Embeddings
Embeddings are numerical representations of text, images, or other data as vectors, where items with similar meaning sit close together in the vector space.
What embeddings mean
Embeddings are numerical representations of data, such as text, images, or audio, expressed as vectors of numbers so that items with similar meaning end up close together in a shared mathematical space. Instead of treating "refund" and "money back" as unrelated strings, an embedding model places them near each other because they mean nearly the same thing. The distance between two vectors becomes a measure of how related the two pieces of content are.
In customer support, embeddings are what let an AI understand that a customer asking "how do I get my money back" is really asking about your refund policy, even though none of the policy's wording appears in the question. They turn fuzzy human phrasing into something a machine can compare and rank, which is the first step in finding the right answer.
Why embeddings matter
- They capture meaning, not spelling, so a question and the article that answers it can match even when they share no exact words.
- They make content comparable, since once everything is a vector you can measure similarity with simple math and rank results by relevance.
- They are the foundation of semantic search, which retrieves by intent rather than by keyword overlap.
- They power retrieval for grounding. The relevant chunks an AI pulls before answering are almost always selected by embedding similarity.
- They work across formats, so the same approach can compare text to text, or even text to images, inside a multimodal AI setup.
It helps to picture this as a map where meaning, not spelling, decides where things sit.
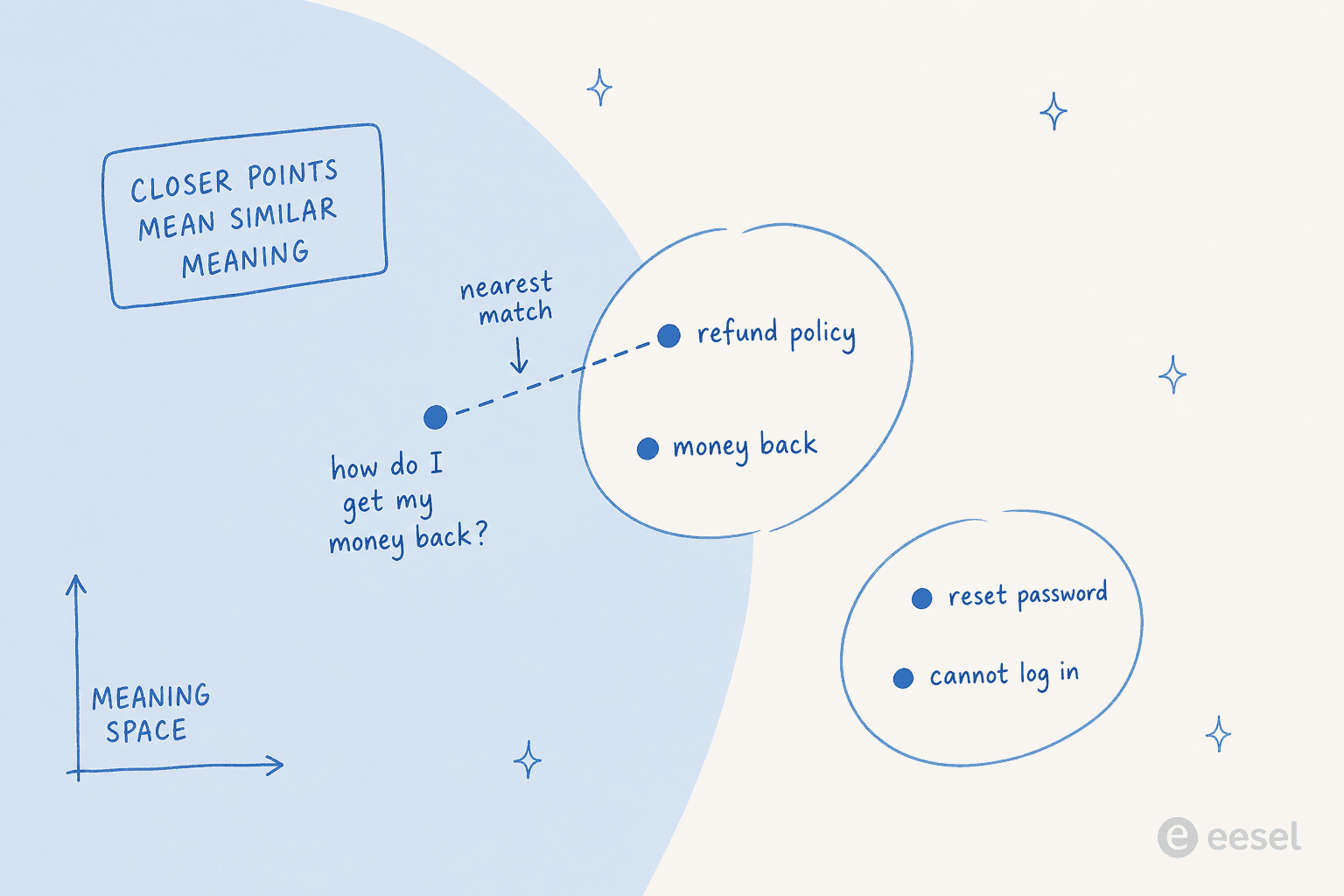
Phrases that mean the same thing land in the same neighborhood, so a question like "how do I get my money back" falls right next to your refund content, while login questions sit in a different region entirely. Retrieval is then just finding the points nearest to the question.
How embeddings work
The pattern is consistent across most AI retrieval systems:
- Convert content to vectors. An embedding model reads each chunk of your knowledge base and outputs a vector that encodes its meaning.
- Store the vectors. Those vectors go into a vector database designed to compare them at speed.
- Embed the query. When a customer asks a question, the same model turns the question into a vector too.
- Find the nearest matches. The system retrieves the stored vectors closest to the query vector, which are the most semantically relevant passages.
A support agent like eesel AI runs exactly this loop: it embeds your help center, internal docs, and historical tickets, then embeds each incoming question and pulls the closest passages to ground its reply. The quality of the answer depends heavily on the quality of the retrieval, and the retrieval depends on the embeddings.
Embeddings in practice
The operator-level detail most people miss is that how you split your content into chunks before embedding it shapes the results as much as the model does. Chunks that are too large blur several topics into one vector, and chunks that are too small lose context, so a passage embeds without the surrounding detail that made it useful. Good retrieval comes from clean, well-structured source content and sensible chunking, which is why a tidy help center quietly does more for answer quality than any clever prompt.
For a deeper walkthrough, read our embeddings guide.
Embeddings that find the right answer
eesel AI embeds your help center and tickets so it retrieves the most relevant content before it answers a customer.