para tu resultado final: el rendimiento bajo presión, la precisión en tareas complicadas y el verdadero costo de mantener tu IA en funcionamiento.
GPT-4 Turbo vs. GPT-4o: ¿qué son estos modelos?
Antes de entrar en materia, hagamos un repaso rápido para ver qué aporta cada uno de estos modelos.
¿Qué es GPT-4 Turbo?
GPT-4 Turbo fue lanzado como una mejora importante del GPT-4 original. Puedes pensar en él como la versión refinada y más eficiente de la familia. Fue construido para ser más rápido, menos costoso y capaz de manejar mucho más contexto con su enorme ventana de 128k tokens. Su conocimiento está actualizado hasta abril de 2023, y rápidamente se convirtió en el favorito de los desarrolladores que construyen aplicaciones que necesitaban la capacidad intelectual de GPT-4 sin su elevado precio original.
¿Qué es GPT-4o?
GPT-4o, donde la "o" significa "omni", es el nuevo modelo insignia de OpenAI. Esto no es solo una pequeña puesta a punto; es un motor completamente nuevo. Su mayor punto a favor es su multimodalidad nativa, que es una forma elegante de decir que puede entender texto, audio e imágenes, todo junto en un solo modelo. Esto hace que las interacciones se sientan mucho más naturales y humanas. Además, ofrece respuestas mucho más rápido y cuesta un 50% menos que GPT-4 Turbo, posicionándose como el nuevo estándar de oro para la IA interactiva en tiempo real.
Rendimiento y velocidad: lo que los benchmarks no te dicen
Sobre el papel, el debate sobre la velocidad parece bastante claro. OpenAI afirma que GPT-4o es el doble de rápido que GPT-4 Turbo, y las primeras pruebas parecen confirmarlo. Tiene un rendimiento mucho mayor (el número de palabras que puede generar por segundo), por lo que, para un negocio, respuestas más rápidas deberían significar clientes más felices. Una victoria clara, ¿verdad?
Bueno, no tan rápido. El problema con estas cifras es que no están escritas en piedra. El rendimiento en el mundo real para los modelos de pago por uso puede ser una montaña rusa. Como han demostrado algunos excelentes análisis de firmas como New Relic, cuando un nuevo modelo se vuelve popular, su rendimiento puede empezar a disminuir bajo la pesada carga. El modelo ultrarrápido que probaste la semana pasada podría siente lento esta semana.
Esto crea un enorme dolor de cabeza para cualquier negocio que dependa de tiempos de respuesta consistentes y predecibles para su IA de cara al cliente. Un bot lento puede ser aún más frustrante que no tener ningún bot, lo que lleva a una experiencia de cliente realmente mala. Aquí es donde simplemente elegir el modelo "más nuevo y mejor" puede volverse en tu contra. Necesitas una forma de probar y confirmar el rendimiento antes de ponerlo en marcha.
Es exactamente por eso que la simulación es tan importante. En lugar de lanzar un nuevo modelo y cruzar los dedos, una plataforma como eesel AI te permite ejecutar cualquier configuración de IA en un potente modo de simulación. Puedes probarlo con miles de tus propios tickets de soporte pasados para ver precisamente cómo se desempeñará, cuál será su tasa de resolución y cuán rápido responderá. Esto te permite eliminar por completo el riesgo del despliegue de un nuevo modelo antes de que interactúe con un cliente real.

Una comparación de rendimiento cara a cara
Aquí tienes un vistazo rápido de cómo se comparan los dos modelos en métricas clave de rendimiento.
| Característica | GPT-4 Turbo | GPT-4o ("Omni") |
|---|---|---|
| Rendimiento | ~20 tokens/segundo | ~109 tokens/segundo (en el lanzamiento) |
| Latencia | Más alta | Más baja |
| Consistencia en el mundo real | Más predecible (especialmente con versiones aprovisionadas) | Variable; puede ralentizarse bajo una carga pesada |
| Multimodalidad | Texto, imágenes | Texto, imágenes, audio, video nativos |
Precisión y razonamiento para tareas empresariales
La velocidad es solo una pieza del rompecabezas. ¿De qué sirve una respuesta rápida si es incorrecta o ignora por completo el punto de tus instrucciones? Aquí es donde el debate entre GPT-4 Turbo y GPT-4o se pone realmente interesante.
Si pasas un tiempo en foros de la comunidad como Reddit o los propios foros de desarrolladores de OpenAI, notarás un patrón: muchos desarrolladores todavía se inclinan por GPT-4 Turbo para trabajos complejos. Consideran que es más fiable para cosas como la codificación, la resolución de acertijos lógicos y el seguimiento de instrucciones detalladas y de varios pasos.
En contraste, a veces se describe a GPT-4o como un poco más "superficial". Si bien es increíblemente rápido y conversacional, algunos usuarios han descubierto que puede quedarse atascado en bucles, ignorar partes de un prompt detallado o perder el hilo del contexto de la conversación. Es la clásica disyuntiva: ¿necesitas una velocidad vertiginosa o una profundidad reflexiva?
Para un equipo de soporte, esto tiene consecuencias muy reales. GPT-4o podría ser perfecto para despachar rápidamente preguntas simples y repetitivas de Nivel 1. Pero para guiar a un cliente a través de un complicado proceso de solución de problemas o para manejar una pregunta delicada sobre facturación, el razonamiento ligeramente más lento pero más robusto de GPT-4 Turbo podría seguir siendo la mejor opción.
La capacidad de "dirigir" un modelo y guiar su comportamiento es un factor muy importante aquí. Por eso es tan crucial tener una capa de control sólida entre tú y el modelo. Por ejemplo, con el editor de prompts personalizable y el motor de flujos de trabajo de eesel AI, obtienes un control total sobre tu IA. Puedes afinar su personalidad, establecer reglas estrictas sobre lo que puede y no puede hablar, y construir acciones personalizadas que puede realizar. Esto te proporciona las barreras de protección para guiar cualquier modelo, asegurando que ofrezca respuestas precisas y acordes a tu marca, y que escale de manera fiable los problemas complicados cuando sea necesario.

Cuándo usar cada modelo
Aquí tienes un desglose simple para ayudarte a decidir:
-
Elige GPT-4 Turbo para:
- Resolución de problemas complejos y de varios pasos, como soporte técnico o análisis financiero.
- Tareas en las que necesitas que la IA siga instrucciones detalladas al pie de la letra.
- Situaciones en las que el razonamiento lógico profundo es más importante que obtener una respuesta instantánea.
-
Elige GPT-4o para:
- Chats de alto volumen en tiempo real, como un chatbot de primera línea en un sitio web.
- Tareas multimodales, como analizar la captura de pantalla de un mensaje de error de un cliente.
- Aplicaciones donde la velocidad y el costo son tus principales prioridades.
Costo y capacidades: una mirada más allá del precio de etiqueta
Hablemos de dinero. A primera vista, GPT-4o es el claro ganador, siendo un 50% más barato para el uso de la API que GPT-4 Turbo. Para cualquier negocio que trabaje a escala, ese tipo de ahorro es difícil de ignorar.
Pero hay un costo oculto que debes vigilar: el consumo de tokens. Como también señaló el análisis de New Relic, es bastante común que los modelos más nuevos y conversacionales sean un poco más "habladores". Podrían usar más palabras (y por lo tanto, más tokens) para decir lo mismo. Por lo tanto, un modelo que es un 50% más barato por token pero que usa un 20% más de tokens por cada respuesta no reducirá tu factura a la mitad. Esto puede llevar a algunos costos operativos impredecibles que son difíciles de presupuestar, especialmente si el volumen de tu soporte sube y baja.
Por supuesto, la característica estrella de GPT-4o es su multimodalidad nativa. Esto es un gran avance para los equipos de soporte. Un cliente puede enviar una foto de una pieza rota, una captura de pantalla de un error de software o incluso un video corto, y la IA puede entenderlo directamente. Esa es una forma increíblemente poderosa de resolver problemas más rápido, y es algo que GPT-4 Turbo simplemente no puede hacer por sí solo.
Los costos impredecibles son uno de los mayores obstáculos cuando intentas escalar la automatización del soporte. Es por eso que una herramienta como eesel AI utiliza precios transparentes y predecibles. Nuestros planes se basan en un número fijo de interacciones de IA mensuales, sin tarifas ocultas por resolución. Este enfoque te protege de facturas sorpresa si una actualización del modelo de repente hace que tu agente de IA sea mucho más hablador, permitiéndote presupuestar con confianza y escalar sin miedo.

Precios oficiales
Como prometimos, aquí están los precios oficiales de la API directamente de OpenAI. Solo recuerda que estos precios pueden cambiar, por lo que siempre es inteligente consultar la fuente para obtener las cifras más recientes.
| Modelo | Costo de Entrada | Costo de Salida |
|---|---|---|
| GPT-4 Turbo | 10,00 $ | 30,00 $ |
| GPT-4o | 5,00 $ | 15,00 $ |
Nota: Los precios son por 1 millón de tokens y están sujetos a cambios. Consulta siempre la página oficial de precios de OpenAI para obtener la información más actualizada.
GPT-4 Turbo vs. GPT-4o: ¿qué modelo deberías elegir?
Entonces, después de todo esto, ¿quién gana el enfrentamiento entre GPT-4 Turbo y GPT-4o? La respuesta honesta es: depende. No hay un único modelo "mejor" para todos. La elección correcta se reduce a tus necesidades específicas.
GPT-4o es el campeón indiscutible en velocidad, costo y cualquier tarea que involucre imágenes, audio o video. Para el chat de alto volumen en tiempo real, es el nuevo rey. Sin embargo, GPT-4 Turbo sigue siendo un contendiente de peso para trabajos complejos y de alto riesgo donde el razonamiento profundo y la fiabilidad son lo más importante.
La mayor conclusión aquí no es sobre elegir un modelo sobre el otro. Se trata de reconocer que construir una IA efectiva y confiable para tu negocio requiere más que simplemente conectarse a la última API. Requiere una plataforma que te permita probar, controlar y desplegar estas poderosas herramientas con confianza.
La forma más inteligente de implementar el soporte con IA
Descubrir el equilibrio adecuado entre velocidad, costo y precisión es el desafío central al construir un gran agente de soporte de IA. Necesitas una solución que se integre con tus herramientas existentes, aprenda del conocimiento de tu empresa y te dé el poder de afinar toda la experiencia del cliente.
eesel AI es una plataforma de IA diseñada para hacer precisamente eso. Se conecta directamente a tu helpdesk (como Zendesk o Freshdesk) y se conecta a todas tus fuentes de conocimiento para automatizar el soporte desde el primer momento.
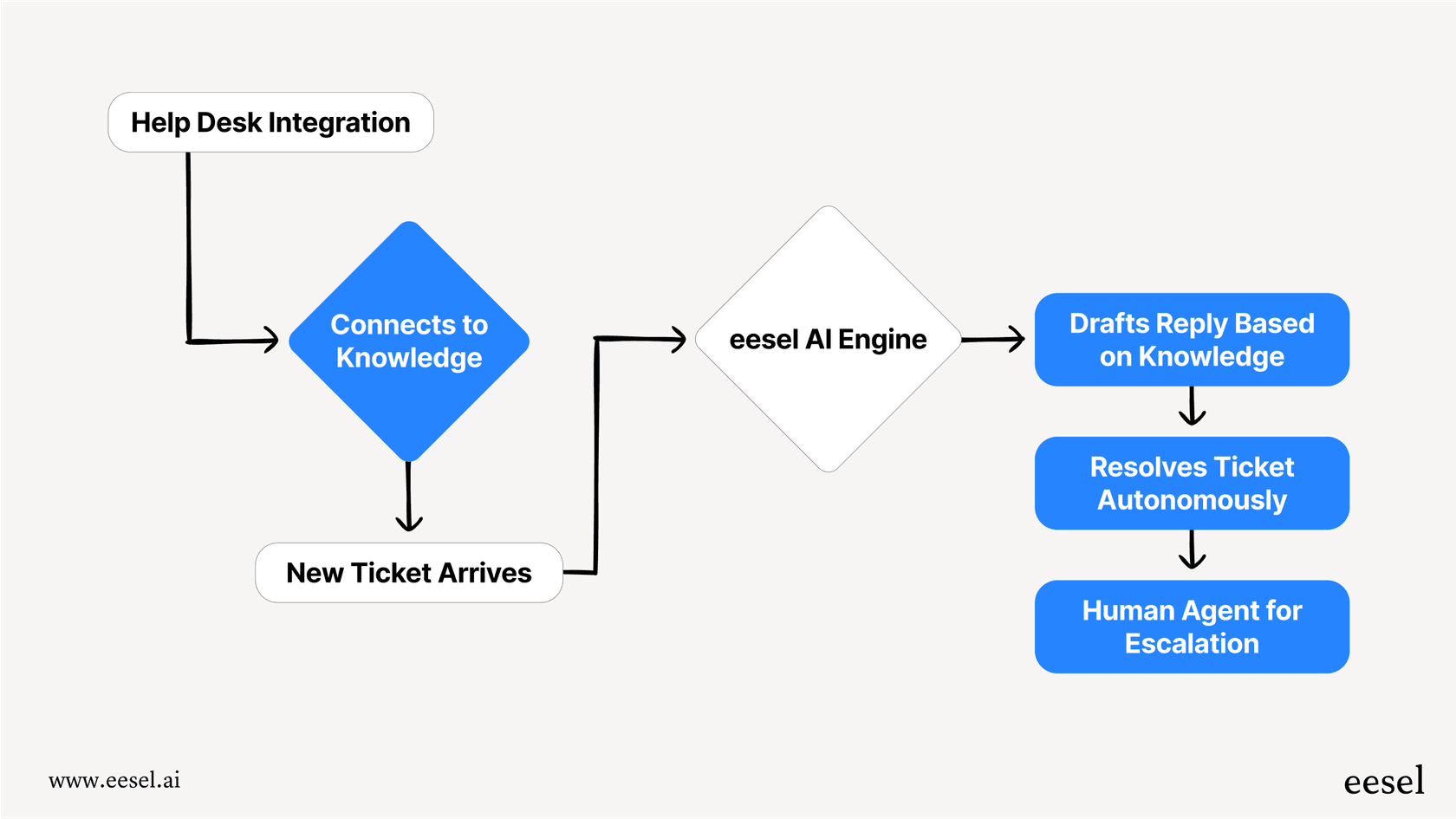
Con potentes características como la simulación sin riesgos, un motor de flujo de trabajo totalmente personalizable y precios predecibles, eesel te permite aprovechar lo mejor de los modelos de OpenAI sin los dolores de cabeza operativos y los riesgos técnicos. Puedes ponerlo en marcha en minutos, no en meses, y finalmente construir una experiencia de soporte con IA de la que realmente puedas estar orgulloso.
Preguntas frecuentes
La principal distinción es que GPT-4o es un modelo más nuevo y [nativamente multimodal](https://learn.microsoft.com/en-us/answers/questions/1689547/choosing-between-gpt-4-turbo-and-gpt-4o-evaluating) capaz de entender texto, audio e imágenes de forma conjunta, ofreciendo respuestas más rápidas y costos de API más bajos. GPT-4 Turbo es un modelo de texto e imagen altamente refinado, conocido por su eficiencia y su ventana de contexto más grande.
GPT-4o es generalmente más rápido con un mayor rendimiento sobre el papel, pero su consistencia en el mundo real puede variar bajo una carga pesada. GPT-4 Turbo, especialmente las versiones aprovisionadas, tiende a ofrecer un rendimiento más predecible, lo cual es crucial para una [experiencia del cliente](https://www.eesel.ai/es/blog/customer-experience-automation) consistente.
Sí, aunque GPT-4o tiene costos de API por token más bajos, a veces puede ser más "hablador", utilizando potencialmente más tokens por interacción. Este mayor consumo de tokens puede contrarrestar parte del ahorro por token, lo que lleva a costos operativos menos predecibles.
Muchos desarrolladores todavía prefieren GPT-4 Turbo para tareas complejas que requieren un razonamiento lógico profundo, codificación y un cumplimiento preciso de instrucciones de varios pasos. Aunque GPT-4o es rápido y conversacional, algunos usuarios consideran que puede ser más superficial o, en ocasiones, pasar por alto elementos detallados del prompt.
Elige GPT-4 Turbo para la resolución de problemas complejos y tareas que necesiten un razonamiento lógico profundo. Opta por GPT-4o para chats de alto volumen en tiempo real y cualquier tarea que involucre entradas multimodales nativas como analizar capturas de pantalla o audio de los clientes.
GPT-4o ofrece multimodalidad nativa, lo que significa que puede procesar y entender texto, audio e imágenes directamente dentro de un único modelo. Esto permite interacciones con el cliente más naturales, como analizar una captura de pantalla de un error o un video corto, algo que GPT-4 Turbo no puede hacer por sí solo.
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.