
Die KI-Welt entwickelt sich in einem schwindelerregenden Tempo. Kaum hat man ein Modell verstanden, kommt schon das nächste auf den Markt und verspricht, schneller, intelligenter und günstiger zu sein. Die neueste große Veröffentlichung, GPT-4o, ist da keine Ausnahme. Es ist OpenAIs glänzender neuer Nachfolger von GPT-4 Turbo, und auf dem Papier sehen die Benchmarks fantastisch aus.
Aber hier ist die eigentliche Frage für jeden, der ein Unternehmen führt: Wie bewährt es sich in der Praxis? Wenn Sie einen KI-Agenten für etwas so Wichtiges wie den Kundensupport entwickeln, erzählen Ihnen die Spezifikationen auf einer Webseite nicht die ganze Geschichte. Dieser Leitfaden ist ein praktischer, schnörkelloser Vergleich von GPT-4 Turbo und GPT-4o. Wir werden die Benchmarks hinter uns lassen und uns ansehen, was für Ihr Geschäft wirklich zählt: Leistung unter Druck, Genauigkeit bei kniffligen Aufgaben und die wahren Kosten für den Betrieb Ihrer KI.
GPT-4 Turbo vs. GPT-4o: Was sind diese Modelle?
Bevor wir ins Detail gehen, lassen Sie uns einen kurzen Überblick geben, was jedes dieser Modelle zu bieten hat.
Was ist GPT-4 Turbo?
GPT-4 Turbo wurde als großes Upgrade zum ursprünglichen GPT-4 eingeführt. Man kann es sich als die verfeinerte, effizientere Version der Familie vorstellen. Es wurde entwickelt, um schneller und kostengünstiger zu sein und mit seinem riesigen 128k-Token-Fenster viel mehr Kontext verarbeiten zu können. Sein Wissen ist auf dem Stand von April 2023, und es wurde schnell zum Favoriten für Entwickler, die Anwendungen erstellen, die die Intelligenz von GPT-4 ohne dessen ursprünglichen, hohen Preis benötigen.
Was ist GPT-4o?
GPT-4o, wobei das „o“ für „omni“ steht, ist OpenAIs neuestes Flaggschiff-Modell. Dies ist nicht nur eine kleine Optimierung, sondern ein völlig neuer Motor. Sein größtes Verkaufsargument ist seine native Multimodalität, was eine schicke Art ist zu sagen, dass es Text, Audio und Bilder in einem einzigen Modell gemeinsam verstehen kann. Dadurch fühlen sich Interaktionen viel natürlicher und menschlicher an. Darüber hinaus liefert es Antworten viel schneller und kostet 50 % weniger als GPT-4 Turbo, was es als den neuen Goldstandard für interaktive KI in Echtzeit positioniert.
Leistung und Geschwindigkeit: Was Benchmarks nicht verraten
Auf dem Papier scheint die Geschwindigkeitsdebatte ziemlich eindeutig zu sein. OpenAI behauptet, GPT-4o sei doppelt so schnell wie GPT-4 Turbo, und erste Tests scheinen dies zu bestätigen. Es hat einen viel höheren Durchsatz (die Anzahl der Wörter, die es pro Sekunde generieren kann), also sollten schnellere Antworten für ein Unternehmen zufriedenere Kunden bedeuten. Ein klarer Sieg, oder?
Nun, nicht so schnell. Das Problem mit diesen Zahlen ist, dass sie nicht in Stein gemeißelt sind. Die reale Leistung von Pay-as-you-go-Modellen kann eine ziemliche Achterbahnfahrt sein. Wie einige großartige Analysen von Firmen wie New Relic gezeigt haben, kann die Leistung eines neuen Modells bei hoher Belastung nachlassen, wenn es populär wird. Das blitzschnelle Modell, das Sie letzte Woche getestet haben, könnte sich diese Woche träge anfühlen.
Dies bereitet jedem Unternehmen, das auf konsistente, vorhersagbare Antwortzeiten für seine kundenorientierte KI angewiesen ist, massive Kopfschmerzen. Ein langsamer Bot kann noch frustrierender sein als gar kein Bot, was zu einer wirklich schlechten Kundenerfahrung führt. Hier kann es sich rächen, einfach das „neueste und beste“ Modell zu nehmen. Sie brauchen eine Möglichkeit, die Leistung zu testen und zu bestätigen, bevor Sie es auf Ihre Kunden loslassen.
Genau aus diesem Grund ist die Simulation so wichtig. Anstatt ein neues Modell zu starten und die Daumen zu drücken, können Sie mit einer Plattform wie eesel AI jedes KI-Setup in einem leistungsstarken Simulationsmodus ausführen. Sie können es an Tausenden Ihrer eigenen vergangenen Support-Tickets testen, um genau zu sehen, wie es sich verhalten wird, wie hoch seine Lösungsrate sein wird und wie schnell es antwortet. So können Sie die Einführung eines neuen Modells vollständig absichern, bevor es jemals mit einem echten Kunden interagiert.

Ein direkter Leistungsvergleich
Hier ist ein kurzer Blick darauf, wie die beiden Modelle bei wichtigen Leistungsmetriken abschneiden.
| Merkmal | GPT-4 Turbo | GPT-4o („Omni“) |
|---|---|---|
| Durchsatz | ~20 Token/Sekunde | ~109 Token/Sekunde (bei Einführung) |
| Latenz | Höher | Niedriger |
| Konsistenz in der Praxis | Vorhersehbarer (besonders bei provisionierten Versionen) | Variabel; kann bei hoher Auslastung langsamer werden |
| Multimodalität | Text, Bilder | Nativ Text, Bilder, Audio, Video |
Genauigkeit und logisches Denken für Geschäftsaufgaben
Geschwindigkeit ist nur ein Teil des Puzzles. Was nützt eine schnelle Antwort, wenn sie falsch ist oder den Sinn Ihrer Anweisungen völlig verfehlt? Hier wird die Debatte GPT-4 Turbo vs. GPT-4o wirklich interessant.
Wenn Sie einige Zeit in Community-Foren wie Reddit oder den Entwicklerforen von OpenAI verbringen, werden Sie ein Muster erkennen: Viele Entwickler setzen immer noch auf GPT-4 Turbo für komplexe Aufgaben. Sie finden es zuverlässiger für Dinge wie Codierung, das Lösen von Logikrätseln und das Befolgen detaillierter, mehrstufiger Anweisungen.
Im Gegensatz dazu wird GPT-4o manchmal als etwas „oberflächlicher“ beschrieben. Obwohl es unglaublich schnell und gesprächig ist, haben einige Benutzer festgestellt, dass es in Schleifen stecken bleiben, Teile einer detaillierten Anweisung ignorieren oder den Kontext des Gesprächs verlieren kann. Es ist ein klassischer Kompromiss: Brauchen Sie rasante Geschwindigkeit oder durchdachte Tiefe?
Für ein Support-Team hat dies sehr reale Konsequenzen. GPT-4o mag perfekt sein, um einfache, repetitive Tier-1-Fragen schnell abzuarbeiten. Aber um einen Kunden durch einen komplizierten Fehlerbehebungsprozess zu führen oder eine sensible Abrechnungsfrage zu behandeln, könnte die etwas langsamere, aber robustere Denkfähigkeit von GPT-4 Turbo immer noch die bessere Wahl sein.
Wie gut Sie ein Modell „steuern“ und sein Verhalten lenken können, ist hier ein entscheidender Faktor. Deshalb ist eine starke Kontrollschicht zwischen Ihnen und dem Modell so wichtig. Mit dem anpassbaren Prompt-Editor und der Workflow-Engine von eesel AI haben Sie beispielsweise die volle Kontrolle über Ihre KI. Sie können ihre Persönlichkeit feinabstimmen, strenge Regeln festlegen, worüber sie sprechen darf und worüber nicht, und benutzerdefinierte Aktionen erstellen, die sie ausführen kann. Dies gibt Ihnen die Leitplanken, um jedes Modell zu führen und sicherzustellen, dass es genaue, markenkonforme Antworten liefert und knifflige Probleme bei Bedarf zuverlässig eskaliert.

Wann welches Modell verwenden
Hier ist eine einfache Aufschlüsselung, um Ihnen bei der Entscheidung zu helfen:
-
Wählen Sie GPT-4 Turbo für:
- Komplexe, mehrstufige Problemlösungen, wie technischer Support oder Finanzanalysen.
- Aufgaben, bei denen die KI detaillierte Anweisungen buchstabengetreu befolgen muss.
- Situationen, in denen tiefes logisches Denken wichtiger ist als eine sofortige Antwort.
-
Wählen Sie GPT-4o für:
- Chats mit hohem Volumen in Echtzeit, wie ein Chatbot an der vordersten Front Ihrer Website.
- Multimodale Aufgaben, wie die Analyse eines Screenshots einer Fehlermeldung eines Kunden.
- Anwendungen, bei denen Geschwindigkeit und Kosten Ihre obersten Prioritäten sind.
Kosten und Fähigkeiten: Ein Blick hinter den Preis
Lassen Sie uns über Geld sprechen. Oberflächlich betrachtet ist GPT-4o der klare Gewinner, da es bei der API-Nutzung 50 % günstiger ist als GPT-4 Turbo. Für jedes Unternehmen, das in großem Maßstab arbeitet, ist eine solche Ersparnis schwer zu ignorieren.
Aber es gibt versteckte Kosten, die Sie im Auge behalten müssen: den Token-Verbrauch. Wie die Analyse von New Relic ebenfalls feststellte, ist es ziemlich üblich, dass neuere, gesprächigere Modelle etwas „geschwätziger“ sind. Sie könnten mehr Wörter (und damit mehr Token) verwenden, um dasselbe zu sagen. Ein Modell, das pro Token 50 % billiger ist, aber für jede Antwort 20 % mehr Token verbraucht, wird Ihre Rechnung also nicht wirklich halbieren. Dies kann zu unvorhersehbaren Betriebskosten führen, die schwer zu budgetieren sind, besonders wenn Ihr Support-Volumen schwankt.
Natürlich ist das Killer-Feature von GPT-4o seine native Multimodalität. Dies ist für Support-Teams eine enorme Sache. Ein Kunde kann ein Bild eines kaputten Teils, einen Screenshot eines Softwarefehlers oder sogar ein kurzes Video senden, und die KI kann es direkt verstehen. Das ist eine unglaublich leistungsstarke Methode, um Probleme schneller zu lösen, und etwas, das GPT-4 Turbo allein nicht kann.
Unvorhersehbare Kosten sind eine der größten Hürden, wenn Sie versuchen, die Support-Automatisierung zu skalieren. Deshalb verwendet ein Tool wie eesel AI transparente und vorhersehbare Preise. Unsere Pläne basieren auf einer festgelegten Anzahl monatlicher KI-Interaktionen, ohne versteckte Gebühren pro Lösung. Dieser Ansatz schützt Sie vor überraschenden Rechnungen, falls ein Modell-Update Ihren KI-Agenten plötzlich viel gesprächiger macht, sodass Sie mit Zuversicht budgetieren und ohne Angst skalieren können.

Offizielle Preise
Wie versprochen, hier sind die offiziellen API-Preise direkt von OpenAI. Denken Sie daran, dass sich diese Preise ändern können, daher ist es immer klug, die Quelle für die neuesten Zahlen zu überprüfen.
| Modell | Input-Kosten | Output-Kosten |
|---|---|---|
| GPT-4 Turbo | 10,00 $ | 30,00 $ |
| GPT-4o | 5,00 $ | 15,00 $ |
Hinweis: Die Preise gelten pro 1 Million Token und können sich ändern. Überprüfen Sie immer die offizielle OpenAI-Preisseite für die aktuellsten Informationen.
GPT-4 Turbo vs. GPT-4o: Welches Modell sollten Sie wählen?
Also, wer gewinnt nach all dem den Vergleich zwischen GPT-4 Turbo und GPT-4o? Die ehrliche Antwort ist: Es kommt darauf an. Es gibt kein einziges „besseres“ Modell für jeden. die richtige Wahl hängt von Ihren spezifischen Bedürfnissen ab.
GPT-4o ist der unangefochtene Champion in Bezug auf Geschwindigkeit, Kosten und alle Aufgaben, die Bilder, Audio oder Video beinhalten. Für Echtzeit-Chats mit hohem Volumen ist es der neue König. GPT-4 Turbo ist jedoch immer noch ein Schwergewichtskandidat für komplexe, anspruchsvolle Aufgaben, bei denen tiefes logisches Denken und Zuverlässigkeit am wichtigsten sind.
Die wichtigste Erkenntnis hier ist nicht, ein Modell über das andere zu stellen. Es geht darum zu erkennen, dass der Aufbau einer effektiven, zuverlässigen KI für Ihr Unternehmen mehr erfordert als nur das Anschließen an die neueste API. Es erfordert eine Plattform, mit der Sie diese leistungsstarken Werkzeuge mit Vertrauen testen, steuern und einsetzen können.
Der intelligentere Weg, KI-Support bereitzustellen
Die richtige Balance zwischen Geschwindigkeit, Kosten und Genauigkeit zu finden, ist die zentrale Herausforderung beim Aufbau eines großartigen KI-Support-Agenten. Sie benötigen eine Lösung, die sich in Ihre bestehenden Werkzeuge einfügt, aus dem Wissen Ihres Unternehmens lernt und Ihnen die Möglichkeit gibt, das gesamte Kundenerlebnis feinabzustimmen.
eesel AI ist eine KI-Plattform, die genau dafür entwickelt wurde. Sie lässt sich direkt in Ihren Helpdesk (wie Zendesk, Freshdesk oder [Intercom]) integrieren und verbindet sich mit all Ihren Wissensquellen, um den Support sofort zu automatisieren.
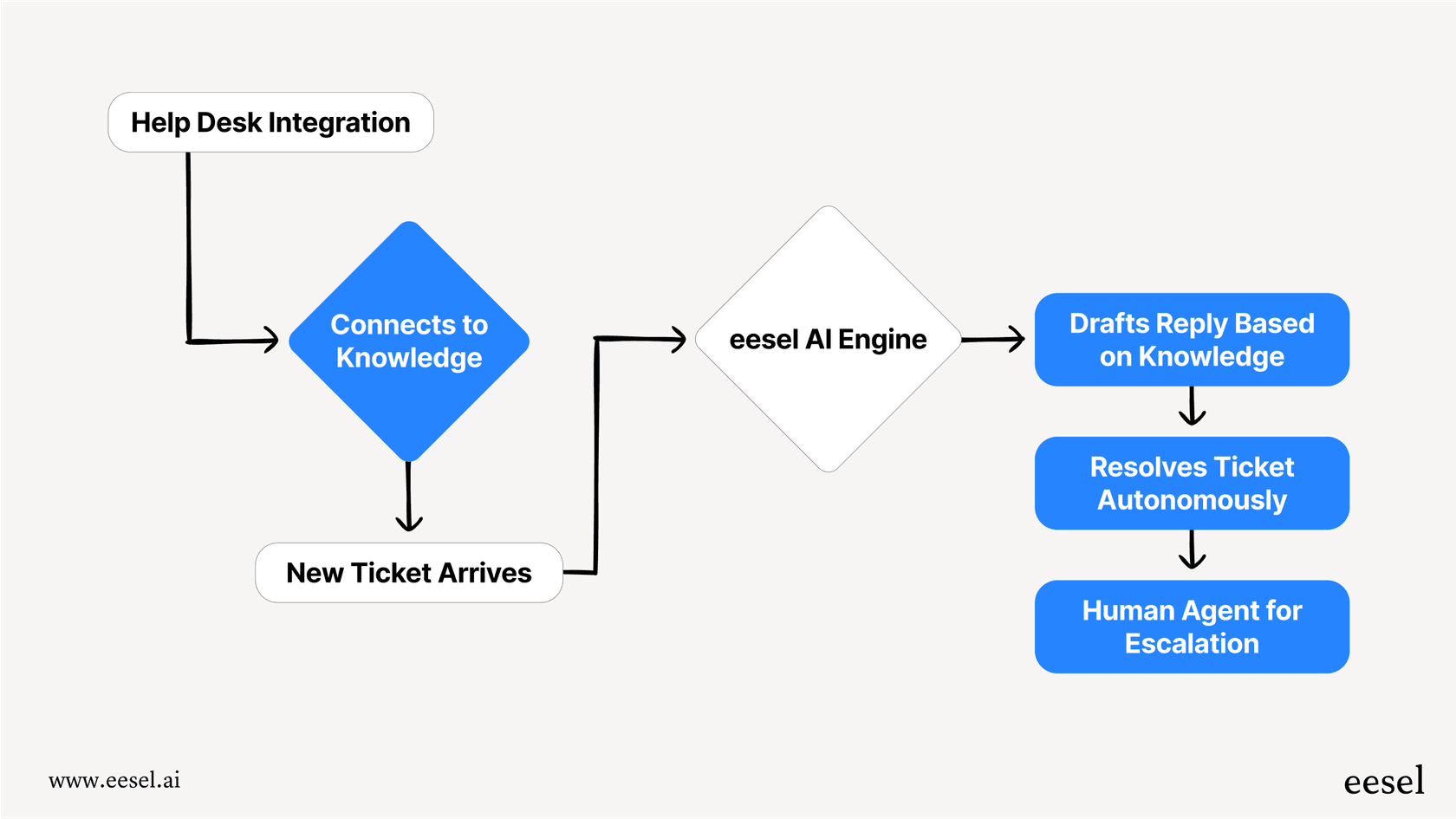
Mit leistungsstarken Funktionen wie risikofreier Simulation, einer vollständig anpassbaren Workflow-Engine und vorhersehbaren Preisen können Sie mit eesel das Beste aus den OpenAI-Modellen herausholen, ohne die betrieblichen Kopfschmerzen und technischen Risiken. Sie können in Minuten statt Monaten live gehen und endlich ein KI-Support-Erlebnis schaffen, auf das Sie wirklich stolz sein können.
Häufig gestellte Fragen
Der Hauptunterschied besteht darin, dass GPT-4o ein neueres, [nativ multimodales Modell](https://learn.microsoft.com/en-us/answers/questions/1689547/choosing-between-gpt-4-turbo-and-gpt-4o-evaluating) ist, das Text, Audio und Bilder gemeinsam verstehen kann und schnellere Antworten sowie niedrigere API-Kosten bietet. GPT-4 Turbo ist ein hochentwickeltes Text- und Bildmodell, das für seine Effizienz und sein größeres Kontextfenster bekannt ist.
GPT-4o ist auf dem Papier im Allgemeinen schneller und hat einen höheren Durchsatz, aber seine reale Konsistenz kann bei hoher Auslastung variieren. GPT-4 Turbo, insbesondere provisionierte Versionen, bietet tendenziell eine vorhersagbarere Leistung, was für eine konsistente [Kundenerfahrung](https://www.eesel.ai/de/blog/customer-experience-automation) entscheidend ist.
Ja, obwohl GPT-4o niedrigere API-Kosten pro Token hat, kann es manchmal „gesprächiger“ sein und potenziell mehr Token pro Interaktion verwenden. Dieser erhöhte Token-Verbrauch kann einen Teil der Einsparungen pro Token wieder aufheben, was zu weniger vorhersehbaren Betriebskosten führt.
Viele Entwickler bevorzugen immer noch GPT-4 Turbo für komplexe Aufgaben, die tiefes logisches Denken, Codierung und die präzise Einhaltung mehrstufiger Anweisungen erfordern. Während GPT-4o schnell und gesprächig ist, finden einige Benutzer, dass es oberflächlicher sein oder gelegentlich detaillierte Elemente in Anweisungen übersehen kann.
Wählen Sie GPT-4 Turbo für komplexe Problemlösungen und Aufgaben, die tiefes logisches Denken erfordern. Entscheiden Sie sich für GPT-4o für Chats mit hohem Volumen in Echtzeit und für alle Aufgaben, die native multimodale Eingaben wie die Analyse von Kunden-Screenshots oder Audio beinhalten.
GPT-4o bietet native Multimodalität, was bedeutet, dass es Text, Audio und Bilder direkt in einem einzigen Modell verarbeiten und verstehen kann. Dies ermöglicht natürlichere Kundeninteraktionen, wie die Analyse eines Screenshots eines Fehlers oder eines kurzen Videos eines Kunden, was GPT-4 Turbo allein nicht kann.
Share this article

Article by
Stevia Putri
Stevia Putri is a marketing generalist at eesel AI, where she helps turn powerful AI tools into stories that resonate. She’s driven by curiosity, clarity, and the human side of technology.