¿Cómo sé si mi soporte de IA está funcionando?
Alicia Kirana Utomo
Katelin Teen
Última edición June 17, 2026

Resumen
"¿Está funcionando mi soporte de IA?" se reduce a cinco números leídos juntos, no uno solo: tasa de resolución, tasa de deflexión, calidad de las respuestas, precisión de escalación y tasa de errores factuales. Si la resolución y la deflexión están subiendo mientras la calidad y el CSAT se mantienen, está funcionando. Si el volumen aumenta pero la satisfacción baja, o el bot responde con confianza sin citar nada, no lo está, sin importar lo ocupado que parezca.
La trampa es juzgar un agente de IA por actividad ("¡respondió a 4.000 tickets!") en lugar de por resultados. Un bot puede estar enormemente ocupado y estar silenciosamente equivocado. La solución es observar el pequeño conjunto de métricas que se describen a continuación, aprender a identificar las señales positivas y de alerta, e idealmente simular con tus tickets reales del pasado antes de confiar en él en vivo.
He pasado los últimos tres años y más implementando agentes de IA en colas de soporte en vivo en eesel, así que este es el cuadro de mando que realmente usaría.
Por qué "¿está funcionando?" es más difícil de lo que parece
Aquí está lo que la mayoría de los paneles no te dirán. El modo de fallo aterrador para el soporte de IA no es que el bot se quede en silencio, es que el bot suene muy bien mientras está equivocado.
He visto a un agente de sonido confiado decirle a un cliente "sí, admitimos el modelo de su auto" para marcas que no estaban en la base de conocimiento en absoluto, simplemente porque alguien había escrito "admitimos todos los modelos" en un documento de ayuda. El bot no estaba roto. Estaba haciendo exactamente lo que se le indicó, y lo hacía con perfecta fluidez. Esta es la razón por la que ahora simulamos cada implementación contra tickets históricos primero, en lugar de activar un interruptor y esperar.
Antes de pasar a los números: "funcionar" significa que la IA está resolviendo los tickets correctos correctamente, transfiriendo el resto limpiamente y no inventando nada en el medio. Los recuentos de actividad son vanidad. Los resultados son la verdad. Si solo te llevas una idea de este artículo, que sea esa.
Los cinco números que realmente te informan
Cuando los equipos me preguntan cómo interpretar su agente de IA, los dirijo a las mismas cinco métricas de soporte al cliente. Leídas juntas, capturan casi todos los modos de fallo.
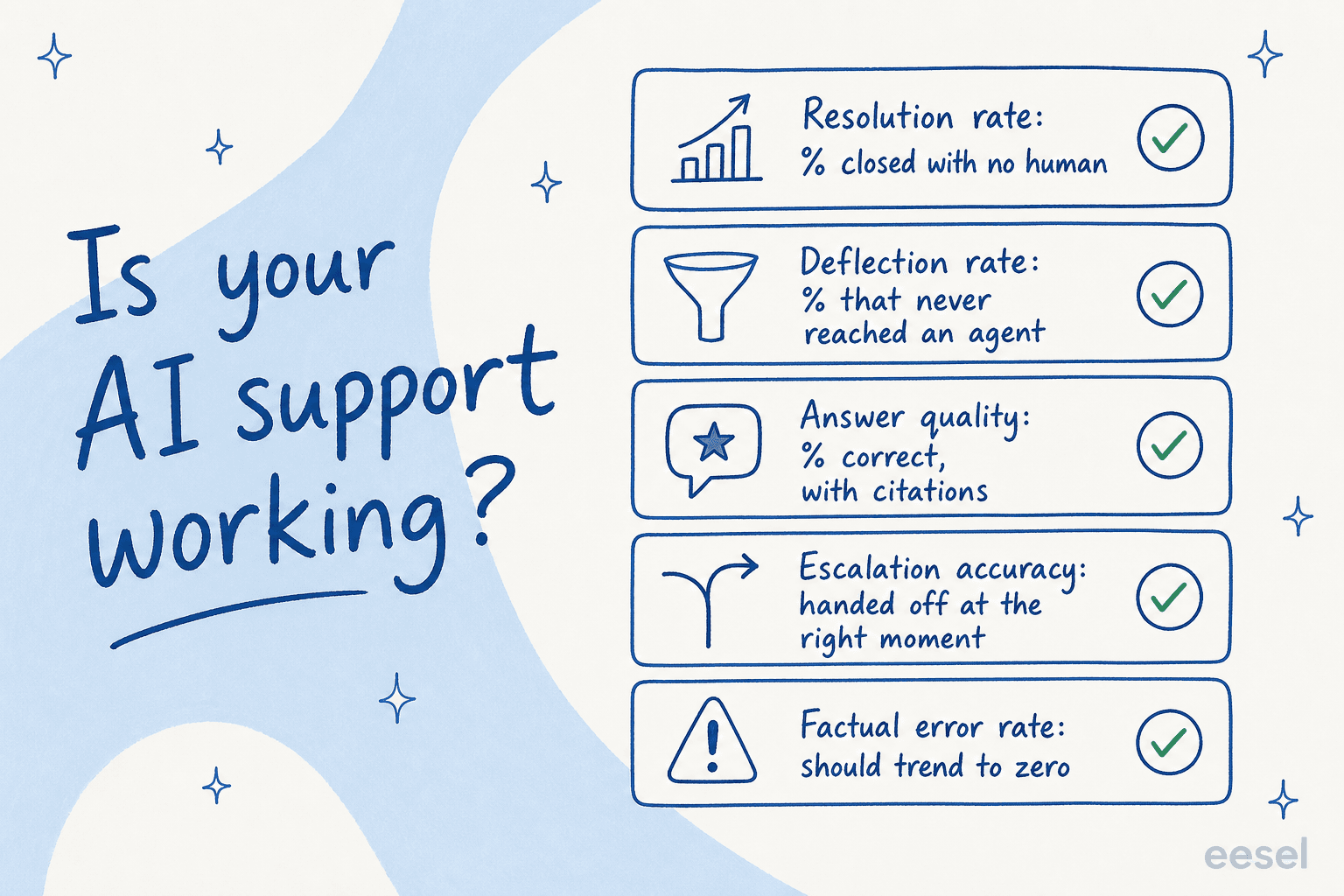
1. Tasa de resolución
El número principal: qué porcentaje de tickets cerró la IA de principio a fin sin que un humano los tocara. Este está directamente vinculado al costo, porque cada ticket resuelto es uno que un agente no tuvo que abrir.
¿Qué es "bueno"? Depende completamente de tu combinación de tickets, pero el nivel 1 es donde la IA demuestra su valor primero. Una aplicación de análisis de conductores de economía gig en Zendesk nos dijo, en una reseña pública de G2, que eesel estaba resolviendo el 73 % de sus solicitudes de nivel 1 en el primer mes, con resultados que aparecían dentro de una prueba de 7 días. En el otro extremo, un servicio de ayuda de TI interno en Jira comenzó en el 15 % de deflexión y estableció un objetivo del 55 %. Ambos "funcionan". El punto no es un punto de referencia universal, es la tendencia: ¿está subiendo la tasa de resolución a medida que alimentas al agente con más conocimiento?
2. Tasa de deflexión
La deflexión y la resolución se usan indistintamente, y no deberían serlo. La resolución es un ticket cerrado sin un humano. La deflexión es un cliente que obtuvo su respuesta y nunca abrió un ticket en absoluto, generalmente a través de un widget de chat o autoservicio antes de que la conversación se convirtiera en un caso de soporte.
Vale la pena rastrearlo por separado, porque una alta tasa de deflexión es lo que silenciosamente reduce tu cola. Si quieres la definición precisa y la fórmula, escribimos sobre qué es la tasa de deflexión y cómo mejorarla, y una pieza separada sobre cómo medir la deflexión de IA versus la deflexión humana para que no cuentes doble.
3. Calidad de las respuestas
El volumen sin calidad es la trampa. Así que la pregunta real detrás de la resolución es: cuando la IA respondió, ¿tenía razón, y mostró su trabajo?
Esto es medible. En una muestra de una semana de 581 chats, calificamos la calidad del chat en el 96 %. En otra muestra de 434 chats, el desglose fue 86 % bueno, 7 % parcial, 6 % deflectado y 1 % fallido por completo, y en tickets reales activados por webhook (la prueba más difícil) fue del 79 % bueno. El método exacto importa menos que tener uno: califica una muestra de respuestas por corrección y si llevaban una cita. Una respuesta sin fuente adjunta es una respuesta en la que no puedes confiar. Un fundador de legal-tech con quien trabajamos lo expresó bien: con eesel podían "establecer límites exactos en las fuentes y siempre proporciona citas transparentes", lo que en su mundo es la diferencia entre útil y una demanda.
4. Precisión de escalación
Un buen agente de IA sabe lo que no sabe. Así que la precisión de escalación es realmente una medida del juicio: cuando la IA no estaba segura, ¿transfirió a un humano en lugar de adivinar?
Este es el número más subestimado de la lista. Quieres un agente que resuelva con confianza y escale honestamente, no uno que responda todo. Un líder de soporte en una plataforma de SMS capturó el ideal en una reseña de G2: la IA "responde con confianza pero no demasiada confianza." Esa segunda parte es todo el juego. Rastrea tu tasa de escalación y, más importante, si las escalaciones ocurren en el momento correcto.
5. Tasa de errores factuales
Por último, el número que debería tender hacia cero: con qué frecuencia la IA dice algo falso. Esto es diferente de las respuestas "parciales". Un error factual es el bot que afirma un hecho incorrecto como si fuera cierto.
En una prueba en el tráfico real de Zendesk de una joyería alemana (alrededor de 1.000 tickets al mes), medimos el 93 % de precisión en el triaje y el 100 % de detección de spam con cero falsos positivos, pero también una tasa de errores factuales del 7 % que nos dijo exactamente dónde tenía brechas la base de conocimiento. Ese 7 % no era razón para abandonar la implementación. Era un mapa. Cada error factual apunta a un documento faltante o contradictorio, que generalmente es corregible, y es el grueso de lo que trata nuestra guía sobre cómo prevenir las alucinaciones de IA en el soporte.
Las señales positivas (y las señales de alerta)
Los números te muestran la tendencia. Pero hay señales cualitativas que puedes leer en una sola tarde revisando transcripciones, y a menudo son más rápidas que esperar un mes de datos.
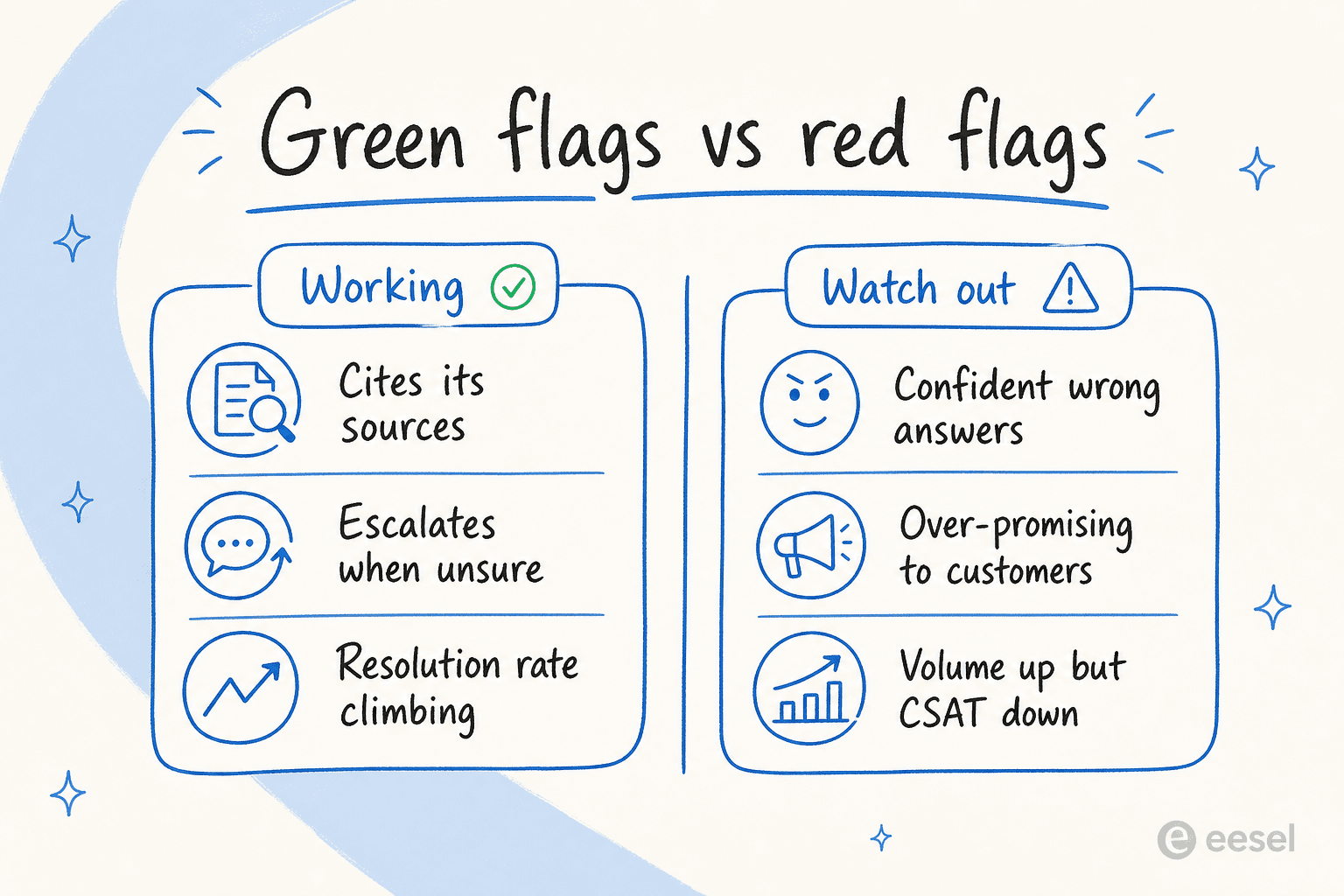
Las señales positivas son las fáciles. La IA cita sus fuentes en cada respuesta. Escala cuando realmente no está segura en lugar de fingir. Tu tasa de resolución está tendiendo al alza semana tras semana, no estancada. Y, la señal más simple de todas, tus agentes dejan de quejarse de tickets repetitivos.
Las señales de alerta son donde pondría tu atención, porque se esconden detrás de paneles que parecen buenos:
- Respuestas incorrectas con confianza. El ejemplo del modelo de auto de antes. El bot es fluido, seguro e incorrecto. Este es el patrón más dañino de todos, porque los clientes lo creen.
- Promesas excesivas. He visto agentes tranquilizar a los clientes de maneras que el negocio no puede respaldar. Un gerente de soporte nos lo señaló directamente, diciéndole a la IA que "deje de decirles a los clientes que los resolveremos. No lo sabes," y "deja de prometerle a los clientes cosas que no podemos hacer." Si tu bot está haciendo compromisos sobre fechas de entrega o resultados, eso es un problema de control, no de conocimiento.
- Volumen en aumento, CSAT en descenso. El agente está manejando más, y los clientes están menos satisfechos. Esa divergencia es la señal más clara de que "ocupado" y "funcionando" se han separado.
- Sin citas. Si no puedes ver de dónde vino una respuesta, el cliente tampoco puede, y tú tampoco cuando la estés auditando más tarde.
La mayoría de estos provienen de brechas de conocimiento o protecciones faltantes, lo cual es una buena noticia, porque ambos son corregibles sin desmantelar nada. El artículo sobre problemas comunes de chatbots de IA profundiza en los culpables habituales.
Dónde buscar realmente
Todo esto supone que puedes ver lo que está haciendo tu agente de IA. Si tu herramienta solo te muestra un recuento total, eso es lo primero que debes corregir, porque no puedes gestionar lo que no puedes leer.
Las dos vistas que reviso con más frecuencia son el panel de informes y el registro de actividad sin procesar. La vista de informes es donde vive la tendencia: volumen de tareas a lo largo del tiempo, cómo se activaron las tareas (chat, correo electrónico, nota interna) y cuántas acciones de IA fueron aprobadas, rechazadas o aún esperan una decisión humana. Esa proporción de aprobación frente a rechazo es un indicador rápido de confianza.

El registro de actividad es donde lees el trabajo real. Cada conversación, su canal, el ticket vinculado y si terminó resuelta o pendiente. Aquí es donde vas a verificar muestras de calidad de respuesta y detectar los casos confiados-incorrectos que los números agregados suavizan. Revisaría diez de estos por semana, como mínimo.

Si tu servicio de ayuda ya ejecuta encuestas de CSAT en conversaciones cerradas, vincula esas puntuaciones específicamente a los tickets manejados por IA. Ese único corte, CSAT en tickets resueltos por IA versus los resueltos por humanos, resuelve la mayoría de los debates "¿es realmente bueno?" más rápido que cualquier otra cosa.
No esperes hasta que esté en vivo para descubrirlo
Aquí está la parte que la mayoría de los equipos omite, y la que más insistiría en seguir: no tienes que descubrir si tu IA funciona probándola con clientes reales.
El error es tratar el lanzamiento como un interruptor de encendido/apagado. El mejor modelo es una rampa. Gradúas la IA a través de etapas de autonomía a medida que los números lo justifican, no antes.
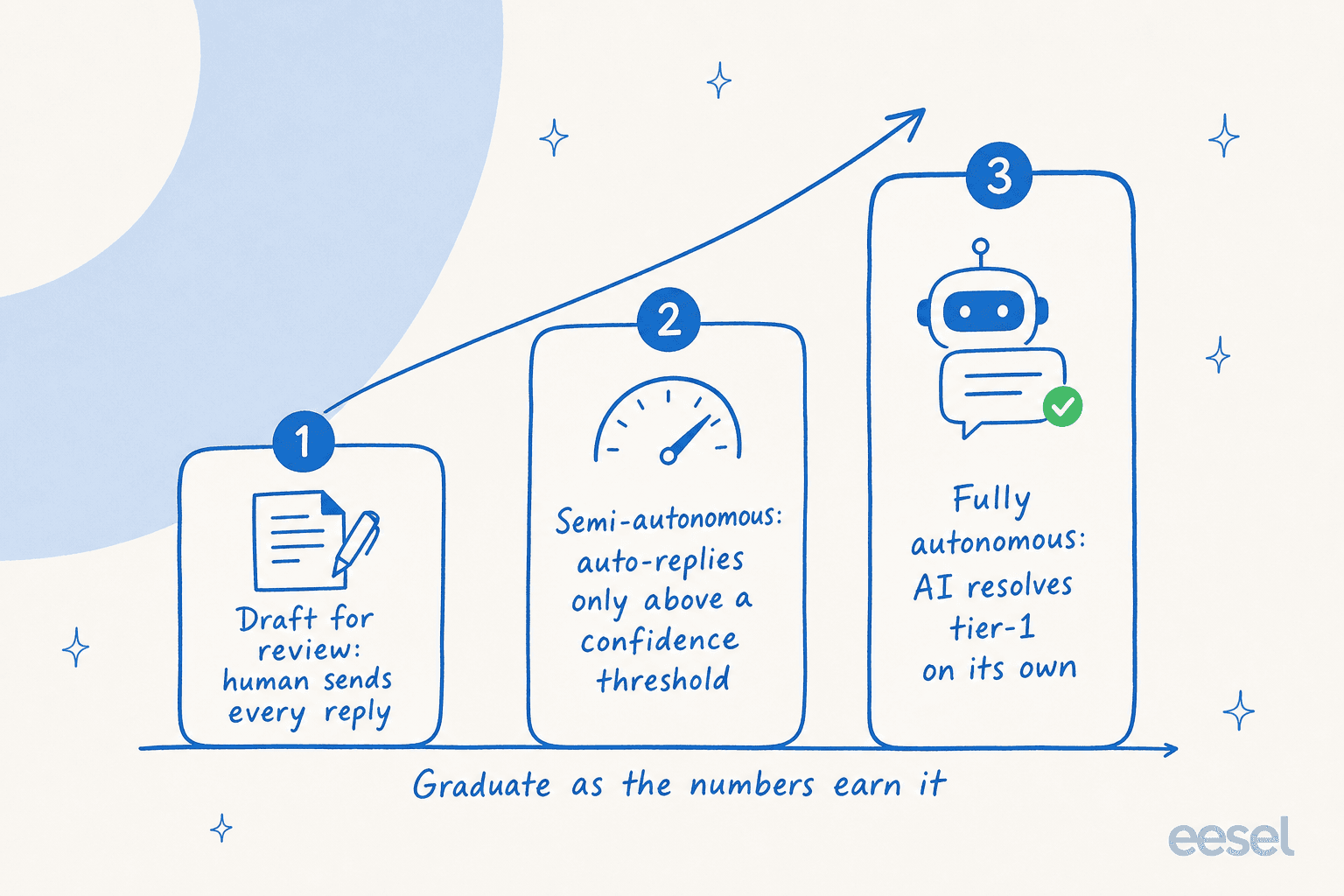
Comienzas en modo borrador, donde la IA escribe respuestas pero un humano envía cada una, por lo que estás calificando la calidad sin ningún riesgo para el cliente. A medida que las respuestas se validan, pasas a semi-autónomo, dejando que la IA responda automáticamente solo por encima de un umbral de confianza y redirigiendo el resto a una persona. Una vez que los números se mantienen, la dejas correr completamente de forma autónoma en los casos de nivel 1 que se ha ganado.
Incluso antes del modo borrador, puedes ejecutar una simulación en miles de tus tickets reales pasados para ver exactamente cómo habría respondido la IA a cada uno, con una tasa de resolución predicha, antes de que salga una sola respuesta en vivo. Ese ensayo de la joyería alemana que mencioné ejecutó una validación cruzada de 100 tickets precisamente de esta manera. Simular primero es cómo respondes "¿está funcionando?" antes de haber arriesgado a un solo cliente. También es, honestamente, la parte que desearía que más equipos hicieran, porque convierte un salto de fe en una medición.
Un aviso justo, ya que trabajo en esto: eesel se integra profundamente con servicios de ayuda como Zendesk, Freshdesk y Help Scout, así que no soy un observador neutral de la categoría. Pero el enfoque de rampa y simulación se aplica con cualquier herramienta que uses. Si tu proveedor de IA no puede mostrarte una prueba en seco con tus propios tickets, eso en sí mismo es una señal amarilla que vale la pena preguntar.
Prueba eesel
Si quieres responder "¿está funcionando mi soporte de IA?" con números en lugar de corazonadas, ese es el problema que eesel está diseñado para resolver. Conectas tu servicio de ayuda y tus fuentes de conocimiento, le das instrucciones al agente en un lenguaje claro y ejecutas una simulación en tus tickets pasados para obtener una tasa de resolución predicha antes de salir en vivo, luego aumentas desde el modo borrador hasta la autonomía con los informes para respaldar cada paso.

Funciona con precios basados en el uso sin tarifas por asiento, y hay un nivel gratuito para probarlo con tu propia cola. Puedes ver cómo otros equipos midieron sus implementaciones en la página de clientes, o lee nuestra guía práctica de IA en atención al cliente para el manual completo. Prueba eesel y descubre cuál sería tu tasa de resolución real.
Preguntas frecuentes
¿Cómo sé si mi soporte de IA está funcionando?
¿Cuál es una buena tasa de resolución para un agente de soporte de IA?
¿En qué se diferencia la deflexión de IA de la resolución de IA?
¿Cuáles son las señales de advertencia de que mi agente de soporte de IA está fallando?
¿Puedo probar mi soporte de IA antes de permitirle responder a los clientes?

Article by
Alicia Kirana Utomo
Kira is a writer at eesel AI with a Computer Science background and over a year of hands-on experience evaluating AI-powered customer service tools. She focuses on breaking down how helpdesk platforms and AI agents actually work so that support teams can make better buying decisions.