Pourquoi la réduction de tickets par IA revient en tête de l'agenda CX
Les responsables du support n'obtiennent pas de budgets plus importants. En revanche, ils font face à des files d'attente bien plus longues. 53 % des praticiens du service client en 2025 ont cité la « gestion du volume de tickets sans augmenter les effectifs » comme leur principal défi, selon le rapport Customer Benchmark 2025 de Freshworks, et 90 % des agents dans les services aux entreprises déclarent que les tâches répétitives les empêchent de traiter les tickets à haute valeur ajoutée.
L'argument économique se construit de lui-même dès que l'on place deux chiffres côte à côte. Un ticket traité par un humain coûte en moyenne 8 à 12 $ tous secteurs confondus, selon Forrester, et grimpe à 25 à 35 $ dans le SaaS B2B. Un ticket traité par l'IA - même lorsque l'IA consulte des données de compte et effectue une action - coûte en moyenne 0,50 à 1,05 $. C'est un différentiel de coût de 12 à 24 fois par interaction, qui se cumule à chaque ticket réduit.
C'est pourquoi l'IA dans le service client devrait passer de 12,06 milliards de dollars en 2024 à 47,82 milliards en 2030, un TCAC de 25,8 %. Et c'est pourquoi 80 milliards de dollars d'économies mondiales de support projetées d'ici 2027 selon Gartner est la ligne que les acheteurs prennent en capture d'écran.
Mais - et c'est la partie que la plupart des articles ignorent - la raison pour laquelle 47 % des entreprises rapportent des coûts stables ou en hausse après le déploiement de l'IA n'est pas l'IA elle-même. C'est qu'ils l'ont branchée sur les mêmes workflows défaillants et ont appelé le résultat « déviation ». C'est le mode d'échec que la section suivante décortique.
« Déviation » et « réduction » - les mots ont leur importance
Beaucoup de confusion dans ce domaine vient de personnes qui utilisent ces termes de façon interchangeable. Ce n'est pas la même chose.
- La déviation est une tactique : le client obtient une réponse (ou un parcours de libre-service qui lui répond vraiment) avant qu'un ticket ne soit ouvert.
- La réduction est le résultat : moins de tickets nécessitant du temps humain. La réduction inclut la déviation, mais aussi le triage IA qui clôture les tickets en quelques secondes, les brouillons qu'un humain peut envoyer en un clic, et les correctifs proactifs produit/UX qui empêchent la question d'être posée.
Pourquoi cela importe : une équipe qui optimise uniquement pour le taux de déviation rendra discrètement plus difficile l'accès des clients à un humain, comme l'a documenté l'analyse de Corebee de plus de 50 fils de discussion d'équipes support. Une équipe qui optimise pour la réduction examine l'ensemble du funnel - y compris les tickets qui doivent toujours passer à un humain, juste plus rapidement et à moindre coût.
« Je ne crois pas en la déviation des tickets. Je crois à rendre les tickets inutiles. Il y a une différence. La déviation redirige le client. Rendre les tickets inutiles corrige ce qui a causé la question. »
Responsable support cité dans la synthèse de discussions de Corebee.ai
Gardez cette distinction à l'esprit pour le reste de cet article. Quand nous disons « réduction de tickets par IA », nous parlons de l'ensemble du funnel - pas seulement du chiffre de déviation affiché sur un tableau de bord.
Le problème des 14 % : ce que la plupart des tableaux de bord de déviation ne vous disent pas
Voici le chiffre le plus important de tout cet article, et c'est celui que presque personne ne cite :
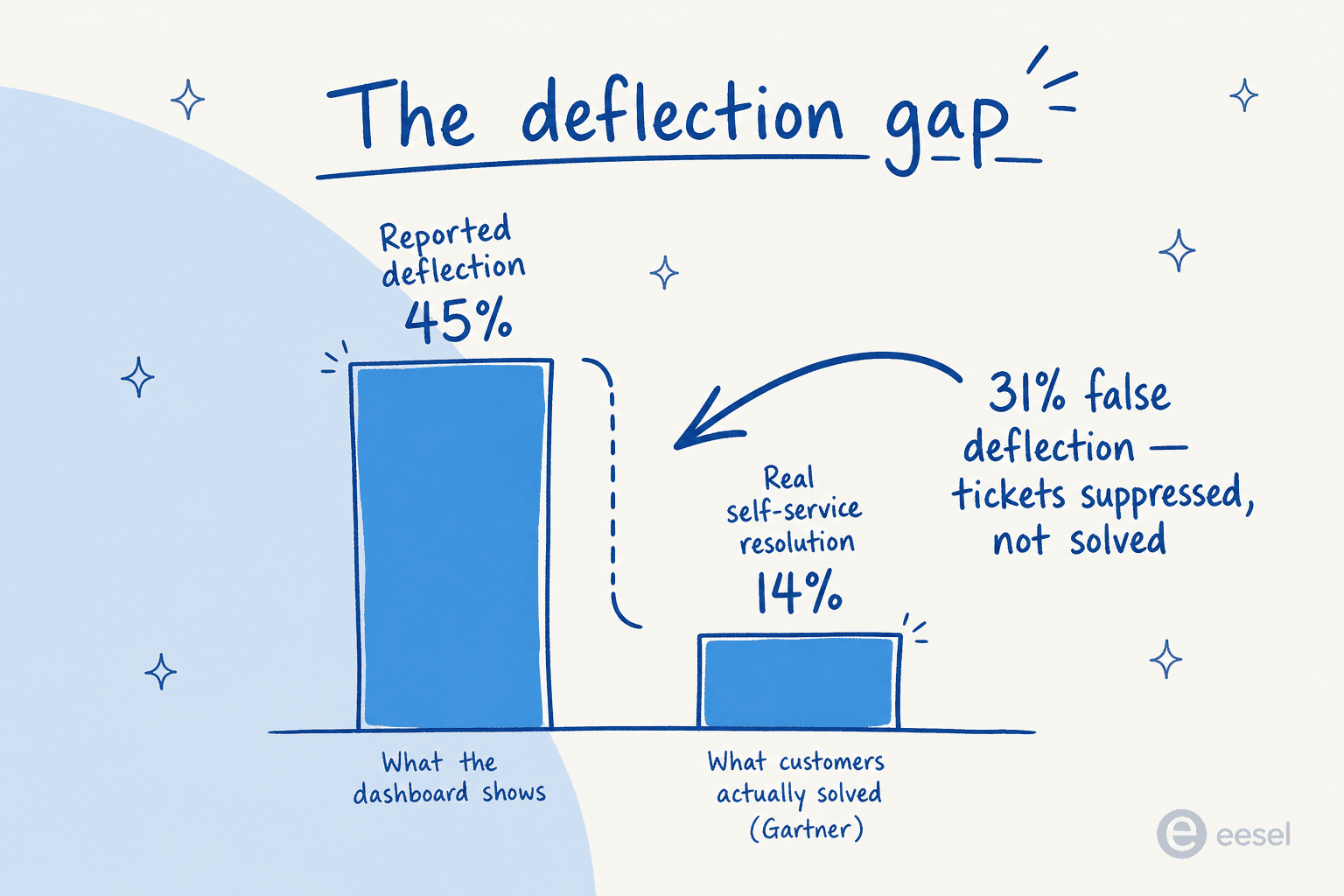
Gartner constate que l'IA dévie plus de 45 % des demandes clients - mais seulement environ 14 % atteignent une résolution complète en libre-service. Les ~31 points de pourcentage restants sont ce que le secteur appelle la fausse déviation : le ticket n'a jamais été ouvert sur votre plateforme, mais le client n'a pas obtenu d'aide. Il est allé ailleurs - téléphone, e-mail, réseaux sociaux, un concurrent.
Une étude de 100 050 interactions de support citée par Corebee.ai a mis en évidence le mécanisme d'échec : les bots IA ont 37 % plus de chances d'éloigner les problèmes de la résolution que les humains lorsqu'ils sont configurés pour optimiser le taux de déviation comme KPI. L'objectif du bot devient « fermer la conversation », pas « résoudre le problème ».
L'écart est le plus visible quand les équipes utilisent la formule ajustée :
Taux de déviation réel = (résolutions en libre-service − re-contacts à 48h) ÷ total des tentatives de recherche d'aide
La plupart des équipes qui prennent la peine de calculer ce chiffre constatent que leur taux de déviation réel est 15 à 25 % inférieur au taux déclaré. Un tableau de bord affichant 80 % de déviation peut signifier 55 à 65 % de résolution réelle. Un tableau de bord affichant 50 % peut signifier 35 à 40 %. Connaître votre vrai chiffre est le prérequis pour vraiment l'améliorer.
La leçon à retenir : ne faites pas du taux de déviation un KPI isolé. Suivez-le en parallèle avec le CSAT des conversations résolues par le bot, le taux de re-contact à 48 heures et le taux de changement de canal. Les équipes qui obtiennent des résultats honnêtes font toutes cela ; les équipes qui ont des métriques supprimées ne le font pas.
Ce que la réduction de tickets par IA fait concrètement
Une fois que vous savez quoi mesurer, la prochaine question est ce que fait réellement l'IA quand elle réduit un ticket. La plupart des articles esquivent cela avec « l'IA utilise le NLP et le machine learning ». Voici à quoi ressemble l'architecture en 2026 :
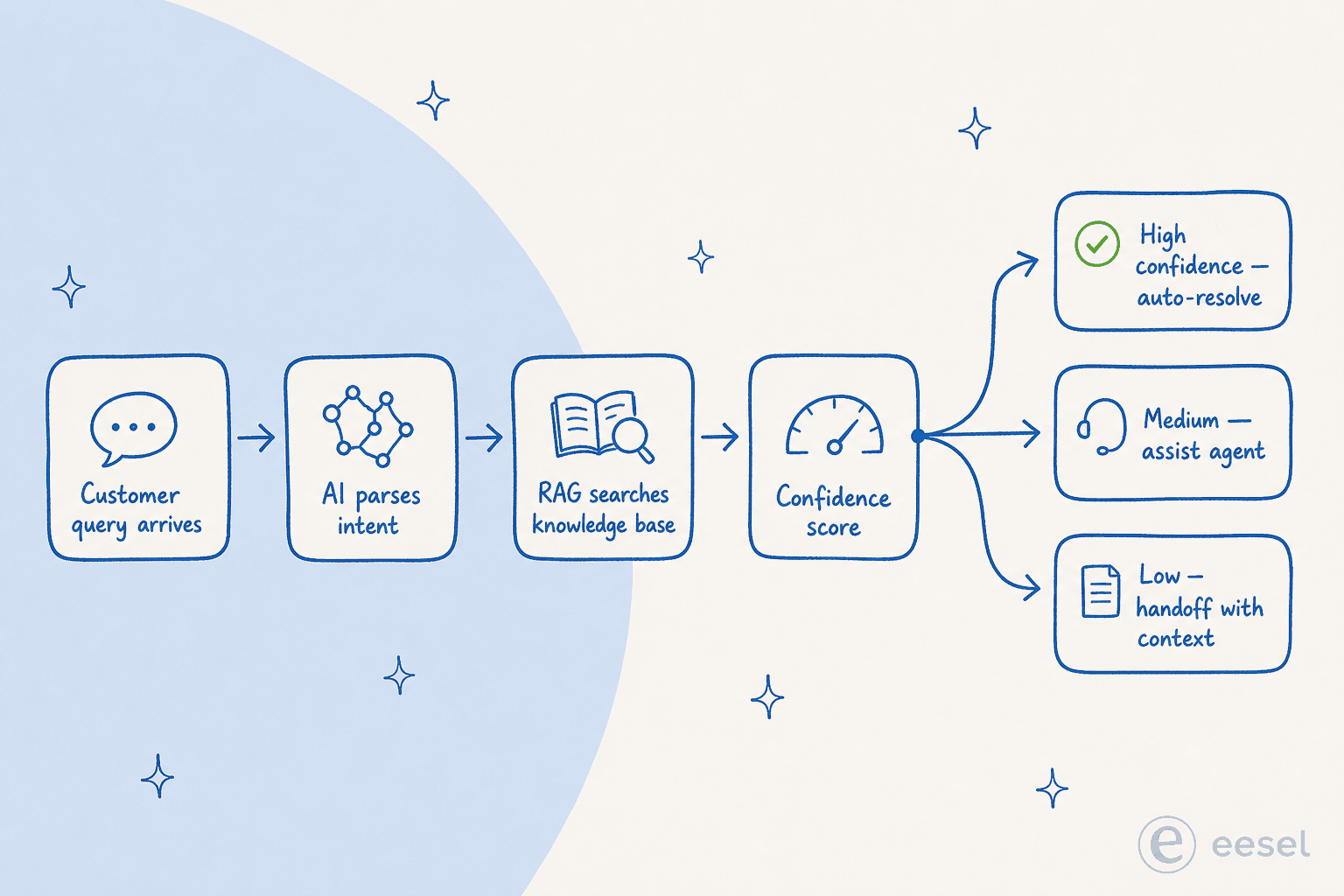
- Analyse d'intention. Un LLM (de la classe GPT-4, Claude, Gemini) lit la demande entrante et extrait l'intention, l'urgence, le sentiment et les entités pertinentes (numéro de commande, niveau de compte, code d'erreur). C'est la couche qui a remplacé les chatbots à correspondance de mots-clés de 2018, et c'est ce qui permet au système de gérer la paraphrase et l'ambiguïté - « mon truc ne fonctionne pas » est routé de la même façon que « je n'arrive pas à me connecter ».
- Récupération depuis la base de connaissances (RAG). Le système encode la demande et votre base de connaissances dans le même espace vectoriel, trouve les articles et résolutions passées qui correspondent sémantiquement, et synthétise une réponse fondée sur le contenu récupéré plutôt que de la générer de zéro. ClarityArc le dit sans détour : « un agent de déviation de tickets est un système de récupération de connaissances avec une interface conversationnelle - son plafond de qualité est déterminé par la qualité de la base de connaissances depuis laquelle il récupère. »
- Score de confiance et routage. Le système attribue un score de confiance et décide de la marche à suivre : confiance élevée → répondre et clôturer ; moyenne → présenter la réponse avec un chemin bien visible vers un humain ; faible → escalader immédiatement avec le contexte complet.
- Actions spécifiques au compte. Le grand déblocage de l'IA agentique : au lieu de simplement récupérer un article, l'agent lit le CRM/système de facturation/commandes et effectue l'action. Consulter une commande, émettre un remboursement, mettre à jour un abonnement. La profondeur d'intégration ajoute 20 à 30 % à la qualité de déviation par rapport à la qualité de la base de connaissances seule, car la plupart des vraies questions ont besoin du contexte du compte, pas de contenu générique.
- Escalade avec transmission du contexte. Quand l'IA ne peut pas gérer la demande, elle ne renvoie pas le client au début. Elle transmet à l'agent humain un résumé complet de la conversation, l'état pertinent du compte et la raison de l'escalade. C'est la différence entre « l'IA a essayé et échoué » et « l'IA a fait le triage pour que l'humain puisse résoudre en 90 secondes ».
Deux avertissements méritent d'être mentionnés ici, car ils font s'effondrer toute la pile quand on les ignore :
- La confiance d'un LLM n'est pas une confiance factuelle. Un LLM peut être confiant à 95 % sur une réponse hallucin ée - les scores de confiance mesurent la probabilité des tokens, pas la vérité. N'utilisez jamais la confiance brute comme seul filtre. Associez-la à des signaux de couverture de la base de connaissances et à des règles de périmètre thématique (post-mortem DEV Community HITL).
- La base de connaissances est votre plafond, pas le modèle. Remplacer GPT-4 par Claude ne corrigera pas un taux de déviation bloqué à 35 %. Mettre à jour votre base de connaissances et resserrer le périmètre, oui.
Ce qui se réduit bien - et ce qui ne se réduit pas
L'autre chiffre que la plupart des couvertures media escamotent : la réduction de tickets par IA n'est pas uniforme selon les types de demandes. Le même agent, sur la même base de connaissances, avec le même modèle, vous donnera des chiffres complètement différents selon ce que vous lui confiez.
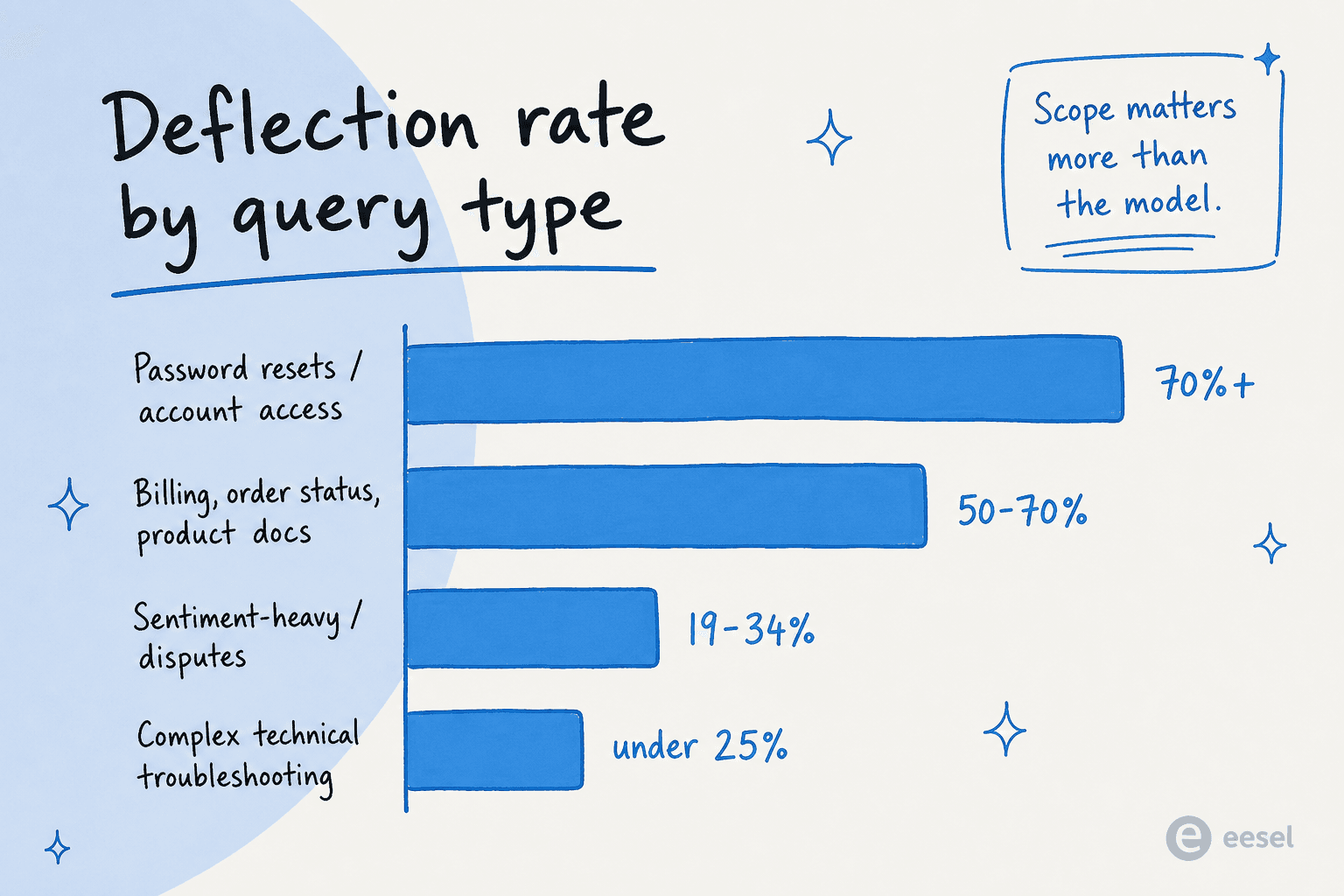
Selon les benchmarks 2026 de ClarityArc et le guide de déviation de Pylon :
| Type de demande | Taux de déviation typique | Pourquoi |
|---|---|---|
| Réinitialisations de mot de passe / accès au compte | 70 %+ | Volume élevé, déterministe, réponse dans le système de référence |
| Statut de commande / WISMO | 50-70 % | Consultation backend une fois les intégrations en place |
| Remboursements et retours (politique standard) | 50-70 % | Base de connaissances claire + action agentique disponible |
| Documentation produit standard / mode d'emploi | 50-70 % | Lié à la base de connaissances, bien documenté |
| Dépannage technique complexe | En dessous de 25 % | Chaque cas est nouveau ; nécessite un raisonnement humain |
| Chargé en émotions / style litigieux | 19-34 % | Contexte émotionnel, pas seulement informationnel |
| Réglementé / sensible à la conformité | En dessous de 20 % | Le risque et la révision priment sur la rapidité |
C'est pourquoi la décision à plus fort levier dans tout projet de réduction de tickets par IA est le périmètre, pas le choix du fournisseur. Choisissez deux ou trois types de demandes dans la moitié supérieure de ce tableau, atteignez 60 à 70 % de déviation réelle, et alors seulement élargissez. Choisir « tout » dès le premier jour tire tellement la moyenne vers le bas que le projet est annulé.
Notre avis : si votre équipe débute, commencez par les réinitialisations de mot de passe et le WISMO. Ils ont un volume élevé, sont déterministes, et réduisent la file d'attente de façon assez visible pour que le reste de l'équipe adhère au projet. Tenter de dévier les tickets de réclamation dès le premier jour est la façon dont les projets IA perdent leur crédibilité en interne.
Des chiffres réels d'équipes réelles (et ce qu'elles avaient en commun)
La sélection des études de cas est réelle - mais la leçon n'est pas « nous devrions aussi atteindre 86 %. » C'est « regardez à quel point chacune d'elles était bien délimitée. »
- Grammarly est passé de 60 % à 87 % de déviation en 10 jours avec la plateforme agentique de Forethought, avec un CSAT amélioré à 4,2/5. L'ajout d'intégrations système a contribué 5 à 10 % supplémentaires.
- Bilt Rewards gère 70 % de ses 60 000 tickets mensuels avec des agents IA.
- Duolingo maintient plus de 80 % de déviation avec Decagon.
- L'IA de Klarna gère les deux tiers de tout le service client - l'équivalent de 700 agents à temps plein.
- Les clients retail de Freshworks voient Freddy AI résoudre 53 % de toutes les demandes entrantes.
- Les clients eCommerce de Gorgias atteignent régulièrement 60 % de déviation même avec un temps de formation minimal.
Le fil conducteur n'est pas la plateforme. C'est le modèle opérationnel : périmètre strict dès le premier jour, intégrations profondes CRM/commandes/facturation, un seuil de confiance calibré, un parcours d'escalade propre, et l'habitude d'utiliser chaque escalade comme une mise à jour de la base de connaissances. Les fournisseurs varient ; la discipline, non.
Les propres benchmarks clients d'eesel reflètent le même schéma. Une entreprise d'analyse de données pour chauffeurs dans l'économie des plateformes sous Zendesk Business a résolu 73 % des demandes de niveau 1 dès son premier mois après un essai de 7 jours. Un helpdesk IT interne sous Jira Service Management est à 15 % de déviation avec un objectif de 55 % à mesure que leur base de connaissances et le périmètre des agents s'étendent. Ce qui bouge, ce n'est pas le modèle - ce sont les données d'entrée.
Les cinq choses que font les équipes qui font vraiment bouger les chiffres
Dans le dossier de plus de 50 déploiements en production analysés par Corebee.ai, le guide de déviation de Pylon, et le guide opérationnel de ClarityArc, les mêmes cinq variables apparaissent dans chaque équipe qui atteint une réduction honnête de 60 %+.
1. La qualité de la base de connaissances en premier, l'IA ensuite
C'est le levier à plus fort impact de tout le système. Une documentation bien structurée augmente la résolution réelle de 15 à 25 % - avant même de toucher aux paramètres du modèle. La raison pour laquelle la plupart des pilotes calent : les équipes pointent l'IA sur la base de connaissances qu'elles ont, pas sur celle dont elles ont besoin. La base de connaissances qu'elles ont été rédigée pour des agents humains qui connaissent déjà le produit, pas pour une IA qui doit répondre à froid.
Le correctif est mécanique : choisissez les deux ou trois intentions que vous allez cibler, auditez les articles de la base de connaissances correspondants, réécrivez-les pour des questions en langage naturel plutôt qu'en jargon interne, et incorporez des tickets récemment résolus dans la base de connaissances comme exemples concrets. Puis déployez.
Si vous partez d'une base de connaissances clairsemée, nos guides pour créer un chatbot de base de connaissances IA et choisir les bons outils de base de connaissances IA couvrent la plomberie des données.
2. Ciblez précisément. Puis encore plus précisément.
Le mode d'échec le plus cohérent dans l'analyse des discussions est celui des équipes qui essaient de couvrir « tout » dès le premier jour. Commencez avec 2 à 3 types de demandes pour lesquels la base de connaissances est vraiment complète. Couvrez-les bien - mesurez honnêtement, corrigez les lacunes, dépassez les 60 % de déviation réelle - et alors seulement élargissez.
Ce qui est exclu du périmètre du premier jour :
- Tout ce qui est chargé en émotions (litiges de remboursement, réclamations, escalades de comptes nommés)
- Tout ce qui est réglementé ou sensible à la conformité
- Tout ce qui nécessite de lire un contexte extérieur à la base de connaissances (bugs d'ingénierie, état du système lors d'incidents)
- Les tickets de vos comptes de premier rang - les VIPs vont chez des humains dès le premier message, sans exception
3. Intégrez suffisamment en profondeur pour que l'IA agisse, pas seulement décrive
Si l'IA ne peut que récupérer des articles de la base de connaissances, elle plafonnera à environ 35 à 40 % de déviation. Les déploiements à 60 à 90 % ont tous une intégration CRM, facturation et système de commandes qui permet à l'agent d'effectuer l'action réelle - consulter la commande, traiter le retour, changer le plan.
Les données de ClarityArc montrent que la profondeur d'intégration contribue 20 à 30 % en plus de la déviation base de connaissances uniquement. La meilleure citation de praticien sur ce point :
« Le vrai déblocage, c'est quand l'IA peut vraiment résoudre le problème de bout en bout dans vos systèmes, pas seulement suggérer quoi dire. »
C'est aussi pourquoi les chatbots basés sur des règles greffés en complément tendent à échouer. Ils récupèrent, mais n'agissent pas. Les clients posent une question qui nécessite des données de compte, le bot échoue, les chiffres de déviation augmentent tandis que le CSAT baisse. Les plateformes IA-natives - celles qui lisent votre helpdesk, votre CRM et votre système de commandes dans un seul runtime - ferment cette boucle.
4. Calibrez le routage par confiance - et laissez l'IA dire « je ne sais pas »
C'est l'objection décisive dans notre propre dossier d'appels clients :
« L'IA ne pourra jamais répondre à 100 % des questions, mais si elle essaie et répond juste "désolé, je ne sais pas", je ne peux pas aller vérifier mes 7 000 tickets pour voir si l'IA a vraiment bien répondu. J'ai besoin d'une IA qui ne gère que les tickets dont elle est sûre, et pour tous les autres, qu'elle les laisse tranquilles. »
un responsable CX d'une marque de compléments alimentaires DTC sur Gorgias + Shopify (~7 000 tickets/mois), dossier clients eesel (anonymisé avec consentement)
C'est toute la thèse sur le routage par confiance en une seule citation. Une IA qui répond à tout est pire qu'une IA qui répond à la moitié et escalade clairement le reste. Ajustez vos seuils élevé/moyen/faible par des tests sur du trafic réel, pas à l'intuition - et recalibrez-les chaque trimestre au fur et à mesure que la base de connaissances évolue.
Si vous voulez approfondir ce sujet, notre analyse du seuil de confiance d'intention des agents IA Zendesk explique comment un vrai helpdesk le met en oeuvre.
5. Traitez chaque escalade comme un signal d'apprentissage
Chaque fois que l'IA escalade, elle vous dit l'une de ces trois choses : la base de connaissances a une lacune, le périmètre était inadapté pour cette intention, ou le seuil de confiance doit être ajusté. Les équipes qui obtiennent les taux de déviation les plus élevés font une revue hebdomadaire de 20 à 30 conversations escaladées et transforment les schémas récurrents en mises à jour de la base de connaissances, changements de périmètre ou règles de routage.
Le contraire - les escalades s'accumulent sans être lues, le bot répond discrètement de façon incorrecte, personne n'audite - est la façon dont un taux de déviation de 65 % devient silencieusement un taux de suppression de 65 % et un pic de churn six mois plus tard.
Comment la réduction de tickets par IA déraille (les modes d'échec à anticiper)
Les mêmes schémas reviennent dans les plus de 50 fils de discussion d'équipes support analysés par Corebee, les post-mortems de la communauté DEV, et les conversations de praticiens dans l'analyse SaaStr de juin 2025. Si vous déployez, anticipez ces schémas dès le premier jour :
- Le taux de déviation devient un KPI. Dès que c'est un chiffre sur lequel les gens sont évalués, le système est optimisé pour atteindre ce chiffre - même au détriment de l'expérience client. Suivez-le comme un signal aux côtés du CSAT et du taux de re-contact, pas comme une cible.
- Les VIPs tombent sur le bot. Le mode d'échec le plus coûteux est que vos comptes de premier rang se heurtent à un mur IA pendant qu'un client à 40 $/mois obtient un humain. Routez les VIPs directement vers des humains dès le premier message. Toujours.
- Des réponses confiantes mais incorrectes. Le bot répond à une demande qu'il aurait dû escalader, le client lui fait confiance, et une question simple devient une crise de confiance. Le correctif est des garde-fous de périmètre thématique (le bot est autorisé à répondre sur X, pas autorisé sur Y), pas seulement un seuil de confiance.
- Boucles du bot sans escalade. Un bouton « parler à un humain » enfoui à quatre clics, un parcours d'escalade qui repose les mêmes questions que le bot avait déjà posées, ou aucun parcours humain du tout. Les clients quittent discrètement quand c'est l'expérience vécue.
- Afflux de re-contacts via d'autres canaux. Votre taux de déviation sur la plateforme monte, votre file téléphonique monte encore plus. Vérifiez toujours les volumes par canal avant de célébrer une victoire de déviation.
Un post-mortem de la communauté DEV d'une équipe traitant plus de 12 000 tâches d'agents par jour illustre cela crûment. Avant d'ajouter des vérifications humaines dans la boucle sur les tâches à enjeux élevés, leur taux d'erreur critique était de 23,4 %. L'agent a clôturé automatiquement 34 tickets qui auraient dû aller à l'ingénierie, dont trois incidents de production actifs. Un client a perdu six heures de données.
« Cet incident nous a coûté un contrat annuel de 280 000 $ et un post-mortem très inconfortable. »
Après l'ajout du HITL sur les bonnes tâches (pas une revue systématique de tout), le taux d'erreur critique est tombé à 5,1 % - une réduction de 78 % - et la charge de révision humaine a diminué de 62 %. La leçon que l'équipe a tirée : « La partie difficile n'est pas de construire l'agent - c'est de décider quand lui faire confiance. »
Un plan de déploiement qui ne détruit pas la confiance
Tout cela ramené à quelque chose que vous pouvez réellement faire dans les 90 prochains jours :
Semaines 1-2 - Diagnostic. Sortez vos 1 000 derniers tickets. Étiquetez-les par intention. Trouvez les trois premières intentions par volume et par complétude de la base de connaissances. Ne choisissez pas uniquement par volume - une intention à volume élevé avec une base de connaissances maigre est un projet, pas une victoire rapide.
Semaines 3-4 - Préparez la base de connaissances. Pour chaque intention retenue, réécrivez ou actualisez les articles de la base de connaissances. Ajoutez 5 à 10 exemples concrets tirés de tickets réels résolus. Supprimez le jargon interne. Testez en demandant à un agent junior de répondre à froid depuis la base de connaissances ; s'il ne peut pas, votre IA ne le pourra pas non plus.
Semaines 5-6 - Branchez les intégrations. Connectez le helpdesk, le CRM et le système de commandes/facturation. L'agent a besoin d'un accès en lecture sur l'état du compte et d'un accès en écriture sur les actions que vous souhaitez réellement qu'il effectue.
Semaines 7-8 - Pilote en mode copilote. Faites tourner l'IA comme copilote - en rédigeant des réponses, sans jamais les envoyer de façon autonome. Mesurez la fréquence à laquelle les agents humains envoient le brouillon sans modification, l'éditent légèrement, ou le réécrivent complètement. Si le taux « envoyé sans modification » atteint 60 %+ sur vos intentions ciblées, vous êtes prêt pour le mode autonome.
Semaines 9-12 - Passez à l'autonome sur l'intention la plus sûre en premier. Commencez avec une seule intention. Seuil de confiance élevé. Valeurs par défaut d'escalade agressives. Audits hebdomadaires des conversations. N'abaissez le seuil que lorsque les données le justifient.
C'est la discipline opérationnelle, pas la technologie, qui différencie les équipes rapportant une réduction honnête de 60 %+ des équipes affichant un taux de déviation de 35 % maquillé pour ressembler à 80 %. Pour une présentation plus complète, voir notre guide pratique pour réduire les tickets de support avec l'IA.
Essayez eesel
Si vous déployez la réduction de tickets par IA et que vous souhaitez une plateforme conçue pour le plan ci-dessus plutôt que contre lui - routage basé sur la confiance, intégrations profondes avec Zendesk, Freshdesk, Gorgias, et plus de 100 autres, contrôle du périmètre par type de ticket, et une tarification qui ne vous punit pas pour tester - c'est exactement ce pour quoi eesel a été conçu.
Les agents eesel vivent dans votre helpdesk existant (sans remplacement de plateforme), apprennent de votre historique de tickets et de votre base de connaissances dès le premier jour, et vous permettent de les briefer en langage naturel - « gère la file WISMO, escalade tout remboursement dépassant 500 $, laisse les tickets des clients mécontents tranquilles. » La tarification est par tâche, pas par siège ou par résolution, donc vous ne payez que pour les tickets que l'IA touche réellement.
Les vrais clients ont progressé rapidement. Une entreprise d'analyse de données pour chauffeurs dans l'économie des plateformes sous Zendesk Business a résolu 73 % des demandes de niveau 1 dès son premier mois après un essai de 7 jours. Une équipe support britannique a généré 56 tâches résolues à partir de seulement 9 macros synchronisées. Le niveau gratuit (50 $ de crédit, sans carte requise) est suffisant pour faire un vrai pilote sur vos propres données.
Essayez eesel gratuitement → - ou réservez une démo de 30 minutes si vous préférez que nous parcourions votre stack avec vous.
Questions fréquentes
Qu'est-ce que la réduction de tickets par IA ?
De combien la réduction de tickets par IA peut-elle réalistement dévier les demandes ?
Quelle est la différence entre la réduction et la déviation de tickets par IA ?
Combien de temps faut-il pour rentabiliser la réduction de tickets par IA ?
Quels tickets de support sont les plus faciles à réduire avec l'IA ?
La réduction de tickets par IA remplacera-t-elle mes agents de support ?
Quel est le meilleur outil de réduction de tickets par IA pour Zendesk, Freshdesk ou Gorgias ?

Article by
Riellvriany Indriawan
Riell is a designer and writer at eesel AI with about two years of experience researching CX platforms, AI chatbots, and helpdesk software. She combines her design background with a sharp eye for how these tools actually look and feel in practice — making her comparisons unusually visual and user-focused.









Comment mesurer honnêtement la réduction de tickets par IA ?