
Le monde de l'IA évolue à un rythme effréné. À peine a-t-on le temps de comprendre un modèle qu'un autre débarque, promettant d'être plus rapide, plus intelligent et moins cher. La dernière grande sortie, GPT-4o, ne fait pas exception. C'est le nouveau successeur brillant de GPT-4 Turbo d'OpenAI, et sur le papier, les benchmarks sont fantastiques.
Mais voici la vraie question pour quiconque dirige une entreprise : comment se comporte-t-il dans le monde réel ? Lorsque vous développez un agent IA pour une tâche aussi importante que le support client, les spécifications sur une page web ne disent pas tout. Ce guide est une comparaison pratique et sans fioritures entre GPT-4 Turbo et GPT-4o. Nous allons dépasser les benchmarks pour examiner ce qui compte vraiment pour votre rentabilité : la performance sous pression, la précision sur des tâches délicates et le coût réel de fonctionnement de votre IA.
GPT-4 Turbo vs GPT-4o : que sont ces modèles ?
Avant d'entrer dans les détails, faisons un rapide tour d'horizon pour voir ce que chacun de ces modèles apporte.
Qu'est-ce que GPT-4 Turbo ?
GPT-4 Turbo a été déployé comme une mise à niveau majeure du GPT-4 original. Vous pouvez le considérer comme la version raffinée et plus efficace de la famille. Il a été conçu pour être plus rapide, moins cher et capable de gérer beaucoup plus de contexte avec son immense fenêtre de 128k tokens. Ses connaissances sont à jour jusqu'en avril 2023, et il est rapidement devenu le favori des développeurs créant des applications qui nécessitaient la puissance de GPT-4 sans son prix initial élevé.
Qu'est-ce que GPT-4o ?
GPT-4o, où le « o » signifie « omni », est le nouveau modèle phare d'OpenAI. Ce n'est pas juste une petite mise au point ; c'est un tout nouveau moteur. Son plus grand argument de vente est sa multimodalité native, ce qui est une façon élégante de dire qu'il peut comprendre le texte, l'audio et les images ensemble dans un seul modèle. Cela rend les interactions beaucoup plus naturelles et humaines. En plus de cela, il fournit des réponses beaucoup plus rapidement et coûte 50 % de moins que GPT-4 Turbo, ce qui le positionne comme la nouvelle référence pour l'IA interactive en temps réel.
Performance et vitesse : ce que les benchmarks ne disent pas
Sur le papier, le débat sur la vitesse semble assez clair. OpenAI affirme que GPT-4o est deux fois plus rapide que GPT-4 Turbo, et les premiers tests semblent le confirmer. Il a un débit beaucoup plus élevé (le nombre de mots qu'il peut générer par seconde), donc pour une entreprise, des réponses plus rapides devraient signifier des clients plus satisfaits. Une victoire nette, n'est-ce pas ?
Eh bien, pas si vite. Le problème avec ces chiffres, c'est qu'ils ne sont pas gravés dans le marbre. Les performances réelles des modèles à la carte peuvent être de véritables montagnes russes. Comme l'ont montré de bonnes analyses de firmes comme New Relic, lorsqu'un nouveau modèle devient populaire, ses performances peuvent commencer à baisser sous la forte charge. Le modèle ultra-rapide que vous avez testé la semaine dernière pourrait sembler lent cette semaine.
Cela crée un véritable casse-tête pour toute entreprise qui dépend de temps de réponse constants et prévisibles pour son IA destinée aux clients. Un bot lent peut être encore plus frustrant qu'aucun bot du tout, conduisant à une expérience client véritablement mauvaise. C'est là que le simple fait de choisir le « dernier et meilleur » modèle peut se retourner contre vous. Vous avez besoin d'un moyen de tester et de confirmer les performances avant de le lâcher dans la nature.
C'est exactement pourquoi la simulation est si importante. Au lieu de lancer un nouveau modèle en croisant les doigts, une plateforme comme eesel AI vous permet d'exécuter n'importe quelle configuration d'IA dans un puissant mode de simulation. Vous pouvez la tester sur des milliers de vos propres tickets de support passés pour voir précisément comment elle se comportera, quel sera son taux de résolution et à quelle vitesse elle répondra. Cela vous permet de dé-risquer complètement le déploiement d'un nouveau modèle avant qu'il n'interagisse avec un client réel.

Comparaison directe des performances
Voici un aperçu rapide de la comparaison des deux modèles sur les principaux indicateurs de performance.
| Caractéristique | GPT-4 Turbo | GPT-4o (« Omni ») |
|---|---|---|
| Débit | ~20 tokens/seconde | ~109 tokens/seconde (au lancement) |
| Latence | Plus élevée | Plus faible |
| Fiabilité en conditions réelles | Plus prévisible (surtout avec les versions provisionnées) | Variable ; peut ralentir sous forte charge |
| Multimodalité | Texte, images | Texte, images, audio, vidéo natifs |
Précision et raisonnement pour les tâches professionnelles
La vitesse n'est qu'une pièce du puzzle. À quoi bon une réponse rapide si elle est fausse ou passe complètement à côté de l'objet de vos instructions ? C'est là que le débat GPT-4 Turbo vs GPT-4o devient vraiment intéressant.
Si vous passez un peu de temps sur des forums communautaires comme Reddit ou les propres forums de développeurs d'OpenAI, vous remarquerez une tendance : de nombreux développeurs s'appuient encore sur GPT-4 Turbo pour les tâches complexes. Ils le trouvent plus fiable pour des choses comme le codage, la résolution de casse-têtes logiques et le suivi d'instructions détaillées en plusieurs étapes.
En revanche, GPT-4o est parfois décrit comme étant un peu plus « superficiel ». Bien qu'il soit incroyablement rapide et conversationnel, certains utilisateurs ont constaté qu'il peut se retrouver coincé dans des boucles, ignorer des parties d'une invite détaillée ou perdre le fil du contexte de la conversation. C'est un compromis classique : avez-vous besoin d'une vitesse fulgurante ou d'une profondeur réfléchie ?
Pour une équipe de support, cela a des conséquences très réelles. GPT-4o pourrait être parfait pour traiter rapidement des questions simples et répétitives de niveau 1. Mais pour guider un client à travers un processus de dépannage compliqué ou gérer une question de facturation sensible, le raisonnement légèrement plus lent mais plus robuste de GPT-4 Turbo pourrait encore être le meilleur choix.
La capacité à « piloter » un modèle et à guider son comportement est un facteur énorme ici. C'est pourquoi il est si important d'avoir une solide couche de contrôle entre vous et le modèle. Par exemple, avec l'éditeur d'invites personnalisable et le moteur de workflow d'eesel AI, vous obtenez un contrôle total sur votre IA. Vous pouvez affiner sa personnalité, définir des règles strictes sur ce dont il peut parler ou non, et créer des actions personnalisées qu'il peut entreprendre. Cela vous donne les garde-fous pour guider n'importe quel modèle, en vous assurant qu'il fournit des réponses précises et conformes à votre marque, et qu'il escalade de manière fiable les problèmes délicats lorsque c'est nécessaire.

Quand utiliser chaque modèle
Voici une répartition simple pour vous aider à décider :
-
Choisissez GPT-4 Turbo pour :
- La résolution de problèmes complexes en plusieurs étapes, comme le support technique ou l'analyse financière.
- Les tâches où vous avez besoin que l'IA suive des instructions détaillées à la lettre.
- Les situations où un raisonnement logique approfondi est plus important qu'une réponse instantanée.
-
Choisissez GPT-4o pour :
- Les chats en temps réel à fort volume, comme un chatbot de première ligne sur un site web.
- Les tâches multimodales, comme l'analyse de la capture d'écran d'un message d'erreur d'un client.
- Les applications où la vitesse et le coût sont vos principales priorités.
Coût et capacités : au-delà du prix affiché
Parlons argent. À première vue, GPT-4o est le grand gagnant, étant 50 % moins cher pour l'utilisation de l'API que GPT-4 Turbo. Pour toute entreprise travaillant à grande échelle, ce genre d'économie est difficile à ignorer.
Mais il y a un coût caché que vous devez surveiller : la consommation de tokens. Comme l'a également noté l'analyse de New Relic, il est assez courant que les modèles plus récents et plus conversationnels soient un peu plus « bavards ». Ils peuvent utiliser plus de mots (et donc, plus de tokens) pour dire la même chose. Ainsi, un modèle 50 % moins cher par token mais qui utilise 20 % de tokens en plus pour chaque réponse ne réduira pas réellement votre facture de moitié. Cela peut entraîner des coûts opérationnels imprévisibles et difficiles à budgétiser, surtout si votre volume de support fluctue.
Bien sûr, la fonctionnalité phare de GPT-4o est sa multimodalité native. C'est un énorme avantage pour les équipes de support. Un client peut envoyer une photo d'une pièce cassée, une capture d'écran d'un bug logiciel, ou même une courte vidéo, et l'IA peut le comprendre directement. C'est un moyen incroyablement puissant de résoudre les problèmes plus rapidement, et c'est quelque chose que GPT-4 Turbo ne peut tout simplement pas faire seul.
Les coûts imprévisibles sont l'un des plus grands obstacles lorsque vous essayez de développer l'automatisation du support. C'est pourquoi un outil comme eesel AI utilise une tarification transparente et prévisible. Nos forfaits sont basés sur un nombre défini d'interactions IA mensuelles, sans frais cachés par résolution. Cette approche vous protège des factures surprises si une mise à jour de modèle rend soudainement votre agent IA beaucoup plus bavard, vous permettant de budgétiser avec confiance et de vous développer sans crainte.

Tarification officielle
Comme promis, voici la tarification officielle de l'API directement d'OpenAI. N'oubliez pas que ces prix peuvent changer, il est donc toujours judicieux de vérifier la source pour les chiffres les plus récents.
| Modèle | Coût d'entrée (input) | Coût de sortie (output) |
|---|---|---|
| GPT-4 Turbo | 10,00 $ | 30,00 $ |
| GPT-4o | 5,00 $ | 15,00 $ |
Note : Les prix sont par million de tokens et sont sujets à changement. Vérifiez toujours la page de tarification officielle d'OpenAI pour les informations les plus à jour.
GPT-4 Turbo vs GPT-4o : quel modèle choisir ?
Alors, après tout cela, qui remporte le match GPT-4 Turbo vs GPT-4o ? La réponse honnête est : cela dépend. Il n'y a pas un seul modèle « meilleur » pour tout le monde. Le bon choix dépend de vos besoins spécifiques.
GPT-4o est le champion incontesté de la vitesse, du coût et de toute tâche impliquant des images, de l'audio ou de la vidéo. Pour le chat en temps réel à fort volume, c'est le nouveau roi. Cependant, GPT-4 Turbo reste un concurrent de poids pour les tâches complexes et à enjeux élevés où le raisonnement approfondi et la fiabilité sont les plus importants.
Le principal enseignement ici n'est pas de choisir un modèle plutôt qu'un autre. Il s'agit de reconnaître que la construction d'une IA efficace et fiable pour votre entreprise nécessite plus que de simplement se connecter à la dernière API. Elle nécessite une plateforme qui vous permet de tester, contrôler et déployer ces outils puissants en toute confiance.
La manière intelligente de déployer le support par IA
Trouver le juste équilibre entre vitesse, coût et précision est le défi central de la création d'un excellent agent de support IA. Vous avez besoin d'une solution qui s'intègre à vos outils existants, apprend des connaissances de votre entreprise et vous donne le pouvoir d'affiner toute l'expérience client.
eesel AI est une plateforme d'IA conçue pour faire exactement cela. Elle se connecte directement à votre service d'assistance (comme Zendesk ou Freshdesk) et à toutes vos sources de connaissances pour automatiser le support dès sa mise en service.
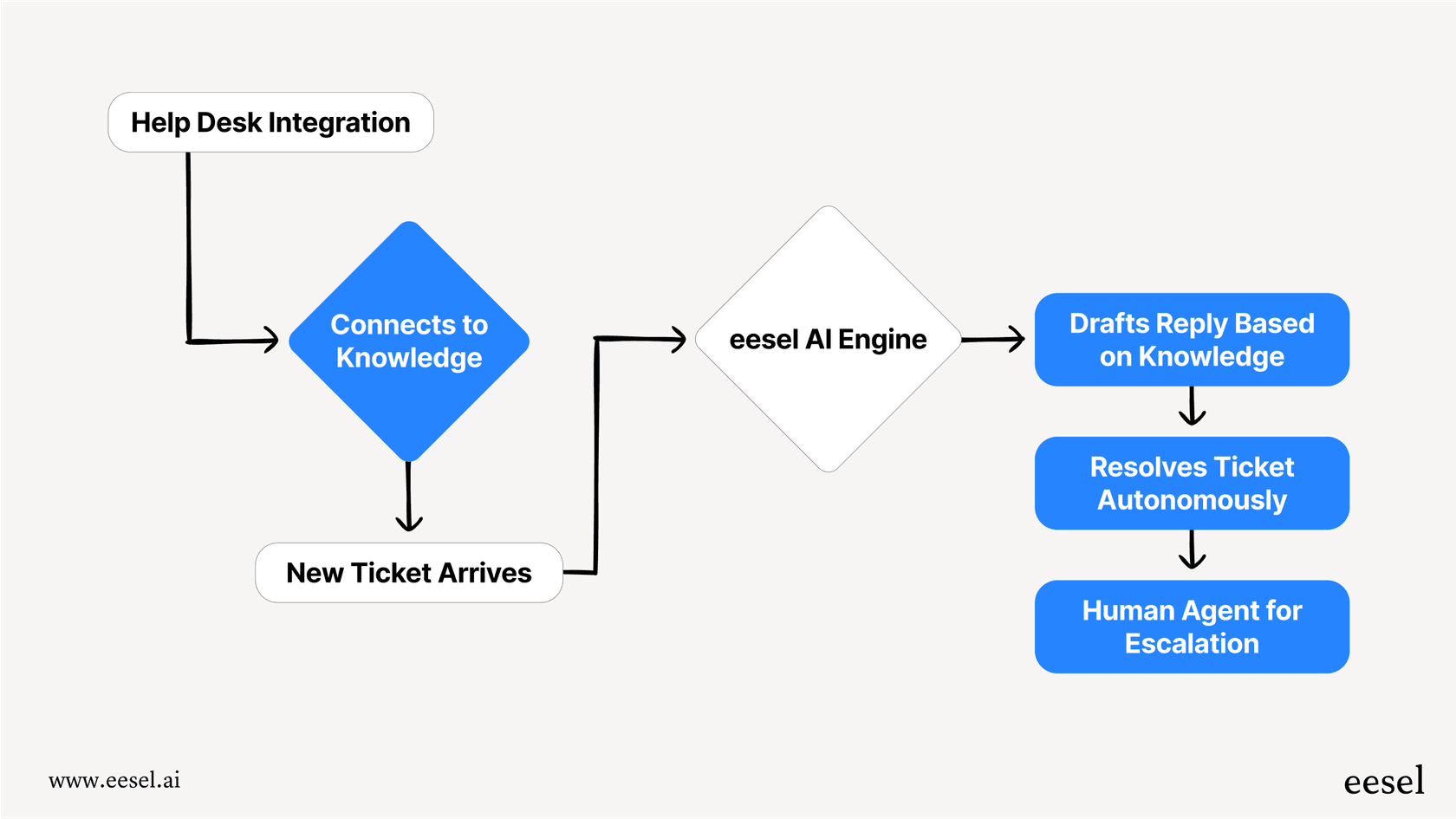
Avec des fonctionnalités puissantes comme la simulation sans risque, un moteur de workflow entièrement personnalisable et une tarification prévisible, eesel vous permet d'exploiter le meilleur des modèles d'OpenAI sans les maux de tête opérationnels et les risques techniques. Vous pouvez être opérationnel en quelques minutes, pas en quelques mois, et enfin construire une expérience de support IA dont vous pouvez être vraiment fier.
Foire aux questions
La principale distinction est que GPT-4o est un modèle plus récent, [nativement multimodal](https://learn.microsoft.com/en-us/answers/questions/1689547/choosing-between-gpt-4-turbo-and-gpt-4o-evaluating) capable de comprendre ensemble le texte, l'audio et les images, offrant des réponses plus rapides et des coûts d'API inférieurs. GPT-4 Turbo est un modèle de texte et d'image très affiné, connu pour son efficacité et sa plus grande fenêtre de contexte.
GPT-4o est généralement plus rapide avec un débit plus élevé sur le papier, mais sa fiabilité en conditions réelles peut varier unter une charge importante. GPT-4 Turbo, en particulier les versions provisionnées, tend à offrir des performances plus prévisibles, ce qui est crucial pour une [expérience client](https://www.eesel.ai/fr/blog/customer-experience-automation) constante.
Oui, bien que GPT-4o ait des coûts d'API par token plus bas, il peut parfois être plus « bavard », utilisant potentiellement plus de tokens par interaction. Cette consommation accrue de tokens peut compenser une partie des économies par token, entraînant des coûts opérationnels moins prévisibles.
De nombreux développeurs préfèrent encore GPT-4 Turbo pour les tâches complexes nécessitant un raisonnement logique approfondi, du codage et un respect précis des instructions en plusieurs étapes. Bien que GPT-4o soit rapide et conversationnel, certains utilisateurs trouvent qu'il peut être plus superficiel ou manquer occasionnellement des éléments détaillés de l'invite.
Choisissez GPT-4 Turbo pour la résolution de problèmes complexes et les tâches nécessitant un raisonnement logique approfondi. Optez pour GPT-4o pour les chats en temps réel à fort volume et toute tâche impliquant des entrées multimodales natives comme l'analyse de captures d'écran ou d'audio de clients.
GPT-4o offre une multimodalité native, ce qui signifie qu'il peut traiter et comprendre directement le texte, l'audio et les images au sein d'un seul modèle. Cela permet des interactions client plus naturelles, comme l'analyse d'une capture d'écran d'erreur d'un client ou d'une courte vidéo, ce que GPT-4 Turbo ne peut pas faire seul.
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.